摘要
本文首先介绍了FSDP的原理和流程,包括参数分片策略、通算掩盖方式以及训练各阶段的执行逻辑。然后结合实验数据,对不同FSDP配置下的性能进行了分析和拆解,明确各个参数对训练速度和显存的影响。最后,简单介绍了FSDP2的原理和优势,并针对LORA训练这一优势场景,与FSDP进行了对比分析。本文不涉及源码的讲解,适合入门分布式训练。
前言
随着数据和模型规模的增加,设备显存成为了制约大模型训练效率的关键因素。当模型参数规模超过了单个设备的显存容量时,如何在有限的硬件资源下高效地训练模型,是算法和工程团队持续关注的问题。
PyTorch 作为深度学习领域的主流框架,其并行策略在不断演进:
● DataParallel(DP)通过单进程多线程实现数据并行,受限于 GIL 锁与单机架构,参数通信效率较低;
● DistributedDataParallel(DDP)采用多进程架构,通过 Ring-AllReduce 等高效通信模式优化梯度同步,成为中小规模分布式训练的标配方案,但仍要求单卡能容纳完整模型参数;
● 当单个设备放不下整个模型时,FullyShardedDataParallel(FSDP)将训练过程中的模型参数、模型梯度和优化器状态切分到不同的设备上,对静态显存进行分割,实现了大模型的分布式训练;
● FSDP2在FSDP的基础上引入了DTensor,移除了FlatParameter,对Tensor的第0维(或指定维度)进行切片,实现了更高效的通信和内存管理
一、原理介绍
FSDP是PyTorch基于ZeRO-3实现的一种数据并行策略,能够将模型参数、梯度、优化器状态切分到不同的设备上,按需进行通信。
PyTorch官方对FSDP的一句话介绍:
FullyShardedDataParallel:a wrapper for sharding module parameters across data parallel workers.
对于一个模型或者模块,通常有两种切分思想:
**1. 使用分片后的参数执行计算,通信激活值:**例如megatron中的张量并行,对linear层的参数进行切分,对中间结果进行通信;优点是不需要对模型参数进行通信,缺点是这种通信不容易与计算重叠,因为连续的计算之间存在依赖关系。
**2. 通过按需通信参数,执行与完整模型相同的计算:**ZeRO和FSDP属于这一类,优点是参数通信不依赖前面的计算,在通信参数的同时,可以执行与所需参数无关的计算任务;但要求单个设备的内存可以放下通信后的参数。
下图为三种ZeRO策略下每个设备的静态显存占用,从上到下依次对应 ZeRO-1、ZeRO-2、ZeRO-3:ZeRO-1 切分优化器状态,ZeRO-2 额外切分模型梯度,ZeRO-3 则进一步切分模型参数。
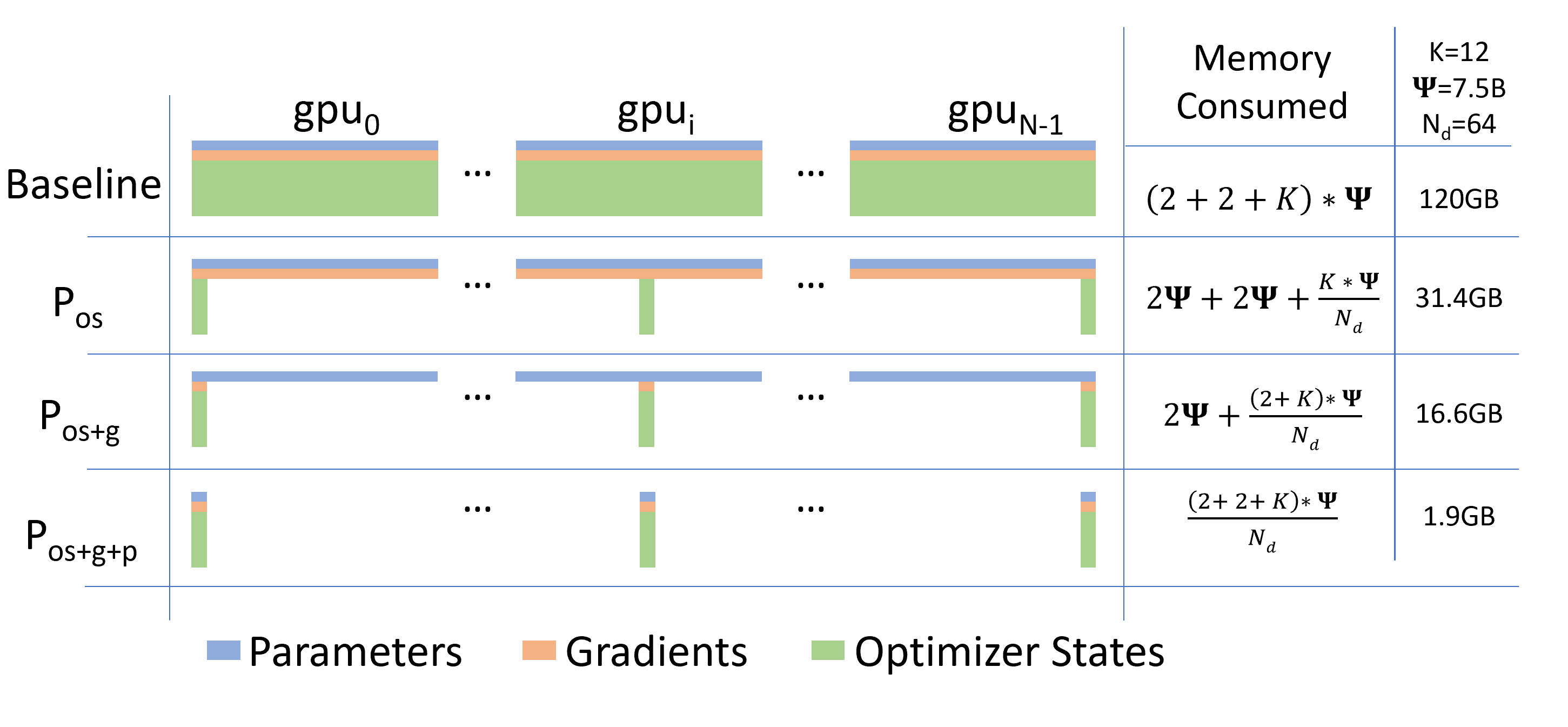
图中, ψ表示模型参数量,K表示优化器状态的内存倍数,以bf16混合精度训练,AdamW优化器为例,在训练过程中,模型参数和梯度的数据类型为bf16,优化器状态的数据类型为FP32。并行方式为DDP时,占用的静态显存为(2+2+12)ψ。
当参数量为7.5 B,DDP,ZeRO-1,ZeRO-2,ZerO-3占用的静态显存分别为120 GB, 31.4 GB,16.6 GB,1.9 GB
此外,ZeRO-1,ZeRO-2与DDP的通信量相同,ZeRO-3的通信量是DDP的1.5倍,原理可参考论文https://arxiv.org/abs/1910.02054
FSDP 作为 PyTorch 原生接口,代码设计相比DeepSpeed更贴合框架原生逻辑,无需引入外部依赖,更加的简洁和高效。
FSDP 可与 TP 混合使用:FSDP 不关注权重形状,只需在其分片前完成 TP 的权重切分即可。FSDP 会在 forward 前 all-gather 完整权重,因此进行TP 计算时,FSDP 域的参数是完整的。
二、基本用法
torch / torch_npu FSDP 的功能逐步完善:
2.1 版本:首次支持基础 FSDP 特性,实现大模型分片训练;
2.3 版本:新增 DeviceMesh 支持,可结合 HSDP(混合分片数据并行)灵活定义设备拓扑;
2.6 版本:新增 FSDP2特性,引入 DTensor,移除了FlatParameters,进一步优化了通信与内存管理。
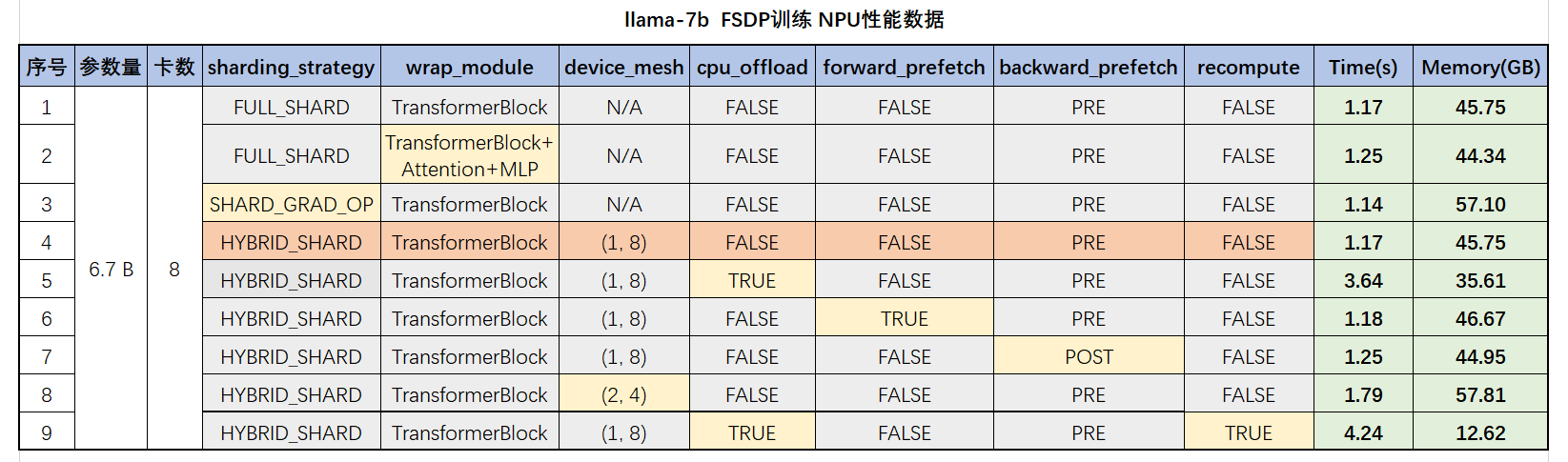
FSDP的配置不同,性能也不同;下面是 llama-7B 在 8 卡 NPU 上的性能测试数据,各参数的含义后面会说明
上面第4行是推荐配置,性能和显存都比较好;recompute是基于torch.utils.checkpoint实现,非FSDP接口
可以参考我的Github仓库:icerain-alt/FSDPToys: Learning and Debugging for FSDP/FSDP2 Training。可以不加载权重和数据集,一键拉起,支持FSDP/FSDP2训练和一些常用的显存优化技巧。
为什么算法人员喜欢用FSDP?
