RabbitMQ架构核心拆解:从消息代理到四大组件,一文看懂异步通信基石
在分布式系统里,你有没有遇到过这样的场景?订单服务处理完一笔交易,需要立刻通知库存系统扣减、物流系统发货、积分系统更新。如果让订单服务直接调用这些下游服务,任何一个环节卡顿或失败,都会导致整个下单流程阻塞,用户体验直线下降。更糟的是,一旦某个服务需要升级或重构,所有依赖它的服务都得跟着改,牵一发而动全身。
RabbitMQ,正是为解决这类"紧耦合"与"同步阻塞"的痛点而生。 它扮演着 "消息代理(Broker)" 的角色,像一个高度智能的邮局,在应用之间构建了一个中立、可靠的通信层。生产者(发送方)只需把"信件"(消息)交给邮局,就可以继续自己的工作,完全不用关心谁来收信、何时送达。消费者(接收方)则按自己的节奏从邮局的"信箱"(队列)里取信处理。这种设计,从根本上实现了系统解耦 与异步通信------发送者与接收者互不知晓、互不影响,系统的可扩展性和容错性因此大幅提升。
消息代理(Broker)的本质:异步通信与系统解耦
RabbitMQ作为消息代理的核心价值,远不止于"转发消息"。它构建了一套基于协议的标准通信范式 ,其本质是AMQP(高级消息队列协议)的Erlang实现。这意味着,任何遵循此协议的应用,无论用什么语言编写,都能通过RabbitMQ进行可靠对话。
这种设计带来了三大核心优势:
- 削峰填谷:面对瞬间流量洪峰(如秒杀),RabbitMQ能将请求暂存于队列,让后端服务按自身处理能力匀速消费,避免系统被压垮。
- 应用解耦:服务间不再直接调用,而是通过消息通信。任一服务的升级、重启或扩容,都不会直接影响其他服务,极大提升了系统整体的可维护性和弹性。
- 异步提速:生产者发出消息后即可返回,不必等待消费者处理完成,从而显著缩短核心链路的响应时间,提升用户体验。
