文章目录
-
- 引言
- 一、时序数据库选型核心维度
-
- [1.1 部署架构灵活性](#1.1 部署架构灵活性)
- [1.2 存储成本与压缩效率](#1.2 存储成本与压缩效率)
- [1.3 数据模型与组织方式](#1.3 数据模型与组织方式)
- [1.4 写入与查询性能](#1.4 写入与查询性能)
- [1.5 时序分析能力](#1.5 时序分析能力)
- [1.6 生态兼容性](#1.6 生态兼容性)
- [二、Apache IoTDB 核心优势解析](#二、Apache IoTDB 核心优势解析)
-
- [2.1 灵活的部署方式](#2.1 灵活的部署方式)
- [2.2 低硬件成本的存储解决方案](#2.2 低硬件成本的存储解决方案)
- [2.3 层级化的测点组织管理](#2.3 层级化的测点组织管理)
- [2.4 高通量的数据读写](#2.4 高通量的数据读写)
- [2.5 丰富的时间序列查询语义](#2.5 丰富的时间序列查询语义)
- [2.6 极低的使用与运维门槛](#2.6 极低的使用与运维门槛)
- [2.7 丰富的生态环境对接](#2.7 丰富的生态环境对接)
- 三、时序大模型驱动的智能分析能力
-
- [3.1 传统时序分析的局限](#3.1 传统时序分析的局限)
- [3.2 Timer系列时序大模型](#3.2 Timer系列时序大模型)
- [3.3 AINode:时序模型托管平台](#3.3 AINode:时序模型托管平台)
- 四、标识符规范与开发体验
-
- [4.1 标识符约束与反引号使用](#4.1 标识符约束与反引号使用)
- [4.2 字符串常量规范](#4.2 字符串常量规范)
- 五、选型决策建议
-
- [5.1 场景匹配矩阵](#5.1 场景匹配矩阵)
- [5.2 技术指标对比](#5.2 技术指标对比)
- 结语
引言
随着物联网、工业互联网的快速发展,时序数据呈现指数级增长。企业在构建物联网大数据平台时,面临应用场景复杂、数据体量大、采样频率高、数据乱序多、数据处理耗时长、分析需求多样、存储与运维成本高等多重挑战。如何选择一款合适的时序数据库,成为决定项目成败的关键因素。
本文将从实际应用场景出发,分析时序数据库选型的关键考量维度,并以Apache IoTDB及其产品TimechoDB为例,深入剖析其在部署灵活性、存储成本、数据建模、读写性能、分析能力、生态兼容性等方面的技术优势,为企业选型提供参考依据。

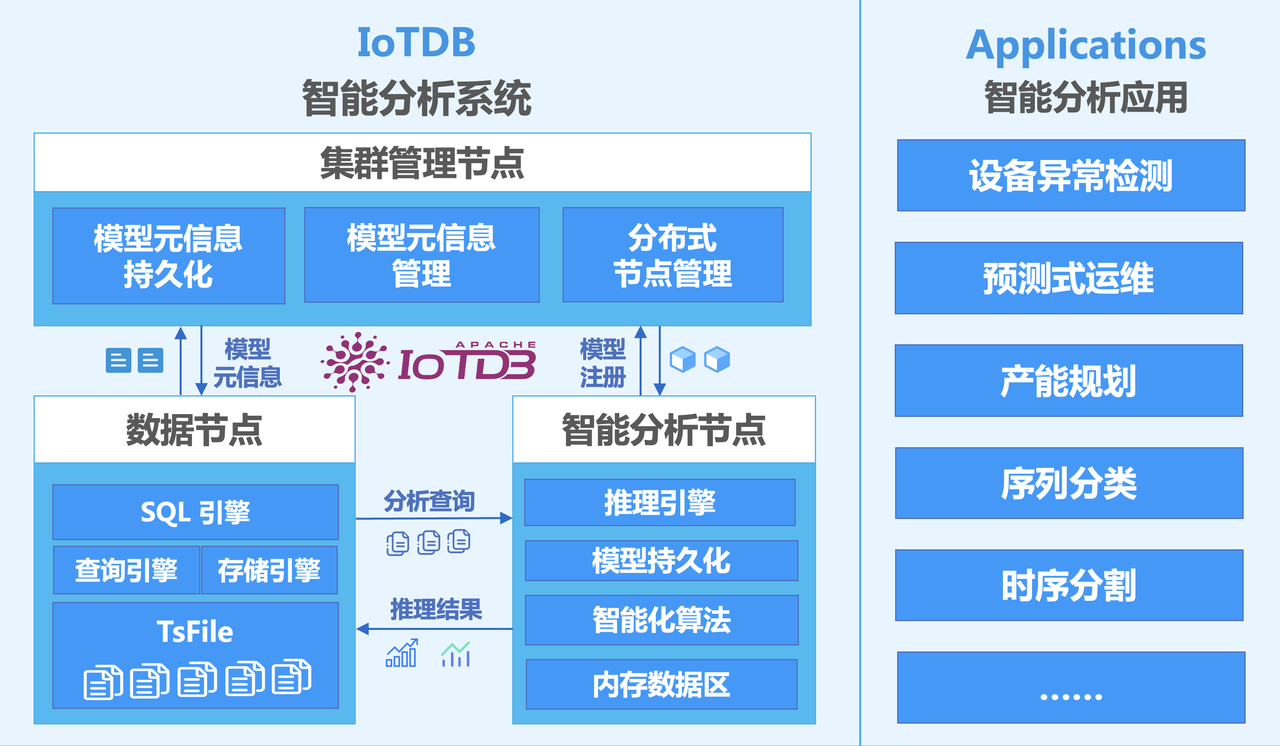
一、时序数据库选型核心维度
1.1 部署架构灵活性
物联网场景具有典型的"云-边-端"协同特征。工业现场可能存在数十个边缘节点,每个节点承载数千测点,同时需要将边缘数据汇总至云端进行全局分析。这就要求时序数据库能够支持:
- 边缘端轻量化部署(解压即用、资源占用低)
- 云端分布式集群部署(水平扩展、高可用)
- 边云协同能力(数据自动同步、统一命名空间)
| 部署模式 | 关键要求 | 典型场景 |
|---|---|---|
