合规自动化:AI 在资产发现与数据合规治理中的"上帝之眼"
你好,我是陈涉川,欢迎你来到我的专栏。这是 模块三:盾之固------AI 加固的防御体系 的 收官之作。
在前九篇中,我们构建了强大的检测引擎、欺骗系统和响应机制。但对于首席信息安全官(CISO)而言,还有一个挥之不去的噩梦:合规(Compliance)。
GDPR 的罚款高达全球营收的 4%;数据泄露后的法律诉讼可能拖垮一家上市公司。面对 PB 级的数据湖、数以万计的云资产和瞬息万变的法律条文,传统的"人工审计"和"Excel 填报"已经彻底失效。
本章将带你进入安全治理的深水区。我们将探讨 AI 如何从"审计员"的角色进化为全自动的"数字资产管家",利用 NLP、计算机视觉和图算法,自动绘制数据地图,精准识别敏感信息,让合规不再是阻碍业务的绊脚石,而是企业数据治理的基石。
引言:看不见的冰山与"薛定谔"的合规
在网络安全的世界里,攻防对抗往往占据了聚光灯的中心。APTs、零日漏洞、勒索软件,这些词汇充满了硝烟味。然而,在董事会的会议室里,真正让高管们夜不能寐的,往往是另一个更沉闷却更致命的词:合规(Compliance)。
想象一下,你是一家跨国企业的 CISO。此刻,冷汗可能已经打湿了你的衬衫后背。因为你的 CEO 问了你三个问题:
- "我们在全球到底有多少台服务器直接暴露在公网上?"
- "我们的客户信用卡信息,是否被误存到了开发环境的日志里?"
- "如果欧盟审计员明天来检查,你能保证我们所有的 AI 模型训练数据都符合 GDPR 的'被遗忘权'吗?"
在 2010 年,你或许可以通过询问 IT 部门主管并查阅 Excel 资产表来回答。但在云原生和大数据时代,这三个问题几乎是无解的。
- 资产的流动性: 开发人员只需一行 Terraform 代码,就能在几秒钟内启动 100 个 AWS EC2 实例。
- 数据的弥散性: 数据不再静止在数据库里,它在微服务之间流动,被复制到数据湖(Data Lake),被转储到 S3 存储桶,被截图发送到 Slack。
- 影子的不可见性: Shadow IT(影子 IT)泛滥,业务部门绕过 IT 采购 SaaS 服务,数据在不受控的角落里野蛮生长。
传统的合规治理是快照式(Snapshot-based)的:每年一次审计,平时"听天由命"。 而 AI 驱动的合规自动化,致力于实现持续合规(Continuous Compliance)。它不仅仅是一个检查工具,更是一个具有全知视角的"上帝之眼"。它利用自然语言处理(NLP)理解数据的内容,利用计算机视觉(CV)看懂文档的结构,利用图神经网络(GNN)推断资产的关系。
本章将深入探讨这一变革。我们将从资产发现(ASM)开始,摸清家底;然后深入敏感数据识别(DLP),精准分类;最终构建一套自动化的治理体系。
第一章:影子资产的狩猎------AI 驱动的攻击面管理(EASM)
你无法保护你看不见的东西。
资产发现(Asset Discovery)是所有合规工作的起点。传统的资产发现依赖于 CMDB(配置管理数据库)和主动扫描(Nmap/Masscan)。但 CMDB 永远是过时的,而 Nmap 只能告诉你端口开了,却不能告诉你这个资产"属于谁"以及"用来干什么"。
1.1 从 IP 到业务语义:资产指纹的智能化
当扫描器发现一个开放 80 端口的 IP 203.0.113.5 时,传统工具只能报告:HTTP Service, Nginx 1.18。
这对于合规来说毫无意义。我们需要知道:这是测试服务器?还是处理核心支付业务的生产服务器?
