一、TCP协议
1.数据传输的总体框架
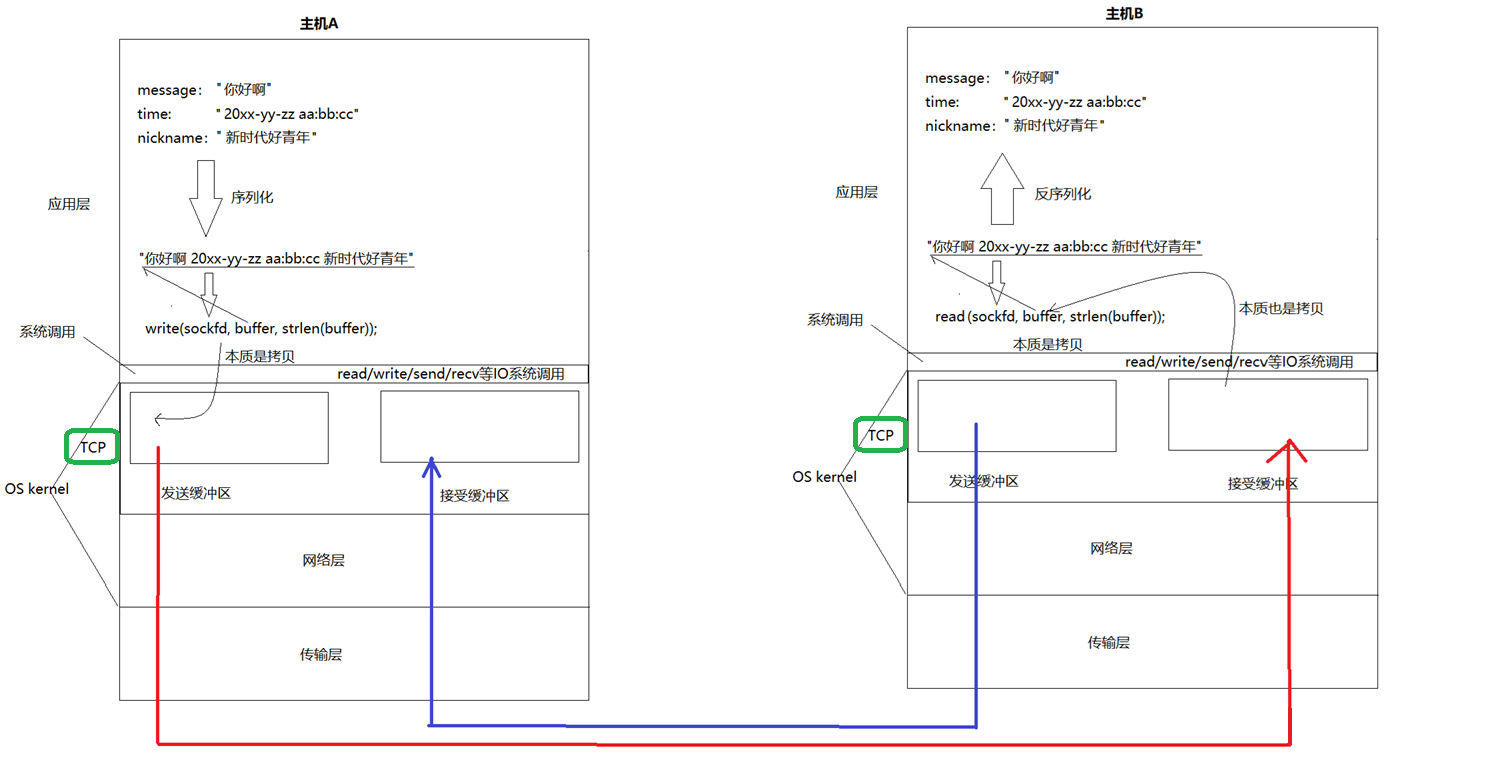
如何找到接收缓冲区?
