在当前目录下,有一个myprocess.c文件。想要运行这个文件就要先对这个文件进行编译生成可执行程序。

现在已经有了myprocess这个可执行程序。我们来运行它。

成功运行该程序。
我们可以知道,这个可执行程序在当前目录下。本质上这个程序就在硬盘里。
想要运行程序时,就要先把这个程序加载到内存中才可以执行。
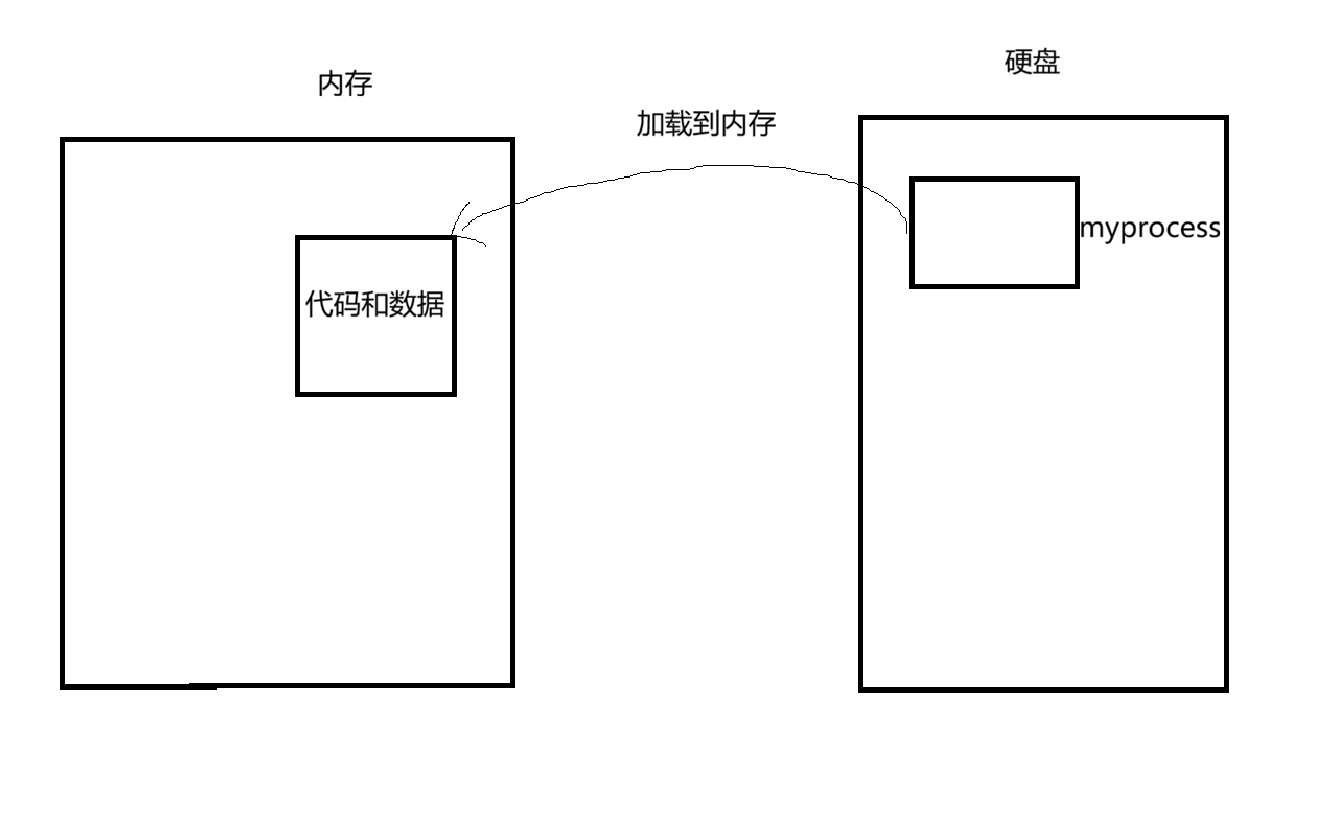
在实际过程中,不可能只有这一个可执行程序被加载到内存中,一定会有其它的可执行程序被加载到内存中。
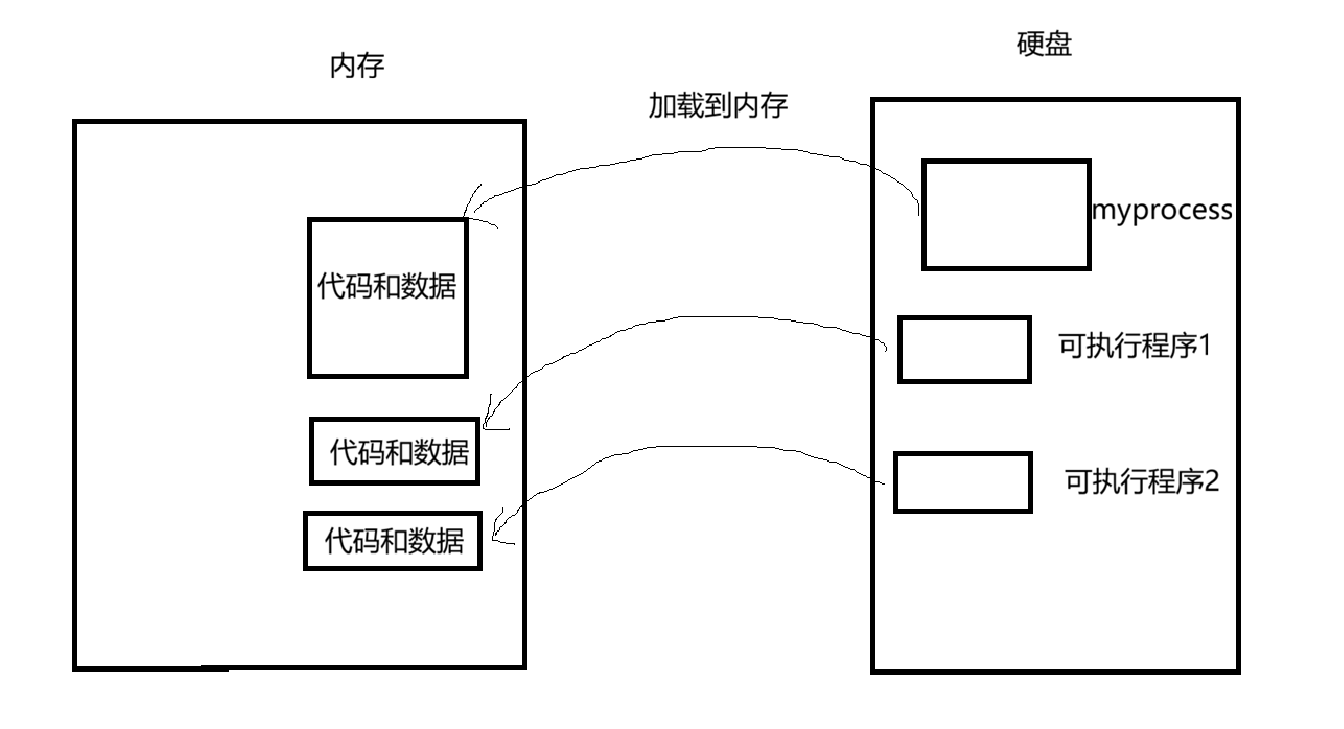
当可执行程序的代码和数据加载到内存运行时,就被称为进程。单仅仅加载到内存是不够的。操作系统目前还无法分辨各个进程之间的区别。这时候就需要PCB(进程控制块),PCB是一个结构体,里面包含着进程的属性,如 pid(唯一表示进程),优先级、代码地址、数据地址等属性。PCB描述着进程的相关信息。