RabbitMQ就像一个永不疲倦的协调员,确保在分布式系统的嘈杂环境中,每条指令都能被准确、有序地传达。
然而,这种解耦也并非没有代价。它引入了额外的系统复杂性,如消息的时序性保证、错误消息的重试与死信处理,都需要开发者基于此架构进行精心设计,否则可能带来新的问题。
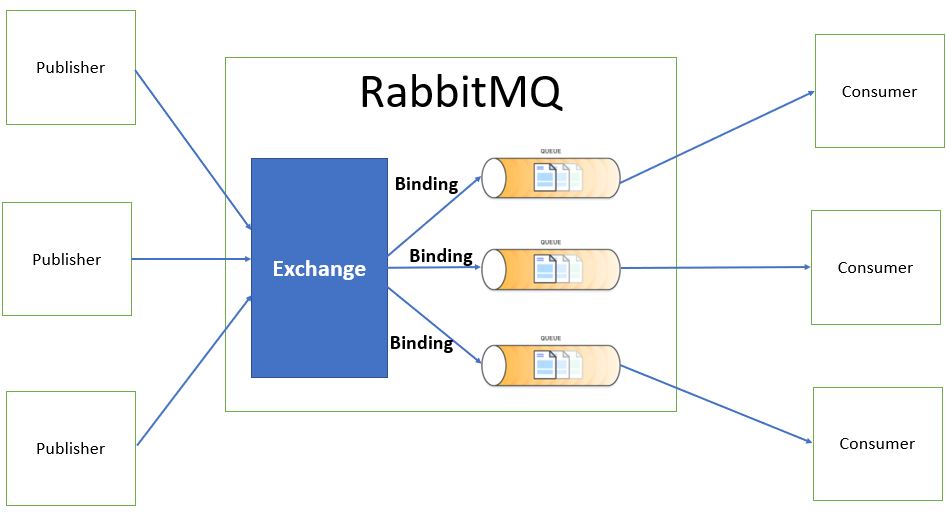
核心架构图:生产者、交换机、队列、消费者的协作关系
理解了其定位后,我们拆解RabbitMQ最核心的四大组件及其协作流程。这远比简单的"发-存-收"复杂:
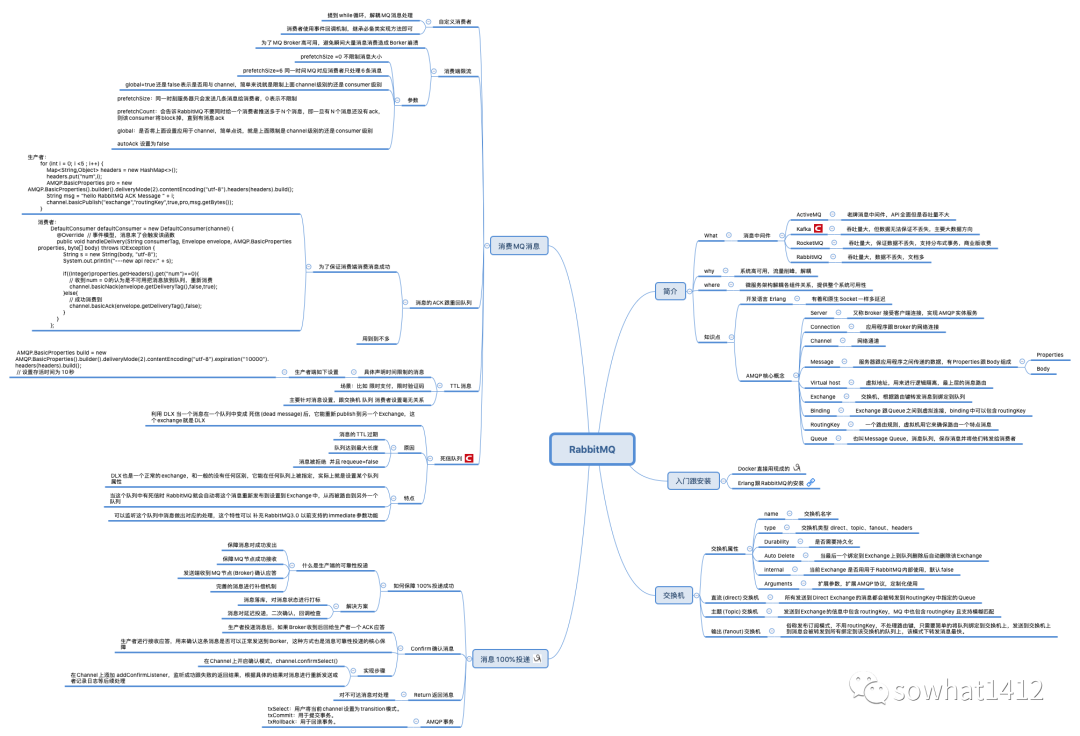
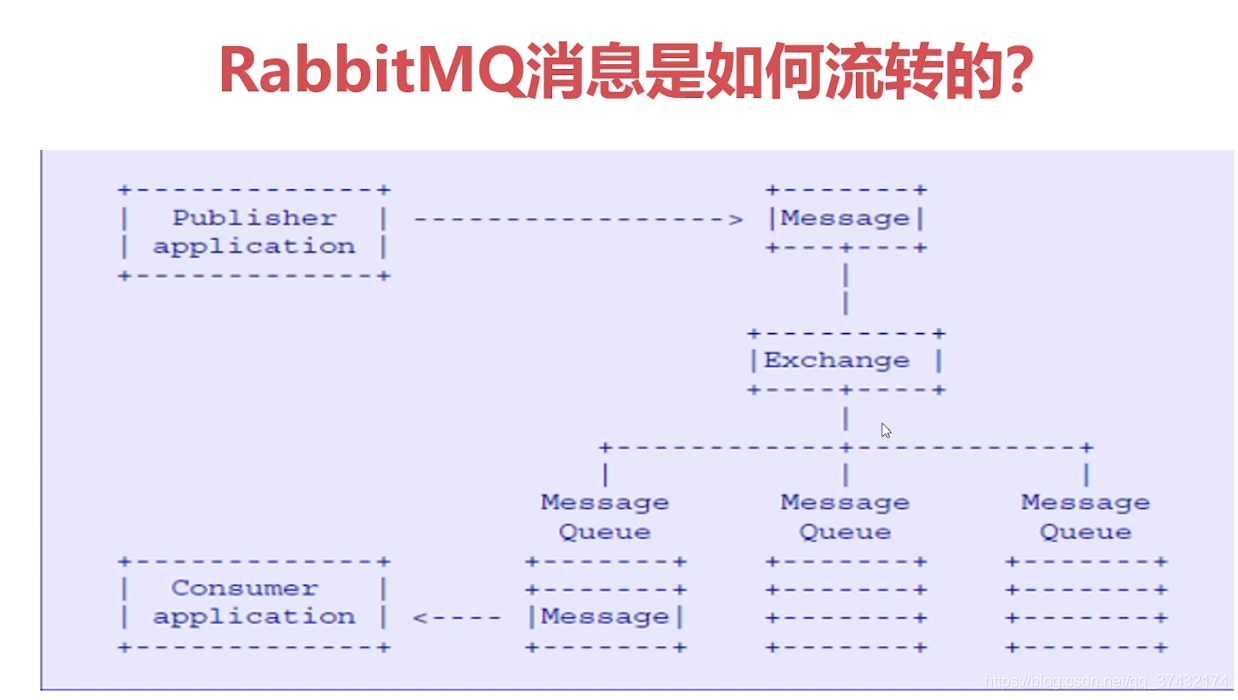
[生产者 (Producer)] --发布消息--> [交换机 (Exchange)]
|
| (根据路由规则)
v
[队列 (Queue)] <--绑定 (Binding)-- [交换机 (Exchange)]
|
| (存储消息)
v
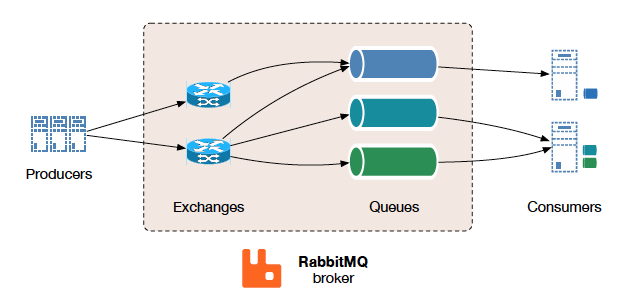
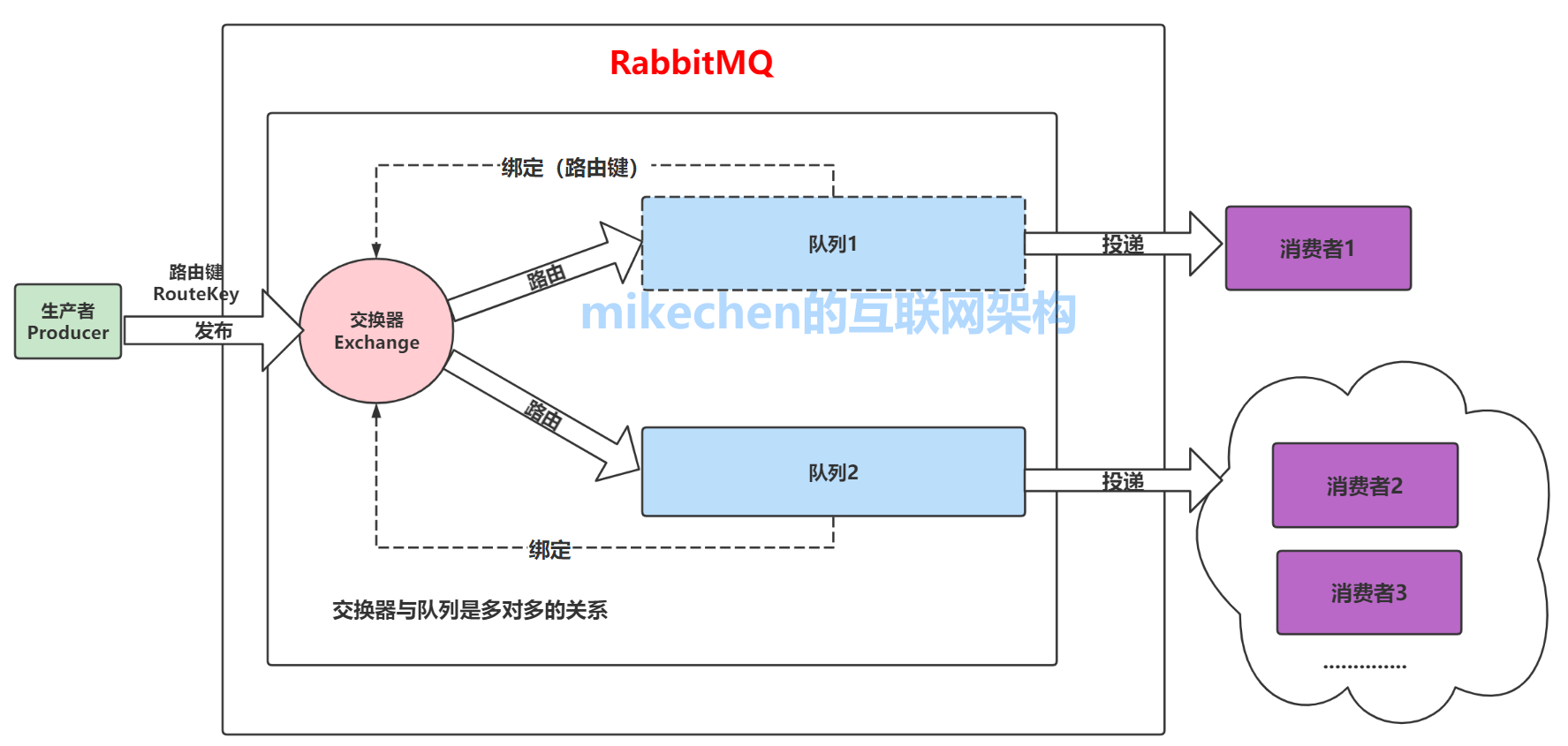
[消费者 (Consumer)] <--获取并消费--关键点在于"交换机"(Exchange)的引入 ,这是RabbitMQ区别于其他一些简单消息队列的精妙设计。生产者从不直接发送消息到队列 ,而是发送到交换机 ,并携带一个routing_key(路由键)。交换机则根据自身的类型 和与队列之间的绑定(Binding)规则,决定将消息投递到哪个(或哪些)队列。
这种设计的灵感来源于传统的邮政系统:你把信(消息)投入邮局(交换机),写上地址(routing_key),邮局内部根据地址分拣规则(绑定和交换机类型),将信分发到对应的邮箱(队列),最终由收件人(消费者)取走。
