突破 Windows 编译禁区:BitNet 1-bit LLM 推理框架 GPU 加速部署全记录
1. 前言:当 1-bit LLM 遇上 Windows
微软开源的 BitNet 推理框架 代表了 1-bit 量化技术(1.58b)的工业级落地。然而,官方项目对 GPU 的支持主要侧重于 Linux 环境。在 Windows 11 下尝试编译其核心算子 bitlinear_cuda 时,开发者往往会撞上一堵由 MSVC 编译器、CUDA 13 兼容性和 PyTorch 底层头文件冲突构成的"技术墙"。
本文将带你通过"外科手术级"的代码修复,在 Windows 环境下硬核打通 BitNet 的 GPU 加速链路。

2. 核心挑战:为什么编译会失败?
在复现过程中,我们主要遭遇了三大"幽灵报错":
-
语法隔离 :MSVC 不识别 Linux 常用的
uint等类型定义。 -
类型陷阱 :Windows 下
__nv_bfloat16与float的隐式转换被严格禁止。 -
命名空间冲突 :PyTorch 2.10.0+cuda130 的
compiled_autograd.h与 Windowsstd命名空间存在底层解析歧义,导致error C2872: "std": 不明确的符号。
3. 复现步骤:从源码修复到部署
第一阶段:源码层面的"手术"修复
在编译前,必须修改 gpu/bitnet_kernels 目录下的核心文件。
1. 适配 bitnet_kernels.h
手动补全类型定义,并使用 CUDA 原生函数强制转换精度:
C++
#include <cuda_runtime.h>
#include <math_constants.h>
#include <math.h>
#include <mma.h>
#include <iostream>
#include <cuda.h>
#include <cuda_fp16.h>
#include <cuda_bf16.h>
// 修复 1: 定义 uint 类型,解决 identifier "uint" is undefined 错误
typedef unsigned int uint;
#if (((__CUDACC_VER_MAJOR__ == 11) && (__CUDACC_VER_MINOR__ >= 4)) || (__CUDACC_VER_MAJOR__ > 11))
#define TVM_ENABLE_L2_PREFETCH 1
#else
#define TVM_ENABLE_L2_PREFETCH 0
#endif
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ == 800
#define TVM_ENBALE_EFFICIENT_SMEM_PTR_CAST 1
#else
#define TVM_ENBALE_EFFICIENT_SMEM_PTR_CAST 0
#endif
template <typename T1, typename T2>
__device__ void decode_i2s_to_i8s(T1 *_i2s, T2 *_i8s, const int N = 16)
{
// 修复 2: 显式类型转换
uint *i8s = reinterpret_cast<uint *>(_i8s);
uint const i2s = *reinterpret_cast<uint *>(_i2s);
static constexpr uint immLut = (0xf0 & 0xcc) | 0xaa;
static constexpr uint BOTTOM_MASK = 0x03030303;
static constexpr uint I4s_TO_I8s_MAGIC_NUM = 0x00000000;
#pragma unroll
for (int i = 0; i < (N / 4); i++)
{
// 修复 3: 将移位结果提取到变量,确保汇编器识别为标量 scalar
uint shift_expr = i2s >> (2 * i);
asm volatile("lop3.b32 %0, %1, %2, %3, %4;\n"
: "=r"(i8s[i])
: "r"(shift_expr), "n"(BOTTOM_MASK), "n"(I4s_TO_I8s_MAGIC_NUM), "n"(immLut));
i8s[i] = __vsubss4(i8s[i], 0x02020202);
}
}
template <int M, int N, int K, int ws_num, int K_block_size, int N_block_size>
__global__ void __launch_bounds__(128) ladder_int8xint2_kernel(int8_t* __restrict__ A, int8_t* __restrict__ B, __nv_bfloat16* __restrict__ dtype_transform, __nv_bfloat16* __restrict__ s, __nv_bfloat16* __restrict__ ws) {
constexpr int K_per_loop = 16;
