编者按: 你是否曾好奇过,那些声称能将长文本输入成本降低90%、延迟减少85%的"Prompt Caching"技术,背后究竟缓存了什么?是简单的文本复用,还是某种更深层的计算优化?
我们今天为大家带来的文章,作者的核心观点是:Prompt Caching的本质并非简单的文本字符串缓存,而是对Transformer注意力机制中Key-Value(KV)矩阵计算结果的复用,通过避免重复计算注意力权重来实现成本削减与性能提升。
文章的重点内容包括:第一,从Tokenizer到Embedding再到Transformer的完整技术拆解,帮助读者建立对LLM内部数据流的直觉认知;第二,对注意力机制(Attention)的数学原理进行深入浅出的阐释,详细展示了Query、Key、Value矩阵的计算过程以及Softmax权重分配机制;第三,揭示了"KV Caching"的核心实现逻辑 ------ 通过缓存历史token的K、V投影矩阵,使模型在增量生成时只需计算最新token,而非重新处理整个上下文;第四,对OpenAI与Anthropic两种缓存策略的对比分析,指出自动路由与显式控制之间的权衡,以及Temperature等采样参数对缓存机制的零影响。
作者 | Sam Rose
编译 | 岳扬
撰写本文时,OpenAI 和 Anthropic 的 API 中,缓存的 input token 单价仅为普通 input token 的十分之一。
Anthropic 甚至声称1,prompt caching 能将长 prompt 的延迟"最高降低 85%"。而在实际测试中,我发现对于足够长的 prompt,这一说法确实成立。我向 Anthropic 和 OpenAI 各发送了数百次请求,注意到在所有 input token 均被缓存的情况下,首 token 延迟(time-to-first-token latency)出现了明显下降。
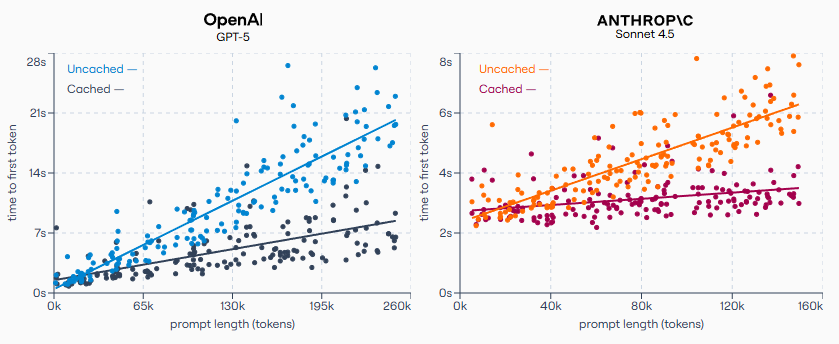
缓存 token(cached token)到底是什么玩意儿?
这背后究竟发生了什么,让服务商能给 input token 打出 1 折的超低折扣?他们在各次请求之间到底保存了什么?这可不是简单地把响应结果存下来,等收到相同 prompt 时再复用 ------ 通过 API 就能很容易地验证这一点并未发生。随便写个 prompt,连续发送十几次,你会发现即使使用情况栏(usage 部分)显示 input token 已被缓存,每次得到的回复仍然各不相同。
我对大模型厂商文档中的解释2-3并不满意 ------ 它们虽能很好地说明如何使用 prompt caching,却巧妙地避开了"究竟缓存了什么"这个核心问题。于是我决定深入探究,一头扎进 LLM 工作原理的"兔子洞",直到彻底搞明白服务商究竟缓存了哪些精确的数据、这些数据的用途,以及它们如何让每个人的 LLM 请求都变得更快速、更便宜。
读完本文,你将......
