核心概念
page
page是golang内存管理的最小单位,golang的page大小是8kb。
如果每次内存分配都是以page为单位,即使创建一个10字节的实例,也需要分配8kb的page,意味着会造成大量内存内部碎片,降低内存利用率。同时,如果申请80kb的实例,需要分配10次page,将会造成重复调用,降低性能。
mspan
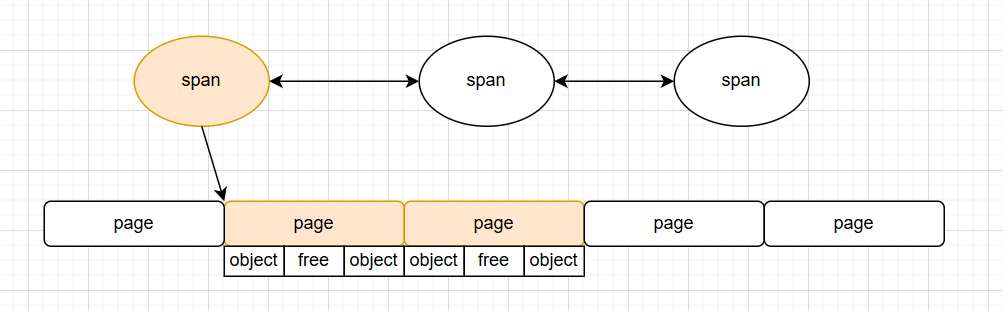
mspan用于golang内存分配的精细化管理,本质上是一组连续的page的封装。
一个mspan可以拆分成多块,在堆分配中对应一个span可以存放多少个对象,在栈分配中对应一个span可以分配多少个堆块。
// runtime/mheap.go
type mspan struct {
// 特殊标记,表示这些结构体实例不通过堆分配,而是运行时启动时,直接从操作系统申请一块特殊内存区域,防止递归分配
_ sys.NotInHeap
// 同等级的 mspan 会从属同一个 mcentral,最终会被组织成链表,因此带有前后指针
next *mspan
prev *mspan
...
startAddr uintptr // span 第一个字节的地址
npages uintptr // span 包含的页数
elemsize uintptr // 将span拆分的数量,在堆分配中对应可以申请的对象个数,在栈分配中对应栈块数量
limit uintptr // span 中数据的结束地址
nelems uint16 // span 中的对象总数
freeindex uint16 // 开始扫描下一个空闲对象的槽索引
freeIndexForScan uint16 // GC 扫描器使用的类似 freeindex 的字段
allocCache uint64 // freeindex 位置的 allocBits 缓存,用于快速查找空闲对象
allocBits *gcBits // span 中对象的分配位图
allocCount uint16 // 已分配对象的数量
allocCountBeforeCache uint16 // span 被缓存前的 allocCount 副本
spanclass spanClass // 大小类和 noscan 标记(uint8)
state mSpanStateBox // span 状态(正在使用,已失效等),原子访问
needzero uint8 // 分配前是否需要清零
divMul uint32 // 用于快速除以 elemsize 的乘法因子
...
}mspan将内存申请划分成不同等级,分配对象时,根据申请的大小映射成对应规格的mspan,从对应的mspan中获取内存。
下图描述了67个等级中每个级别对应的使用对象,span大小,拆分的数量,内存碎片等信息。
此外还要一个class为0的span类型,由于大对象分配。
// runtime/sizeclasses.go
// class bytes/obj bytes/span objects tail waste max waste min align
// 1 8 8192 1024 0 87.50% 8
// 2 16 8192 512 0 43.75% 16
// 3 24 8192 341 8 29.24% 8
// 4 32 8192 256 0 21.88% 32
// 5 48 8192 170 32 31.52% 16
// 6 64 8192 128 0 23.44% 64
// 7 80 8192 102 32 19.07% 16
...
// 65 27264 81920 3 128 10.00% 128
// 66 28672 57344 2 0 4.91% 4096
// 67 32768 32768 1 0 12.50% 8192mcache
mcache是P独占的缓存,用于分配堆内存和栈内存。
堆内存缓存是一个数组,元素是指向mspan的指针。并且为了减轻gc标记扫描压力,将对象分成指针类型和非指针类型,非指针类型的不需要扫描下游节点,因为非指针类型只能被引用而不能引用其他对象。不同类型的对象分配不同的span。
栈内存缓存缓存了不同大小的栈空闲列表,实现栈内存的复用。
// runtime/mcache.go
type mcache struct {
_ sys.NotInHeap
// 用于pprof的采样分析
nextSample int64
memProfRate int
scanAlloc uintptr
// Tiny 分配器专门用于优化无指针的小型对象,将多个小型对象打包到同一个内存块中,减少内存开销
tiny uintptr // tiny块起始指针
tinyoffset uintptr // 下一个空闲的tiny块地址
tinyAllocs uintptr // 使用tiny分配的次数
// 堆内存缓存,大小为136,包含有指针和无指针的68个等级的span
alloc [numSpanClasses]*mspan
// 栈内存缓存,用于goroutine 栈内存的分配与复用,指向栈空闲列表
stackcache [_NumStackOrders]stackfreelist
// 清扫代,用于检测是否被gc回收了还没刷新
flushGen atomic.Uint32
}mcentral
mcentral的作用是为mcache提供内存分配服务
mcentral是全局的,一个mcentral聚合了同一等级的所有span,当mcache缓存不足时会从mcentral中获取。
// runtime/mcentral.go
type mcentral struct {
_ sys.NotInHeap
// mcentral存储的span类型
spanclass spanClass
// 使用双集合存储span,目的是方便在gc时做状态转移。
// 仍有空闲内存的span,包括span从未使用和span已经使用了部分
partial [2]spanSet
// 已经满了的span
full [2]spanSet
}mheap
mheap 是 Go 内存管理系统的顶层组件,负责管理整个程序的全局堆内存。它是内存分配器的最底层,直接与操作系统交互,为上层的 mcentral 和 mcache 提供内存支持。
-
管理所有的mcentral,mcentral缓存不足时会向mheap获取
-
当mheap内存不够时,向操作系统申请内存,申请单位是heapAreana,大小为64M
-
负责将page组装成mspan
type mheap struct {
_ sys.NotInHeap// 申请内存时需要加全局锁 lock mutex // 页面分配器,处理内存页的分配、释放、回收等底层操作 pages pageAlloc // gc的清扫代,用于协调gc时span的状态 sweepgen uint32 // 记录了所有的 mspan,所有 mspan 都是经由 mheap,使用连续空闲页组装生成的 allspans []*mspan // all spans out there // 比例清扫相关 pagesInUse atomic.Uintptr // 统计为 mSpanInUse 的页面数 pagesSwept atomic.Uint64 // 本周期已清扫页面数 pagesSweptBasis atomic.Uint64 // 清扫比例起始页面数 sweepHeapLiveBasis uint64 // 堆活跃内存起始值 sweepPagesPerByte float64 // 比例清扫比率 reclaimIndex atomic.Uint64 // 下一个要回收的页面索引 reclaimCredit atomic.Uintptr // 额外清扫页面的备用信用 // 全局的mcentral集合 central [numSpanClasses]struct { mcentral mcentral pad [(cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize) % cpu.CacheLinePadSize]byte } // heapAreana 数组,64 位系统下,二维数组容量为 [1][2^22] // 每个 heapArena 大小 64M,因此理论上,Golang 堆上限为 2^22*64M = 256T // arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena ...}