- 生产者(Producer):消息的创造者,负责创建消息并发送到交换机。
- 交换机(Exchange) :消息路由的决策中心,是逻辑组件,不存储消息。其类型(Direct, Topic, Fanout, Headers)决定了不同的路由算法。
- 队列(Queue) :消息的存储容器,本质是位于Broker上的缓冲区,等待消费者提取。消息在此持久化,确保Broker重启不丢失。
- 消费者(Consumer):消息的处理者,从队列中获取消息并进行业务处理。
- 绑定(Binding) :连接交换机与队列的规则 ,定义了什么样的消息(通过
routing_key匹配)应该进入哪个队列。
通过这套清晰的分层架构,RabbitMQ将复杂的消息路由逻辑从客户端剥离,集中到服务端的交换机处理,使得客户端设计更简单,同时获得了极高的路由灵活性。这正是它成为企业级异步通信基石的架构基础。
架构深度拆解:四大核心组件如何协同工作
理解了RabbitMQ作为消息代理的宏观定位后,我们必须深入其内部,剖析构成其消息流转骨架的四大核心组件。它们并非孤立存在,而是通过一套精密的协作机制,共同完成了从消息投递到消费的完整闭环。
交换机(Exchange):消息路由的决策中心与四大类型
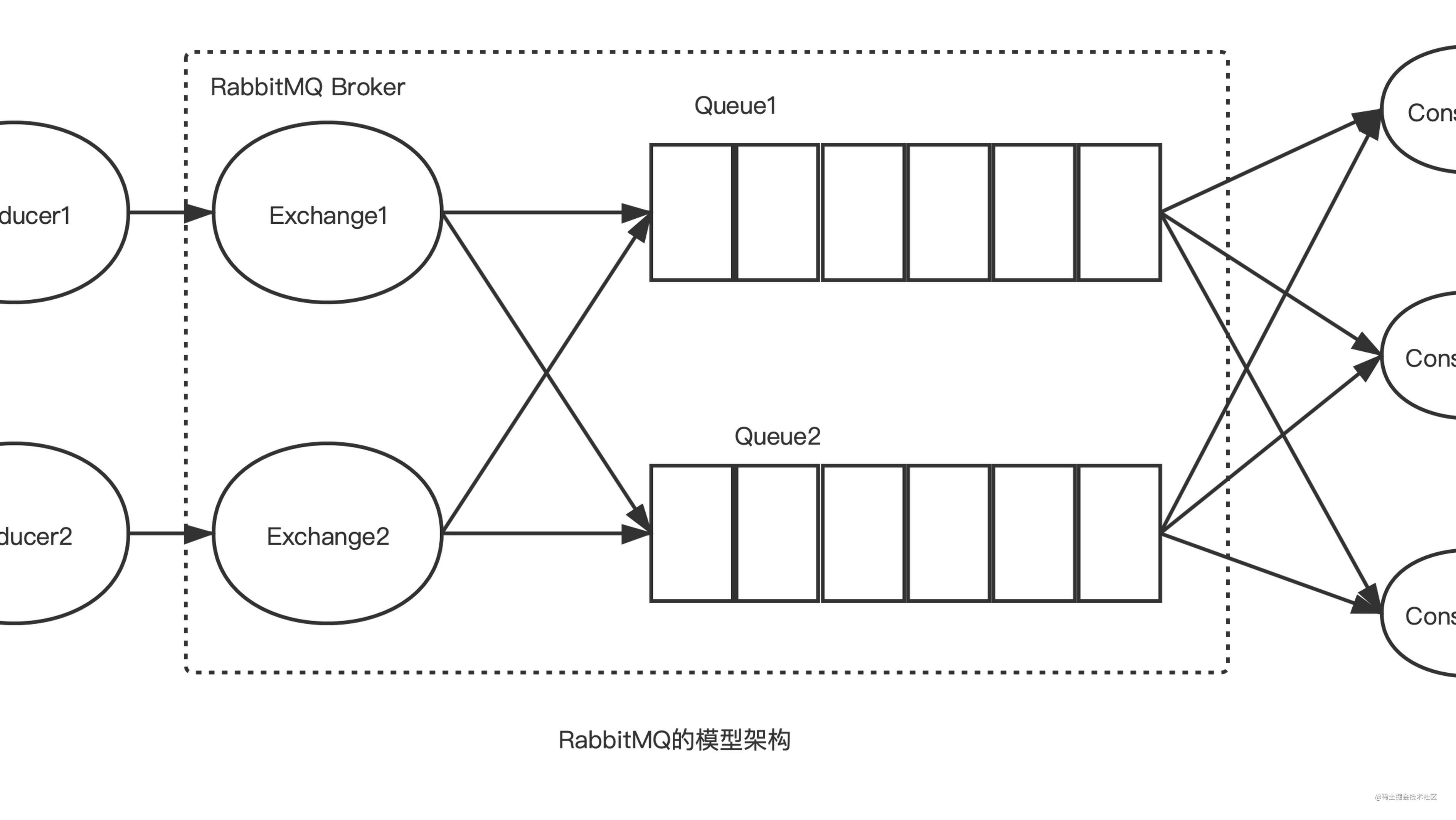
生产者发送消息时,并非直接投递给队列,而是首先发送到交换机(Exchange) 。这是RabbitMQ架构中最核心的设计,交换机本身不存储消息,其唯一职责是充当"路由决策中心" ,根据预定义的规则和消息携带的routing_key,决定将消息分发到哪些队列。
