目录
[一、MySQL 的四层体系结构](#一、MySQL 的四层体系结构)
[1.1 连接层](#1.1 连接层)
[1.2 服务层](#1.2 服务层)
[1.3 引擎层(存储引擎层)](#1.3 引擎层(存储引擎层))
[1.4 存储层](#1.4 存储层)
[2.1 存储引擎的定义](#2.1 存储引擎的定义)
[2.2 存储引擎的基础操作](#2.2 存储引擎的基础操作)
[(3)查询 MySQL 支持的所有存储引擎](#(3)查询 MySQL 支持的所有存储引擎)
三、主流存储引擎详解:InnoDB/MyISAM/Memory
[3.1 InnoDB:兼顾高可靠性与高性能的通用引擎](#3.1 InnoDB:兼顾高可靠性与高性能的通用引擎)
[3.2 MyISAM:轻量高效的只读 / 读多写少引擎](#3.2 MyISAM:轻量高效的只读 / 读多写少引擎)
[3.3 Memory:基于内存的临时存储引擎](#3.3 Memory:基于内存的临时存储引擎)
[4.1 核心特性对比表](#4.1 核心特性对比表)
[4.2 面试高频题:InnoDB 与 MyISAM 的核心区别](#4.2 面试高频题:InnoDB 与 MyISAM 的核心区别)
[5.1 选 InnoDB:绝大多数生产环境的首选](#5.1 选 InnoDB:绝大多数生产环境的首选)
[5.2 选 MyISAM:读多写少的静态数据场景](#5.2 选 MyISAM:读多写少的静态数据场景)
[5.3 选 Memory:临时数据存储 / 缓存场景](#5.3 选 Memory:临时数据存储 / 缓存场景)
[5.4 混合选型:复杂系统的灵活方案](#5.4 混合选型:复杂系统的灵活方案)
前言
在 MySQL 的学习和实战中,存储引擎是绕不开的核心知识点。不同于其他数据库,MySQL 采用插件式的存储引擎架构,将查询处理与数据的存储、提取相分离,这让 MySQL 能在不同业务场景下灵活适配,发挥最优性能。本文将从 MySQL 体系结构入手,全面讲解存储引擎的核心概念、主流引擎的特点与区别,以及实际业务中的选型策略,覆盖 MySQL 存储引擎的所有核心知识点。
一、MySQL 的四层体系结构
要理解存储引擎,首先要明确它在 MySQL 整体架构中的位置。MySQL 的体系结构从上到下分为四层,存储引擎层是核心层之一,与连接层、服务层、存储层协同工作,各层职责清晰、分工明确。
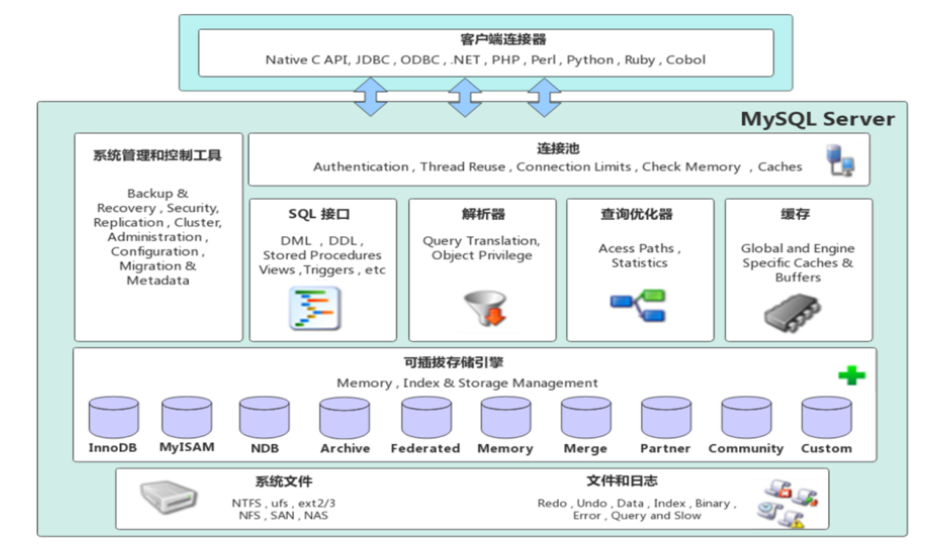
1.1 连接层
最上层是客户端与服务器的连接服务,核心职责是处理客户端的连接请求,完成身份认证 和权限校验,同时提供线程池管理、SSL 安全连接等能力。
- 支持多种客户端连接器:Native CAPI、JDBC、ODBC、PHP、Python 等;
- 为通过认证的客户端分配独立线程,保证并发访问;
- 验证客户端对数据库 / 表的操作权限,无权限则直接拒绝请求。
1.2 服务层
MySQL 的核心服务层,完成绝大多数核心功能,是跨存储引擎的功能统一实现层,无论使用哪种存储引擎,该层的处理逻辑均一致。
- 核心能力:SQL 接口、查询缓存、SQL 解析器、查询优化器、内置函数执行;
- 关键流程:解析客户端的 SQL 语句并生成内部解析树,优化查询计划(如确定表查询顺序、是否使用索引),最终生成执行操作;
- 跨引擎功能:存储过程、函数、视图、触发器等均在该层实现;
- 性能优化点:对 SELECT 语句会先查询内部缓存,缓存命中可大幅提升读操作效率。
1.3 引擎层(存储引擎层)
本文的核心,也是 MySQL 架构的特色所在 ------真正负责数据的存储和提取,服务器通过 API 与存储引擎进行通信。
