📖【项目地址】
https://github.com/datawhalechina/torch-rechub
📄【文档地址】
https://datawhalechina.github.io/torch-rechub/(torch-rechub)
知识内容可以参看 Fun-Rec项目:
https://github.com/datawhalechina/fun-rec
本文档提供了 Torch-RecHub 的详细安装说明,包括稳定版和最新开发版的安装步骤。
安装指南
系统要求
在安装 Torch-RecHub 之前,请确保您的系统满足以下要求:
- Python 3.9+
- PyTorch 1.7+(推荐使用 CUDA 版本以获得 GPU 加速)
- NumPy
- Pandas
- SciPy
- Scikit-learn
安装方式
稳定版(推荐用户使用)
最简单的安装方式是通过 pip:
pip install torch-rechub最新开发版
要安装包含最新功能的开发版本:
# 首先安装 uv(如果尚未安装)
pip install uv
# 克隆并安装
git clone https://github.com/datawhalechina/torch-rechub.git
cd torch-rechub
uv sync
PS
记得切虚拟环境
mkdir -p /home/waitu1232/.virtualenvs
python3 -m venv /home/waitu1232/.virtualenvs/torch-rechub
source /home/waitu1232/.virtualenvs/torch-rechub/bin/activateuv:
指 Python 生态里那个 Astral 出的 uv(一个超快的 Python 包/环境管理工具)