当主机收到报文后,通过 端口号port 和 套接字描述符sockfd 来定位接收缓冲区(本质就是文件),过程如下(以下大致思路,实际略有不同):
1.找到对应进程
需要使用网络的每个进程都有唯一的pid,还有一个或多个端口号port。而为了通过端口号port快速定位进程 ,操作系统会维护一个哈希表 ,构造(port:pid)的键值对存放在哈希表中,port是key值,pid是value。
2.找到缓冲区
套接字(缓冲区)本质就是文件,套接字描述符sockfd本质就是文件描述符,所以,可以通过对应进程PCB中的文件描述符表找到缓冲区。
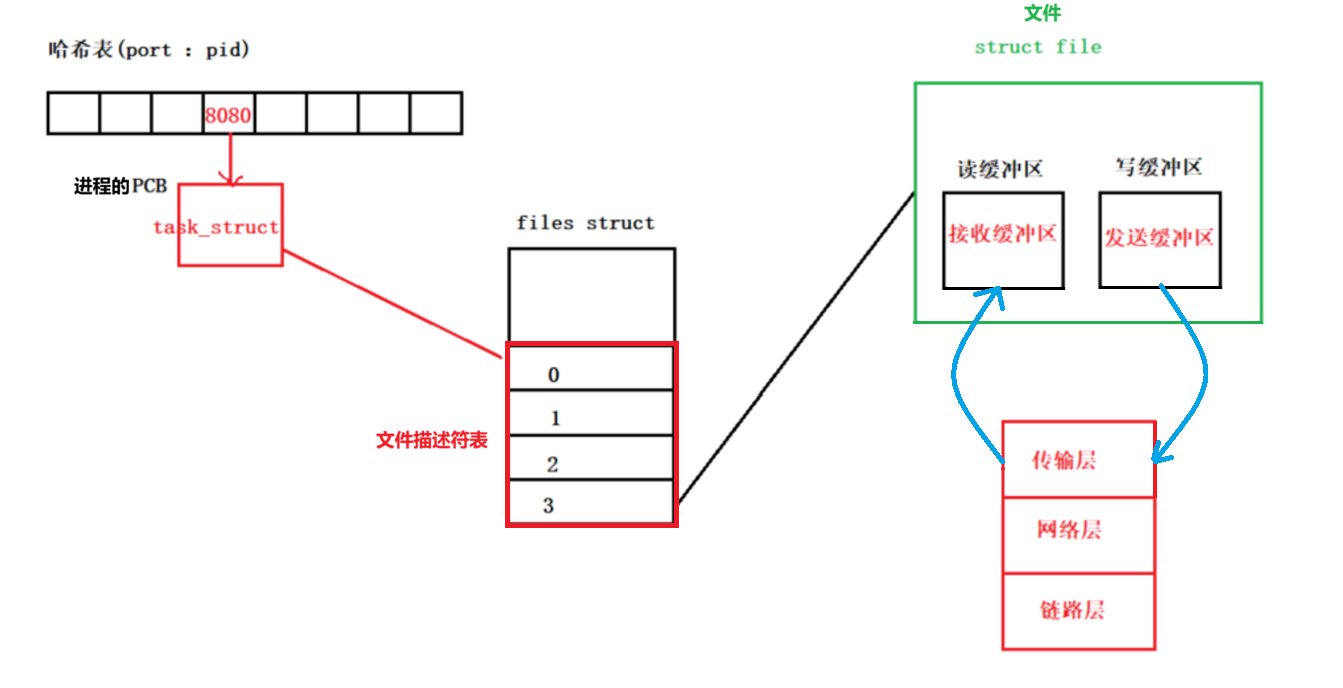
将TCP层解包后的有效载荷放入找到的接收缓冲区中,应用层就可以根据文件描述符sockfd用read读取有效载荷(报文)了,这就完成了数据的接收。
发送也是一样,不过是走了相反的方向。
2.TCP协议基础知识
TCP全称为**"传输控制协议(Transmission Control Protocol")**,它可以对数据的传输进行细致的控制。
传输控制协议
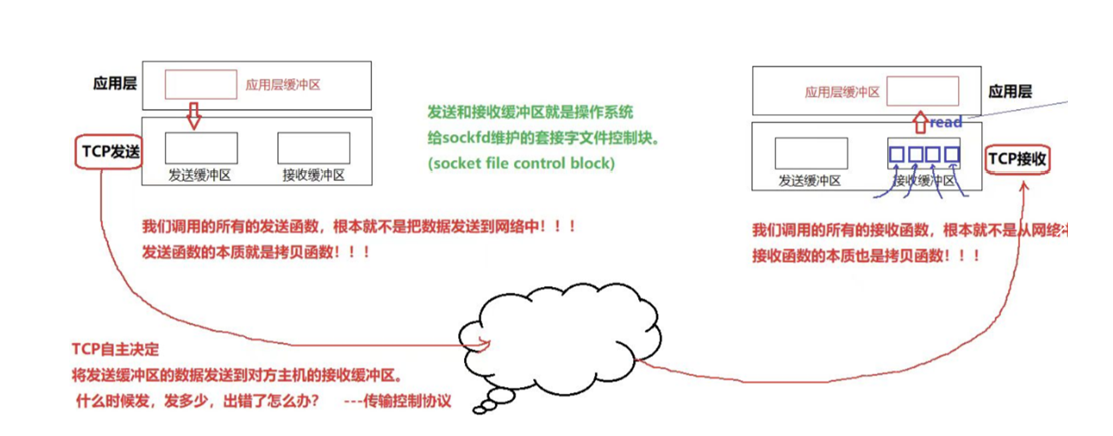
为什么 TCP 叫传输控制协议?
