我是@iFeng的小屋,一枚4年程序猿。
一、爬取目标
我又写了这个B站评论区通用爬虫 。它适配了所有的视频链接 ,优化了滚动加载逻辑,稳定性更强,一样能把主评论和底下所有二级回复都完整抓下来,打包成Excel。
哔哩哔哩(Bilibili,简称B站) 是中国知名的视频社区平台。目前是源码格式,还没有封装成软件,如果想要软件的我后续开发一个软件版本的。
二、展示爬取结果
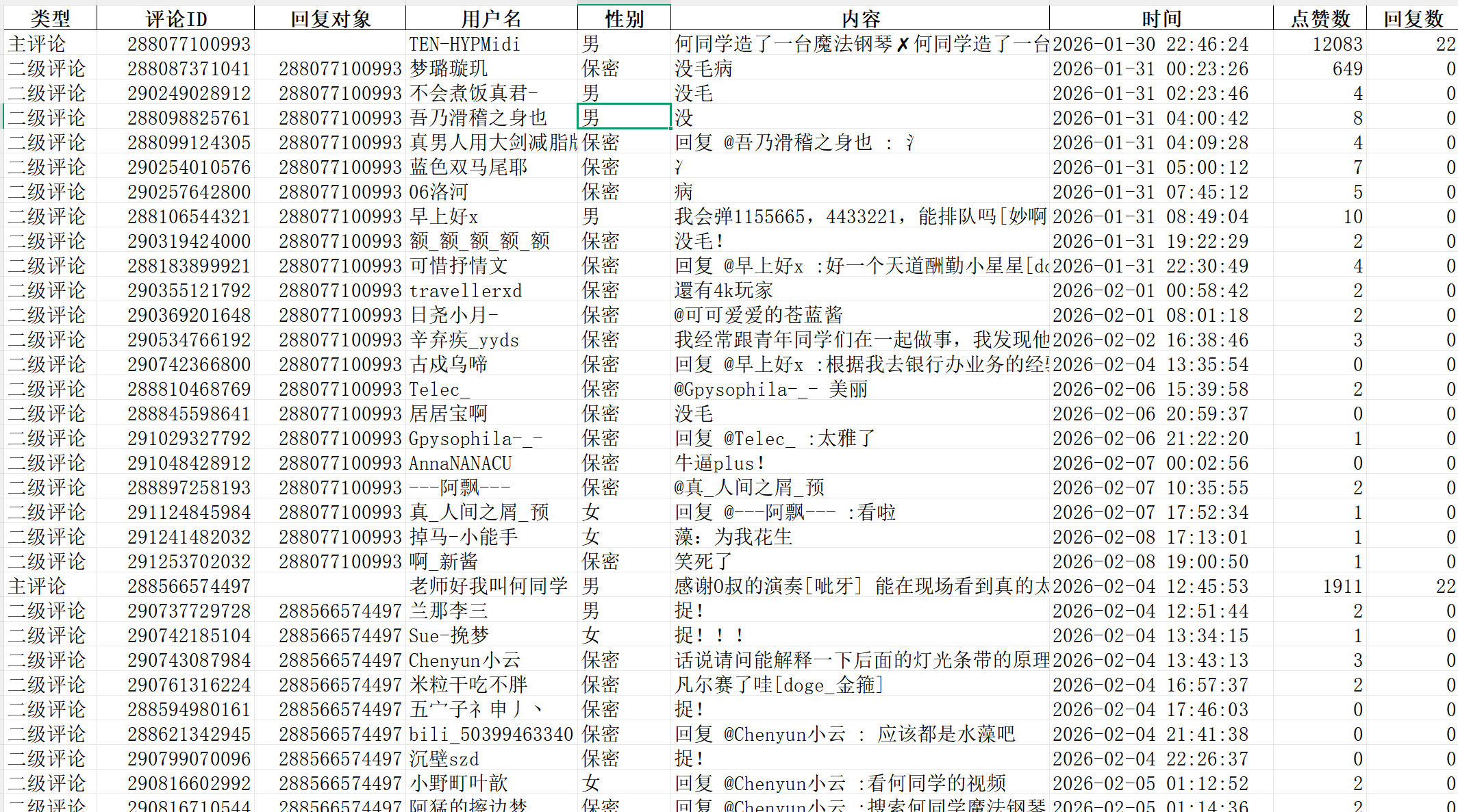
字段:类型,评论ID,回复对象,用户名,性别,内容(一二级),时间,点赞数,回复数。
三、爬虫代码讲解
导入库:
python
from DrissionPage import ChromiumPage
import requests
import pandas as pd
import time
from datetime import datetime3.1 核心思路与配置
目标更换为普通视频,并加入初始化滚动,提升稳定性。
python
driver_dp.get('https://www.bilibili.com/video/BV1h56BBZEVq/...') # 普通视频链接
time.sleep(5)
driver_dp.scroll.down(400) # 优化点:先向下滚动400像素,触发加载
time.sleep(3)3.2核心函数拆解:模拟滚动与监听
python
def scroll_to_bottom():
print("开始滚动页面加载更多评论...")
