如果你也在折腾"让大模型在本地改代码"的 Agent,八成遇到过这种崩溃瞬间:模型说要执行命令、工具跑完回传一大坨、上下文越滚越长、性能忽高忽低、最后还把权限问题搞成"你敢让我删库我就敢执行"......😅
OpenAI 的 Codex CLI(本地跨平台软件代理)把这套流程摊开讲得很直白:核心就是 agent loop(代理循环)------一个负责"用户 ↔ 模型 ↔ 工具"编排的 harness。把 loop 设计对了,Agent 才不会像一只喝了三杯咖啡的无头苍蝇。
下面就用更接地气(但依然严谨)的方式,把 Codex 的 agent loop 彻底"拆开看看",顺便给做 Java/Python 工程化的同学一些能直接落地的套路。
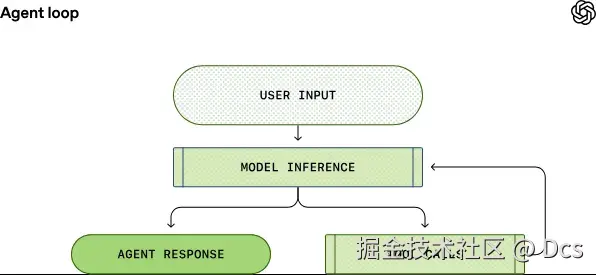
1)所谓 Agent Loop:其实就是"反复问、反复干、反复追加"的流水线
Codex 这套 loop 的节奏非常规律:
-
收用户输入:把用户的话塞进要发给模型的 prompt(注意:真实 prompt 不是一段字符串,而是"多条消息/多种 item 的列表")。
-
模型推理(inference):把 prompt 送到模型,让模型输出。
-
分支:模型输出要么是
- 最终回复(assistant message):这回合结束;
- 工具调用(tool call) :比如让 agent 执行
ls、读文件、跑测试等。
-
执行工具 + 追加结果:agent 执行工具,把工具输出追加回 prompt,再请求模型下一轮推理。
-
循环直到停止调用工具:最后必须以 assistant message 收尾(哪怕主要产出是"本地代码改动")。
一回合(turn)里可能有很多次"推理↔工具"迭代;多回合(multi-turn)则会把历史对话都带上,prompt 越滚越长:
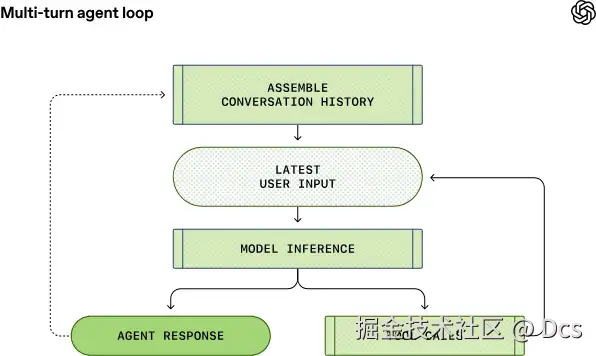
这也解释了为什么 Agent 工程化最容易踩的坑,永远是这两座大山:
- 性能(请求体越来越大,推理越来越贵,缓存还经常失效)
- 上下文窗口(context window)不够用(尤其单回合工具调用特别多的时候)
2)Codex 如何"组装 prompt":不是你以为的一段文本,而是一串分角色的 item
Codex CLI 用的是 Responses API,而不是让用户直接手搓 prompt。用户提交的 JSON 里最关键的三块是:
instructions:系统/开发者指令(Codex 既支持用户配置,也有模型内置 base instructions)tools:可调用的工具定义列表(Codex 内置 shell、plan 等,也可接 MCP 工具,甚至用 web_search)input:多条 item 的数组(消息、文件、图片、推理结果、工具调用/输出等都在这里)
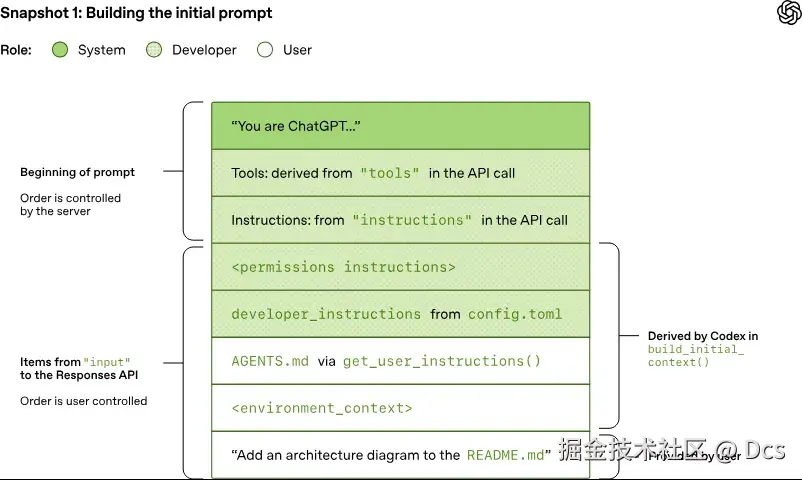
Codex 会先往 input 里插入一堆"铺垫项",再追加用户的真实提问。典型的插入顺序包含:
- developer 消息:权限/沙箱说明(只约束 Codex 自带的 shell 工具)
- developer 消息:用户自定义 developer_instructions(可选)
- user 消息:用户指令聚合(可选)(例如 AGENTS.md/AGENTS.override.md、skills 等)
- user 消息:环境上下文(cwd、shell 等)
示例(权限/沙箱说明):
txt
<permissions instructions>
- description of the sandbox explaining file permissions and network access
- instructions for when to ask the user for permissions to run a shell command
- list of folders writable by Codex, if any
</permissions instructions>示例(环境上下文):
txt
<environment_context>
<cwd>/Users/mbolin/code/codex5</cwd>
<shell>zsh</shell>
</environment_context>而真正发到 Responses API 的 input item,是这种结构:
json
{
"type": "message",
"role": "user",
"content": [
{
"type": "input_text",
"text": "Add an architecture diagram to the README.md"
}
]
}另外,Codex 还会把工具定义塞到 tools 里,长得大概这样(里面同时包含 shell、plan、web_search、以及 MCP 工具):
