文章:Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training
代码:暂无
单位:META、牛津大学
这篇文章挺有意思,但是更多偏分析,流程图偏少,推荐大家有空去看看。
一、问题背景
当下大语言模型的一个神奇现象引发了学界广泛关注:仅用文本训练的LLM,从未见过一张图片,却能形成丰富的视觉先验知识,这种隐性知识让模型具备了潜在的视觉能力。只需少量多模态数据微调,就能将这份能力激活,实现视觉问答、图像理解等任务,甚至部分场景下无需视觉数据也能完成视觉推理。
但此前的研究始终未能说清:LLM的视觉先验知识究竟从何而来?是单一的能力模块,还是由不同能力组成?不同的文本预训练数据,对视觉先验知识的形成影响如何?这些问题的答案,直接决定了如何针对性地训练出视觉能力更强的多模态大模型(MLLM),也是当前多模态研究领域亟待解决的核心问题。
与此同时,学界的柏拉图表征假说也为研究提供了理论支撑:当模型在多样数据和任务中不断缩放时,无论基于文本还是图像训练,其潜在表征都会收敛到对现实世界的统一统计模型,文本和图像只是世界的不同"投影",强大的模型能从单一模态中学习到世界的底层结构------这也为LLM从文本中习得视觉知识提供了合理性。
二、方法创新
为了拆解LLM的视觉先验知识,研究团队设计了一套系统性的研究方法,核心创新点体现在三个方面,且整个研究基于超100组对照实验,耗费50万GPU小时,覆盖MLLM构建全流程,确保结论的严谨性:
-
精细化拆解视觉先验知识 :首次将LLM的视觉先验知识拆分为感知先验 和推理先验两大独立模块,分别探究其形成机制和影响因素,打破了此前将视觉先验视为单一能力的认知。
-
多维度变量控制实验:从模型规模(340M-13B参数)、数据规模(0B-1T tokens)、数据来源(16类文本,含代码、数学、艺术、网页爬取等)、数据混合比例、视觉编码器类型、视觉指令微调数据六大维度,进行对照实验,精准定位不同因素对视觉先验知识的影响。
-
打造专属评估工具与训练策略 :① 提出MLE-Bench(多层存在基准) ,专门用于精细化评估模型的感知能力,弥补了传统基准在感知能力评估上的不足;② 设计盲视觉指令微调 技巧,既可以提升模型的视觉适配效率,也能探究模型如何通过语言"破解"视觉任务;③ 推导出数据中心的预训练配方,通过平衡推理型文本和视觉描述型文本的比例,针对性培养LLM的视觉先验知识。
此外,研究还采用了两阶段MLLM适配策略(视觉对齐+监督微调),并设计了鲁棒的VQA评估解析方法,避免因模型输出格式问题导致的评估偏差,让实验结果更精准。
三、实验结果
经过大规模对照实验,研究团队得出了6项核心发现,同时在1T token规模下验证了新预训练配方的有效性,关键结果如下:
-
视觉能力缩放规律非均匀:VQA性能整体随模型和数据规模提升,但不同视觉任务差异显著------OCR/图表问答更依赖模型规模,视觉中心型问答则让大模型从更多数据中获益更多,小模型易触顶。
-
数据来源决定视觉能力偏向:推理型文本(代码、数学、学术)和视觉描述型文本(艺术、美食),能显著提升模型的视觉中心型任务表现,不同文本源会培养出不同的视觉先验。