- 插件式架构:支持多种存储引擎,可根据业务需求灵活选择;
- 核心能力:数据存储、索引创建、DML 操作(增删改)的具体实现;
- 关键特点:索引在该层实现,不同存储引擎的索引结构、锁机制等差异显著;
- 主流引擎:InnoDB、MyISAM、Memory、Archive 等,其中 InnoDB 为 MySQL5.5 + 的默认引擎。
1.4 存储层
MySQL 的最底层,负责将数据持久化到文件系统,并完成与存储引擎层的交互。
- 存储内容:不仅包含业务数据,还包括数据库的各类日志(redo log、undo log、二进制日志、慢查询日志等)、索引文件、表结构文件;
- 交互方式:存储引擎层将数据操作指令传递给存储层,存储层完成文件的读写、磁盘 I/O 等物理操作。
四层架构的核心优势:将查询处理与数据存储解耦,让存储引擎可根据业务场景灵活替换,这是 MySQL 能适配从简单静态查询到高并发事务系统的关键。
二、存储引擎核心概念
2.1 存储引擎的定义
存储引擎是MySQL 中存储数据、建立索引、更新 / 查询数据的技术实现方式 ,也被称为表类型 ------存储引擎是基于表的,而非基于数据库。
这意味着一个 MySQL 数据库中,不同的表可以根据需求选择不同的存储引擎,极大提升了数据库的灵活性。
2.2 存储引擎的基础操作
(1)建表时指定存储引擎
如果建表时未指定,MySQL 会使用默认存储引擎(MySQL5.5 + 为 InnoDB),指定语法如下:
CREATE TABLE 表名(
字段1 字段1类型 [COMMENT 字段1注释],
字段n 字段n类型 [COMMENT 字段n注释]
) ENGINE = 存储引擎名 [COMMENT 表注释] ;示例 1:创建使用 MyISAM 引擎的表
create table my_myisam(
id int,
name varchar(10)
) engine = MyISAM ;示例 2:创建使用 Memory 引擎的表
create table my_memory(
id int,
name varchar(10)
) engine = Memory ;(2)查询当前数据库的默认存储引擎
通过查询建表语句,可查看某张表的存储引擎(未指定则为默认):
-- 查看account表的建表语句,包含存储引擎信息
show create table account;(3)查询 MySQL 支持的所有存储引擎
show engines;执行结果会展示 MySQL 支持的所有引擎,以及引擎的是否可用、事务支持、锁机制等核心属性。
三、主流存储引擎详解:InnoDB/MyISAM/Memory
MySQL 支持多种存储引擎,其中InnoDB、MyISAM、Memory是最常用的三种,三者的设计理念、核心特性、适用场景差异巨大,下面逐一详解。
3.1 InnoDB:兼顾高可靠性与高性能的通用引擎
InnoDB 是 MySQL5.5 + 的默认存储引擎,也是目前生产环境中使用最广泛的引擎,专为高并发、需要事务支持的场景设计,兼顾数据的可靠性和访问性能。
(1)核心特点
- 支持事务:DML 操作遵循 ACID 模型,支持事务的提交、回滚,可通过事务保证数据的一致性;
- 行级锁:针对行数据加锁,大幅提升高并发场景下的访问性能(避免全表锁导致的并发阻塞);
- 支持外键约束:通过 FOREIGN KEY 约束保证表之间的关联完整性,避免脏数据;
- 崩溃恢复:基于 redo log、undo log 实现崩溃恢复,保证数据不丢失。
(2)文件组成
InnoDB 引擎的每张表对应一个xxx.ibd 文件(表空间文件),该文件是二进制文件,包含了表的表结构(新版为 sdi、早期为 frm)、业务数据、索引信息。
-- 查看该参数状态