- 用户调用的网络发送函数,如 write、send、sendto 等,实际是将数据从应用层缓冲区拷贝到 TCP 协议层(也就是操作系统内部的发送缓冲区)
- 用户调用的网络接收函数,如 read、recv、recvfrom 等,实际是将数据从 TCP 协议层的接收缓冲区拷贝到用户层的缓冲区中
真正负责双方主机 TCP 协议层之间数据发送的过程,完全由 TCP 自主决定。 比如什么时候发送数据、一次发送多少数据、发送过程中出现错误该如何处理等,这些都由 TCP 协议自身控制,属于操作系统内部的操作,与用户层没有关联。这正是 TCP 被称为传输控制协议的原因 ------ 数据传输的整个过程由它自行控制和决定。
全双工通信模式
客户端(c)向服务端(s)发送数据,与服务端(s)向客户端(c)发送数据,使用的是不同的发送缓冲区和接收缓冲区对 。所以客户端给服务端发送数据时,并不会影响服务端给客户端发送数据,这说明 TCP 是全双工通信模式,一方在发送数据时,不影响另一方同时发送数据。
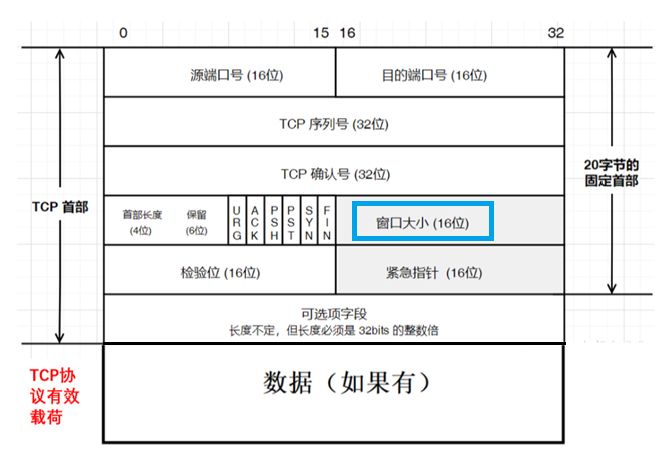
3.TCP协议格式
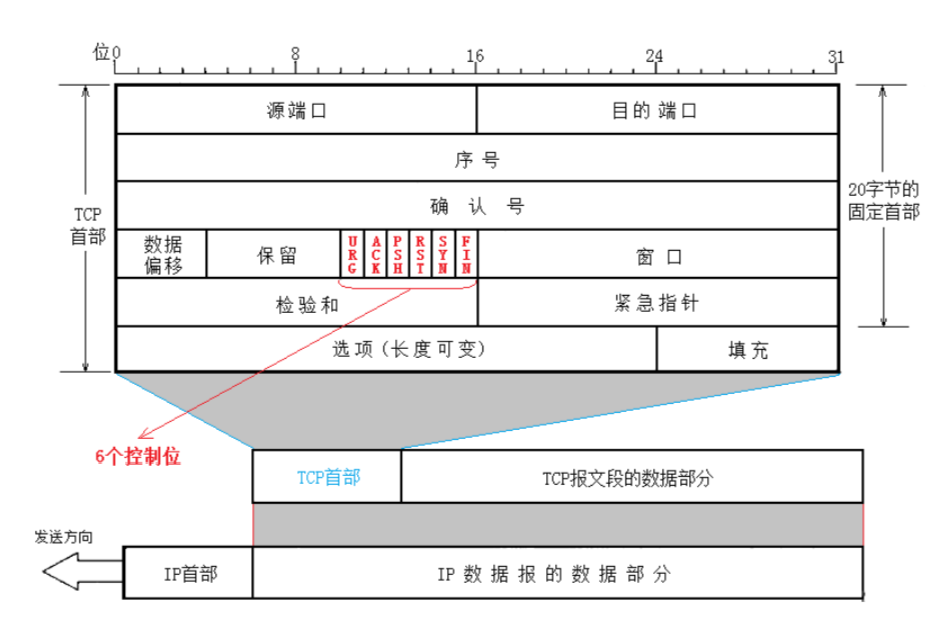
- TCP协议报头=固定长度首部(20字节)+选项
- TCP协议报文=固定长度首部(20字节)+选项+数据
选项的内容不讲解,只需要知道这部分不是定长的。
格式说明
图中每一行包含 4 个字节(32 位):
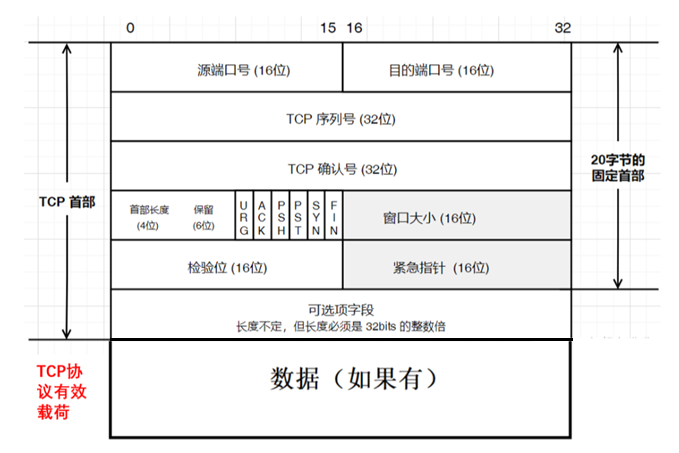
| 字段 | 长度 | 说明 |
|---|---|---|
| 源端口号(Source Port) | 16 位 | 发送方进程的端口号 |
| 目的端口号(Destination Port) | 16 位 | 接收方进程的端口号 |
| TCP序列号(Sequence Number) | 32 位 | 表示本报文段所发送数据的第一个字节的编号(后面讲) |
| TCP确认序号(Acknowledgment Number) | 32 位 | 表示接收方期望收到发送方下一个报文段的第一个字节数据的编号(后面讲) |
| 首部长度(Header Length) | 4 位 | 也叫数据偏移(Data Offset),指数据段中 "数据" 部分起始处距离 TCP 报文段起始处的字节偏移量,用于确定 TCP 报头部分的长度(固定首部+选项)。 计算方法:TCP报头所占字节数=首部长度 * 4(后面讲) |
| 保留(Reserved) | 6 位 | 为 TCP 协议未来的功能扩展预留空间,目前这 6 位必须全部为 0 |