把 pip + venv + pip-tools(锁依赖) 这些常用事,做成一个更快、更一体化的工具。
它通常用来:
- 装依赖 (替代
pip install ...,速度很快) - 创建/管理虚拟环境 (替代
python -m venv ...) - 锁定依赖版本(生成锁文件,保证"在我电脑能跑、在服务器也能跑")
- 跑项目命令 (比如
uv run python xxx.py,自动用正确环境)
开发环境设置
如果您想为 Torch-RecHub 做出贡献或使用源代码:
# 1. Fork 并克隆仓库
git clone https://github.com/YOUR_USERNAME/torch-rechub.git
cd torch-rechub
# 2. 安装依赖并设置环境
uv sync
# 3. 以开发模式安装包
uv pip install -e .验证安装
要验证 Torch-RecHub 是否正确安装,您可以运行:
import torch_rechub
print(torch_rechub.__version__)或运行一个简单的示例:
python examples/matching/run_ml_dssm.py故障排除
PyTorch 安装
如果您需要安装特定 CUDA 版本的 PyTorch,请访问 PyTorch 官方网站 获取针对您系统的安装说明。
GPU 支持
要获得 GPU 加速,请确保您拥有:
- NVIDIA GPU,计算能力 3.5 或更高
- 已安装 CUDA Toolkit
- 已安装 cuDNN 库
项目介绍
项目概述
Torch-RecHub 是一个使用 PyTorch 构建的、灵活且易于扩展的推荐系统框架。它旨在简化推荐算法的研究和应用,提供常见的模型实现、数据处理工具和评估指标。

