注:本文会讲述堆与栈(非数据结构概念)在存储空间的作用,并会分析在裸机与RTOS中的例子来介绍和区分
(1).基本概念
一、 栈 (Stack):为了"办事"而存在的临时工位
1. 定义 栈是一块连续的 、自动管理的内存区域。
-
特点 :它的操作非常快(仅次于 CPU 寄存器),遵循 "后进先出" (LIFO) 原则。
-
生命周期 :自动生灭。函数调用时自动分配,函数返回时自动释放。你不需要操心。
2. 保存什么内容? 栈主要保存 "为了执行函数而产生的临时数据",具体包括:
-
局部变量 :函数内部定义的变量(如
int i,char buf[10])。 -
函数参数 :调用函数时传进去的值(如
func(int a, int b)中的 a 和 b)。 -
返回地址:函数执行完后,CPU 应该回到哪一行代码继续执行。
-
现场保护:发生中断或子函数调用时,CPU 寄存器里的值。
-
例子:栈是如何工作的

形象比喻 : 栈就像是 "便签纸"。
-
main函数在便签上写了 x 和 y。 -
调用
add时,撕下一张新便签贴在上面,写上 a, b 和 result。 -
add算完后,把这张便签撕掉扔进垃圾桶(自动释放)。 -
回到
main的便签继续工作。
二、 堆 (Heap):为了"存货"而存在的仓库
1. 定义 堆是一块巨大的 、散乱的 、手动管理的内存区域。
-
特点:空间大,但分配和释放速度慢。它不像栈那样有条理,数据可以在里面随便放。
-
生命周期 :手动生灭 。从你
malloc开始存在,直到你free结束。如果你忘了free,它就一直占着(内存泄漏)。
2. 保存什么内容? 堆主要保存 "生命周期需要由程序员控制的数据" 或 "特别大的数据":
-
大数组/缓冲区:比如处理一张图片(100KB),栈太小放不下,必须放堆里。
-
动态数据结构:链表节点、二叉树节点(因为你不知道会有多少个节点,无法在编译时确定)。
-
跨函数存活的数据:你希望一个数据在函数 A 里创建,但函数 A 结束后数据还要留给函数 B 用。
-
例子:堆是如何工作的

形象比喻 : 堆就像是 "公共仓库"。
-
你想存一大箱货物,便签纸(栈)肯定贴不住。
-
你去找管理员(
malloc)申请了一个货架位置。 -
管理员给了你一张 提货单(指针)。
-
你把 提货单(指针) 夹在手里的便签本(栈)里。
-
当你办事时,通过便签本上的提货单,去仓库找到货物。
-
办完事,你必须告诉管理员"货架空出来了"(
free),否则那个货架永远被占用。
Gemini said
好的,我们回归最基础的概念。为了让你彻底理清,我们可以把 RAM(随机存储器) 想象成一个 "办事大厅"。
在这个大厅里,主要划分为两个核心区域:栈(Stack) 和 堆(Heap)。
一、 栈 (Stack):为了"办事"而存在的临时工位
1. 定义 栈是一块连续的 、自动管理的内存区域。
-
特点 :它的操作非常快(仅次于 CPU 寄存器),遵循 "后进先出" (LIFO) 原则。
-
生命周期 :自动生灭。函数调用时自动分配,函数返回时自动释放。你不需要操心。
2. 保存什么内容? 栈主要保存 "为了执行函数而产生的临时数据",具体包括:
-
局部变量 :函数内部定义的变量(如
int i,char buf[10])。 -
函数参数 :调用函数时传进去的值(如
func(int a, int b)中的 a 和 b)。 -
返回地址:函数执行完后,CPU 应该回到哪一行代码继续执行。
-
现场保护:发生中断或子函数调用时,CPU 寄存器里的值。
3. 例子:栈是如何工作的
C
// 这是一个子函数
int add(int a, int b) { // 1. 参数 a, b 存放在栈中
int result; // 2. 局部变量 result 存放在栈中