在Linux中的PCB是 task_struct 这个结构体。所以当进程加载到内存的时候,还会创建PCB,记录着该进程的信息。
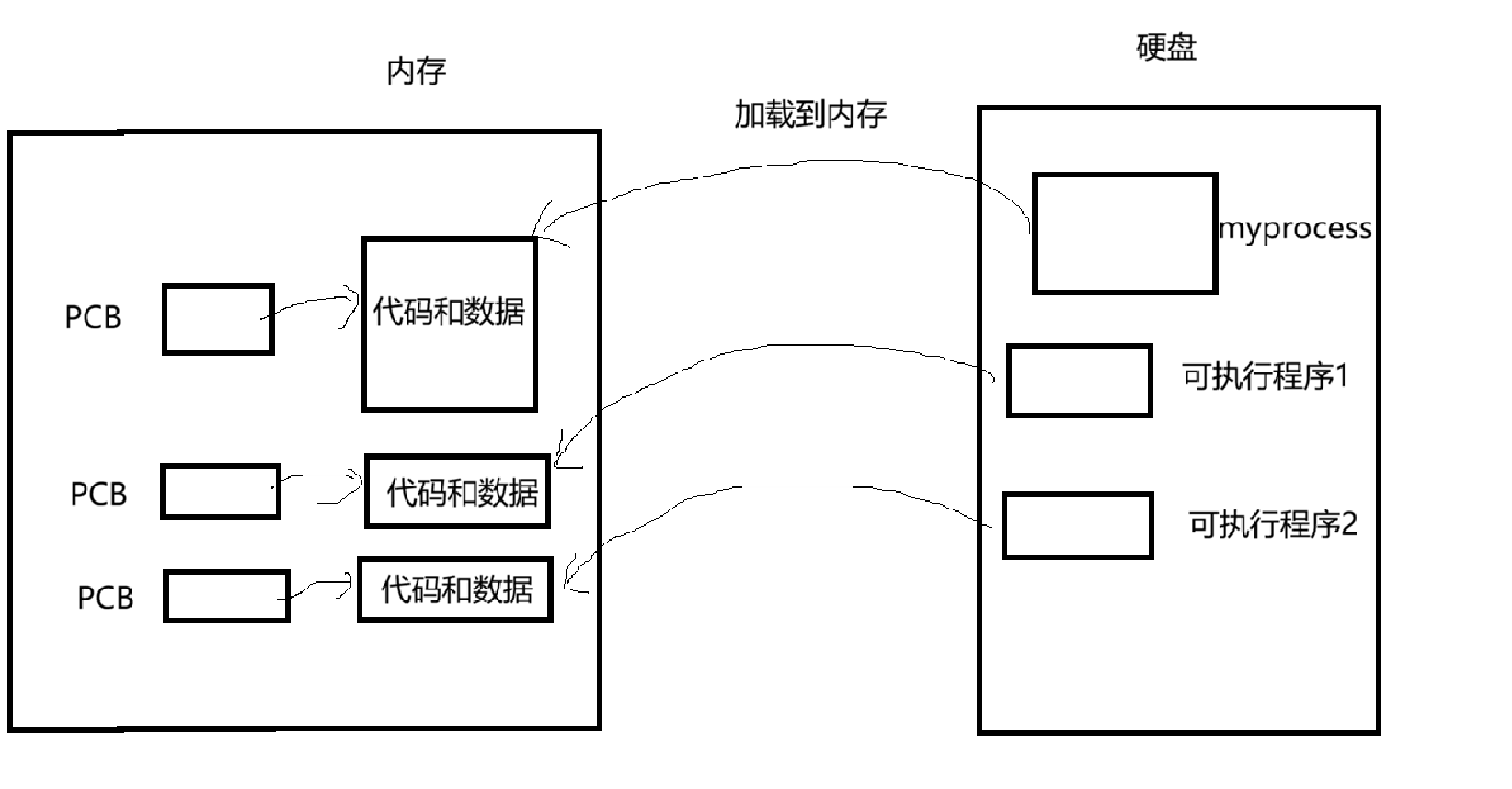
在task_struct这个结构体里面还有该结构体的指针,用来指向PCB,所以PCB之间使用该结构体的指针进行链接
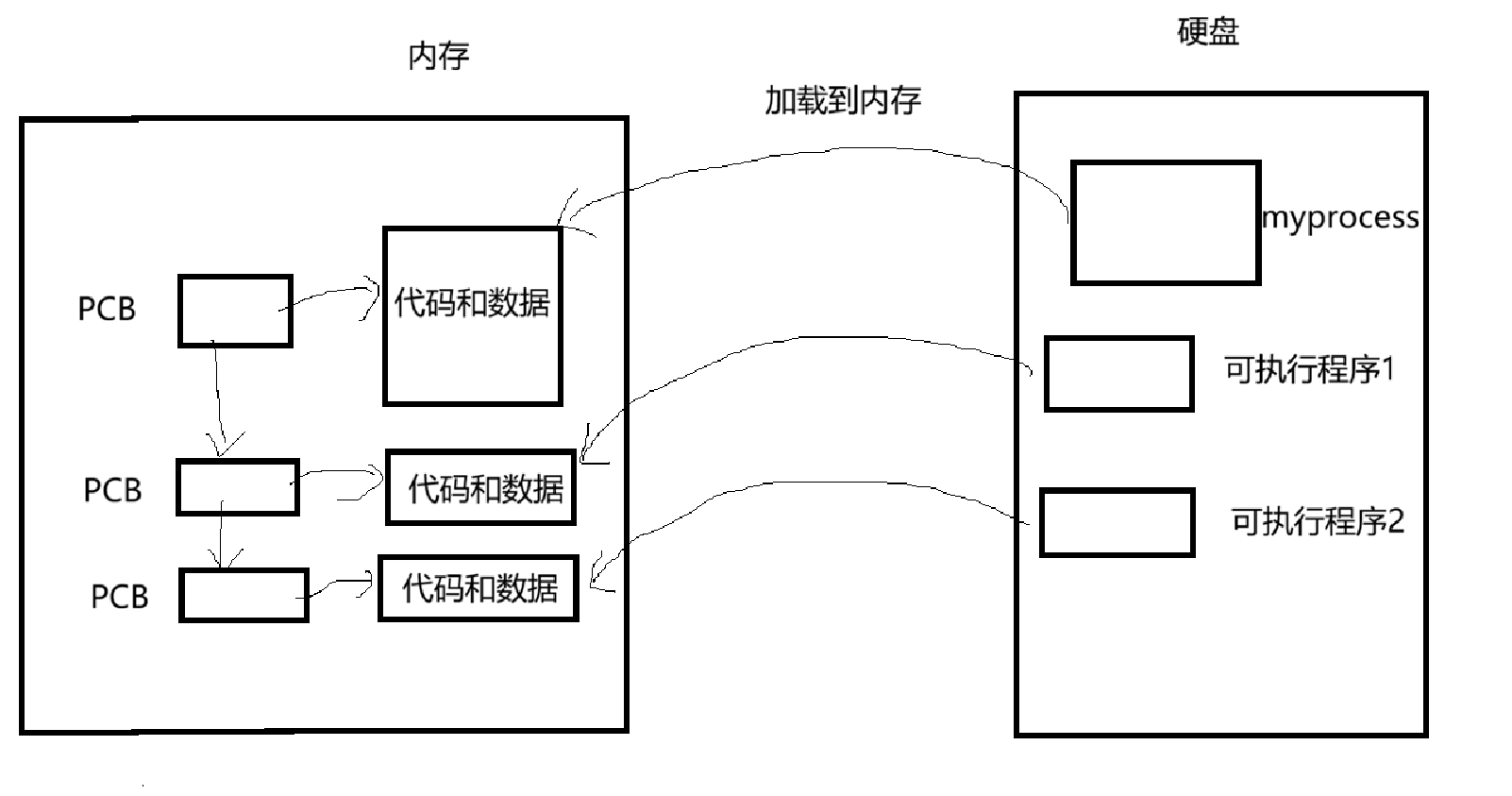
既然是用指针进行链接,那么就是链表。在Linux中是用双向循环链表来实现的。
为了简化讲解,这里的图就用单链表来代替。
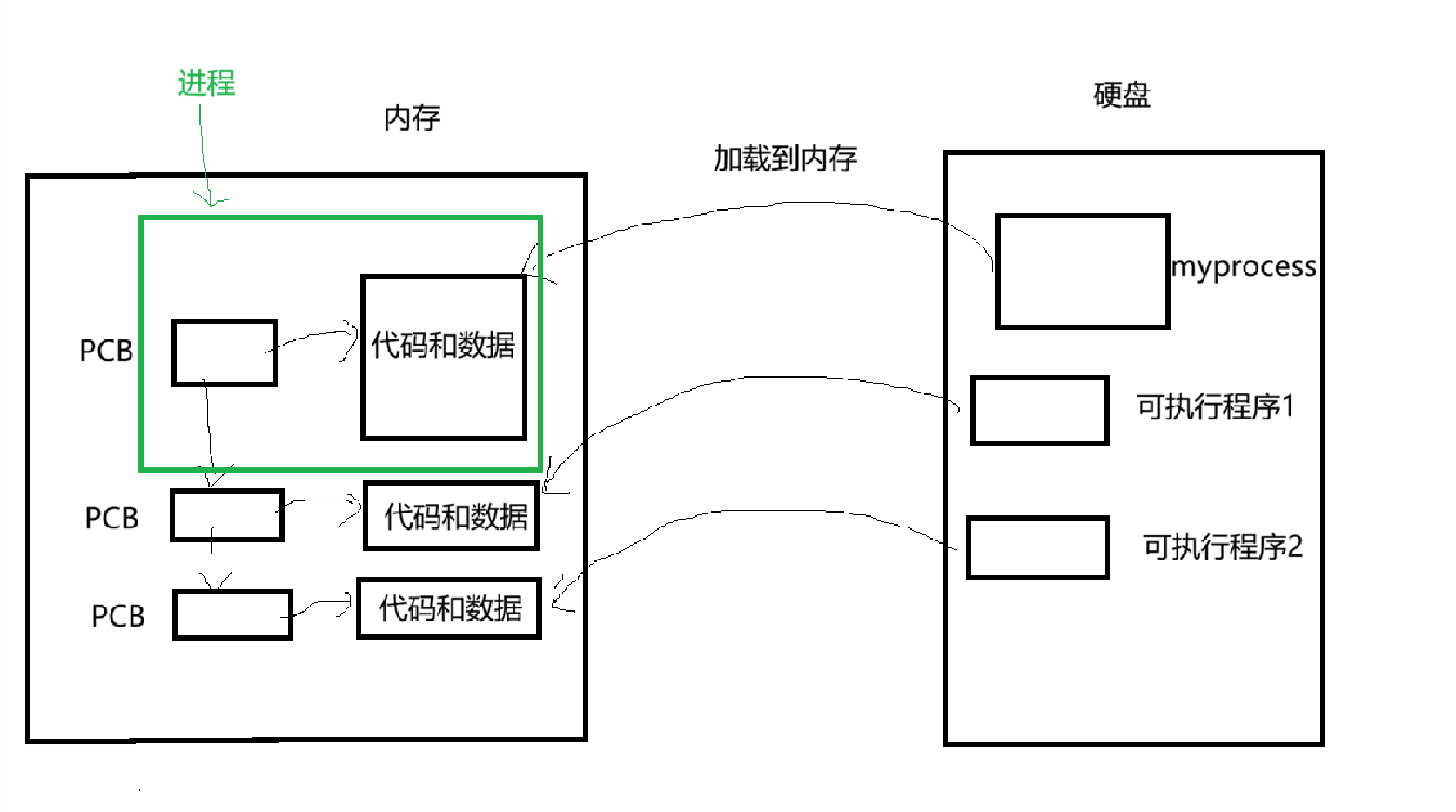
这里就修改一下进程的理解,进程 = PCB(task_struct) + 自己的代码和数据。
我们之前的指令如ls、pwd、mkdir是指令,也是程序。所以在使用这些指令时,也会被加载到内存中运行起来,都是进程。
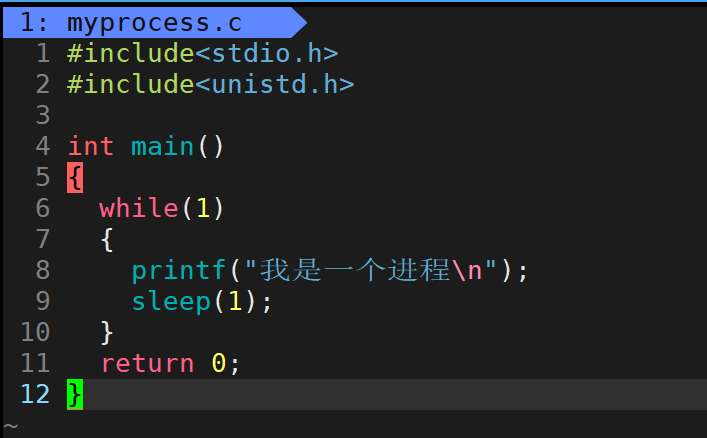
当前的代码是循环打印"我是一个进程",间隔1秒打印。