特性
- 模块化设计: 易于添加新的模型、数据集和评估指标。
- 基于 PyTorch: 利用 PyTorch 的动态图和 GPU 加速能力。
- 丰富的模型库: 包含多种经典和前沿的推荐算法。
- 标准化流程: 提供统一的数据加载、训练和评估流程。
- 易于配置: 通过配置文件或命令行参数轻松调整实验设置。
- 可复现性: 旨在确保实验结果的可复现性。
- 易扩展: 模型训练与模型定义解耦,无basemodel概念。
- 原生函数: 尽可能使用pytorch原生的类与函数,不做过多定制。
- 模型代码精简: 在符合论文思想的基础上方便新手学习
- 其他特性: 例如,支持负采样、多任务学习等。
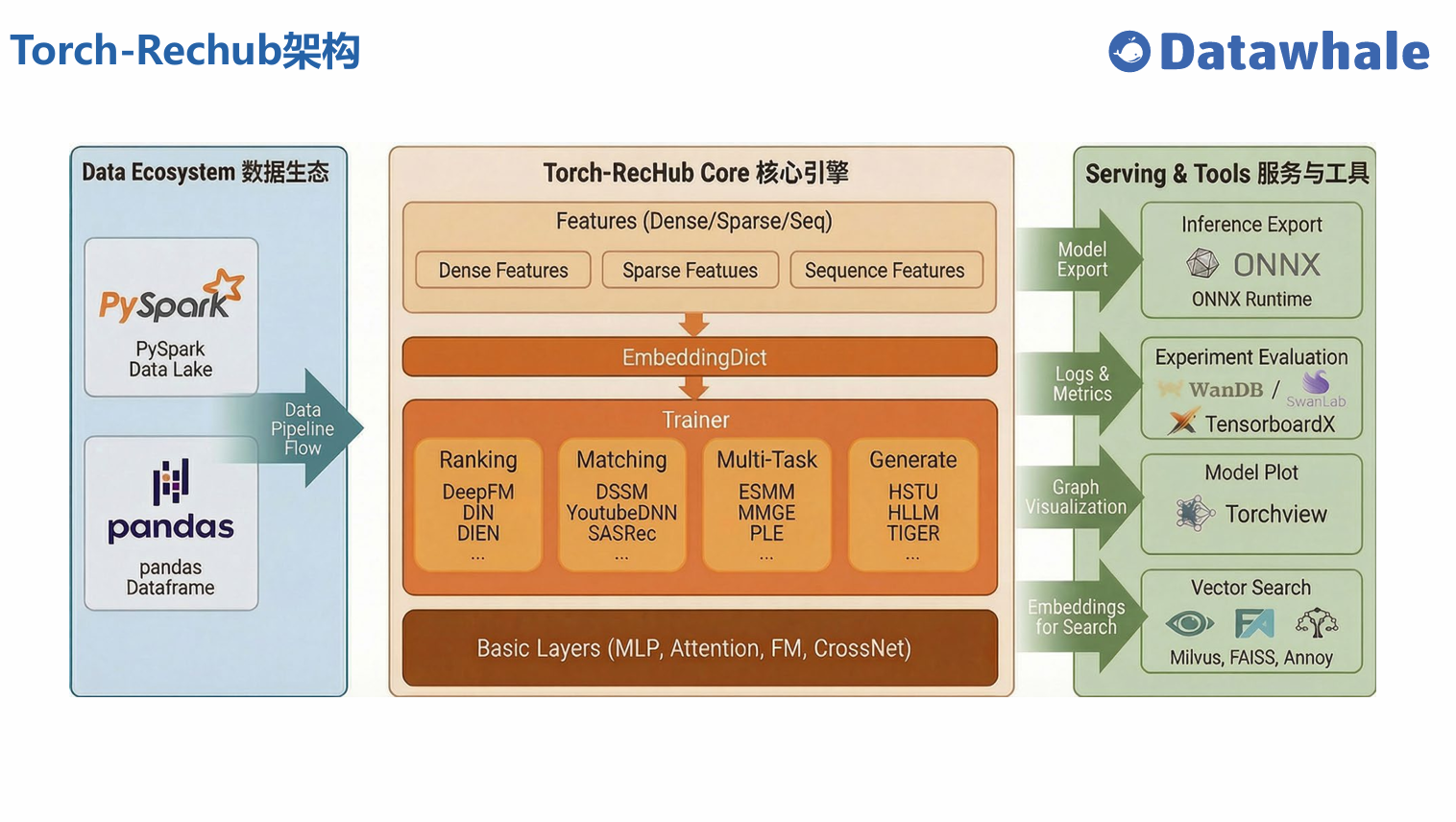
整体架构
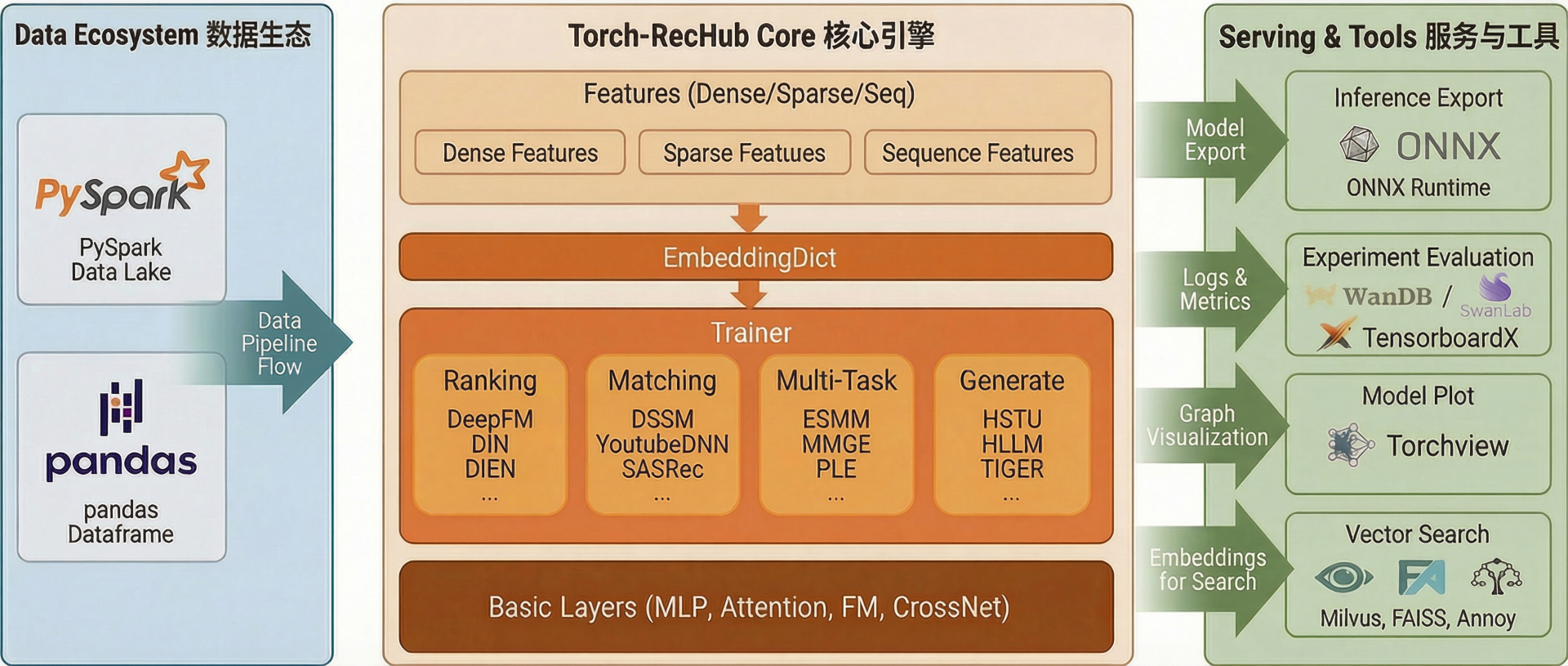
核心组件
Torch-RecHub 采用模块化设计,将推荐系统的核心功能划分为多个组件,包括:
1. 特征处理
处理不同类型的特征,包括数值型特征、类别型特征和序列特征。
详情请参考 特征定义 页面。
2. 数据流水线
负责数据加载、预处理和生成数据加载器,支持排序模型和召回模型的数据处理。
详情请参考 数据流水线 页面。
3. 模型库
实现各种推荐模型,包括排序模型、召回模型、多任务模型和生成式推荐模型。
详情请参考 模型库 页面。
4. 训练与评估
提供统一的训练接口,支持模型训练、评估、预测和ONNX导出功能。
详情请参考 训练与评估 页面。
5. 研发工具
提供各种工具函数,如ONNX导出、模型可视化、回调函数和损失函数等。
详情请参考 研发工具 页面。
支持的模型
排序模型 (Ranking Models) - 13个