- 在更深层次上理解 LLM 的工作原理
- 对"LLM 的运作方式"建立新的直觉认知
- 弄明白究竟哪些二进制数据被缓存了,以及它们如何降低你的 LLM 请求成本
01 LLM 架构
本质上,LLM 就是一个巨大的数学函数:输入一串数字,并输出一个数字。在 LLM 内部,存在着一个由数十亿个精心设计的运算构成的巨型图结构,负责将这些输入数字转化为输出数字。
这个由海量数学运算构成的巨型图结构大致可分为 4 个部分。
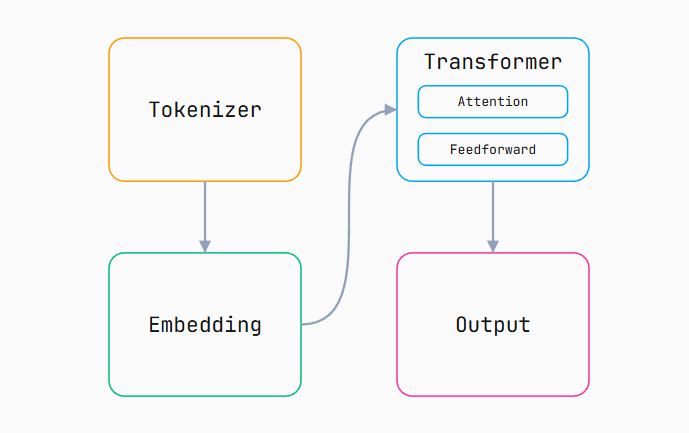
图中的每个节点都可以看作一个函数,接收输入并产生输出。输入会以循环方式不断馈入 LLM,直到遇到某个特殊的输出值指示其停止。 用伪代码表示大致如下:
prompt ="What is the meaning of life?";
tokens = tokenizer(prompt);
while(true){
embeddings = embed(tokens);
for([attention, feedforward] of transformers){
embeddings = attention(embeddings);
embeddings = feedforward(embeddings);
}
output_token = output(embeddings);
if(output_token === END_TOKEN){
break;
}
tokens.push(output_token);
}
print(decode(tokens));尽管以上描述已大幅简化,但现代 LLM 的核心代码行数之少仍让我感到意外。
Sebastian Raschka4 用 PyTorch 从零实现了多个开源模型,还产出了大量高质量的教学材料 ------ 如果你喜欢本文,大概率也会喜欢他的内容。以当前领先的开源模型之一 Olmo 3 为例,其核心代码仅数百行5。
Prompt caching 发生在 Transformer 的"attention(注意力机制)"中。接下来我们将按顺序逐步拆解 LLM 的工作原理,直到抵达这一环节。这意味着,我们的旅程得从 tokens 说起。
02 Tokenizer(分词器)
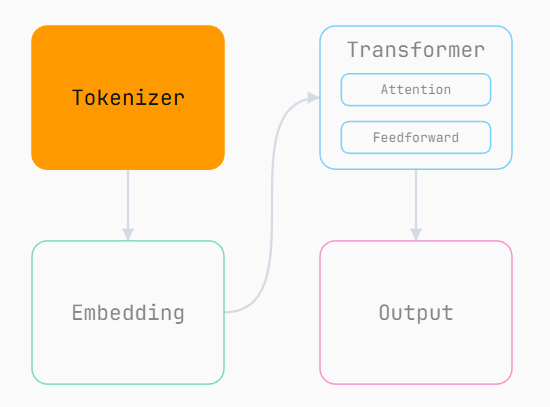
在 LLM 处理你的 prompt(提示词)之前,必须先将其转换为它能理解的表示形式。这个过程分为两步,由 tokenizer 和 embedding 共同完成。为什么要这么做,要到讲 embedding 时才能完全明晰,现在请先耐心了解 tokenizer 的作用。
Tokenizer 会将你的 prompt 拆成多个小片段,并为每个唯一的片段分配一个整数 ID,称为"token"。例如,GPT-5 对 prompt "Check out ngrok.ai" 的分词结果如下:

该 prompt 已被拆分为数组 "Check", " out", " ng", "rok", ".ai",并转换为 tokens 4383, 842, 1657, 17690, 75584。相同的 prompt 始终生成相同的 tokens。tokens 也是区分大小写的 ------ 因为大小写能传递语义信息。例如,首字母大写的 "Will" 更可能是人名,而小写的 "will" 则更可能是助动词。
为什么不直接按空格或字符分割?
这其实是个相当深刻的问题,细讲起来足以让本文篇幅翻倍。简短而不尽兴的答案是:这是一种权衡。若想深入理解,Andrej Karpathy 有一期从零实现 tokenizer 的精彩视频(https://www.youtube.com/watch?v=zduSFxRajkE) 。对于 prompt caching 而言,只需知道:tokenization 的作用就是把文本变成数字。
Tokens 是 LLM 输入与输出的基本单位。当你向 ChatGPT 提问时,回复会随着每次 LLM 迭代完成而逐个 token 流式返回。服务商这么做,是因为生成完整回复可能需要数十秒,而一旦 token 生成就立即返回,能让交互体验更流畅自然。
我们来问一个 LLM 领域的经典问题,亲眼看看这个过程:
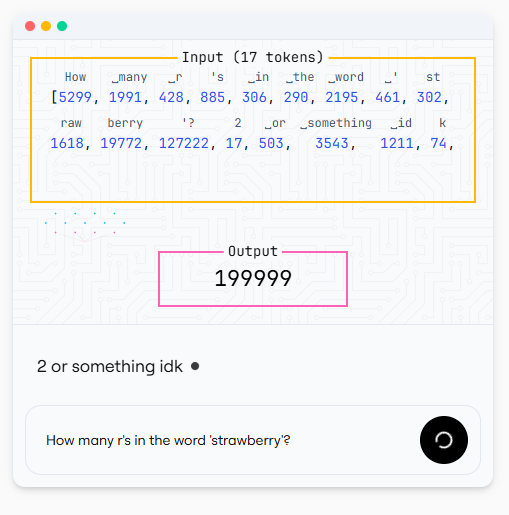
Prompt tokens 输入,✨ AI 魔法发生 ✨,输出一个 token,循环往复。这个过程称为"inference(推理)"。注意:每个输出 token 都会在下一轮迭代前被追加到 input prompt 中。LLM 需要全部上下文才能给出高质量回答 ------ 如果只输入原始 prompt,它会反复尝试生成答案的第一个 token。如果只输入已生成的回答部分,它会立刻忘记问题本身。因此,每一轮迭代都必须将完整的 prompt 加上已生成的回答内容重新输入 LLM。
那个 199999 token 是什么?
