论文标题
Neural Attention Search Linear: Towards Adaptive Token-Level Hybrid Attention Models
论文地址
https://arxiv.org/pdf/2602.03681
作者背景
汉诺威大学
代码仓库
https://github.com/automl/NeuralAttentionSearchLinear
一、动机
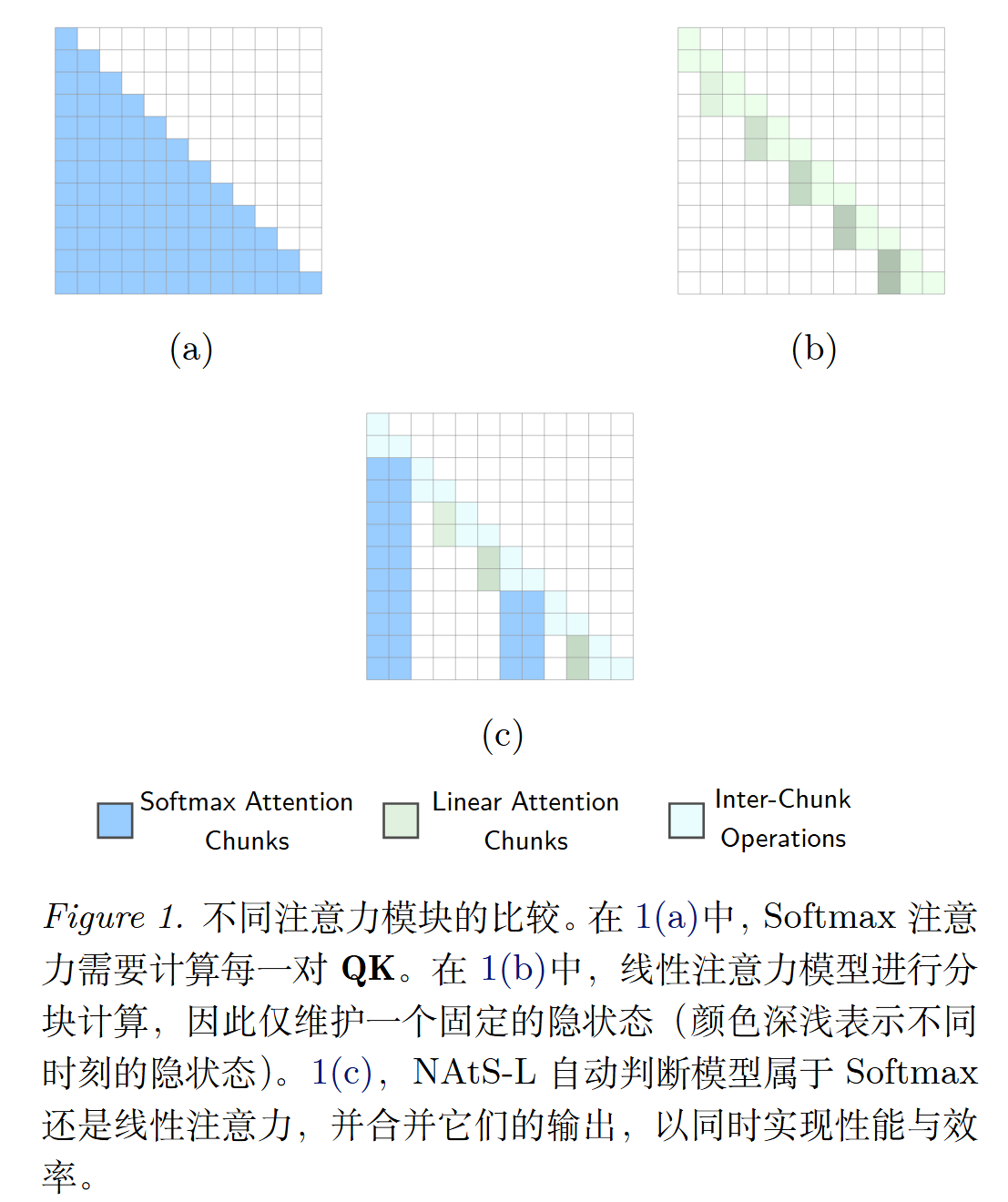
长上下文场景中,标准 Transformer 的 softmax 注意力像是 "把过去每一页都完整夹在书里,随时翻阅",表达力强,但训练/预填充计算量会随长度平方增长,推理还要存很大的 KV cache,越来越吃力
线性注意力家族更像是"维护一本随时间更新的摘要笔记",计算更省、推理更轻,但细节模糊,难以精准定位
当前常见的"混合架构"做法是:仅在模型的某些层上使用 softmax,其余层则使用线性层,从而达到更折衷的效果。但问题是,只要 softmax 层存在,就会有长上下文的计算于存储瓶颈。
对此,作者提出了一种新思路:别按"层"固定分工,而是按"token(更准确说是按 chunk)的重要性"来动态分配。对可能需要被检索的重要内容使用 softmax 进行全量保存,其余 token 使用线性注意力进行总结压缩
二、NAtS-L 原理
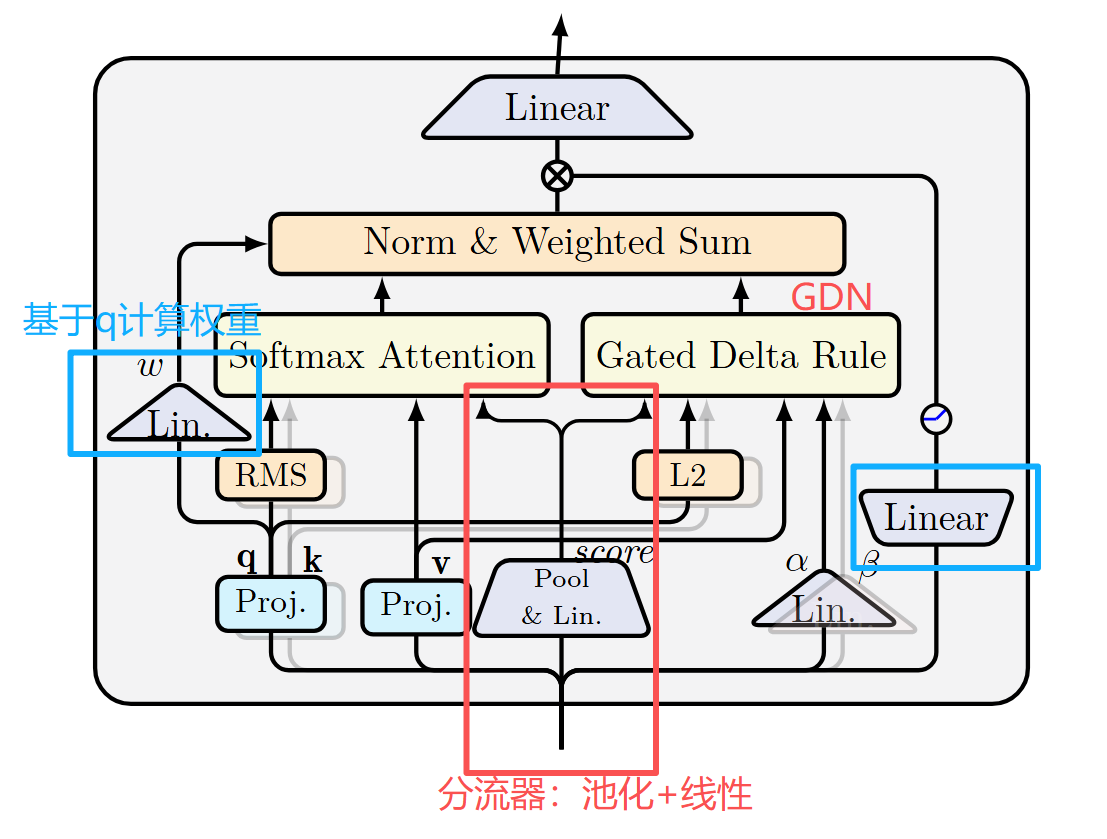
作者提出 NAtS-L(Neural Attention Search Linear),它在每一层中,把输入序列切成多个 chunk,每个 chunk 选择更合适的注意力计算方式
