本文介绍如何从零开始构建一个完整的 RAG(检索增强生成)智能体系统,使用 Qwen 系列模型、ChromaDB 向量数据库,完全不依赖 LangChain 等框架,实现文档检索、知识问答等核心功能。
📋 目录
主要功能列表
🎯 核心功能
1. 深度思考模式 💭
- 功能说明 :启用后,模型会显示完整的思考过程(
<think>标签内的内容),帮助理解模型的推理逻辑 - 使用方式:在聊天界面勾选「深度思考」复选框
- 技术实现 :通过
enable_thinking参数控制,使用 Qwen3-4B 的思考模式能力 - 适用场景:需要理解模型推理过程、调试复杂问题、学习 AI 思考方式
python
# 代码实现
thinking_ck = gr.Checkbox(label="深度思考", value=False)
enable_thinking = thinking_ck.value
response = model.chat(message, enable_thinking=enable_thinking)2. 知识库自由开关 📚
- 功能说明:可以随时开启或关闭知识库检索功能,灵活控制是否使用知识库内容
- 使用方式:在聊天界面勾选「使用知识库」复选框
- 工作原理 :
- 开启时:用户问题会先进行知识库检索,检索到的相关内容会作为上下文输入 LLM
- 关闭时:直接使用 LLM 的通用知识回答,不进行知识库检索
- 优势:节省检索时间,快速响应简单问题;需要专业知识时再开启
python
# 代码实现
use_kb_ck = gr.Checkbox(label="使用知识库", value=False)
if use_kb and kb_loaded:
kb_results = knowledge_base.search(message, top_k=3)
context = "\n\n【相关知识库内容】\n" + format_results(kb_results)
prompt = f"{context}\n\n问题:{message}\n回答:"
else:
prompt = message3. 广度搜索(Reranker 开关) 🔍
- 功能说明:控制是否使用 Reranker 模型进行精确重排序,提升搜索精度
- 使用方式:在聊天界面勾选「广度搜索」复选框
- 工作原理 :
- 关闭(仅 Embedding):快速检索,使用向量相似度排序,速度更快
- 开启(Embedding + Reranker):两阶段检索,先用 Embedding 召回 top-15,再用 Reranker 精排 top-3,精度更高
- 性能对比 :
- 仅 Embedding:检索时间 < 10ms,精度中等
- Embedding + Reranker:检索时间 < 150ms,精度高
- 设计理念 :节省回答等待时间。简单问题用快速检索,复杂问题用精确检索
python
# 代码实现
broad_search_ck = gr.Checkbox(label="广度搜索", value=False)
results = knowledge_base.search(
query=message,
top_k=3,
use_reranker=broad_search # 控制是否使用 Reranker
)4. 终止对话 ⏹️
- 功能说明:可以随时中断正在生成的回答,节省时间和资源
- 使用方式:点击「⏹ 停止生成」按钮
- 技术实现 :通过全局标志位
_stop_flag控制,生成器在下一个 token 时检查并退出
python
# 代码实现
def stop_chat_fn():
global _stop_flag
_stop_flag = True
# 在生成循环中检查
for tok in model.stream_chat(...):
if _stop_flag:
break
yield tok5. 模型参数设置 ⚙️
- 功能说明:可以灵活调整模型生成参数,控制回答的风格和质量
- 可调参数 :
- Temperature (0.0-2.0):控制随机性,值越大越随机
- Max Tokens (128-8192):最大生成长度
- Top-p (0.0-1.0):核采样,控制候选词范围
- Top-k (1-100):Top-k 采样,限制候选词数量
- 系统提示词:自定义 AI 角色和对话风格
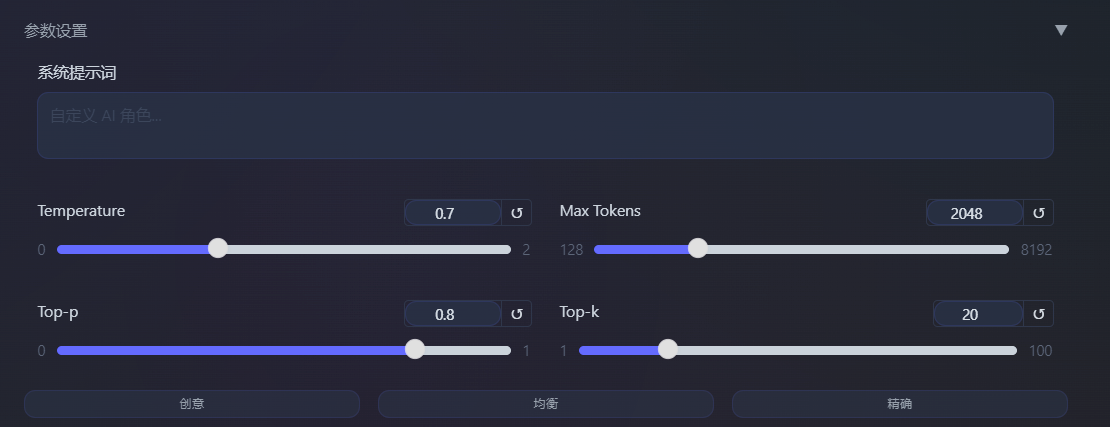
- 预设模式 :
- 创意模式:Temperature=1.2, Top-p=0.95, Top-k=40(适合创作、头脑风暴)
