讨论 iOS 应用代码混淆时,很多文章都会停留在源码阶段,比如改变量名、插入宏、用脚本批量替换标识符。这些方式在持续开发阶段确实有意义。但当你面对的是已经编译完成的 IPA,或者你无法接触完整源码时,混淆的操作方式就完全不同了。
这篇文章谈论拿到一个已经打包完成的 iOS IPA,如何对其中的代码结构进行混淆处理,并确保还能正常运行?
检查从解包开始
无论做什么混淆,第一步不是"加密",而是观察。
把 IPA 改成 zip 解压后,目录结构会很清晰:
- Payload/AppName.app/
- 可执行二进制文件
- Frameworks
- 各类资源文件
接下来可以用常见的符号查看工具读取主二进制文件,观察几个点:
- 类名是否具备语义
- Swift 方法名是否完整暴露
- Objective-C 选择器是否可读
- 是否残留调试信息
如果在符号列表中能直接看到类似 UserManager、loginWithToken:、fetchOrderList 这样的名称,那么混淆工作就有明确目标。
源码混淆与成品包混淆的区别
在源码阶段,可以使用:
- 宏替换
- 脚本重命名
- Swift Shield 等基于源码的混淆工具
- 构建时插桩
但这些方式依赖完整工程。
在成品包阶段,关注点会变成:
- 已编译符号的重写
- 方法名与类名映射替换
- 资源引用一致性维护
- 重新签名与可执行验证
这两个阶段的工具链并不重叠。
成品 IPA 的代码混淆流程
1. 导入 IPA 并定位可执行文件
把 IPA 载入 Ipa Guard 混淆工具后,第一件事是确认目标二进制。
