开发一款 AI 编程工具:从想法到实现
如何用 Gradio + Qwen3 + ChromaDB 构建一个类 Cursor 的 AI 代码编辑器?本文分享从架构设计到关键技术实现的完整过程。
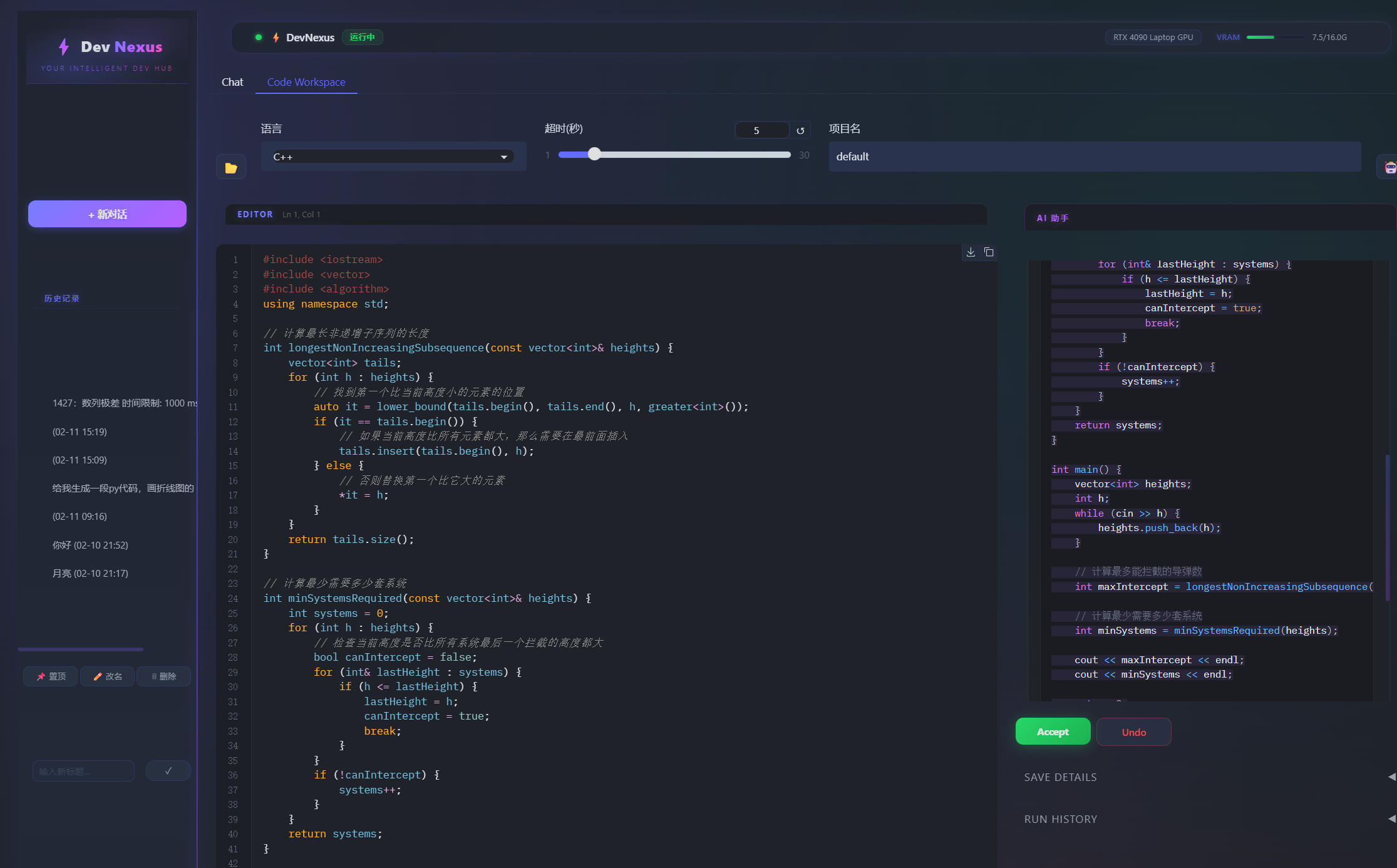
系统界面图
📖 前言
在 AI 编程助手日益普及的今天,GitHub Copilot、Cursor、Codeium 等工具已经改变了我们的编程方式。但作为一个开发者,我一直在思考:能否打造一个完全本地化、可定制的 AI 编程工具?