- 均衡模式:Temperature=0.7, Top-p=0.8, Top-k=20(默认,适合大多数场景)
- 精确模式:Temperature=0.3, Top-p=0.7, Top-k=10(适合事实性回答、代码生成)
python
# 代码实现
temperature = gr.Slider(0.0, 2.0, value=0.7, step=0.05, label="Temperature")
max_tokens = gr.Slider(128, 8192, value=2048, step=128, label="Max Tokens")
top_p = gr.Slider(0.0, 1.0, value=0.8, step=0.05, label="Top-p")
top_k = gr.Slider(1, 100, value=20, step=1, label="Top-k")
system_prompt = gr.Textbox(label="系统提示词", placeholder="自定义 AI 角色...", lines=2)6. 知识库管理 📖
6.1 添加文档
- 支持方式 :
- 文本输入:直接粘贴或输入文档内容
- 文件上传:支持多种格式(PDF、DOCX、TXT、MD、JSON、CSV、HTML 等)
- 自动处理 :
- 文本分割(chunk_size=500, overlap=50)
- Embedding 编码
- 向量存储到 ChromaDB
- 支持格式 :
- 文档:
.pdf,.docx,.doc,.txt,.md - 表格:
.xlsx,.xls,.csv - 代码:
.py,.js,.java,.c,.cpp - 配置:
.json,.yaml,.yml,.xml,.ini,.cfg,.conf - 其他:
.html,.htm,.rst,.tex,.log
- 文档:
python
# 代码实现
def add_document_fn(text, file):
if file:
doc_id = knowledge_base.add_file(file.name)
elif text:
doc_id = knowledge_base.add_document(text)
return f"✅ 已添加: {doc_id}"6.2 删除文档
- 功能说明:支持批量删除知识库中的文档
- 使用方式 :
- 在「文档列表」中勾选要删除的文档
- 点击「🗑 删除选中」按钮
- 删除效果:删除文档及其所有文本块,释放存储空间
python
# 代码实现
def delete_selected_docs_fn(selected_labels):
for label in selected_labels:
doc_id = _kb_doc_map.get(label)
knowledge_base.delete_document(doc_id)
return "✅ 已删除"6.3 搜索知识库
- 功能说明:独立的知识库搜索功能,可以测试检索效果
- 使用方式 :
- 在「搜索测试」区域输入查询内容
- 设置返回数量(1-10)
- 点击「搜索」按钮
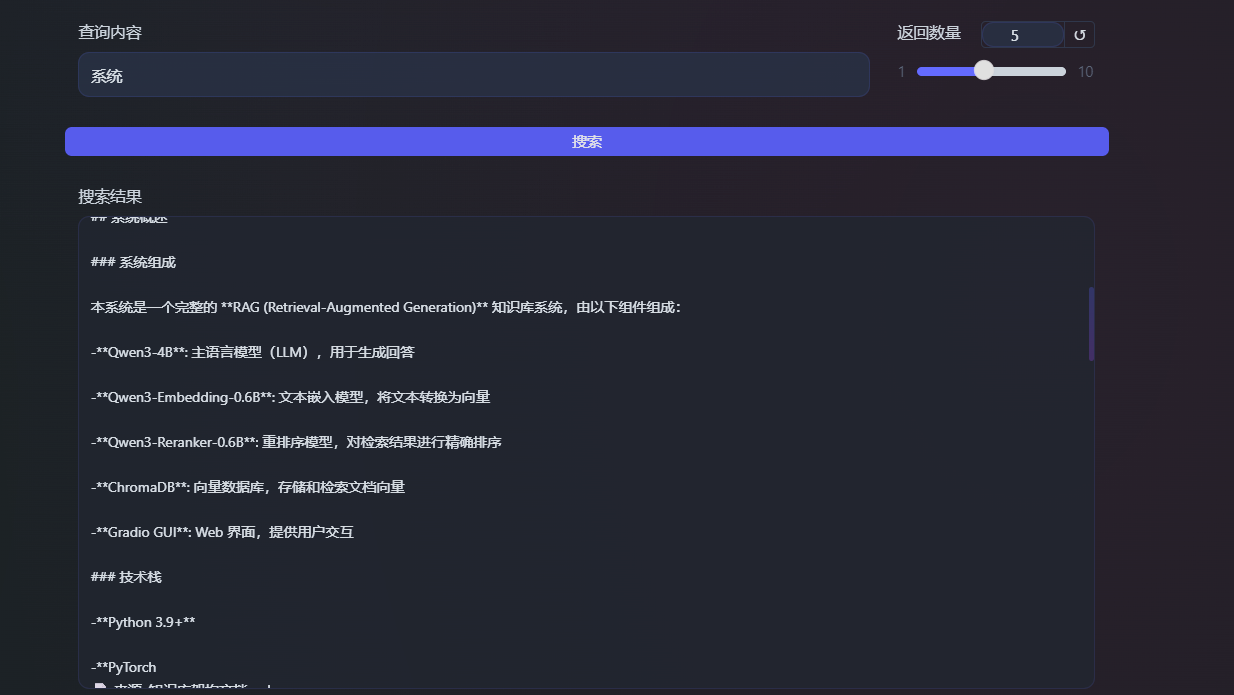
- 显示信息 :
- 相似度分数(Embedding)
- Reranker 分数(如果启用)
- 文档来源
- 完整文本内容
python
# 代码实现
def search_kb_fn(query, top_k):
results = knowledge_base.search(query, top_k=int(top_k))
# 格式化显示结果,包含分数和来源信息
return format_search_results(results)6.4 刷新文档列表
- 功能说明:手动刷新知识库文档列表,查看最新状态
- 使用方式:点击「🔄 刷新列表」按钮
7. 会话管理 💬
- 新对话:创建新的对话会话
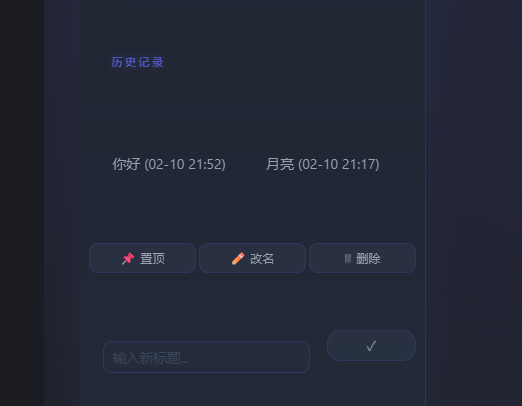
- 历史记录:保存和加载历史对话
- 会话操作 :
- 置顶:将重要会话置顶显示
- 重命名:自定义会话标题
- 删除:删除不需要的会话
- 导入导出 :
- 导出:将所有会话导出为 JSON 文件
- 导入:从 JSON 文件导入会话
8. Prompt 模板 📝
- 预设模板 :
- 📝 论文润色
- 💻 代码解释
- 📊 数据分析
- 🧠 知识讲解
- 使用方式:点击模板按钮,自动填充到输入框
9. 人格模式 🎭
- 功能说明:快速切换不同的 AI 人格和对话风格
- 预设人格:通过按钮快速切换,自动调整系统提示词和生成参数
🎨 功能设计理念
为什么这样设计?