在一个包含多个 framework 的项目里,需要明确:
- 主程序二进制
- 是否需要处理子 framework
- 是否存在第三方 SDK 需要排除
如果对所有模块都做同强度处理,可能会影响运行。
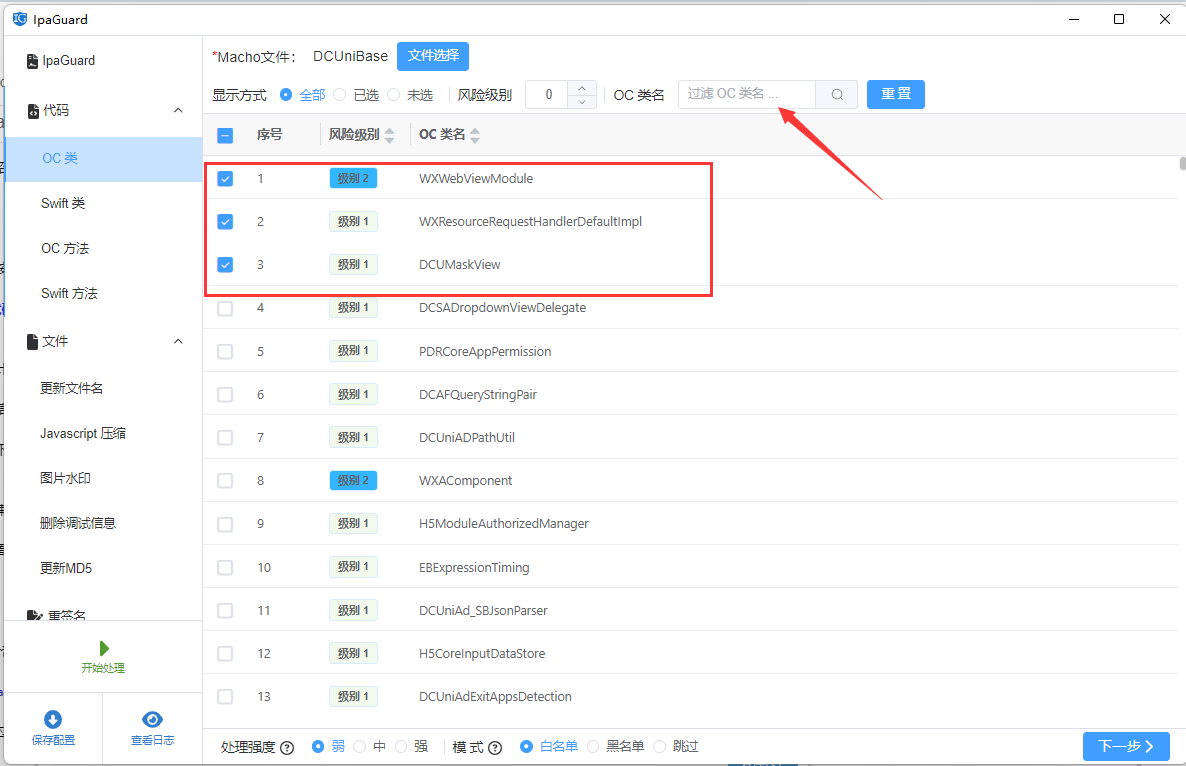
2. 分级选择混淆目标
在 Ipa Guard 中,可以看到代码模块分为:
- OC 类
- Swift 类
- OC 方法
- Swift 方法
此时不要一次性全选。
可以先做一个验证轮次:
- 选择业务模块相关类
- 排除系统类
- 排除明显依赖动态调用的部分
工具提供名称搜索和过滤能力,可以快速定位特定前缀类,例如 App, Biz, Core 等命名空间。
处理完成后导出 IPA,重新解包检查符号变化。
3. 方法级混淆与动态调用的关系
在一些项目中,会存在:
NSSelectorFromString- 反射调用
- runtime 绑定
如果方法名被替换,而调用处仍按原字符串拼接,运行阶段会找不到实现。
在这种情况下,可以采用分组处理方式:
- 仅混淆非动态调用模块
- 对字符串拼接部分做保留策略
Ipa Guard 支持按类和方法精细选择混淆对象,这种可控配置在调试阶段会节省大量时间。
4. 调试信息清理
有些 IPA 在打包时未完全移除调试符号。
清理自动注释、调试信息后,可以再通过工具查看符号表,对比前后差异。
验证方式很简单:
- 处理前导出符号列表
- 处理后再次导出
- 对比可读名称比例
如果语义名称明显减少,说明结构级混淆已生效。
资源层面的辅助处理