经过几个月的开发,我构建了 Code Workspace ------ 一个集成在 DevNexus 智能体系统中的 AI 代码编辑器。它不仅支持代码编辑、一键运行、AI 辅助,还具备代码记忆库 和个性化风格审阅等独特功能。
本文将分享这个项目的核心设计思路、技术架构和实现细节。(目前基于本地部署Qwen3 4b,未来用户可以自定义接api,实现高效编程)
🎯 为什么需要这个工具?
痛点分析
在开发过程中,我遇到了几个常见痛点:
1.上下文切换成本高:写代码 → 切换到终端运行 → 切换到 AI 聊天工具 → 再切回编辑器
2.代码记忆碎片化:写过的好代码散落在各处,难以复用和学习
3.AI 建议不够个性化:通用 AI 无法学习我的编码风格和习惯
4.算法刷题效率低:需要手动整理题目、测试用例,流程繁琐
设计目标
基于这些痛点,我设定了三个核心目标:
- ✅ 无缝集成:在 AI 对话系统中嵌入编辑器,无需切换窗口
- ✅ 智能记忆:代码自动向量化存储,支持语义检索和学习
- ✅ 个性化 AI:基于历史代码学习用户风格,提供个性化建议
🏗️ 系统架构
整体架构图
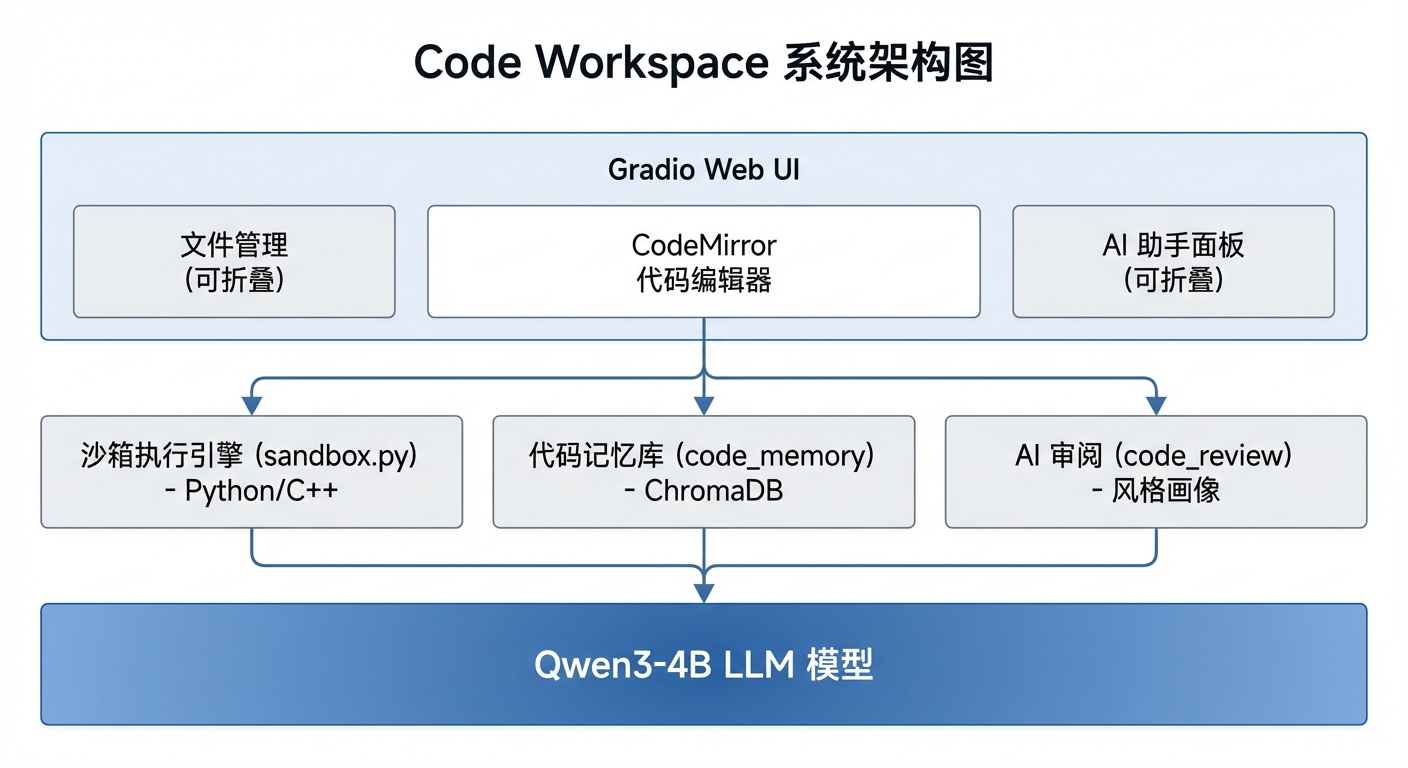
技术栈选择
| 组件 | 技术选型 | 理由 |
|---|---|---|
| 前端框架 | Gradio | 快速构建 Web UI,Python 原生,易于集成 |
| 代码编辑器 | CodeMirror | 轻量级、可定制、支持语法高亮 |
| 向量数据库 | ChromaDB | 轻量级、易部署、支持元数据过滤 |
| Embedding 模型 | Qwen3-Embedding-0.6B | 中文友好、小模型高效 |
| LLM | Qwen3-4B | 开源、支持思考模式、本地部署 |
🔧 核心技术实现
1. 沙箱执行引擎:安全隔离的代码运行
挑战:如何在 Web 环境中安全执行用户代码?
解决方案:独立的沙箱目录 + 超时控制 + 自动清理
python
@dataclass
class RunResult:
"""代码执行结果"""
run_id: str
language: str # "python" | "cpp"
source_code: str
stdout: str
stderr: str
exit_code: int
runtime_ms: float
success: bool
compile_exit_code: int # C++ only
compile_stderr: str # C++ only
def execute(code: str, language: str, stdin: str = "", timeout: int = 5) -> RunResult:
"""在隔离目录中执行代码"""
# 1. 创建唯一运行目录
run_id = str(uuid.uuid4())
run_dir = SANDBOX_DIR / f"run_{run_id}"
run_dir.mkdir(parents=True, exist_ok=True)
try:
if language == "python":
# Python: 直接解释执行
code_file = run_dir / "code.py"
code_file.write_text(code, encoding="utf-8")
start_time = time.time()
result = subprocess.run(
[PYTHON_EXE, str(code_file)],
input=stdin.encode("utf-8"),
capture_output=True,
timeout=timeout,
cwd=str(run_dir)
)
runtime_ms = (time.time() - start_time) * 1000