堆&栈
区别
|------|-----------------------|-------------------|
| | 栈 | 堆 |
| 布局 | 连续的内存空间 | 非连续内存 |
| 分配方式 | 自动分配回收,生命周期与函数一致 | 需要手动申请与回收,或通过gc回收 |
| 扩展性 | 不允许扩容或者扩容时需要重新申请空间并拷贝 | 只需申请新空间 |
| 访问速度 | 快,因为连续的空间可以用到缓存 | 较慢 |
| 存储内容 | 局部变量、函数参数、返回值、函数调用上下文 | 对象、数组、大尺寸数据等 |
| 线程安全 | 线程私有 | 线程共享 |
栈的特点是性能高,因为它连续且生命周期短,但为了保证它的连续牺牲了灵活性,导致无法自由地申请新空间。
并且由于栈的独特结构,通过push和release实现内存的申请和释放,不需要手动进行垃圾回收。
golang为了减少系统调用,尽量地将操作在用户态完成,程序的堆和栈都是使用预先申请内存缓存,只有在缓存不够的情况下才调用mmap申请内存。
内存逃逸
由栈的特点得知,栈内存是不需要gc的。在golang中,为了减轻gc的压力,会尽量地把对象分配在栈上,让它能够自动地释放内存。那么什么情况下对象一定会申请到堆内存呢。
引用自官方回复:golang.org/doc/faq#sta...
How do I know whether a variable is allocated on the heap or the stack?
From a correctness standpoint, you don't need to know. Each variable in Go exists as long as there are references to it. The storage location chosen by the implementation is irrelevant to the semantics of the language.
The storage location does have an effect on writing efficient programs. When possible, the Go compilers will allocate variables that are local to a function in that function's stack frame. However, if the compiler cannot prove that the variable is not referenced after the function returns, then the compiler must allocate the variable on the garbage-collected heap to avoid dangling pointer errors. Also, if a local variable is very large, it might make more sense to store it on the heap rather than the stack.
In the current compilers, if a variable has its address taken, that variable is a candidate for allocation on the heap. However, a basic escape analysis recognizes some cases when such variables will not live past the return from the function and can reside on the stack.
简单地说,如果变量被函数之外捕获,或者变量太大就会被分在堆上。
可以通过go build -gcflags '-m -l' xxxx.go命令查看逃逸分析。
下面列举几个常见地内存逃逸case:
- 函数返回局部变量指针
- interfact{}逃逸,因为编译器无法提前预知interfact的类型,无法提前分配内存
- 申请的栈空间过大,map和slice不能超过64KB,普通类型不能超过10MB
- 切片逃逸:slice未指定长度或者slice内的元素逃逸
- 闭包逃逸
- channel逃逸:向channel中传入指针类型
详情可参见Golang 内存调优 - 逃逸分析在计算机领域中,堆栈是非常重要的概念,数据结构中有堆栈,内存分配中也有堆栈;本该分配 - 掘金
堆内存
概要
Golang根据大小将对象分成3类
- tiny微对象,小于16b且不包含指针的对象
- small小对象,16b到32kb之间
- large大对象,32kb以上
申请过程类似多级缓存,依次从mcache,mcentral,mheap,操作系统中申请。
|----|-----------------------------------------------------------------------------|----------------------------------------|-------------------|
| 阶段 | 流程 | 粒度 | 适用对象 |
| 1 | 从tiny块中获取内存,计算偏移量后追加到tiny块中,如果内存不足,从mcache中申请内存补充tiny块。 | P独占,不需要加锁 | tiny |
| 2 | 从mcache中根据对象大小类型获取对应的mspan,如果mspan空间不足,向mcentral中申请等大的mspan替换mcache中的mspan。 | P独占,不需要加锁 | tiny,small |
| 3 | 从mcentral的队列中获取msapn,如果没有mspan可用,则向mheap申请内存补充mspan。 | 全局共享,需要加spanClass级别的锁(不同的spanClass不冲突) | tiny,small |
| 4 | 从mheap中查找符合的连续空闲page,将page封装成mspan返回,如果空闲页不足,向操作系统申请内存。 | 全局共享,加全局锁 | tiny,small, large |
| 5 | 调用mmap函数,申请最少64MB的内存 | 全局共享,由于mheap已经加锁,不需要额外加锁 | tiny,small,large |
特点
- 多级缓存,通过mcache,mcentral,mheap3级内存缓存,优先使用本地无锁缓存,减少并发冲突。
- 批量申请缓存,当内存不够时一次性向操作系统申请64MB的内存,避免频繁系统调用,以空间换时间,提升了分配性能。
- span分级,创建对象时根据对象大小申请最恰当的span类型,减少了内部碎片的发生。
源码解读
malloc------申请内存
根据对象大小执行不同的分配函数
// runtime/malloc.go
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// 双重检查:确保在 GC 标记终止阶段不调用 mallocgc
if doubleCheckMalloc {
if gcphase == _GCmarktermination {
throw("mallocgc called with gcphase == _GCmarktermination")
}
}
// 特殊处理零大小分配请求
if size == 0 {
// 返回全局零地址指针,避免分配实际内存
return unsafe.Pointer(&zerobase)
}
// GC 辅助:如果 GC 正在进行,分配者需要协助完成标记工作
if gcBlackenEnabled != 0 {
// 扣除辅助信用分,用于 GC 标记进度
deductAssistCredit(size)
}
// 实际执行内存分配,根据大小和类型选择不同的分配策略
var x unsafe.Pointer
var elemsize uintptr
