😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本专栏《人工智能》旨在记录最新的科研前沿,包括
大模型、智能体、强化学习等相关领域,期待与你一同探索、学习、进步,一起卷起来叭!🚩Paper:Controlled Self-Evolution for Algorithmic Code Optimization
💭开源代码:https://github.com/QuantaAlpha/EvoControl
💻时间:202601
💭推荐指数:🌟🌟🌟🌟🌟
往期精彩专栏内容,欢迎订阅:
🔗【多智能体】20260213:通过任务算术转移思维链能力
🔗【免训练&测试时推理】20251014:不确定性影响模型输出
🔗【低训练&测试时推理】20251014:测试时针对特定样本进行语言模型优化
🔗【免训练&强化学习】】20250619:训练无关的组相对策略优化
🔗【多智能体&强化学习】20250619:基于统一多模态思维链的奖励模型
🔗【多智能体&强化学习】20250615:构建端到端的自主信息检索代理
🔗【多智能体】20250611:基于嵌套进化算法的多代理工作流
🔗【多智能体】20250610:受木偶戏启发实现多智能体协作编排
🔗【多智能体】20250609:基于LLM自进化多学科团队医疗咨询多智能体框架
🔗【具身智能体】20250608:EvoAgent:针对长时程任务具有持续世界模型的自主进化智能体
介绍
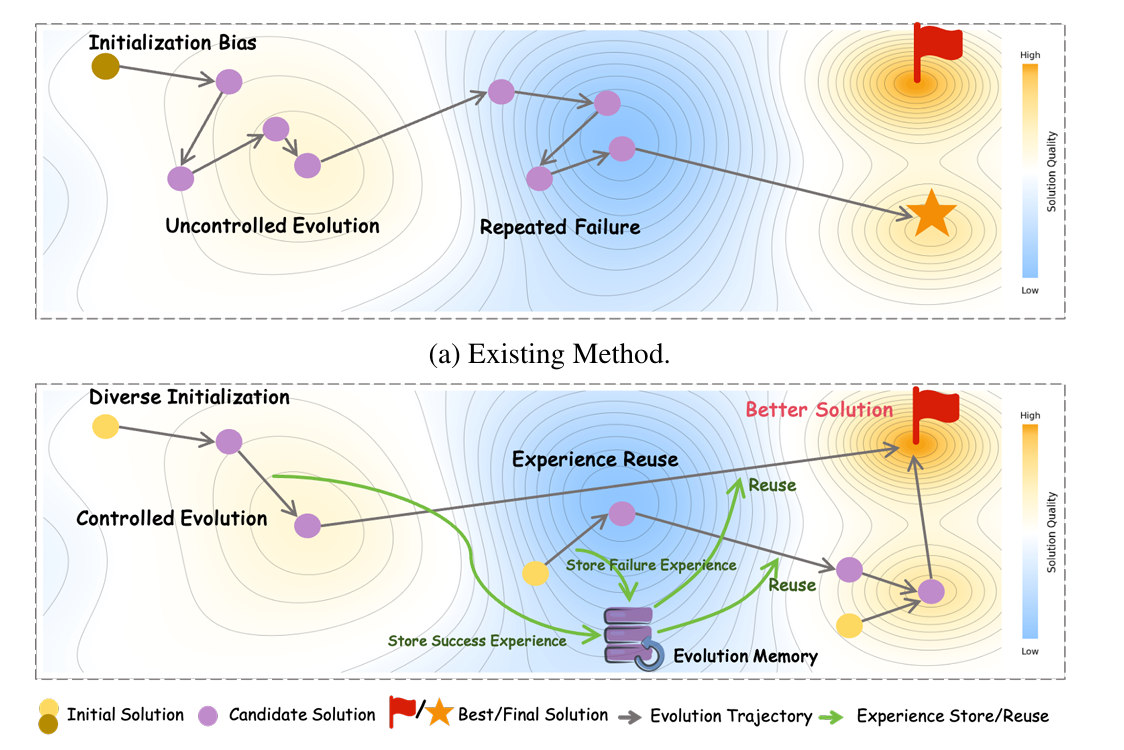
- 研究问题:这篇文章要解决的问题是现有自我进化方法在代码优化中的探索效率低,无法在有限的预算内发现具有优越复杂度的解决方案。
- 研究难点:该问题的研究难点包括初始化偏差、无控制的随机操作和缺乏跨任务的经验利用。
- 相关工作:该问题的研究相关工作有自进化方法(如AlphaEvolve和SE-Agent),这些方法通过"生成-验证-细化"循环来提高代码质量,但由于无指导的随机探索,探索效率低下。
研究方法
这篇论文提出了受控自我进化(Controlled Self-Evolution, CSE)框架,用于解决代码优化中的探索效率低的问题 。具体来说,CSE包括三个关键组件:多样化规划初始化、遗传进化和分层进化记忆。