1、PyTorch原生支持,无需安装其他依赖
2、与单卡训练代码差异不大,只需在初始化时添加 FSDP 封装逻辑
3、对于一个新模型,可以快速的基于FSDP适配
4、让算法人员更专注于模型本身的迭代,而非工程实现细节
下面是一段伪代码,模型是**DiffusionTransformer(DiT)** ,FSDP的切分策略是**FULL_SHARD**
python
# 导入FSDP相关API
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import ModuleWrapPolicy
from torch.distributed.fsdp.api import MixedPrecision, ShardingStrategy
from dit import DiffusionTransformer, TransformerBlock
# 初始化模型
model = DiffusionTransformer()
# 指定参数分片策略,对DiT中的TransformerBlock进行分片
auto_wrap_policy = ModuleWrapPolicy({TransformerBlock})
# 应用FSDP
model = FSDP(
model,
device_id=rank,
auto_wrap_policy=auto_wrap_policy,
sharding_strategy=ShardingStrategy.FULL_SHARD, # ZeRO-3
mixed_precision=MixedPrecision(
param_dtype=torch.bfloat16,
reduce_dtype=torch.float32,
buffer_dtype=torch.float32,
),
limit_all_gathers=True
)
# 优化器初始化要放在FSDP之后
optimizer = torch.optim.AdamW(model.parameters(), lr=args.lr)FSDP 封装后,训练循环的计算和参数更新逻辑与单卡训练基本相同
python
for batch_idx, (inputs, targets) in enumerate(loader):
t0 = time.time()
inputs = inputs.cuda()
targets = targets.cuda()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()1、auto_wrap_policy和sharding_strategy是影响性能和显存的主要参数:
2、sharding_strategy用于控制切分深度,ZeRO-2还是ZeRO-3
3、auto_wrap_policy用于控制切分粒度,哪些module放在一起切分
三、设计思想
3.1 FSDP单元
FSDP通过指定wrap_policy,模型实例分解为Unit单元
每个单元的参数、梯度和优化器状态被分散到通信组的所有设备,独立进行计算和通信
在整个训练过程中,优化器状态保持分片状态
在前向和反向计算期间,FSDP一次只通信当前单元所需的参数,而其余参数保持分片状态(暂不考虑参数预取)
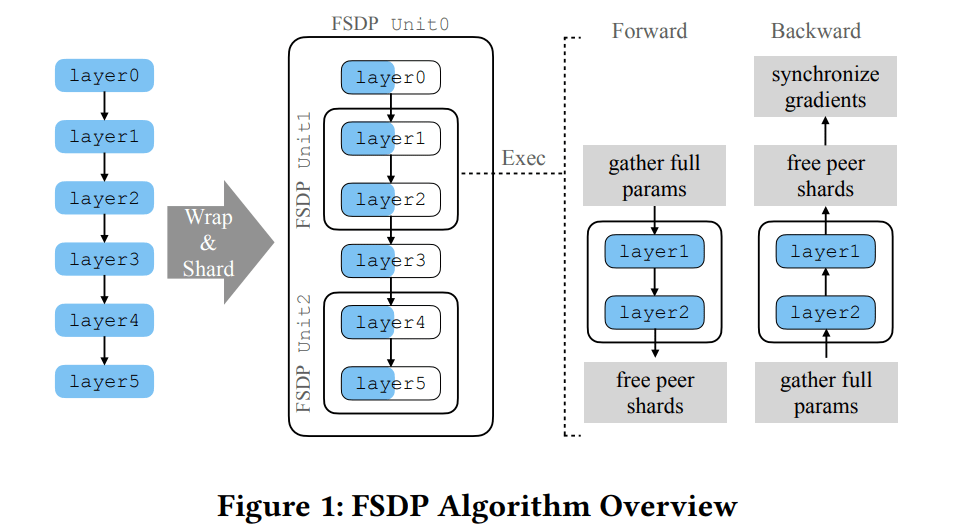
图中是一个6层的模型,划分为3个Unit,Unit 1包含layer 1和layer 2,Unit 2包含layer 4和layer 5,剩余的layer 0和layer 3分配给Unit 0
假设用2张卡进行训练,模型参数被分为2份。前向传播过程中,先把 Unit 0 的参数聚合,执行layer 0;执行到 layer 1 的时候,再把 Unit 1 的参数聚合,用来执行 layer 1 和 layer 2;等 layer 2 执行完,再把 Unit 1 的参数释放掉;在聚合Unit 0的时候,layer 3的参数已经还原了,所以直接执行layer 3;接着执行到 layer 4,再聚合 Unit 2 的参数,用来执行 layer 4 和 layer 5;最后等 layer 5 执行完,把 Unit 2 的参数释放掉。
