【VLN】VLN Paradigm Alg:Reinforcement learning 强化学习及其细节(4)
-
- [1. 强化学习图示及其定义](#1. 强化学习图示及其定义)
- [2. 监督学习、无监督学习、强化学习对比](#2. 监督学习、无监督学习、强化学习对比)
- [3. Comparison between RL and Supervised Learning](#3. Comparison between RL and Supervised Learning)
-
- [3.1 回报(Return)](#3.1 回报(Return))
- [3.3 折扣回报(Discounted Returns)](#3.3 折扣回报(Discounted Returns))
- [3.4 回报中的随机性(观测视角)](#3.4 回报中的随机性(观测视角))
- [3.5 观测到的折扣回报](#3.5 观测到的折扣回报)
- [3.6 回报中的随机性(理论视角)](#3.6 回报中的随机性(理论视角))
1. 强化学习图示及其定义
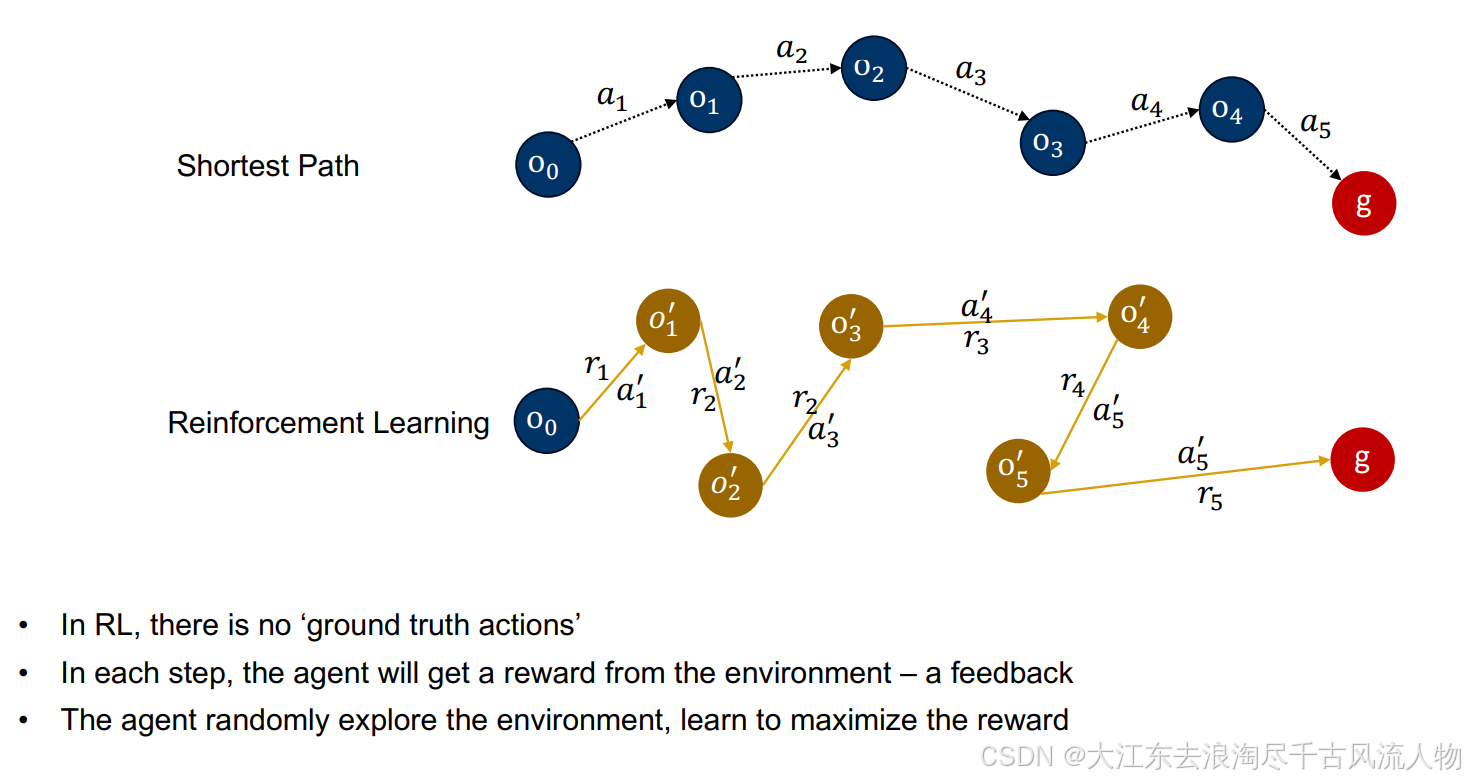
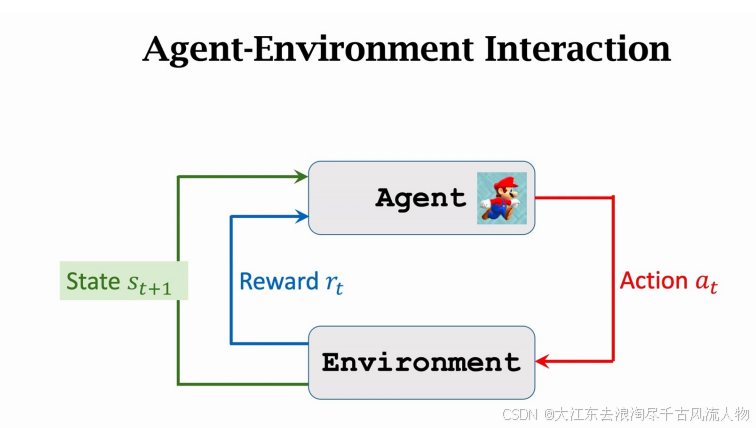
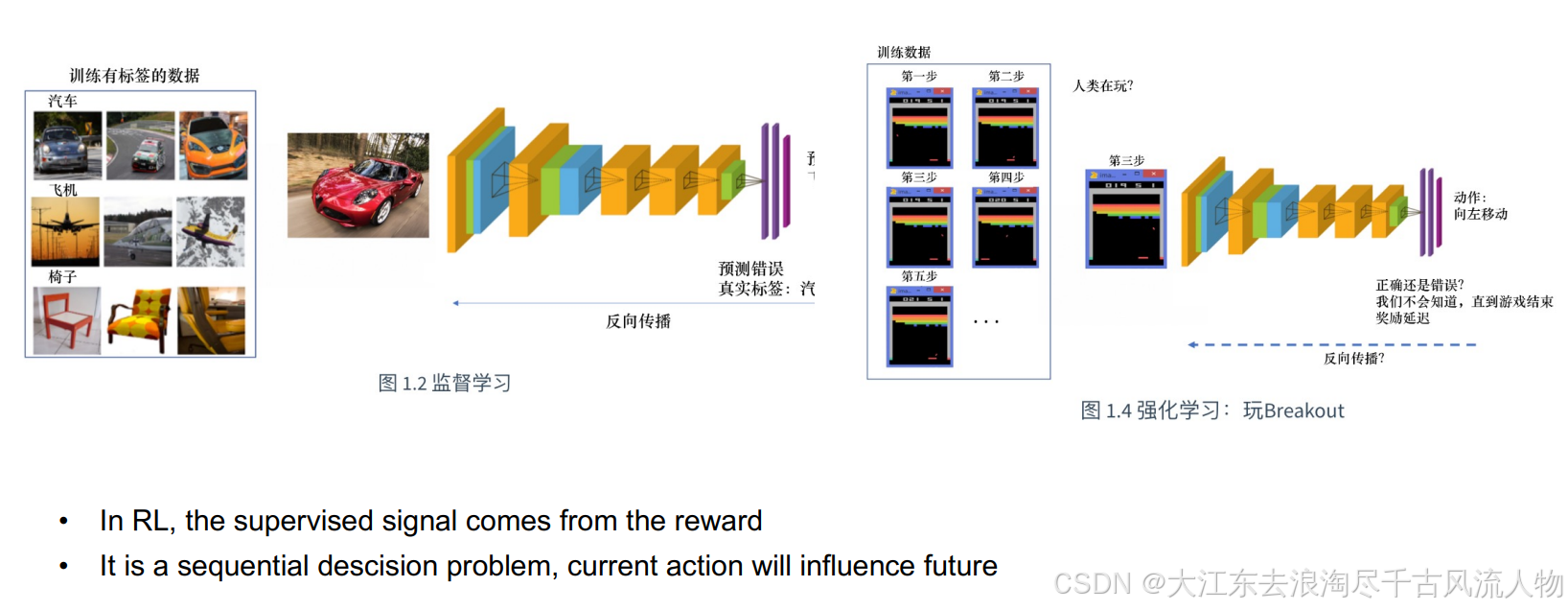
强化学习(RL) 研究的是智能体如何通过与环境交互,以最大化累积奖励为目标来学习策略。
监督学习则是通过标注数据,以最小化损失函数为目标来学习模型。
• RL is about how an agent learn a policy through interaction with the environment by maximizing the rewards
• Supervised Learning is about learning a model through labeled data by minimizing the loss function.