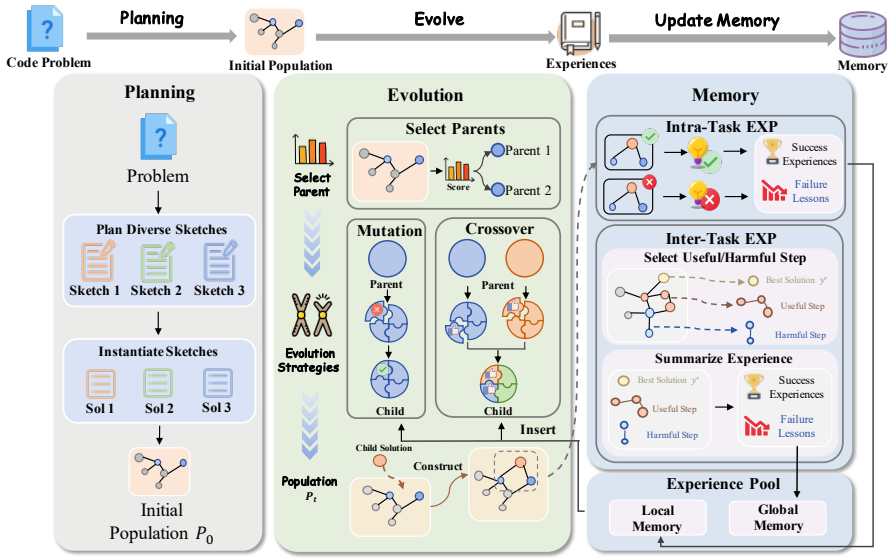
- 多样化规划初始化:通过多样化的规划策略生成高质量且多样的初始解决方案,确保解空间的广泛覆盖,减少陷入劣质局部区域的概率。
具体步骤包括:提示代理生成一组高层次的解决方案草图。将每个草图实例化为具体的代码实现,形成初始候选解。
CSE框架中的多样化规划初始化是如何具体实现的?
多样化规划初始化通过两个阶段实现:多样化和完成。
首先,提示代理生成一组高层次的解决方案草图,每个草图代表一种语义上不同的策略。例如,对于代码生成任务,代理可能会提出贪婪算法、动态规划或位操作优化等不同方法。
然后,将每个草图实例化为具体的代码实现,形成初始候选解。通过这种方式,初始种群不再是由单一模式随机扰动而成,而是实现了解空间的广泛覆盖,减少了陷入劣质局部区域的概率。
-
遗传进化:通过细粒度的反馈引导机制替代随机操作,实现有针对性的变异和组合交叉。具体步骤包括:
- 父代选择:基于归一化奖励的概率选择父代 ,保留低奖励但可能包含有用逻辑片段的个体。公式如下: P select ( y i ( t ) ) = F ( y i ( t ) , x ) ∑ j = 1 ∣ P t ∣ F ( y j ( t ) , x ) P_{\text{select}}\left(y_{i}^{(t)}\right)=\frac{\mathcal{F}\left(y_{i}^{(t)}, x\right)}{\sum_{j=1}^{\left|\mathcal{P}{t}\right|}\mathcal{F}\left(y{j}^{(t)}, x\right)} Pselect(yi(t))=∑j=1∣Pt∣F(yj(t),x)F(yi(t),x)其中, P select ( y i ( t ) ) P_{\text{select}}\left(y_{i}^{(t)}\right) Pselect(yi(t))表示候选解 y i ( t ) y_{i}^{(t)} yi(t)的选择概率, F ( y i ( t ) , x ) \mathcal{F}\left(y_{i}^{(t)}, x\right) F(yi(t),x)表示其奖励, P t \mathcal{P}_{t} Pt表示当前种群。这种机制实现了软选择分布,优先选择高奖励个体,同时保留低奖励但可能包含有用逻辑片段的个体。