-
节省回答等待时间 ⏱️
- 知识库开关:简单问题不检索,直接回答
- Reranker 开关:快速问题用 Embedding,精确问题用 Reranker
- 终止对话:不满意立即停止,不浪费时间
-
灵活可控 🎛️
- 所有功能都可以自由开关
- 参数可以实时调整
- 不需要重启程序
-
用户友好 👥
- 清晰的界面布局
- 直观的操作方式
- 丰富的状态反馈
系统架构
整体架构图
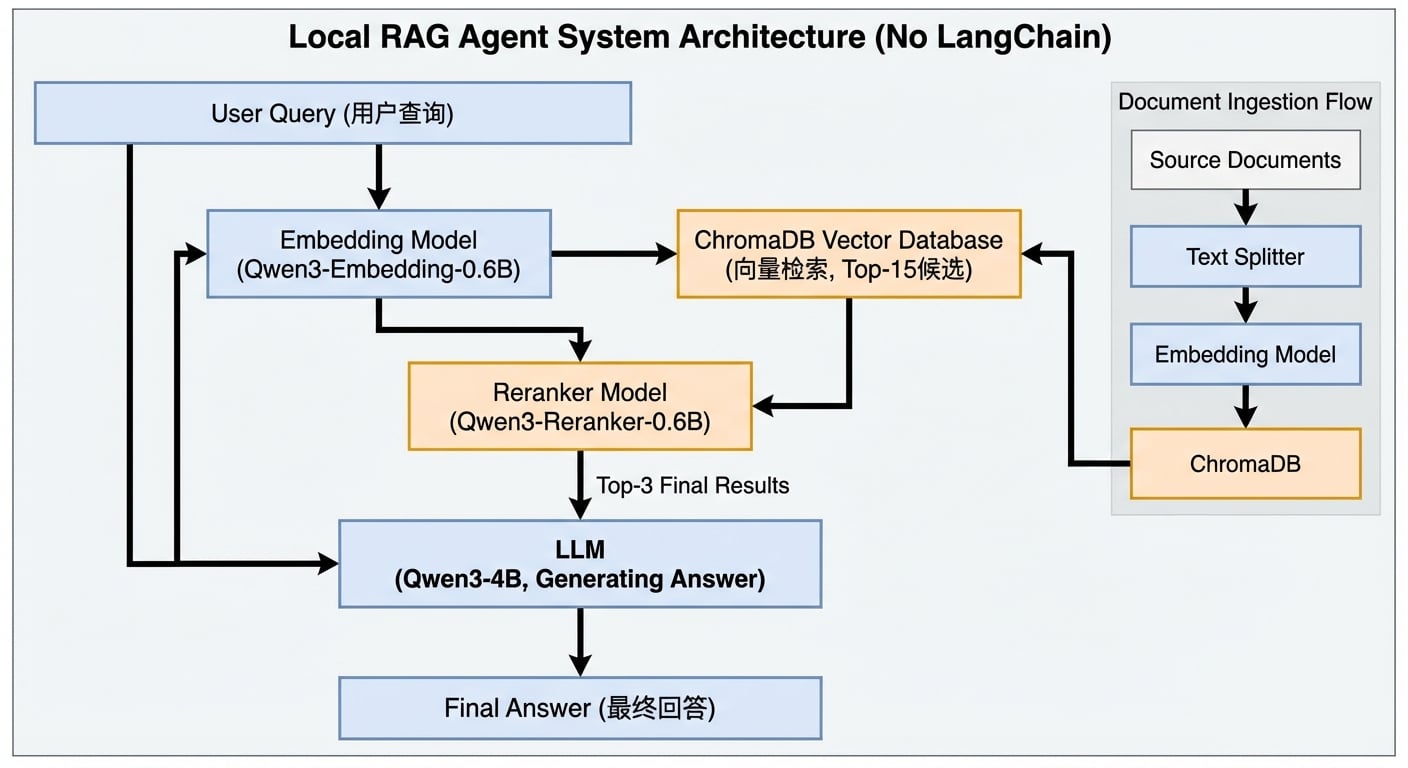
数据流
1.文档入库流程:
文档 → 文本分割 → Embedding 编码 → 向量存储 (ChromaDB)2.查询检索流程:
用户问题 → Embedding 编码 → 向量检索 (top-15)
→ Reranker 重排序 (top-3) → LLM 生成回答技术选型
为什么选择这些技术?
| 组件 | 技术选型 | 理由 |
|------|----------|------|
| LLM | Qwen3-4B | 开源、中文友好、支持思考模式 |
| Embedding | Qwen3-Embedding-0.6B | 专为中文优化、小模型高效 |
| Reranker | Qwen3-Reranker-0.6B | 提升检索精度、与 Embedding 同系列 |
| 向量数据库 | ChromaDB | 轻量级、易部署、支持持久化 |
| 文本分割 | 自实现 | 不依赖 LangChain,完全可控 |
为什么不使用 LangChain?