这种设计将复杂的路由逻辑从客户端剥离到服务端,实现了生产者和具体队列的彻底解耦。生产者只需关心"把消息发给哪个交换机、带什么标签",而"消息最终去哪"则由服务端根据绑定规则动态决定。根据路由策略的不同,RabbitMQ提供了四种交换机类型:
- Direct(直连) :一对一精确匹配 。消息只会被路由到
BindingKey与RoutingKey完全一致的队列。它常用于处理有明确指向性的任务,例如将"订单支付"消息精准路由到支付处理队列。 - Topic(主题) :基于模式匹配的灵活路由 。
RoutingKey和BindingKey都是由点号分隔的字符串,支持*(匹配一个单词)和#(匹配零个或多个单词)通配符。例如,BindingKey为*.error的队列能收到system.error的消息,这使其成为日志分类、事件通知等场景的理想选择。 - Fanout(扇出) :一对多广播 。它会将消息无条件地复制并路由到所有与其绑定的队列 ,完全忽略
RoutingKey。适用于需要将同一消息(如系统公告)分发给多个不同下游服务的场景。 - Headers(头部) :最不常用的一种类型 。它不依赖
RoutingKey,而是根据消息头(Headers)中的键值对进行匹配。虽然理论上更灵活,但配置复杂且性能较差,在实际生产中很少被采用。
交换机的核心价值在于,它将消息的"目的地"从静态的队列名,转变为动态的、可配置的路由规则,极大地提升了系统的灵活性和可维护性。
队列(Queue)与绑定(Binding):消息的存储容器与分发规则
如果说交换机是"智能交通枢纽",那么队列(Queue) 就是消息的"缓冲区"和"存储容器"。它是消息的最终落脚点,也是消费者拉取消息的唯一来源。每个队列都是独立的,消息在其中以FIFO(先进先出)的顺序被存储。
队列的核心作用是解耦消息的发送速率和处理速率。即使消费者暂时宕机或处理缓慢,消息也会安全地堆积在队列中,等待恢复后继续消费,从而实现"削峰填谷"。队列可以设置为持久化,以保障消息在服务器重启后不丢失。