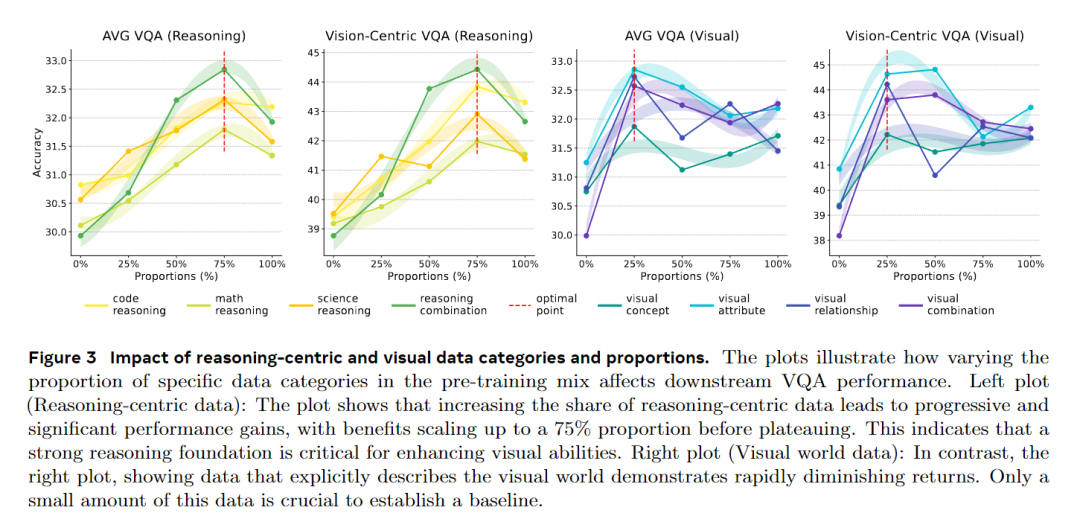
-
两类核心文本的影响差异显著:视觉描述型文本是基础,但其作用会快速饱和,少量即可;推理型文本的作用则持续提升,比例达75%时仍能带来性能增益。
-
最优数据混合比例出炉 :视觉任务最优配比为60%推理型文本+15%视觉描述型文本,并非单纯增加视觉文本比例;而平衡语言和视觉能力的最优配比(mix6),能在不损失语言性能的前提下,大幅提升视觉能力。
-
视觉先验的两大模块来源不同:感知先验来自广泛的多样化文本,无特定数据源;推理先验则主要由推理型文本培养,且可逐步缩放,二者为相互独立的模块。
-
两大模块的依赖主体不同:视觉推理能力主要来自LLM的文本预训练推理先验,具备模态无关的通用性,不受视觉编码器影响;感知能力则更依赖视觉编码器的特性和后续的视觉指令微调数据。
在1T token规模的7B模型验证中,采用新配方的平衡模型相比纯语言优化模型,不仅语言性能(困惑度、准确率)略有提升,还在所有视觉任务中实现全面超越,整体VQA准确率从37.32%提升至38.64%,验证了方法的有效性。
此外,MLE-Bench实验显示,感知先验具有尺度依赖性,多样化文本训练的模型更擅长识别中小尺寸物体;盲视觉指令微调则能进一步提升模型视觉性能,尤其在知识型问答中效果显著。
四、优势与局限
核心优势
-
理论层面:首次系统性拆解了LLM视觉先验知识的结构和起源,为柏拉图表征假说提供了强有力的实证支撑,深化了对跨模态表征学习的理解,解释了"文本训练的模型为何能懂视觉"的核心问题。
-
实践层面 :提出了可落地的LLM预训练数据配方,让开发者能从预训练阶段主动培养视觉先验知识,而非后续微调被动激活,大幅提升MLLM的训练效率,减少多模态数据的依赖,为下一代MLLM的研发提供了清晰的方向。
-
工具层面:提出的MLE-Bench和盲视觉指令微调技巧,成为多模态研究领域的新工具,为后续精细化评估和训练模型提供了参考。
-
结论普适性:实验覆盖多模型规模、多数据类型、多视觉编码器,结论具有较强的通用性,可迁移至不同的MLLM架构中。
研究局限
-
架构适配性有限:研究主要基于适配器式MLLM架构,结论未必适用于离散视觉令牌化、视觉-语言端到端联合训练的架构,后续需进一步验证。
-
未考虑安全伦理问题:研究聚焦于模型能力,未探究文本中的偏见、刻板印象是否会通过视觉先验知识,在MLLM中形成有害的视觉关联,存在潜在的公平性风险。
-
模态覆盖单一:研究仅针对静态图像,未涉及视频等动态视觉模态,无法解释LLM的视觉先验知识在时序推理、动作识别等动态视觉任务中的作用。
-
盲微调的潜在问题:盲视觉指令微调虽能提升性能,但会导致模型在无图像时产生幻觉回答,违背"无视觉输入则识别缺失"的合理逻辑,这一问题仍需解决。
五、一句话总结
这项研究通过大规模对照实验,首次拆解了LLM从文本中习得的视觉先验知识为感知和推理两大独立模块,明确了其各自的形成机制和影响因素,提出了针对性培养视觉先验知识的文本预训练配方,在理论上验证了跨模态统一表征的合理性,在实践上为下一代视觉感知能力更强的多模态大模型研发提供了可落地的方法论,让LLM从"学文字"到"懂视觉"的过程从偶然走向必然。