1.轻量级:减少依赖,降低部署复杂度
2.可控性:完全掌控每个环节的实现细节
3.定制化:可以根据需求灵活调整
4.学习价值:深入理解 RAG 系统的底层原理
核心组件实现
1. Embedding 模型封装
核心功能:将文本转换为向量表示
python
classEmbeddingModel:
"""Embedding 模型封装类"""
def__init__(self, model_name="Qwen/Qwen3-Embedding-0.6B", model_path=None):
# 自动检测本地模型路径
if model_path is None:
# 检查多个可能的路径
possible_paths =[
"~/.cache/modelscope/hub/models/Qwen/Qwen3-Embedding-0___6B",
"./Qwen3-Embedding-0.6B",
]
for path in possible_paths:
if os.path.exists(path):
model_path = path
break
self.model_name = model_path or model_name
self.model = None
self.tokenizer = None
defload(self, device="auto", dtype="auto"):
"""加载模型"""
from transformers import AutoModel, AutoTokenizer
self.tokenizer = AutoTokenizer.from_pretrained(
self.model_name,
trust_remote_code=True,
padding_side="left" # Qwen3-Embedding 要求
)
self.model = AutoModel.from_pretrained(
self.model_name,
torch_dtype=self._get_dtype(dtype, device),
trust_remote_code=True,
)
self.model =self.model.to(self._get_device(device))
self.model.eval()
defencode_query(self, query: str) -> torch.Tensor:
"""编码查询文本(带指令前缀)"""
# Qwen3-Embedding 的查询格式
text =f"Instruct: Given a web search query, retrieve relevant passages that answer the query\nQuery:{query}"
returnself._encode_with_pooling(text)
defencode_documents(self, documents: List[str]) -> torch.Tensor:
"""编码文档列表(无需指令前缀)"""
returnself._encode_with_pooling(documents)
def_encode_with_pooling(self, texts: Union[str, List[str]]) -> torch.Tensor:
"""使用 last token pooling 编码"""
ifisinstance(texts,str):
texts =[texts]
# 分词
encoded =self.tokenizer(
texts,
padding=True,
truncation=True,
max_length=8192,
return_tensors="pt"
).to(self.model.device)
# 前向传播
with torch.no_grad():
outputs =self.model(**encoded)
# Last token pooling(Qwen3-Embedding 官方推荐)
embeddings =self._last_token_pool(
outputs.last_hidden_state,
encoded["attention_mask"]
)
# L2 归一化
embeddings = F.normalize(embeddings,p=2,dim=1)
return embeddings
@staticmethod
def_last_token_pool(last_hidden_states, attention_mask):
"""Last token pooling 实现"""
left_padding =(attention_mask[:,-1].sum()== attention_mask.shape[0])
if left_padding:
return last_hidden_states[:,-1]
else:
sequence_lengths = attention_mask.sum(dim=1)-1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[
torch.arange(batch_size,device=last_hidden_states.device),
sequence_lengths
]关键点:
- 使用
last token pooling而非mean pooling(Qwen3-Embedding 官方推荐) - 查询和文档使用不同的格式(查询带指令前缀)
- 支持批量编码,提高效率
2. Reranker 模型封装
核心功能:对检索结果进行语义相关性重排序
python
classRerankerModel:
"""Reranker 模型封装类"""
def__init__(self, model_name="Qwen/Qwen3-Reranker-0.6B", model_path=None):
# 类似 Embedding 的路径检测逻辑
self.model_name = model_path or model_name
self.model = None
self.tokenizer = None
self.token_true_id = None
self.token_false_id = None
defload(self, device="auto", dtype="auto"):
"""加载模型(注意:使用 CausalLM 而非 SequenceClassification)"""
from transformers import AutoModelForCausalLM, AutoTokenizer
self.tokenizer = AutoTokenizer.from_pretrained(
self.model_name,
trust_remote_code=True,
padding_side="left"
)
# Qwen3-Reranker 使用 CausalLM 架构
self.model = AutoModelForCausalLM.from_pretrained(
self.model_name,
torch_dtype=self._get_dtype(dtype, device),
trust_remote_code=True,
)
self.model =self.model.to(self._get_device(device))
self.model.eval()
# 预计算 yes/no token id
self.token_true_id =self.tokenizer.convert_tokens_to_ids("yes")
self.token_false_id =self.tokenizer.convert_tokens_to_ids("no")
defrerank(self, query: str, documents: List[str], top_k: int= None) -> List[Dict]:
"""重排序文档"""
# 格式化 query-document 对
pairs =[
f"<Instruct>: Given a web search query, retrieve relevant passages that answer the query\n"
f"<Query>: {query}\n<Document>: {doc}"
for doc in documents
]
# 添加系统提示词
prefix ='<|im_start|>system\nJudge whether the Document meets the requirements based on the Query and the Instruct provided. Note that the answer can only be "yes" or "no".<|im_end|>\n<|im_start|>user\n'
suffix ="<|im_end|>\n<|im_start|>assistant\n<think>\n\n</think>\n\n"
# 批量处理
all_scores =[]
batch_size =16
for i inrange(0,len(pairs), batch_size):
batch = pairs[i:i + batch_size]
inputs =self._process_batch(batch, prefix, suffix)
scores =self._compute_scores(inputs)
all_scores.extend(scores)
