前言:最近在整理项目中用到的技术栈,今天总结一下
茶杯图库工坊的缓存与数据库一致性问题:
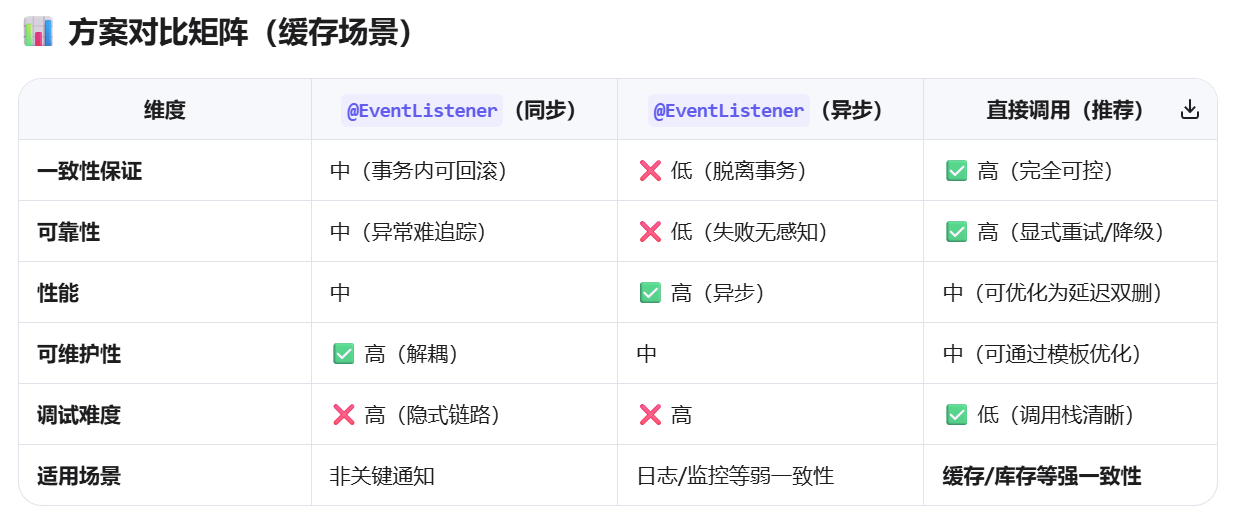
在这里我们选择使用的是:直接调用方式

可以看到,我们这里在MySQL数据库中删除对应的图片信息后立刻直接调用清理缓存 了,后续可以加入异步延时双删
对于我们常用的方案即:@EventListener 实现观察者模式,之所以没有采用,主要有于以下原因:
┌─────────────────────────────────────────────────────────────────┐
│ Spring 容器启动阶段 │
├─────────────────────────────────────────────────────────────────┤
│ 1. @EventListener 方法扫描 │
│ 2. 创建 ApplicationListenerMethodAdapter │
│ 3. 注册到 ApplicationEventMulticaster │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 运行时事件处理阶段 │
├─────────────────────────────────────────────────────────────────┤
│ 1. publishEvent() → ApplicationEventMulticaster │
│ 2. 事件类型匹配 → 找到所有适配的监听器 │
│ 3. 顺序/条件/异步处理 → 执行监听方法 │
└─────────────────────────────────────────────────────────────────┘✅ 适用场景
非关键路径:日志记录、统计分析、邮件通知等最终一致性可接受的场景
业务解耦:跨模块松耦合通信(如订单创建 → 积分系统)
❌ 缓存场景致命缺陷
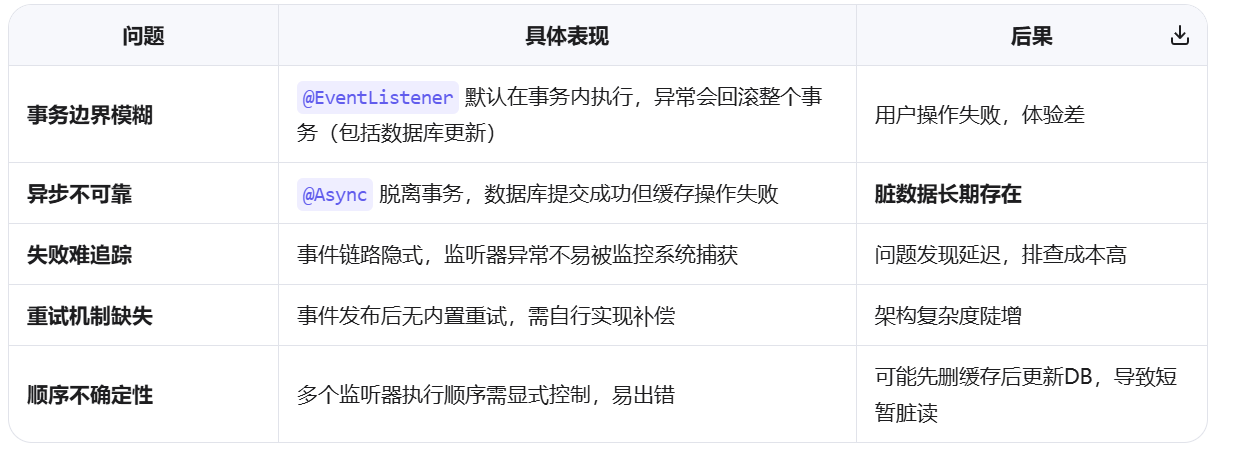
因此,如果使用@EventListener处理缓存一致性问题的话,常出现:
-
@EventListener 不确定会在当前线程执行还是其他线程执行,如果异步实现,可能也不知道何时执行
