一、核心概念:哈希表与哈希冲突
1. 哈希表(Hash Table)基础
哈希表是一种以空间换时间的数据结构,核心是通过「哈希函数」将键(Key)映射到数组的指定索引位置,实现平均 O(1) 时间复杂度的增删查改。
(1)核心公式:索引 = 哈希函数(Key) % 数组长度
(2)理想状态:每个 Key 都能通过哈希函数映射到唯一索引,无冲突、存取效率极高。
2. 哈希冲突(Hash Collision)
定义
当不同的 Key 通过哈希函数计算后,得到了相同的索引位置,就称为哈希冲突(哈希碰撞)。
(1)例:Key1="张三",哈希值 = 10;Key2="李四",哈希值 = 10;数组长度 = 8 → 索引 = 10%8=2,两者映射到同一索引,产生冲突。
(2)注意:哈希冲突无法完全避免(因为 Key 的范围远大于数组长度,根据鸽巢原理,必然存在冲突),只能 "避免" 或 "解决。
二、避免哈希冲突(重点:哈希函数设计 + 负载因子调节)
避免冲突的核心是让哈希值尽可能均匀分布,减少冲突概率,主要靠 2 个手段:
1. 哈希函数设计(核心)
哈希函数的目标:相同 Key 必须返回相同哈希值,不同 Key 尽可能返回不同哈希值。
常用设计原则 / 方法(满足 "均匀性")
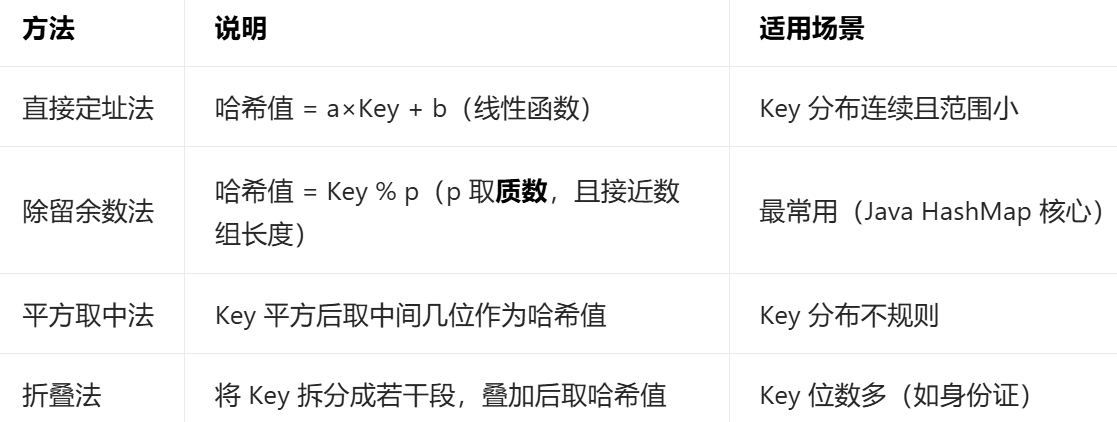
关键优化(Java 中的实践)
Java 的 Object.hashCode() 是基础,但 HashMap 对其做了二次哈希(扰动函数),进一步打散哈希值:
java
// HashMap 中的哈希函数(JDK8)
static final int hash(Object key) {
int h;
// 1. 取key的hashCode;2. 高16位与低16位异或,打散哈希值
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}作用:减少 "高位不同、低位相同" 的 Key 产生冲突的概率(比如 Key1=0x12345678,Key2=0x98765678,低位相同,异或后哈希值差异更大)。
2. 负载因子调节(重点掌握)
定义
负载因子(Load Factor)= 哈希表中元素个数 / 数组长度。
例:数组长度 = 16,元素个数 = 8 → 负载因子 = 0.5。
核心作用
负载因子决定了哈希表的 "拥挤程度",是平衡「空间」和「冲突概率」的关键:
(1)负载因子过高 (如 1.0):数组满了才扩容,空间利用率高,但冲突概率剧增,存取效率退化为 O(n);
(2)负载因子过低 (如 0.2):冲突概率低,但数组空闲空间多,空间浪费严重。
Java HashMap 的实现(重点)
(1)默认负载因子:0.75(经过工程验证的最优值,平衡空间和冲突);
(2)扩容触发条件:元素个数 > 数组长度 × 负载因子 → 数组扩容为原来的 2 倍(必须是 2 的幂,配合位运算快速计算索引);
(3)例:数组长度 = 16,负载因子 = 0.75 → 元素个数≥12 时,扩容为 32。
三、解决哈希冲突(重点:开散列 / 哈希桶)
当冲突不可避免时,需要通过特定策略解决,主流有 2 种方式:
1. 闭散列(开放定址法)
定义
冲突发生时,在数组中寻找下一个空闲位置存放冲突元素,核心是 "在同一个数组里找位置"。
常用方法