# 排序并返回 top_k
results =[
{"text": doc,"score": score}
for doc, score inzip(documents, all_scores)
]
results.sort(key=lambdax: x["score"],reverse=True)
return results[:top_k]if top_k else results
def_compute_scores(self, inputs) -> List[float]:
"""计算 yes/no logits 分数"""
with torch.no_grad():
logits =self.model(**inputs).logits[:,-1, :]
true_logit = logits[:,self.token_true_id]
false_logit = logits[:,self.token_false_id]
# 计算概率
scores = torch.softmax(
torch.stack([false_logit, true_logit],dim=1),
dim=1
)[:,1].tolist()
return scores关键点:
- Qwen3-Reranker 使用
CausalLM架构,通过 yes/no token 的 logits 计算相关性分数 - 需要特定的 prompt 格式(包含系统提示词和特殊后缀)
- 批量处理提高效率
3. 文本分割器(不依赖 LangChain)
核心功能:将长文档分割成适合向量化的文本块
python
classSimpleTextSplitter:
"""简单的文本分割器(不依赖 LangChain)"""
def__init__(self, chunk_size: int=500, chunk_overlap: int=50):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
# 中文友好的分隔符优先级
self.separators =["\n\n","\n","。","!","?",";",","," ",""]
defsplit_text(self, text: str) -> List[str]:
"""分割文本"""
iflen(text)<=self.chunk_size:
return[text]
chunks =[]
start =0
while start <len(text):
# 尝试在分隔符处分割
end = start +self.chunk_size
chunk = text[start:end]
# 如果还有剩余文本,尝试在最后一个分隔符处分割
if end <len(text):
for sep inself.separators:
if sep and sep in chunk:
last_sep_pos = chunk.rfind(sep)
if last_sep_pos >self.chunk_size *0.5: # 至少保留一半内容
chunk = chunk[:last_sep_pos +len(sep)]
end = start +len(chunk)
break
chunks.append(chunk.strip())
# 重叠处理
start = end -self.chunk_overlap
return[chunk for chunk in chunks if chunk]关键点:
- 支持重叠分割,避免上下文丢失
- 中文友好的分隔符优先级
- 简单高效,无外部依赖
4. 知识库核心类
核心功能:整合 Embedding、Reranker、ChromaDB,提供完整的知识库功能
python
classKnowledgeBase:
"""知识库核心类"""
def__init__(
self,
db_path: str="./knowledge_db",
embedding_model_path: str= None,
reranker_model_path: str= None,
chunk_size: int=500,
chunk_overlap: int=50,
use_reranker: bool= True
):
# 初始化组件
self.embedding_model =EmbeddingModel(model_path=embedding_model_path)
self.reranker_model =RerankerModel(model_path=reranker_model_path)if use_reranker else None
self.text_splitter =SimpleTextSplitter(chunk_size, chunk_overlap)
# 初始化 ChromaDB
import chromadb
from chromadb.config import Settings
self.client = chromadb.PersistentClient(
path=str(Path(db_path)/"chroma_db"),
settings=Settings(anonymized_telemetry=False)
)
# 创建或获取集合(使用余弦相似度)
self.collection =self.client.get_or_create_collection(
name="knowledge_base",
metadata={"hnsw:space": "cosine"}
)
defadd_document(self, text: str, doc_id: str= None, metadata: dict= None) -> str:
"""添加文档到知识库"""
# 1. 文本分割
chunks =self.text_splitter.split_text(text)
# 2. Embedding 编码
embeddings =self.embedding_model.encode_documents(chunks)
embeddings_list = embeddings.numpy().tolist()
# 3. 准备元数据
if doc_id is None:
import uuid
doc_id =str(uuid.uuid4())
ids =[f"{doc_id}_chunk_{i}"for i inrange(len(chunks))]
metadatas =[
{
"doc_id": doc_id,
"chunk_index": i,
"text_preview": chunk[:200],
**(metadata or {})
}
for i, chunk inenumerate(chunks)
]
# 4. 存储到 ChromaDB
self.collection.add(
ids=ids,
embeddings=embeddings_list,
documents=chunks,
metadatas=metadatas
)
return doc_id
defsearch(
self,
query: str,
top_k: int=5,
use_reranker: bool= None
) -> List[Dict]:
"""搜索相关文档(两阶段检索)"""
# 阶段1: Embedding 检索
query_embedding =self.embedding_model.encode_query(query)
query_embedding_list = query_embedding.numpy().tolist()
# 如果使用 Reranker,检索更多候选(通常 2-3 倍)
retrieval_k = top_k *3if(use_reranker orself.use_reranker)else top_k
results =self.collection.query(
query_embeddings=[query_embedding_list],
n_results=retrieval_k
)
# 格式化结果
candidates =[]
if results["documents"]andlen(results["documents"][0])>0:
for doc, metadata, distance inzip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0]
):
candidates.append({
"text": doc,
"score": 1- distance, # 余弦距离转相似度
"metadata": metadata or {}
})
# 阶段2: Reranker 重排序(如果启用)
if(use_reranker orself.use_reranker)andself.reranker_model:
reranked =self.reranker_model.rerank_with_metadata(
query=query,
candidates=candidates,
top_k=top_k
)
return reranked
# 不使用 Reranker,直接返回前 top_k
returnsorted(candidates,key=lambdax: x["score"],reverse=True)[:top_k]关键点:
- 两阶段检索:Embedding 召回 + Reranker 精排
- 自动管理模型加载和卸载
- 支持元数据存储和检索
两阶段检索策略
为什么需要两阶段检索?