FSDP支持module和size两种wrap_policy,前者能对nn.Module的子类进行包裹,使用灵活,性能也更好;后者有一些额外的张量操作,涉及将一个module拆开,或者多个module合并,不推荐使用
以LLama模型为例,如果指定TransformerLayer进行分片,则每个TransformerLayer都是一个FSDP单元,里面的LayerNorm, Attention, MLP的参数会被聚合、展平、分散到不同的设备上
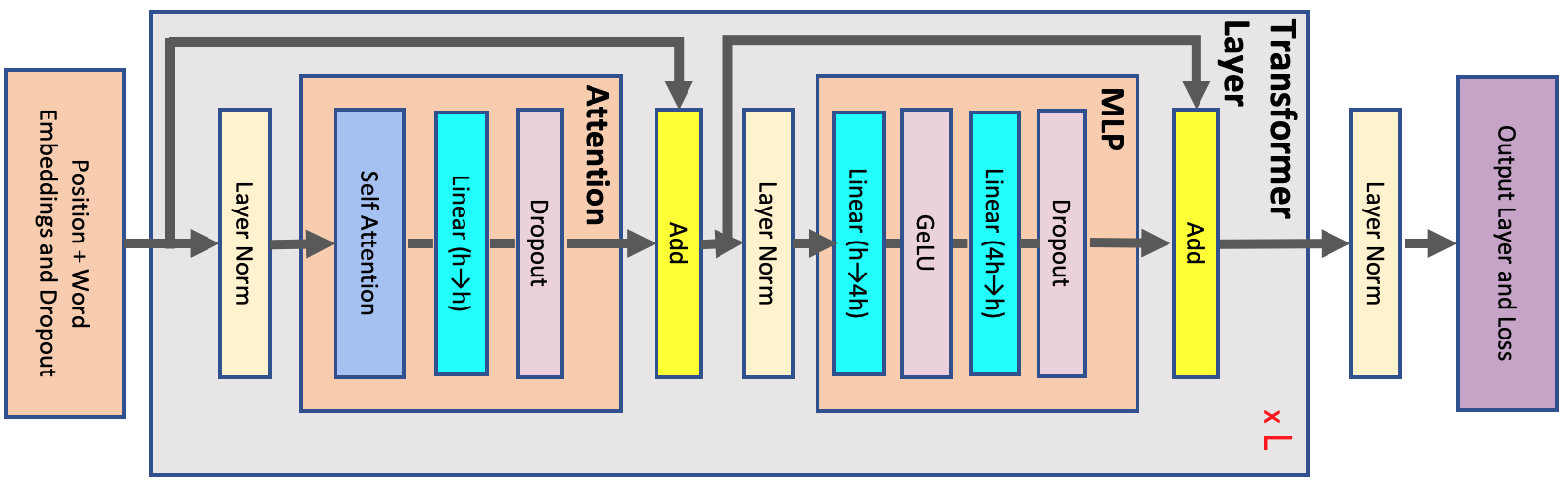
从单个TransformerLayer单元的视角来看,FSDP的通信和计算流程如下,忽略对Tensor的reshape操作:

有一点需要注意,最外层的FSDP单元(Unit 0) forward完成后,不会立即释放参数,要等到backward完成才会释放。因为Unit 0通常会包含模型的最后一层,forward计算完成后需要立刻backward,可以节省一次free和all-gather的开销。
除了指定单个TransformerLayer进行分片,FSDP还支持对多个 Module 进行分片 ,可同时指定(TransformerLayer, Attention, MLP)等多个层级。在不考虑通算异步的场景下,FSDP参数的聚合与释放遵循按需调度的逻辑。
当 forward 计算进入TransformerLayer时,FSDP 不会立即聚合该层级的所有参数,而是按计算流程分步处理:
1、首先聚合两个LayerNorm的参数,用于执行LayerNorm计算;
2、第一个LayerNorm计算完成后,聚合Attention的参数并执行计算,完成后立即释放Attention的参数分片;
3、第二个LayerNorm计算完成后,聚合MLP的参数并执行计算,完成后立即释放MLP的参数分片;
4、最终,待TransformerLayer整体计算结束,释放两个LayerNorm的参数分片。
与对TransformerLayer单个module分片对比,多层级分片可以降低峰值显存,但会增加通信次数,性能会有损耗。
因此,在计算 FSDP 的显存占用时,不仅要统计当前设备上的参数分片,还需考虑 all-gather 后最大 FSDP 单元的参数量。
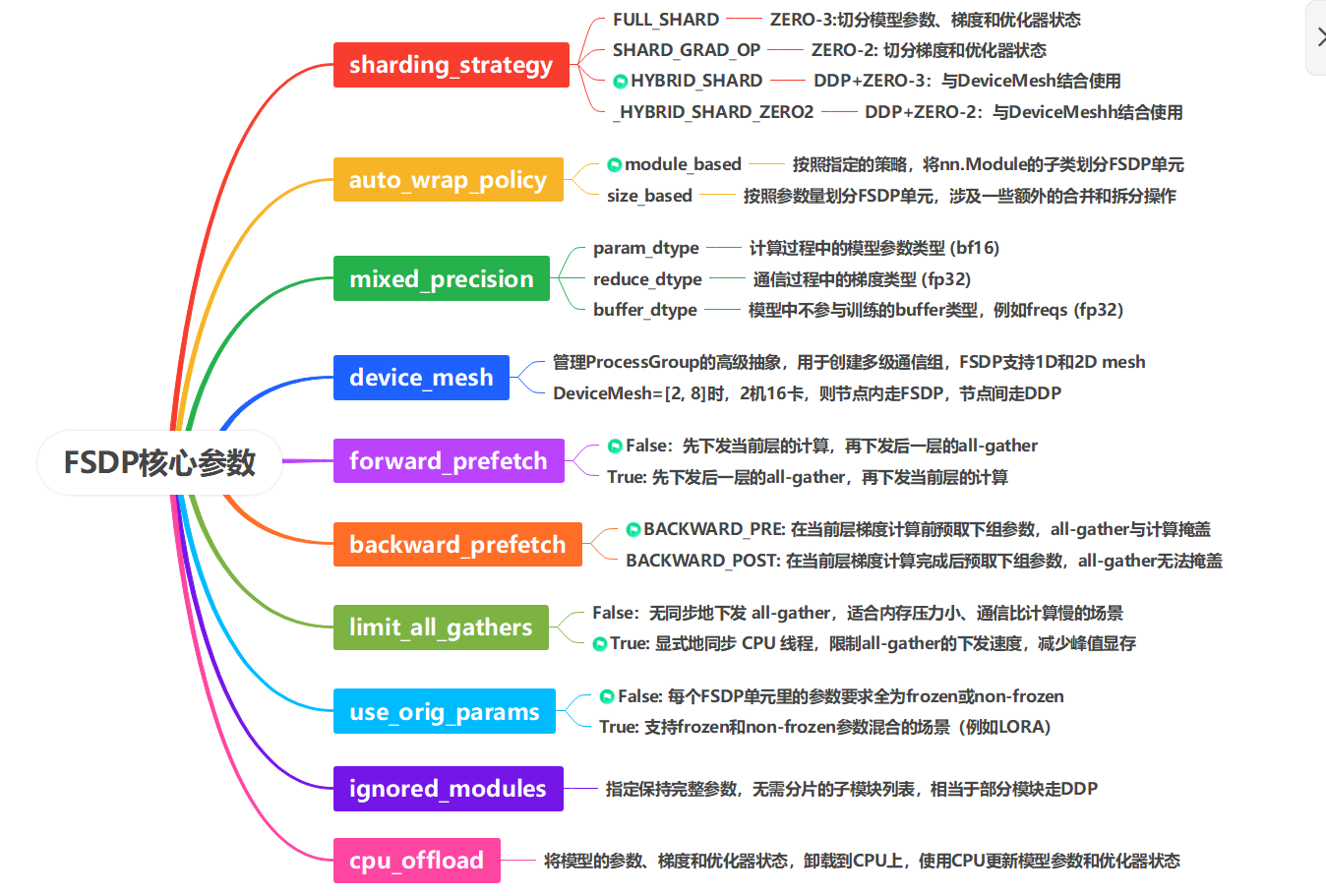
3.2 分片策略
与 DeepSpeed 相比对比,FSDP 不支持ZeRO-1 模式,两者的策略对应关系如下:
| FSDP | DeepSpeed | 切分说明 |
|---|---|---|
FULL_SHARD |
ZeRO-3 | 切分权重、梯度和优化器状态 |
SHARD_GRAD_OP |
ZeRO-2 | 切分梯度和优化器状态 |
2Ddevice_mesh + HYBRID_SHARD |
MiCS | device_mesh=2,8,0-7和8-15是2个FSDP组,模型复制两份,切分8份。rank_i和rank_{i+8}持有相同的权重--完整模型的1/8,rank_i和rank_{i+8}通过allreduce同步梯度。 |
2Ddevice_mesh + _HYBRID_SHARD_ZERO2 |
- | 按照device_mesh切分梯度和优化器状态 |
NO_SHARD |
- | 相当于DDP |
注意:
device_mesh仅在启用HYBRID_SHARD或_HYBRID_SHARD_ZERO2时生效,单独设置device_mesh不起作用
3.2.1 ZeRO与FSDP
以一个4 B的多模态模型为例,8卡FSDP并行,bf16混合精度训练,从SHARD_GRAD_OP改为FULL_SHARD,显存降低了5.6 GB
| 分片策略 | 端到端时间 | 计算时间 | 未掩盖通信时间 | 空闲时间 | 显存占用 |
|---|---|---|---|---|---|
FULL_SHARD |