- DeepFM、Wide&Deep、DCN、DCN-v2、DIN、DIEN、BST、AFM、AutoInt、FiBiNET、DeepFFM、EDCN
召回模型 (Matching Models) - 12个
- DSSM、YoutubeDNN、YoutubeSBC、MIND、SINE、GRU4Rec、SASRec、NARM、STAMP、ComiRec、FacebookDSSM
多任务模型 (Multi-Task Models) - 5个
- ESMM、MMoE、PLE、AITM、SharedBottom
生成式推荐 (Generative Recommendation) - 2个
- HSTU、HLLM
快速开始
要开始使用 Torch-RecHub,请参考 快速入门 页面,了解如何安装框架并运行第一个示例。
生产部署
Torch-RecHub 支持将训练好的模型导出为 ONNX 格式,便于部署到生产环境。详情请参考 生产部署 页面。
社区贡献
我们欢迎各种形式的贡献!请查看 贡献指南 了解详细的贡献流程。
常见问题
如果您在使用过程中遇到问题,请查看 常见问题 页面,或在 GitHub 上提交 Issue。
核心组件导览
Torch-RecHub 采用模块化设计,将推荐系统的核心功能划分为多个组件,包括特征处理、数据流水线、模型设计和训练评估等。这种模块化设计使得框架易于扩展和使用,同时保持了良好的代码组织结构。
核心组件架构
Torch-RecHub 的核心组件架构如下:
- 特征层:处理不同类型的特征,包括数值型特征、类别型特征和序列特征
- 数据层:负责数据加载、预处理和生成数据加载器
- 模型层:实现各种推荐模型,包括排序模型、召回模型、多任务模型和生成式推荐模型
- 训练层:提供统一的训练接口,支持模型训练、评估、预测和ONNX导出
- 工具层:提供各种工具函数,如ONNX导出、模型可视化、回调函数和损失函数等