| 嵌入式 | 解压即用,MB级内存占用 | 工业网关、车载设备 |
| 单机版 | 支持TB级数据管理 | 工厂车间级监控 |
| 分布式集群 | 线性扩展,7×24小时服务 | 集团级工业互联网平台 |
| 云原生 | K8s部署,弹性伸缩 | 云端SaaS服务 |
1.2 存储成本与压缩效率
时序数据的体量往往在数月内即可从GB级增长至PB级。如果采用传统关系型数据库或通用NoSQL数据库,存储成本将呈线性增长,成为企业难以承受的负担。
关键指标:压缩比
时序数据库应针对时序特征设计专用编码和压缩算法:
- 差值编码:对于单调递增的时间戳,仅存储差值
- 二阶差分编码:适用于平稳变化的时间序列
- RLE游程编码:适用于重复值较多的场景
- SDT死区压缩:在误差允许范围内减少存储点数
根据实际测试,针对工业设备振动数据、环境温湿度数据等典型场景,专业时序数据库的压缩比可达20:1至100:1,大幅降低磁盘占用。
1.3 数据模型与组织方式
物联网设备的测点往往具有明确的层级关系:
工厂 → 产线 → 设备 → 部件 → 测点传统时序数据库多采用"扁平化"的标签键值对模型,虽然灵活但丧失了天然的层级语义。企业需要额外维护测点元数据管理系统,导致数据孤岛。
更优方案:层级化测点组织
支持在数据库中直接根据设备实际层级关系建模,实现工业测点管理结构的天然对齐。同时支持针对层级结构的目录树查看、通配符匹配、递归检索等能力。
1.4 写入与查询性能
物联网场景存在明显的读写不对称特征:
- 写入:海量并发,每秒数百万测点写入
- 查询:维度丰富,跨设备聚合、长时间跨度分析
写入性能瓶颈通常出现在:
- 写入链路序列化开销
- 索引维护开销
- 磁盘I/O瓶颈
查询性能挑战主要体现在:
- 海量时间点扫描
- 多设备时间戳对齐
- 时序特征计算(滑动窗口、插值、降采样)
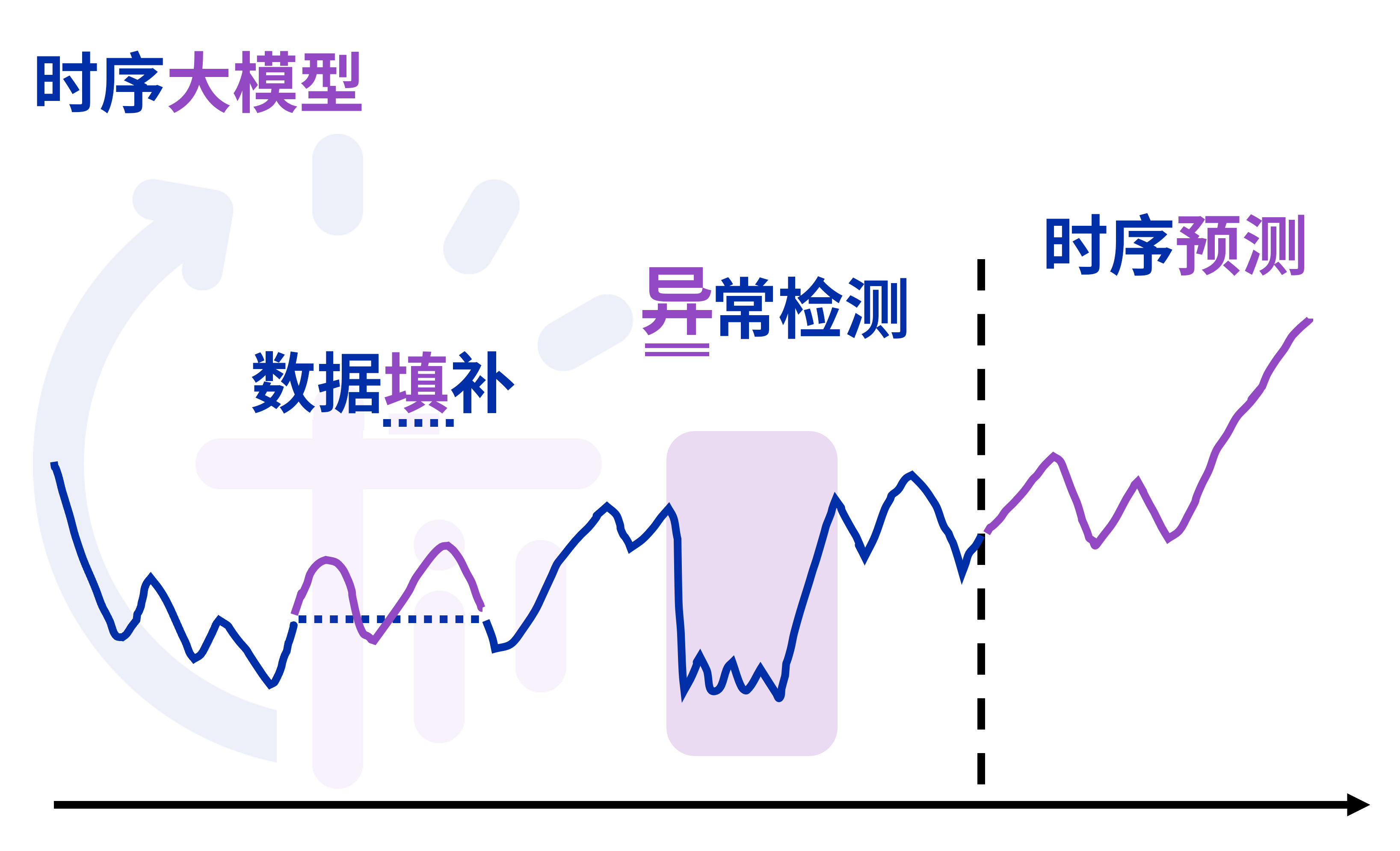
1.5 时序分析能力
传统数据库仅提供基础的聚合函数(SUM、AVG、MAX),难以满足时序分析需求。专业时序数据库应内置:
- 时序特征提取:峰值、谷值、周期、趋势
- 插值与填充:线性插值、前值填充、分段插值
- 降采样与重采样:等间隔转非等间隔、频率转换
- 异常检测:基于统计阈值、机器学习模型
- 预测分析:基于时序基础模型的未来趋势预测
1.6 生态兼容性
时序数据库很少独立存在,通常需要与以下系统集成:
- 可视化:Grafana、DataEase、ThingsBoard
- 大数据处理:Spark、Flink、Hadoop
- 机器学习:TensorFlow、PyTorch
- 消息队列:Kafka、MQTT Broker
二、Apache IoTDB 核心优势解析
2.1 灵活的部署方式
IoTDB从设计之初即考虑云边端协同场景:
边缘端部署
bash
# 解压即用,无需安装
wget https://archive.apache.org/dist/iotdb/1.3.0/apache-iotdb-1.3.0-all-bin.zip