-
// Spring 事件处理流程包含:
-
ApplicationEventMulticaster 查找监听器
-
反射调用监听方法
-
事务管理和异常处理
-
线程池调度(如果使用 @Async)
3.延迟方面
// 直接调用场景 - 用户体验优秀
用户删除图片 → 立即清理缓存 → 下次查询显示最新数据
总延迟:< 1ms
// @EventListener 场景 - 可能出现不一致
用户删除图片 → 事件排队处理 → 缓存延迟清理 → 下次查询可能看到旧数据
总延迟:100ms+
那么对于直接调用的方式:
✅ 缓存场景核心优势
| 优势 | 说明 | 价值 |
|---|---|---|
| 强一致性保证 | 数据库与缓存操作在同一方法/事务内,失败统一回滚 | 避免脏数据 |
| 显式控制 | 执行顺序、重试逻辑、降级策略清晰可见 | 可预测、易维护 |
| 易于调试 | 调用栈完整,异常堆栈直接定位问题 | 运维成本低 |
| 可靠性高 | 可实现完善的重试、熔断、补偿机制 | 生产环境稳定 |
一句话总结
缓存一致性是"可靠性优先"场景,事件机制的"隐式解耦"反而增加不确定性;直接调用虽耦合稍高,但通过模板方法/策略模式可优雅封装,换来的是可预测、可监控、可修复的强一致性保障。
记住 :设计模式是工具,不是教条。在缓存这种对数据正确性要求极高的场景,显式 > 隐式,可控 > 解耦。
这里顺便讲一下这个方案:canal 监听 mysql binlog
Canal 是阿里巴巴开源的 MySQL binlog 增量订阅组件 ,通过伪装成 MySQL 从库(Slave)拉取 binlog,解析后投递给下游消费者。在缓存一致性场景中,它提供了一种业务代码零侵入的解决方案。
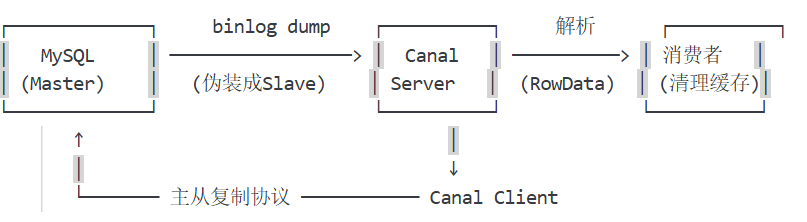
核心流程
- 伪装 Slave :Canal 向 MySQL 发送
COM_REGISTER_SLAVE+COM_BINLOG_DUMP命令 - 拉取 binlog:MySQL 将 binlog 事件流式推送给 Canal
- 解析事件 :Canal 解析为结构化数据(如
UpdateRowsEvent) - 投递消费:通过 TCP/HTTP/Kafka/RocketMQ 投递给业务系统