- 进化策略:将代码分解为一组不相交的功能组件 ,进行有针对性的变异和组合交叉。
- 有针对性的变异:识别并修复特定故障组件,同时保持其他组件不变。公式如下:
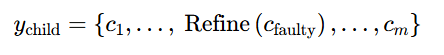
其中, c faulty c_{\text{faulty}} cfaulty表示故障组件, Refine ( c faulty ) \text{ Refine}\left(c_{\text{faulty}}\right) Refine(cfaulty)表示对该组件的修复。 - 组合交叉:在不同组件之间进行逻辑重组,结合各自的优势。公式如下:
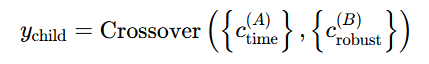
其中, c time ( A ) c_{\text{time}}^{(A)} ctime(A)表示时间效率高的组件, c robust ( B ) c_ {\text{robust}}^{(B)} crobust(B)表示鲁棒性强的组件。
- 有针对性的变异:识别并修复特定故障组件,同时保持其他组件不变。公式如下:
-
分层进化记忆:分层总结任务和跨任务的经验,为进化过程提供搜索指导。具体步骤包括:
- 本地记忆:记录每次迭代中父代和子代的奖励变化,提取成功和失败的经验 。
- 较父代和子代的奖励变化 Δ t = F ( y child ( t ) , x ) − F ( y parent ( t ) , x ) \Delta_{t}=\mathcal{F}\left(y_{\text{child}}^{(t)}, x\right)-\mathcal{F}\left(y_{\text{parent}}^{(t)}, x\right) Δt=F(ychild(t),x)−F(yparent(t),x)。
- 提取成功洞察( Δ t > 0 \Delta_{t}>0 Δt>0)和失败教训( Δ t ≤ 0 \Delta_{t}\leq 0 Δt≤0),分别标记为正模式和负约束。
动态注入到提示上下文中,形成双向指导。
- 全局记忆:收集每个任务的所有进化步骤及其奖励变化,提炼任务级别的全局经验 。
- 对每个任务,保留前K个改进步骤和后K个退化步骤。