// 小对象分配路径(小于等于 maxSmallSize - mallocHeaderSize)
if size <= maxSmallSize-mallocHeaderSize {
// 未指定类型或无指针类型的对象
if typ == nil || !typ.Pointers() {
// 极小数对象(小于 maxTinySize,通常是16字节)
if size < maxTinySize {
x, elemsize = mallocgcTiny(size, typ, needzero)
} else {
// 较大的无指针小对象
x, elemsize = mallocgcSmallNoscan(size, typ, needzero)
}
} else if heapBitsInSpan(size) {
// 有指针但不需要 malloc 头的小对象
x, elemsize = mallocgcSmallScanNoHeader(size, typ, needzero)
} else {
// 有指针且需要 malloc 头的小对象
x, elemsize = mallocgcSmallScanHeader(size, typ, needzero)
}
} else {
// 大对象分配路径(直接通过 mheap 分配)
x, elemsize = mallocgcLarge(size, typ, needzero)
}
// 调整 GC 辅助债务
if gcBlackenEnabled != 0 && elemsize != 0 {
if assistG := getg().m.curg; assistG != nil {
// 减少辅助债务,因为碎片不会被使用,不需要标记
assistG.gcAssistBytes -= int64(elemsize - size)
}
}
// 返回指向分配内存的指针
return x
}tiny对象申请内存
mallocgcTiny函数
从tiny块中获取内存
P的mcache有tiny分配器,会选取类型为1(对象大小为8个字节且非指针类型)的span作为存储微对象的内存块,基于offset偏移量的方式将多个不同大小tiny对象合并到同一个内存块中,减小内存碎片。
普通的span分配,span被划分成等大的区域,每个区域正好可以容纳一个对象,这种情况可能导致内存碎片,例如每个区域的大小是8字节,如果我要为5字节大的对象申请,会有3字节的内存碎片。
但为什么不全部使用这种基于偏移量的方式进行内存分配
我猜测是因为使用tiny分配器,需要进行内存对齐,偏移量计算,导致复杂度上升。同时,所在的span块需要全部的对象释放了才能被回收,可能会有内存泄漏风险。
// size: 请求分配的字节大小
// typ: 要分配的类型信息(必须是无指针类型)
// needzero: 是否需要将分配的内存初始化为零值
// 返回值: (分配的内存指针, 分配的内存块大小)
func mallocgcTiny(size uintptr, typ *_type, needzero bool) (unsafe.Pointer, uintptr) {
mp := acquirem() // 获取gmp中的m
mp.mallocing = 1 // 标记当前m正在进行分配
c := getMCache(mp) // 获取当前P的本地内存缓存
off := c.tinyoffset // 获取当前tiny块的可用偏移量
// 进行内存对齐
if size&7 == 0 {
off = alignUp(off, 8) // 8字节对齐:适用于64位整数、指针等
} else if goarch.PtrSize == 4 && size == 12 {
// 32位系统上特殊处理12字节对象,避免原子访问错误
off = alignUp(off, 8)
} else if size&3 == 0 {
off = alignUp(off, 4) // 4字节对齐:适用于32位整数、浮点数等
} else if size&1 == 0 {
off = alignUp(off, 2) // 2字节对齐:适用于16位整数、字符等
}
// mcache中的tiny块空间足够
if off+size <= maxTinySize && c.tiny != 0 {
x := unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size // 更新tiny块的可用偏移量
c.tinyAllocs++ // 增加tiny分配计数
mp.mallocing = 0 // 重置分配标志
releasem(mp) // 释放m资源(释放锁和重置标志)
return x, 0 // 返回分配的指针,第二个返回值为0表示使用现有块
}
// 现有tiny块空间不足,需要分配新的maxTinySize大小的块
checkGCTrigger := false // 标记是否需要检查GC触发条件
span := c.alloc[tinySpanClass] // 从mcache的span集合中获取tiny类型(8字节且非指针类型)的span
v := nextFreeFast(span) // 尝试从mcache中分配span
if v == 0 {
// 快速分配失败,从mcentral中申请span
v, span, checkGCTrigger = c.nextFree(tinySpanClass)
}
x := unsafe.Pointer(v) // 新分配的内存指针
// 将新分配的内存块清零,确保安全
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// 根据剩余空间大小决定是否更新tiny块指针
// 选择剩余空间更小的块作为新的tiny块,以提高空间利用率
if !raceenabled && (size < c.tinyoffset || c.tiny == 0) {
c.tiny = uintptr(x) // 更新当前tiny块的起始地址
c.tinyoffset = size // 设置新tiny块的可用偏移量
}
// 在GC期间,将新分配的对象标记为黑色(已标记)
// 由于是无指针类型,不需要进行进一步扫描
if writeBarrier.enabled {
gcmarknewobject(span, uintptr(x))
}
// 完成分配,清理并释放资源
mp.mallocing = 0 // 重置分配标志
releasem(mp) // 释放m资源
// 检查是否需要触发GC循环
// 如果分配后堆大小达到阈值,启动新的GC循环
if checkGCTrigger {
if t := (gcTrigger{kind: gcTriggerHeap}); t.test() {
gcStart(t) // 启动GC循环
}
}
return x, span.elemsize // 返回分配的指针和实际分配的块大小
}从mcache获取内存
// nextFreeFast 是 Go 内存分配器中的快速空闲对象查找函数,用于在 mspan 中高效定位下一个可用对象。
func nextFreeFast(s *mspan) gclinkptr {
// 使用硬件加速指令快速查找 allocCache 中第一个 0 位(空闲对象)
theBit := sys.TrailingZeros64(s.allocCache)
// 如果找到空闲位(theBit < 64),则继续处理
if theBit < 64 {
// 计算空闲对象在 mspan 中的绝对索引
// freeindex: 上次查找结束的位置,避免每次从头开始
// theBit: 当前缓存中第一个空闲位的相对位置
result := s.freeindex + uint16(theBit)
// 确保计算得到的索引在有效范围内(小于 mspan 中的对象总数)
if result < s.nelems {
// 计算下一次查找的起始位置
freeidx := result + 1
// 检查是否需要重新加载 allocCache:
// 当 freeidx 是 64 的倍数且不是最后一个对象时,表示当前缓存已耗尽
// 返回 0 触发慢速查找路径,重新加载缓存