- 清理缓存:消费者根据事件内容删除/更新对应缓存
✅ Canal 方案优势
| 优势 | 说明 | 价值 |
|---|---|---|
| 业务零侵入 | 无需修改业务代码,缓存逻辑完全解耦 | 降低代码复杂度,避免缓存逻辑污染核心业务 |
| 彻底解耦 | 数据库与缓存通过 binlog 异步联动 | 服务可独立演进,避免循环依赖 |
| 多端消费 | 一份 binlog 可同时投递给缓存、ES、数仓等 | 统一数据出口,避免多处写重复逻辑 |
| 可靠性高 | Canal 支持 ACK 机制,失败可重试 | 消息不丢失(需配合持久化队列) |
| 扩展性强 | 支持 Kafka/RocketMQ 等 MQ,方便水平扩展 | 应对高并发场景 |
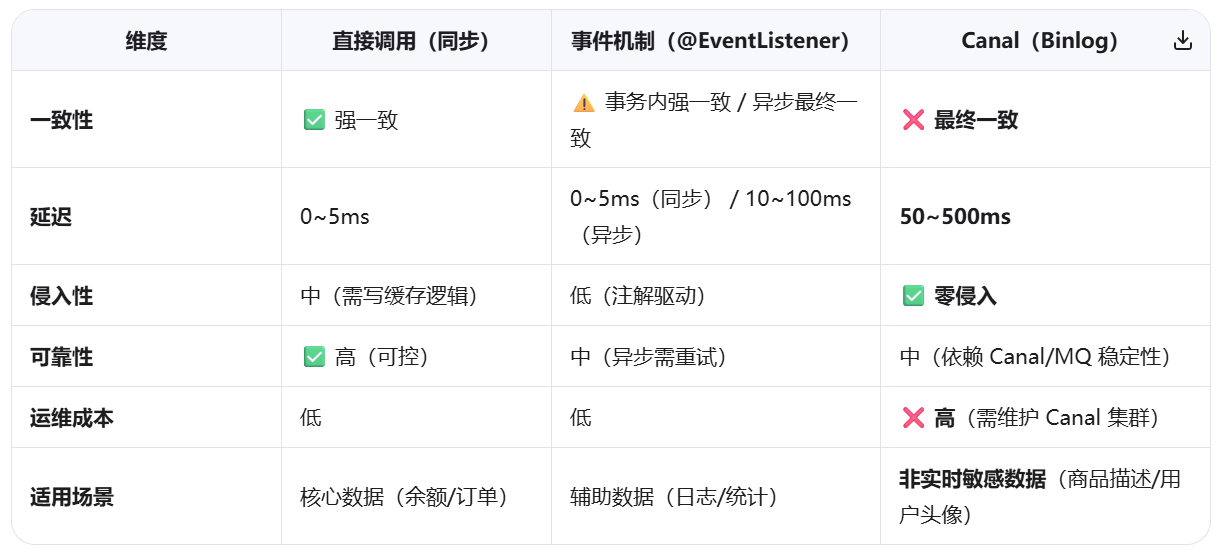
核心缺陷:最终一致性 + 延迟风险
1️⃣ 一致性模型对比
| 方案 | 一致性级别 | 典型延迟 | 脏数据窗口 |
|---|---|---|---|
| 直接调用 | 强一致性 | 0(同步) | 无 |
| Canal | 最终一致性 | 50~500ms | 存在 |
| 纯异步事件 | 最终一致性 | 10~100ms | 存在 |
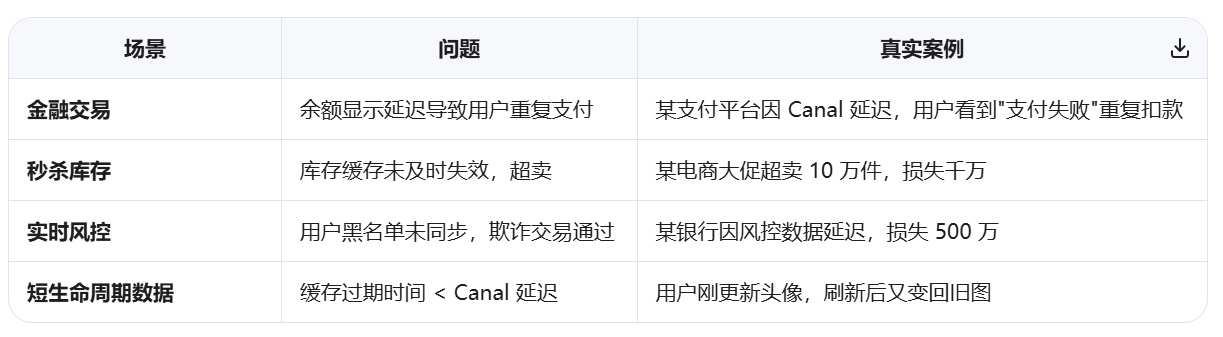
💡 关键问题 :Canal 从 binlog 产生 → 解析 → 投递 → 消费 → 清理缓存,至少存在 50~500ms 延迟。在此窗口期内:
- 用户更新数据 → 立即刷新页面 → 仍看到旧缓存(体验差)
- 金融/交易场景:余额显示错误 → 用户投诉
三种方案综合对比
生产环境推荐策略:分层混合架构
✅ 核心原则:按数据敏感度分层处理
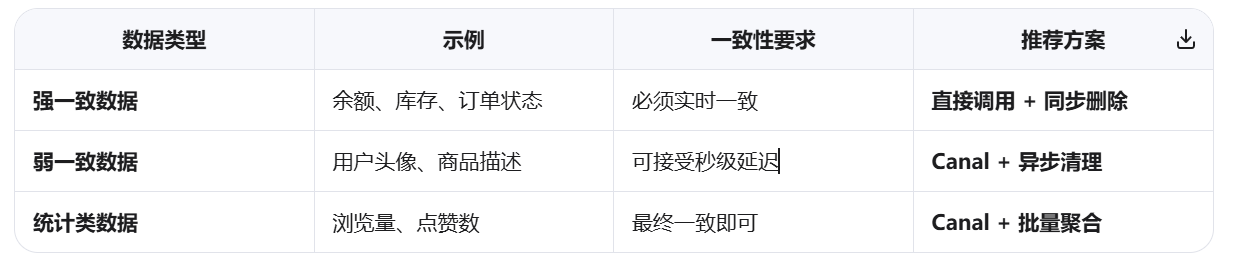
降低 Canal 延迟的优化技巧

不推荐 Canal 的场景(血泪教训)
一句话总结
Canal 是优秀的「最终一致性」解决方案,但绝不能用于强一致场景。
- ✅ 适合 :商品描述、用户头像、文章内容等非实时敏感数据
- ❌ 禁用 :余额、库存、订单状态等强一致要求数据
- 🚀 最佳实践 :核心数据直接调用 + 非核心数据 Canal 异步同步,分层治理