- 使用LLM提炼任务级别的全局经验 g τ g_{\tau} gτ,并将其存储在向量数据库中。
- 在进化过程中,生成目标查询并检索相关经验,注入到当前上下文中。
- 本地记忆:记录每次迭代中父代和子代的奖励变化,提取成功和失败的经验 。
实验设计
- 数据集:在EffiBench-X上进行实验,该数据集包含了来自AtCoder、Codeforces和LeetCode等平台的623个算法问题,涵盖六种编程语言。
- 实验设置:在每个问题上运行30次候选解,记录路径中最优解。比较了四种代码生成范式:直接生成、自我反射、SE-Agent和AlphaEvolve。
- 评价指标:报告执行时间比(ET)、内存峰值比(MP)和内存积分比(MI)三个标准化效率指标。
结果分析
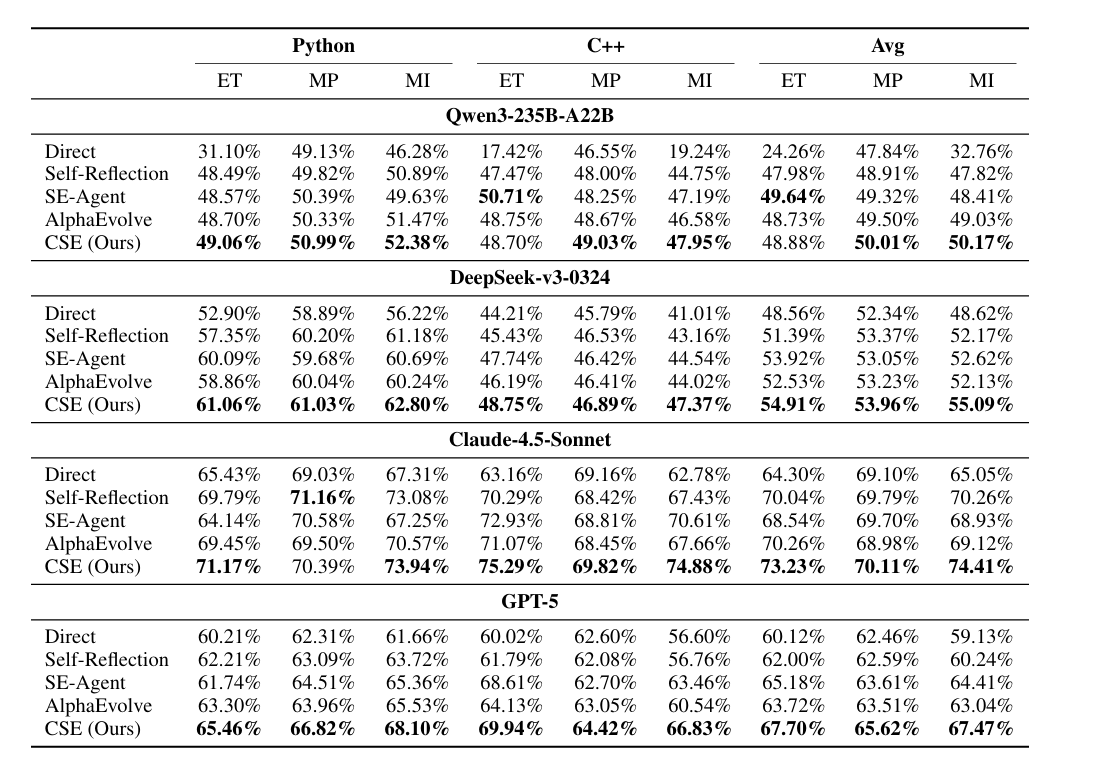
- 主要结果:CSE在大多数效率指标上均优于所有基线方法,特别是在内存积分上表现突出,表明其在有限探索预算内发现算法高效解决方案的能力。
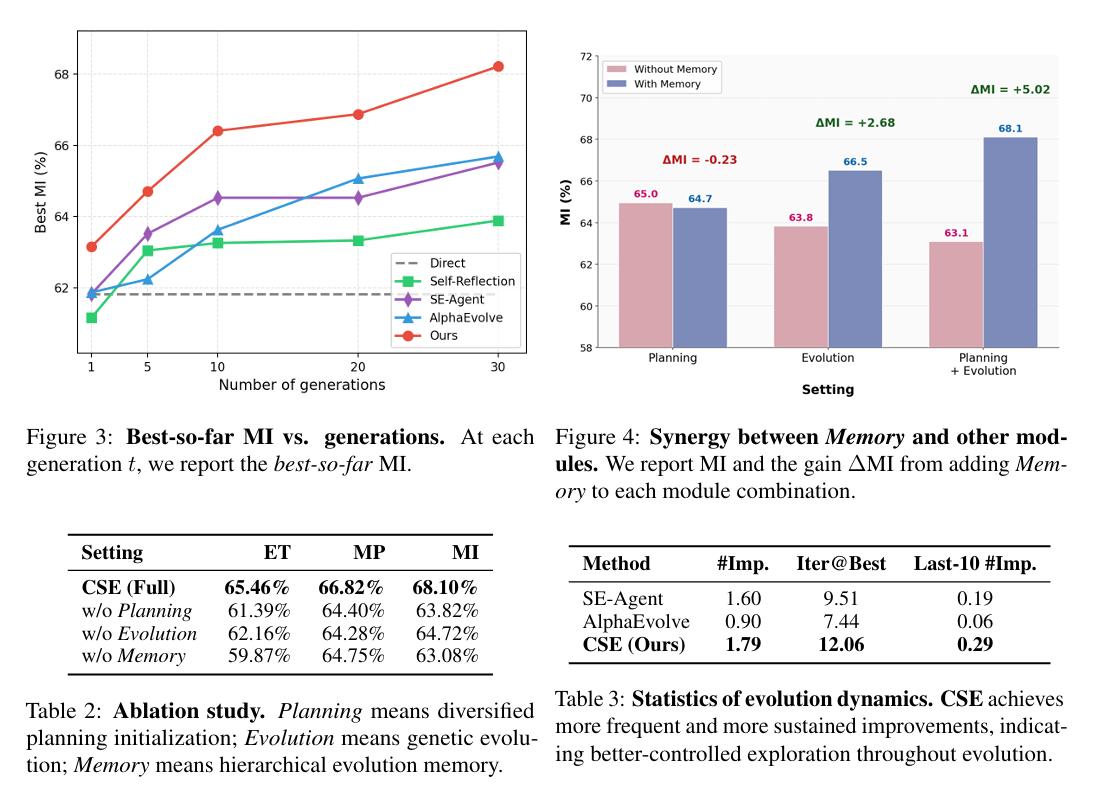
- 消融研究:移除多样化规划、遗传进化和分层进化记忆后,CSE的性能显著下降,表明这三个组件对CSE的有效性至关重要。
- 进化动态分析:CSE在整个预算内持续改进,早期迭代中改进次数更多,后期迭代中也表现出更强的进步。
总体结论
本文提出的受控自我进化(CSE)框架通过多样化的规划初始化、遗传进化和分层进化记忆,解决了现有自我进化方法在代码优化中的探索效率低的问题。实验结果表明,CSE在各种大型语言模型(LLM)骨干上均表现出色,实现了早期高效性和持续改进。本文的工作强调了在自我进化范式中进行受控、反馈驱动探索的重要性。
不足与反思
虽然CSE可以通过多轮进化不断提高解决方案质量,但目前尚未探索如何将这种迭代优化平摊到基础模型中。一个有前景但尚未充分探索的方向是将CSE的进化轨迹蒸馏成RL风格的训练信号,以加强基础模型,从而实现可比或更好的优化并产生更高质量的解决方案。
📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2026.02.13
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!