result = a + b;
return result; // 3. 返回后,a, b, result 占用的空间自动失效
}
void main() {
int x = 10; // x 存放在栈中
int y = 20; // y 存放在栈中
int z = add(x, y); // 调用 add 时,栈会"长"出一截给 add 函数用
}形象比喻 : 栈就像是 "便签纸"。
-
main函数在便签上写了 x 和 y。 -
调用
add时,撕下一张新便签贴在上面,写上 a, b 和 result。 -
add算完后,把这张便签撕掉扔进垃圾桶(自动释放)。 -
回到
main的便签继续工作。
二、 堆 (Heap):为了"存货"而存在的仓库
1. 定义 堆是一块巨大的 、散乱的 、手动管理的内存区域。
-
特点:空间大,但分配和释放速度慢。它不像栈那样有条理,数据可以在里面随便放。
-
生命周期 :手动生灭 。从你
malloc开始存在,直到你free结束。如果你忘了free,它就一直占着(内存泄漏)。
2. 保存什么内容? 堆主要保存 "生命周期需要由程序员控制的数据" 或 "特别大的数据":
-
大数组/缓冲区:比如处理一张图片(100KB),栈太小放不下,必须放堆里。
-
动态数据结构:链表节点、二叉树节点(因为你不知道会有多少个节点,无法在编译时确定)。
-
跨函数存活的数据:你希望一个数据在函数 A 里创建,但函数 A 结束后数据还要留给函数 B 用。
3. 例子:堆是如何工作的
C
#include <stdlib.h>
void process_image() {
// 1. 指针 p 是局部变量,它本身存放在【栈】中!
// 2. malloc(1024) 申请的 1024 字节的大空间,是在【堆】中!
// 3. p 的值是一个地址,指向堆里的这块空间。
char *p = (char *)malloc(1024);
if (p != NULL) {
// 在堆里写入数据
p[0] = 0xFF;
p[1] = 0xAA;
// 使用完毕,必须手动释放!
free(p);
}
// 函数返回,栈里的指针变量 p 消失了。
// 如果上面没写 free(p),堆里的 1024 字节就成了没人能找到的孤魂野鬼(内存泄漏)。
}形象比喻 : 堆就像是 "公共仓库"。
-
你想存一大箱货物,便签纸(栈)肯定贴不住。
-
你去找管理员(
malloc)申请了一个货架位置。 -
管理员给了你一张 提货单(指针)。
-
你把 提货单(指针) 夹在手里的便签本(栈)里。
-
当你办事时,通过便签本上的提货单,去仓库找到货物。
-
办完事,你必须告诉管理员"货架空出来了"(
free),否则那个货架永远被占用。
三、 总结对比表
| 特性 | 栈 (Stack) | 堆 (Heap) |
|---|---|---|
| 管理者 | 编译器自动生成指令(自动挡) | 程序员手动写代码(手动挡) |
| 内容 | 局部变量、参数、返回地址 | 大数据、链表、图片缓存 |
| 大小 | 小(通常几 KB) | 大(取决于剩余 RAM,通常几十 KB) |
| 速度 | 极快 (CPU 指令直接操作) | 较慢 (需要算法去查找空闲块) |
| 生长方向 | 向下生长 (高地址 -> 低地址) | 向上生长 (低地址 -> 高地址) |
| 碎片问题 | 无 (严格排队,没有空隙) | 严重 (容易产生零碎空间) |
四、 它们是如何互动的?(关键点)
指针是连接栈和堆的桥梁。
通常我们不会直接"在堆里写代码",而是:
-
在 栈 上定义一个指针变量。
-
让这个指针指向 堆 里的数据。
(2).在裸机上的堆和栈
一、 裸机中栈和堆的大小是如何设置的?