| 控制标志(Control Flags) | 6 位 | 共包含 6 个标志位,每个标志位占 1 个 bit,分别对应不同的控制功能(后面讲) |
| 窗口大小(Window Size) | 16 位 | 表示滑动窗口的大小(接收方还能接受的字节数据量),用于 TCP 的流量控制(后面讲) |
| 校验和(Checksum) | 16 位 | 用于验证传输的数据是否损坏。发送端根据数据内容计算生成校验和数值,接收端根据接收到的数据重新计算校验和。若两个数值相同,说明数据有效;反之则无效,接收端会丢弃该数据包。校验和的计算基于伪报头 + TCP 报头 + TCP 数据三部分 |
| 紧急指针(Urgent Pointer) | 16 位 | 仅当标志位字段的 URG 标志位为 1 时才有意义,用于指出有效载荷中紧急数据的位置(偏移量),紧急数据的大小固定为1字节。 |
| 选项(Options) | 可变 | 长度不固定,但必须是 32bits(4 字节)的整数倍,内容可根据需求变化,因此必须通过首部长度来区分选项的具体长度 |
| 数据 | 可变 | 应用层的报文和有效载荷 |
补充说明
1.各标志位详解
标志位字段共 6bit,包含 6 个标志位,每个标志位占 1bit,只有 0 和 1 两种状态。
- URG (Urgent): 为1时,表示报文段中有紧急数据,应优先处理。此时紧急指针字段有效。
- ACK (Acknowledgment): 为1时,表示TCP确认号字段有效。在连接建立后,绝大多数报文此位都被置1。
- PSH (Push): 为1时,催促接收方立即将 接收缓冲区中的数据 推送给上层应用程序,而不必等待缓冲区填满。常用于交互式应用(如Telnet、SSH),以降低延迟。
- RST (Reset): 为1时,表示需要重置连接。通常用于异常终止连接,或拒绝一个非法的连接请求。
- SYN (Synchronize): 为1时,表示这是一个连接请求或连接接受报文。用于三次握手建立连接。
- FIN (Finish): 为1时,表示发送方数据已发送完毕,要求释放连接。用于四次挥手关闭连接。
2.重置连接
基础知识:
- TCP需要双方保持连接才能通信
- 两个主机间每建立一个连接,操作系统就会通过链表等数据结构管理起来
- 当RST标志位为1时,表示当前连接非法,需要重新连接
举例说明:
- 客户端与服务端通信时,突然服务器断电了,主机直接停止运行。
- 此时,服务器中维护连接的数据结构消失,但是客户端维护的连接数据结构还在。
- 所以,客户端认为它与服务器的连接依旧正常,还会给服务器发数据。
- 服务器重新启动后,接收到客户端的数据,但发现并没有和客户端建立连接。