show variables like 'innodb_file_per_table';该参数默认开启,代表每张 InnoDB 表对应一个独立的 ibd 文件,便于表的管理和数据迁移;若关闭,所有表的数据会存储在系统表空间文件(ibdata1)中。
表结构提取 :ibd 文件为二进制文件,无法直接打开,可通过 MySQL 自带的ibd2sdi指令提取其中的 sdi 数据字典信息,从而查看表结构。
(3)逻辑存储结构
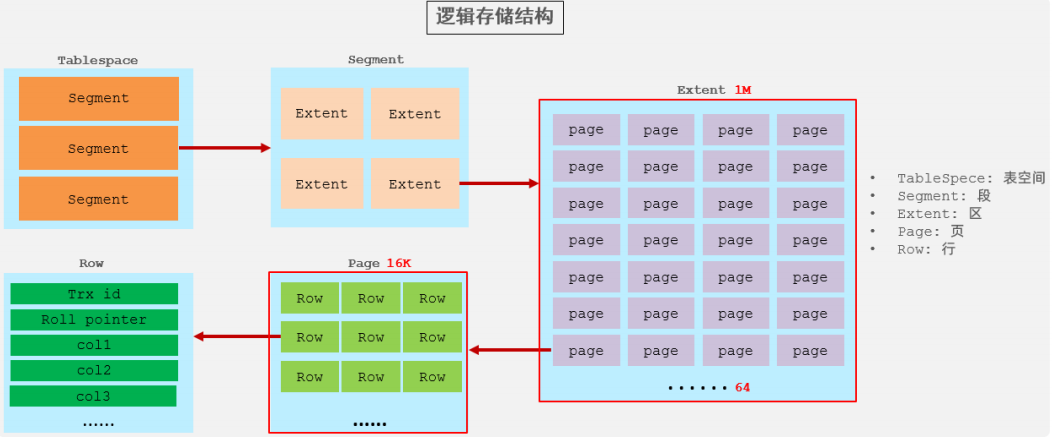
InnoDB 的数据存储有严格的层级逻辑,从高到下依次为:表空间 → 段 → 区 → 页 → 行,各层级职责和大小固定,是 InnoDB 高效管理数据的基础。
- 表空间:逻辑存储的最高层,ibd 文件就是表空间文件,一个表空间包含多个段;
- 段:分为数据段、索引段、回滚段等,由 InnoDB 引擎自动管理,无需人工干预,一个段包含多个区;
- 区 :表空间的单元结构,固定大小 1MB ,默认页大小为 16KB,因此一个区包含 64 个连续的页;
- 页 :InnoDB 磁盘管理的最小单元,固定大小 16KB,为保证页的连续性,InnoDB 每次从磁盘申请 4-5 个区;
- 行:InnoDB 面向行存储,每行除了自定义字段,还包含两个隐藏字段(事务 ID、回滚指针),用于事务和 MVCC 实现。
3.2 MyISAM:轻量高效的只读 / 读多写少引擎
MyISAM 是 MySQL 早期的默认存储引擎,设计理念为轻量、高效,舍弃了事务、外键等复杂功能,专注于提升读操作性能,适合读多写少的场景。
(1)核心特点
- 不支持事务、外键:简化设计,提升基础操作效率;
- 仅支持表锁:对整张表加锁,写操作会阻塞全表的读、写操作,并发性能差;
- 访问速度快:无事务、锁机制的额外开销,读操作(SELECT)性能优于 InnoDB;
- 表损坏修复 :支持
myisamchk工具修复损坏的表文件,适合静态数据存储。
(2)文件组成
MyISAM 的每张表对应三个独立文件,文件前缀为表名,后缀分别为:
- xxx.sdi:存储表结构信息;
- xxx.MYD:MYData,存储业务数据;
- xxx.MYI:MYIndex,存储索引信息。
数据与索引分离存储,让 MyISAM 的索引维护更轻量,这也是其读操作快的原因之一。
3.3 Memory:基于内存的临时存储引擎
Memory 引擎(也叫 Heap 引擎)将所有数据存储在内存中,磁盘中仅保留表结构文件,访问速度是三者中最快的,但存在数据持久化的缺陷,适合作为临时表或缓存使用。
(1)核心特点
- 内存存储:数据全部在内存中,磁盘 I/O 为 0,查询、插入速度极快;
- 默认 Hash 索引:与 InnoDB、MyISAM 的 B+Tree 索引不同,Memory 默认使用 Hash 索引,等值查询效率更高,但不支持范围查询;
- 数据非持久化:服务器重启、崩溃后,内存中的数据会全部丢失,仅保留表结构;
- 表大小限制:受内存大小和配置参数限制,无法存储大量数据。
(2)文件组成
Memory 引擎的每张表仅对应一个xxx.sdi文件,仅存储表结构信息,无数据和索引文件(数据、索引均在内存中)。
四、三大存储引擎核心对比(含面试高频考点)
为了更直观的区分三者的差异,下面从存储限制、事务支持、锁机制、索引类型 等维度做全面对比,同时梳理面试中高频的InnoDB 与 MyISAM 区别考点。
4.1 核心特性对比表
| 特性 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有(受内存限制) |
| 事务安全 | 支持 | 不支持 | 不支持 |