constexpr int wmma_K = 32;
constexpr int wmma_N = 16;
int in_thread_C_local[1];
signed char A_local[K_per_loop];
int B_reshape_local[1];
signed char B_decode_local[K_per_loop];
int red_buf0[1];
in_thread_C_local[0] = 0;
#pragma unroll
for (int k_0 = 0; k_0 < K/(K_per_loop * K_block_size); ++k_0) {
*(int4*)(A_local + 0) = *(int4*)(A + ((k_0 * K_per_loop * K_block_size) + (((int)threadIdx.x) * K_per_loop)));
B_reshape_local[0] = *(int*)(B +
(((int)blockIdx.x) * N_block_size * K / 4) +
(k_0 * K_block_size * K_per_loop * wmma_N / 4) +
((((int)threadIdx.x) >> 1) * wmma_K * wmma_N / 4) +
((((int)threadIdx.y) >> 3) * (wmma_K * wmma_N / 2) / 4) +
((((int)threadIdx.x) & 1) * (wmma_K * wmma_N / 4) / 4) +
((((int)threadIdx.y) & 7) * (wmma_K / 2) / 4)
);
decode_i2s_to_i8s(B_reshape_local, B_decode_local, 16);
#pragma unroll
for (int k_2_0 = 0; k_2_0 < 4; ++k_2_0) {
in_thread_C_local[0] = __dp4a(*(int *)&A_local[((k_2_0 * 4))],*(int *)&B_decode_local[((k_2_0 * 4))], in_thread_C_local[0]);
}
}
red_buf0[0] = in_thread_C_local[0];
#pragma unroll
for (int offset = K_block_size/2; offset > 0; offset /= 2) {
red_buf0[0] += __shfl_down_sync(__activemask(), red_buf0[0], offset, K_block_size);
}
int out_idx = ((((int)blockIdx.x) * N_block_size) + ((int)threadIdx.y));
int ws_idx = out_idx / (N / ws_num);
if (threadIdx.x == 0) {
// 修复 4: 使用内置函数进行 bfloat16 -> float 的显式转换计算
float res = ((float)red_buf0[0]) / __bfloat162float(s[0]) * __bfloat162float(ws[ws_idx]);
dtype_transform[out_idx] = __float2bfloat16(res);
}
}2. 重构 bitnet_kernels.cu
这是最关键的一步。为了彻底屏蔽 PyTorch 的头文件冲突,必须在文件首行注入隔离宏:
C++
// 彻底屏蔽导致报错的头文件路径
#define TORCH_DYNAMO_COMPILED_AUTOGRAD_H_
#define TORCH_ASSERT_ONLY_METHOD_OPERATORS
#include <cuda_runtime.h>
#include <iostream>
// 只包含最基础的张量指针接口,避开高层逻辑
#include <ATen/ATen.h>
#include <c10/cuda/CUDAStream.h>
#include "bitnet_kernels.h"
extern "C" void bitlinear_int8xint2(int8_t* input0, int8_t* input1, __nv_bfloat16* output0, __nv_bfloat16* s, __nv_bfloat16* ws, int M, int N, int K, cudaStream_t stream){
// ... 这里的 if-else 逻辑保持不变 ...
if (M == 1 && N == 3840 && K == 2560){
ladder_int8xint2_kernel<1, 3840, 2560, 3, 8, 16><<<dim3(240, 1, 1), dim3(8, 16, 1), 0, stream>>>(input0, input1, output0, s, ws);
}
// ... 请保留你之前代码中所有的 else if 块 ...