unzip apache-iotdb-1.3.0-all-bin.zip
cd apache-iotdb-1.3.0-all-bin
# 启动单机版
./sbin/start-standalone.sh云端分布式集群
yaml
# docker-compose 三节点集群示例
version: "3"
services:
iotdb-confignode:
image: apache/iotdb:1.3.0-confignode
iotdb-datanode-1:
image: apache/iotdb:1.3.0-datanode
iotdb-datanode-2:
image: apache/iotdb:1.3.0-datanode
iotdb-datanode-3:
image: apache/iotdb:1.3.0-datanode边云协同工具
提供专门的数据云端同步工具,支持断点续传、压缩传输、增量同步,实现终端-云端无缝连接。
2.2 低硬件成本的存储解决方案
IoTDB采用列式存储引擎,针对时序特征设计专用编码器:
| 编码类型 | 适用场景 | 压缩比 | 解码速度 |
|---|---|---|---|
| PLAIN | 随机性强的数据 | 1:1 | 极快 |
| RLE | 重复值多的数据 | 5:1~50:1 | 快 |
| TS_2DIFF | 平稳变化的数据 | 10:1~30:1 | 中等 |
| GORILLA | 浮点数 | 15:1~40:1 | 中等 |
| SDT | 允许误差的连续数据 | 20:1~100:1 | 慢 |
关键设计:无需区分历史库与实时库,冷热数据统一管理。系统根据数据写入时间和访问频率,自动执行文件合并策略,无需人工干预。
2.3 层级化的测点组织管理
传统扁平模型(OpenTSDB/InfluxDB)
cpu_usage{host="server01",dc="shanghai"} 23.5
temperature{sensor="s1001",line="L3"} 36.2IoTDB树形模型
root.工厂1.产线A.设备01.温度
root.工厂1.产线A.设备01.振动
root.工厂1.产线B.设备02.温度路径检索能力示例
sql
-- 查询工厂1下所有设备的温度
SELECT temperature FROM root.工厂1.*.*.temperature
-- 通配符多层匹配
SELECT * FROM root.工厂1.产线A.设备01.*
-- 使用反引号处理特殊节点
SELECT `温度(℃)` FROM `root.工厂1.产线A.设备01`这种模型与工业设备管理架构天然对齐,运维人员可直接按照物理层级进行权限管控、数据隔离、模型复用。
2.4 高通量的数据读写
写入性能
IoTDB针对时序数据写入路径深度优化:
- 批量写入接口(Batch Insert)
- 异步刷盘机制
- 顺序I/O主导的LSM树结构
- 内存双缓存区避免写入停顿
查询性能
- 时间分区剪枝:按时间范围自动跳过无关文件