| 锁机制 | 行级锁(支持表锁) | 仅表锁 | 仅表锁 |
| B+Tree 索引 | 支持 | 支持 | 支持 |
| Hash 索引 | 不支持(自适应 Hash) | 不支持 | 支持(默认) |
| 全文索引 | 5.6 版本后支持 | 支持 | 不支持 |
| 空间使用 | 高(数据 + 索引一体化) | 低(数据 + 索引分离) | N/A(内存存储) |
| 内存使用 | 高(缓冲池缓存数据 + 索引) | 低(仅缓存索引) | 中等 |
| 批量插入速度 | 低(事务、锁开销) | 高 | 高 |
| 外键支持 | 支持 | 不支持 | 不支持 |
| 数据持久化 | 支持 | 支持 | 不支持 |
| 崩溃恢复 | 支持 | 不支持 | 不支持 |
4.2 面试高频题:InnoDB 与 MyISAM 的核心区别
这是 MySQL 面试中必问的考点 ,核心区别围绕事务、锁机制、外键三个核心点展开,拓展可结合索引、存储、并发性能等维度,答案如下:
- 事务支持:InnoDB 支持事务,遵循 ACID 模型;MyISAM 不支持事务,操作原子性无法保证;
- 锁机制:InnoDB 支持行级锁和表锁,高并发场景下阻塞少,并发性能优;MyISAM 仅支持表锁,写操作会阻塞全表,并发性能差;
- 外键支持:InnoDB 支持外键约束,可保证表间关联的完整性;MyISAM 不支持外键,需通过业务代码保证数据一致性;
- 索引与存储:InnoDB 的索引与数据一体化存储在 ibd 文件中,为聚簇索引;MyISAM 的索引与数据分离存储在 MYI、MYD 文件中,为非聚簇索引;
- 缓存机制:InnoDB 的缓冲池可缓存数据和索引,MyISAM 仅缓存索引,读操作的缓存效率 InnoDB 更优;
- 崩溃恢复:InnoDB 基于 redo log、undo log 实现崩溃恢复,MyISAM 无此机制,表损坏需手动修复。
五、存储引擎的选型策略:根据业务场景定方案
存储引擎的选型没有 "最优解",只有 "最合适的解",核心原则是匹配业务的核心需求。对于复杂的应用系统,还可根据表的功能不同,组合使用多种存储引擎。
5.1 选 InnoDB:绝大多数生产环境的首选
适用场景:
- 需支持事务的场景:金融、电商、支付等核心业务系统,要求数据的一致性和可靠性;
- 高并发读写的场景:用户中心、订单系统、商品库等,行级锁能保证高并发下的性能;
- 需使用外键的场景:多表关联紧密的业务,通过外键约束避免脏数据。
核心优势:兼顾事务、并发、可靠性,是 MySQL 官方推荐的默认引擎,能覆盖 90% 以上的业务场景。
5.2 选 MyISAM:读多写少的静态数据场景
适用场景:
- 静态数据查询:博客系统的文章表、新闻系统的资讯表、报表系统的统计结果表;
- 纯读操作的场景:数据仓库的历史数据表、日志查询系统的日志表;
- 对性能要求高、无需事务的场景:搜索引擎的索引表、缓存落地的临时表。
核心优势:读操作性能高,资源开销小,表文件简单易管理。
5.3 选 Memory:临时数据存储 / 缓存场景
适用场景:
- 临时计算:复杂查询的中间结果集、报表生成的临时数据;
- 缓存层:作为数据库的缓存,存储热点数据,提升查询速度;
- 会话存储:用户的临时会话信息、验证码信息等无需持久化的数据。
核心注意点:数据非持久化,需在业务中做容错处理;避免存储大量数据,防止内存溢出。
5.4 混合选型:复杂系统的灵活方案
对于大型复杂的应用系统,可根据表的功能拆分,组合使用多种引擎:
- 核心业务表(订单、用户、支付):用 InnoDB 保证事务和并发;
- 静态查询表(文章、分类):用 MyISAM 提升读性能;
- 临时计算表(中间结果、缓存):用 Memory 提升处理速度。