javascript
[
// Codex's default shell tool for spawning new processes locally.
{
"type": "function",
"name": "shell",
"description": "Runs a shell command and returns its output...",
"strict": false,
"parameters": {
"type": "object",
"properties": {
"command": {"type": "array", "description": "The command to execute"},
"workdir": {"description": "The working directory..."},
"timeout_ms": {"description": "The timeout for the command..."}
},
"required": ["command"]
}
},
// Codex's built-in plan tool.
{
"type": "function",
"name": "update_plan",
"description": "Updates the task plan...",
"strict": false,
"parameters": {
"type": "object",
"properties": {"plan": "...", "explanation": "..."},
"required": ["plan"]
}
},
// Web search tool provided by the Responses API.
{ "type": "web_search", "external_web_access": false },
// MCP server tool (example).
{
"type": "function",
"name": "mcp__weather__get-forecast",
"description": "Get weather alerts for a US state",
"strict": false,
"parameters": {
"type": "object",
"properties": {"latitude": {}, "longitude": {}},
"required": ["latitude", "longitude"]
}
}
]Codex 文章里还有几张"prompt 快照"的图,直观看出服务器会把 system、tools、instructions、input 组装成最终 prompt:
3)流式推理 + 工具回填:SSE 事件才是"真实对话记录"
Codex 发起一次推理,Responses API 会用 SSE(Server-Sent Events)流式返回事件;这些事件不仅用来 UI 实时输出,还会被 Codex 转成内部对象,并追加回 input,供下一轮推理继续使用。
示例(SSE 事件流片段):
txt
data: {"type":"response.reasoning_summary_text.delta","delta":"ah ", ...}
data: {"type":"response.reasoning_summary_text.delta","delta":"ha!", ...}
data: {"type":"response.reasoning_summary_text.done", "item_id":...}
data: {"type":"response.output_item.added", "item":{...}}
data: {"type":"response.output_text.delta", "delta":"forty-", ...}
data: {"type":"response.output_text.delta", "delta":"two!", ...}
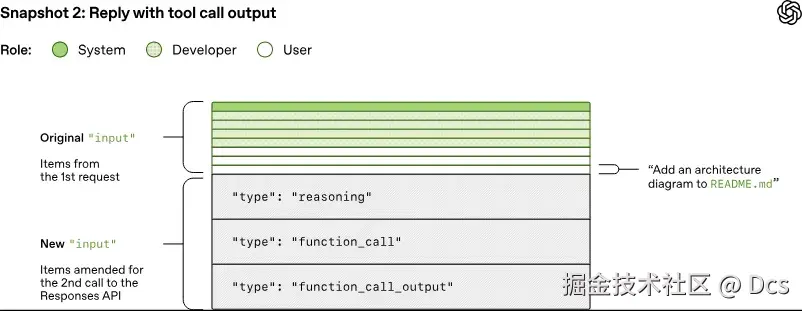
data: {"type":"response.completed","response":{...}}如果模型输出了 function_call,Codex 执行工具后会把 推理摘要、函数调用、函数输出 一股脑追加回下一次请求的 input,示例:
javascript
[
/* ... original items ... */
{
"type": "reasoning",
"summary": [
{"type": "summary_text", "text": "**Adding an architecture diagram for README.md**\n\nI need to..."}
],
"encrypted_content": "gAAAAABpaDWNMxMeLw..."