- 元数据过滤剪枝:按设备路径提前过滤
- 向量化执行引擎:SIMD指令加速
- 谓词下推:将过滤条件下推到存储层
2.5 丰富的时间序列查询语义
IoTDB提供近百种内置聚合与时序计算函数:
时间序列对齐
sql
-- 不同采样频率设备的时间戳对齐
SELECT AVG(temperature) FROM root.工厂.*.*.temperature
GROUP BY ([2024-01-01 00:00:00, 2024-01-02 00:00:00), 1m)
FILL (linear)时序特征计算
sql
-- 计算设备振动的有效值
SELECT sqrt(avg(power(vibration, 2))) FROM root.设备.*
-- 异常值检测(超过3倍标准差)
SELECT * FROM root.设备.温度
WHERE abs(温度 - avg(温度) over (interval 1h)) > 3*stddev(温度) over (interval 1h)嵌套聚合
sql
-- 先计算每台设备平均温度,再计算产线整体平均
SELECT avg(temperature) FROM
(SELECT avg(temperature) as temperature FROM root.工厂.*.*.temperature GROUP BY device)2.6 极低的使用与运维门槛
类SQL语法
熟悉关系型数据库的开发人员可在10分钟内上手:
sql
-- 创建存储组(Database)
CREATE DATABASE root.工厂1
-- 创建时间序列
CREATE TIMESERIES root.工厂1.产线A.设备01.温度 WITH
DATATYPE=FLOAT, ENCODING=GORILLA
-- 插入数据
INSERT INTO root.工厂1.产线A.设备01(timestamp, 温度, 振动) VALUES (now(), 36.5, 0.12)
-- 查询数据
SELECT 温度, 振动 FROM root.工厂1.产线A.设备01
WHERE time > now() - 1h AND 温度 > 35.0多语言原生接口
- Java JDBC
- Python PEP 249
- C/C++ Native API
- Go/Rust/Node.js 社区驱动
可视化运维控制台
提供集群监控、查询诊断、性能分析、慢查询定位等运维能力。
2.7 丰富的生态环境对接
大数据生态
sql
-- 将IoTDB数据映射为Spark表
CREATE TEMPORARY VIEW iotdb_table
USING org.apache.iotdb.spark.db
OPTIONS (
url "jdbc:iotdb://127.0.0.1:6667/",
sql "SELECT * FROM root.工厂1.*.*.temperature"
)
-- 使用Spark SQL进行分析
SELECT line, avg(temperature)