这个推理过程总得有个终点。LLM 拥有多种"特殊"token,其中之一就是标志着响应结束的 token。 在 GPT-5 的分词器中,这就是 token 199999。这只是 LLM 终止生成过程的多种方式之一:你也可以通过 API 指定最大生成 token 数,服务商还可能基于安全策略设定其他终止规则。
此外还有用于标记对话消息起止的特殊 token ------ 正是这些 token 让 ChatGPT、Claude 等聊天模型能分辨一条消息何时结束、下一条何时开始。
关于 tokenizer(分词器)的最后一点:它们种类繁多!ChatGPT 使用的 tokenizer 与 Claude 不同,甚至 OpenAI 自家的不同模型也使用不同的 tokenizer。每种 tokenizer 都有自己独特的文本切分规则。如果你想直观比较不同 tokenizer 的分词效果,可以试试 tiktokenizer6。
认识了 tokens 之后,接下来我们聊聊 embeddings。
03 Embedding
经过 tokenizer 处理后的 tokens,现在进入 embedding 阶段。要理解 embedding,不妨先思考模型的目标是什么。
人类用代码解决问题时,会编写接收输入、产生输出的函数,比如华氏转摄氏:
function fahrenheitToCelsius(fahrenheit){
return((fahrenheit -32)*5)/9;
}我们可以把任意数字传入 fahrenheitToCelsius,并能获得正确结果。但假如我们面对一个问题,却不知道背后的公式呢?假如我们只有下面这张神秘的输入-输出对照表:
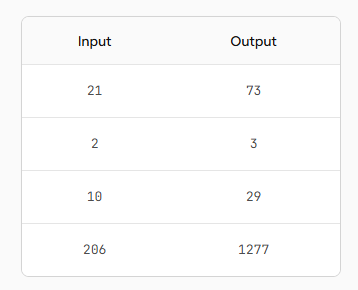
(我并不指望你能认出这个函数 ------ 不过,如果你把截图贴进 ChatGPT,它能立刻识别出来。)
当我们知道每个输入对应的正确输出,却不知道产生这种对应关系的函数时,就可以"训练"一个模型来学习这个函数。做法是:给模型提供一块"画布" ------ 那个由海量数学运算构成的巨型图结构,然后不断调整这个图结构,直到模型收敛到正确的函数。每次更新图结构后,我们都将输入数据喂进去,观察输出数据与目标的差距。反复迭代,直到结果足够接近目标。这就是训练的本质。
事实证明,在训练文本生成模型时,能够识别两个句子是否"相似"会很有帮助。但"相似"具体指什么?它们可能同样悲伤、幽默或发人深省;也可能在长度、节奏、语气、语言、词汇或结构上相近。描述句子相似性的方式有无数维度,而两个句子可能在某些维度上相似,在另一些维度上则不然。
Tokens 本身只是简单的整数编号,没有任何"维度"信息;而 embeddings 则是高维向量,承载了丰富的语义和结构信息。
Embedding 是一个长度为 n 的数组,代表 n 维空间中的一个位置。如果 n=3,embedding 可能是 10, 4, 2,表示三维空间中 x=10、y=4、z=2 的坐标点。在 LLM 训练过程中,每个 token 会被随机分配一个起始位置,随后训练过程会不断微调所有 token 的位置,直到找到能产生最佳输出的排列方式。
Embedding 阶段的第一步,就是查表获取每个 token 对应的 embedding。用伪代码表示大概是这样:
// Created during training, never changes during inference.