代码混淆解决的是结构语义问题。
但在逆向分析时,资源文件也提供线索:
- JSON 里可能写着接口路径
- HTML 里有业务描述
- 图片名可能对应模块
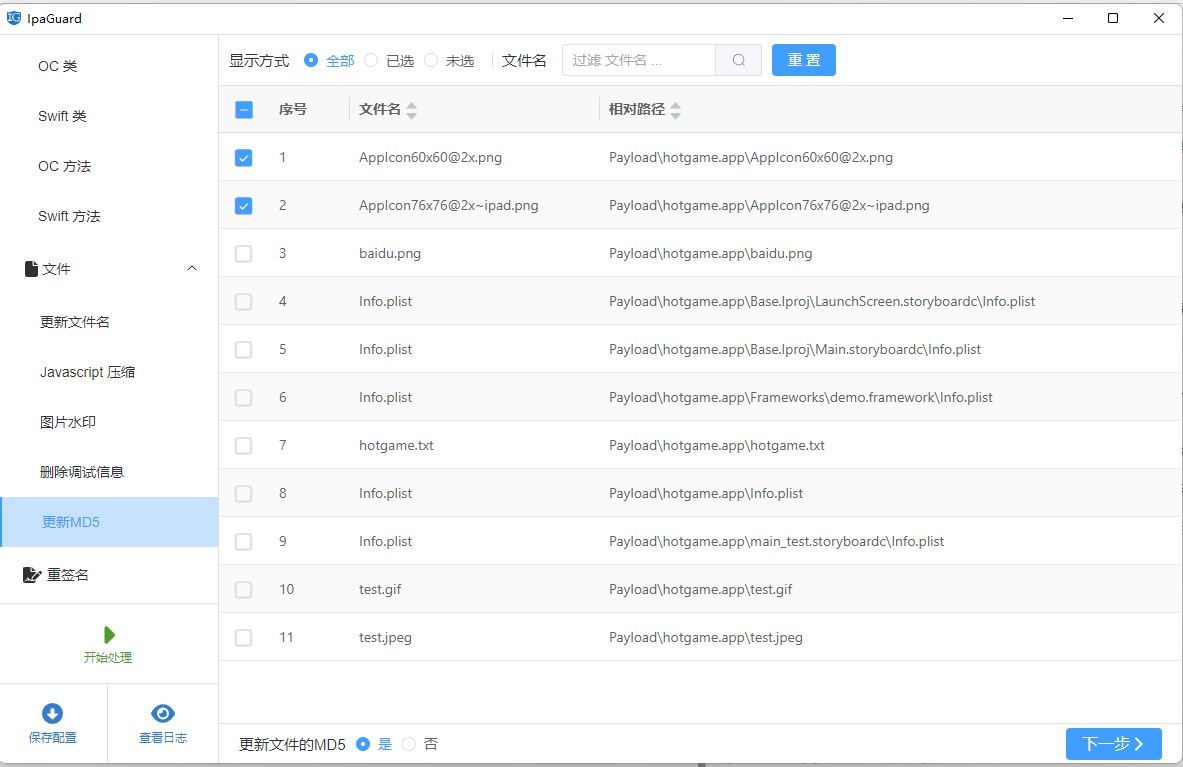
在同一轮处理里,可以同步对资源做:
- 文件名重命名
- 图片添加水印
- 修改资源 MD5 值
重新解包后对比 MD5 校验结果,可以看到变化。
重签名与真机验证
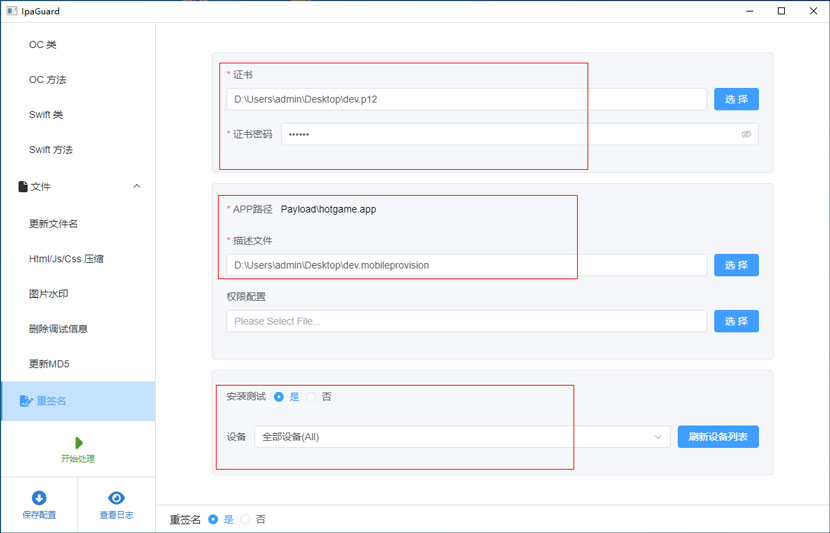
代码混淆完成后,必须执行签名流程。
在 Ipa Guard 中:
- 配置开发证书与描述文件
- 自动重签名
- 安装到测试设备
运行测试的目标不是看界面是否正常,而是关注:
- 登录流程是否异常
- 动态调用是否报错
- 推送、支付等模块是否仍可执行
如果出现闪退,可以回到混淆配置界面,减少混淆对象,重新处理。
多工具协作场景
在完整安全流程中,可以组合使用:
- 源码阶段混淆工具(如 Swift Shield)
- 编译参数优化
- 符号裁剪
- 成品包混淆工具(如 Ipa Guard)
- 资源签名校验机制
这些工具解决的问题层级不同。
源码工具处理的是构建阶段可见结构,成品包工具处理的是最终发布结构。
当两者叠加时,解包后看到的信息量会进一步减少。
一些实践中的调整思路
在项目规模较大时,可以采用迭代式混淆:
- 第一轮:仅混淆类名
- 第二轮:加入方法混淆
- 第三轮:提高强度并清理调试信息
每一轮都进行真机验证。
这样可以快速定位问题来源,而不是在全部混淆后再排查崩溃点。