FROM iotdb_table
GROUP BY line可视化集成
- Grafana数据源插件:支持完整的时间序列查询语义
- DataEase插件:面向企业级报表
- ThingsBoard集成:设备管理与可视化一体化
三、时序大模型驱动的智能分析能力
3.1 传统时序分析的局限
| 维度 | 传统方法 | 痛点 |
|---|---|---|
| 预测 | ARIMA、Prophet | 需要专业建模、调参困难 |
| 异常检测 | 3σ、IQR | 阈值难以确定、场景泛化差 |
| 数据填补 | 线性插值、均值填充 | 长序列缺失效果差 |
| 特征工程 | 人工提取 | 依赖专家经验 |
3.2 Timer系列时序大模型
IoTDB团队长期自研时序基础模型Timer,基于Transformer架构,经海量多领域时序数据预训练,具备零样本分析能力:
Timer-1模型
- 少样本泛化:仅需数十个样本微调即可超越传统深度模型
- 通用任务适配:统一架构支持预测、填补、异常检测
- 可扩展性:模型效果随参数规模和数据量持续提升
Timer-XL模型
- 超长上下文:支持数万个时间点的输入
- 多变量预测:非平稳序列、多变量协变量场景
- 万亿级工业预训练:覆盖能源、钢铁、交通等多领域
Timer-Sundial模型
- 1.28亿参数,1万亿时间点预训练
- 零样本预测:无需微调即可适配新场景
- 生成式预测:输出概率分布,支持不确定性评估
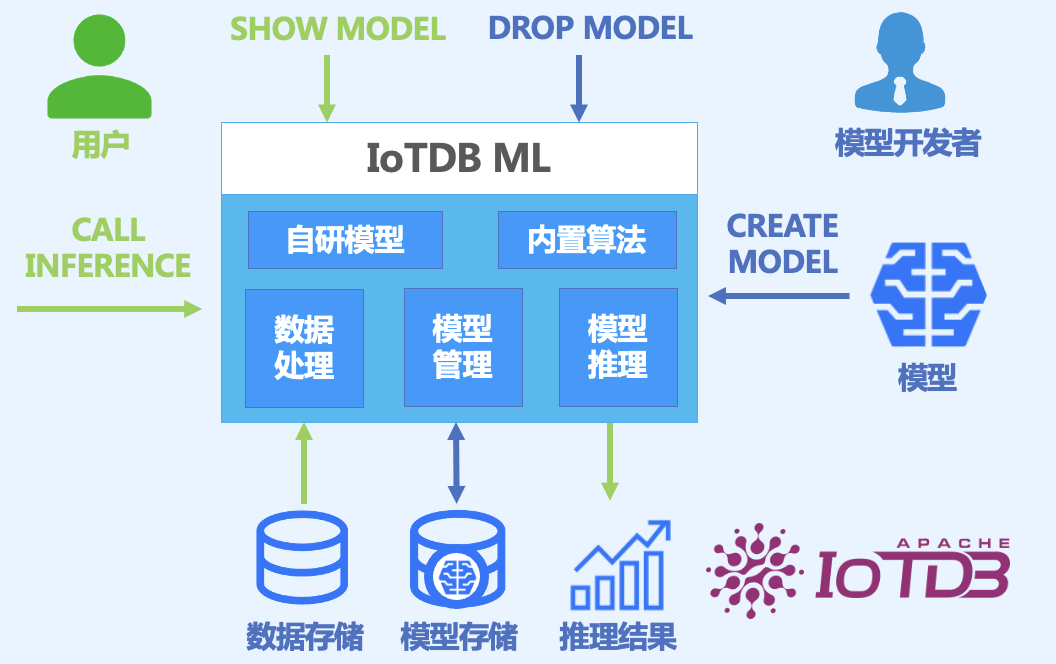
3.3 AINode:时序模型托管平台
IoTDB提供AINode能力,支持集成业界前沿时序基础模型:
sql
-- 注册时序预测模型
CREATE MODEL timer_forecast
USING 'org.apache.iotdb.ainode.TimerForecaster'
WITH (
'model_type' = 'Timer-Sundial',
'context_length' = '1024',
'forecast_horizon' = '96'
)
-- 使用模型进行零样本预测
SELECT timer_forecast(temperature, 'horizon=24')
FROM root.设备.温度
WHERE time > now() - 7d
-- 异常检测
SELECT time, temperature,
detect_anomaly(temperature) AS is_anomaly
FROM root.设备.温度四、标识符规范与开发体验
时序数据库的使用体验在很大程度上取决于其语法设计的严谨性与灵活性。IoTDB在标识符处理方面提供了完备的方案:
4.1 标识符约束与反引号使用
当标识符包含特殊字符或为纯数字时,需要使用反引号引用:
sql
-- 创建包含特殊字符的触发器
CREATE TRIGGER `alert.``listener-sg1d1s1`
AFTER INSERT ON root.sg1.d1.s1