return RunResult(
run_id=run_id,
language="python",
source_code=code,
stdout=result.stdout.decode("utf-8", errors="replace"),
stderr=result.stderr.decode("utf-8", errors="replace"),
exit_code=result.returncode,
runtime_ms=runtime_ms,
success=result.returncode == 0
)
elif language == "cpp":
# C++: 编译 → 执行(两阶段)
cpp_file = run_dir / "code.cpp"
cpp_file.write_text(code, encoding="utf-8")
# 编译阶段
compile_result = subprocess.run(
["g++", "-std=c++17", str(cpp_file), "-o", str(run_dir / "code.exe")],
capture_output=True,
timeout=15,
cwd=str(run_dir)
)
if compile_result.returncode != 0:
return RunResult(
run_id=run_id,
language="cpp",
source_code=code,
stdout="",
stderr=compile_result.stderr.decode("utf-8", errors="replace"),
exit_code=-1,
runtime_ms=0,
success=False,
compile_exit_code=compile_result.returncode,
compile_stderr=compile_result.stderr.decode("utf-8", errors="replace")
)
# 执行阶段
start_time = time.time()
exec_result = subprocess.run(
[str(run_dir / "code.exe")],
input=stdin.encode("utf-8"),
capture_output=True,
timeout=timeout,
cwd=str(run_dir)
)
runtime_ms = (time.time() - start_time) * 1000
return RunResult(
run_id=run_id,
language="cpp",
source_code=code,
stdout=exec_result.stdout.decode("utf-8", errors="replace"),
stderr=exec_result.stderr.decode("utf-8", errors="replace"),
exit_code=exec_result.returncode,
runtime_ms=runtime_ms,
success=exec_result.returncode == 0,
compile_exit_code=0,
compile_stderr=""
)
finally:
# 延迟清理:保留运行目录 24 小时(用于调试)
pass关键设计点:
- UUID 隔离:每次运行创建唯一目录,避免冲突
- 超时控制:Python 5秒,C++ 编译15秒,执行5秒
- 编码兼容:UTF-8 / GBK 双编码,适配 Windows 环境
- 延迟清理:保留运行目录 24 小时,便于调试
2. 代码记忆库:让 AI 学习你的编码风格
挑战:如何让 AI 记住历史代码,并学习用户的编码风格?