具体实现流程如下:
- 切块
线性注意力刚问世时,尽管在算法复杂上很优雅,但实际使用时往往并不能提效,原因在于它不能充分利用 GPU 的并行计算能力(串行特性、计算碎片化、频繁读写等),需要做针对性的硬件/算子优化。所以作者在设计新的 attention 机制时也沿用了 "分块" 思想来减少硬件上的低效迭代
- 打分
使用【池化+线性层】这一简单轻量的模块把输入特征映射成二分类结果
s c o r e t = W s c o r e ∗ M e a n ( X t ) score_t = W_{score} * Mean(Xt) scoret=Wscore∗Mean(Xt)
- 分流
把各 chunk 分成两个集合,然后构造两种 mask 矩阵 M l a M_{la} Mla 和 M n l a M_{nla} Mnla 用于 attention 计算
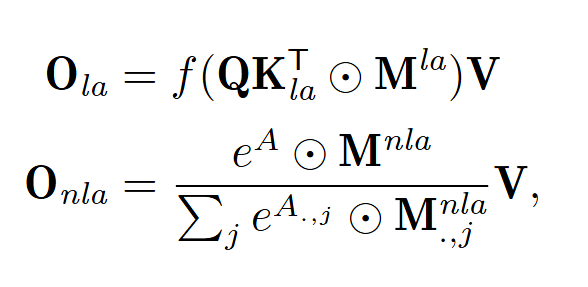
- 合流
softmax 与线性注意力输出的数值尺度可能不一致,不能直接相加。本文的对齐方法为:
-
对两条输出分别做归一化( RMS norm)
-
把最终状态下的 query 张量映射为权重,计算两种注意力的加权和
注意力输出的含义在于:"这个 query(q)和历史的 k/v 匹配得多好",所以用 q 来决定两种注意力的权重更合理
三、FlashAttention 和 GDN 路径
3.1 FlashAttention:不是不做全连接,而是"分块算、边算边归一化"
FlashAttention 是对注意力计算流程的流水线式改造
- 传统 softmax 注意力:先把"所有 i 看所有 j 的分数表"一次性写满(一个超大表格),再做 softmax,再乘 V。
