系列内容:OpenCV概述与环境配置,OpenCV基础知识和绘制图形,图像的算数与位运算,图像视频的加载和显示,图像基本变换,滤波器,形态学,图像轮廓,图像直方图,车辆统计项目,特征检测和匹配,图像查找和拼接,虚拟计算器项目,信用卡识别项目,图像的分割与修复,人脸检测与车牌识别,目标追踪,答题卡识别判卷与文档ocr扫描识别,光流估计
(一)目标追踪介绍
目标追踪综述
1.目标跟踪简介
目标跟踪是计算机视觉领域的一个重要问题,目前广泛应用在体育赛事转播、安防监控和无人机、无人车、机器人等领域.
2.目标跟踪任务分类
目标跟踪可以分为以下几种任务:
- (1)单目标跟踪 - 给定一个目标,追踪这个目标的位置。
- (2)多目标跟踪 - 追踪多个目标的位置
- (3)Person Re-ID - 行人重识别,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。旨在弥补固定的摄像头的视觉局限,并可与行人检测/行人跟踪技术相结合。
- (4)MTMCT - 多目标多摄像头跟踪(Multi-target Multi-camera Tracking),跟踪多个摄像头拍摄的多个人
姿态跟踪 - 追踪人的姿态
按照任务计算类型又可以分为以下2类。
- (1)在线跟踪 - 在线跟踪需要实时处理任务,通过过去和现在帧来跟踪未来帧中物体的位置。
- (2)离线跟踪 - 离线跟踪是离线处理任务,可以通过过去、现在和未来的帧来推断物体的位置,因此准确率会在线跟踪高。
3.目标跟踪的困难点
虽然目标追踪的应用前景非常广泛,但还是有一些问题限制了它的应用:
- 形态变化 - 姿态变化是目标跟踪中常见的干扰问题。运动目标发生姿态变化时, 会导致它的特征以及外观模型发生改变, 容易导致跟踪失败。例如:体育比赛中的运动员、马路上的行人。
- 尺度变化 - 尺度的自适应也是目标跟踪中的关键问题。当目标尺度缩小时, 由于跟踪框不能自适应跟踪, 会将很多背景信息包含在内, 导致目标模型的更新错误:当目标尺度增大时, 由于跟踪框不能将目标完全包括在内, 跟踪框内目标信息不全, 也会导致目标模型的更新错误。因此, 实现尺度自适应跟踪是十分必要的。
- 遮挡与消失 - 目标在运动过程中可能出现被遮挡或者短暂的消失情况。当这种情况发生时, 跟踪框容易将遮挡物以及背景信息包含在跟踪框内, 会导致后续帧中的跟踪目标漂移到遮挡物上面。若目标被完全遮挡时, 由于找不到目标的对应模型, 会导致跟踪失败。
- 图像模糊 - 光照强度变化, 目标快速运动, 低分辨率等情况会导致图像模型, 尤其是在运动目标与背景相似的情况下更为明显。因此, 选择有效的特征对目标和背景进行区分非常必要。
4.目标跟踪方法
既然目标跟踪领域有这么多困难,那么我们采用什么样的方法来进行目标跟踪呢?目标跟踪的方法按照模式划分可以分为2类。
- (1)生成式模型 - 早期的工作主要集中于生成式模型跟踪算法的研究, 如光流法23-24、粒子滤波8、Meanshift算法9-10、Camshift11算法等.此类方法首先建立目标模型或者提取目标特征, 在后续帧中进行相似特征搜索.逐步迭代实现目标定位.但是这类方法也存在明显的缺点, 就是图像的背景信息没有得到全面的利用.且目标本身的外观变化有随机性和多样性特点, 因此, 通过单一的数学模型描述待跟踪目标具有很大的局限性.具体表现为在光照变化, 运动模糊, 分辨率低, 目标旋转形变等情况下, 模型的建立会受到巨大的影响, 从而影响跟踪的准确性; 模型的建立没有有效地预测机制, 当出现目标遮挡情况时, 不能够很好地解决。
- (2)鉴别式模型 - 鉴别式模型是指, 将目标模型和背景信息同时考虑在内, 通过对比目标模型和背景信息的差异, 将目标模型提取出来, 从而得到当前帧中的目标位置.文献在对跟踪算法的评估中发现25, 通过将背景信息引入跟踪模型, 可以很好地实现目标跟踪.因此鉴别式模型具有很大的优势. 2000年以来, 人们逐渐尝试使用经典的机器学习方法训练分类器, 例如MIL26、TLD27、支持向量机28、结构化学习29、随机森林30、多实例学习31、度量学习32. 2010年, 文献12首次将通信领域的相关滤波方法引入到目标跟踪中.作为鉴别式方法的一种, 相关滤波无论在速度上还是准确率上, 都显示出更优越的性能.然而, 相关滤波器用于目标跟踪是在2014年之后.自2015年以后, 随着深度学习技术的广泛应用, 人们开始将深度学习技术用于目标跟踪。
按照时间顺序,目标跟踪的方法经历了从经典算法到基于核相关滤波算法,再到基于深度学习的跟踪算法的过程。
- 经典跟踪算法
- 基于核相关滤波的跟踪算法
- 基于深度学习的跟踪算法
5.经典跟踪算法
早期的目标跟踪算法主要是根据目标建模或者对目标特征进行跟踪。
基于目标模型建模的方法 通过对目标外观模型进行建模, 然后在之后的帧中找到目标.例如, 区域匹配、特征点跟踪、基于主动轮廓的跟踪算法、光流法等.最常用的是特征匹配法, 首先提取目标特征, 然后在后续的帧中找到最相似的特征进行目标定位, 常用的特征有: SIFT3特征、SURF4特征、Harris角点5等。
基于搜索的方法 随着研究的深入, 人们发现基于目标模型建模的方法6对整张图片进行处理, 实时性差.人们将预测算法加入跟踪中, 在预测值附近进行目标搜索, 减少了搜索的范围.常见一类的预测算法有Kalman7滤波、粒子滤波8方法.另一种减小搜索范围的方法是内核方法:运用最速下降法的原理, 向梯度下降方向对目标模板逐步迭代, 直到迭代到最优位置.诸如, Meanshift9-10、Camshift11算法
- (1)光流法:
光流法(Lucas-Kanade)的概念首先在1950年提出, 它是针对外观模型对视频序列中的像素进行操作.通过利用视频序列在相邻帧之间的像素关系, 寻找像素的位移变化来判断目标的运动状态, 实现对运动目标的跟踪.但是, 光流法适用的范围较小, 需要满足三种假设:图像的光照强度保持不变; 空间一致性, 即每个像素在不同帧中相邻点的位置不变, 这样便于求得最终的运动矢量; 时间连续.光流法适用于目标运动相对于帧率是缓慢的, 也就是两帧之间的目标位移不能太大。
- (2)Meanshift:
Meanshift 方法是一种基于概率密度分布的跟踪方法,使目标的搜索一直沿着概率梯度上升的方向,迭代收敛到概率密度分布的局部峰值上。首先 Meanshift 会对目标进行建模,比如利用目标的颜色分布来描述目标,然后计算目标在下一帧图像上的概率分布,从而迭代得到局部最密集的区域。Meanshift 适用于目标的色彩模型和背景差异比较大的情形,早期也用于人脸跟踪。由于 Meanshift 方法的快速计算,它的很多改进方法也一直适用至今。
- (3)粒子滤波:
粒子滤波(Particle Filter)方法是一种基于粒子分布统计的方法。以跟踪为例,首先对跟踪目标进行建模,并定义一种相似度度量确定粒子与目标的匹配程度。在目标搜索的过程中,它会按照一定的分布(比如均匀分布或高斯分布)撒一些粒子,统计这些粒子的相似度,确定目标可能的位置。在这些位置上,下一帧加入更多新的粒子,确保在更大概率上跟踪上目标。Kalman Filter 常被用于描述目标的运动模型,它不对目标的特征建模,而是对目标的运动模型进行了建模,常用于估计目标在下一帧的位置。
可以看到,传统的目标跟踪算法存在两个致命的缺陷:
没有将背景信息考虑在内, 导致在目标遮挡, 光照变化以及运动模糊等干扰下容易出现跟踪失败.
跟踪算法执行速度慢(每秒10帧左右), 无法满足实时性的要求
6.基于核相关滤波的跟踪算法
接着,人们将通信领域的相关滤波(衡量两个信号的相似程度)引入到了目标跟踪中。一些基于相关滤波的跟踪算法(MOSSE12、CSK13、KCF14、BACF15、SAMF16)等, 也随之产生, 速度可以达到数百帧每秒, 可以广泛地应用于实时跟踪系统中.其中不乏一些跟踪性能优良的跟踪器, 诸如SAMF、BACF在OTB17数据集和VOT201518竞赛中取得优异成绩。
7.基于深度学习的跟踪算法
随着深度学习方法的广泛应用, 人们开始考虑将其应用到目标跟踪中71.人们开始使用深度特征并取得了很好的效果.之后, 人们开始考虑用深度学习建立全新的跟踪框架, 进行目标跟踪。在大数据背景下,利用深度学习训练网络模型,得到的卷积特征输出表达能力更强。在目标跟踪上,初期的应用方式是把网络学习到的特征,直接应用到相关滤波或 Struck 的跟踪框架里面,从而得到更好的跟踪结果,比如前面提到的 DeepSRDCF 方法。本质上卷积输出得到的特征表达,更优于 HOG 或 CN 特征,这也是深度学习的优势之一,但同时也带来了计算量的增加。
8.目标跟踪方法总结
目标跟踪的方法主要分为2大类,一类是相关滤波、一类是深度学习。
相比于光流法、Kalman、Meanshift等传统算法,相关滤波类算法跟踪速度更快,深度学习类方法精度高;
具有多特征融合以及深度特征的追踪器在跟踪精度方面的效果更好;
使用强大的分类器是实现良好跟踪的基础;
尺度的自适应以及模型的更新机制也影响着跟踪的精度。
10.数据集
主要的数据集数据对比,结果如图17.1所示:
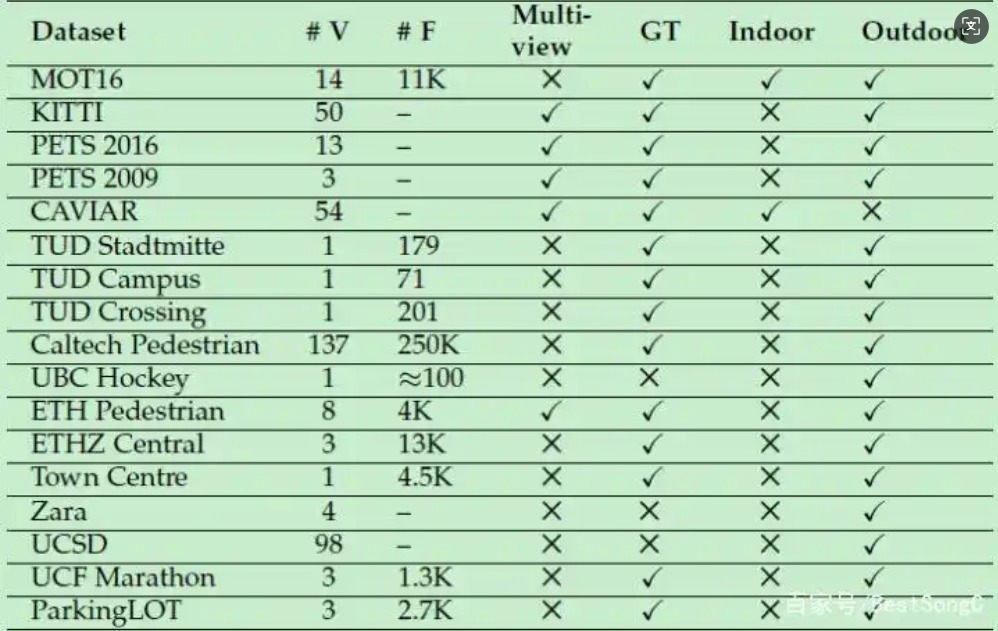 17.1-目标追踪数据集
17.1-目标追踪数据集
(二)OpenCV目标追踪算法介绍
OpenCV目标追踪算法介绍:
OpenCV上有八种不同的目标追踪算法.
- BOOSTING Tracker: 和Haar cascades (AdaBoost) 背后所用的机器学习算法相同,但是距其诞生已有十多年了。这一追踪器速度较慢,并且表现不好。(最低支持OpenCV 3.0.0)
- MIL Tracker: 比上一个追踪器更精确,但是失败率比较高。(最低支持OpenCV 3.0.0)
- KCF Tracker: 比BOOSTING和MIL都快,但是在有遮挡的情况下表现不佳。(最低支持OpenCV 3.1.0)
- CSRT Tracker: 比KCF稍精确,但速度不如后者。(最低支持OpenCV 3.4.2)
- MedianFlow Tracker: 出色的跟踪故障报告。当运动是可预测的并且没有遮挡时,效果非常好,但是对于快速跳动或快速移动的物体,模型会失效。(最低支持OpenCV 3.0.0)
- TLD Tracker: 在多帧遮挡下效果最好。但是TLD的误报非常多,所以不推荐。(最低支持OpenCV 3.0.0)
- MOSSE Tracker: 速度真心快,但是不如CSRT和KCF的准确率那么高,如果追求速度选它准没错。(最低支持OpenCV 3.4.1)
- GOTURN Tracker: 这是OpenCV中唯一一深度学习为基础的目标检测器。它需要额外的模型才能运行。(最低支持OpenCV 3.2.0)
(三)目标追踪实战
OpenCV目标跟踪算法的使用大概可以分为以下几个步骤:
- (1)创建MultiTracker对象.
- (2)读取视频或摄像头数据.
- (3)框选ROI区域.
- (4)给MultiTracker对象添加实际的追踪算法.
- (5)对每一帧进行目标追踪.
示例代码:
1.jupyter notebook:
python
import cv2
import argparse
# ap=argparse.ArgumentParser()
# ap.add_argument('-v','--video',type=str,help='path to input video file')
# ap.add_argument('-t','--tracker',type=str,default='kef',help='OpenCV object tracker type')
# args=vars(ap.parse_args())
#MultiTracker_create以及以后的一些目标追踪算法在opencv4.5以后换了地方
#cv2.legacy.MultiTracker_create
#定义OPenCV中的七种目标追踪算法
OPENCV_OBJECT_TRACKERS={
'boosting':cv2.TrackerBoosting_create,
'csrt':cv2.TrackerCSRT_create,
'kef':cv2.TrackerKCF_create,
'mil':cv2.TrackerMIL_create,
'tid':cv2.TrackerTLD_create,
'medianflow':cv2.TrackerMedianFlow_create,
'mosse':cv2.TrackerMOSSE_create
}
trackers=cv2.MultiTracker_create()
cap=cv2.VideoCapture('./vehicles.mp4')
while True:
flag,frame=cap.read()
if frame is None:
break
#变成黑白的
# gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
#追踪目标
success,boxes=trackers.update(frame)
#绘制追踪到的矩形区域
for box in boxes:
#box是给浮点数,画图需要整理
(x,y,w,h)=[int(v) for v in box]
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow('frame',frame)
key=cv2.waitKey(100)
if key==ord('s'):
#框选ROI区域
roi=cv2.selectROI('frame',frame,showCrosshair=True,fromCenter=False)
# print(roi)
#创建一个实际的目标追踪器
tracker=OPENCV_OBJECT_TRACKERS['kef']()
trackers.add(tracker,frame,roi)
elif key==27:
break
cap.release()
cv2.destroyAllWindows()运行结果,结果如图17.2和图17.3所示:
 17.2-目标追踪检测(1)
17.2-目标追踪检测(1)  17.3-目标追踪检测(2)
17.3-目标追踪检测(2)
python
import cv2
import argparse
ap=argparse.ArgumentParser()
ap.add_argument('-v','--video',type=str,help='path to input video file')
ap.add_argument('-t','--tracker',type=str,default='kef',help='OpenCV object tracker type')
args=vars(ap.parse_args())
#MultiTracker_create以及以后的一些目标追踪算法在opencv4.5以后换了地方
#cv2.legacy.MultiTracker_create
#定义OPenCV中的七种目标追踪算法
OPENCV_OBJECT_TRACKERS={
'boosting':cv2.TrackerBoosting_create,
'csrt':cv2.TrackerCSRT_create,
'kef':cv2.TrackerKCF_create,
'mil':cv2.TrackerMIL_create,
'tid':cv2.TrackerTLD_create,
'medianflow':cv2.TrackerMedianFlow_create,
'mosse':cv2.TrackerMOSSE_create
}
trackers=cv2.MultiTracker_create()
cap=cv2.VideoCapture('./vehicles.mp4')
while True:
flag,frame=cap.read()
if frame is None:
break
#变成黑白的
# gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
#追踪目标
success,boxes=trackers.update(frame)
#绘制追踪到的矩形区域
for box in boxes:
#box是给浮点数,画图需要整理
(x,y,w,h)=[int(v) for v in box]
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow('frame',frame)
key=cv2.waitKey(100)
if key==ord('s'):
#框选ROI区域
roi=cv2.selectROI('frame',frame,showCrosshair=True,fromCenter=False)
# print(roi)
#创建一个实际的目标追踪器
tracker=OPENCV_OBJECT_TRACKERS['kef']()
trackers.add(tracker,frame,roi)
elif key==27:
break
cap.release()
cv2.destroyAllWindows()(四)OpenCV中使用深度学习模型
扩展:OpenCV与深度学习结合
1.通过OpenCV中的DNN包,就可以在OpenCV中实现深度学习中训练好的模型:
- cv2.dnn.readNet
- cv2.dnn.readNetFromCaffe
- cv2.dnn.readNetFromDarknet
- cv2.dnnreadNetFromTensorflow
- cv2.dnn.readNetFromTorch
- cv2.readTorchBlob
2.把图片变成tensor
cv2.dnn.blobFromImage()
3.基本流程:
net=cv2.dnn.readNetFromCaffe()
把图片变成tensor
blob=cv2.dnn.blobFromImage(img)
把图片给到网络进行预
net.setInput(blob)
预测
net.forward()
示例代码(金毛狗和拉布拉多犬):
python
#OpenCV和深度学习结合
config='./bvlc_googlenet.prototxt'
model='./bvlc_googlenet.caffemodel'
import cv2
import numpy as np
net=cv2.dnn.readNetFromCaffe(config,model)
#读图片(金毛狗和拉布拉多犬)
img=cv2.imread('./dog.jpg')
# img=cv2.imread('./dog1.jpg')
#转化为tensor
blob=cv2.dnn.blobFromImage(img,1.0,(224,224),(104,117,123))
net.setInput(blob)
r=net.forward()
# print(r)
#返回的是属于1000个物体的概率
print(r.shape)
#希望看一下概率前三的是社么物体
#读类别
classes=[]
with open('./synset_words.txt','r') as fp:
#返回找到字符串的索引
classes=[x[x.find(' ')+1:] for x in fp]
# print(classes)
#对得到的结果排序
order=sorted(r[0],reverse=True)
#只要前三的概率
z=list(range(3))
for i in range(3):
#返回的是满足条件的索引
z[i]=np.where(r[0]==order[i])[0][0]
print('第',i+1,'项匹配',classes[z[i]],end='')
print('类所在行:',z[i]+1,' ','可能性:',order[i])金毛犬如图17.4,拉布拉多犬图17.5所示:
 17.4-金毛犬
17.4-金毛犬  17.5-拉布拉多犬
17.5-拉布拉多犬
(1)金毛狗深度学习匹配结果:
python
(1, 1000)
第 1 项匹配 golden retriever
类所在行: 208 可能性: 0.8343014
第 2 项匹配 Labrador retriever
类所在行: 209 可能性: 0.028573554
第 3 项匹配 clumber, clumber spaniel
类所在行: 217 可能性: 0.026441319(2)拉布拉多犬匹配结果:
python
(1, 1000)
第 1 项匹配 Labrador retriever
类所在行: 209 可能性: 0.9073125
第 2 项匹配 American Staffordshire terrier, Staffordshire terrier, American pit bull terrier, pit bull terrier
类所在行: 181 可能性: 0.031111853
第 3 项匹配 golden retriever
类所在行: 208 可能性: 0.009617143