组件关系
各核心组件之间的关系如下:
- 特征层 -> 数据层:特征定义用于指导数据层进行数据预处理和特征工程
- 数据层 -> 训练层:数据生成器生成的数据加载器用于模型训练和评估
- 模型层 -> 训练层:训练层使用模型层定义的模型进行训练和评估
- 训练层 -> 工具层:训练层使用工具层提供的工具函数进行ONNX导出、模型可视化等操作
组件详情
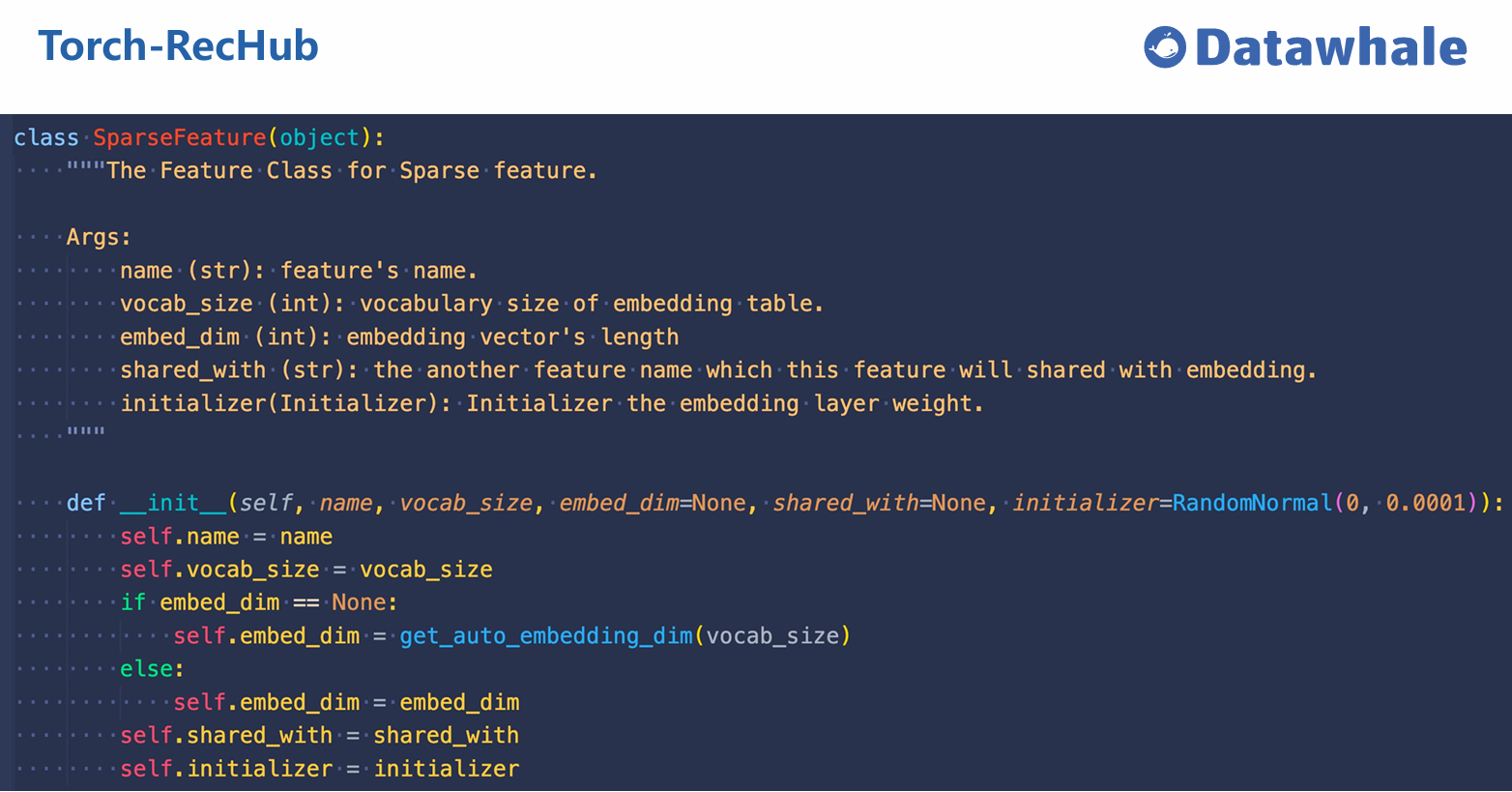
特征处理
特征处理组件用于定义和处理不同类型的特征,包括:
- DenseFeature:处理数值型特征
- SparseFeature:处理类别型特征
- SequenceFeature:处理序列特征或多热特征
详情请参考 特征定义 页面。
数据流水线
数据流水线组件用于处理数据加载、预处理和生成数据加载器,包括:
- TorchDataset:用于训练和验证的数据集合
- PredictDataset:用于预测的数据集合
- DataGenerator:用于生成排序模型和多任务模型的数据加载器
- MatchDataGenerator:用于生成召回模型的数据加载器
详情请参考 数据流水线 页面。
训练与评估
训练与评估组件用于训练不同类型的推荐模型,包括:
- CTRTrainer:用于训练排序模型
- MatchTrainer:用于训练召回模型
- MTLTrainer:用于训练多任务模型
详情请参考 训练与评估 页面。
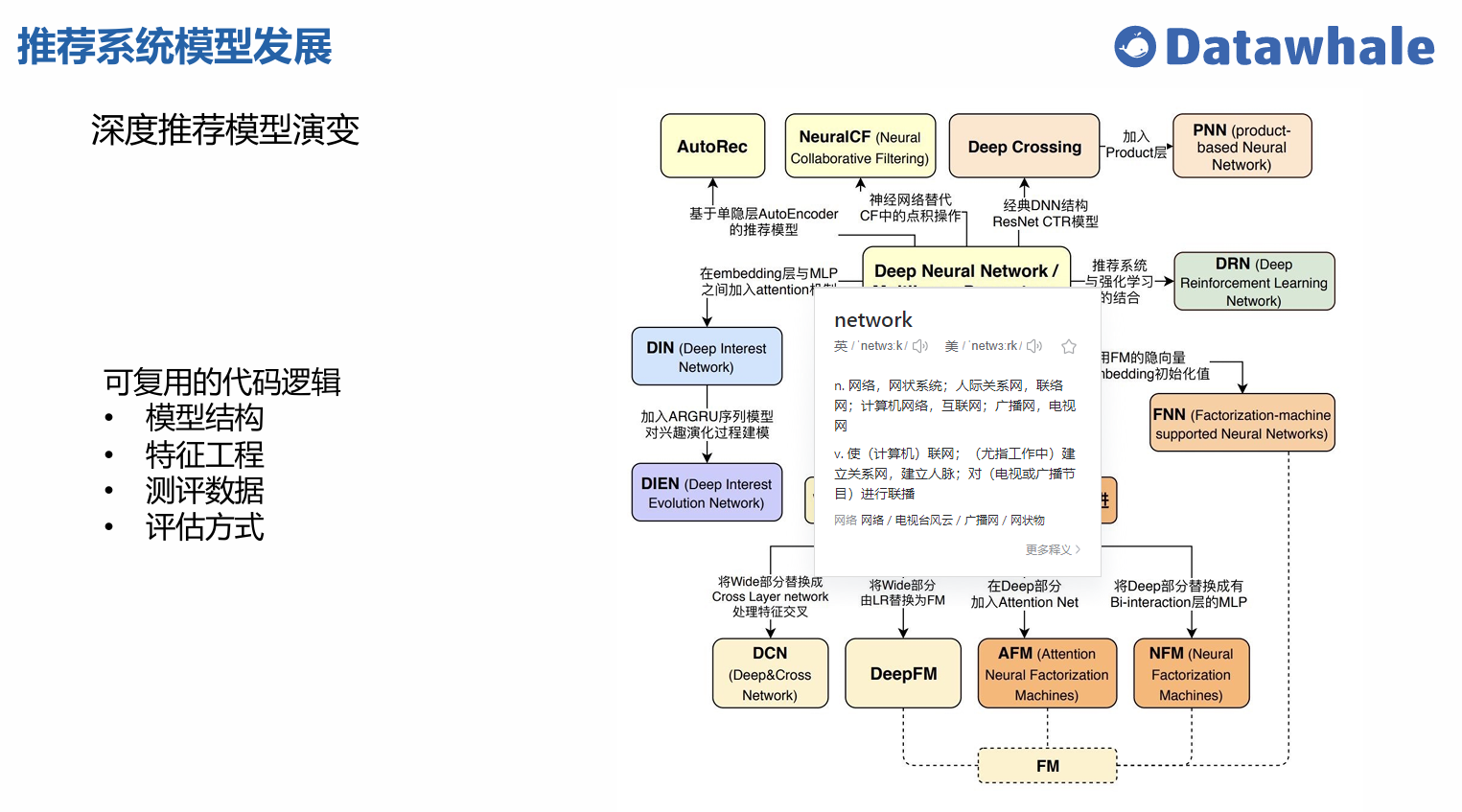
模型库导览
Torch-RecHub 提供了丰富的推荐模型库,涵盖了推荐系统的各个环节,包括排序、召回、多任务学习和生成式推荐。所有模型均基于 PyTorch 实现,易于使用和扩展。
模型库结构
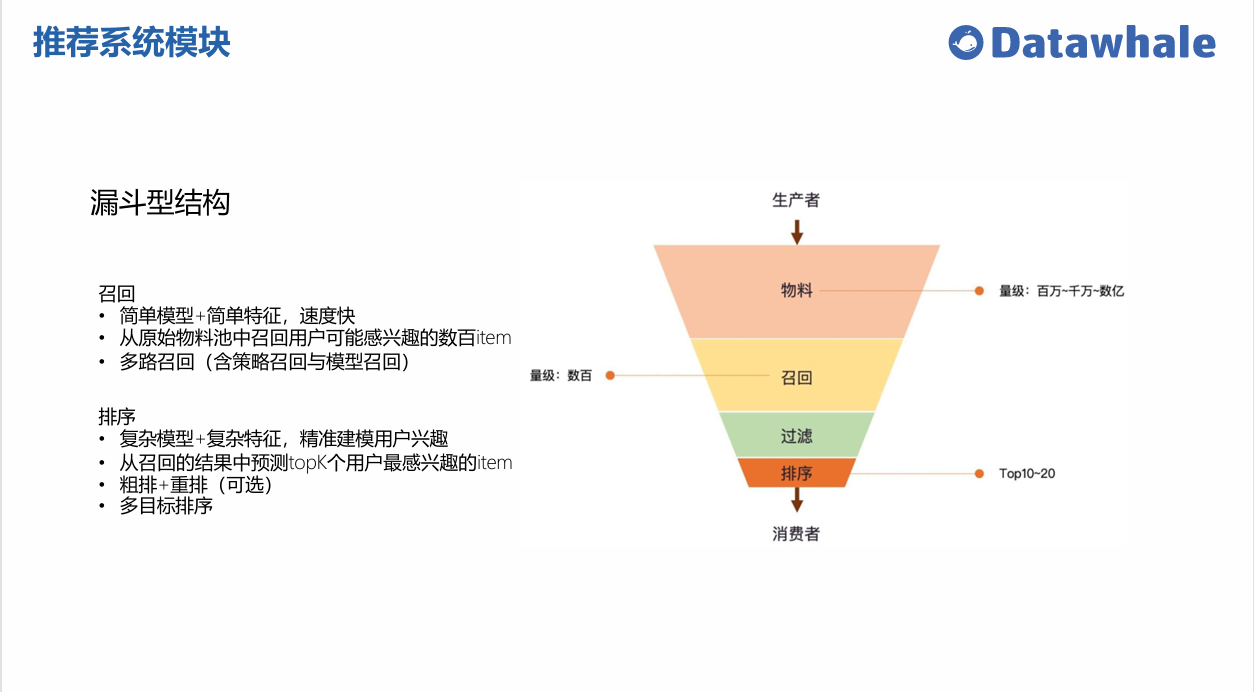
模型库按照推荐系统的不同阶段和任务类型进行组织:
- 排序模型 (Ranking):用于精排阶段,预测用户对物品的点击率或偏好分数
- 召回模型 (Matching):用于粗排阶段,从海量物品中召回候选集
- 多任务模型 (Multi-Task):同时优化多个相关任务,提高模型的泛化能力
- 生成式推荐 (Generative):利用生成式模型生成个性化推荐
模型选择指南
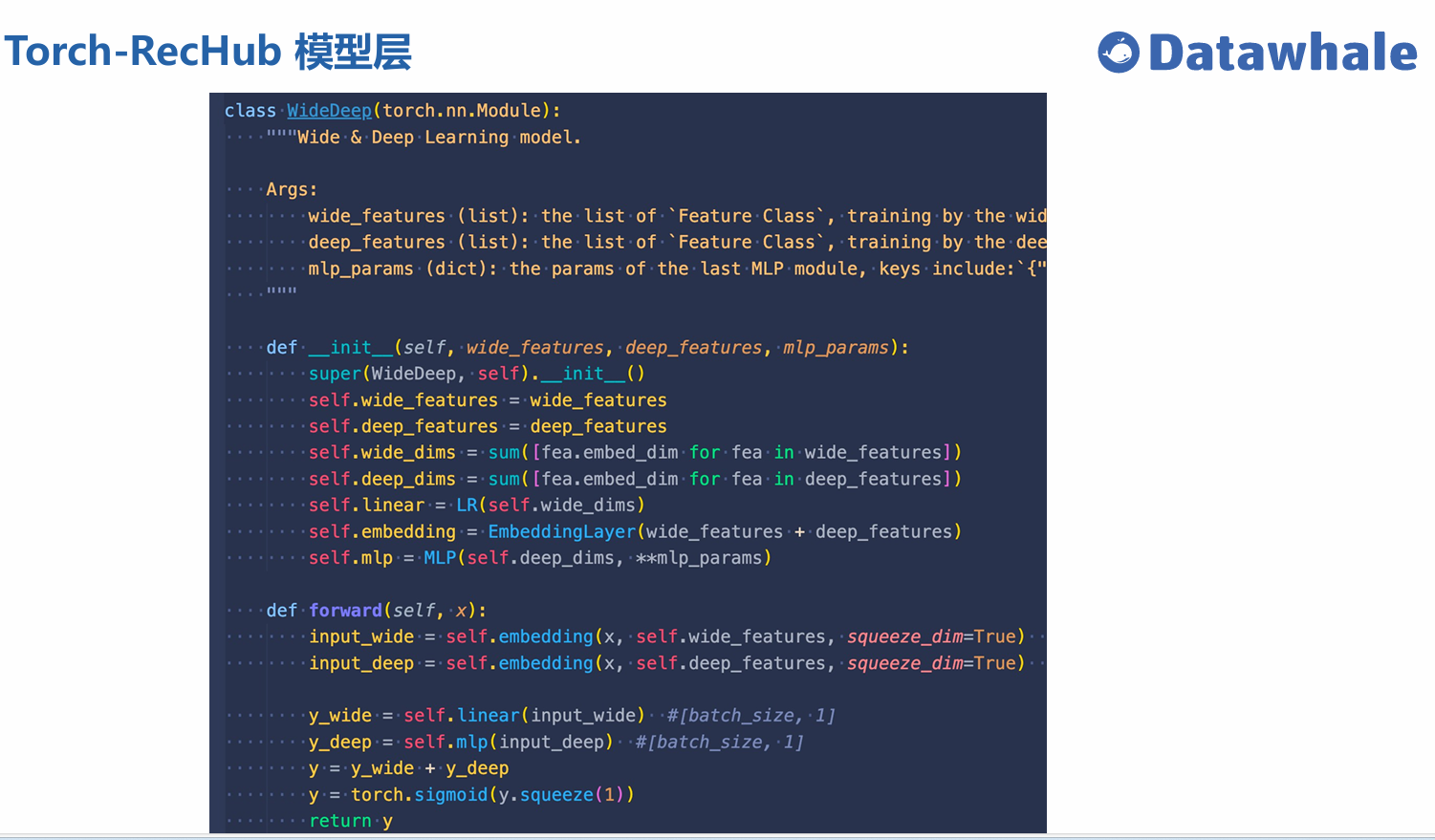
排序模型选择
|-----------|------------|-----------------------|
| 模型 | 适用场景 | 特点 |
| WideDeep | 基础排序任务 | 结合线性模型和深度模型,兼顾记忆和泛化能力 |
| DeepFM | 特征交互重要的场景 | 同时捕获低阶和高阶特征交互 |
| DCN/DCNv2 | 显式特征交叉场景 | 显式学习高阶特征交叉,计算效率高 |
| DIN | 用户兴趣动态变化场景 | 基于注意力机制捕捉用户兴趣 |
| DIEN | 长序列兴趣建模 | 建模用户兴趣的动态演化过程 |
| BST | 序列特征重要的场景 | 使用 Transformer 建模序列特征 |
| AutoInt | 自动特征交互学习 | 自动学习特征交互模式 |
召回模型选择
|---------------------|----------|----------------------|
| 模型 | 适用场景 | 特点 |
| DSSM | 文本匹配场景 | 双塔结构,将用户和物品映射到同一向量空间 |
| YoutubeDNN | 大规模推荐场景 | 基于用户行为序列的深度召回 |