- FlashAttention :别先把整张表写出来,而是把 Q/K/V 分块后依次计算;每算完一块就把输出做"在线更新",同时维护 softmax 必需的统计量(最大值、归一化分母之类),最后得到和原始 softmax 几乎一致的结果,但显存压力小很多
所以作者设计 NAtS-L 时也采用了分块,更自然地添加到 FlashAttention 流程中
3.2 GDN:把线性注意力理解成"持续更新的摘要笔记"
GDN(Gated DeltaNet)像是一种维护"记忆笔记"的注意力机制
-
softmax 注意力:把原文(KV cache)都留着,随时回去逐字检索。
-
线性注意力 / GDN :每新来一个 token,就决定:
- 旧笔记里哪些内容该淡忘一点
- 新信息该写进摘要的哪个"槽位"(由 key 决定"写入位置/方向",由 value 决定"写入内容")
更重要的是, GDN 也可以 chunk-wise 并行化,类似于攒一波更新后"一次性写一页摘要"
3.3 梯度计算过程
这里有个难点:决定走上述哪条路径的分流器,其输出会经过 argmax 处理得到选择结果,这一操作是不可导的。于是反向传播过程中,梯度无法走到分流器,导致其无法更新参数
对此,作者并没有使用 Gumbel-Softmax 或软路由等方案来让选择操作可导,而是从已有计算图中寻找其他可替代的学习信号
具体地,回顾分流过程中应用的两种 mask 矩阵,它所接收的梯度信号意味着该如何调整它们的 0、1元素,才能让输出更接近 label(实际上 mask 矩阵也不涉及参数更新),相当于:分流器该更多地选择 softmax 路径还选择 GDN 路径。这实际上就是分流器本身所需要的学习信号!