const EMBEDDINGS = [...];
function embed(tokens) {
return tokens.map(token => {
return EMBEDDINGS[token];
});
}于是,我们把 tokens(整数数组)转换成了 embeddings(数组的数组,即"矩阵")。


tokens 75, 305, 284, 887 被转换为一个由 3 维 embeddings 构成的矩阵。
Embedding 的维度越多,模型可用于比较句子的"角度"就越多。 我们刚才一直在用 3 维 embeddings 举例,但当前主流模型的 embedding 维度通常是几千维,最大的甚至超过 10,000 维。
为了说明更高维度的价值,下面我展示了 8 组彩色形状,它们最初位于一维空间中 ------ 挤在一条直线上,杂乱无章,难以理解。但随着维度增加,你就能清楚地看到存在 8 个不同的、相关的组别。
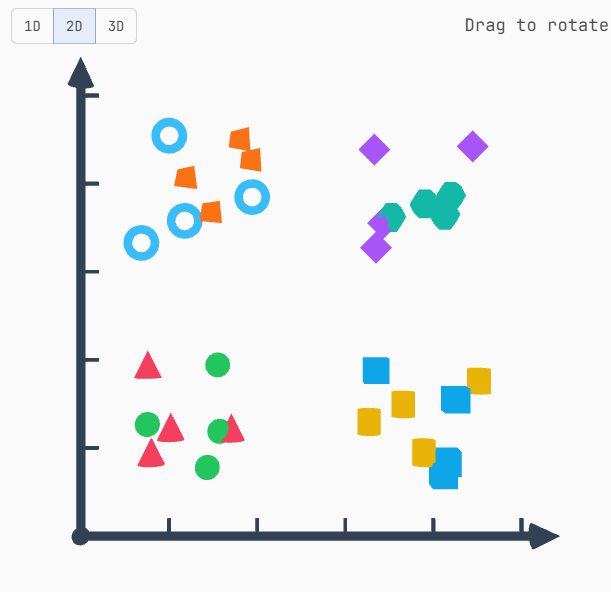

三维是我这里能提供的视觉示例的极限,至于几千维的空间能表达什么,就得靠你发挥想象力了。
Embedding 阶段还有最后一件事要做。在获取 token 的 embedding 后,会将该 token 在 prompt 中的位置信息编码进 embedding 中。 我没有深入研究这一机制的具体实现方式,只知道它对 prompt caching 的工作方式影响不大,但如果没有这一步,LLM 就无法判断 prompt 中 tokens 的先后顺序。
更新一下前面的伪代码,假设存在一个叫 encodePosition 的函数,它接收 embeddings 和位置信息,并返回嵌入了位置编码的新 embeddings。
const EMBEDDINGS =[...];
// Input: array of tokens (integers)
function embed(tokens){
// Output: array of n-dimensional embedding arrays
return tokens.map((token, i)=>{
const embeddings = EMBEDDINGS[token];
return encodePosition(embeddings, i);
});
}总而言之,embeddings 是 n 维空间中的点,你可以将其视为它们所代表文本的语义含义。在训练过程中,每个 token 都会在该空间中移动,靠近其他语义相似的 token。维度越多,LLM 对每个 token 的表示就越复杂、越细腻。
至此,tokenizer 和 embedding 阶段所做的全部工作,都是为了把原始文本转换成 LLM 能处理的形式。接下来,我们来看看这些数据进入 transformer 阶段后会发生什么。
04 Transformer
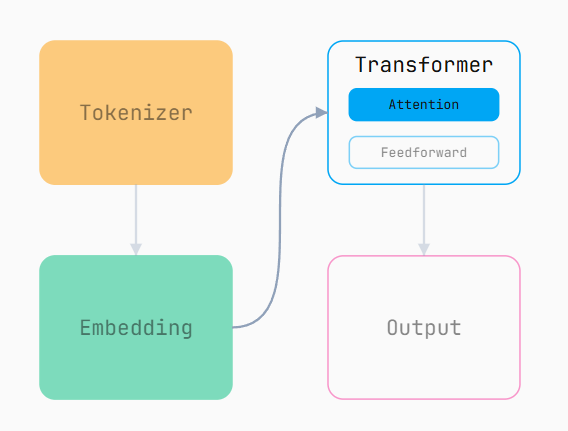
Transformer 阶段的核心任务,就是接收 embeddings 作为输入,并在 n 维空间中对它们进行调整。它通过两种方式实现这一点,而我们只关注第一种:attention(注意力机制)。我们暂不讨论 "Feedforward" 层或输出阶段(至少在这篇文章中👀)。
Attention 机制的作用,是帮助 LLM 理解 prompt 中各个 token 之间的关系 ------ 具体做法是让每个 token 能够影响其他 token 在 n 维空间中的位置。 它通过加权组合 prompt 中所有 token 的 embeddings 来实现这一点。输入是整个 prompt 的 embeddings,输出则是一个新的 embedding,它是所有输入 embeddings 的加权组合。
举个例子,如果 prompt 是 "Mary had a little",被分词为四个 token:Mary、had、a、little,那么 attention 机制可能会决定,在生成下一个 token 时,模型会认为:
- "Mary" 最重要(63%)(译者注:因为整个句子的主语是 Mary,后续内容很可能围绕她展开)
- "had" 和 "a" 次之(16% 和 12%)(译者注:它们是语法结构的一部分,但语义信息较弱)
- "little" 也有一定作用(9%)(译者注:它修饰后面的名词)
然后,它会把所有 token 的 embeddings 分别乘以对应的权重,然后把结果加在一起,得到一个融合后的向量。这正是 LLM 判断"在当前上下文中,每个 token 应该被关注多少"的方式。
这是目前为止整个流程中最复杂、最抽象的部分。我会先用伪代码展示它,然后再看看 embeddings 在经过这一过程时是如何被变换的。我本想让这一部分的数学内容少一些,但这里很难避免一些数学运算。别担心,你能行的,我相信你。
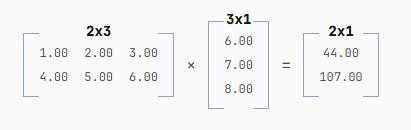
Attention 中的大部分计算都是矩阵乘法。对于本文而言,你只需知道:输出矩阵的形状由两个输入矩阵的形状决定,输出的行数等于第一个输入矩阵的行数,列数等于第二个输入矩阵的列数。
理解了这一点,我们来看一个简化版的注意力机制如何计算分配给每个 token 的权重。在以下代码中,我用 * 表示矩阵乘法。
// Similar to EMBEDDINGS from the pseudocode
// earlier, WQ and WK are learned during
// training and do not change during inference.