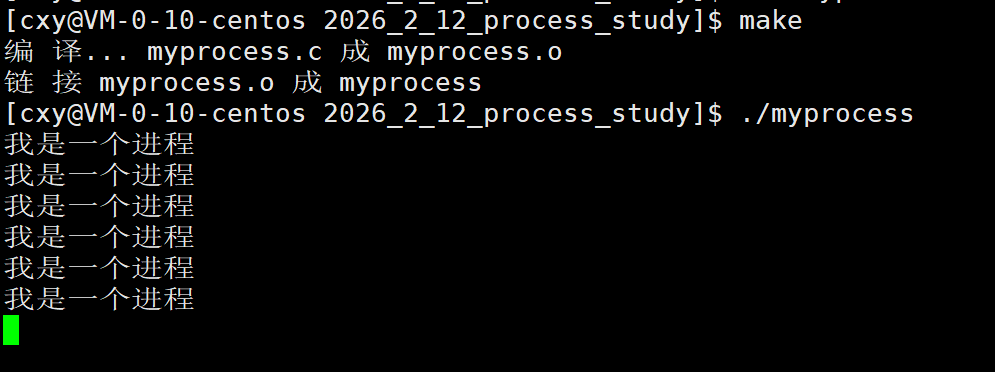
运行这个程序
这个程序正在循环打印着"我是一个进程"。既然这个程序可以运行,那么在内存中就有进程,该进程拥有着自己的PCB。
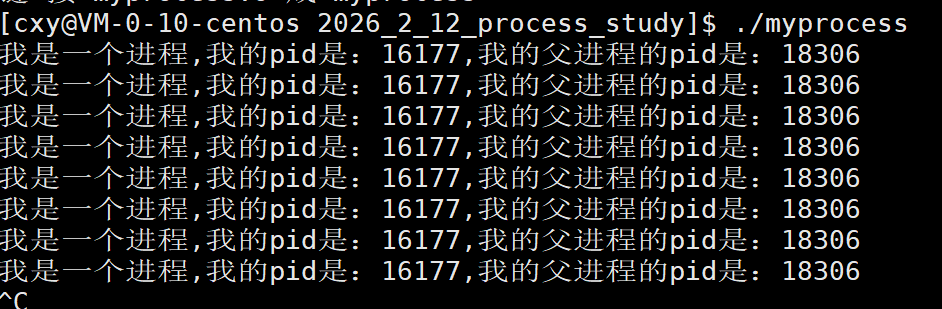
我们可以获取一下这个进程的pid(process id 进程标识符,用来唯一标识一个进程)
可以在代码中调用库函数getpid,可以获取当前进程的pid
现在运行这个程序。
成功获得了该进程的pid。
现在这个进程正在运行中,我们从新打开一个终端。
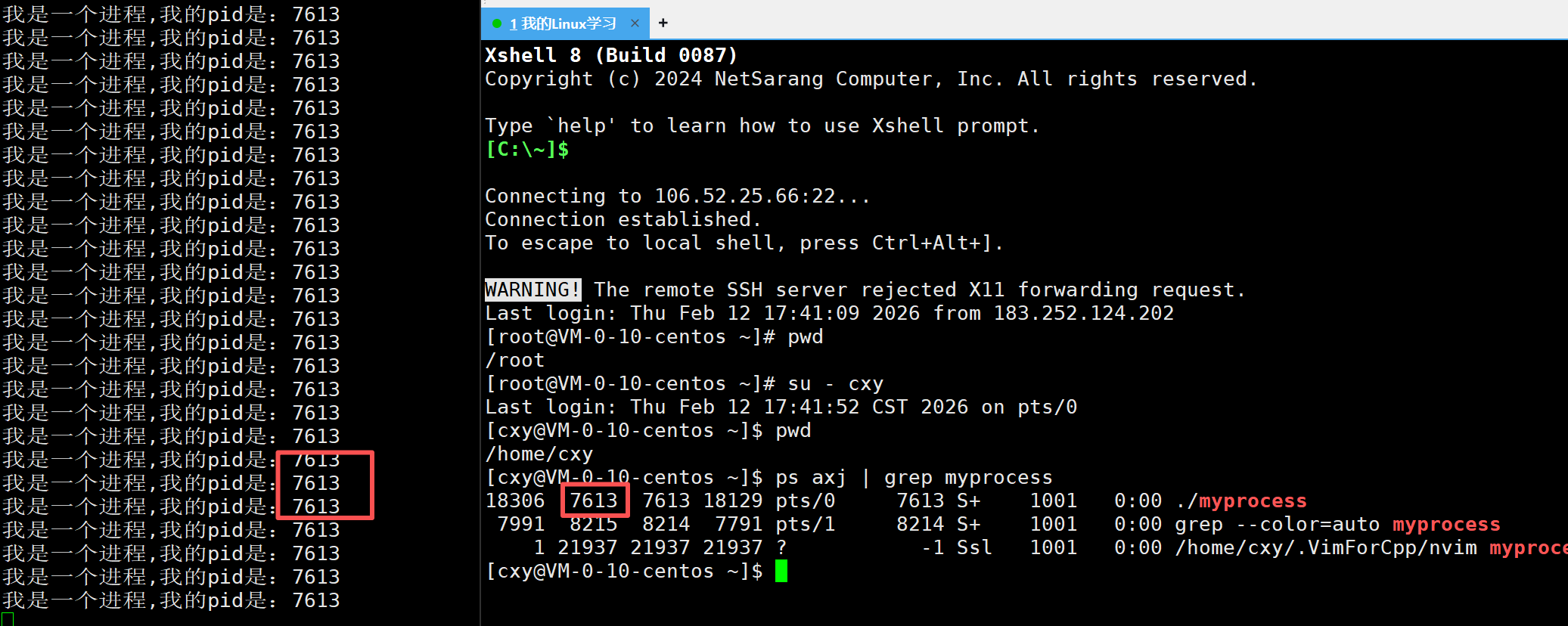
可以看见当前的pid
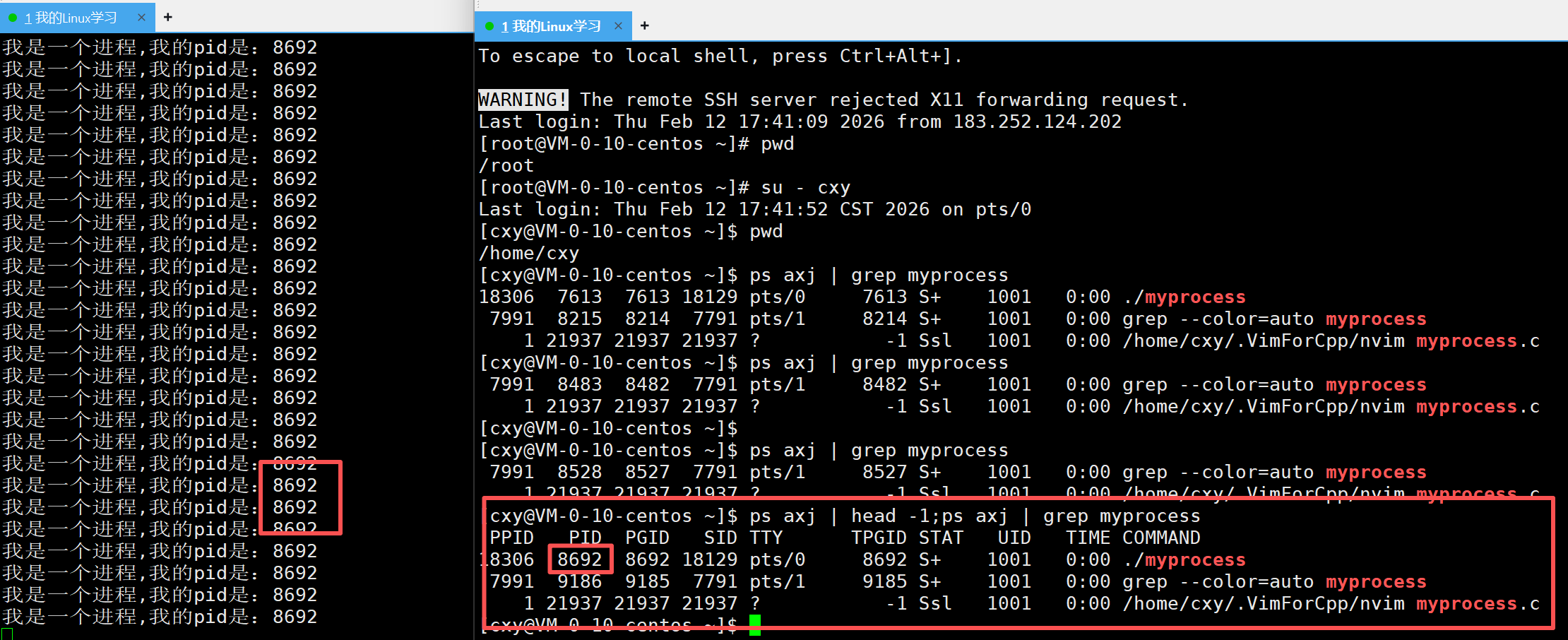
现在来讲一下这个命令

封号前面这句指令就显示

进程的属性
封号后面那句就是只过滤出myprocess的进程信息

两条指令通过封号(或者&&)连接起来,最终显示myprocess进程的属性和值

(注:我上下有些截图的pid值是不一样的,因为我终止了该进程又重新运行这个程序,操作系统给该进程重新分配了pid。所以上面的图片只需要看图片中左右两边终端进程的pid相等即可)
还可以通过查看目录来看进程的pid。
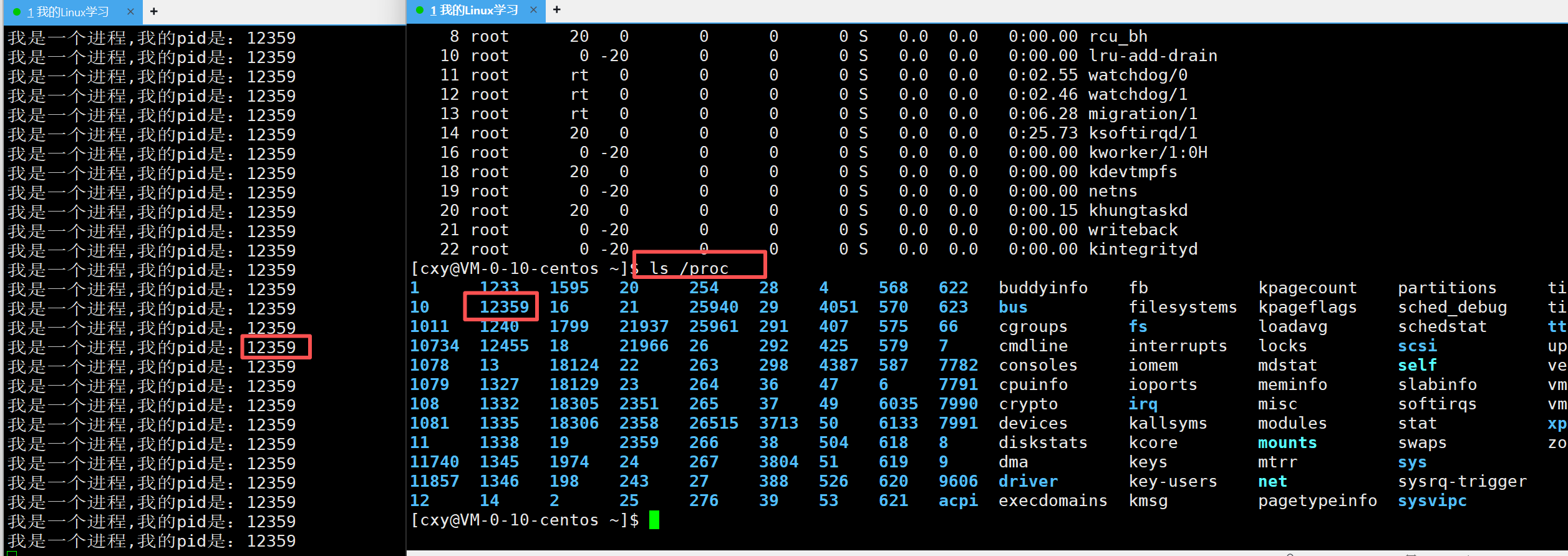
可以观察到左边的pid是12359,在proc这个目录下可以看见有一个目录的名称是12359

这条指令是只显示proc目录下的12359目录。
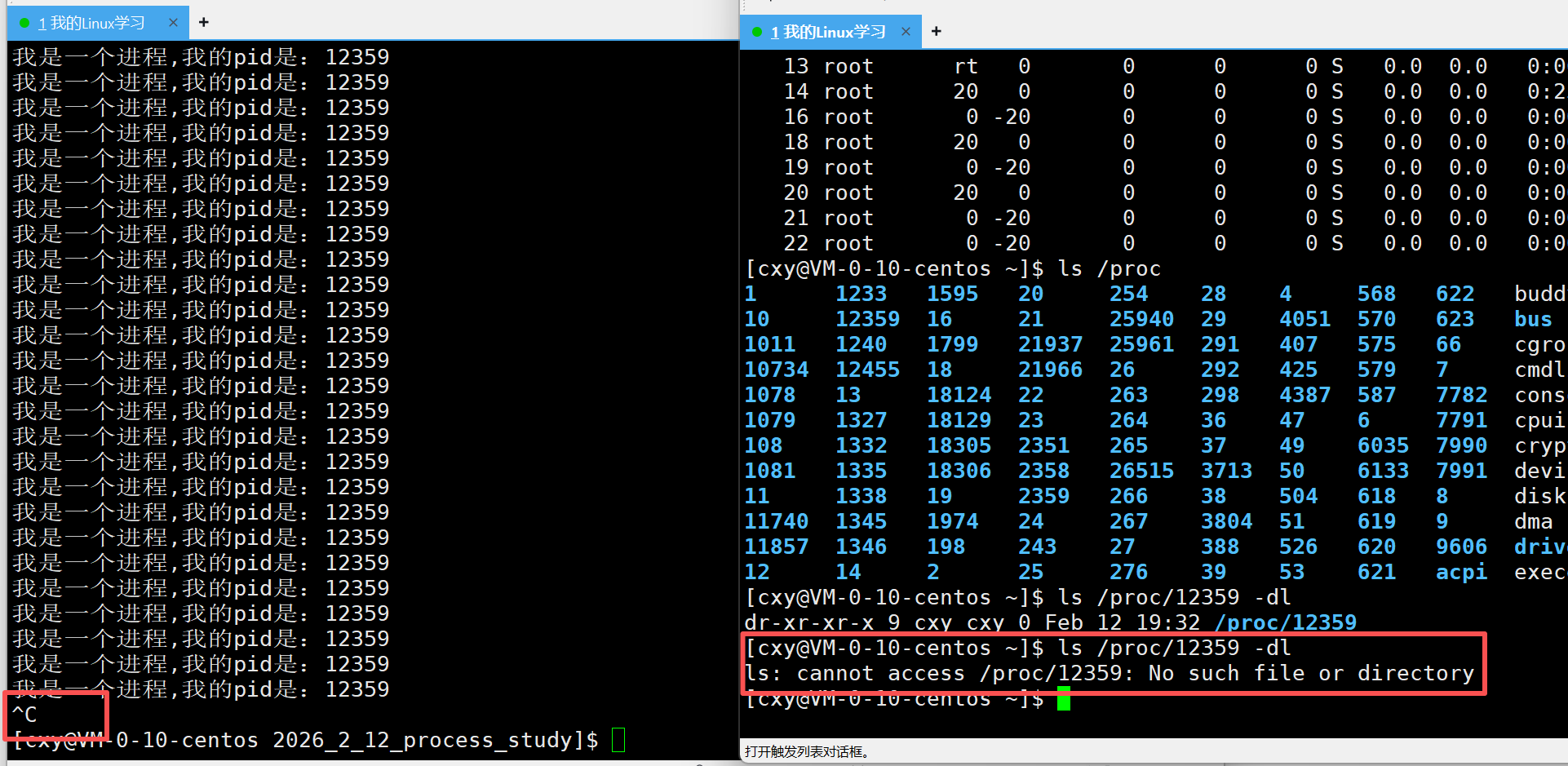
现在我们把左边终端的进程给杀死(Ctrl + c)
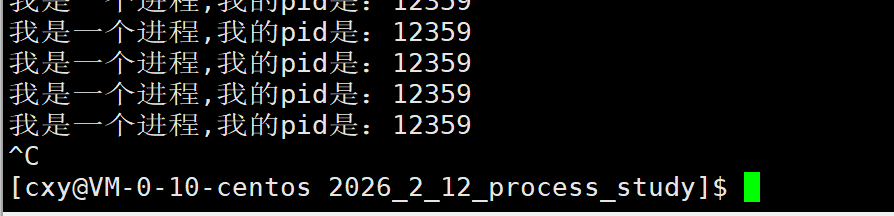
再去右变的终端查看,最终显示效果如下:
现在来讲库函数getppid(),获取父进程的pid。
在Linux中,基本所有的进程都是通过其父进程创建来的。
所以现在来了解一下父进程和子进程之间的关系。
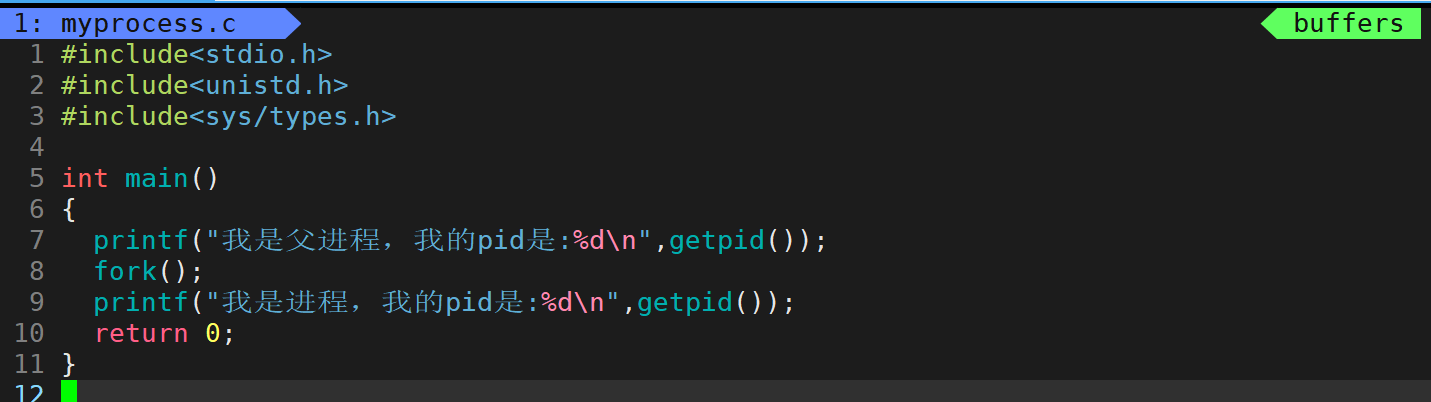
现在来显示一下父进程的pid
运行该程序。
可以显示当前进程的父进程的pid
现在来用代码来创建子进程,使用库函数fork()
刚开始执行这个代码时,只有一个执行流,也就是当前进程(父进程)。在执行到fork()的时候,就会编程两个执行流。一个是当前进程(父进程)和被fork()创建出来的子进程。
此时父进程会继续执行第9行及以下的语句,子进程也会执行第9行及以下的语句。
所以理论上最终结果就是先打印 "我是父进程,我的pid是:xxx",然后父进程接着打印"我是进程,我的pid是:xxx"。然后是子进程打印"我是进程,我的pid是:aaa"
现在来运行这个代码看看结果是否如上面所说,图片如下:

进程=PCB + 自己的数据和代码
刚开始运行时
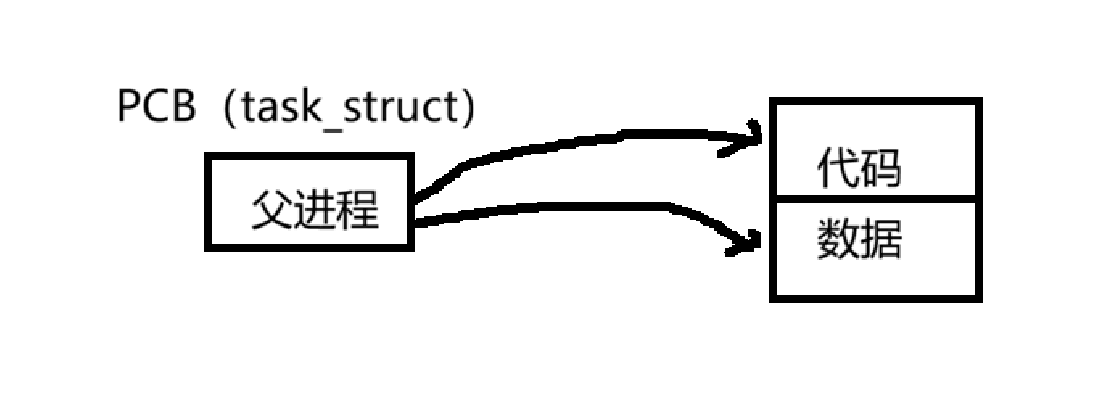
在使用fork()创建子进程的时候,本质上是新创建了一个新的进程。也就是有新的PCB。子进程的PCB是从父进程的PCB拷贝过来了。里面有很多属性的值都是一样单。但肯定要修改一些属性的值,如pid。