作者基于 mask 矩阵的梯度,把同一个 chunk 中的相关梯度做汇总起来,作为分流器的梯度效率方面,未被激活的 chunk 对应梯度全部置 0,各 chunk 仅参与一次梯度运算,避免因路径选择而出现双倍计算开销;更妙的是,作者发现计算 mask 梯度时,可以直接复用 softmax attention 和 GDN 计算图的中间变量,使得除了按 chunk 汇总以外,几乎没有新计算开销
Straight-Through Estimator 思想:简单粗暴地把离散方程输出的导数当成输入的导数四、实验
4.1 实验设置
训练任务:从头预训练,上下文长度 4096
数据集:Fineweb-Edu
- 0.38B 模型:150 亿 token
- 0.8B 模型:500 亿 token
实验组:
- NAtS-L:21 层都用 NAtS-L(每层都有 chunk 切分与路径分配)
- NAtS-L Hybrid:在 GDN 主干里插入 6 个 NAtS-L 层(其余 15 层仍是 GDN)
对比模型:
- GDN
- Mamba2
- 标准 Transformer
- GDN Hybrid(按层混合,线性:非线性 = 3:1)
模型全都基于 flash-linear-attention 库实现
4.2 实验结果
作者做了三方面的评测:
- 语言能力、常识推理:LAMBADA、PIQA、HellaSwag等(更看"模型本体知识")
- 检索、信息抽取:把输入截到 4096(和训练一致),看能否从上下文里抓关键线索(SWDE、SQD、FDA 等)
- 长文本外推 :
- 65,536 长度下的困惑度(PG19、NarrativeQA、CodeParrot)