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
// 更新 allocCache:将已使用的位右移出去,保留剩余未检查的位
// theBit + 1: 跳过当前找到的空闲位及其之前的已分配位
s.allocCache >>= uint(theBit + 1)
// 更新下次查找的起始位置
s.freeindex = freeidx
// 增加已分配对象的计数
s.allocCount++
// 计算并返回分配对象的地址:
// uintptr(result)*s.elemsize: 对象在 span 内的偏移量
// + s.base(): 加上 span 的基地址,得到内存中的实际地址
// gclinkptr: 转换为 GC 安全的指针类型
return gclinkptr(uintptr(result)*s.elemsize + s.base())
}
}
// 未找到空闲对象或索引无效,返回 0 触发慢速查找路径
return 0
}从mcentral获取内存
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, checkGCTrigger bool) {
// 从 mcache 的 alloc 数组中获取对应 spanClass 的 mspan
s = c.alloc[spc]
// 初始化 GC 触发检查标志为 false
checkGCTrigger = false
// 获取mspan中下一个空闲对象的索引
// nextFreeIndex 内部会尝试重新加载 allocCache 或扫描 allocBits
freeIndex := s.nextFreeIndex()
// 检查 span 是否已满
if freeIndex == s.nelems {
// 验证 span 状态一致性:已分配计数应等于对象总数
if s.allocCount != s.nelems {
println("runtime: s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount != s.nelems && freeIndex == s.nelems")
}
// 从 mcentral 获取新的 mspan,将当前满的 mspan 放回 mcentral
c.refill(spc)
// 由于获取了新 span,可能增加了堆内存使用,需要检查 GC 触发条件
checkGCTrigger = true
// 更新 span 引用为新获取的 span
s = c.alloc[spc]
// 从新 span 中获取下一个空闲对象的索引
freeIndex = s.nextFreeIndex()
}
// 验证空闲索引的有效性,确保不越界
if freeIndex >= s.nelems {
throw("freeIndex is not valid")
}
// 计算分配对象的地址
// freeIndex * s.elemsize: 计算对象在 span 内的偏移量
// + s.base(): 加上 span 的基地址,得到对象在内存中的实际地址
v = gclinkptr(uintptr(freeIndex)*s.elemsize + s.base())
// 更新 span 的已分配计数
s.allocCount++
// 验证分配计数的一致性,确保不超过对象总数
if s.allocCount > s.nelems {
println("s.allocCount=", s.allocCount, "s.nelems=", s.nelems)
throw("s.allocCount > s.nelems")
}
// 返回分配的对象指针、所属 span 和 GC 触发检查标志
return
}调用了refill函数从上级mcentral申请内存
func (c *mcache) refill(spc spanClass) {
// 获取当前已耗尽的 mspan
s := c.alloc[spc]
// 验证 mspan 确实已满
if s.allocCount != s.nelems {
throw("refill of span with free space remaining")
}
if s != &emptymspan {
// 验证 span 的清扫代是否处于正确的缓存状态
// sweepgen+3 是缓存状态的标记,防止异步清扫
if s.sweepgen != mheap_.sweepgen+3 {
throw("bad sweepgen in refill")
}
// 将已满的 mspan 归还到 mcentral的full队列
mheap_.central[spc].mcentral.uncacheSpan(s)
// 统计本次缓存期间使用的槽位数
stats := memstats.heapStats.acquire()
// 计算本次缓存期间实际分配的对象数量
slotsUsed := int64(s.allocCount) - int64(s.allocCountBeforeCache)
// 更新对应大小类的小对象分配计数
atomic.Xadd64(&stats.smallAllocCount[spc.sizeclass()], slotsUsed)
// 如果是 Tiny 分配器的 span,特殊处理 Tiny 分配计数
if spc == tinySpanClass {
atomic.Xadd64(&stats.tinyAllocCount, int64(c.tinyAllocs))
c.tinyAllocs = 0 // 重置 Tiny 分配计数
}
memstats.heapStats.release()
// 更新总分配字节数,用于 GC 控制
bytesAllocated := slotsUsed * int64(s.elemsize)
gcController.totalAlloc.Add(bytesAllocated)
// 清除缓存前的分配计数
s.allocCountBeforeCache = 0
}
// 从 mcentral 获取新的可用 mspan
s = mheap_.central[spc].mcentral.cacheSpan()
// 如果获取失败,说明内存不足
if s == nil {
throw("out of memory")
}
// 验证新获取的 mspan 确实有空闲空间
if s.allocCount == s.nelems {
throw("span has no free space")
}
// 标记新 mspan 为缓存状态
// sweepgen+3 确保该 span 在下一个清扫阶段不会被异步清扫
s.sweepgen = mheap_.sweepgen + 3
// 记录当前的分配计数,用于下次归还时统计
s.allocCountBeforeCache = s.allocCount
// 更新内存使用统计和 GC 控制器状态
// 计算当前已使用的字节数(已分配对象的大小)
usedBytes := uintptr(s.allocCount) * s.elemsize
// 更新 GC 控制器:
// - 增加 heapLive(使用高估策略,假设所有槽都将被使用)
// - 刷新 scanAlloc(已分配的可扫描内存量)
gcController.update(int64(s.npages*pageSize)-int64(usedBytes), int64(c.scanAlloc))
c.scanAlloc = 0 // 重置 scanAlloc
// 将新获取的 mspan 存储到 mcache 中,完成 refill
c.alloc[spc] = s
}通过cacheSpan获取可用的span,如果mcache的partial和full列表都没有满足条件的空闲对象,从mheap中申请内存。
func (c *mcentral) cacheSpan() *mspan {
// 计算当前 span 的字节数,并扣除清扫信用额度,用于控制 GC 清扫进度
// class_to_allocnpages 将 sizeclass 映射到分配的页数
spanBytes := uintptr(class_to_allocnpages[c.spanclass.sizeclass()]) * _PageSize