- 此时,服务器就给客户端发送一个RST标志位为1的报文,告诉客户端连接不合法,请建立新连接。
3.紧急指针
紧急数据通常称为带外数据,TCP规定只能有1字节,需要被尽快读取。
**URG=1 时表示有紧急数据,此时16位紧急指针字段有效,表示紧急数据在有效载荷中的偏移量。**接收方读取 TCP 报头后,会先从紧急指针指示的偏移量处读取 1 字节紧急数据,再从有效载荷起始位置读取剩余数据。
**实际上,紧急指针和 URG 标志位一般用不到。**若需使用带外数据,可能是运维人员用于查询服务器状态(如服务器压力大时,发送 1 字节带外数据询问状态,服务器返回 1 字节状态码,带外数据无需经过冗长数据流,可直接在应用层读取)。
若要读取带外数据,可将 recv/send 的 flags 标志位按位或上 MSG_OOB
cpp
ssize_t recv(int socket, void *buf, size_t len, int flags);
ssize_t send(int socket, const void *buf, size_t len, int flags);
eg.
recv(sockfd,&ch,1,MSG_OOB);TCP报文的报头和有效载荷如何分离呢?
TCP 报文头部与有效载荷的分离依赖于头部中的 "数据偏移"(Data Offset) 字段。具体步骤如下:
1.读取 TCP 报文的前 20 字节
这是 TCP 头部的基本部分(固定长度),其中包含 数据偏移 字段(位于第 13 字节的高 4 位)。
2.解析"数据偏移"字段
该字段以 4 字节 为单位表示整个头部的长度。例如:
- 若数据偏移值为 5,表示头部长度为 5×4 = 20 字节(无选项)。
- 若数据偏移值为 8,表示头部长度为 8×4 = 32 字节(含 12 字节选项)。
- 注意:数据偏移长度为4位,表示范围是 0 (0000) ~15(1111),又以4字节为单位,结合实际,头部长度的范围是20字节~60字节
3.根据数据偏移计算头部结束位置
从报文起始位置向后偏移 (数据偏移值 × 4) 字节,即得到头部结束处。之后的所有内容即为 有效载荷(应用层数据)。
4.处理选项字段(如果有)
如果数据偏移大于 5,说明头部包含选项。在读取完基本头部(20 字节)后,继续读取 (数据偏移值×4 -- 20) 字节的选项,然后剩余部分才是有效载荷。
示例
假设收到一个 TCP 报文,其数据偏移字段为 6,则:
- 头部总长度 = 6 × 4 = 24 字节。
- 前 20 字节为固定头部,接着 4 字节为选项,之后全部为有效载荷。
为什么在TCP报头中,只表示了报头的大小?