(1)线性探测 :冲突后,依次往后找空闲位置(索引 + 1、+2...);
缺点:易产生 "聚集效应"(连续位置被占,后续冲突概率更高);
(2)二次探测 :冲突后,按索引 ±1²、±2²... 找空闲位置;
优点:缓解聚集效应;缺点:仍可能局部聚集;
(3)伪随机探测 :冲突后,按随机数序列找空闲位置。
缺点
数组满了无法扩容(或扩容成本高);
删除元素时需标记 "已删除",否则会破坏探测链;
冲突严重时,探测效率急剧下降。
2. 开散列(链地址法 / 哈希桶,重点掌握)
定义
数组的每个索引位置(称为 "桶")对应一个链表 / 红黑树 ,冲突的元素直接挂在同一个桶的链表 / 红黑树下,核心是 "数组 + 链表 / 红黑树"。
实现逻辑(以 Java HashMap为例)
- 数组初始长度为16,每个桶默认是null;
- Key计算哈希值后,通过(数组长度-1)&哈希值得到索引(替代取模,效率更高);
- 若索引位置为空,直接创建节点放入;
- 若索引位置已有节点(冲突),将新节点挂在链表尾部;
- 当链表长度≥8且数组长度≥64时,链表转为红黑树(降低查询复杂度至O(logn));
- 当红黑树节点数≤6时,转回链表(节省空间)。
优势(为何成为主流)
●冲突处理简单,无聚集效应;
•扩容成本低(仅需迁移部分桶);
•删除元素无需标记,直接从链表/红黑树删除即可;
●Java、Python、C++等主流语言的哈希表均采用此方式。
图解:
java
数组索引:0 1 2 3 ...
[ ] [节点A] [节点B→节点C→节点D] [ ]节点 B、C、D 哈希冲突,都映射到索引 2,挂在同一个链表下。
四、冲突严重时的解决办法
当哈希表冲突率过高(如负载因子超标、哈希函数设计差),需针对性解决:
- 优化哈希函数:重新设计哈希函数,让哈希值分布更均匀(如Java的扰动函数);
- 提高扩容频率:降低负载因子(如从0.75改为0.5),提前扩容,减少冲突;
- 调整数组长度:数组长度取质数(除留余数法)或2的幂(位运算高效),避免哈希值分布不均;
- 链表转红黑树:如Java HashMap,链表长度≥8 时转红黑树,将查询效率从O(n)降为O(logn);
- 分片哈希:将大哈希表拆分为多个小哈希表,分散冲突压力。
五、哈希表实现性能分析
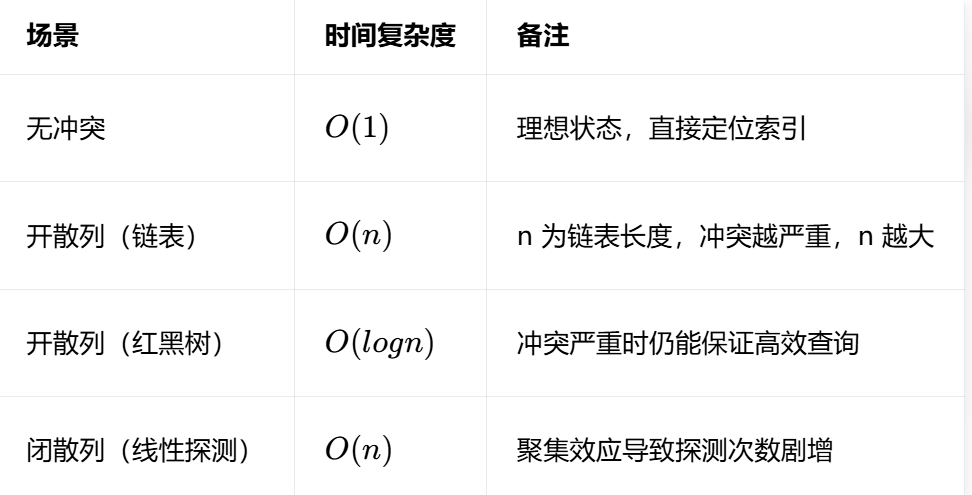
性能关键影响因素
- 哈希函数均匀性:越均匀,冲突越少,性能越好;
- 负载因子:0.75是工程最优值,过高/过低都会影响性能;
- 冲突解决方式:开散列(红黑树)>开散列(链表)>闭散列;
- 数组扩容策略:2倍扩容+2的幂长度,兼顾效率和均匀性。
六、与 Java 类集的关系
- HashMap 和 HashSet 即 java 中利用哈希表实现的 Map 和 Set
- java 中使用的是哈希桶方式解决冲突的
- java 会在冲突链表长度大于一定阈值后,将链表转变为搜索树(红黑树)
- java 中计算哈希值实际上是调用的类的 hashCode 方法,进行 key 的相等性比较是调用 key 的 equals 方法。所以如果要用自定义类作为 HashMap 的 key 或者 HashSet 的值,必须覆写 hashCode 和 equals 方法,而且要做到 equals 相等的对象,hashCode 一定是一致的。