deductSweepCredit(spanBytes, 0)
traceDone := false
trace := traceAcquire()
if trace.ok() {
// 记录 GC 清扫开始的 trace 事件,用于性能分析
trace.GCSweepStart()
traceRelease(trace)
}
// spanBudget 用于限制在寻找可用 span 时的清扫次数
// 如果清扫了 spanBudget 个 span 仍未找到可用空间,则直接分配新的 span
// 这样可以限制寻找可用空间的时间,并分摊小对象清扫的成本
// 设置为 100 可以将空间开销限制在 1%
spanBudget := 100
var s *mspan // 要返回的 span
var sl sweepLocker // 清扫锁,用于保护 span 清扫过程
// 首先尝试从已清扫的部分填充 span 列表中获取
sg := mheap_.sweepgen // 当前堆的清扫代数,用于处理并发清扫
if s = c.partialSwept(sg).pop(); s != nil {
goto havespan // 找到可用 span,直接跳转到返回处理
}
// 获取清扫锁,准备处理未清扫的 span
sl = sweep.active.begin()
if sl.valid {
// 尝试从未清扫的部分填充 span 列表中获取
for ; spanBudget >= 0; spanBudget-- {
s = c.partialUnswept(sg).pop()
if s == nil {
break // 列表为空,跳出循环
}
if s, ok := sl.tryAcquire(s); ok {
// 成功获取了 span 的所有权,开始清扫
s.sweep(true)
sweep.active.end(sl) // 释放清扫锁
goto havespan // 清扫完成,跳转到返回处理
}
// 获取所有权失败,说明该 span 正在被其他清扫器处理
// 此时应该忽略这个 span,因为其他清扫器会负责处理它
}
// 尝试从未清扫的完全填充 span 列表中获取
for ; spanBudget >= 0; spanBudget-- {
s = c.fullUnswept(sg).pop()
if s == nil {
break // 列表为空,跳出循环
}
if s, ok := sl.tryAcquire(s); ok {
// 成功获取了spanClass级别的锁,拿到 span 的所有权,开始清扫
s.sweep(true)
// 检查清扫后是否有可用空间
freeIndex := s.nextFreeIndex()
if freeIndex != s.nelems {
// 有可用空间,更新 freeindex 并使用
s.freeindex = freeIndex
sweep.active.end(sl) // 释放清扫锁
goto havespan // 跳转到返回处理
}
// 没有可用空间,将 span 添加到已清扫的完全填充列表中
c.fullSwept(sg).push(s.mspan)
}
// 获取所有权失败,忽略这个 span
}
// 释放清扫锁
sweep.active.end(sl)
}
// 记录 GC 清扫完成的 trace 事件
trace = traceAcquire()
if trace.ok() {
trace.GCSweepDone()
traceDone = true
traceRelease(trace)
}
// 无法从 mcentral 获取可用 span,尝试从 mheap 分配新的 span
s = c.grow()
if s == nil {
return nil // 分配失败
}
// 此时 s 应该是一个带有可用对象的 span
havespan:
if !traceDone {
// 确保记录清扫完成事件
trace := traceAcquire()
if trace.ok() {
trace.GCSweepDone()
traceRelease(trace)
}
}
// 检查 span 是否确实有可用对象,防止状态错误
n := int(s.nelems) - int(s.allocCount)
if n == 0 || s.freeindex == s.nelems || s.allocCount == s.nelems {
throw("span has no free objects") // 断言失败,说明 span 状态错误
}
// 计算分配位图的起始位置,用于快速查找可用对象
// freeByteBase 是 s.freeindex 所在的 64 位块的起始位置
freeByteBase := s.freeindex &^ (64 - 1)
whichByte := freeByteBase / 8 // 转换为字节索引
// 初始化分配位图缓存,提高后续对象分配的效率
s.refillAllocCache(whichByte)
// 调整 allocCache,使 s.freeindex 对应到 allocCache 的最低位
// 这样在后续分配时可以快速找到下一个可用位
s.allocCache >>= s.freeindex % 64
// 返回准备好的 span 给本地缓存使用
return s
}从mheap中获取内存
func (c *mcentral) grow() *mspan {
// 根据 sizeclass 获取该类对象需要分配的页面数量
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
// 根据 sizeclass 获取该类对象的大小(字节数)
size := uintptr(class_to_size[c.spanclass.sizeclass()])
// 从全局堆(mheap)中分配指定页数和 spanclass 的内存块
s := mheap_.alloc(npages, c.spanclass)
// 如果堆分配失败(如内存不足),返回 nil
if s == nil {
return nil
}
// 计算 span 中可容纳的对象数量
n := s.divideByElemSize(npages << _PageShift )
// 设置 span 的结束地址(limit)
// base() 返回 span 的起始地址,size*n 是总字节数
s.limit = s.base() + size*n
// 初始化堆位信息,用于垃圾回收标记
s.initHeapBits()
return s
}
func (h *mheap) alloc(npages uintptr, spanclass spanClass) *mspan {
var s *mspan
systemstack(func() {
if !isSweepDone() {
h.reclaim(npages)
}
// 申请内存
s = h.allocSpan(npages, spanAllocHeap, spanclass)
})
return s
}先从mheap中通过基数树索引快速寻找满足条件的连续空闲页,如果没有足够的空闲页,则向操作系统申请缓存。
func (h *mheap) allocSpan(npages uintptr, typ spanAllocType, spanclass spanClass) (s *mspan) {
gp := getg()
base, scav := uintptr(0), uintptr(0)
growth := uintptr(0)
// 栈内存分配是否需要页对齐
needPhysPageAlign := physPageAlignedStacks && typ == spanAllocStack && pageSize < physPageSize
pp := gp.m.p.ptr()
if !needPhysPageAlign && pp != nil && npages < pageCachePages/4 {
// 小对象可用使用P中的页缓存
...