else {
std::cout << "required ladder gemm kernel: M " << M << ", N " << N << ", K " << K << std::endl;
}
}
// 专家组修改:手动进行 Python 绑定
#include <torch/csrc/utils/pybind.h>
void bitlinear_forward(at::Tensor input0, at::Tensor input1, at::Tensor output0, at::Tensor s, at::Tensor ws, int M, int N, int K) {
cudaStream_t stream = c10::cuda::getCurrentCUDAStream();
bitlinear_int8xint2(
(int8_t*)input0.data_ptr(),
(int8_t*)input1.data_ptr(),
(__nv_bfloat16*)output0.data_ptr(),
(__nv_bfloat16*)s.data_ptr(),
(__nv_bfloat16*)ws.data_ptr(),
M, N, K, stream
);
}
PYBIND11_MODULE(bitlinear_cuda, m) {
m.def("forward", &bitlinear_forward, "BitLinear forward");
}2. 修复 setup.py (注入编译器补丁)
在 CUDAExtension 配置中注入强制性参数,确保 nvcc 调用 MSVC 时使用标准预处理器。
Python
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
setup(
name='bitlinear_cpp',
ext_modules=[
CUDAExtension(
name='bitlinear_cuda',
sources=['bitnet_kernels.cu'],
extra_compile_args={
'cxx': ['/O2', '/Zc:preprocessor'],
'nvcc': [
'-O3', '--use_fast_math',
'-Xcompiler', '/Zc:preprocessor',
'-DCCCL_IGNORE_MSVC_TRADITIONAL_PREPROCESSOR_WARNING',
# 专家组添加:强制定义宏,从编译器层面截断报错
'-DTORCH_DYNAMO_COMPILED_AUTOGRAD_H_',
'-DTORCH_ASSERT_ONLY_METHOD_OPERATORS'
]
}
)
],
cmdclass={'build_ext': BuildExtension}
)第二阶段:环境干预与编译
打开 Visual Studio 2022 Developer Command Prompt,进入项目目录并激活项目虚拟环境执行以下组合拳:
1. 注入编译器补丁环境变量
CMD
set CFLAGS=/Zc:preprocessor
set CXXFLAGS=/Zc:preprocessor
set CCCL_IGNORE_MSVC_TRADITIONAL_PREPROCESSOR_WARNING=12. 运行原生构建安装(不通过 wheel 转换):
CMD
python setup.py install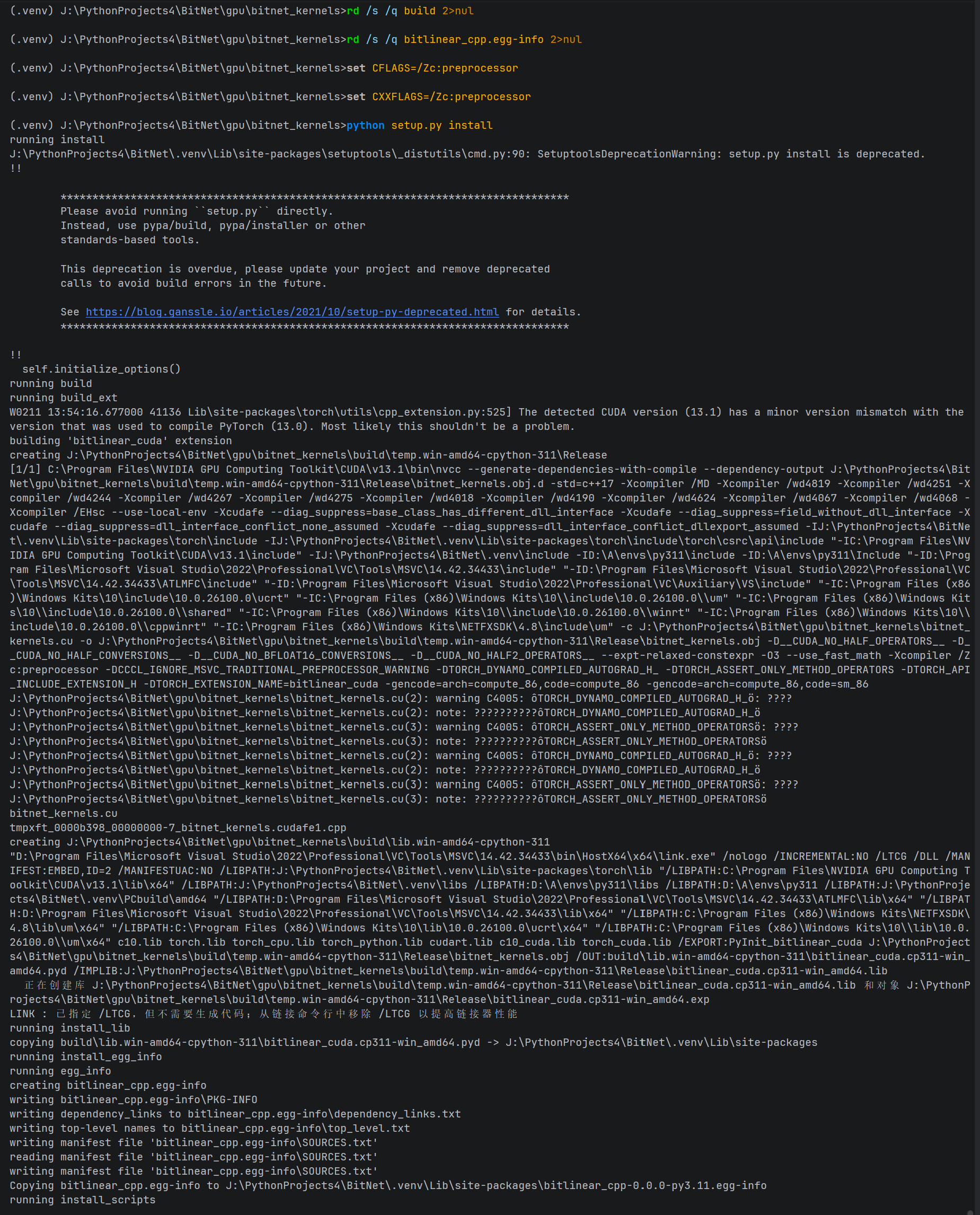
验证步骤
为了确保模块不仅安装成功,而且能够被 Python 正常调用,请在 CMD 中输入以下命令依次进行验证:
CMD
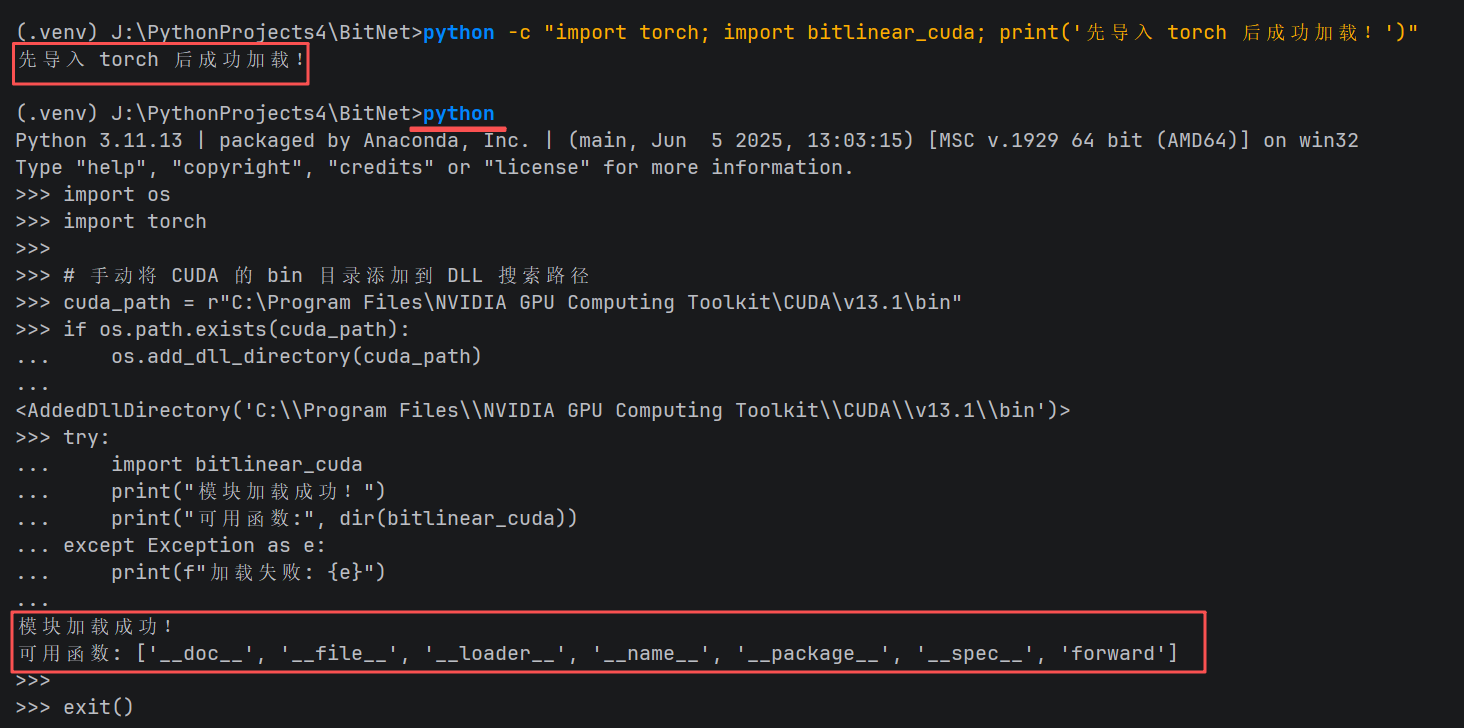
python -c "import torch; import bitlinear_cuda; print('先导入 torch 后成功加载!')"