然而,队列和交换机之间并非自动关联,这就需要绑定(Binding) 来建立连接。绑定是定义在交换机和队列之间的路由规则 ,它告诉RabbitMQ:"当消息到达这个交换机且满足某个条件时,请将其放入这个队列。" 绑定的关键要素是BindingKey(对于Fanout交换机可省略),它是与消息RoutingKey进行匹配的依据。
组件协同工作流可以概括为以下清晰步骤:
- 生产者 将消息发布到指定的交换机 ,并提供一个
RoutingKey。 - 交换机 接收到消息,根据自身的类型和所有与之建立的绑定规则,进行路由判断。
- 对于每一个匹配的绑定,消息会被复制 (对于Fanout/Topic)或转发 (对于Direct)到对应的队列中存储。
- 消费者订阅并监听特定的队列,从中获取并处理消息。
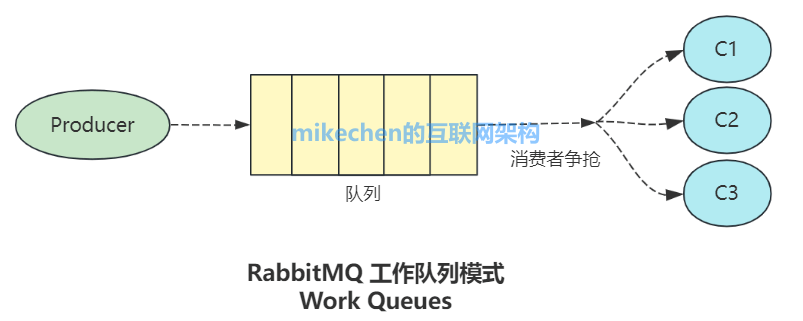
一个队列可以被多个消费者订阅 ,此时RabbitMQ默认采用轮询(Round-Robin) 的方式分发消息,实现负载均衡。但必须注意,RabbitMQ原生不支持队列层面的广播(即一条消息被所有消费者消费),这是其与Kafka等流式平台在设计目标上的一个显著区别。若需广播语义,必须借助Fanout交换机为每个消费者创建独立的队列来实现。
这种"交换机-绑定-队列"的三角模型,是RabbitMQ灵活性的基石,使其能够通过不同的组件组合,优雅地支撑从点对点通信到复杂事件分发的各类业务场景。
从发送到消费:一条消息的完整流转与可靠性保障
理解了RabbitMQ的静态组件后,其真正的价值在于动态的消息流转过程。一条消息从生产者发出,到被消费者成功处理,其旅程并非简单的"发送-接收",而是由一系列精心设计的机制保障其可靠性与高效性。