2. 监督学习、无监督学习、强化学习对比
强化学习 不是 监督学习的一种。
机器学习三大基础范式 为:监督学习、无监督学习、强化学习 ,三者是并列关系;此外还有半监督、自监督、弱监督等衍生范式。
三大范式核心区别
| 对比维度 | 监督学习 (SL) | 无监督学习 (UL) | 强化学习 (RL) |
|---|---|---|---|
| 核心思想 | 学习输入→输出的映射函数 | 挖掘数据内在结构/分布/模式 | 智能体通过交互试错学习最优策略 |
| 数据要求 | 必须有标注标签(标准答案) | 无标注,仅原始输入数据 | 无标注,有环境奖励/惩罚信号 |
| 反馈类型 | 即时、精确的监督信号(标签) | 无外部反馈,仅数据内部规律 | 延迟、稀疏的奖励信号 |
| 优化目标 | 最小化预测值与标签的损失函数 | 最小化重构误差/类内距/最大化类间距 | 最大化长期累积奖励 |
| 典型任务 | 图像分类、房价预测、文本分类 | 用户分群、数据降维、异常检测 | 游戏AI、机器人控制、推荐系统、自动驾驶 |
| 代表算法 | CNN、Transformer、SVM、线性回归 | K-Means、PCA、DBSCAN、自编码器 | DQN、PPO、A3C、策略梯度、Q-Learning |