8.02 | 7.66 | 0.21 | 0.15 | 52.9 G |
SHARD_GRAD_OP |
7.99 | 7.66 | 0.16 | 0.17 | 58.5 G |
4B 模型参数在 BF16 类型下占 8GB 显存,经 8 卡full shard分片后单卡仅存 1GB;而shard_grad_op在forward之后会持有完整的模型权重,单卡占8GB,理论增量应为 7GB。实际差值的原因在于, full shard在backward聚合unit参数的过程中存在额外的参数缓冲区(all-gather buffer)。参考:FSDP Notes --- PyTorch 2.3 documentation

FULL_SHARD的profiling图:前向两个all-gather预取权重;反向reduce-scatter当前层梯度,all-gather预取下一层的权重
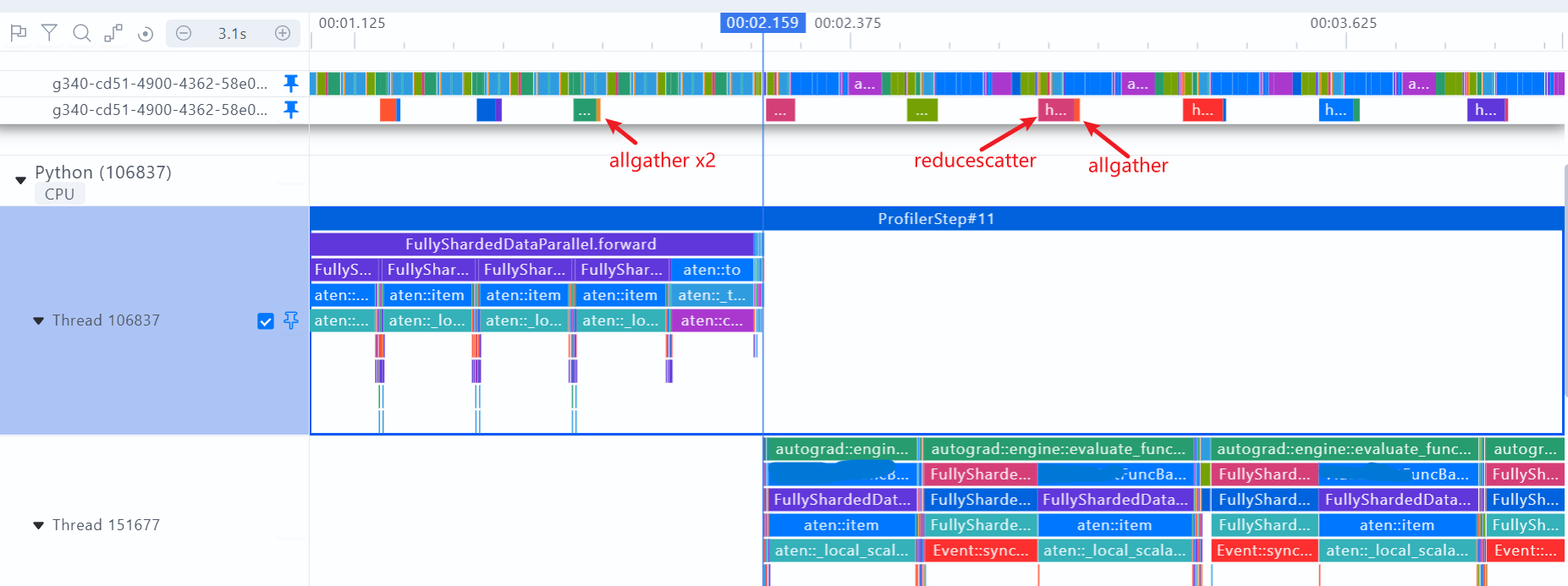
SHARD_GRAD_OP的profiling图:前向两个all-gather预取权重;反向reduce-scatter当前层梯度,没有all-gather操作
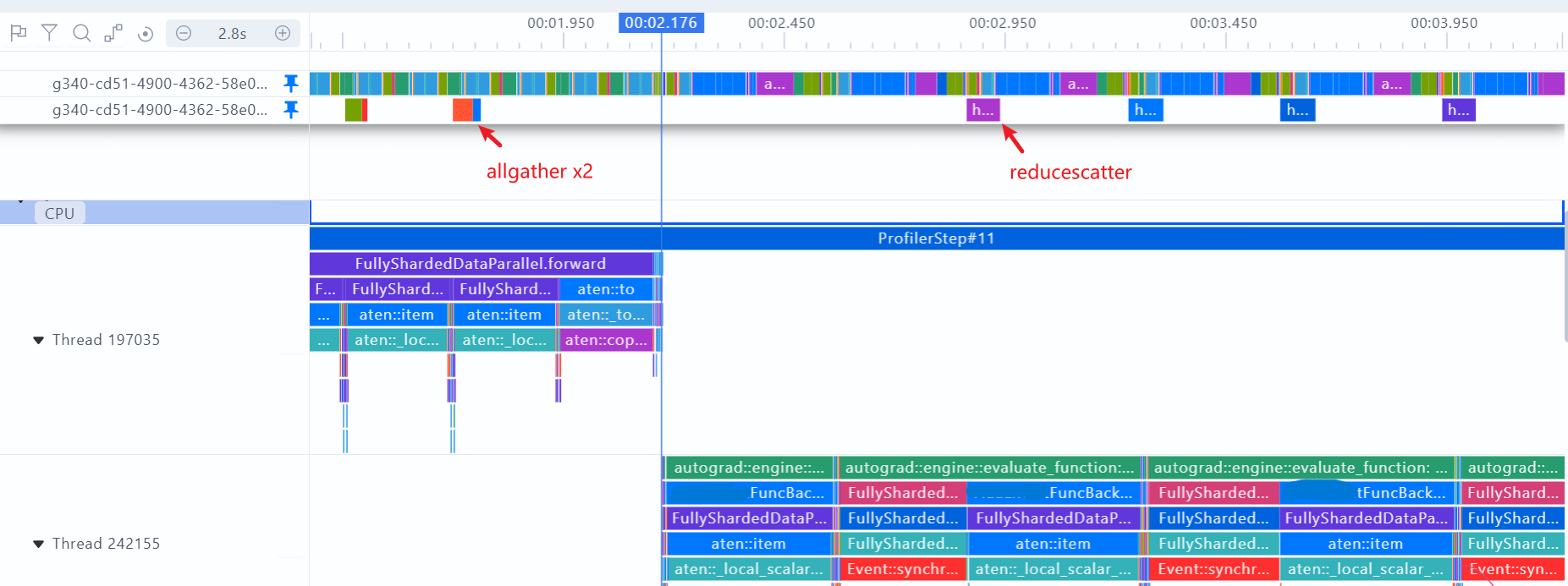
建议:在计算和通信掩盖较好的情况下,all-gather不是通信瓶颈时,建议使用FULL_SHARD,有较大的显存收益
3.2.2 HSDP
HYBRID_SHARD+DeviceMesh组合使用,也叫做HSDP (DDP + FSDP)
DeviceMesh是管理ProcessGroup的高级抽象,用于创建多级通信组,比如DP,FSDP,TP,支持多维并行计算
以2机16卡为例,通过设置DeviceMesh=[2, 8],可以让节点内走FSDP,节点间走DDP,提高通信效率
python
mesh_2d = init_device_mesh(device_type, (2, 8), mesh_dim_names=("replicate", "shard"))
model = FSDP(
model,
device_mesh=mesh_2d,
device_id=rank,
auto_wrap_policy=auto_wrap_policy,
sharding_strategy=ShardingStrategy.HYBRID_SHARD,
mixed_precision=MixedPrecision(
param_dtype=torch.bfloat16,
reduce_dtype=torch.float32,
buffer_dtype=torch.float32,
),
limit_all_gathers=True
)案例:某参数量7B的多模态模型,256卡训练时,从默认的FULL_SHARD修改为HYBRID_SHARD,device_mesh=[16, 16],性能提升了30%
建议:对于有通信瓶颈、显存有富余的训练任务,可以将DeviceMesh+HYBRID_SHARD作为一种调优手段
3.3 参数管理
3.3.1 FlatParameter
为了实现高效的通信,FSDP 将一个单元内的所有参数合并为一个大的一维张量FlatParameter
通过这一方式,整合了参数的通信操作,又能在各进程间实现均匀分片,具体过程如下:
**合并与填充:**将原始参数分别扁平化后依次拼接,并在右侧填充至可被分片因子(进程数)整除的长度
**参数分片:**将FlatParameter等分为若干块,每个进程分配一块; FlatParameter的梯度与自身保持相同的分片 / 未分片状态
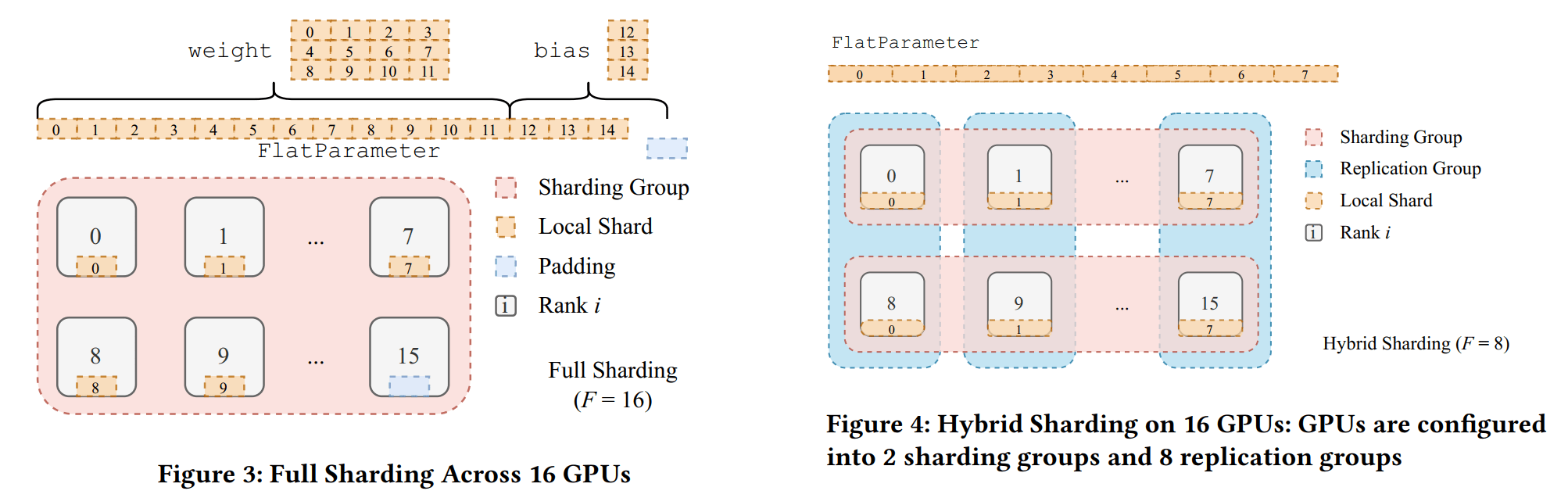
在2机16卡的机器上进行实验,以nn.Linear(4, 3)为例,加上bias一共是15个参数。FULL_SHARD策略下,FSDP会先将参数padding到16个,然后分给每张卡。HYBRID_SHARD + device_mesh=[2, 8]策略下,FSDP会将参数拷贝一份,每台机器(8卡)分片一组参数。