}
// 加全局锁
lock(&h.lock)
// 需要页对齐的情况
if needPhysPageAlign {
extraPages := physPageSize / pageSize
base, _ = h.pages.find(npages + extraPages)
if base == 0 {
var ok bool
growth, ok = h.grow(npages + extraPages)
if !ok {
unlock(&h.lock)
return nil
}
base, _ = h.pages.find(npages + extraPages)
if base == 0 {
throw("grew heap, but no adequate free space found")
}
}
base = alignUp(base, physPageSize)
scav = h.pages.allocRange(base, npages)
}
if base == 0 {
// 通过基数树索引快速寻找满足条件的连续空闲页
base, scav = h.pages.alloc(npages)
if base == 0 {
var ok bool
// 内存不足,向操作系统申请内存
growth, ok = h.grow(npages)
if !ok {
unlock(&h.lock)
return nil
}
base, scav = h.pages.alloc(npages)
if base == 0 {
throw("grew heap, but no adequate free space found")
}
}
}
if s == nil {
s = h.allocMSpanLocked()
}
unlock(&h.lock)
...
HaveSpan:
...
// 初始化span
h.initSpan(s, typ, spanclass, base, npages)
...
return s
}向操作系统申请内存
func (h *mheap) grow(npage uintptr) (uintptr, bool) {
assertLockHeld(&h.lock) // 确保已持有堆锁,保证并发安全
// 将请求的页面数以512倍数对齐,减少系统调用次数
ask := alignUp(npage, pallocChunkPages) * pageSize
totalGrowth := uintptr(0) // 记录实际扩展的内存总大小
// 计算扩展后的内存结束地址
end := h.curArena.base + ask
// 将结束地址对齐到物理页边界
nBase := alignUp(end, physPageSize)
出
if nBase > h.curArena.end || /* overflow */ end < h.curArena.base {
// 当前 Arena 空间不足或地址溢出,需要分配新的 Arena
// 向操作系统申请内存
av, asize := h.sysAlloc(ask, &h.arenaHints, true)
if av == nil {
// 内存分配失败,输出错误信息
...
return 0, false
}
if uintptr(av) == h.curArena.end {
// 新分配的内存与当前 Arena 连续,直接扩展当前 Arena
h.curArena.end = uintptr(av) + asize
} else {
// 新分配的内存与当前 Arena 不连续
// 处理当前 Arena 的剩余空间
if size := h.curArena.end - h.curArena.base; size != 0 {
// 将当前 Arena 的剩余空间从保留状态转换为可用状态
...
}
// 切换到新分配的 Arena 空间
h.curArena.base = uintptr(av)
h.curArena.end = uintptr(av) + asize
}
// 重新计算新的结束地址
// 由于 sysAlloc 已返回有效区域,这里不会发生地址溢出
nBase = alignUp(h.curArena.base+ask, physPageSize)
}
...
// 返回实际扩展的内存大小
return totalGrowth, true
}向操作系统申请内存,最小为64M
func (h *mheap) sysAlloc(n uintptr, hintList **arenaHint, register bool) (v unsafe.Pointer, size uintptr) {
// 确保加锁成功
assertLockHeld(&h.lock)
// 申请内存对齐成64M的倍数
n = alignUp(n, heapArenaBytes)
// 申请内存
v = sysReserve(unsafe.Pointer(p), n)
...
return
}
func sysReserve(v unsafe.Pointer, n uintptr) unsafe.Pointer {
return sysReserveOS(v, n)
}
func sysReserveOS(v unsafe.Pointer, n uintptr) unsafe.Pointer {
// Linux系统通过mmap申请内存
p, err := mmap(v, n, _PROT_NONE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
if err != 0 {
return nil
}
return p
}small对象申请内存
0申请small对象跟tiny对象流程相似,区别是不需要经过tiny分配器分配内存,而是直接使用mcache中的span
small对象分配根据大小和是否是指针类型,分成3种情况分配,每种情况的区别如下:
|---------------------------|------------|------------------------|---------------------|
| 函数 | 适用对象类型 | 指针信息存储 | GC 行为 |
| mallocgcSmallNoscan | 无指针 | 无需存储指针信息 | 跳过清扫扫描 |
| mallocgcSmallScanNoHeader | 有指针 | span 的堆位图中 | 需扫描,指针信息直接在 span 中 |
| mallocgcSmallScanHeader | 有指针且大小大于1k | 需要额外创建一个malloc头来存储指针信息 | 需扫描,指针信息在 malloc 头中 |
large对象申请内存
大对象可能会占据整一个span,如果大对象频繁申请的话会导致mcache和mcentral缓存频繁耗尽,为了避免mcache和mcentral的频繁刷新,大对象直接从mheap中申请整个span,该span的class为0。
func (c *mcache) allocLarge(size uintptr, noscan bool) *mspan {
// 检查 size 是否接近 uintptr 的最大值,避免后续计算溢出
if size+_PageSize < size {
throw("out of memory")
}
npages := size >> _PageShift
if size&_PageMask != 0 {
npages++
}
// 为这次 span 分配扣除清扫信用额度,在必要时进行清扫
deductSweepCredit(npages*_PageSize, npages)
// 为大对象创建一个特殊的 span 类
// 大对象的 sizeclass 固定为 0,noscan 表示对象是否不含指针
spc := makeSpanClass(0, noscan)
// 从全局堆(mheap)中分配指定页数和 spanclass 的内存块
s := mheap_.alloc(npages, spc)
if s == nil {
throw("out of memory") // 内存分配失败,抛出异常
}
// 更新内存分配统计信息
...