利用 AI 进行网页指纹分析:
我们可以训练一个多模态模型,结合 DOM 结构 、网页截图 和 文本内容 来推断资产属性。
- 视觉分析(CNN): 对网页进行截图,输入 ResNet 或 Vision Transformer。模型识别出页面包含"Login"框、公司 Logo 以及"Internal Use Only"的红色横幅。
- 文本分析(NLP): 抓取 HTML 中的 <title>, <footer>, meta 标签以及 Favicon 的 Hash 值。模型识别出关键词 "Staging", "Test", "Jenkins", "Swagger UI"。
- 推断结论: AI 给该资产打上标签:Type: DevTool, Sensitivity: High (Internal Exposed), Owner: DevOps Team。
案例:僵尸资产(Zombie Assets)识别
企业中存在大量废弃的资产,既消耗成本又带来风险。
AI 可以分析流量日志(VPC Flow Logs)和 DNS 记录。
- 特征: 该服务器过去 90 天没有任何业务流量流入,只有自动化的健康检查(Health Check)流量和定期的系统补丁更新流量。
- 判定: 这是一个"僵尸资产"。AI 自动生成工单建议下线,从而满足"资产最小化"的合规要求。
1.2 影子 API(Shadow API)的自动发现
在微服务架构中,API 是数据流转的毛细血管。开发人员经常上线了 API 却忘记在 API 网关(Kong/Apigee)注册,也没有更新 Swagger 文档。这些未管理的 API 是数据泄露的重灾区。
基于流量重组的 API 清单生成:
利用我们在第 25 篇中提到的 eBPF 或流量镜像技术,我们可以捕获所有的 HTTP 请求。
但这不仅仅是记录日志。我们需要利用 序列挖掘算法(Sequence Mining) 和 聚类算法(Clustering) 自动还原 API 结构。
- URL 参数化:
-
原始流量:
GET /users/123/orders/abc-999
GET /users/456/orders/xyz-888
-
- AI 归纳:
AI 识别出 123, 456 是数字 ID,abc-999 是 UUID。
自动生成模式:GET /users/{user_id}/orders/{order_id}。
2.数据类型推断:
分析 Response Body。
{"card": "4111-xxxx", "exp": "12/25"}AI 识别出这是 PCI-DSS 敏感数据。
3.生成合规报告:
"发现未注册 API GET /users/{id}/orders,该接口传输信用卡信息,但未开启 TLS 加密,违反 PCI-DSS 第 4.1 条。"
1.3 跨域资产关联(Graph Correlation)
很多时候,单一资产看起来是合规的,但它们之间的关系违规了。
- 规则: 生产环境(Prod)不能连接测试环境(Dev)。
- 现象: 资产 A(标记为 Prod)连接了 资产 B(标记为 Unknown)。
利用 图神经网络(GNN) 构建资产关系图谱。
- 节点: 服务器、数据库、S3 桶、负载均衡器。
- 边: 网络连接、IAM 权限、代码部署关系。
- 推理: GNN 通过邻居节点传播标签。如果 Unknown 资产 B 的所有入站连接都来自 Dev 环境,且它运行着调试版本的镜像,那么 GNN 会以极高置信度将 B 标记为 Dev。
- 违规检测: 此时,边 A(Prod) -> B(Dev) 就显现为一条红色的违规链路(Lateral Movement Path or Data Leakage Path)。
第二章:数据分类分级(DLP)的智能化革命
摸清了"管道"(资产),接下来要搞清楚管道里流的是"水"还是"油"(数据)。
数据防泄漏(DLP, Data Loss Prevention) 的核心痛点在于识别(Identification)。
传统的 DLP 依赖 正则表达式(RegEx) 和 关键词匹配。
- 匹配 \d{16} 认为是信用卡。
- 匹配 confidential 认为是机密文件。
这种方法在海量数据面前面临着"误报(False Positive)"和"漏报(False Negative)"的双重夹击。
- 误报: 任何 16 位数字都被当成信用卡(比如订单号、日志 ID)。
- 漏报: 攻击者把 "Credit Card" 改写成 "C.C." 或者 "Payment Method",正则就瞎了。
2.1 超越正则:NLP 在实体识别(NER)中的应用
命名实体识别(NER, Named Entity Recognition) 是 NLP 的经典任务。在安全领域,我们需要训练专门的 Security-NER 模型。
上下文感知(Context Awareness):
BERT 或 RoBERTa 等 Transformer 模型最大的优势在于理解上下文。
- Case A: "The order id is 4111111111111111."