//
// These are both n*n matrices, where n is the
// number of embedding dimensions. In our example
// above, n =3.
const WQ =[[...],[...],[...]];
const WK =[[...],[...],[...]];
// The input embeddings look like this:
//[
//[-0.1,0.1,-0.3],// Mary
//[1.0,-0.5,-0.6],// had
//[0.0,0.8,0.6],// a
//[0.5,-0.7,1.0]// little
//]
function attentionWeights(embeddings){
const Q = embeddings * WQ;
const K = embeddings * WK;
const scores = Q * transpose(K);
const masked = mask(scores);
return softmax(masked);
}接下来,让我们看看 embedding 在流经这个函数时是如何变化的。
等等,WQ 和 WK 变量到底是什么?
还记得我之前说过,每个 token 的 embedding 最初都被随机分配了一个位置,然后在训练过程中不断微调,直到模型找到一个良好的排列状态吗?
WQ 和 WK 也是类似的。它们是 n×n 的矩阵(n 即 embedding 维度),在训练开始时被赋予随机值,随后也在训练中被不断调整,以帮助模型收敛到一个更优的解。
任何在训练过程中被调整的数,都被称为"模型参数"。embedding 向量中的每个浮点数,以及 WQ、WK 矩阵中的每个数值,都是一个参数。当你听说某个模型有"1750 亿参数"时,指的就是这些数字。
至于 WQ 和 WK 到底代表什么,我们其实并不完全清楚。随着模型训练收敛,它们最终会变成某种对 embedding 的变换方式,有助于模型生成更好的输出。 它们内部可能在做任何事情 ------ 而如何解释这些矩阵的含义,目前仍是一个开放且活跃的研究方向。
要得到 Q 和 K,我们分别将 embeddings 与 WQ 和 WK 相乘。WQ 和 WK 的行数和列数始终等于 embedding 的维度(本例中为 3)。这里我为 WQ 和 WK 选取了随机值,并将结果四舍五入到小数点后两位以便阅读。
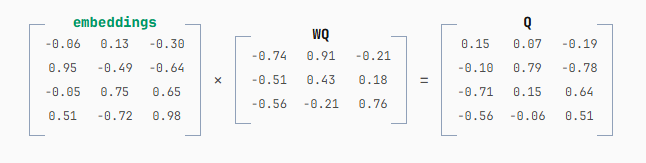
得到的 Q 矩阵有 4 行 3 列。4 行是因为 embeddings 矩阵有 4 行(每个 token 一行),3 列是因为 WQ 有 3 列(每个 embedding 维度一列)。
K 的计算完全相同,只是将 WQ 换成 WK。
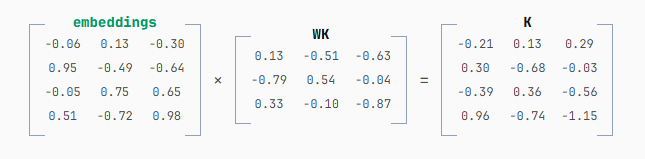
Q 和 K 都是输入 embedding 到新的 n 维空间的"投影"。它们不是原始的 embedding,但由原始 embeddings 推导而来。
然后,我们将 Q 和 K 相乘。我们对 K 进行"转置",也就是沿对角线翻转,使得得到的矩阵是一个方阵,其行数和列数都等于输入提示词中的 token 数量。
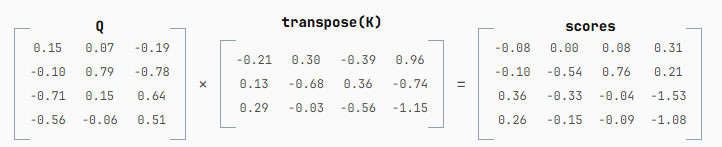
这些 scores 表示每个 token 对下一个生成 token 的重要程度。 左上角的数值 -0.08,代表 "Mary" 对 "had" 的重要性。再往下一行的 -0.10,则代表 "Mary" 对 "a" 的重要性。在展示完矩阵运算后,我会用图示更直观地说明这一点。接下来的所有操作,都是为了将这些 scores 转换为可用于混合 embeddings 的权重。