// 更新内部不一致统计信息(用于 GC 控制)
// 将大 span 放入 mcentral 的清扫列表,使后台清扫器可以看到这个 span
// 大对象也需要参与垃圾回收的清扫过程
mheap_.central[spc].mcentral.fullSwept(mheap_.sweepgen).push(s)
// 设置 span 的结束地址(limit)
s.limit = s.base() + size
// 初始化堆位信息,用于垃圾回收标记
s.initHeapBits()
return s
}栈内存
概要
golang的栈内存归根结底还是通过mmap获取的。
跟堆内存相似,同样使用了多级缓存机制,与堆内存共用mheap缓存,正常情况下无需进入系统调用向操作系统申请缓存。
mcache中有栈缓存列表,将缓存分成不同的等级,按需获取。
这里的Order代表申请的的内存大小的等级,跟spanClass的意思类似。
// runtime/mcache.go
type mcache struct {
_ sys.NotInHeap
...
// 栈内存缓存,用于goroutine 栈内存的分配与复用,指向栈空闲列表
stackcache [_NumStackOrders]stackfreelist
}- 申请栈内存的时
-
协程创建时,会预先申请轻量(普通g 2kb,g0 64kb)的内存作为栈内存
-
发现内存不够用的时候,再申请一个比原来的栈大两倍的空间。把原来栈中的内容都拷贝到新栈上,同时释放旧栈消耗的内存空间
- 扩容判断
goruntinue一个stackguard0,值为stack.lo + StackGuard,可以理解为栈的边界水位线。
type g struct {
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
}同时计算机有一个寄存器SP,在golang中SP永远指向栈顶
协程在运行的时候,不停地通过调用 SUBQ 来为函数调用分配函数帧,调用 ADDQ 来清除函数帧。在申请内存时(例如函数调用会会分配栈帧),会对比SP和StackGuard0的值,如果SP超过了StackGuard0,会进行扩容。
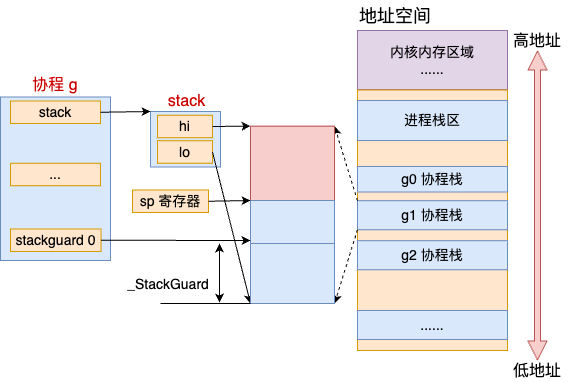
- 流程
|----|---------------------------------------------------------------------------------|--------------------------------|
| 阶段 | 流程 | 粒度 |
| 1 | 从mcache中根据堆内存大小从空闲列表中获取对应大小的缓存块,如果空闲列表没有多余空闲块,向stackpool中获取新的空闲链表替换mcache的本地链表。 | P独占,不需要加锁 |
| 2 | 从stackpool中获取对应大小的span,并将span拆分成链表返回给mcache。如果stackpool没有可用的span,就向mheap申请span | 全局共享,需要加order级别的锁(不同的order不冲突) |
| 3 | 从mheap中查找符合的连续空闲page,将page封装成mspan返回,如果空闲页不足,向操作系统申请内存。 | 全局共享,加全局锁 |
| 4 | 调用mmap函数,申请最少64MB的内存 | 全局共享,由于mheap已经加锁,不需要额外加锁 |
如果申请的栈内存大于32kb,会从专门的全局大栈缓存中获取(加锁),如果全局大栈缓存耗尽,直接从mheap中申请。
var stackLarge struct {
lock mutex
free [heapAddrBits - pageShift]mSpanList // free lists by log_2(s.npages)
}源码解读
协程创建
golang中协程分成两种,g0和普通g,g0的栈较大,会预先分配64kb,普通的g分配2kb栈内存
malg新建goruntinue
// runtime/proc.go
func malg(stacksize int32) *g {
// 分配一个新的 g 结构体
newg := new(g)
if stacksize >= 0 {
// 计算实际需要的栈大小:
// 1. 加上系统预留空间(stackSystem)用于栈溢出时的紧急处理
// 2. 调用 round2 向上对齐到最接近的 2 的幂,优化内存对齐和性能
stacksize = round2(stackSystem + stacksize)
// 在系统栈上执行栈分配
systemstack(func() {
// 调用 stackalloc 分配实际的栈空间并设置到 newg.stack 字段
newg.stack = stackalloc(uint32(stacksize))
})
// 设置栈守卫0:用于检测栈是否要扩容
newg.stackguard0 = newg.stack.lo + stackGuard
...