- Case B: "Please charge my card 4111111111111111."
对于正则来说,这两个都是 16 位数字。
对于 BERT 来说,Case A 周围的词是 "order id",Case B 周围的词是 "charge", "card"。
BERT 的 Attention 机制 会关注到 "card" 这个词,从而给予 Case B 极高的"信用卡"置信度,而将 Case A 排除。这极大地降低了误报率。
2.2 小样本学习(Few-Shot Learning)与自定义实体
企业往往有自己特定的数据格式,比如"员工工号"、"项目代号(Project Titan)"。通用模型无法识别。
利用 GPT-4 或微调的小型模型(如 DistilBERT),我们可以通过提供 3-5 个样本,快速教会 AI 识别新类型的数据。
- Prompt:
"Here are examples of our internal 'Project Codes': Alpha-X1, Beta-Y2, Gamma-Z9. Find all Project Codes in the following text: 'The delays in Omega-W5 are causing issues.'"
- AI Output:
"Found: Omega-W5."
这种灵活性使得合规系统能够适应业务的快速迭代。
2.3 隐性关联挖掘:跨字段的 PII 组合发现
在 GDPR 中,PII(个人身份信息)的定义非常广泛,不仅包括姓名、身份证,还包括 IP 地址、Cookie ID、地理位置轨迹。
AI 模型可以跨字段进行语义聚合。
- 数据库表结构: Col_A: 39.9, Col_B: 116.3
- 传统工具: 认为是两个浮点数。
- AI 分析: 发现这两个列通常成对出现,且数值范围符合经纬度特征。判定为 Geolocation Data(敏感个人数据)。
第三章:非结构化数据的暗网------OCR 与视觉合规
结构化数据(数据库)只占企业数据的 20%。剩下的 80% 是非结构化数据:PDF 合同、扫描的身份证复印件、Slack 里的截图、白板上的架构图照片。这些被称为 Dark Data(暗数据),是合规的盲区。
3.1 OCR 与版面分析(Layout Analysis)
传统的 OCR(如 Tesseract)只能把图片转成一堆乱序的文字。它丢失了版面信息,导致无法理解数据的含义。
现代的多模态模型(如 Microsoft 的 LayoutLM 或 Google 的 DocOWL )同时结合了 图像特征 、文字内容 和 坐标位置(Bbox)。
场景:识别身份证图片
- 传统 OCR: 提取出 "姓名"、"张三"、"110101...",由于排版复杂,可能混在一起变成 "姓名张三110101..."。
- LayoutLM:
- 看到左上角有国徽(视觉特征 -> 身份证)。
- 看到 "公民身份号码" 字样(文本特征)。
- 提取其右侧或下方的 18 位数字(位置特征)。
- 结论: 这是一张中国居民身份证,且未加盖"仅供办理业务使用"的水印(合规风险提示)。
3.2 视频与音频的合规审计
随着远程会议(Zoom/Teams)的普及,大量的敏感信息存在于会议录屏中。
- ASR(自动语音识别): 将音频转录为文本。
- NLP 审计: 分析转录文本。
- "好的,我的密码是 123456,请帮我重置。" -> 检测到口播密码。
- "我们计划在 Q4 收购 A 公司。" -> 检测到内幕信息泄露。
AI 系统可以自动扫描这些录像文件,标记违规时间戳,并通知合规官进行处理。
第四章:代码仓库的秘密------Secrets Detection 2.0
源代码是企业最核心的资产,也是泄露凭证(Secrets)的重灾区。
开发人员经常将 AWS AK/SK、数据库密码、API Key 硬编码在代码中,然后推送到 GitHub。
4.1 从熵值检测到 LLM 语义分析