AS 'org.apache.iotdb.db.engine.trigger.example.AlertListener'
-- 创建纯数字命名的UDF
CREATE FUNCTION `111` AS 'org.apache.iotdb.udf.UDTFExample'
-- 路径节点包含星号
SELECT temperature FROM `root.设备.*.温度`4.2 字符串常量规范
IoTDB支持完整的字符串转义规则:
sql
-- 插入包含特殊字符的文本
INSERT INTO root.ln.wf02.wt02(timestamp, hardware)
VALUES (1, 'v1'), (2, '\\'), (3, '\'quoted\'')
-- 别名定义(字符串方式)
SELECT s1 AS '温度(℃)', s2 AS '振动(mm/s)'
FROM root.工厂1.产线A.设备01五、选型决策建议
5.1 场景匹配矩阵
| 业务场景 | 推荐选型 | 核心考量 |
|---|---|---|
| 工厂车间级SCADA | IoTDB单机版 | 低运维成本、类SQL易用 |
| 集团级工业互联网 | TimechoDB分布式 | 高可用、混合负载、企业级服务 |
| 车联网平台 | IoTDB集群 | 高通量写入、地理空间查询 |
| 能源电力调度 | TimechoDB | 时序预测、异常预警、高可靠性 |
| 科研观测 | IoTDB开源版 | 灵活模型、时序分析函数 |
5.2 技术指标对比
| 维度 | 传统时序数据库 | IoTDB | 差异说明 |
|---|---|---|---|
| 边云协同 | 需二次开发 | 原生支持 | 降低开发成本50%+ |
| 存储成本 | 5:1~10:1 | 20:1~100:1 | 节省存储开支60%-80% |
| 查询语法 | 类SQL支持度不一 | 完整类SQL | 学习曲线平缓 |
| 时序分析 | 需外接计算引擎 | 内置百种函数 | 减少数据搬运 |
| AI能力 | 需独立部署 | AINode集成 | 一站式智能分析 |
| 开源协议 | 部分SSPL/商业 | Apache 2.0 | 商业友好 |
结语
时序数据库选型不是单纯的技术比较,而是需要综合考虑业务场景、团队能力、成本预算、生态依赖等多维度的系统工程。
Apache IoTDB自2018年开源以来,已在国家电网、中冶赛迪、华为云、阿里巴巴等数千家企业的核心生产环境中得到验证。其商业化产品TimechoDB在保持开源优势的基础上,进一步增强了性能、稳定性、效能工具和企业服务保障,为企业构建物联网大数据平台提供了从开源到商业化的平滑演进路径。
对于正在规划物联网数据基础设施的团队而言,建议采取"开源验证 + 商业化生产"的策略:初期使用Apache IoTDB快速构建原型,验证技术可行性;在生产阶段根据对服务SLA、性能优化、功能增强的需求,选择是否升级至TimechoDB。这一路径既能控制前期试错成本,又能为长期发展保留充足的空间。