}
return newg
}从mcache中获取内存
stackalloc 为 goroutine 分配栈空间,必须在g0上执行,避免在分配过程中发生栈溢出导致死锁(分配时栈会增长,导致又触发栈扩容)
func stackalloc(n uint32) stack {
thisg := getg() // 获取当前 goroutine
if thisg != thisg.m.g0 { // 检查是否为调度栈(m.g0)
throw("stackalloc not on scheduler stack")
}
// 栈大小必须是 2 的幂
if n&(n-1) != 0 {
throw("stack size not a power of 2")
}
// 小栈和大栈的分配策略不同
// 小栈使用固定大小的自由链表分配器,大栈使用专用的 span
var v unsafe.Pointer
// 小栈条件:Linux为32KB
if n < fixedStack << _NumStackOrders && n < _StackCacheSize {
// 计算栈大小级别(order)
order := uint8(0)
n2 := n
for n2 > fixedStack {
order++
n2 >>= 1
}
var x gclinkptr
// 特殊情况处理:
// 1. stackNoCache:禁用栈缓存
// 2. thisg.m.p == 0:无处理器(如 exitsyscall 或 procresize 内部)
// 3. thisg.m.preemptoff != "":正在执行不可抢占操作(如 GC)
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
// 从全局栈池获取栈块
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
// 从本地 mcache 获取栈块(无锁)
c := thisg.m.p.ptr().mcache // 获取当前 P 的 mcache
x = c.stackcache[order].list // 从缓存链表获取栈块
if x.ptr() == nil {
// 缓存为空,从全局池补充
stackcacherefill(c, order)
x = c.stackcache[order].list
}
// 更新缓存状态:移除已分配的栈块
c.stackcache[order].list = x.ptr().next
c.stackcache[order].size -= uintptr(n)
}
v = unsafe.Pointer(x) // 转换为 unsafe.Pointer
} else {
// 大栈分配路径:使用专用的 span
var s *mspan
// 计算所需的页面数
npage := uintptr(n) >> _PageShift
log2npage := stacklog2(npage)
// 尝试从大栈缓存获取
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
// 可能需要获取堆锁
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
// 缓存未命中,从堆分配新 span
if s == nil {
// 从堆分配手动管理的 span
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}
...
// 返回分配的栈范围
return stack{uintptr(v), uintptr(v) + uintptr(n)}
}从stackpool申请内存
当本地 mcache 中空闲链表的栈块用尽时,会从全局栈池中补充本地 mcache 的栈块
func stackcacherefill(c *mcache, order uint8) {
// 从全局栈池获取栈块填充到本地缓存
var list gclinkptr // 存储获取到的栈块链表
var size uintptr // 已获取的栈块总大小
// 加锁保护全局栈池
lock(&stackpool[order].item.mu)
// 循环获取栈块,直到达到缓存容量的一半
for size < _StackCacheSize /2 {
// 从全局栈池分配栈块
x := stackpoolalloc(order)
// 将新获取的栈块插入到链表头部
x.ptr().next = list
list = x
// 更新已获取的总大小
size += fixedStack << order
}
// 释放锁
unlock(&stackpool[order].item.mu)
// 更新本地 mcache 的栈缓存:
c.stackcache[order].list = list
c.stackcache[order].size = size
}从全局栈池中获取指定大小的内存,如果全局栈池不够,则向mheap申请一个span,并将span拆分成多个栈块,填充到stackpoll中
func stackpoolalloc(order uint8) gclinkptr {
// 获取当前 order 对应的全局栈池列表
// stackpool[order].item.span 存储了该大小级别的所有可用 span
list := &stackpool[order].item.span
s := list.first
// 获取mheap的锁
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
// 如果没有可用的 span,需要分配新的 span
if s == nil {
// 计算需要分配的页面数
// 分配一个手动管理的 span,专门用于存储栈块
s = mheap_.allocManual(_StackCacheSize>>_PageShift, spanAllocStack)
if s == nil {
throw("out of memory")
}
// 执行操作系统特定的栈初始化
osStackAlloc(s)
// 设置 span 中每个栈块的大小
s.elemsize = fixedStack << order
// 将 span 分割为多个栈块,并构建链表
for i := uintptr(0); i < _StackCacheSize; i += s.elemsize {
x := gclinkptr(s.base() + i)
// 将当前栈块插入到链表头部
x.ptr().next = s.manualFreeList
s.manualFreeList = x
}
// 将新分配的 span 插入到全局栈池列表中
list.insert(s)
}
...
// 更新链表,移除已分配的栈块
s.manualFreeList = x.ptr().next
// 增加该 span 的已分配计数
// 如果该 span 的所有栈块都已分配完毕,将其从全局列表中移除
if s.manualFreeList.ptr() == nil {
list.remove(s)
}
// 返回分配的栈块地址
return x
}从mheap中申请内存
后续过程堆内存中mheap的申请过程一样。
func (h *mheap) allocManual(npages uintptr, typ spanAllocType) *mspan {
if !typ.manual() {
throw("manual span allocation called with non-manually-managed type")
}
return h.allocSpan(npages, typ, 0)
}向操作系统申请内存
......
栈扩容
当 goroutine 执行时触发栈溢出检查(超过 stackguard0 限制),会通过 morestack 切换到系统栈并调用此函数
func newstack() {
// 获取当前系统栈(g0),用于后续操作
thisg := getg()
...
// 获取当前正在执行的 goroutine(即需要扩展栈的 goroutine)
gp := thisg.m.curg
...
// stackguard0 用于检测栈溢出,当栈指针接近 stackguard0 时触发 newstack
stackguard0 := atomic.Loaduintptr(&gp.stackguard0)
// 计算旧栈大小和新栈大小(默认是旧栈的两倍)
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2
// 确保新栈足够大以容纳当前函数的最大栈帧
if f := findfunc(gp.sched.pc); f.valid() {
max := uintptr(funcMaxSPDelta(f)) // 当前函数所需的最大栈空间
needed := max + stackGuard // 需要的总空间(包括保护区域)
used := gp.stack.hi - gp.sched.sp // 已使用的栈空间
// 如果新栈不够大,继续翻倍
for newsize-used < needed {
newsize *= 2
}
}
// 更改 goroutine 状态为 Gcopystack,表示正在复制栈,这样并发 GC 就不会扫描该栈
casgstatus(gp, _Grunning, _Gcopystack)
// 分配新栈空间并复制旧栈内容到新栈
copystack(gp, newsize)
// 恢复 goroutine 状态为 Grunning
casgstatus(gp, _Gcopystack, _Grunning)
// gogo 会恢复 goroutine 的调度上下文,使其在新栈上从原调用点继续执行
gogo(&gp.sched)
}参考
https://mp.weixin.qq.com/s/2TBwpQT5-zU4Gy7-i0LZmQ
提案:扩展 Go 页面分配器 --- Proposal: Scaling the Go page allocator
https://mp.weixin.qq.com/s/-8woNmYLr94UdZsozCbgHQ
Golang 内存调优 - 逃逸分析在计算机领域中,堆栈是非常重要的概念,数据结构中有堆栈,内存分配中也有堆栈;本该分配 - 掘金