为什么在TCP报头中,没有表示 报头+有效载荷 的大小,只表示了 报头 的大小?而在UDP报头中有16位的UDP长度字段,其定义了整个UDP数据报的长度(报头+有效载荷/数据)
1.TCP 是面向字节流的协议
- TCP 把数据视为连续的字节流,不保留单个"消息"边界。接收方依靠序列号和确认号来重组数据流,不需要在 TCP 层知道每个报文段的确切数据长度。
- 整个 TCP 段的长度可以通过 IP 总长度减去 IP 头部长度和 TCP 头部长度(由"数据偏移"字段给出)间接得到。
- 因此,TCP 头部只需提供头部长度(数据偏移),而不需要再额外携带整个报文段的总长度。
2.UDP 是面向数据报的协议
- UDP 每个数据报都是独立的,接收端必须能够明确区分每个报文的起止。16 位 UDP 长度字段直接指明头部与数据的总长度,让接收方知道当前数据报在哪里结束
- 由于 UDP 没有连接状态,也不使用序列号,只能依靠长度字段判断报文边界,否则无法从 IP 层交付的数据中正确分离出 UDP 报文。
3.协议分工的不同
- IP 层已经提供了总长度字段,TCP 利用这一信息(结合自己的头部偏移)即可算出数据长度,避免了在传输层重复记录。
- UDP 同样可以借助 IP 长度推算,但为了自包含(self‑contained)以及支持伪首部校验和计算,仍保留了独立长度字段。
4.TCP协议的可靠性
通信不可靠的现象
- 数据包可能丢失在网络中,对方主机没有接收到。
- 一份数据可能会被分成多个数据包按顺序发送,但对方接收的顺序很可能会改变。
- 一份数据可能在一段时间内没有被对方收到,所以发送方又重发了一次,此时接收方会收到两份一样的数据。
- 发送方太快,接收方接收缓冲区很快被占满,以后发来的数据就会被丢弃。
- 发送方太慢,接收方大部分时间都在等待数据,处于饥饿。
总而言之,丢包、乱序、重复、校验失败、发送太快发送、太慢都是不可靠的表现。可靠的通信都需要避免这些问题。
而在其中,最核心的就是避免丢包问题。
确认应答机制概念
TCP协议通过很多机制来避免丢包,确保可靠性,其中确认应答机制尤其重要。
所谓确认应答机制可以简单理解为:在双方通信时,发送方每发送一个数据包,接收方就要返回一个ACK应答。如果在一定的时间内没有接收到应答,发送方就只能再次将同样的数据发送,直到收到应答。
正确理解可靠性
如果对端没有给我们应答,那我们就不能确定对端是否收到我发送的消息,我们只能保证历史消息的可靠性