| MIND | 多兴趣推荐场景 | 为用户学习多个兴趣表示 |
| GRU4Rec/SASRec | 序列推荐场景 | 建模用户近期行为序列 |
| ComirecDR/ComirecSA | 可控多兴趣推荐 | 允许控制生成的兴趣数量 |
多任务模型选择
|--------------|-----------|-----------------------|
| 模型 | 适用场景 | 特点 |
| SharedBottom | 任务相关性强的场景 | 所有任务共享底层网络 |
| MMOE | 任务冲突较大的场景 | 多门控专家混合,为不同任务学习不同专家组合 |
| PLE | 复杂多任务场景 | 渐进式分层提取,缓解负迁移问题 |
| ESMM | 样本选择偏差场景 | 全空间建模,解决样本选择偏差 |
| AITM | 任务间存在依赖关系 | 自适应信息迁移,学习任务间的依赖关系 |
生成式推荐选择
|--------|--------------|---------------------|
| 模型 | 适用场景 | 特点 |
| HSTU | 大规模序列推荐 | 层级序列转换单元,支撑万亿参数推荐系统 |
| HLLM | 融合 LLM 能力的推荐 | 结合大语言模型的语义理解能力 |
模型文档导航
排序模型
详细介绍各种排序模型的原理、使用方法和参数说明。
召回模型
详细介绍各种召回模型的原理、使用方法和参数说明。
多任务模型
详细介绍各种多任务模型的原理、使用方法和参数说明。
生成式推荐模型
详细介绍各种生成式推荐模型的原理、使用方法和参数说明。
使用示例
# 排序模型使用示例
from torch_rechub.models.ranking import DeepFM
from torch_rechub.trainers import CTRTrainer
# 创建模型
model = DeepFM(deep_features=deep_features, fm_features=fm_features, mlp_params={"dims": [256, 128], "dropout": 0.2})
# 创建训练器
trainer = CTRTrainer(model, optimizer_params={"lr": 0.001}, device="cuda:0")
# 训练模型
trainer.fit(train_dataloader, val_dataloader)
# 召回模型使用示例
from torch_rechub.models.matching import DSSM
from torch_rechub.trainers import MatchTrainer
# 创建模型
model = DSSM(user_features=user_features, item_features=item_features, temperature=0.02,
user_params={"dims": [256, 128, 64]}, item_params={"dims": [256, 128, 64]})
# 创建训练器
trainer = MatchTrainer(model, mode=0, device="cuda:0")
# 训练模型
trainer.fit(train_dataloader)贡献新模型
如果您想贡献新的模型,请参考 贡献指南,遵循项目的编码规范和文档要求。
03 代码讲解






笔记

obsidian://open?vault=%E5%BF%B5%E5%AE%89%E7%AC%94%E8%AE%B0&file=think%26write%2FTorch-rechub