- RULER:4k/8k/16k 的检索能力
- LongBench:多种长文本理解任务
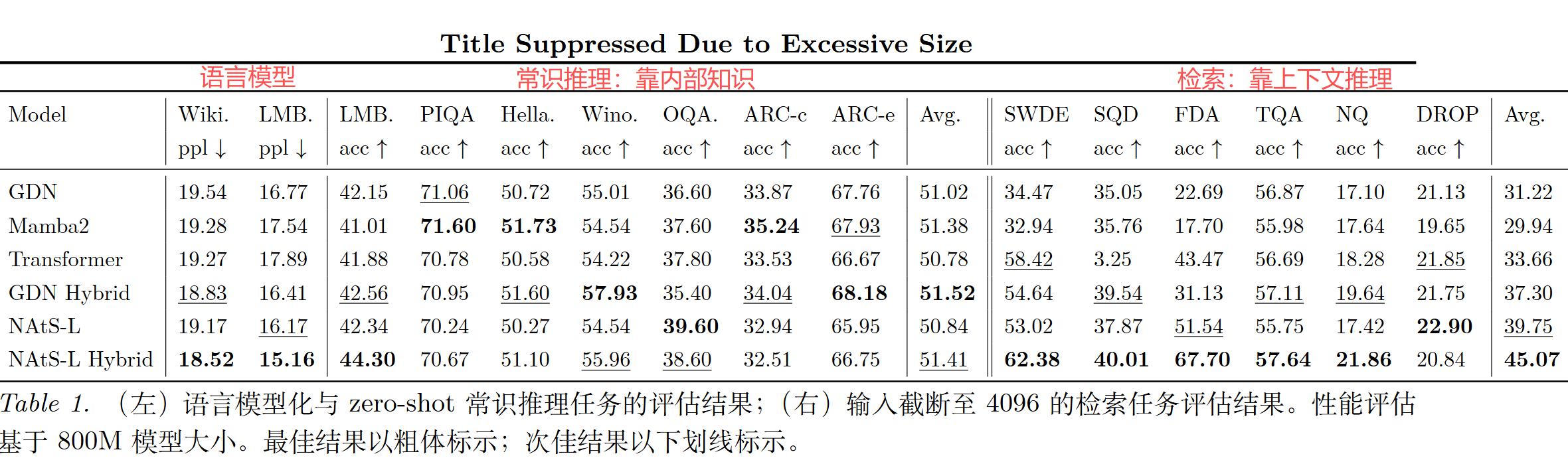
【结论一】在"常识/短任务"上各家差距不大;但在"需要从上下文中抠信息"的检索任务上,NAtS-L 系列整体更稳,NAtS-L Hybrid 的平均检索分数最高,与标准 Transformer 相比平均提升了 36%
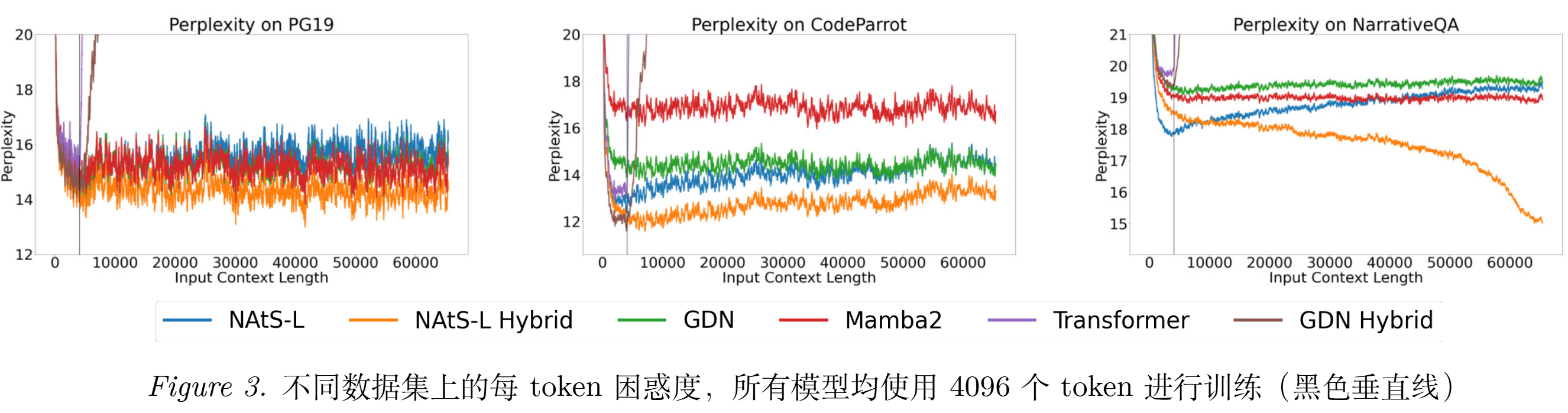
【结论二】GDN Hybrid 虽然在训练长度附近可能更低,但一旦超过训练长度就容易失效;NAtS-L 和 NAtS-L Hybrid 能更好保持困惑度
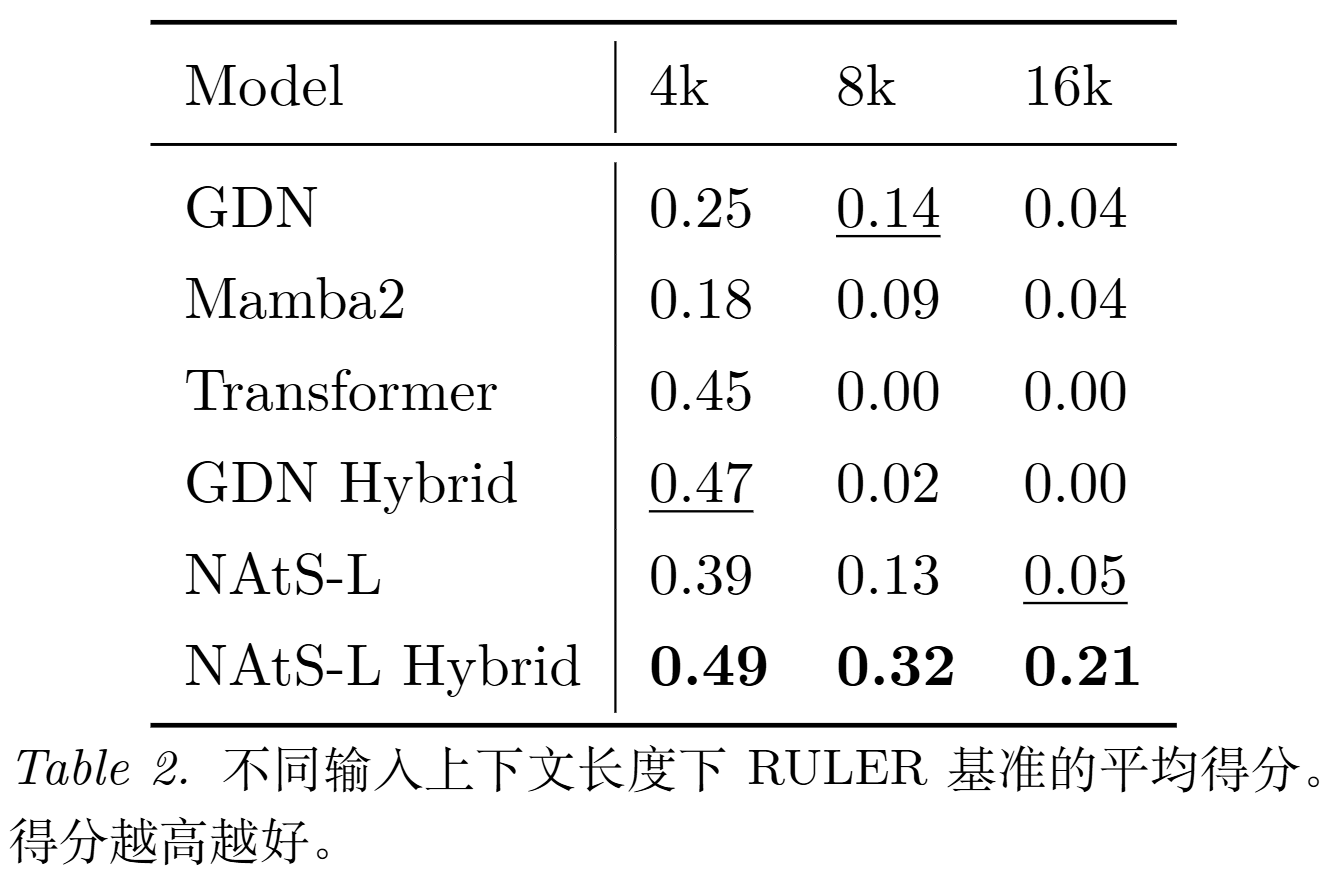