1.Embedding 检索:快速召回大量候选(速度快,但精度有限)
2.Reranker 重排序:精确排序少量候选(速度慢,但精度高)
实现策略
python
# 阶段1: Embedding 检索(召回 top-15)
retrieval_k = top_k *3 # 检索更多候选
embedding_results = chromadb.query(n_results=retrieval_k)
# 阶段2: Reranker 重排序(精排 top-3)
if use_reranker:
final_results = reranker.rerank(
query=query,
candidates=embedding_results,
top_k=top_k # 最终返回 top-3
)
else:
final_results = embedding_results[:top_k]优势:
- 兼顾速度和精度
- Embedding 快速召回,Reranker 精确排序
- 可灵活开关 Reranker
完整代码实现
项目结构
project/
├── embedding_model.py # Embedding 模型封装
├── reranker_model.py # Reranker 模型封装
├── knowledge_base.py # 知识库核心类
├── qwen_chat.py # LLM 封装
├── gui_chat.py # Gradio 界面(可选)
└── requirements.txt # 依赖列表依赖安装
bash
# 核心依赖
pipinstalltorchtransformerschromadbsentencepiece
# 可选依赖(文件解析)
pipinstallpdfplumberpython-docxopenpyxlbeautifulsoup4pandas使用示例
python
from knowledge_base import KnowledgeBase
from qwen_chat import QwenChatModel
# 1. 初始化知识库
kb =KnowledgeBase(
db_path="./knowledge_db",
use_reranker=True
)
# 2. 加载模型
kb.load_embedding_model(device="cpu",dtype="float32")
kb.load_reranker_model(device="cpu",dtype="float32")
# 3. 添加文档
doc_id = kb.add_document(
text="人工智能是计算机科学的一个分支,致力于创建能够执行通常需要人类智能的任务的系统。",
metadata={"source": "wikipedia","topic": "AI"}
)
# 4. 搜索
results = kb.search(
query="什么是人工智能?",
top_k=3,
use_reranker=True
)
# 5. 集成 LLM 生成回答
llm =QwenChatModel()
llm.load()
context ="\n".join([r["text"]for r in results])
prompt =f"""基于以下上下文回答问题:
{context}
问题:{query}
回答:"""
answer = llm.chat(prompt)
print(answer)部署与使用
1. 模型下载
bash
# 使用 ModelScope(国内加速)
pipinstallmodelscope
# 下载 Embedding 模型
python-c"from modelscope import snapshot_download; snapshot_download('Qwen/Qwen3-Embedding-0.6B', cache_dir='./models')"
# 下载 Reranker 模型
python-c"from modelscope import snapshot_download; snapshot_download('Qwen/Qwen3-Reranker-0.6B', cache_dir='./models')"