父进程是PCB + 自己的数据和代码,也就是父进程的PCB指向自己的数据和代码
子进程是PCB+ 数据和代码,子进程的PCB默认也是指向父进程的数据和代码。
这就是为什么上面的代码中,子进程在被调度之后会执行父进程之后的代码
所以目前子进程没有自己的代码和数据,只是共享父进程的代码和数据
现在执行man 2 fork命令来查看fork函数的返回值。


上面查看到了fork函数的返回值的相关信息。
成功时,将子进程的pid返回给父进程,并且给子进程返回0.
失败时给父进程返回-1,表示子进程创建失败。
所以我们就可以利用fork返回值。
现在来讲为什么fork函数需要给父进程和子进程返回不同的内容和是怎么给父进程返回一个值和给子进程返回一个值(返回不同的值)。
fork函数需要给父进程和子进程返回不同的内容:
这是因为一个父进程可以拥有多个子进程,但每个子进程只有一个父进程。也就是给fork给父进程返回子进程的pid时,是因为父进程可能会有多个子进程,所以需要返回子进程的pid。而子进程只有一个父进程,所以不需要返回父进程的pid,只需要给子进程返回0来表示该子进程创建成功。如果创建子进程失败就给父进程返回-1.
怎么给父进程返回一个值和给子进程返回一个值(返回不同的值):
这是因为在调用fork函数时,父进程会执行fork里面的函数,在return 之前其实子进程就已经创建好了甚至已经被调度。子进程并不是在fork函数return之后创建的。
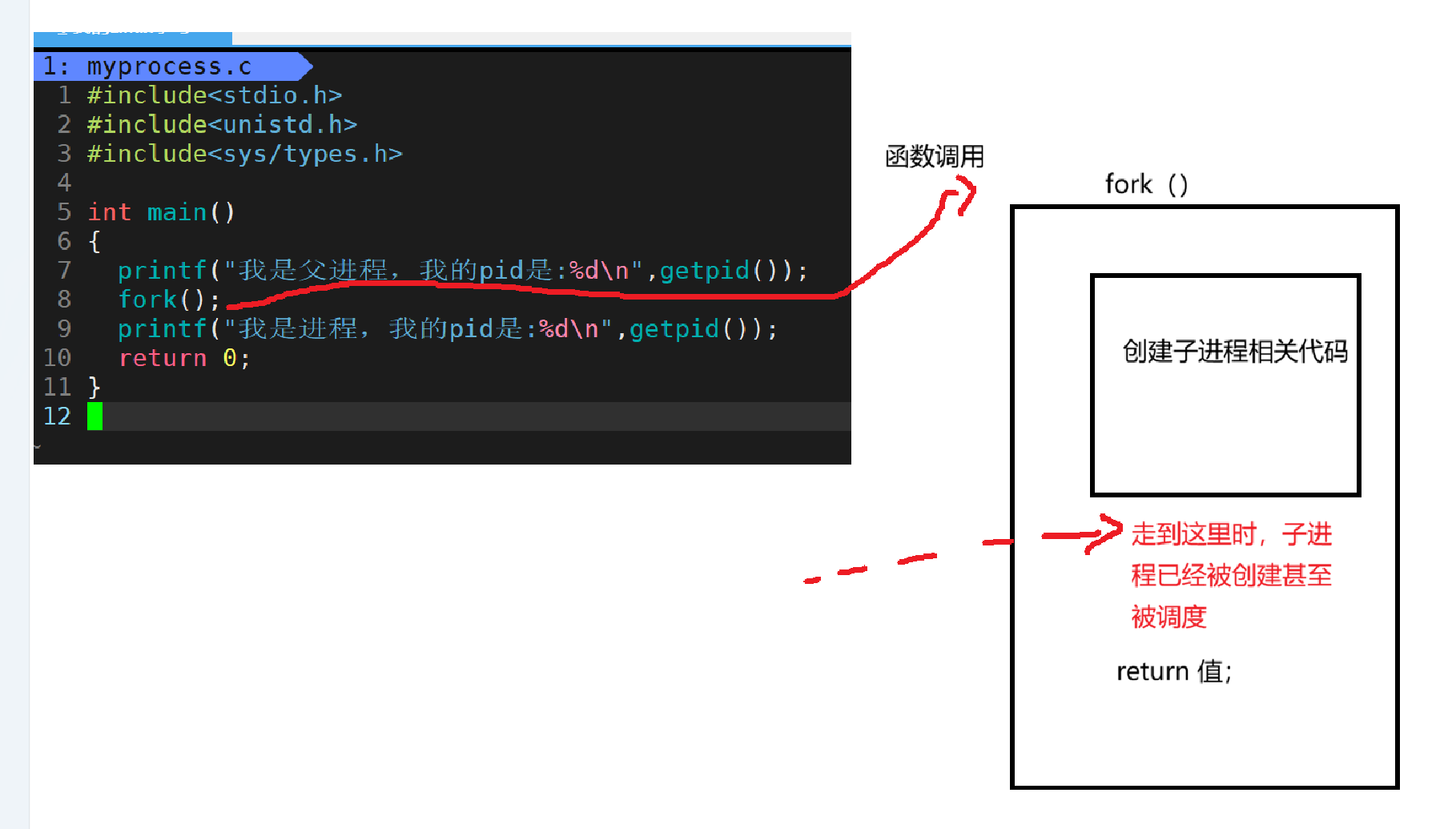
所以父进程会执行一次return语句,子进程也会执行一次return语句。
所以我们就可以根据fork给父子进程返回的内容来让父进程和子进程执行不同的代码。
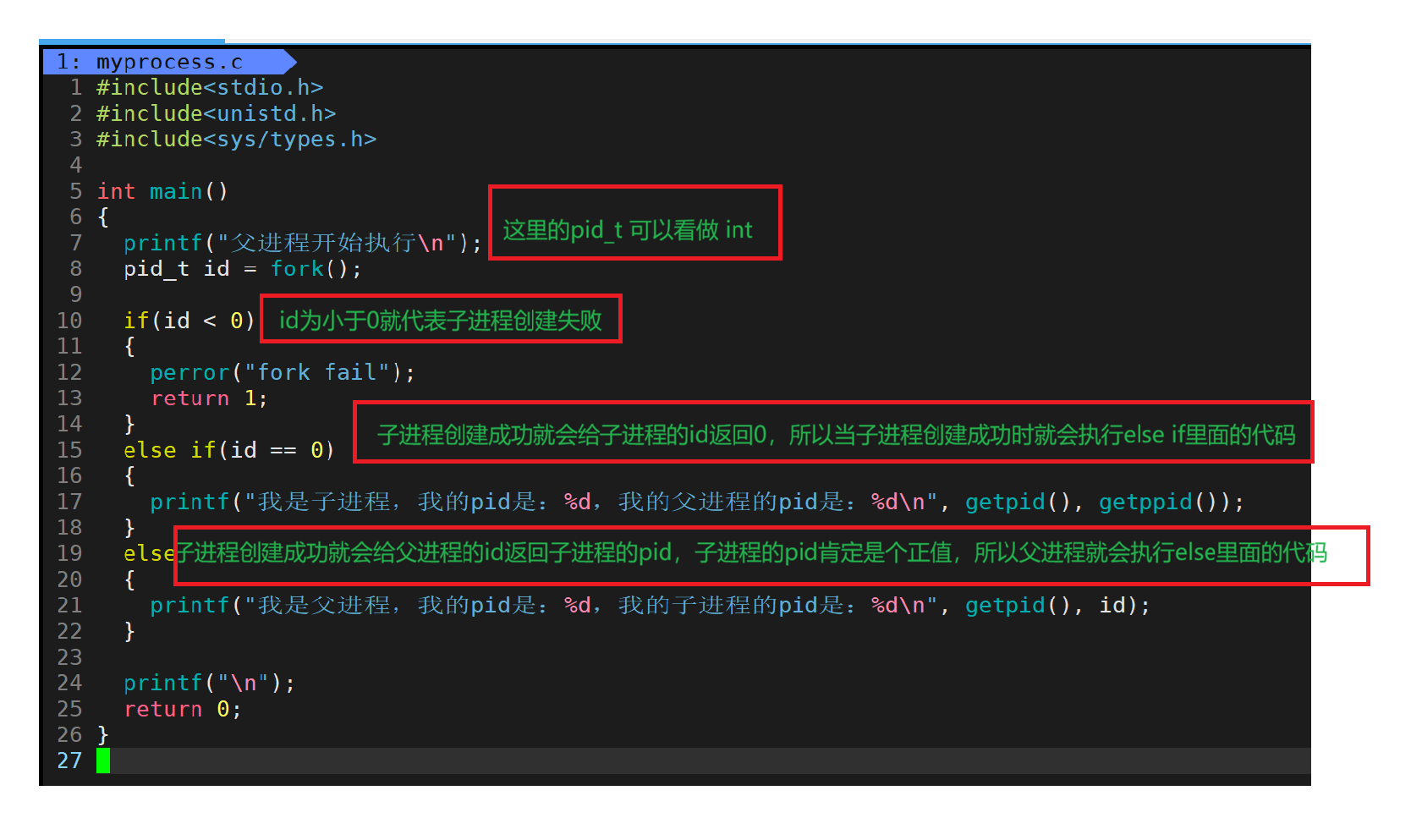
运行结果如下图:

上面说过,子进程会共享父进程的代码和数据。
所以fork之后给父进程中变量id赋值子进程的pid,在下面的条件判断语句中就会执行最后else的部分。
而给子进程的变量id赋值为0,在下面的条件判断语句中就会执行中间的else if的部分。
所以就做到了父进程和子进程执行不同的代码块。
这里又有一个疑惑,上面说了子进程会共享父进程的数据和代码。
那这里的共享父进程的代码很好理解。程序被加载到内存的时候,代码就是只读的,父进程和子进程都不能修改。那数据呢?当创建子进程成功时,父进程对变量id进行修改。子进程也对变量id进行修改。难道这里的变量id一次性存储了两个值?
在回答这个问题之前,我们要知道一个结论就是进程具有独立性 。
这里的独立性就是一个进程挂掉了不会影响另一个进程。
子进程挂掉了不会影响父进程。
父进程挂掉了也不会印象子进程。
现在回到上面的那个问题。在数据层面父进程和子进程默认是共享的,但是在父子进程的任意一方修改时。操作系统就会把被修改的数据在底层拷贝一份,给要修改数据的进程修改这个新创建的变量
这个技术就是写时拷贝
代码里面的
c
pid_t id = fork();其实就是fork函数把返回值赋值给变量id,此时对数据进行了修改操作。就触发了写时拷贝。