解决方案:向量化存储 + 语义检索 + 风格画像
python
class CodeMemory:
"""代码记忆库:向量化存储代码,支持语义检索"""
def __init__(self, embedding_model=None):
self.embedding_model = embedding_model
# 与知识库共享 ChromaDB 实例
self.client = chromadb.PersistentClient(
path=str(Path("./knowledge_db") / "chroma_db")
)
self.collection = self.client.get_or_create_collection(
name="code_memory",
metadata={"hnsw:space": "cosine"}
)
def extract_code_structure(self, code: str, language: str) -> dict:
"""提取代码结构(函数名、类名、import)"""
structure = {
"functions": [],
"classes": [],
"imports": []
}
if language == "python":
# 提取函数定义
func_pattern = r"def\s+(\w+)\s*\("
structure["functions"] = re.findall(func_pattern, code)
# 提取类定义
class_pattern = r"class\s+(\w+)"
structure["classes"] = re.findall(class_pattern, code)
# 提取 import
import_pattern = r"(?:from\s+(\S+)\s+)?import\s+(\S+)"
imports = re.findall(import_pattern, code)
structure["imports"] = [f"{f} {i}" if f else i for f, i in imports]
return structure
def save(self, run_result: RunResult, project_name: str,
user_note: str, tags: list, auto_summary: bool = True):
"""保存代码到记忆库"""
code = run_result.source_code
lang = run_result.language
# 1. 提取代码结构
structure = self.extract_code_structure(code, lang)
# 2. 生成向量嵌入
embedding = self.embedding_model.encode_documents([code])[0]
embedding_list = embedding.numpy().tolist()
# 3. 构建元数据
doc_id = f"code_{run_result.run_id}"
metadata = {
"language": lang,
"project": project_name or "default",
"user_note": user_note,
"tags": ",".join(tags),
"functions": ",".join(structure["functions"]),
"classes": ",".join(structure["classes"]),
"imports": ",".join(structure["imports"]),
"success": str(run_result.success),
"runtime_ms": str(run_result.runtime_ms),
"timestamp": datetime.now().isoformat(),
"run_id": run_result.run_id
}
# 4. 存入 ChromaDB
self.collection.add(
ids=[doc_id],
embeddings=[embedding_list],
documents=[code],
metadatas=[metadata]
)
return doc_id
def search(self, query: str, top_k: int = 5,
project: str = None, language: str = None) -> list:
"""语义搜索代码"""
# 1. 编码查询
query_embedding = self.embedding_model.encode_query(query)
query_embedding_list = query_embedding.numpy().tolist()
# 2. 构建过滤条件
where = {}
if project:
where["project"] = project
if language:
where["language"] = language
# 3. 检索
results = self.collection.query(
query_embeddings=[query_embedding_list],
n_results=top_k,
where=where if where else None
)
# 4. 格式化结果
code_results = []
if results["documents"] and len(results["documents"][0]) > 0:
for doc, metadata, distance in zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0]
):
code_results.append({
"code": doc,
"score": 1 - distance,
"metadata": metadata or {}
})
return code_results存储的元数据:
- 代码结构:函数列表、类列表、import 列表
- 执行结果:stdout、stderr、exit_code、耗时
- 用户标注:备注、标签、项目名
- 时间戳:便于时间序列分析
3. AI 代码审阅:个性化风格学习
挑战:如何让 AI 审阅代码时考虑用户的编码风格?