在 STM32 等单片机开发中(如 Keil MDK 或 STM32CubeIDE),这两个空间的大小通常是在**启动文件(Startup File)或链接脚本(Linker Script)**中静态定义的。
1. 设置位置:启动文件 (.s 汇编文件)
打开你的工程,找到类似 startup_stm32f103xb.s 的文件,开头通常就是:
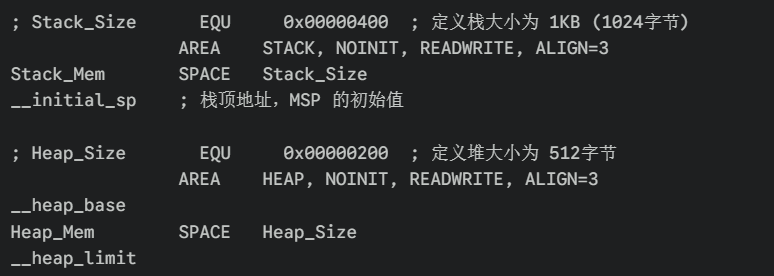
-
栈 (Stack):这里预留了 1KB 的连续内存。这就是你整个裸机程序所有函数嵌套能用的"总存款"。
-
堆 (Heap) :这里预留了 512 字节。这就是你调用
malloc能用的最大上限。
二、 栈 (Stack):核心误区纠正与实例
1. 核心误区:Main 函数与子函数的栈是独立的吗?
答案:绝对不是。这是一个极其重要的概念修正。
真相 :在裸机中,整个程序只有一个巨大的栈空间(就是上面定义的那 1KB)。
-
main函数和它调用的子函数,大家共用这同一块长条形的内存。 -
并没有"独立的栈",只有**"独立的栈帧 (Stack Frame)"**。
2. 栈的运作:像在笔记本上写字
想象这 1KB 的栈就是一个 笔记本。
-
Main 函数进场:
-
它在笔记本的第 1 页 写下了它的局部变量
int a。 -
MSP 指针 指向第 1 页的末尾。
-
-
Main 调用子函数
Func_A:-
CPU 不会换一本新笔记本,而是直接翻到第 2 页(紧接着 Main 的后面)。
-
Func_A在第 2 页写下它的局部变量char b。 -
MSP 指针 移到了第 2 页的末尾。
-
-
Func_A 返回:
-
CPU 把第 2 页撕掉(MSP 指针回退到第 1 页末尾)。
-
第 2 页的数据变成了"垃圾数据",等待被下次覆盖。
-
3. 栈里保存什么?
-
局部变量 :函数内部定义的
int i,char buf[]等。 -
返回地址 (LR):当子函数执行完,CPU 知道回哪里继续执行。
-
现场寄存器 (R0-R12):如果寄存器不够用了,或者发生中断,CPU 会把寄存器的值临时存在栈里。
4. 代码实例
 结论 :栈是连续的、线性的 。所有函数(包括主函数)像"叠罗汉"一样挤在这预设的 1KB 空间里。如果叠得太高(递归太深),超出了 1KB,就叫 栈溢出 (Stack Overflow),程序崩溃。
结论 :栈是连续的、线性的 。所有函数(包括主函数)像"叠罗汉"一样挤在这预设的 1KB 空间里。如果叠得太高(递归太深),超出了 1KB,就叫 栈溢出 (Stack Overflow),程序崩溃。
三、 堆 (Heap):裸机下的管理与碎片化
裸机下的堆,主要服务于标准 C 库的 malloc 和 free。
1. 裸机堆里保存什么?
-
动态申请的数据 :你明确调用
malloc想要存储的大块数据,或者不知道长度的数据(比如变长数组、链表节点)。 -
注意:指针变量本身是在栈里 ,指针指向的实体内容在堆里。
2. 裸机堆的回收机制 (最容易出问题的地方)
在没有 RTOS 的情况下,编译器(如 ARMCC 或 GCC)提供的 malloc/free 库函数通常实现得比较简单(通常是基于链表的管理算法)。
碎片化 (Fragmentation) 是如何产生的?