早期的工具(如 TruffleHog, GitLeaks)主要依赖 熵值(Entropy) 检测。
- 原理: 密钥通常是随机字符串,熵值很高。
- 缺点: 误报极高。i_love_coffee 的哈希值熵值也很高;混淆后的代码熵值也很高。
LLM 驱动的 Secrets Detection:
AI 不仅看字符串本身,还看变量名 和代码上下文。
- Case A: const my_hash = "a1b2c3d4e5..." (熵值高,但变量名叫 hash,可能是校验和,风险低)
- Case B: const stripe_key = "sk_live_..." (熵值高,变量名包含 key,前缀符合 Stripe 格式,风险极高)
- Case C: // use this for testing only: password = "admin" (熵值低,但注释表明这是密码,且未加密,风险高)
LLM 能够理解 Case C 这种低熵值但高风险的情况,这是传统工具做不到的。
4.2 基础设施即代码(IaC)的合规扫描
在云原生环境下,基础设施(防火墙、负载均衡、S3 权限)都是代码(Terraform, Kubernetes YAML)。
这给了我们 Shift Left(左移) 的机会:在资源创建之前就进行合规检查。
Policy-as-Code (PaC) + AI:
-
User: 写了一个 Terraform 文件,创建了一个 S3 Bucket,设置 acl = "public-read"。
-
AI Copilot: 实时拦截。
Terraform resource "aws_s3_bucket" "example" { acl = "private" # AI Auto-fix server_side_encryption_configuration { ... } }- "检测到你正在创建一个公开可读的存储桶。"
- "根据公司《数据安全规范》第 3 章,所有存储桶必须默认为私有,且开启 KMS 加密。"
- "是否自动应用以下修复代码?"
这不仅仅是扫描,这是即时教育 和自动修复。
第五章:代码实战------构建基于 Transformers 的 PII 扫描器
说了这么多理论,让我们动手写一个简单的 PII 扫描器。我们将使用 Hugging Face 上的预训练模型来识别文本中的敏感实体。
5.1 环境准备
我们需要安装 transformers 和 torch。我们将使用微软的 presidio-analyzer(基于正则和逻辑)配合 bert-base-NER(基于深度学习)来构建混合引擎。但在本例中,为了展示 AI 的能力,我们专注于 BERT 部分。
python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
# 1. 加载预训练的 NER 模型
# dslim/bert-base-NER 是一个经典的在 CoNLL-2003 数据集上微调的模型
# 它可以识别 Person (PER), Organization (ORG), Location (LOC), Miscellaneous (MISC)
model_name = "dslim/bert-base-NER"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
# 2. 创建 Pipeline
nlp = pipeline("ner", model=model, tokenizer=tokenizer, aggregation_strategy="simple")
# 3. 模拟一段包含敏感信息的文本(比如客服聊天记录)
text = """
Hello, my name is Sarah Connor. I live in Los Angeles.
I am calling from Cyberdyne Systems regarding ticket #9982.
My email is sarah.connor@cyberdyne.com.