# 下载 LLM 模型
python-c"from modelscope import snapshot_download; snapshot_download('Qwen/Qwen3-4B', cache_dir='./models')"2. 环境配置
bash
# 创建 conda 环境
condacreate-nagentpython=3.9
condaactivateagent
# 安装依赖
pipinstall-rrequirements.txt3. 启动服务
python
# gui_chat.py
import gradio as gr
from knowledge_base import KnowledgeBase
from qwen_chat import QwenChatModel
kb =KnowledgeBase()
llm =QwenChatModel()
defchat_fn(message, history, use_kb):
if use_kb:
# 检索相关知识
results = kb.search(message,top_k=3)
context ="\n".join([r["text"]for r in results])
prompt =f"基于以下上下文回答问题:\n\n{context}\n\n问题:{message}\n回答:"
else:
prompt = message
# 生成回答
response = llm.chat(prompt)
return response
demo = gr.ChatInterface(
fn=chat_fn,
title="本地智能体系统",
description="基于 Qwen3-4B + Embedding + Reranker + ChromaDB"
)
demo.launch(server_name="0.0.0.0",server_port=7860)系统界面
界面布局
系统采用 Gradio 框架构建 Web 界面,采用现代化的暗色主题设计,整体布局分为左右两栏:
┌─────────────────────────────────────────────────────────┐
│ 状态栏(GPU/显存信息) │
├──────────────┬──────────────────────────────────────────┤
│ │ │
│ 左侧边栏 │ 右侧聊天区 │
│ │ │
│ - Logo │ - 聊天对话框 │
│ - 新对话 │ - 人格模式选择 │
│ - 历史记录 │ - Prompt 模板 │
│ - 工具 │ - 输入框 │
│ - 模型加载 │ - 功能开关(思考/知识库/广度搜索) │
│ - 知识库加载 │ - 参数设置(可折叠) │
│ │ - 知识库管理(可折叠) │
│ │ │
└──────────────┴──────────────────────────────────────────┘界面截图
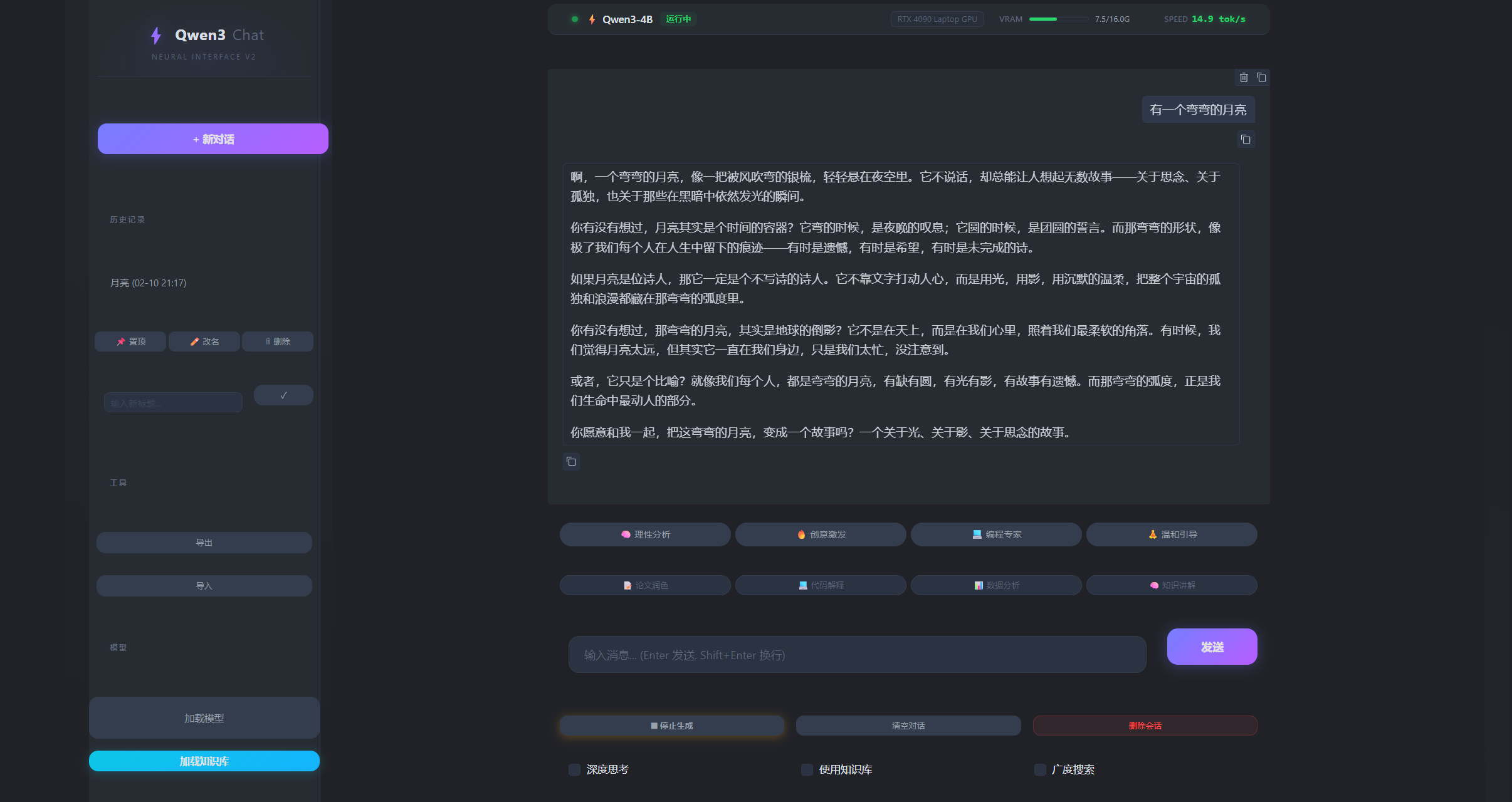
- 主界面全貌
- 知识库管理界面
- 参数设置面板
- 历史记录管理
- 知识库搜索结果显示
主要界面元素
1. 左侧边栏
- Logo 区域:显示 "Qwen3 Chat" 标识
- 新对话按钮:快速创建新会话
- 历史记录列表 :显示所有保存的对话会话
- 支持置顶、重命名、删除操作
- 点击可加载历史对话
- 工具区域 :
- 导出:导出所有会话为 JSON
- 导入:从 JSON 文件导入会话
- 模型区域 :
- 加载模型按钮:加载 Qwen3-4B 模型
- 加载知识库按钮:初始化知识库系统
- 知识库状态显示:显示文档数和块数
2. 右侧聊天区
- 状态栏:显示模型状态、GPU 信息、显存使用情况
- 聊天对话框 :
- 支持 Markdown 渲染
- 支持 LaTeX 数学公式
- 支持代码高亮
- 支持复制功能
- 人格模式选择:快速切换 AI 人格
- Prompt 模板:常用模板快速填充
- 输入框 :
- 支持多行输入
- Enter 发送,Shift+Enter 换行
- 自动聚焦
- 功能开关行 :
- ⏹ 停止生成:中断当前生成
- 清空对话:清空当前会话
- 删除会话:删除当前会话