解决方案:风格画像 + 历史代码检索 + 结构化审阅
python
class CodeReviewer:
"""AI 代码审阅:基于风格画像的个性化审阅"""
def __init__(self, chat_model_ref, code_memory=None):
self._chat_model_ref = chat_model_ref
self.code_memory = code_memory
self.style_profile_path = Path("./code_workspace/style_profile.json")
def _load_style_profile(self) -> str:
"""加载用户编码风格画像"""
if self.style_profile_path.exists():
try:
data = json.loads(self.style_profile_path.read_text(encoding="utf-8"))
return json.dumps(data, ensure_ascii=False, indent=2)
except Exception:
pass
return ""
def _generate_style_profile(self):
"""生成风格画像(每 20 次保存触发)"""
if not self.code_memory:
return
# 获取最近 30 次代码记录
recent_codes = self.code_memory.collection.get(
limit=30,
include=["documents", "metadatas"]
)
if len(recent_codes["documents"]) < 20:
return
# 构建 prompt
codes_sample = "\n\n---\n\n".join(recent_codes["documents"][:10])
prompt = f"""分析以下代码样本,总结用户的编码风格特征:
{codes_sample}
请从以下维度分析:
1. 命名习惯(驼峰/下划线/其他)
2. 注释风格和密度
3. 函数粒度偏好(长函数/短函数)
4. 常用库和工具
5. 常见问题和改进方向
输出 JSON 格式:
{{
"naming_style": "...",
"comment_density": "...",
"function_granularity": "...",
"common_libraries": [...],
"common_issues": [...],
"improvement_areas": [...]
}}"""
model = self.chat_model
if model:
try:
response = model.chat(
user_input=prompt,
system_prompt="你是代码风格分析专家,只输出 JSON 格式。",
enable_thinking=False,
temperature=0.3,
max_new_tokens=1024
)
# 解析并保存风格画像
profile = json.loads(response)
self.style_profile_path.write_text(
json.dumps(profile, ensure_ascii=False, indent=2),
encoding="utf-8"
)
except Exception as e:
print(f"[警告] 风格画像生成失败: {e}")
def review(self, code: str, language: str, run_result=None) -> dict:
"""执行代码审阅"""
model = self.chat_model
if not model:
return {"raw_review": "模型未加载"}
# 1. 检索相似历史代码
similar_runs = []
if self.code_memory:
query = f"[{language}] " + " ".join(
re.findall(r"(?:def|class|import)\s+(\w+)", code)[:10]
)
similar_runs = self.code_memory.search(query, top_k=5)
# 2. 加载风格画像
style_profile = self._load_style_profile()
# 3. 构建审阅 prompt
prompt = self._build_review_prompt(
code, language, run_result, similar_runs, style_profile
)
# 4. LLM 生成结构化审阅
raw = model.chat(
user_input=prompt,
system_prompt="你是代码审阅专家,只输出 JSON 格式的审阅结果。",
enable_thinking=False,
temperature=0.4,
max_new_tokens=2048
)
# 5. 解析 JSON 结果
return self._parse_review_output(raw)
def _build_review_prompt(self, code, language, run_result,
similar_runs, style_profile):
"""构建审阅 prompt"""
parts = []
# 风格画像上下文
if style_profile:
parts.append(f"【用户编码风格画像】\n{style_profile}\n")
# 相似历史代码
if similar_runs:
parts.append("【相似历史代码】")
for i, r in enumerate(similar_runs[:3], 1):
parts.append(f"\n{i}. {r['metadata'].get('project', 'unknown')}")
parts.append(r['code'][:200] + "...")
# 当前代码
parts.append(f"\n【待审阅代码】\n```{language}\n{code}\n```")
# 运行结果(如果有)
if run_result:
parts.append(f"\n【运行结果】")
if run_result.success:
parts.append(f"✅ 执行成功 ({run_result.runtime_ms:.1f}ms)")
else:
parts.append(f"❌ 执行失败")
parts.append(f"stderr: {run_result.stderr[:500]}")
# 审阅要求
parts.append("""
【审阅要求】
请从以下维度审阅代码,输出 JSON 格式:
{
"summary": "总体评价(1-2句话)",
"issues": [
{
"severity": "high|medium|low",
"type": "bug|style|performance|security",
"description": "问题描述",
"suggestion": "改进建议",
"line": 行号(可选)
}
],
"style_alignment": "与用户编码风格的符合度(高/中/低)",
"suggestions": ["优化建议1", "优化建议2"]
}""")
return "\n".join(parts)风格画像生成时机:
- 每保存 20 次代码时自动触发
- 分析最近 30 次代码记录
- 提取命名、注释、函数粒度等特征
- 生成 JSON 格式的风格画像
审阅流程:
- 检索相似历史代码(语义搜索)
- 加载用户风格画像
- 构建包含上下文的 prompt
- LLM 生成结构化审阅(JSON)
- 解析并展示结果
4. AI Agent 集成:深度绑定编辑器
挑战:如何让 AI 既能"看"代码,又能"改"代码?
解决方案:Ask 模式(只读) + Edit 模式(读写)
python
def _build_ai_prompt(code, language, run_result, problem_context,
user_instruction, mode="ask"):
"""构建 AI prompt(5 层上下文)"""
parts = []
# 1. 题目上下文(如果有)
if problem_context:
parts.append(f"【题目】\n{problem_context}\n")
# 2. 当前代码
parts.append(f"【代码】\n```{language}\n{code}\n```")
# 3. 运行输出(如果有)
if run_result:
parts.append(f"【运行输出】\nstdout:\n{run_result.stdout}\n")
if run_result.stderr:
parts.append(f"stderr:\n{run_result.stderr}\n")
# 4. 用户指令
parts.append(f"【用户指令】\n{user_instruction}\n")
# 5. 模式指令
if mode == "ask":
parts.append("【要求】请简洁回答用户问题,不要修改代码。")
elif mode == "edit":
parts.append("【要求】请返回完整的修改后的代码,使用 ```code```格式包裹。")
return "\n".join(parts)
def ai_ask_fn(code, language, run_result, problem_context, user_instruction):
"""Ask 模式:AI 只回答问题,不修改代码"""
prompt = _build_ai_prompt(code, language, run_result,
problem_context, user_instruction, mode="ask")
response = chat_model.stream_chat(
user_input=prompt,
enable_thinking=False,
temperature=0.7
)
# 流式返回,显示在右侧 AI 面板
for token in response:
yield token
def ai_edit_fn(code, language, run_result, problem_context, user_instruction):
"""Edit 模式:AI 生成新代码,直接覆写编辑器"""
prompt = _build_ai_prompt(code, language, run_result,
problem_context, user_instruction, mode="edit")
response = chat_model.chat(
user_input=prompt,
enable_thinking=False,
temperature=0.5
)
# 提取代码块
code_match = re.search(r"```(?:python|cpp)?\n(.*?)\n```", response, re.DOTALL)
if code_match:
new_code = code_match.group(1).strip()
# 保存原始代码到 State(用于 Undo)
original_code_state = code
# 返回新代码(覆写编辑器)
return new_code, original_code_state
return code, None # 未找到代码块,不修改两种模式对比:
| 模式 | 用途 | 输出位置 | 是否修改代码 |
|---|---|---|---|
| Ask | 解释代码、回答问题 | 右侧 AI 面板 | ❌ |
| Edit | 修复 Bug、优化代码 | 直接覆写编辑器 | ✅ |
🎨 界面设计
三栏可折叠布局
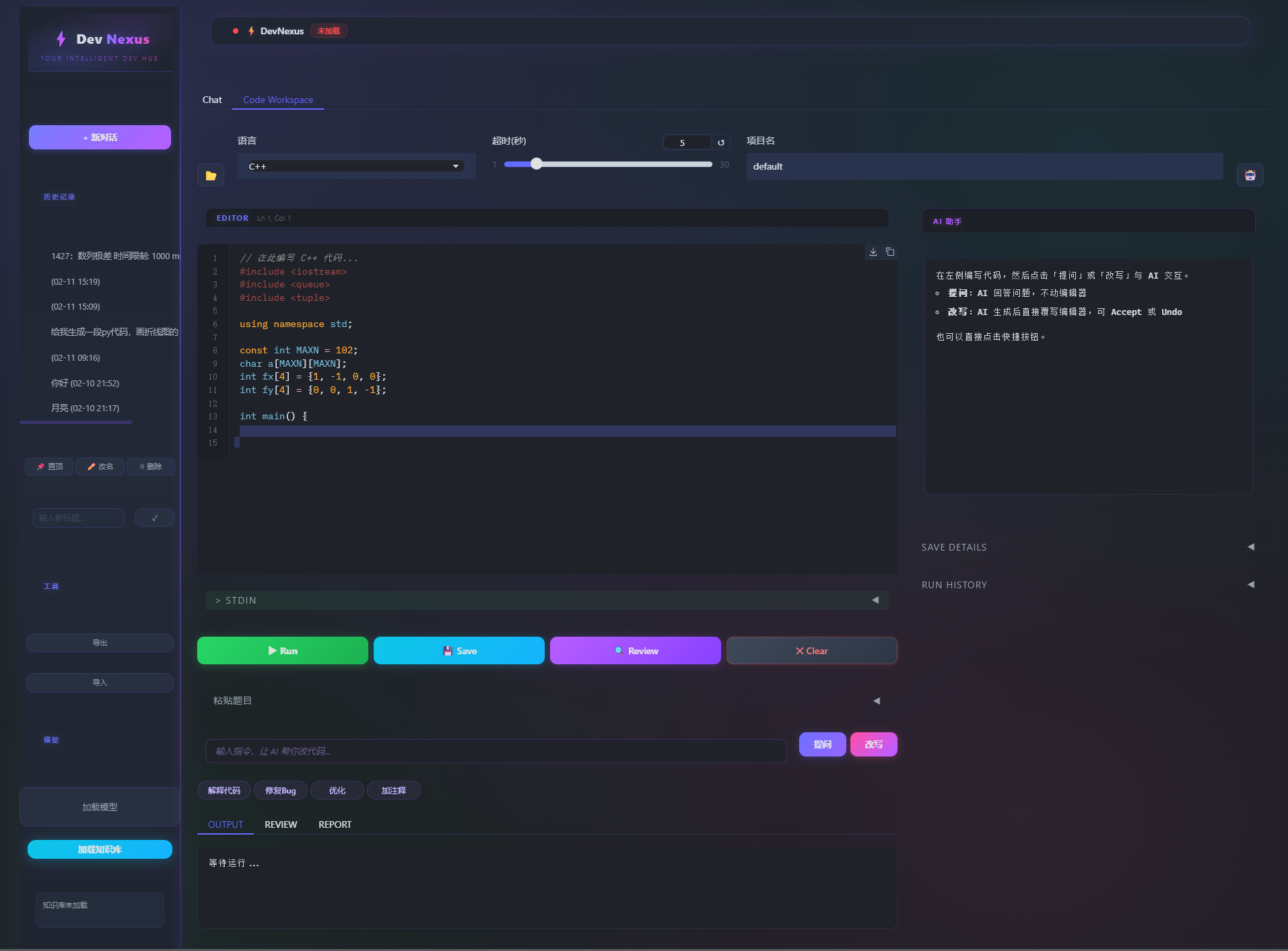
核心 UI 组件
-
CodeMirror 编辑器
- Python / C++ 语法高亮
- 注释高亮(亮橙色 #F59E0B)
- 自动语言识别
-
文件管理器
- 浏览目录、打开文件
- 自动识别语言并切换编辑器模式
- 保存文件到磁盘
-
AI 助手面板
- 流式显示 AI 回复
- Accept / Undo 按钮(Edit 模式)
- 保存详情和历史记录
-
终端输出
- OUTPUT:运行结果(stdout/stderr)
- REVIEW:代码审阅报告
- REPORT:项目统计报告
💡 关键技术亮点
1. 题目整理 Agent
场景:从 LeetCode / OJ 复制题目,格式混乱
解决方案:LLM 整理为标准格式,自动插入编辑器
python
def organize_problem_fn(raw_text):
"""整理算法题目"""
prompt = f"""整理以下算法题目,提取关键信息:
{raw_text}
输出格式:
题目名称:[名称]
题目描述:[描述]
输入格式:[格式]
输出格式:[格式]
示例:
输入:
[示例输入]
输出:
[示例输出]
约束条件:
[约束]
请以注释形式输出,便于插入代码编辑器。"""
response = chat_model.chat(
user_input=prompt,
enable_thinking=False,
temperature=0.3
)
# 转为注释块
comment_block = f"/*\n{response}\n*/" if language == "cpp" else f'"""\n{response}\n"""'
# 插入编辑器顶部
return comment_block + "\n\n" + current_code2. 快捷指令系统
预设常用指令,一键触发:
- 解释代码 :
"请解释这段代码的功能和逻辑" - 修复 Bug :
"修复代码中的 bug,确保能正常运行" - 优化代码 :
"优化代码性能,保持功能不变" - 添加注释 :
"为代码添加详细注释"
3. 项目报告生成
统计运行历史、成功率、语言分布,AI 分析趋势:
python
class CodeReporter:
def generate_report(self, project_name=None):
"""生成项目报告"""
# 1. 基础统计
stats = self.memory.get_stats(project_name)
# 2. AI 趋势分析
prompt = f"""分析以下代码统计数据,给出趋势分析和改进建议:
运行次数:{stats['total_runs']}
成功率:{stats['success_rate']:.1%}