信道(Channel)与连接:高并发通信的关键设计
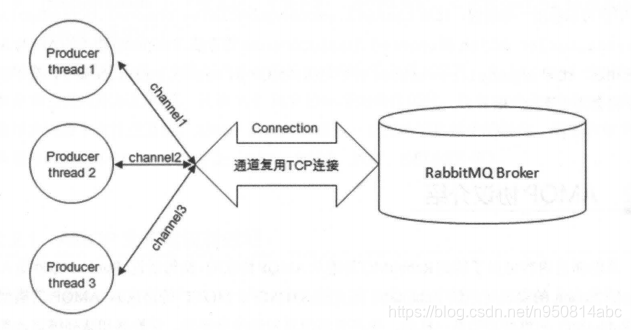
在RabbitMQ的通信模型中,TCP连接是昂贵的,而信道是轻量级的。这是其支撑高并发场景的核心设计。
一个应用程序与RabbitMQ服务器之间首先会建立一个TCP连接。如果每次发送或接收消息都直接操作这个TCP连接,频繁的创建、销毁和同步开销将是巨大的性能瓶颈。RabbitMQ的解决方案是引入信道(Channel)。
- 信道是建立在TCP连接之上的虚拟连接。一个TCP连接可以创建多个信道,所有具体的消息操作(如声明队列、发布消息、消费消息)都通过信道进行。
- 这种设计实现了连接复用。多个线程或进程可以共享同一个TCP连接,通过各自独立的信道进行通信,避免了频繁建立TCP连接的开销,极大地提升了通信效率。
- 信道是线程隔离的。每个信道都有自己的状态和通信流,确保了多线程环境下的操作安全。
简单来说,TCP连接是高速公路,而信道是高速公路上并行的多条车道。 应用程序通过一条"公路"接入RabbitMQ,然后在各自的"车道"上高效、安全地传输消息。
然而,这种设计也带来了新的复杂性。信道的生命周期管理、异常处理(如信道意外关闭导致未确认消息的处理)成为客户端实现时必须仔细考虑的问题。此外,虽然信道隔离了逻辑,但所有信道共享底层TCP连接的带宽,在极端高并发场景下,仍需关注连接本身的瓶颈。
消息确认(ACK)与持久化:防止消息丢失的底层逻辑
消息的可靠性贯穿于生产、存储、消费全链路。RabbitMQ通过一套组合机制来保障。
1. 生产端到Broker的可靠性
生产者并非将消息直接扔给Broker就结束。通过发布确认(Publisher Confirm)机制,生产者可以异步获知消息是否已被Broker成功接收并(可选地)持久化到磁盘。这是比事务机制性能更高的推荐方式。