【结论三】Transformer 和按层混合的 GDN Hybrid 在长检索任务上的效果基本掉到 0;而 NAtS-L Hybrid 还能保持 0.21,并且在 4k/8k/16k 都是最好
这很符合论文动机:真正影响长检索的是:"你到底把哪些 token 留成了可检索的形式"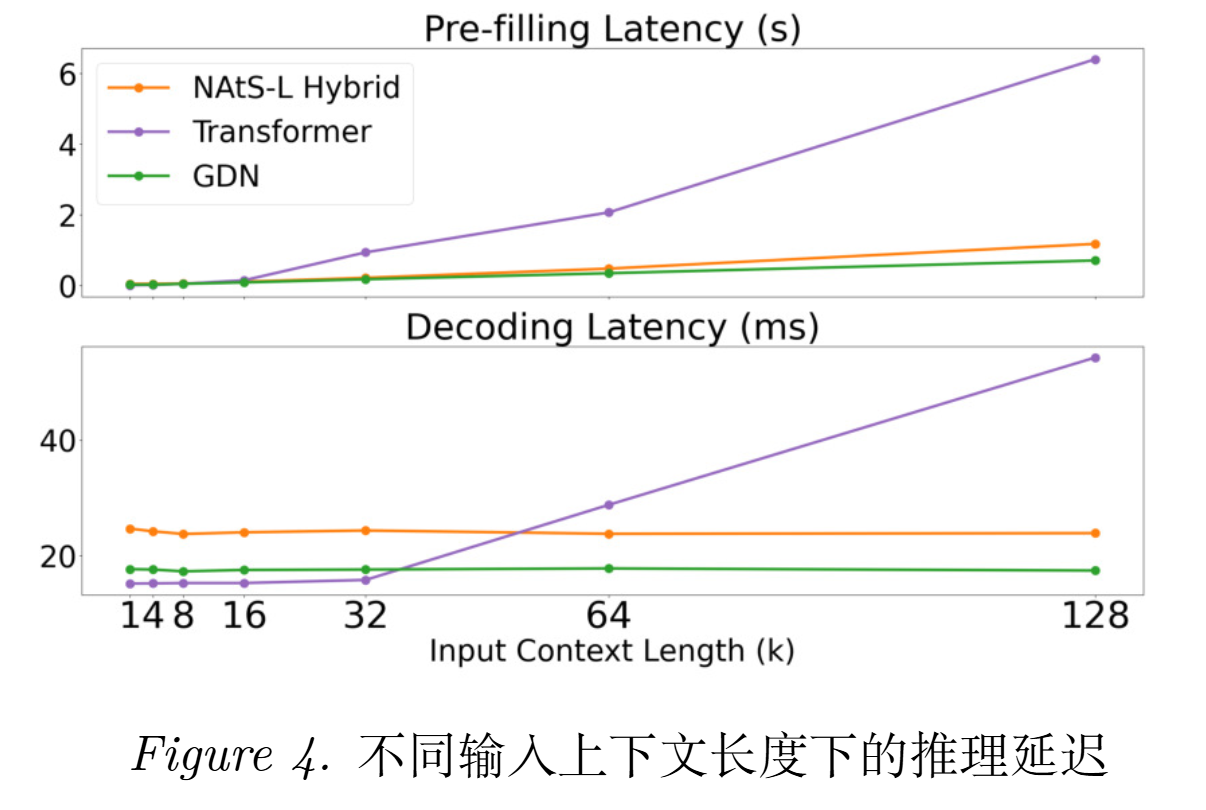
【结论四】在最长输入长度的测试下,NAtS-L Hybrid 的 prefilling 相比 Transformer 有 5.4× 加速 ;decoding 在 128k 上有 2.3× 加速 ;同时它的 prefilling 只比纯 GDN 慢 1.66×
五、NAtS-L 最终学会了怎样的"分流策略"
作者专门分析了 softmax token 的分布。