last_height = driver_dp.run_js('return document.body.scrollHeight;')
scroll_attempts = 0
while scroll_attempts < 3: # 允许尝试3次
# 1. 滚动到底部
driver_dp.scroll.to_bottom()
time.sleep(3) # 必须等待,给网络和渲染留时间
# 2. 计算新高度,判断内容是否真的增加了
new_height = driver_dp.run_js('return document.body.scrollHeight;')
if new_height == last_height: # 高度没变,可能到底了
scroll_attempts += 1
print("可能已无新内容。")
else: # 高度增加,说明加载了新内容
last_height = new_height
scroll_attempts = 0 # 重置尝试计数
print("加载了新内容,继续滚动...")
# 3. 尝试捕获新加载出的评论数据包
try:
res = driver_dp.listen.wait(timeout=5)
if res:
all_responses.append(res) # 存入列表,后续统一处理
print(f"截获到第 {len(all_responses)} 批数据")
except:
print("本次滚动未发现新数据接口。")代码解读:
-
这个函数实现了自动翻页。通过反复滚动到底部,触发B站的"懒加载"机制。
-
driver_dp.run_js()让我们能在Python里执行JavaScript代码,用来获取页面高度。 -
driver_dp.listen.wait()是阻塞等待,直到监听到目标请求发生,或者超时。 -
整个逻辑是:滚动 -> 等待加载 -> 尝试捕获数据 -> 判断是否继续。
3.3 核心函数拆解:深度抓取二级回复
python
def get_secondary_comments(root_rpid, total_count):
"""根据主评论ID,抓取其下所有二级回复"""
comments_per_page = 10
# 计算需要抓多少页(B站接口每页最多返回'comments_per_page'条)
total_pages = (total_count + comments_per_page - 1) // comments_per_page
all_replies = []
for current_page in range(1, total_pages + 1):
# 构造请求URL,核心是 root(主评ID)和 pn(页码)
url = f'https://api.bilibili.com/x/v2/reply/reply?oid=115983628897173&type=1&root={root_rpid}&ps={comments_per_page}&pn={current_page}'
resp = requests.get(url, headers=headers).json()
if resp['code'] == 0: # 接口返回成功
replies = resp['data']['replies']
if replies:
all_replies.extend(replies) # 合并到总列表
print(f" 已获取第 {current_page}/{total_pages} 页回复")
time.sleep(0.5) # 礼貌间隔,避免请求过快被封
return all_replies代码解读:
-
这是突破页面显示限制,获取完整回复链的关键。
-
主评论的
count字段只告诉你回复总数,页面上通常只展示几条。此函数直接调用B站分页接口,通过循环请求获取全部。 -
root={root_rpid}指明了我们要的是哪条主评论下的回复。
3.4 数据处理与存储的精细操作
python
# 1. 构建DataFrame
df = pd.DataFrame(all_comments)
# 2. 指定并调整列顺序,让表格更美观
columns = ['类型', '评论ID', '回复对象', '用户名', '性别', '内容', '时间', '点赞数', '回复数']
df = df[columns]
# 3. 关键步骤:确保ID列为字符串,防止大整数被科学计数法或精度丢失
df['评论ID'] = df['评论ID'].astype(str)
df['回复对象'] = df['回复对象'].astype(str)
# 4. 使用ExcelWriter进行高级保存
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f'B站评论数据_{timestamp}.xlsx'
with pd.ExcelWriter(filename, engine='openpyxl') as writer:
df.to_excel(writer, index=False, sheet_name='评论数据')
# 获取工作表对象,进行格式微调
worksheet = writer.sheets['评论数据']
# 将B列(评论ID)和C列(回复对象)的单元格格式强制设为"文本"
# '@'在Excel格式代码中代表文本格式
for cell in worksheet['B']:
cell.number_format = '@'
for cell in worksheet['C']:
cell.number_format = '@'
print(f"数据已安全保存至: {filename}")四、如何运行?
-
安装依赖 :
pip install DrissionPage pandas requests openpyxl -
获取Cookie :登录B站网页版,F12打开开发者工具,在Network里任意找一个请求,复制其
Request Headers中的cookie值。 -
修改目标链接 :将
driver_dp.get()里的URL换成你的目标视频链接。 -
执行脚本 :运行程序,**弹出谷歌浏览器后先在网页上登陆B站账号才能正常爬取!**等待浏览器打开并完成自动滚动抓取。结果将保存在当前目录下的时间戳Excel文件中。
五、说明
需要本文完整可运行源码文件 ,源代码文件我放在同名的公主号里了,有需要的自取。
或对其中任何技术细节有疑问,欢迎在评论区交流。
持续分享Python干货中!更多爬虫源码干货,请前往主页查看~