},
{
"type": "function_call",
"name": "shell",
"arguments": "{\"command\":\"cat README.md\",\"workdir\":\"/Users/mbolin/code/codex5\"}",
"call_id": "call_8675309..."
},
{
"type": "function_call_output",
"call_id": "call_8675309...",
"output": "<p align=\"center\"><code>npm i -g @openai/codex</code>..."
}
]对应的第二张快照图:
当模型终于输出 assistant message(不再请求工具)时,这个 turn 才算结束:
txt
data: {"type":"response.output_text.done","text":"I added a diagram to explain...", ...}
data: {"type":"response.completed","response":{...}}用户再发一句话,就进入下一 turn:需要把上一次 assistant message 和本次 user message 一起追加进去:
javascript
[
/* ... all items from the last request ... */
{
"type": "message",
"role": "assistant",
"content": [{ "type": "output_text", "text": "I added a diagram to explain the client/server architecture." }]
},
{
"type": "message",
"role": "user",
"content": [{ "type": "input_text", "text": "That's not bad, but the diagram is missing the bike shed." }]
}
]第三张快照图更能说明:这玩意儿会一直长一直长......

4)性能:请求体"看似二次方",但缓存命中能救命
很多同学看到"每次把所有历史 input 都带上"第一反应:这不就是网络传输二次方增长吗? 没错。
Responses API 支持 previous_response_id 来减少重复传输但Codex 当前选择不用它,主要为了两点:
- 保持请求无状态:对 API 提供方更友好。
- 支持 ZDR(Zero Data Retention) :不在服务端存历史数据,避免与"零数据保留"冲突;同时 reasoning 的
encrypted_content允许服务端解密以保留"模型理解",但不持久化用户数据本身。
真正的性能关键在于:prompt caching。缓存命中要求非常苛刻:必须是精确的前缀匹配 。因此缓存命中要求非常苛刻:必须是精确的前缀匹配。因此) Codex 特别强调"旧 prompt 是新 prompt 的 exact prefix",这不是强迫症,是省钱省到骨子里了😂。
哪些变化会导致 cache miss?
- 中途改
tools(甚至工具顺序不稳定都会炸) - 改
model(模型内置指令变了) - 改沙箱配置、审批策略、cwd 等
Codex 的一个经典教训:早期接入 MCP 工具时,因为 工具枚举顺序不一致 导致缓存频繁失效(工具数量一多,直接"性能心电图"📉)。
为了尽量保住前缀,Codex 对"中途配置变更"的处理是:追加新消息,而不是修改旧消息:
- 沙箱配置/审批模式变化:追加新的 developer
<permissions instructions> - cwd 变化:追加新的 user
<environment_context>
这招非常值得抄作业:你改的是"环境状态",但你不能动 prompt 的"历史前缀"。
5)上下文窗口:不够用怎么办?压缩(compaction)才是正解
Agent 聊着聊着就爆 context window,这事不是"会不会发生",而是"什么时候发生"。Codex 的策略是超过阈值就 compact :把冗长的 input 替换成一个更短、但能代表历史的 item 列表,让后续推理还能"记得发生过啥"。
早期需要手动 /compact;后来 Responses API 提供了专门的 compaction endpoint: platform.openai.com/docs/guides...
它会返回一组可直接替代原 input 的 items,其中包含 type=compaction 以及不透明的 encrypted_content,用于保留模型的"潜在理解"。Codex 现在会在超过 auto_compact_limit 后自动触发这件事。
6)给做 Java/Python 工程化 Agent 的"抄作业清单"✅
把 Codex 的设计拆完,可以总结出几条非常硬核、非常工程的结论:
- 把 prompt 当"不可变日志"来设计 追加新事件,不修改旧事件。你改旧的,缓存就没了;你改多了,定位就疯了。
- 工具列表要稳定排序 + 版本可控 工具顺序不稳定 ≈ 主动放弃缓存。生产环境别玩"每次启动动态扫描全部工具再随机排列"的刺激游戏。
- 权限/沙箱必须写进 prompt 这不是文档,这是模型行为约束的一部分。尤其是 shell 这类高危工具,不写清楚"哪些目录可写、何时需要用户确认",迟早出事故。
- 流式事件要落地成结构化记录 SSE 不只是展示给用户看的"打字效果",而是下一轮推理的输入材料。要能回放、能审计、能复现。
- 上下文管理要有自动化机制 compaction 不是锦上添花,是续命针。阈值触发、摘要策略、加密理解保留,都是工程必须项。
当 Agent loop 真正做对了,你会发现"让模型写代码"不再是玄学,更像一套可控的流水线:可追溯、可审计、可缓存、可压缩、可扩展。
而 Codex 把这套"写代码的 AI 代理"最核心的一环------loop------摊开讲清楚了:所谓智能体,很多时候并不是模型多聪明,而是 harness 多靠谱。
(Codex 开源仓库: github.com/openai/code... )
喜欢就奖励一个"👍"和"在看"呗~