这个 score 矩阵的第一个问题是:它允许未来的 token 影响过去的 token。在第一行,我们唯一知道的词是"Mary",所以它应该是唯一对生成"had"有贡献的词。第二行也是如此,我们知道"Mary"和"had",所以只有这两个词应该对生成"a"有贡献,依此类推。
为了解决这个问题,我们对矩阵应用一个三角形掩码(triangular mask),将未来 token 对应的位置置零。不过,我们并不是真的设为 0,而是设为负无穷(negative infinity) ------ 原因稍后解释。

第二个问题是,这些 scores 是任意的数值。如果它们能变成一个每行之和等于 1 的概率分布,对我们来说会更有用。这正是 softmax 函数的作用。softmax 具体如何运作的细节并不重要 ------ 它比简单的"将每个数字除以该行总和"稍复杂一点,但结果是一样的:每行之和为 1,且每个数字都在 0 和 1 之间。

为了解释为什么用负无穷,下面是一个 softmax 的代码实现:
function softmax(matrix){
return matrix.map(row =>{
const exps = row.map(x => Math.exp(x));
const sumExps = exps.reduce((a, b)=> a + b,0);
return exps.map(exp => exp / sumExps);
});
}它并不是简单地把每个数加起来再除以总和,而是先对每个数值取 Math.exp,也就是计算 e^x。如果我们用 0 代替负无穷,Math.exp(0) === 1,这些被屏蔽的位置仍然会产生非零权重。而 Math.exp(-Infinity) 是 0,这正是我们想要的。
下面的图片展示了提示词"Mary had a little"的 attention 权重示例。
这些权重与上面的计算结果不匹配,因为我是从 Transformer Explained 网站7上运行的 GPT-2 模型中提取的。所以这些是一个真实模型(尽管是老模型)的真实权重。
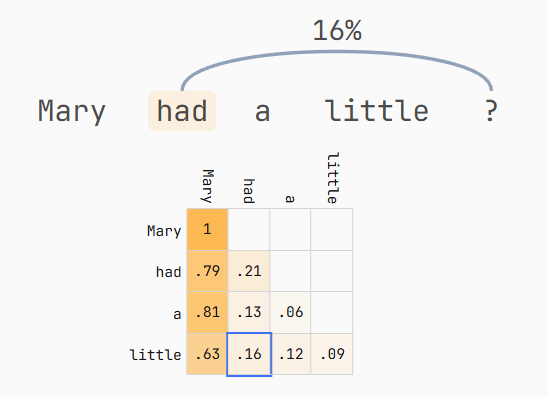
第一行只有"Mary",因此Mary对"had"的生成的贡献是100%。然后在第二行,"Mary"贡献了79%,而"had"贡献了21%用于生成"a",以此类推。LLM 认为这个句子中最重要的词是 "Mary",这一点并不意外------从每一行中 "Mary" 都拥有最高权重就能看出。如果我让你补全"Jessica had a little"这个句子,你不太可能选择"lamb"。
接下来就只剩下对 token embeddings 进行加权混合了,谢天谢地,这一步比计算权重要简单得多。
// Learned during training, doesn't change
// during inference. This is also an n*n matrix,
// where n is the number of embedding dimensions.
const WV =[[...],[...],...];
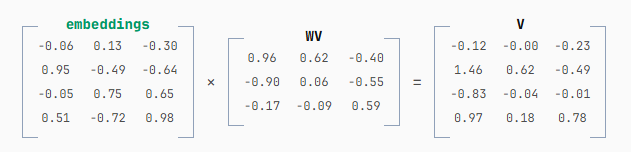
function attention(embeddings){
const V = embeddings * WV;
// This is the `attentionWeights` function from
// the section above. We're wrapping it in
// this `attention` function.
const weights = attentionWeights(embeddings);
return weights * V;
}
为什么不直接混合原始 embeddings?