3.3.2 unshard & reshard
模型计算需要完整的权重数据,因此,FSDP 会在计算前(pre_forward)恢复参数的原始形状,计算后(post_forward)再将其扁平化处理
FSDP Pre_Forward:all-gather聚合当前单元的参数,再通过slice,split,view操作,将FlatParameter还原

FSDP Post_Forward:将FSDP单元里的参数扁平化,只保留属于自身的参数分片

3.3.3 参数分片实例
以llma-7b为例,8卡并行,切分策略为FULL_SHARD,仅对TransformerBlock进行包裹,经过FSDP切分的模型结构如下:
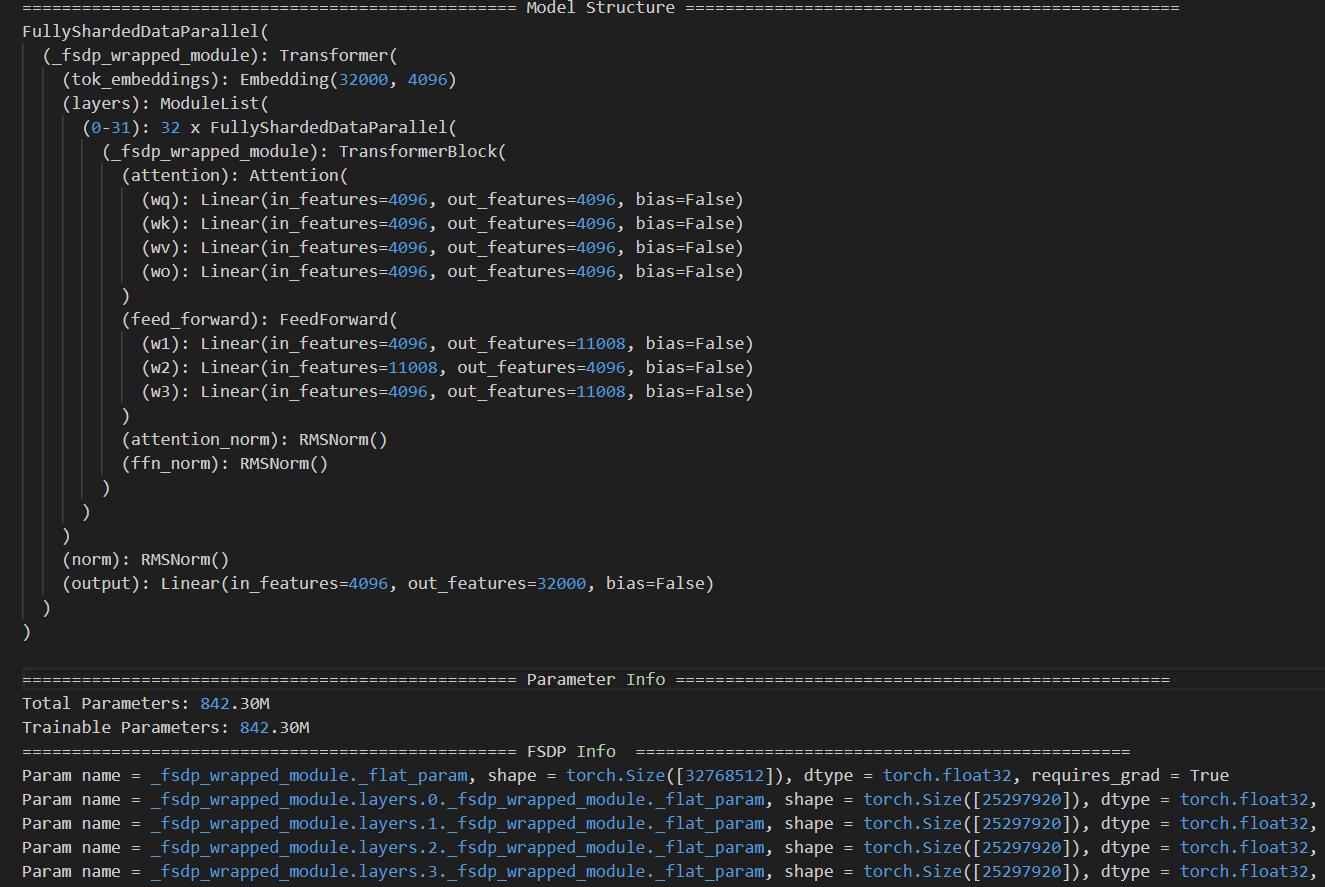
● 切分后的模型主体单元(Unit 0)的参数量:
分别对应Embedding layer + Output layer + RMSNorm的参数,与实际打印出来的size一致
● 切分后的Transformer单元(Unit 1~32)的参数量:
分别对应 Attention + FFN + RMSNorm的参数,与实际打印出来的size一致
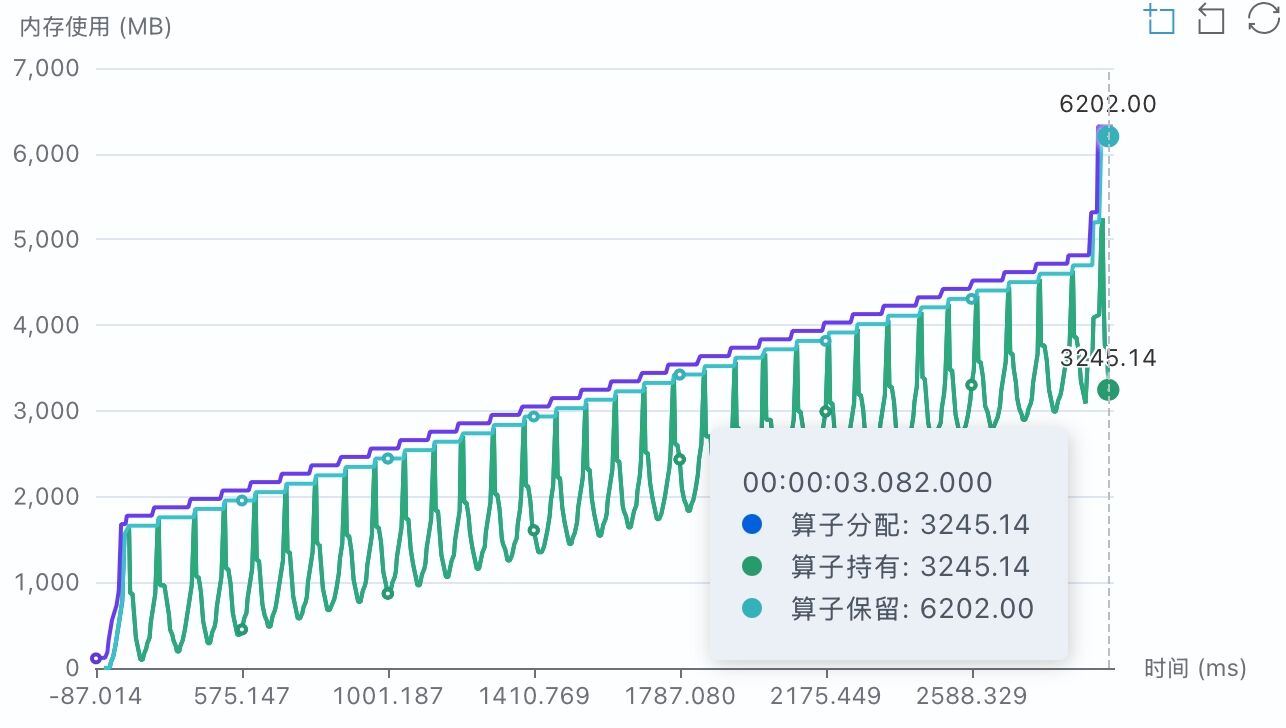
参数初始化显存分析:
● Llama2模型的参数量为6.7 B,分配给每张卡上的参数为0.842 B,初始化时数据类型FP32
● FP32 类型的每个参数占用4个Byte,模型参数占用的显存为 0.842B × 4Byte ≈ 3.14GB
● 采集内存Profiling分析,算子持有的显存约为3.17 GB(图中3245 MB),与参数理论显存基本一致
● FSDP 创建FlatParameter时,需同时维护原始参数与 FlatParameter,单卡进程实际显存占用约 6 GB(参数显存的 2 倍)
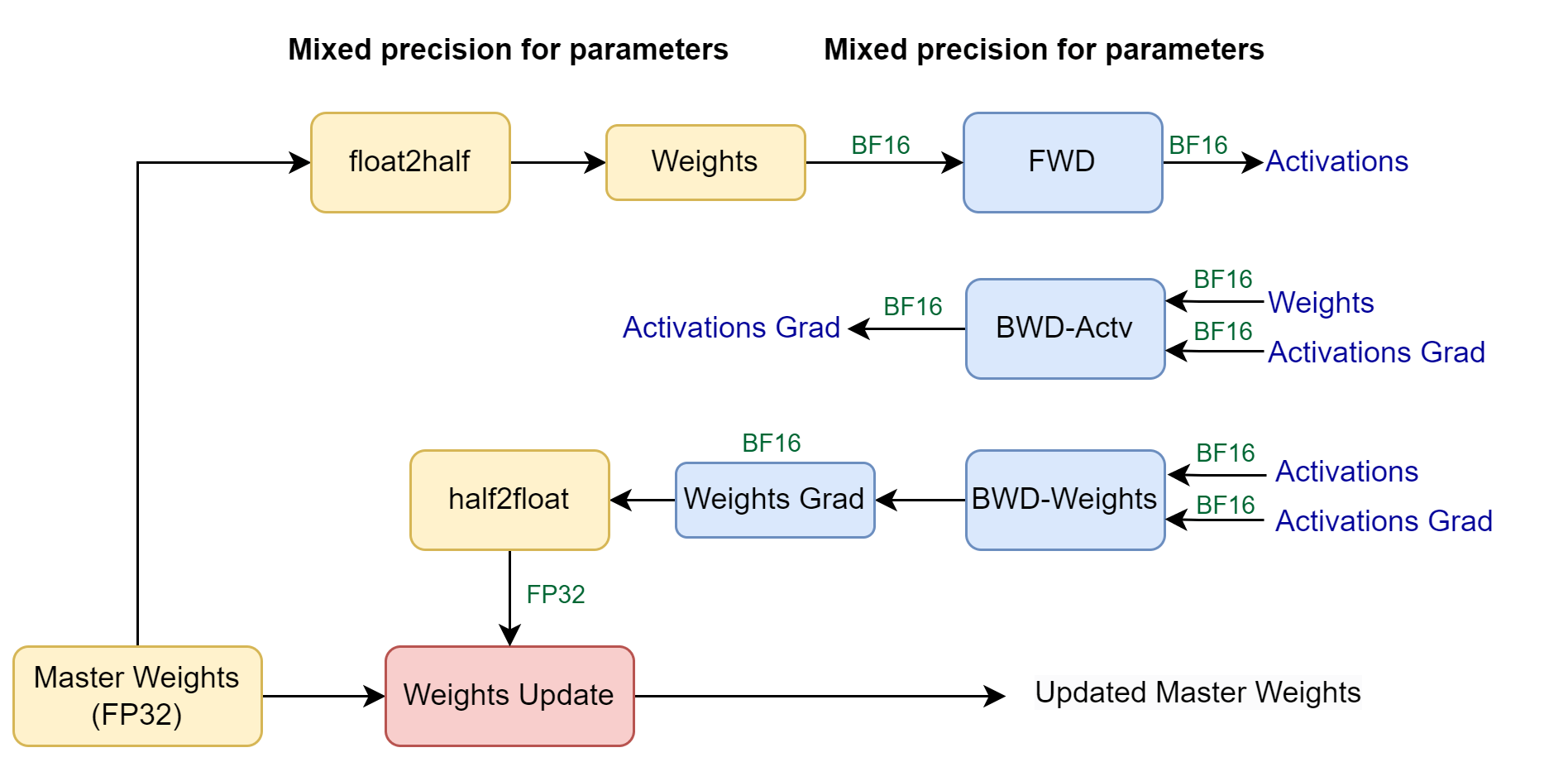
3.4 混合精度
使用BF16混合精度训练时,通常配置为
python
model = FSDP(
model,
device_id=rank,
auto_wrap_policy=auto_wrap_policy,
sharding_strategy=ShardingStrategy.FULL_SHARD,
mixed_precision=MixedPrecision(
param_dtype=torch.bfloat16, # 模型参数类型
reduce_dtype=torch.float32, # 用于通信的梯度类型
buffer_dtype=torch.float32, # buffer的数据类型
),
limit_all_gathers=True
)● FSDP在本地会保存一份FP32的Weights,在执行forward和backward时会cast成低精度(FP16 / BF16)
● Gradients在backward过程中是低精度,在FSDP post backward hook中,会转为FP32,再用于通信和更新模型参数
● buffer是指模型中不参与梯度更新的参数(例如位置编码),FSDP不对其分片,仅转换为指定的数据类型
3.5 CPU Offload
FSDP的CPU Offload,能够将模型的参数、梯度和优化器状态,卸载到CPU上,使用CPU更新模型参数和优化器状态。
以llama2-7b为例,模型参数量为6.74 B,使用AdamW优化器,bf16混合精度训练
开启CPU Offload,训练显存从45.75 GB降低到了35.61 GB,降低了10.14 GB,单步时间从1.17 s增加到3.64 s
显存下降的理论值与实际值比较接近。AdamW优化器状态包含FP32类型的模型参数、一阶动量和二阶动量,因此倍数为12

在all-gather前将模型参数从cpu复制到device,在梯度计算完成后,将模型梯度从device复制到cpu,这一操作可与计算异步进行。
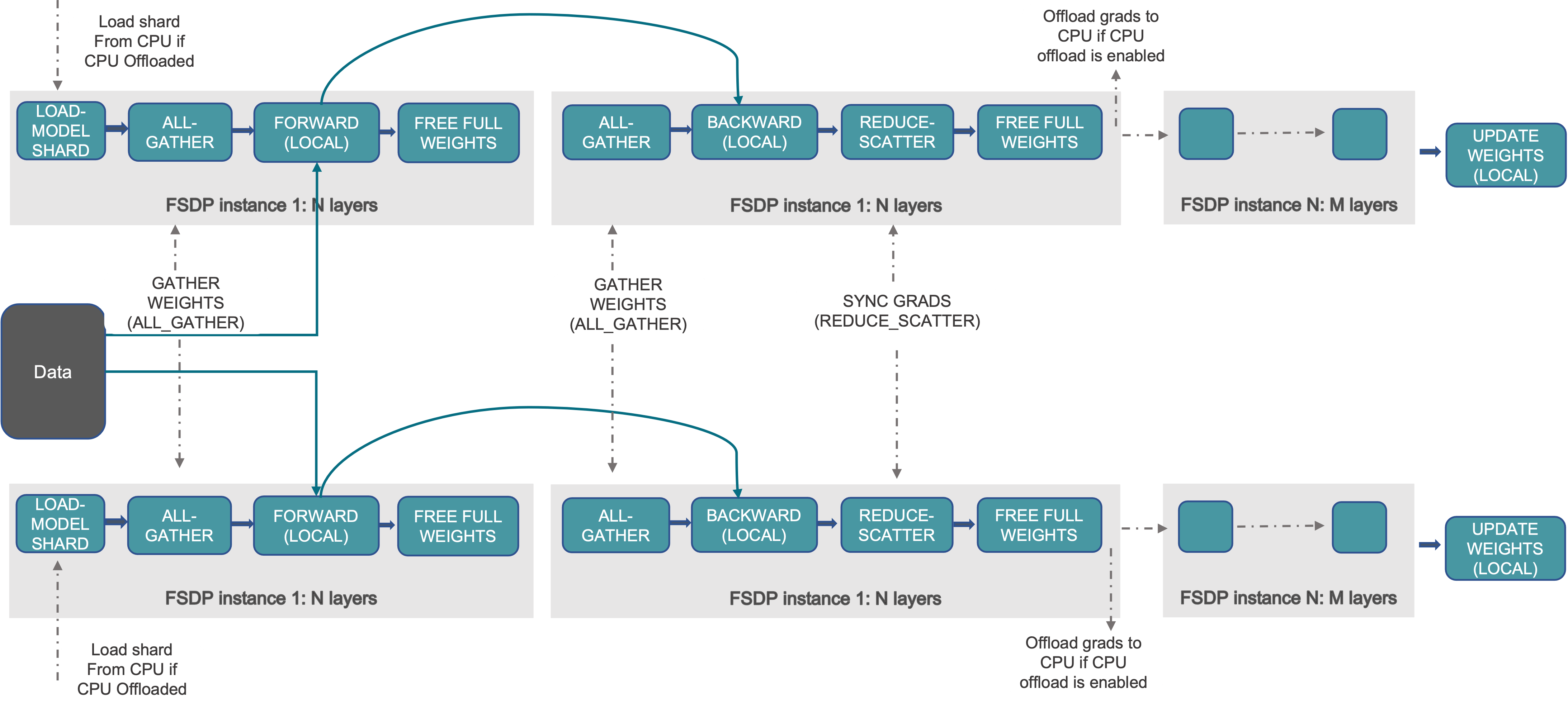