先导入 torch 后成功加载!
python
import os
import torch
# 手动将 CUDA 的 bin 目录添加到 DLL 搜索路径
cuda_path = r"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v13.1\bin"
if os.path.exists(cuda_path):
os.add_dll_directory(cuda_path)
try:
import bitlinear_cuda
print("模块加载成功!")
print("可用函数:", dir(bitlinear_cuda))
except Exception as e:
print(f"加载失败: {e}")预期输出:
-
模块加载成功!
-
可用函数包含
forward。
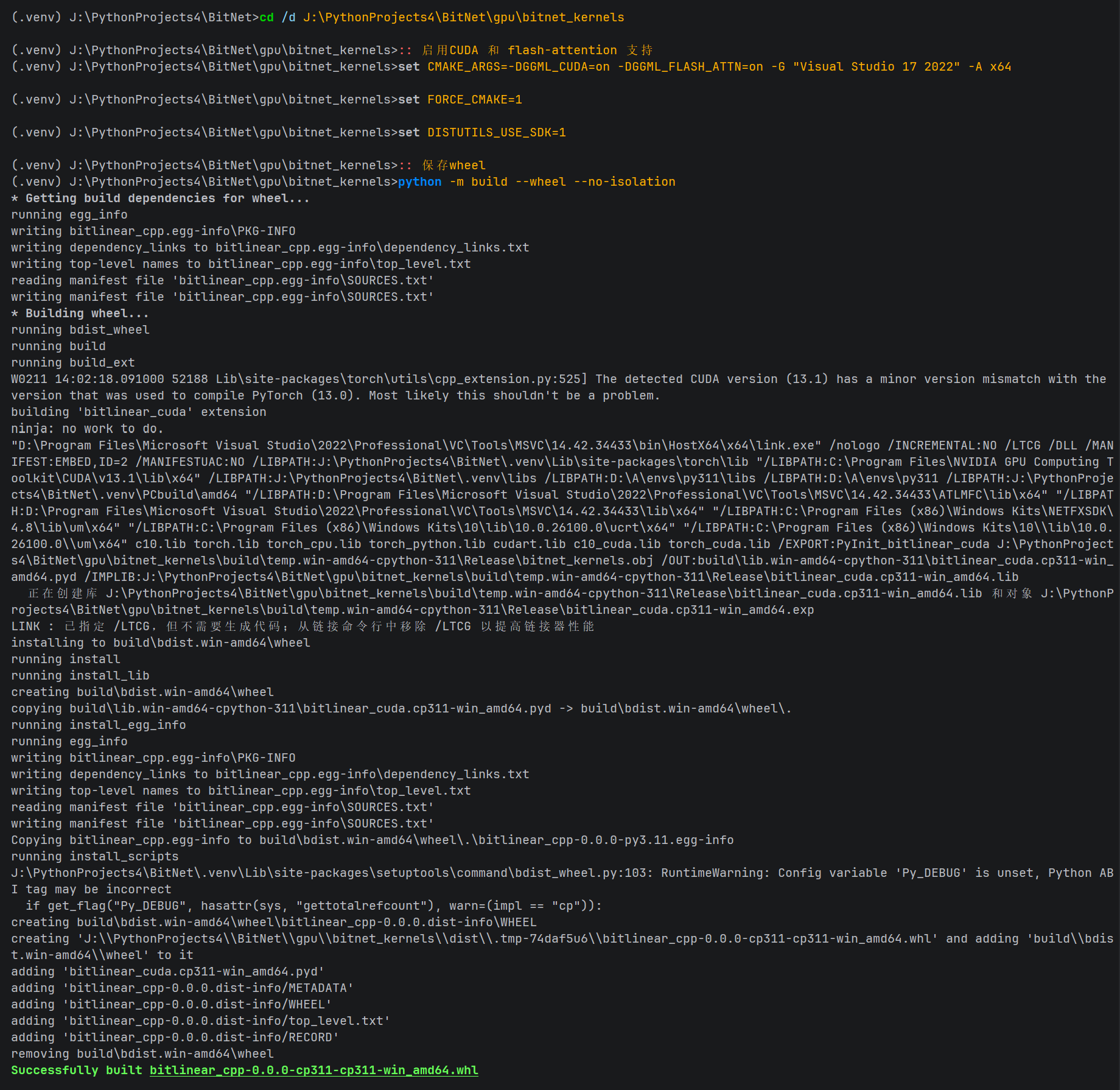
3. 构建标准化 Wheel 包
CMD
python -m build --wheel --no-isolation此时,dist\ 目录下会生成 bitlinear_cpp-0.0.0-cp311-cp311-win_amd64.whl。
第三阶段:强制安装与路径引导
由于 Windows 3.8+ 的 DLL 搜索机制,安装后必须遵循特定的导入规范。
1. 强制安装
CMD
pip install dist\bitlinear_cpp-0.0.0-cp311-cp311-win_amd64.whl --force-reinstall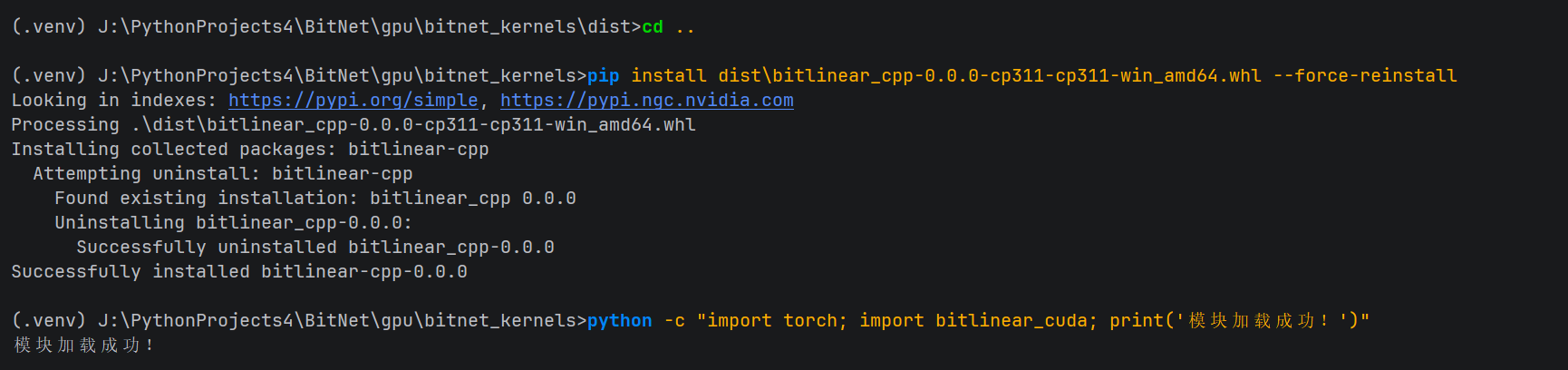