当我们通过 Q 和 K 相乘得到 attention 权重时,我们完全是在衡量 token 之间的相关性。Embeddings 编码了 token 的各种语义信息 ------ 某一维可能表示"颜色",另一维表示"大小",再一维表示"礼貌/粗鲁程度",等等。而权重是通过相似度来判断哪些 token 更相关。
WV 的作用,则是让模型决定在混合时保留哪些维度的信息。
以句子 "Mary had a little" 为例,这里关于 "Mary" 最重要的信息是"人名"。模型在训练中可能也学到了很多关于 "Bloody Mary(血腥玛丽鸡尾酒)" 或 "Mary Queen of Scots(苏格兰女王玛丽)" 的知识,但这些与这首童谣无关,如果带入后续计算反而会引入噪声。因此,WV 允许模型在混合 embeddings 之前,先过滤掉不相关的特征。
接着,我们将生成的权重与 V 相乘,输出一组新的 embeddings:
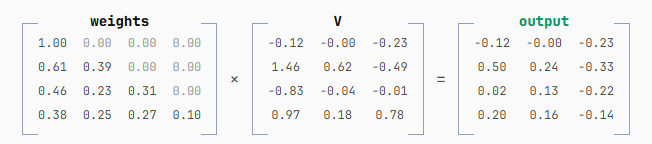
Attention 机制的最终输出,就是这个输出矩阵的最后一行。 通过 attention 过程,前面所有 token 的上下文信息都被融合进了这一行。但要注意:为了得到最后一行,前面所有行都必须被计算出来。
总而言之,输入是一组 embeddings,输出是一个新的 embedding。Attention 机制通过大量精细的数学运算,按照训练中学到的 WQ、WK 和 WV 矩阵所决定的重要性比例,将各个 token 的信息进行了加权融合。正是这一机制,让 LLM 能够理解在其上下文窗口中"什么内容重要,以及为什么重要"。
现在,我们终于掌握了讨论 caching 所需的一切知识。
当然,Attention 还有更多技术细节
我在本文展示的是一个简化版的 attention,目的是突出与 prompt caching 最相关的核心部分。实际中的 attention 机制更为复杂。如果你希望深入了解更多技术细节,我推荐 3blue1brown 关于 attention 的视频8。
05 Prompt caching
我们再来看一遍上面的网格,但这次会展示在推理循环中每生成一个新 token 时,它是如何逐步填充的。
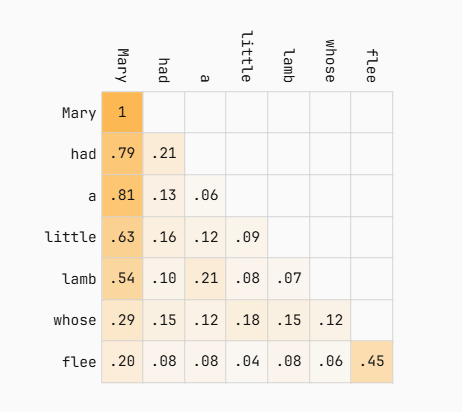
每次生成新 token 时,都会将其追加到输入中,并重新完整处理整个 prompt。但仔细观察:之前计算出的权重从未改变。第二行始终是 0.79 和 0.21,第三行始终是 0.81、0.13、0.06。我们其实在不断重复大量不必要的计算。如果你刚刚才处理完 "Mary had a",那么在生成下一个 token 时,对 "Mary had a little" 中前三个 token 的大部分矩阵运算其实是冗余的 ------ 而这正是 LLM 推理循环的默认行为。
通过以下两个改动,就能避免这些重复计算:
- 在每次迭代中缓存 K 和 V 矩阵。
- 只将最新 token 的 embeddings 输入模型,而不是整个 prompt。
现在我们再次走一遍矩阵运算过程,但这一次:前 4 个 token 的 K 和 V 矩阵已被缓存,我们只传入一个新 token 的 embeddings。
是的,又要面对矩阵运算了,抱歉!不过内容和之前基本一致,我们会快速过一遍。
计算新的 Q 时,输出只有一行。WQ 和之前一样,没有变化。
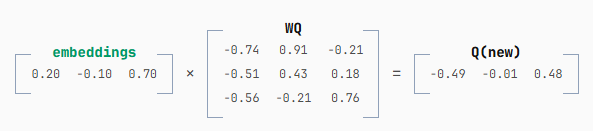
接着,计算新的 K 也同样只输出一行,而 WK 也和之前一样保持不变。
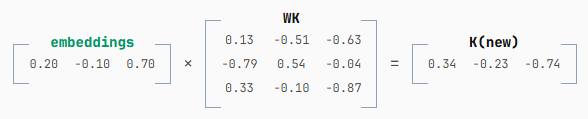
但随后我们将这一新行追加到前一次迭代缓存的 4 行 K 矩阵之后:
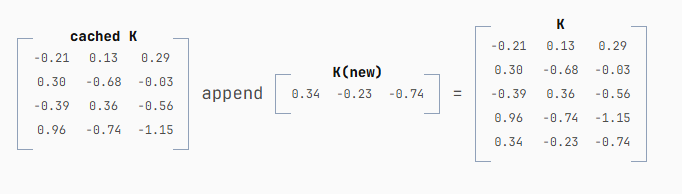
于是现在我们拥有了提示词中所有 token 的 K 矩阵,但我们只需要计算它的最后一行。
我们继续以这种方式来获取新的 score:

以及新的的 weights:

全程我们只计算必需的部分,完全不需要对旧值进行任何重新计算。获取 V 的新一行时也是同样的做法:
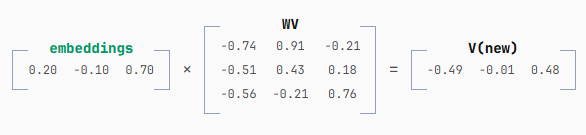
然后将其追加到我们缓存的 V 中:

最后,我们将新的权重与新的 V 相乘,得到最终的新 embeddings:
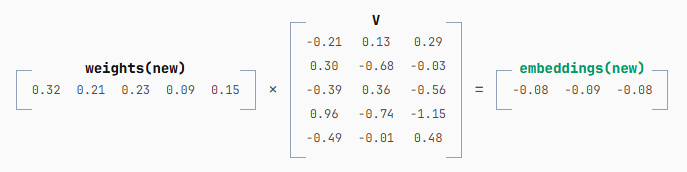
我们只需要这单独一行新的 embedding。得益于缓存的 K 和 V,先前所有 token 的上下文信息都已被融入其中。
被缓存的数据是 embeddings * WK 和 embeddings * WV 的结果,也就是 K 和 V。 因此,提示词缓存通常被称为"KV caching"。