2. Broker内部的存储可靠性
消息到达Broker后,其安全性依赖于持久化:
- 队列持久化:声明队列时设置为持久化,确保Broker重启后队列元数据不丢失。
- 消息持久化 :在发送消息时设置
deliveryMode=2,Broker会将其写入磁盘。RabbitMQ的消息存储设计巧妙,所有队列的持久化消息最终都顺序追加写入同一个底层存储文件,通过队列索引来维护消息与队列的映射关系。这种统一存储有利于磁盘顺序写,提升IO效率,但也意味着单个队列的读写性能会受到全局存储负载的影响。
3. 消费端的可靠性
这是最容易丢失消息的环节。RabbitMQ提供了两种ACK模式:
- 自动ACK :消息一旦被消费者获取,即被视为成功消费。如果消费者处理消息时崩溃,消息将永久丢失。
- 手动ACK:消费者在处理完消息后,必须显式发送ACK。如果消费者崩溃,Broker未收到ACK,会将消息重新投递给其他消费者(如果存在)或等待该消费者重连。
手动ACK配合QoS(服务质量)预取限制 ,是保证"至少成功消费一次"的标配。但这也引入了新问题:如果消费者处理成功但ACK发送失败,会导致消息被重复消费,业务层需要实现幂等性来应对。
缺陷与平衡 :绝对的可靠性往往以牺牲性能为代价。持久化带来磁盘IO开销,手动ACK增加了网络往返和复杂度。因此,架构师必须在消息的可靠性等级与系统吞吐量、延迟之间做出权衡。例如,对日志收集场景,允许少量丢失以换取极高吞吐;对支付订单消息,则必须启用全套持久化和确认机制。
最终,RabbitMQ的可靠性不是某个"银弹"功能,而是一套由生产者确认、消息/队列持久化、消费者手动ACK及死信队列(处理无法投递的消息)共同构成的防御体系,理解每道防线的作用与代价,是正确使用它的关键。