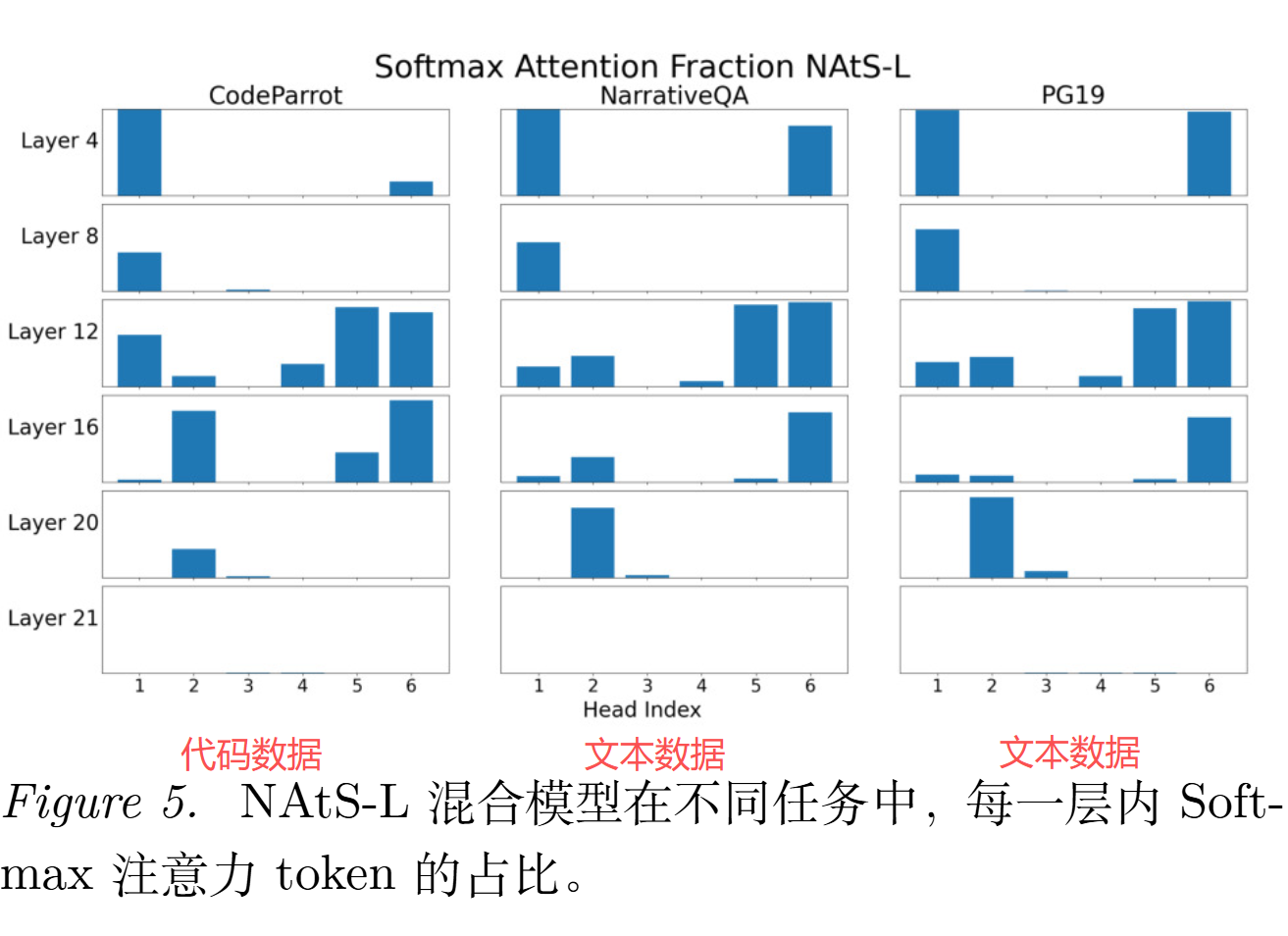
可见:
- 有的 head 似乎"只写摘要"(几乎全线性)
- 有的 head 会"摘要 + 关键原文一起留"(混合)
- 浅层更偏线性、深层更偏 softmax(先局部加工,再更抽象的维度上才全局检索)
- 但几乎没有 head 是"全都留原文"(纯 softmax)
- 各 head 的路由分布与任务相关,说明路由器不是学了一个死规则,而是能随机应变
六、后续优化
扩大搜索空间
目前只在 softmax 和 GDN 两种操作里选,未来可以把更多线性/稀疏/混合注意力也放进可选菜单
效果-效率权衡
NAtS-L 目前没加"softmax 用量"的约束,未来可以通过正则,让模型在效果与效率之间更可控地权衡