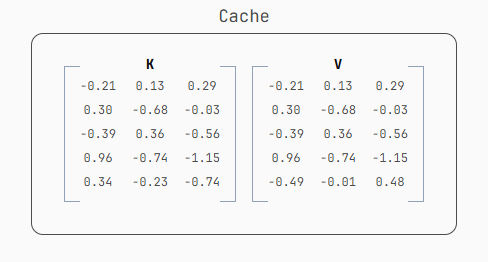
就是这样,上面那些 K 和 V 矩阵,就是服务提供商保存在他们巨大数据中心里的 1 和 0,用来给我们提供一折的 token 成本和更快的响应。
服务提供商在请求发出后,会将每个提示词的这些矩阵保留 5-10 分钟,如果你发送一个以相同提示词开头的新请求,他们就会复用缓存的 K 和 V,而不是重新计算它们。缓存匹配不需要完全一致 ------ 即使新 prompt 只和缓存中的某一部分开头相同,也可以复用那部分已缓存的计算结果,而不必整个 prompt 完全匹配。
OpenAI 和 Anthropic 的缓存机制截然不同。OpenAI 完全自动处理,会尽可能尝试将请求路由到缓存条目。 在我的实验中,通过发送请求然后立即重发,缓存命中率约为 50%。考虑到长上下文窗口的首字节延迟(time-to-first-byte)可能很长,这种自动缓存可能导致性能表现不稳定。
Anthropic 则赋予你更多控制权,让你决定何时缓存以及缓存多久。 你需要为这项特权付费,但在我进行的实验中,当我们要求 Anthropic 缓存某个提示词时,他们会 100% 地将请求路由到缓存条目。因此,如果你的应用涉及长上下文窗口,并且需要可预测的延迟,Anthropic 可能是更合适的选择。
等等,那 temperature 这些参数会影响提示词缓存吗?
LLM 提供商提供了多种参数来控制模型输出的随机性,常见的有 temperature、top_p 和 top_k。这些参数都作用于推理循环的最后一步,即模型根据它为词表中每个 token 分配的概率来选取 token。这发生在 attention 机制产生最终 embedding 之后,因此提示词缓存不受这些参数影响。你可以随意调整它们,而不用担心导致缓存的提示词失效。
致谢
为了学习撰写本文所需的全部知识,我如饥似渴地阅读了大量优质内容,以下是我认为对我最有帮助的:
- Build a Large Language Model (From Scratch)9 by Sebastian Raschka10.
- Neural Networks: Zero to Hero11 by Andrej Karpathy12.
- Neural Networks video course13 by 3blue1brown14.
- Transformer Explainer15 by Aeree Cho16 et al.
如果你喜欢这篇文章,你一定会喜欢这些资源。
END
本期互动内容 🍻
❓按照文中逻辑,缓存本质是拿内存换计算。当你处理10万Token以上的超长上下文时,有没有估算过KV Cache的内存占用成本 vs 重新计算的API成本?在什么临界点你会选择放弃缓存?
文中链接
1https://claude.com/blog/prompt-caching
2https://docs.claude.com/en/docs/build-with-claude/prompt-caching
3https://platform.openai.com/docs/guides/prompt-caching
4https://magazine.sebastianraschka.com/
5https://github.com/rasbt/LLMs-from-scratch/blob/main/ch05/13_olmo3/standalone-olmo3.ipynb
6https://tiktokenizer.vercel.app/
7https://poloclub.github.io/transformer-explainer/
8https://www.youtube.com/watch?v=eMlx5fFNoYc
9https://www.oreilly.com/library/view/build-a-large/9781633437166/
10https://sebastianraschka.com/
11https://www.youtube.com/watch?v=VMj-3S1tku0\&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ
13https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi
14https://www.youtube.com/@3blue1brown
15https://poloclub.github.io/transformer-explainer/
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: