
🔥小叶-duck:个人主页
❄️个人专栏:《Data-Structure-Learning》
✨未择之路,不须回头
已择之路,纵是荆棘遍野,亦作花海遨游
目录
[二、Stack 的适配器实现](#二、Stack 的适配器实现)
[2.1 按需实例化](#2.1 按需实例化)
[三、 Queue 的适配器实现](#三、 Queue 的适配器实现)
[四、双端队列 deque:结构与适配逻辑](#四、双端队列 deque:结构与适配逻辑)
[1、vector 与 list 的优缺点对比](#1、vector 与 list 的优缺点对比)
[2、deque 的本质与核心特性](#2、deque 的本质与核心特性)
[3、deque 底层结构:缓冲区与中控器的协作](#3、deque 底层结构:缓冲区与中控器的协作)
[4、deque 的优缺点:适用场景与局限性](#4、deque 的优缺点:适用场景与局限性)
一、容器适配器
1、什么是适配器
适配器 是一种设计模式 (设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口 ,本质是接口转换: 通过封装一个底层容器 (如deque、vector、list),屏蔽藏其部分接口,仅暴露符合自身数据访问规则的方法。例如:
- Stack 需 "后进先出(LIFO)",则只需底层容器能支持尾插(push_back) 、尾删(pop_back) 、取尾元素(back) 这三个接口即可;
- Queue 需 "先进先出(FIFO)",则只需底层容器能支持尾插(push_back) 、头删(pop_front) 、取头元素(front) 、取尾元素(back) 这四个接口即可。
2、容器适配器的核心思想
这种设计的优势在于:无需重复实现内存管理逻辑 ,直接复用底层容器 的成熟功能,同时保持接口的简洁性。
虽然 stack 和 queue 中也可以存放元素,但在 STL 中并没有将其划分在容器的行列,而是将其称为容器适配器,这是因为 stack 和 queue 只是对其他容器的接口进行了包装,STL 中 stack 和 queue 默认使用 deque,比如:


二、Stack 的适配器实现
stack 的核心是 "仅允许栈顶操作 ",我们通过模板参数可指定底层容器(默认使用 deque,兼顾效率与灵活性),封装其尾操作接口。
由于 deque 还没讲解到,这里我们可以先不传缺省值讲解 stack 的适配器实现:
1、代码模拟实现
cpp
//Stack.h
#include<iostream>
#include<vector>
#include<list>
using namespace std;
namespace MyStack
{
//Container适配转换出stack
template<class T, class Container>
// 模板参数:T为元素类型,Container为底层容器类型
class stack
{
public:
//入栈
void push(const T& x)
{
_con.push_back(x);
}
//出栈
void pop()
{
_con.pop_back();
}
//获取栈顶元素
const T& top() const
{
return _con.back();
//不管是vector还是list等容器都有通用的获取尾部数据接口back()
//所以这里必须写成_con.back();这种写法
}
//判空
bool empty()
{
return _con.size() == 0;
}
//获取数据个数
size_t size()
{
return _con.size();
}
private:
Container _con;
//_con的类型为模板参数Container,当Container实例化成具体容器时
//模拟实现stack,_con调用的接口就会转换成对应容器的接口使用
};
}- 模板参数灵活性:用户可指定任意支持 push_back / pop_back / back 的容器作为底层(如stack<int, vector<int>> st 或 stack<string, list<string>> st )。
2、接口测试代码
cpp
#include"Stack.h"
void test_stack1()
{
MyStack::stack<int, vector<int>> st;//基于底层容器为数组的栈
//此时模板参数T实例化成int,Container实例化成vector<int>
st.push(1);
st.push(2);
st.push(3);
st.push(4);
while (!st.empty())
{
cout << st.top() << " ";
st.pop();
}
cout << endl;
}
int main()
{
test_stack1();
return 0;
}
2.1 按需实例化
首先我们可以先讲一下什么是按需实例化 :
"按需实例化"指的是:C++模板 (包括函数模板和类模板)的代码,只有在真正被使用 到的时候,编译器才会为其生成具体的类型版本 (即实例化)。没有被用到的部分,编译器只是大致检查模板本身的语法 (比如括号是否匹配、关键词是否正确)。对于模板中依赖于具体类型的代码,编译器会暂时"相信"它是合法的,留到实例化时再检查。这就是所谓的两阶段查找。
所以我们对上面的 pop() 接口进行一些修改:
cpp
//Stack.h
namespace MyStack
{
//Container适配转换出stack
template<class T, class Container>
// 模板参数:T为元素类型,Container为底层容器类型
class stack
{
public:
//按需实例化
void pop()
{
_con.pop_front();
//首先我们要清楚栈是不能出栈底元素的,所以这个在功能上就不对
//其次如果我们Container实例化成的是vector容器,而vector是没有pop_front()这个接口的
//所以正常来说是有问题的,但是当我们没有调用该函数运行程序时是不会报错的
//原因就是按需实例化:当一个类被实例化后不是类中所有的成员函数都会实例化,
//而是根据你是否调用了该函数来进行实例化,而没有被实例化的成员函数其内部编译器是不会仔细查看的
//所以即使Container实例化成的是vector容器,只要我们不调用这个函数也不会报错
//但是只要我们调用了该函数编译器就会查找vector容器是否有该接口,若没有就会报错
}
private:
Container _con;
//_con的类型为模板参数Container,当Container实例化成具体容器时
//模拟实现stack,_con调用的接口就会转换成对应容器的接口使用
};
}
//Test.cpp
void test_stack1()
{
MyStack::stack<int, vector<int>> st;//基于底层容器为数组的栈
//此时模板参数T实例化成int,Container实例化成vector<int>
st.push(1);
st.push(2);
st.push(3);
st.push(4);
cout << st.top() << endl;
cout << endl;
}
int main()
{
test_stack1();
return 0;
}
我们会发现尽管vector没有 pop_front() 的接口,只要我们没有调用 pop() 函数,该函数就不会被实例化,编译器也就不会仔细查看。
但是当我们调用了该函数就会报错:

三、 Queue 的适配器实现
Queue 的核心是 "队尾入、队头出",同样通过模板参数指定底层容器,封装其尾插、头删等接口。
1、代码模拟实现
cpp
//Queue.h
namespace MyQueue
{
template<class T, class Container>
class queue
{
public:
//入队列
void push(const T& x)
{
_q.push_back(x);
}
//出队列
void pop()
{
_q.pop_front();
//通过这个接口我们就能知道vector是不适合作为队列的底层容器的
//首先在实现上vector本身就没有pop_front()这个接口,无法调用
//其次队列出数据是头部出,而vector头删数据的效率是非常低的(时间复杂度为O(N))
//所以队列的实现我们就不会用vector作为底层容器
}
//获取队头数据
const T& front()
{
return _q.front();
}
//获取队尾数据
const T& back()
{
return _q.back();
}
//判空
bool empty()
{
return _q.size() == 0;
}
//获取数据个数
size_t size()
{
return _q.size();
}
private:
Container _q;
};
}- 用 vector 作为底层容器(vector::pop_front 效率极低,时间复杂度 O (n)),所以我们一般不会去使用它来作为底层容器
2、接口测试代码
cpp
//Test.cpp
void test_queue1()
{
//MyQueue::queue<int, vector<int>> q1;
MyQueue::queue<int, list<int>> q1;
q1.push(1);
q1.push(2);
q1.push(3);
q1.push(4);
while (!q1.empty())
{
cout << q1.front() << " ";
q1.pop();
}
cout << endl;
}
int main()
{
test_queue1();
return 0;
}
四、双端队列 deque:结构与适配逻辑
1、vector 与 list 的优缺点对比
|----------|----------------------------------------------------------------------|-----------------------------------------------------------------------------|
| 类别 | vector | list |
| 访问特性 | 物理空间连续,可支持快速下标随机访问;CPU 高速缓存命中率高,数据访问效率优异 | 物理空间不连续不支持快速下标随机访问;CPU 高速缓存命中率低,数据访问效率较差 |
| 增删特性 | 尾插、尾删操作效率极高;但头部或中间位置插入 / 删除效率低下( 时间复杂度 (O(N) ),且插入可能触发扩容,存在性能损耗与空间浪费 | 任意位置插入 / 删除效率极高( 时间复杂度 (O(1)) );插入无需扩容,可按需申请空间与释放内存 |
| 排序性能 | 适合基于随机访问的排序算法(如快速排序),对数组形式的 vector,快速排序能高效利用其连续存储特性,缓存友好,排序速度快 | 因不支持随机访问,排序时需依赖指针遍历(如归并排序),无法高效利用 CPU 缓存,且指针操作额外开销大,排序速度慢于 vector 搭配快速排序的场景 |
2、deque 的本质与核心特性
deque 即双端队列 ,是 STL 中一种双开口 的 "连续" 空间数据结构。
首先我们可以讲一下为什么会有 deque 这个容器,设计目的就是为了将 stack 和 queue 两者功能进行取长补短,而且 deque 这个容器的底层结构设计思路 是基于前面所学的 vector 和 list 的 :
我们知道 vector 就是数组,数据是存放在一段连续的空间中,而 list 的数据是存放在一个个不连续的单个空间通过指针进行连接。所以 deque 的结构相当于将两者进行了结合:
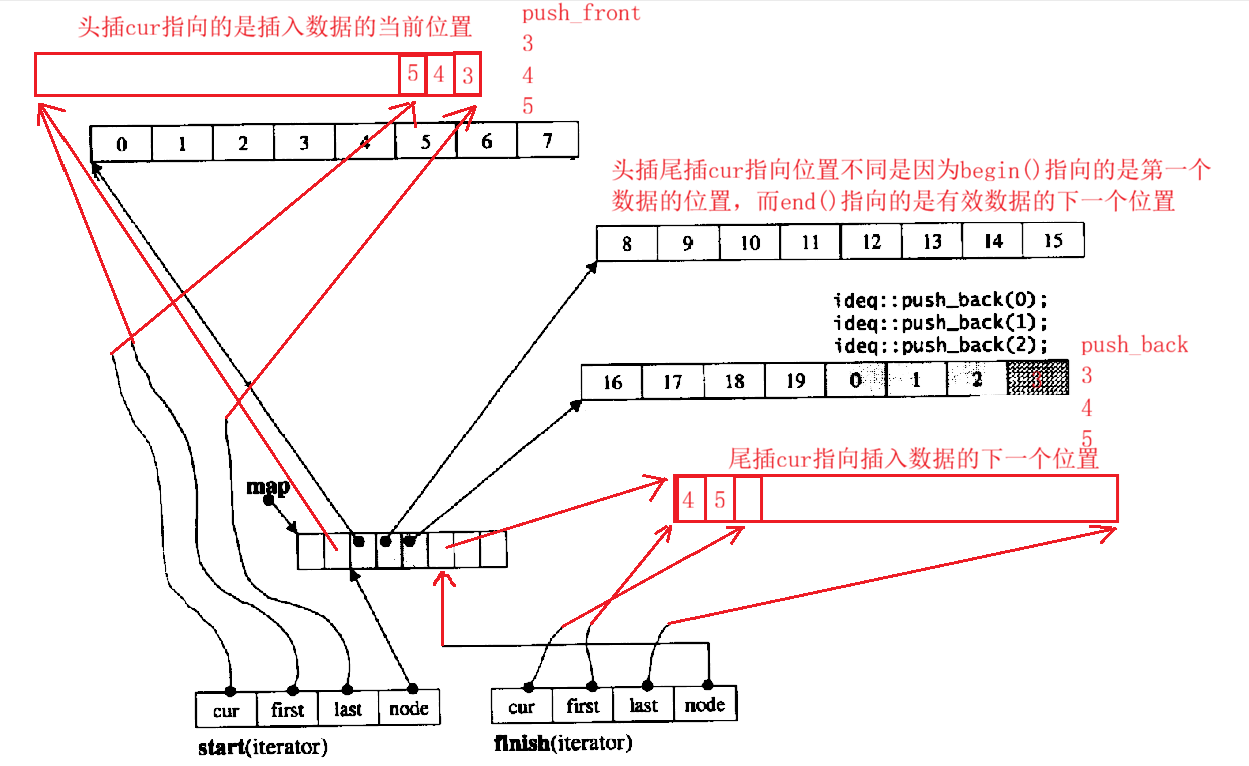
用一个数组来存放指针,而指针的内容就是一段连续的空间。所以不难发现这个数组其实是指针数组,大致如下图所示:
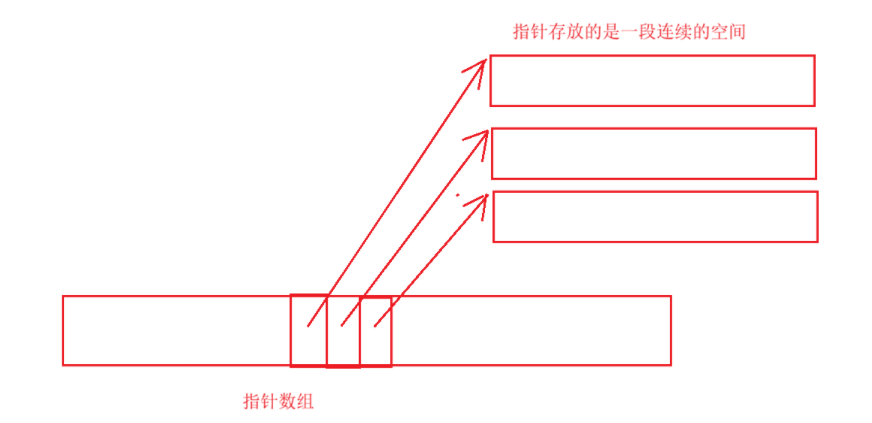
而这个指针数组就被叫做中控器(map) ,这些一段段连续的空间就被叫做缓冲区(buffer)。
deque 的核心特性围绕 "双端操作高效" 和 "空间利用灵活" 展开,具体可概括为两点:
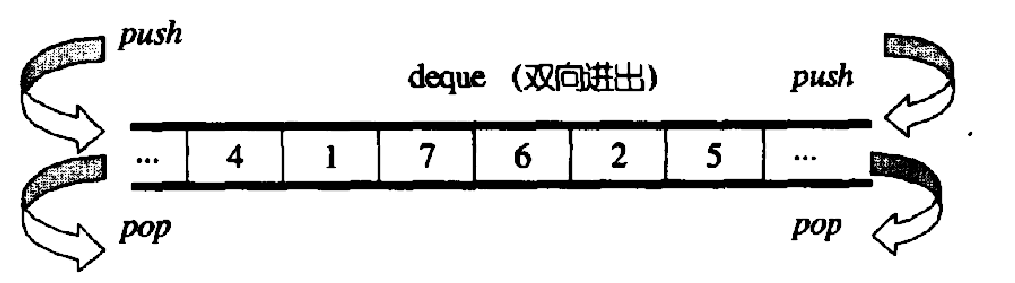
- 双端操作效率高:支持在头部和尾部进行插入(push_front / push_back)、删除(pop_front / pop_back)操作,且时间复杂度均为 O(1),无需像 vector 那样头操作时需搬移大量元素,也无需像 list 那样维护节点间的指针关联。
- "伪连续" 空间结构 :表面上支持随机访问,给人 "连续空间" 的使用体验,但实际底层由一段段小的连续缓冲区(buffer) 和一个中控器(map) 组成 ------ 中控器存储着各个缓冲区的地址 ,通过迭代器的特殊设计 ,将分段的缓冲区 "拼接" 成逻辑上的连续空间。
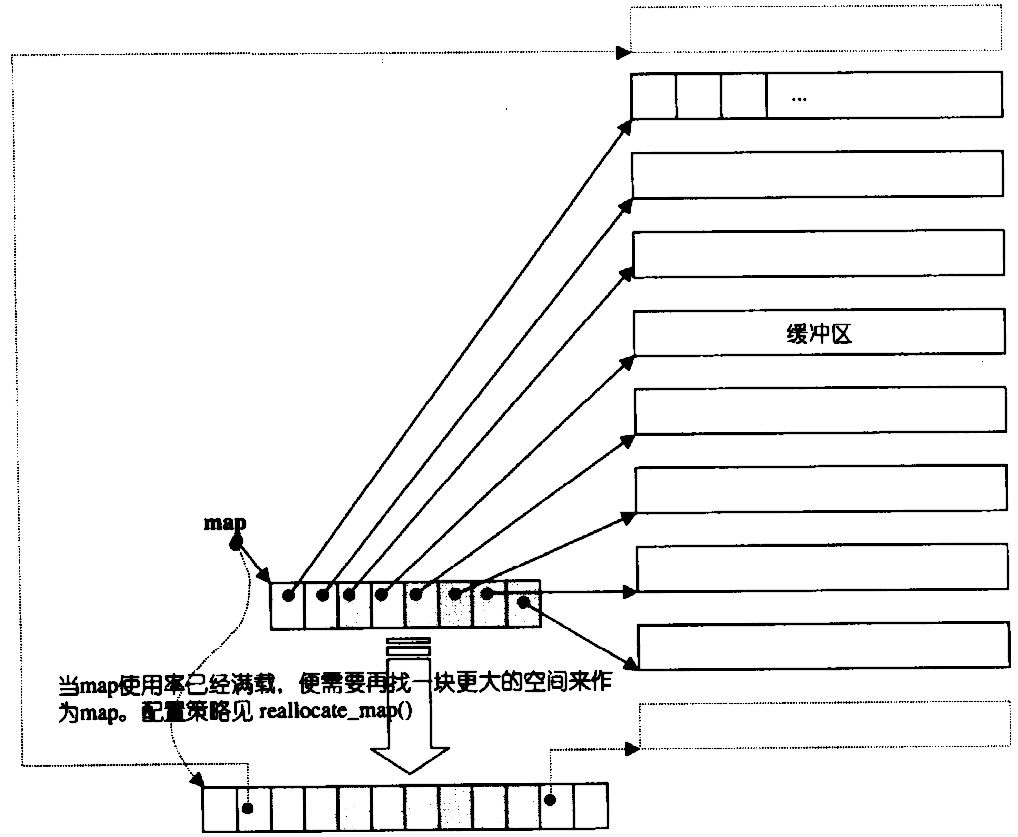
那有些人就会问了:按照这种结构我们怎么去访问里面的数据呢?所以下面我就用一个简单的大框架来为大家讲解一下:
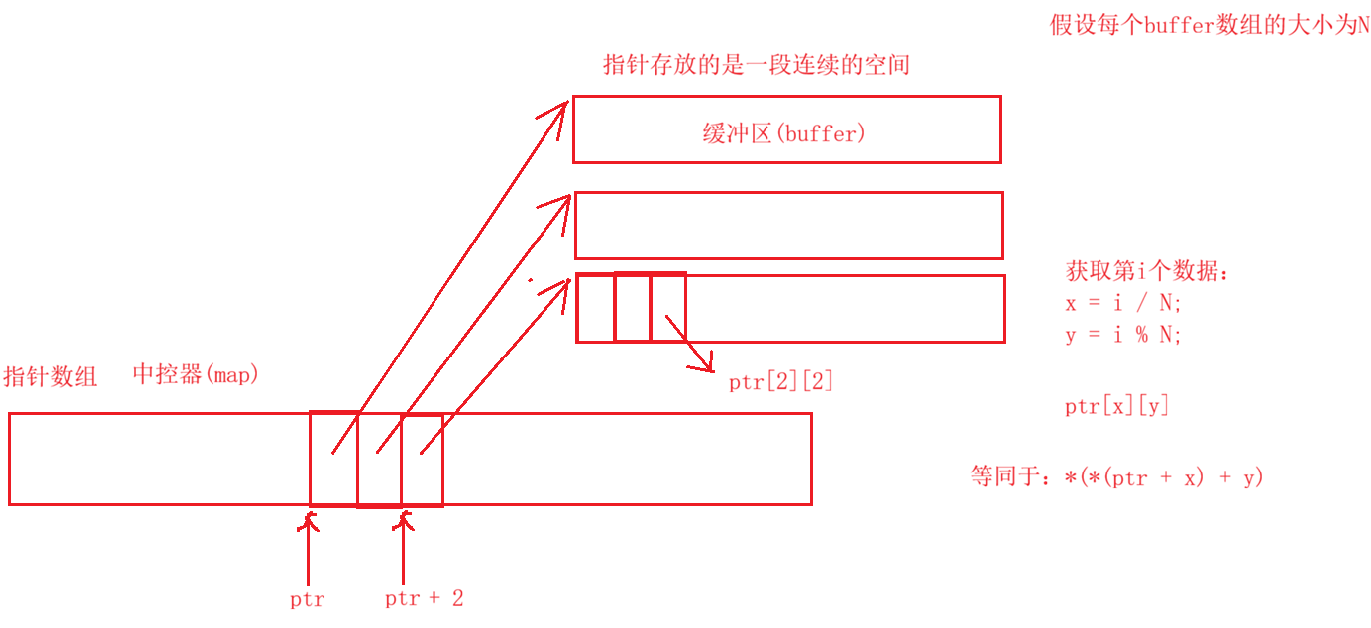
3、deque 底层结构:缓冲区与中控器的协作
deque 的底层结构可拆解为"中控器 + 缓冲区 "两部分,二者配合实现 "伪连续" 特性,具体结构如下:
缓冲区(buffer):
- 存储实际数据的最小单元,是固定大小的连续内存块(比如默认大小为 512 字节)。
- 每个缓冲区独立存在,当数据装满一个缓冲区后,会新申请一个缓冲区,而非像 vector 那样对当前数组进行扩容而导致整体迁移旧数据。
中控器(map):
- 本质是一个动态数组,存储的是各个缓冲区的首地址(指针数组)。
- 当缓冲区数量增加导致中控器装满时,会申请一个更大的中控器(类似 vector 扩容),但只需拷贝旧中控器中存储的 "缓冲区地址",无需迁移缓冲区中的实际数据,效率远高于 vector 扩容。
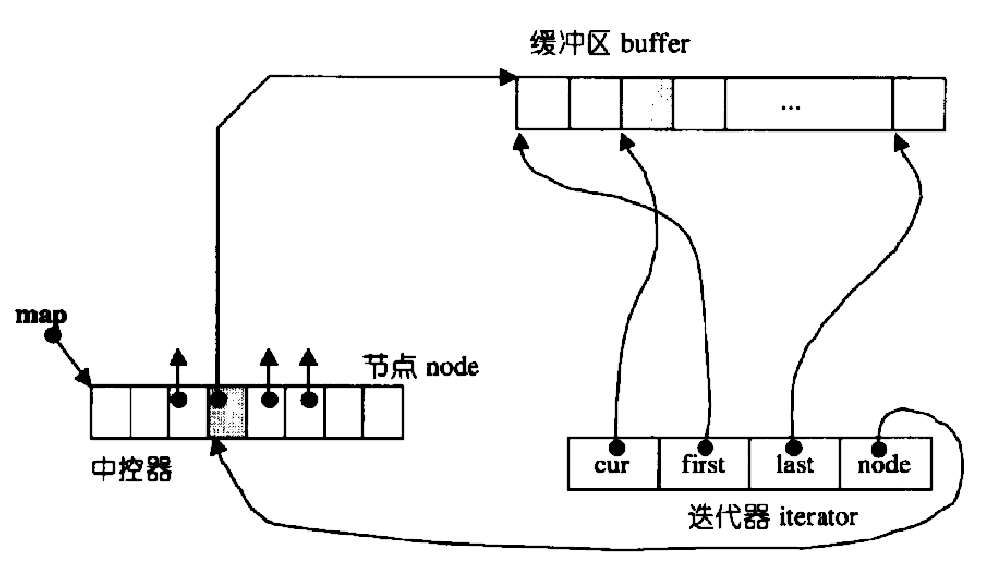
迭代器的 "衔接" 作用:
deque 的迭代器是实现 "伪连续" 的关键,它内部包含四个核心成员:
- cur:指向当前缓冲区中正在访问的元素。
- first:指向当前缓冲区的起始位置。
- last:指向当前缓冲区的末尾位置(不含有效元素)。
- node:指向中控器中当前缓冲区地址所在的节点。
"伪连续" 的逻辑:当迭代器从一个缓冲区的末尾(cur == last)移动到下一个元素时,会通过迭代器 node 找到下一个缓冲区的地址 (也就是node + 1 :原因是中继器本质为一个指针数组,是连续的空间),再将 cur 重新指向新缓冲区的 first,从而实现 **"跨缓冲区连续访问"**的效果。
底层的一些源码:
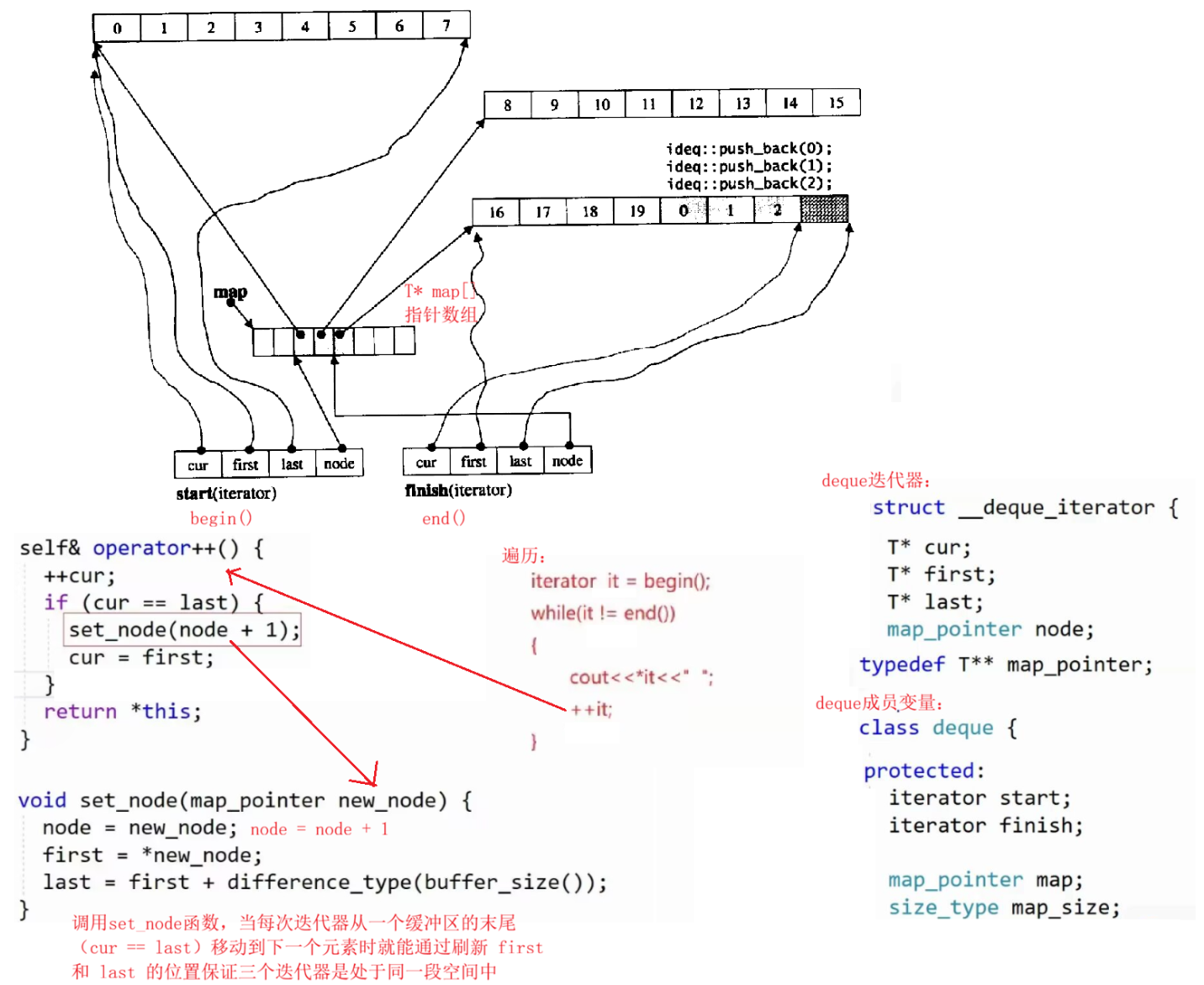
满了之后头插尾插的逻辑:
4、deque 的优缺点:适用场景与局限性
优点:
- 与 vector 比较,deque 头部插入和删除时,由上图可知不需要像 vector 一样移动后面元素,效率更高,而且在扩容时,也只需拷贝旧中控器中存储的 "缓冲区地址",无需迁移缓冲区中的实际数据,效率远高于 vector 扩容。
- 与 list 比较,由于 list 每次头插尾插都只能申请一个空间,当需要多次插入时就需要多次进行申请空间,而 deque 每次可以申请一段空间,减少了多次插入数据申请空间的次数,在效率上也优于 list。
- 虽然对于下标访问的效率不及 vector,但是对于 list 而言访问数据就变得更加灵活。
缺点:
- 不适合遍历,因为在遍历时,deque 的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下( 空间复杂度为O(N) ),而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑 vector 和 list。
- 中间插入/删除数据的效率极低,因为 SGI 选择了保证缓冲区(buffer)的空间大小不变,所以当在中间插入或删除数据时我们不能通过仅修改对应的缓冲区空间大小来实现功能,只能将从该位置往后的所有缓冲区中的数据全部进行移动,导致效率变得十分低下( 空间复杂度为O(N) )
适用场景:
- 适合只需头尾操作、无需频繁遍历的场景,因此成为 stack(仅尾操作)、queue(头尾操作)的默认底层容器,能 "扬长避短"。
局限场景:
- 需要频繁遍历(如 for 循环遍历所有元素)、或需要大量随机访问的场景 ------ 此类场景优先选择 vector(连续空间,遍历 / 随机访问高效),若需频繁中间插入 / 删除则选择 list。
5、代码演示
cpp
//Test.cpp
void test_deque1()
{
deque<int> dq;
dq.push_back(3);
dq.push_back(4);
dq.push_back(5);
dq.push_front(2);
dq.push_front(1);
dq[4] *= 10;
for (auto e : dq)
{
cout << e << " ";
}
cout << endl;
}
int main()
{
test_deque1();
return 0;
}
结束语
到此,stack 和 queue 的模拟实现以及 双端队列 deque 就讲解完了。stack(栈)和 queue (队列)并非从零构建的容器 ,而是通过 "容器适配器" 模式实现 ------ 即复用现有容器的接口 ,封装出符合自身规则 的新数据结构。希望这篇文章对大家学习C++能有所帮助!
C++参考文档:
https://legacy.cplusplus.com/reference/
https://zh.cppreference.com/w/cpp
https://en.cppreference.com/w/