3.6 FSDP流程
回顾一下FSDP的训练流程,在FSDP初始化之后,各个进程保留一份本地的模型分片,以FSDP Unit为单位,通过all-gather聚合权重进行前向计算,完成后释放权重;反向传播时再次聚合权重,计算后通过reduce-scatter同步梯度,释放完整权重,最后使用通信后的梯度更新本地的模型参数。
四、通算重叠
4.1 通算重叠
FSDP的核心思想就是当前层的计算和下一层的通信重叠,保证计算流上的算子能够持续执行,避免空闲等待。
为达到这一效果,FSDP 采用一条独立的 CUDA 流来下发通信算子(包括 all-gather 和 reduce-scatter)

以一个6层的模型为例,layer0和layer3属于Unit 0,layer1-2属于Unit 1,layer4-5属于Unit 2
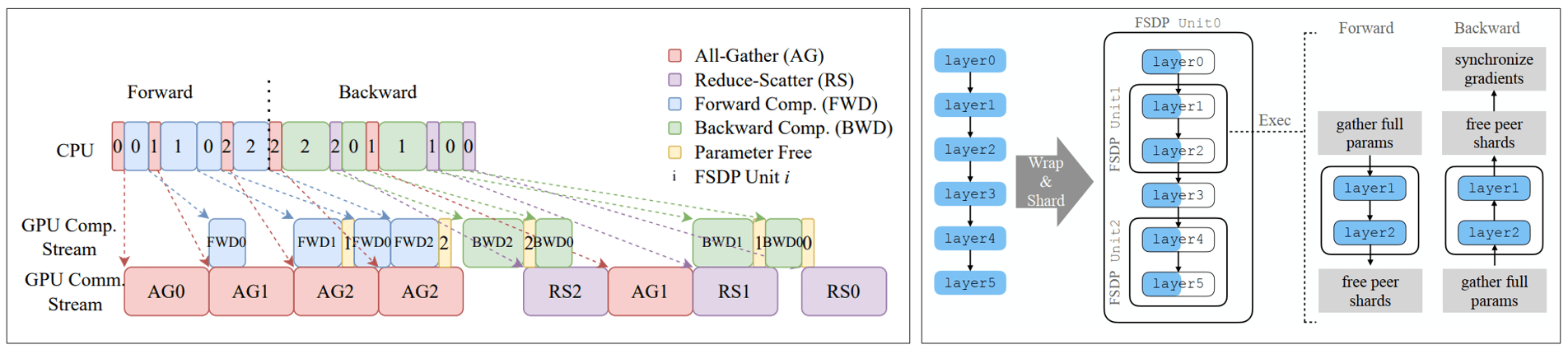
前向阶段:
unit0:通信流执行 AG0(无法被计算掩盖),计算流随后执行 FWD0
unit1:unit0 的 FWD0 计算时,通信流启动 AG1(被计算掩盖);AG1 完成后执行 FWD1
unit2:unit1 的 FWD1 计算时,通信流启动 AG2(被掩盖);计算流执行 FWD2 完成前向
反向阶段:
unit2:计算流执行 BWD2,通信流随后执行 RS2
unit1:unit2 的 RS2 通信时,计算流启动 BWD1;通信流执行 RS1
unit0:unit1 的 RS1 通信时,计算流启动 BWD0;通信流执行 RS0
注意到,unit 0是在计算完成后才释放参数的,另外FWD1执行后,立刻又执行了FWD0,因为layer3的参数在AG0就已经聚合了
4.2 参数预取
4.2.1 前向和反向预取
ForwardPrefetch:
● 隐式前向预取:依赖于独立CUDA流下发all-gather操作。从 CPU 视角看,可让后续 all-gather 与先下发的前向计算重叠
● 显式前向预取:CPU先下发下一层的all-gather,再下发当前层的计算。但要求模型的执行顺序与参数预取的顺序一致,仅节省下发前向计算核的时间,并无明显优势,不建议开启
BackwardPrefetch:
● BACKWARD_PRE:在当前参数梯度计算前预取下组参数,all-gather与计算掩盖、显存占用较高
● BACKWARD_POST:在当前梯度计算完成后预取下组参数,all-gather无法掩盖、显存占用较低
以一个4 B的多模态模型为例,8卡FSDP并行,bf16混合精度训练。通过修改参数预取的配置,观察性能和显存的变化
| 前向预取 | 反向预取 | 端到端时间 | 计算时间 | 未掩盖通信时间 | 空闲时间 | 显存占用 |
|---|---|---|---|---|---|---|
| √ | √ | 8.02 | 7.66 | 0.21 | 0.15 | 52.90 G |
| × | √ | 8.04 | 7.72 | 0.13 | 0.18 | 51.23 G |
| × | × | 8.12 | 7.66 | 0.25 | 0.20 | 51.16 G |
BACKWARD_PRE:当前层的计算,与上一层的reduce-scatter,下一层的all-gather重叠

BACKWARD_POST:当前层的计算,仅与上一层的reduce-scatter重叠。如下图,执行all-gather的时候计算流正在等待(event_wait)

建议:使用FSDP的默认配置就好,也就是forward_prefetch=False, backward_prefetch=BackwardPrefetch.BACKWARD_PRE
4.2.2 速率限制
当FSDP单元的计算慢于 all-gather 通信时,如果不限制CPU 下发 all-gather 的速度,会导致设备内存中驻留多个 FSDP 单元的参数
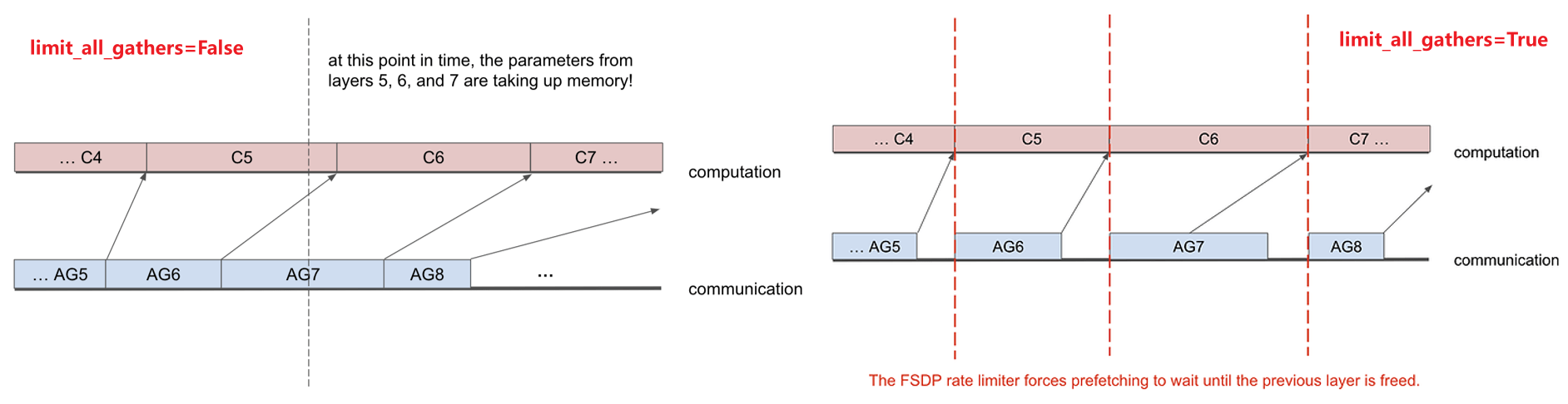
针对这一问题,FSDP 提供了速率限制器(rate_limiter)的接口:
当limit_all_gathers设为True时,FSDP 会显式地同步 CPU 线程,确保设备内存中仅保留两个连续的 FSDP 单元 ------ 当前执行计算的FSDP单元和预取的下一个FSDP单元。

当limit_all_gathers设为False时,FSDP 允许 CPU 线程无同步地下发 all-gather,适合内存压力小、通信比计算慢的场景
总结:limit_all_gathers设为True并不会降低性能,而且有较大的显存收益,建议开启
五、FSDP2介绍与使用
5.1 FSDP2原理与使用
FSDP2与FSDP1相比,主要有以下几点区别:
1、移除了FlatParameter,引入了DTensor,根据DeviceMesh在每个参数的第0维进行切分,参数管理更高效
2、改进了内存管理机制,减少了CPU侧的同步,移除了recordStream,无需设置limit_all_gathers=True
3、移除了use_orig_params,在同一FSDP单元包含冻结和非冻结的参数时,可以节省显存和通信
FSDP2的配置更简单一点,接口信息见官方文档:torch.distributed.fsdp.fully_shard --- PyTorch 2.6 documentation
FSDP2的接口是fully_shard,默认切分策略为ZeRO-3,与FSDP1的hybrid_shard等效,下面是伪代码:
python
# 导入FSDP2相关API
from torch.distributed.device_mesh import init_device_mesh
from torch.distributed.fsdp import fully_shard, MixedPrecisionPolicy, CPUOffloadPolicy
from dit import DiffusionTransformer, TransformerBlock
# 初始化模型
model = DiffusionTransformer()
# 初始化device_mesh
mesh_2d = init_device_mesh(device_dtype, (2, 8), mesh_dim_names=["replicate", "shard"])
# FSDP2接口配置
settings = dict(
mesh=mesh_2d,
mp_policy=MixedPrecisionPolicy(
param_dtype=torch.bfloat16,
reduce_dtype=torch.float32
),
offload_policy=CPUOffloadPolicy() if args.cpu_offload else None,
)
# 对DiT中的TransformerBlock进行分片
for module in model.modules():
if isinstance(module, TransformerBlock):
fully_shard(module, **settings)
fully_shard(model, **settings)
optimizer = torch.optim.AdamW(model.parameters(), lr=args.lr)FSDP1 与 FSDP2 的参数管理:
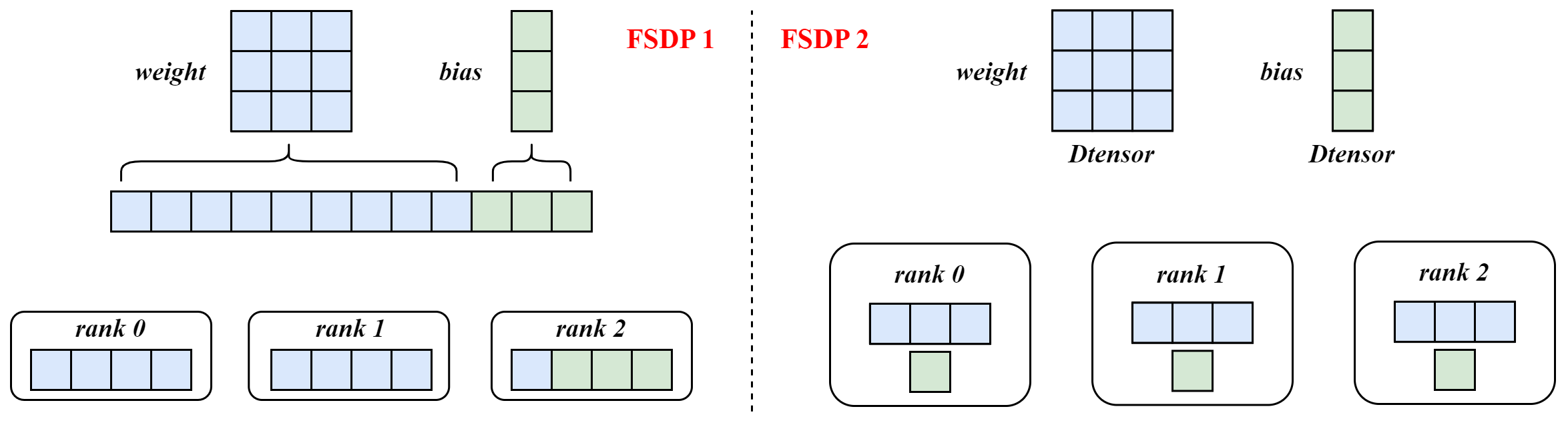
以nn.Linear(3, 3)为例,weight的shape是(3, 3),bias的shape为(3, )。在FSDP1上,weight和bias被展平、拼接、填充为1D张量,用于参数分片和通信;而在FSDP2上,weight和bias都沿着dim=0进行切分,由DTensor进行管理。
5.2 LORA场景上的应用
在一个8B模型的 LORA 任务中,相同切片策略下从 FSDP1 迁移至 FSDP2 后,显存降低了 16GB,训练速度提升 8%