"""
# 4. 执行识别
results = nlp(text)
# 5. 解析结果
print(f"Original Text: {text}\n")
print("Detected Entities:")
for entity in results:
print(f" - Type: {entity['entity_group']}, Word: {entity['word']}, Score: {entity['score']:.4f}")
# 6. 自定义 PII 掩码函数 (Redaction)
def redact_text(text, entities):
redacted_text = text
# 按位置倒序替换,防止索引偏移
for entity in sorted(entities, key=lambda x: x['start'], reverse=True):
if entity['entity_group'] in ['PER', 'LOC', 'ORG']: # 假设我们要屏蔽人名、地名、组织名
start, end = entity['start'], entity['end']
mask = f"<{entity['entity_group']}>"
redacted_text = redacted_text[:start] + mask + redacted_text[end:]
return redacted_text
print("\nRedacted Text:")
print(redact_text(text, results))5.2 代码解读与优化
- 模型选择: 上述代码使用的是通用的 NER 模型。在金融或医疗场景,你应该使用特定领域的模型(如 ClinicalBERT)或使用自己的数据进行微调(Fine-tuning)。
- 聚合策略(Aggregation Strategy): BERT 分词(Tokenizer)会将单词切分为 Sub-words(如 "Cyberdyne" 可能变成 "Cyber" + "##dyne")。aggregation_strategy="simple" 会自动将这些片段合并回完整的单词,这对提取完整的 PII 至关重要。
- 局限性: 仅靠 NER 无法识别像"信用卡号"这样的模式,因为它们在通用的语料库中被视为数字。因此,工业级的 DLP 方案通常是 AI (NER) + 正则 (Regex) + 校验算法 (Luhn Algorithm) 的组合拳。
第六章:技术挑战------误报与性能的平衡
在合规自动化中,性能是一个巨大的瓶颈。
扫描一个 1TB 的数据库,如果用 BERT 逐条推理,可能需要几个月。
6.1 采样与分层扫描(Sampling & Tiered Scanning)
不要试图用 AI 扫描每一个字节。
- L1 快速扫描(Metadata Scan): 检查表名、字段名。如果字段名叫 user_password,直接标记高危,无需看内容。
- L2 正则扫描(Regex Scan): 对 L1 未命中的字段,抽取前 1000 行数据,用高性能正则引擎(如 Hyperscan)快速筛查。
- L3 AI 深度扫描(AI Deep Scan): 仅对 L2 中疑似但无法确定的数据(如"这是乱码还是加密后的密码?"),或者非结构化文档,调用 LLM/BERT 进行昂贵的深度分析。
6.2 假阳性(False Positives)的抑制
合规告警的误报会让业务部门崩溃。
我们可以引入 基于规则的后处理(Rule-based Post-processing)。
- 规则: 如果 AI 识别出 "Python" 是 LOC (地点),但上下文中有 "programming language",则修正为 MISC 或忽略。
- 置信度阈值: 仅报告置信度 > 0.95 的发现。对于 0.8-0.95 的,进入人工复核队列(Human-in-the-Loop)。
第七章:从法条到配置------CSPM 与 SSPM 的语义鸿沟
云安全态势管理(CSPM)和 SaaS 安全态势管理(SSPM)是现代合规的支柱。
然而,传统 CSPM 工具(如 Prisma Cloud, Wiz)的核心痛点在于 "语义鸿沟(Semantic Gap)"。
- 法务视角(Lawyer's View): "根据 HIPAA 规定,所有包含患者健康信息(PHI)的数据必须在传输和存储时加密。"
- 工程师视角(Engineer's View): aws s3api put-bucket-encryption --bucket my-bucket ... 或 server_side_encryption_configuration = "AES256"。
中间缺少一个"翻译官"。传统的做法是靠安全专家手动编写几百条 Rego 策略或 OPA(Open Policy Agent)规则。每当法律更新或云服务推出新功能(比如 AWS 新出了个 Lake Formation),这个过程就要重来一遍。