补充关键要点
-
强化学习 ≠ 监督学习
监督学习是"看答案学 ",强化学习是"试错、挨打、拿奖励学 ",奖励常延迟、稀疏,无固定标签。
-
常见衍生范式
- 半监督学习:少量标注 + 大量无标注数据
- 自监督学习:无标注,自己构造监督信号(如BERT、对比学习),属无监督衍生
- 弱监督学习:使用噪声、粗略、间接标注
3. Comparison between RL and Supervised Learning
1. https://datawhalechina.github.io/easy-rl/#/
Elements in RL
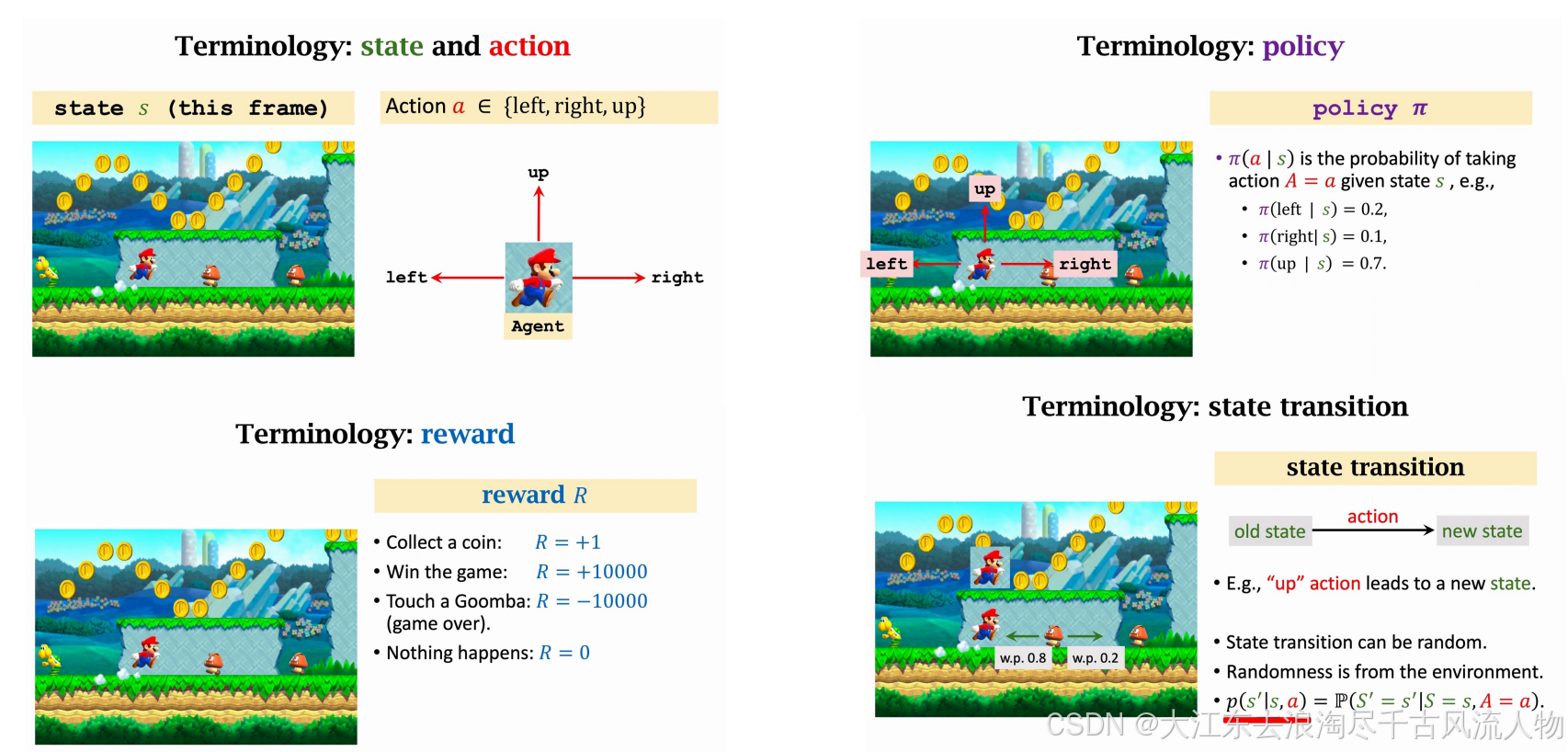
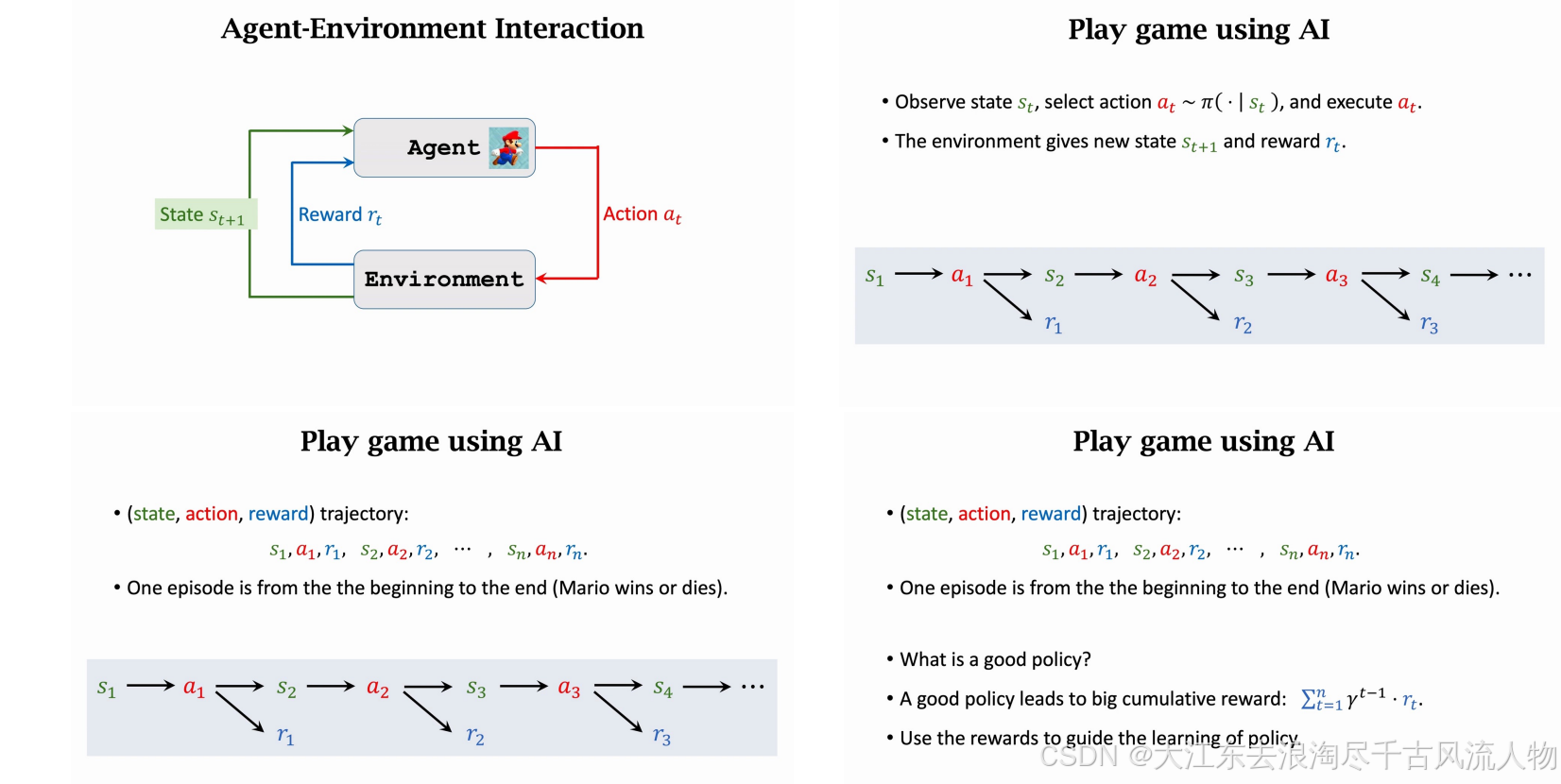

强化学习中的回报与折扣回报
3.1 回报(Return)
回报(也称为累积未来奖励 ),表示从时刻 (t) 开始,后续所有时刻获得的奖励之和。
U t = R t + R t + 1 + R t + 2 + R t + 3 + ... U_t = R_t + R_{t+1} + R_{t+2} + R_{t+3} + \dots Ut=Rt+Rt+1+Rt+2+Rt+3+...
核心问题:当前奖励与未来奖励的权重
在时刻 t t t, R t R_t Rt和 R t + 1 R_{t+1} Rt+1 是否同等重要?
-
示例选择:
- 现在给你 80 美元。
- 一年后给你 100 美元。
-
核心结论:
- 未来奖励的价值低于当前奖励(即时奖励更有价值)。
- 因此, R t + 1 R_{t+1} Rt+1 的权重应小于 R t R_t Rt。
3.3 折扣回报(Discounted Returns)
回报(也称为累积未来奖励):
U t = R t + R t + 1 + R t + 2 + R t + 3 + ... U_t = R_t + R_{t+1} + R_{t+2} + R_{t+3} + \dots Ut=Rt+Rt+1+Rt+2+Rt+3+...
定义:折扣回报
折扣回报(也称为累积折扣未来奖励),通过折扣因子对未来奖励进行加权。
- γ \gamma γ:折扣因子(可调超参数,取值范围通常为 0 ≤ γ < 1 0 \leq \gamma < 1 0≤γ<1),用于降低未来奖励的权重。
- 公式:
U t = R t + γ R t + 1 + γ 2 R t + 2 + γ 3 R t + 3 + ... U_t = R_t + \gamma R_{t+1} + \gamma^2 R_{t+2} + \gamma^3 R_{t+3} + \dots Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+...
注:越远的未来奖励,被折扣的程度越大( γ \gamma γ 的幂次越高)。
3.4 回报中的随机性(观测视角)
定义:时刻 (t) 的折扣回报
U t = R t + γ R t + 1 + γ 2 R t + 2 + ⋯ + γ n − t R n U_t = R_t + \gamma R_{t+1} + \gamma^2 R_{t+2} + \dots + \gamma^{n-t} R_n Ut=Rt+γRt+1+γ2Rt+2+⋯+γn−tRn
((n) 为序列终止时刻)
3.5 观测到的折扣回报
在游戏(任务)结束时,我们可以观测到所有具体的奖励值 ( r t , r t + 1 , r t + 2 , ... , r n r_t, r_{t+1}, r_{t+2}, \dots, r_n rt,rt+1,rt+2,...,rn,从而计算出观测到的折扣回报:
u t = r t + γ r t + 1 + γ 2 r t + 2 + ⋯ + γ n − t r n u_t = r_t + \gamma r_{t+1} + \gamma^2 r_{t+2} + \dots + \gamma^{n-t} r_n ut=rt+γrt+1+γ2rt+2+⋯+γn−trn
注: U t U_t Ut 是随机变量, u t u_t ut是其一次观测到的具体值。
3.6 回报中的随机性(理论视角)
定义:时刻 (t) 的折扣回报
U t = R t + γ R t + 1 + γ 2 R t + 2 + ⋯ + γ n − t R n U_t = R_t + \gamma R_{t+1} + \gamma^2 R_{t+2} + \dots + \gamma^{n-t} R_n Ut=Rt+γRt+1+γ2Rt+2+⋯+γn−tRn
随机性来源
在时刻 (t),奖励 R t , ... , R n R_t, \dots, R_n Rt,...,Rn 是随机的,因此回报 U t U_t Ut 也是随机的:
- 奖励 R i R_i Ri 依赖于状态 S i S_i Si 和动作 A i A_i Ai。
- 回报 U t U_t Ut 依赖于 R t , R t + 1 , ... , R n R_t, R_{t+1}, \dots, R_n Rt,Rt+1,...,Rn。
- 因此,(U_t) 最终依赖于从 (t) 到 (n) 的状态-动作序列 S t , A t , S t + 1 , A t + 1 , ... , S n , A n S_t, A_t, S_{t+1}, A_{t+1}, \dots, S_n, A_n St,At,St+1,At+1,...,Sn,An。