语言分布:{stats['language_dist']}
平均耗时:{stats['avg_runtime_ms']:.1f}ms
请分析:
1. 近期编程模式
2. 常见问题类型
3. 改进方向建议"""
ai_analysis = self.chat_model.chat(
user_input=prompt,
enable_thinking=False,
temperature=0.5
)
# 3. 生成 Markdown 报告
report = f"""# 项目报告:{project_name or '全部项目'}
## 基础统计
- 运行次数:{stats['total_runs']}
- 成功率:{stats['success_rate']:.1%}
- 语言分布:{stats['language_dist']}
- 平均耗时:{stats['avg_runtime_ms']:.1f}ms
## AI 趋势分析
{ai_analysis}
"""
return report🚀 使用场景
场景 1:算法刷题
1. 从 OJ 网站复制题目 → 粘贴到「粘贴题目」区 → 点「整理题目」
2. AI 整理后自动以注释形式插入编辑器顶部
3. 在注释下方编写解题代码
4. 填入测试用例到 STDIN → 点 ▶ Run → 查看 OUTPUT
5. 遇到 bug → 点「修复Bug」→ AI 自动改写 → Accept / Undo
6. 通过后 → 点 💾 Save 保存到记忆库场景 2:日常编程
1. 点 📂 打开文件面板 → 导航到项目目录 → 点击文件加载
2. 编辑代码 → ▶ Run 测试
3. 对某段逻辑不确定 → 选「提问」让 AI 解释
4. 需要重构 → 输入指令 → 点「改写」→ AI 生成 → Accept
5. 点「保存到文件」写回磁盘场景 3:代码复盘
1. 点 🔍 Review → AI 生成结构化审阅(bug/风格/建议)
2. 在 REPORT tab 点「生成报告」→ 查看历史统计和趋势
3. 系统每 20 次保存自动更新你的编码风格画像📊 项目数据
- 开发时间:3 个月
- 代码行数:~2000 行 Python
- 核心模块:4 个(sandbox、memory、review、report)
- 支持语言:Python、C++
- 存储代码数:1000+(测试数据)
🎓 经验总结
成功经验
- 渐进式开发:先实现核心功能,再逐步完善
- 用户反馈驱动:根据实际使用场景优化功能
- 技术选型合理:Gradio + ChromaDB 快速迭代
遇到的挑战
-
沙箱安全:初期未考虑超时,导致死循环卡死
- 解决:添加超时控制和自动清理
-
编码问题:Windows 环境下 GBK 编码导致乱码
- 解决:UTF-8 / GBK 双编码兼容
-
风格画像生成:初期效果不理想
- 解决:增加样本数量,优化 prompt
技术债务
- 错误处理:部分异常处理不够完善
- 性能优化:大量代码时的检索速度需要优化
- 测试覆盖:单元测试覆盖率较低
📚 参考资源
🙏 致谢
感谢 Qwen 团队提供的优秀开源模型,以及 Gradio、ChromaDB 等开源项目的支持。
作者 :Brain-coder
日期 :2026-02-11
项目:DevNexus --- Your Intelligent Dev Hub
💡 提示:本文档提供了完整的开发思路和技术实现,读者可以根据自己的需求进行调整和扩展。如有问题,欢迎交流讨论。