7.1 LLM 作为"法律-技术"转译器
大语言模型(LLM)天生就是最好的翻译官。它既读过人类的法律文本(GDPR, CCPA, ISO 27001),也读过机器的配置文档(Terraform, Kubernetes Manifests, AWS SDK)。
工作流程:
- 输入法条: "GDPR 第 32 条:控制者和处理者应实施适当的技术和组织措施,以确保障安水平与风险相适应。"
- LLM 推理(Chain-of-Thought):
- 思考: "适当的技术措施"通常包括加密、假名化、访问控制。
- 上下文: 当前环境是 AWS。
- 映射: 对应 AWS 服务:KMS(加密)、IAM(访问控制)、CloudTrail(审计日志)。
- 生成检测规则(Policy-as-Code):
LLM 自动生成 OPA/Rego 代码:
python
package aws.s3
# Deny if encryption is not enabled
deny[msg] {
bucket := input.resource.aws_s3_bucket[name]
# 检查加密配置是否存在
count(bucket.server_side_encryption_configuration) == 0
msg = sprintf("GDPR Art. 32 Violation: S3 bucket '%v' missing encryption", [name])
}7.2 动态合规映射(Dynamic Compliance Mapping)
随着业务变化,合规要求也在变。
- 场景: 业务部门突然决定进军欧洲市场。
- 传统做法: 购买咨询服务,花费 6 个月进行 GDPR 差距分析。
- AI 做法:
- CISO 告诉 AI:"我们将处理欧盟公民数据。"
- AI 自动激活"GDPR 知识库"。
- AI 扫描现有的基础设施代码(IaC)。
- 差距报告: "发现 15 个 DynamoDB 表位于 us-east-1(弗吉尼亚),但这违反了 GDPR 的数据驻留(Data Residency)要求。建议迁移至 eu-central-1(法兰克福)或 eu-west-1(爱尔兰)。"
这种 "意图驱动(Intent-Driven)" 的合规,将原本静态的检查表变成了动态的护栏。
第八章:Chat with Compliance------RAG 驱动的智能助手
面对堆积如山的合规文档(内部策略、外部法规、审计报告),员工往往无所适从。
"我能不能把客户数据发给 ChatGPT 润色邮件?"
"我在家里用私人电脑办公违规吗?"
没人会去翻那本 200 页的《员工安全手册》。
我们需要一个 RAG(检索增强生成) 系统,让合规变得"可对话"。
8.1 架构设计:构建企业合规大脑
我们不需要训练一个新模型,我们只需要让 LLM "外挂"上企业的知识库。
- 知识摄入(Ingestion):
- 收集文档:ISO 27001 标准、公司《数据安全管理办法》、IT 运维手册、过往审计问卷(SIG/CAIQ)。
- 切片(Chunking):将文档按章节或语义切分为 500-1000 token 的片段。
- 向量化(Embedding):
- 使用 text-embedding-ada-002 或 BERT 将文本片段转换为向量。
- 存入向量数据库(如 Milvus, Pinecone, ChromaDB)。
- 检索与生成(Retrieval & Generation):
- 用户提问: "如果我想采购一个新的 SaaS 工具,流程是什么?"
- 检索: 系统在向量库中找到《第三方供应商管理规定》第 4 章。
- 生成: LLM 结合检索到的内容回答:"根据规定,你需要先填写《供应商安全评估表》,经安全部审批后方可采购。如果涉及 PII,还需签署 DPA(数据处理协议)。表单链接在这里:Link。"
8.2 自动化回答审计问卷(Auto-filling Questionnaires)
对于 B2B 企业,回答客户发来的安全问卷(Security Questionnaires)是销售流程中最痛苦的环节。几百个问题:"你们有做渗透测试吗?""你们的数据备份策略是什么?"
利用 RAG,AI 可以自动回答这些问题。
- 输入: 客户发来的 Excel 问卷。
- 处理:
- AI 读取问题:"Do you encrypt data at rest?"
- AI 检索内部知识库(白皮书、SOC2 报告)。
- AI 生成答案:"Yes, we use AES-256 for all data at rest via AWS KMS."
- 引用来源: "参见《SOC2 Type II Report 2023》第 15 页。"
- 效果: 将原本需要安全工程师 3 天的工作缩短到 3 分钟。
第九章:隐私工程------如何在不看数据的情况下使用数据?
合规的终极目标不是"不使用数据",而是"安全地使用数据"。
AI 在这里扮演了双重角色:既是隐私泄露的风险源 (参见模块四),也是隐私保护的技术手段。
9.1 差分隐私(Differential Privacy, DP)
这是一种数学定义的隐私保护标准。
简单来说,差分隐私保证了:攻击者无法通过查询结果推断出某个特定个体是否在数据集中。
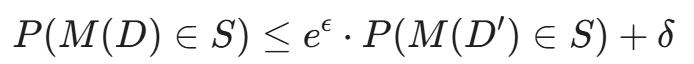
(不用深究公式,理解 \\epsilon 是隐私预算即可,值越小隐私保护越强。)
AI 的应用:
在训练 AI 模型或生成统计报表时,AI 可以自动计算需要添加多少 拉普拉斯噪声(Laplace Noise) 或 高斯噪声,以满足 \\epsilon 的要求,同时最大化数据的可用性(Utility)。
- 场景: 统计员工薪资分布。
- 传统: 直接算出平均值。如果只有 2 个人,平均值就泄露了。
- DP-AI: 自动添加扰动。输出结果虽然不是精确的平均值,但足以反映趋势,且数学上证明了无法反推个人薪资。
9.2 合成数据(Synthetic Data)与 GANs
如果数据太敏感(如医疗记录、金融交易),连脱敏都可能有风险,最好的办法是 "造假"。
利用 生成对抗网络(GANs) 或 变分自编码器(VAEs),甚至最新的 扩散模型(Diffusion Models),
我们可以生成 合成数据。
- 真实数据: 100 万条真实的信用卡交易记录。
- 训练: 用这些数据训练一个 GAN。
- 生成: GAN 生成 100 万条全新 的交易记录。
- 统计特性一致: 男女比例、消费金额分布、欺诈模式与真实数据完全一样。
- 隐私安全: 生成的数据在现实世界中找不到对应的人。没有真实的姓名,没有真实的卡号。
AI 的价值:
合规部门可以将这份"合成数据"放心地交给第三方分析公司、开发测试团队,甚至公开发布,而无需担心 GDPR/CCPA 违规。这彻底解决了"测试环境不得使用生产数据"的合规难题。
9.3 机器遗忘(Machine Unlearning):AI 时代的"橡皮擦"
还记得引言中 CEO 的第三个问题吗?"如果用户要求行使'被遗忘权',我们能从 AI 模型中删除他的数据吗?"
在传统数据库中,这只是一个 DELETE FROM users WHERE id = 123 的 SQL 语句。但在 AI 领域,这是一个世界级的难题。数据一旦参与了训练,它的特征就"弥散"在了神经网络数以亿计的权重参数中。你不能简单地把参数置零,那会破坏模型的智力。
为了合规,我们需要引入 机器遗忘(Machine Unlearning) 技术。
- SISA 训练架构(Sharded, Isolated, Sliced, Aggregated) :
- 原理:不要把所有数据放在一个大锅里煮。我们将训练数据分成 10 个切片(Shards),训练 10 个子模型,最后聚合结果。
- 合规优势 :当用户 A 要求删除数据时,我们只需要定位到他所在的那个切片,重新训练那 1/10 的子模型即可。这比重新训练整个大模型快 10 倍,极大降低了合规成本。
- 影响函数(Influence Functions) :
- 利用数学方法计算特定数据点对模型参数的"影响力"。
- 通过对参数进行逆向更新(反向梯度),在不重新训练的情况下,从数学上"抵消"该数据对模型的影响。
合规价值: 这让 AI 系统具备了真正的"可审计性"。当监管机构询问时,你可以出示数学证明:"该用户的数据影响已从权重 W 中剔除,模型现在的行为与从未见过该数据时一致。"
第十章:人的因素------AI 时代的合规官
技术再先进,最终责任人(Accountability)还是人。
AI 不会坐牢,CISO 会。
10.1 AI 治理委员会(AI Governance Board)
企业需要建立新的组织架构。不仅仅是 IT 部门,还包括法务、HR、伦理委员会。
- 角色: 审查 AI 模型的合规性。
- 工具: 使用 Model Cards(模型卡片)记录模型的训练数据来源、适用范围、潜在偏见。
- AI 辅助决策: AI 可以预扫描模型卡片,提示风险:"警告:该信用评分模型使用了'居住地邮编'作为特征,可能导致对特定族裔的间接歧视(Redlining),违反《公平信贷机会法》。"
10.2 持续监控与"人机回环"
合规不是一次性的。
- Continuous Compliance Monitoring (CCM): 这是一个 24/7 的仪表盘。
- Human-in-the-Loop: 当 AI 建议阻断某项业务操作(因为它判定违规)时,必须提供"申诉"按钮,让人类合规官介入复核。
结语:从"合规表格"到"数字护城河"
至此,AI 不再仅仅是一个只会画图或聊天的机器人,它穿上了西装,戴上了工牌,成为了企业中最不知疲倦的"合规官"。
通过本章,我们解决的不仅仅是罚款问题,而是信任问题。在数据即资产的时代,合规自动化(Compliance Automation) 是企业数字化转型的安全带。没有它,跑得越快,死得越惨。
【模块三总结】盾之固------构建自适应的防御体系
随着第 28 篇的落幕,我们正式完成了 《硅基之盾:AI 与网络安全攻防全鉴》 的第三大模块------盾之固。
回望这十篇文章(第 19-28 篇),我们实际上是在构建一个有生命的、会呼吸的防御体系。如果说模块二是展示黑客如何用 AI 磨尖"矛",那么模块三就是教我们如何用 AI 铸造一面自我进化的"盾":
- 感知的进化(19-21 篇) : 我们抛弃了死板的特征码。从 自编码器 对异常流量的无监督发现,到 智能 SOC 的告警降噪,再到 EDR 在端点侧对勒索软件的实时阻断。我们让防御系统学会了"察言观色"。
- 身份与诱捕(22-24 篇) : 防御不再是被动的挨打。通过 行为生物识别 ,我们锁定了攻击者的身份;通过 AI 补丁生成 ,我们缩短了暴露窗口;通过 动态蜜罐,我们甚至开始主动戏弄攻击者,扭转了攻防的不对称性。
- 环境与治理(25-28 篇) : 我们将防线延伸到了云原生深处。从 eBPF 容器防御 到 ChatWithSecurity 的交互式狩猎,再到攻克 加密流量 的堡垒,最终以今天的 合规自动化 为整个体系兜底。
我们构建了一座看似坚不可摧的"硅基堡垒"。这套系统能自动发现威胁、自动修补漏洞、自动处理合规风险。CISO 似乎终于可以睡个好觉了。
但是......真的可以吗?
在我们在前三个模块中,所有的假设都建立在一个隐含的前提 之上: ------ AI 模型本身是可信的、坚固的、不可战胜的。
我们假设 AI 永远能正确识别猫和狗;我们假设 AI 永远不会泄露训练数据;我们假设 AI 永远忠诚地执行我们的指令。
如果这个地基崩塌了呢?
- 如果黑客不再攻击你的服务器,而是给你的 AI 模型"下毒"?
- 如果他在路边的停车牌上贴了一张特制的贴纸,你的自动驾驶汽车就会无视"停止"信号,加速撞向人群?
- 如果你的竞争对手不需要入侵数据库,只需要通过 API 不断提问,就能**"偷走"**你花费千万美元训练的模型参数?
当防御者依赖 AI 时,AI 本身就成了最大的单点故障(SPOF)。
欢迎进入 模块四:内生安全------AI 模型本身的安全性。
这是目前安全界最前沿、最烧脑、也最令人细思极恐的领域。我们将不再讨论如何用 AI 保护系统,而是讨论 如何保护 AI 本身。
我们将剥开神经网络的黑盒,直面数学层面的"幽灵"。
下期预告:第 29 篇《对抗性攻击:一张贴纸如何让自动驾驶视觉系统失效?》 为什么人类眼中的"熊猫",在加上一点点看不见的噪声后,AI 却以 99% 的置信度认为是"长臂猿"?这不是科幻小说,这是数学对感知的欺骗。敬请期待。
陈涉川
2026年02月13日