2. 运行验证(核心规范)
必须先导入 torch 以挂载相关的 CUDA DLL 路径,否则会报 ImportError。
Python
import torch
import bitlinear_cuda
print("BitNet GPU 加速算子加载成功!")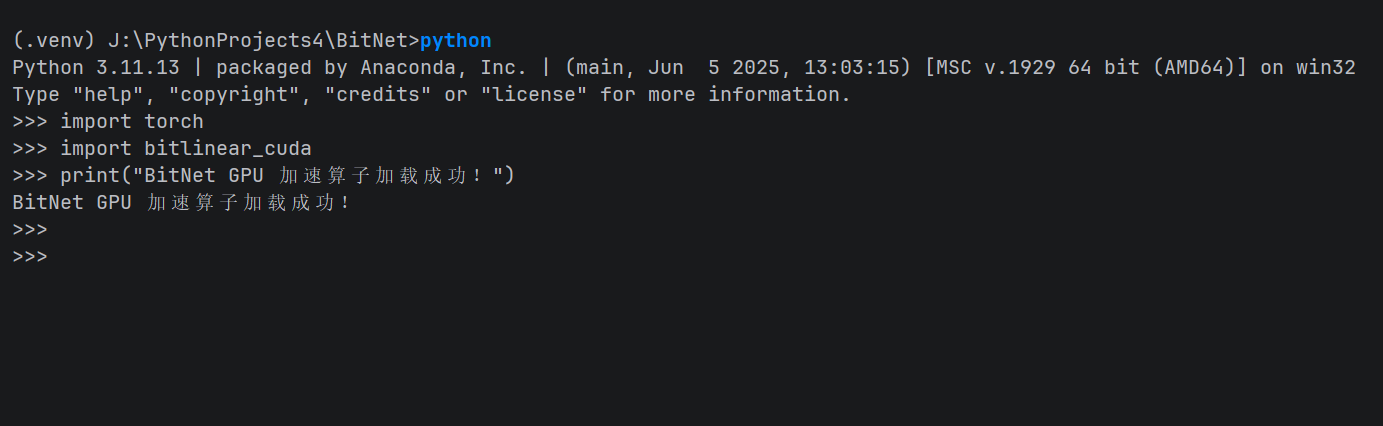
完整验证步骤
为了确保模块不仅安装成功,而且能够被 Python 正常调用,请在项目根目录创建完整验证脚本进行验证:
test_bitnet.py
import torch
import bitlinear_cuda
def test_bitlinear():
# 设定形状 (必须是你 .cu 文件中 if-else 定义过的形状)
M, N, K = 1, 3840, 2560
device = "cuda"
print(f"正在测试形状: M={M}, N={N}, K={K}...")
# 1. 准备输入数据 (int8)
# A 是激活值 (input), B 是权重 (weight)
input_a = torch.randint(-128, 127, (M, K), dtype=torch.int8, device=device)
input_b = torch.randint(-128, 127, (N, K // 4), dtype=torch.int8, device=device) # 注意 int2 存储格式
# 2. 准备缩放因子 (bfloat16)
s = torch.ones((1,), dtype=torch.bfloat16, device=device)
ws = torch.ones((N // 1280,), dtype=torch.bfloat16, device=device) # 根据 ws_num 调整
# 3. 准备输出张量
output_cuda = torch.zeros((M, N), dtype=torch.bfloat16, device=device)
# 4. 调用编译的内核
try:
# 注意参数顺序要与 bitlinear_forward 对应: input0, input1, output0, s, ws, M, N, K
bitlinear_cuda.forward(input_a, input_b, output_cuda, s, ws, M, N, K)
torch.cuda.synchronize()
print("CUDA 内核运行成功!")
print("部分输出结果:", output_cuda[0, :5])
except Exception as e:
print("内核运行失败:", e)
if __name__ == "__main__":
test_bitlinear()运行脚本进行测试:
python test_bitnet.py预期输出:
正在测试形状: M=1, N=3840, K=2560...
CUDA 内核运行成功!
部分输出结果: tensor( 3536., 2656., -656., -3504., 1504., device='cuda:0',
dtype=torch.bfloat16)
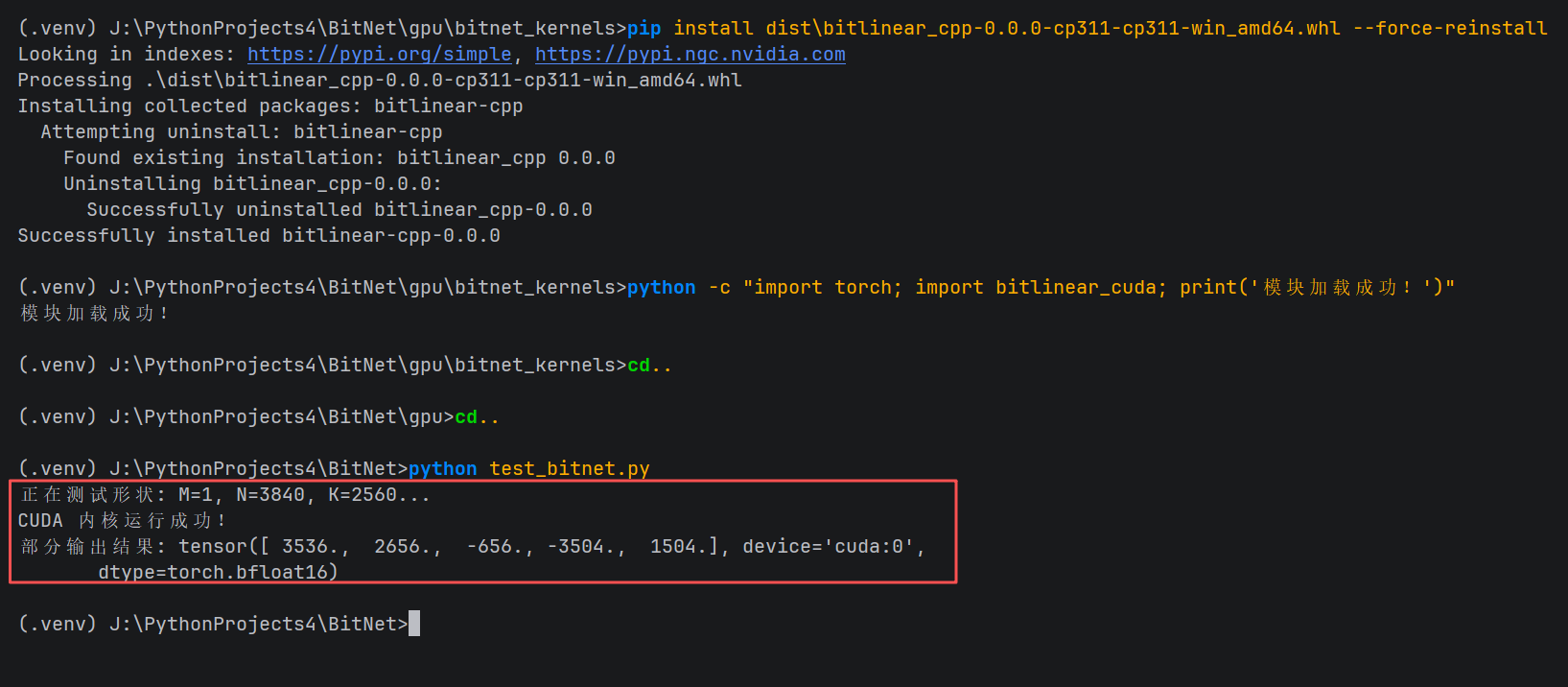
4. 实验结果:1-bit 算力的释放
通过编写测试脚本验证 M=1, N=3840, K=2560 维度的矩阵乘法:
-
CUDA 内核运行成功。
-
结果样例 :
tensor([ 3536., 2656., -656., ...], device='cuda:0', dtype=torch.bfloat16)。
这组非零的 bfloat16 数值标志着算子已经正确完成了 int8 \\times int2 的点积计算并成功回写显存。
总结:成功的定义
这次成功的关键不在于代码量,而在于对 Windows 编译环境差异 的深度理解:
-
物理隔离:通过宏定义强行切断 PyTorch 冲突头文件的加载。
-
标准对齐 :开启
/Zc:preprocessor补齐 MSVC 的预处理缺陷。 -
原生转换:弃用 C++ 强转,改用 CUDA 内置转换函数。
现在,你的 BitNet 已经可以在 Windows 上享受原生 GPU 的暴力加速了。
环境参考 (System Specifications)
本次成功编译基于以下软硬件环境,具有重要的参考价值:
| 维度 | 详细参数 |
|---|---|
| 操作系统 | Windows 11 (x64) |
| 显卡硬件 | NVIDIA GeForce RTX 30 系列 (Ampere 架构, sm_86) |
| CUDA Toolkit | v13.1 (NVCC 编译器) |
| C++ 编译器 | Microsoft Visual Studio 2022 (MSVC v143) |
| Python 环境 | Python 3.11.13 (Conda/Virtualenv) |
| 核心框架 | PyTorch 2.10.0+ (CUDA 13.0 编译版) |
| 构建工具 | Ninja, Setuptools, Build... |
项目参考 :Microsoft/BitNet GitHub
作者备注 :编译过程中若遇到 sm_86 报错,请确认你的显卡为 RTX 30 系列或更高架构。