- 深度思考:启用思考模式
- 使用知识库:启用知识库检索
- 广度搜索:启用 Reranker 重排序
- 参数设置(可折叠) :
- 系统提示词输入框
- Temperature 滑块
- Max Tokens 滑块
- Top-p 滑块
- Top-k 滑块
- 预设模式按钮(创意/均衡/精确)
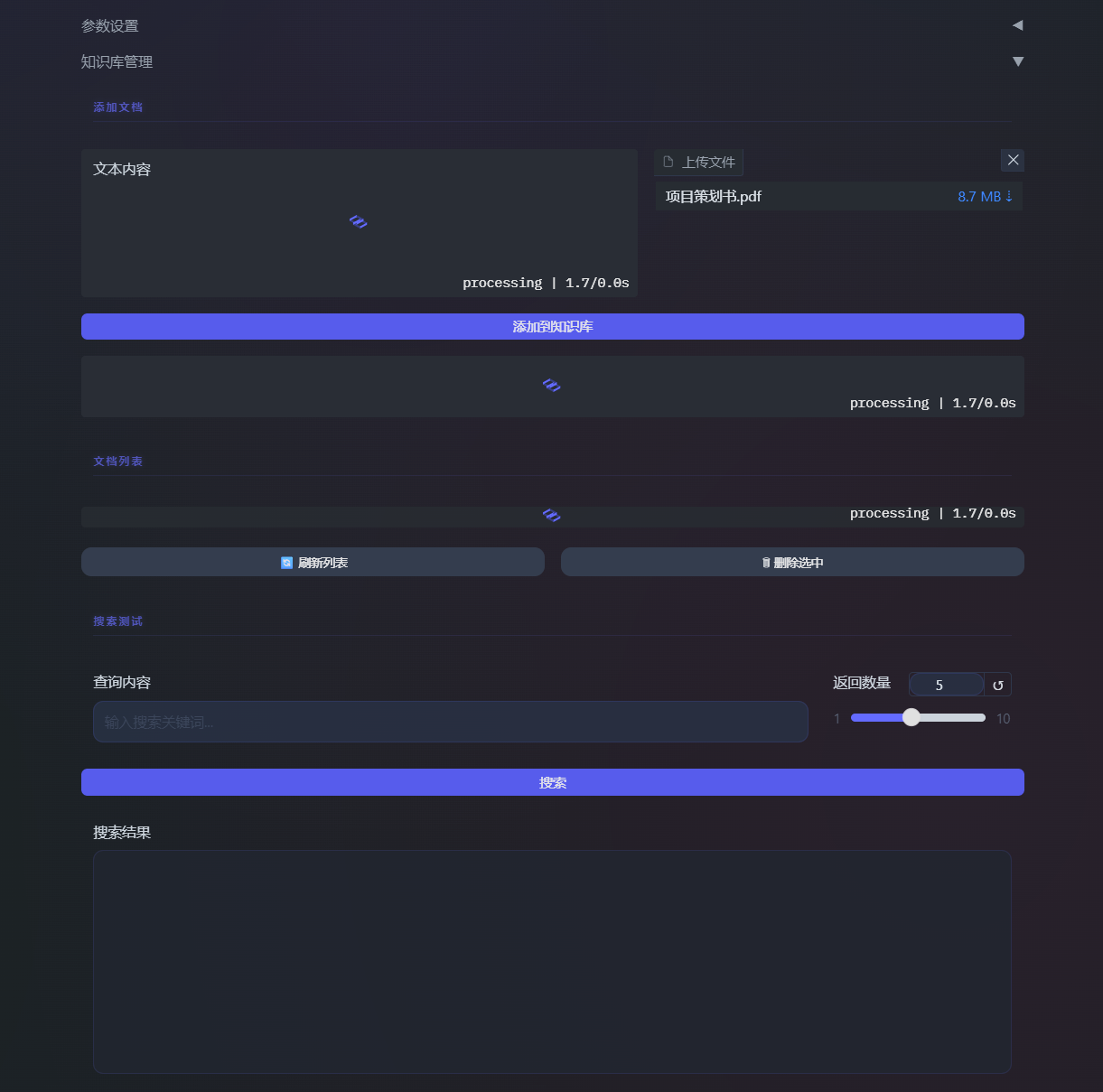
- 知识库管理(可折叠) :
- 添加文档 :
- 文本输入框
- 文件上传按钮
- 添加到知识库按钮
- 文档列表 :
- 复选框列表(显示所有文档)
- 刷新列表按钮
- 删除选中按钮
- 搜索测试 :
- 查询输入框
- 返回数量滑块
- 搜索按钮
- 结果显示区域
- 添加文档 :
界面特色
-
现代化设计:
- 深色主题,护眼舒适
- 霓虹边框效果
- 流畅的动画过渡
- 响应式布局
-
信息丰富:
- 实时显示 GPU 状态
- 显存使用情况
- 生成速度统计
- 知识库统计信息
-
操作便捷:
- 快捷键支持(Enter 发送)
- 一键操作(模板、人格模式)
- 折叠面板(节省空间)
- 状态反馈(成功/失败提示)
界面交互流程
典型使用流程
-
首次使用:
启动程序 → 点击「加载模型」→ 等待加载完成 → 点击「加载知识库」→ 添加文档 → 开始对话 -
日常使用:
选择历史会话或创建新对话 → 勾选「使用知识库」(如需要) → 勾选「广度搜索」(如需高精度) → 输入问题 → 查看回答 -
知识库管理:
展开「知识库管理」面板 → 添加文档(文本或文件) → 查看文档列表 → 测试搜索功能 → 删除不需要的文档
性能优化
1. 显存管理
python
# 策略1: Embedding/Reranker 使用 CPU,LLM 使用 GPU
kb.load_embedding_model(device="cpu",dtype="float32")
kb.load_reranker_model(device="cpu",dtype="float32")
llm.load(device_map="cuda:0",torch_dtype=torch.float16)
# 策略2: 按需加载模型
ifnot kb.embedding_model_loaded:
kb.load_embedding_model()
# 使用完后卸载
kb.unload_embedding_model()2. 批量处理
python
# 批量编码文档
embeddings = embedding_model.encode_documents(chunks,batch_size=32)
# 批量重排序
reranked = reranker_model.rerank(query, documents,batch_size=16)3. 缓存机制
python
# 缓存查询向量
@lru_cache(maxsize=100)
defcached_encode_query(query: str):
return embedding_model.encode_query(query)总结
核心优势
1.完全自主可控:不依赖 LangChain,每个环节都可定制
2.轻量级部署:最小化依赖,易于部署和维护
3.高性能检索:两阶段检索策略,兼顾速度和精度
4.中文友好:使用 Qwen 系列模型,中文效果优秀
适用场景
- ✅ 企业内部知识库
- ✅ 文档问答系统
- ✅ 智能客服
- ✅ 个人知识管理
- ✅ 研究和学习 RAG 原理
技术亮点
-Last Token Pooling:Qwen3-Embedding 官方推荐的池化方式
-Yes/No Logits:Qwen3-Reranker 的独特评分机制
-两阶段检索:Embedding 召回 + Reranker 精排
-自实现文本分割:不依赖 LangChain,完全可控
未来扩展
- 支持更多文档格式
- 支持多轮对话上下文检索
- 支持增量更新和增量索引
- 支持混合检索(关键词 + 向量)
参考资源
作者:Brain-coder
日期:2026-02-10
版本:1.0
💡 提示:本文档提供了一个简易智能体的完整的实现思路和代码示例,读者可以根据自己的需求进行调整和优化。如有问题,欢迎交流讨论。