在LORA场景,DiTBlock是一个FSDP单元,包含了冻结(主干网络,backbone)和非冻结(lora层)的参数。在FSDP1中,冻结的参数与非冻结的参数占用相同的显存,一起被展平、分片以及集合通信;在FSDP2中,每个Tensor沿着0维切片,由Dtensor进行管理,冻结的参数无需占用一份梯度显存,也不需要进行reduce-scatter通信。如下图,可以看到reduce-scatter的通信量,FSDP2是远小于FDSP1的。

Profiling性能对比图,左边为FSDP1,右边为FSDP2
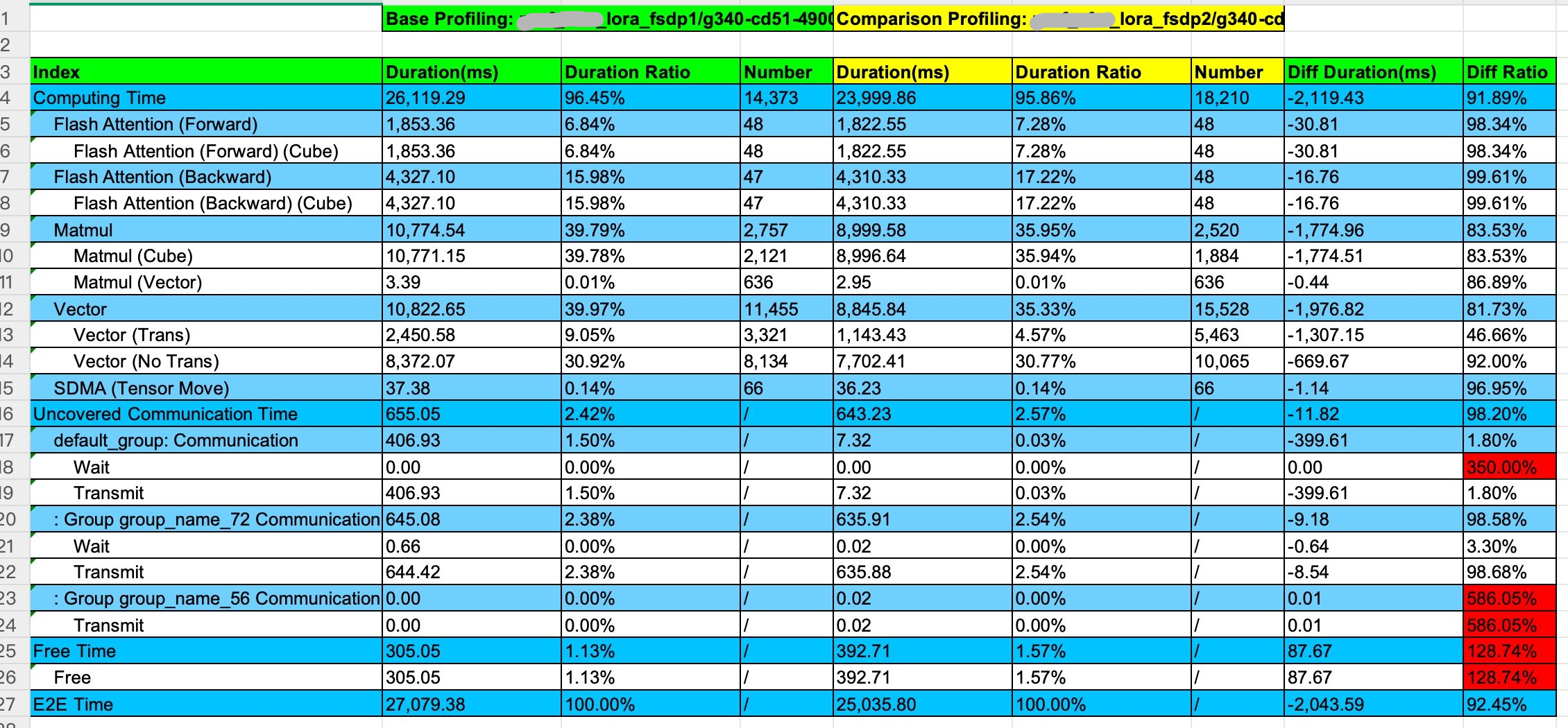
从Profiling对比结果来看,FSDP1升级FSDP2的性能收益来自于计算,计算收益来自于Matmul
通过对比Profiling细节,发现FSDP1 Linear层反向的matmul算子数量是FSDP2的两倍
如下图,Profiling中AddmmBackward是linear层的反向,可以看到连续下发了两个matmul算子 (aten: mm),分别用于计算权重的梯度和反向激活值
实际上LORA任务中的backbone参数是冻结的,这个linear层属于backbone,不需要计算权重梯度,但FSDP1还是计算了

在FSDP2中,linear层的反向只下发了一个matmul算子,用于反向传播计算激活值,没有计算权重的梯度,这才是符合预期的

总结:在LORA场景,FSDP2不会计算冻结权重的梯度(dw),减少了计算量和显存;也不会对这部分梯度进行通信,减少了通信量。
通过调整wrap policy,设置use_orig_params=False,FSDP也达到接近FSDP2的效果。方法就是将所有LORA的nn.Linear层,也就是requires_grad=True的参数,单独包裹起来,视为一个FSDP单元。这样,那些requires_grad=False的参数,就不会参与reduce-scatter的通信,以及dw的计算了
六、总结
FSDP 通过多层配置实现了通信和计算的精细控制,主要有三点:
(1) 通过auto_wrap_policy控制切分的粒度,指定对模型的哪些部分进行组合、切片;
(2) 通过sharding_strategy控制切片的深度,切分优化器状态、模型梯度、模型参数;
(3) 结合device_mesh构建设备拓扑,将DDP与FSDP结合(HSDP),将训练规模扩展至百卡、千卡级集群。
在通信方面,FSDP 设计了参数预取机制,在当前 FSDP 单元执行计算时,提前触发下一个单元的all-gather操作。理论上,可以将第一个FSDP单元之外的所有all-gather都与计算掩盖。为避免参数预取过量导致的设备内存冗余,FSDP 提供了limit_all_gathers速率控制接口,通过同步 CPU 与设备线程调度,确保设备内存中仅保留当前计算单元与预取下一单元。
此外,在Torch2.6版本后,FSDP2在参数和内存管理方面进行了优化,在LORA场景等部分参数冻结的场景,有较大的性能收益。
参考资料
-
Introducing PyTorch Fully Sharded Data Parallel (FSDP) API | PyTorch
-
[1910.02054 ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://arxiv.org/abs/1910.02054 "1910.02054] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models")
-
[2304.11277 PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel](https://arxiv.org/abs/2304.11277 "2304.11277] PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel")
-
torchtitan/docs/fsdp.md at main · pytorch/torchtitan · GitHub