想象你的堆空间是 一排只有 10 个座位的电影院 (总大小 10 字节)。
-
申请 A :
ptrA = malloc(3);-> 占用座位 1, 2, 3。剩余 7 个。 -
申请 B :
ptrB = malloc(3);-> 占用座位 4, 5, 6。剩余 4 个。 -
申请 C :
ptrC = malloc(3);-> 占用座位 7, 8, 9。剩余 1 个。- 此时内存布局:
[AAA] [BBB] [CCC] [空]
- 此时内存布局:
-
释放 B :
free(ptrB);-
此时内存布局:
[AAA] [空空空] [CCC] [空] -
虽然中间空出了 3 个位置,但它们被夹在 A 和 C 之间。
-
-
灾难发生 - 申请 D :
ptrD = malloc(4);-
失败!
-
虽然总共有 4 个空位(中间 3 个 + 最后 1 个),但没有连续的 4 个位置。
-
这就是内存碎片。
-
3. 裸机下堆设置多了会怎样?
-
浪费 RAM :裸机 RAM 本来就小(如 STM32F103C8T6 只有 20KB)。如果你给堆分了 10KB,但实际上只用了
malloc几次,剩下的空间就白白闲置了,栈想用也用不了。 -
更严重的碎片化 :如果没有高效的算法(像 FreeRTOS 的 heap_4 那样的合并算法),裸机的
free函数往往不具备高效合并相邻空闲块的能力 ,或者合并效率很低。随着程序运行时间变长,堆里会充满"小孔洞",最终导致明明有内存却malloc失败。
注:**能不用堆就不用堆 :在裸机开发中,99% 的场景推荐使用全局数组** 或栈变量 来替代 malloc。
- 坏习惯 :
char *buf = malloc(100);...free(buf); - 好习惯 :
static char buf[100];(虽然占用 RAM,但绝对安全,无碎片)。
**注:**栈要给够 :如果你要在局部变量里定义大数组(如 char buffer[512]),一定要去启动文件里把 Stack_Size 改大,否则程序会莫名其妙进入 HardFault 死机。
(3).裸机和RTOS上的堆和栈对比
一、 栈和堆的大小设置:RTOS vs 裸机
在裸机中,内存布局是"一眼望穿"的;而在 RTOS 中,内存布局变成了"两层套娃"。
1. 裸机 (Bare Metal)
-
设置位置 :全部在 启动文件 (.s) 中设置。
-
栈 (Stack) :只有一个
Stack_Size。这是所有函数(Main + 子函数)和中断共用的唯一空间。 -
堆 (Heap) :只有一个
Heap_Size。这是给标准库malloc用的。
2. RTOS (Real-Time OS)
RTOS 引入了"系统级"和"任务级"的概念,设置变复杂了:
-
A. 启动文件中的 Stack (MSP)
-
设置 :依然在启动文件
.s中设置,但通常可以设得比较小(比如 1KB 或 512B)。 -
用途 :只给中断服务函数 (ISR) 和 RTOS 内核启动前使用 。普通任务不用这里!
-
-
B. RTOS 总堆 (Total Heap)
-
设置 :在
FreeRTOSConfig.h中通过#define configTOTAL_HEAP_SIZE设置(比如 20KB)。 -
用途:这是 RTOS 的"大金库"。所有的任务栈、信号量、队列都从这里扣除。
-
-
C. 任务栈 (Task Stack)
-
设置 :在创建任务
xTaskCreate时指定(如usStackDepth参数)。 -
来源 :注意!任务栈是从"RTOS 总堆"里 malloc 出来的。
-
一句话区别:
-
裸机:栈是栈,堆是堆,井水不犯河水。
-
RTOS :任务栈 寄生 在 RTOS 的堆里面。
结论:RTOS中有基本的栈还有系统申请的堆空间中的任务栈
二、 MSP 与 PSP 指针:双栈机制
"是否是同一个 SP? " 答案是:物理上是两个独立的寄存器,但逻辑上 CPU 同一时间只能用其中一个。
1. 定义
-
MSP (Main Stack Pointer):主栈指针。
-
PSP (Process Stack Pointer):进程栈指针。
2. 裸机 vs RTOS 的区别
-
裸机:
-
只用 MSP。无论在运行 Main 函数还是在跑中断,SP 寄存器永远指向 MSP 的地址。
-
PSP 在裸机里通常是闲置的。
-
-
RTOS:
-
双栈切换。
-
运行内核/中断时 :CPU 自动切换使用 MSP。
-
运行用户任务时 :CPU 自动切换使用 PSP。
-
3. 为什么要这样设计?(为了安全!)
如果某个任务写的不好,导致 栈溢出 (Stack Overflow):
-
在裸机中:栈溢出会直接破坏全局变量甚至中断向量表,系统直接死机或乱跑。
-
在 RTOS 中 :因为它用的是 PSP,溢出只会破坏堆里的数据(因为任务栈在堆里),通常不会破坏 MSP。这意味着中断和内核还能响应,你还有机会在 HardFault 中查出是哪个任务出了问题,甚至重启该任务,而不是整个系统挂掉。
三、 优先级:反直觉的颠倒
这也是初学者最容易晕的地方。
1. 硬件优先级 (NVIC / 裸机)
-
规则 :数字越小,优先级越高。
-
例子:0 是最高优先级(皇帝),15 是最低(平民)。
-
适用对象:所有的中断(定时器中断、串口中断、外部中断)。
2. 软件优先级 (RTOS 任务)
-
规则 :数字越大,优先级越高。
-
例子 :
configMAX_PRIORITIES - 1是最高优先级,0 是空闲任务(垫底)。 -
适用对象 :你创建的各种
Task。
3. 谁是大王?
永远记住:硬件中断 > 软件任务 。 不管你的 RTOS 任务优先级设得有多高(比如 999),只要一个中断(优先级 15,最低的中断)来了,CPU 立刻 暂停任务去跑中断。
-
MSP 此时接管现场。
-
PSP 暂停工作。
四、 RTOS 的堆内存管理 (heap_x.c)
FreeRTOS 提供了 5 种堆管理文件,用来替代裸机那个简陋的 malloc/free。
1. 为什么裸机容易碎片化?
裸机通常直接调用编译器库(C Library)的 malloc。
-
它的算法通常很基础(比如简单的链表)。
-
致命弱点 :当你
free了一块内存,它可能只是简单标记"这里空了",但不会主动去检查这块空地能不能和旁边的空地合并。 -
结果:内存变成了"瑞士奶酪",全是小洞,存不下大数据。
2. RTOS 的 Heap_4.c 是如何"回收"的?
heap_4.c 之所以强,是因为它实现了 内存合并 (Coalescence) 算法。
工作流程例子 : 假设堆里有 3 块连续的内存:[A] [B] [C]
-
你
free(B)。现在 B 是空的。 -
Heap_4 不会就此罢休,它会向左看:A 是空的吗?如果是,把 A 和 B 捏在一起。
-
它会向右看:C 是空的吗?如果是,把 B 和 C 捏在一起。
-
最终结果:原本三个小碎片,被合并成了一个巨大的连续空闲块。
3. 五种模式速览
-
Heap_1 :只分配,不回收。最安全,适合由于不删除任务的系统。(无碎片,因为根本不释放)
-
Heap_2 :能回收,但不合并。会产生碎片。(不推荐)
-
Heap_3 :也就是封装了标准 C 的
malloc/free,只是加了线程保护。碎片化问题和裸机一样。 -
Heap_4 :能回收 + 能合并。最常用,碎片化极低。
-
Heap_5 :和 Heap_4 算法一样,但支持不连续的物理内存(比如内部 SRAM + 外部 SDRAM)。