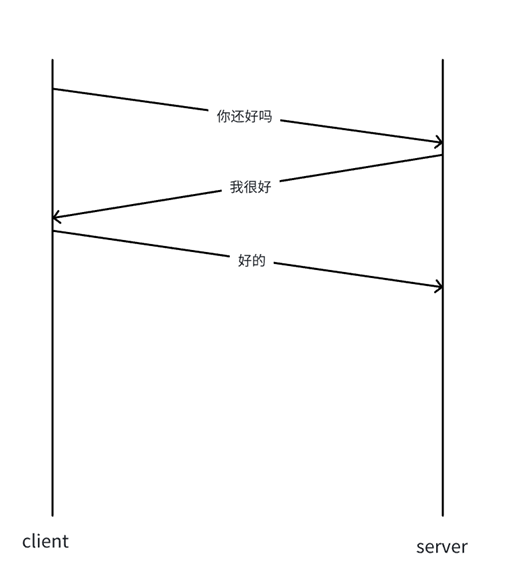
1.对历史消息的保证:
- 关键机制:具有应答。
- 一旦发送出去的报文收到了接收方的确认应答,发送方就能100%确定该历史消息已经被对方成功接收。这是可靠性得以实现的基础。
2.对最新消息的挑战:
- 核心困境:最新的报文永远没有应答。
- 在通信过程中,刚刚发送出去的、最新的那个报文,在它被确认之前,其状态是未知的。发送方无法确定它是否已经到达、是否在途中丢失或损坏。因此,单凭应答机制,无法保证"最新"报文的可靠性。
5.TCP协议的通信过程
**发送方发送一个报文后,接收方返回一个确认"应答",以确认收到数据(确认应答机制)。**对于应答,我们不再需要回应,因为ACK不携带数据。
下面我们以客户端给服务端发送报文为例(TCP/UDP通信中,服务端和客户端是等价的)
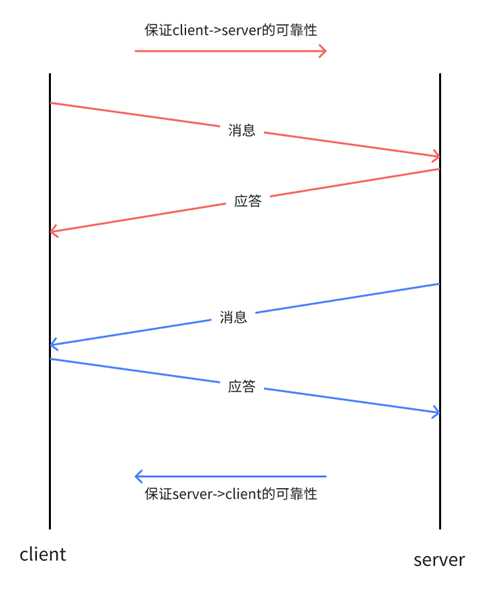
实际上,客户端一般是一次发送多个消息,服务端则对每个消息做应答
二、TCP的主要机制
1.确认应答(ACK)机制
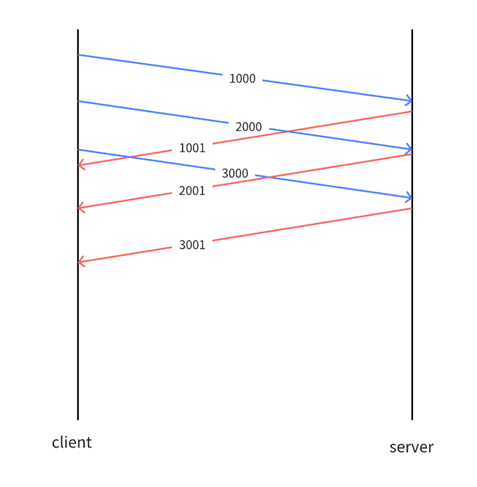
如果发送方每次只发一个数据段,等到收到接收方的应答后,再发送下一个数据段,具体实现就会简单很多。但是TCP实际工作时,为了提升效率,发送方会同时发送多个数据段,而接收方会同时对每个数据段发出对应的应答。
那如何让接收方收到的数据段按序排列,发送方收到的应答与发送的数据段对应?------使用字节序列号来标识数据段本身 ,其实就是填写报文中的报头来标识有效载荷或做出应答,下面探讨其如何实现:
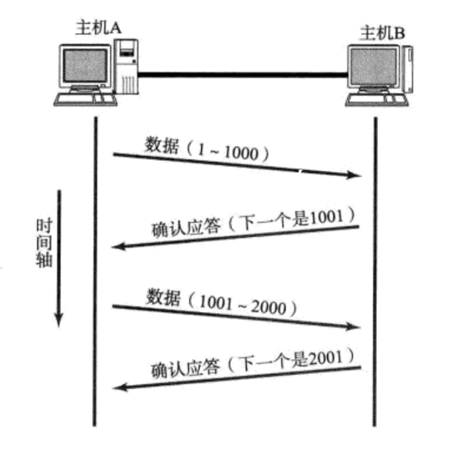
对于TCP来说,它传输的不是一个个独立的"消息包",而是一个连续的、无结构的字节流。
- 应用层视角: 你可能会发送两条消息:"Hello" 和 "World"。
- TCP视角: 它看到的是一个连续的字节序列:'H', 'e', 'l', 'l', 'o', 'W', 'o', 'r', 'l', 'd'。
在发送缓冲区中,TCP将每个字节的数据都进行了编号,即为序列号 (简单理解:发送缓冲区为char类型的数组,序列号为数组下标)。TCP是以报文段(多个字节)为单位 来发送数据的,而这个报文段的序列号就是 该报文段的第一个字节的序列号 。
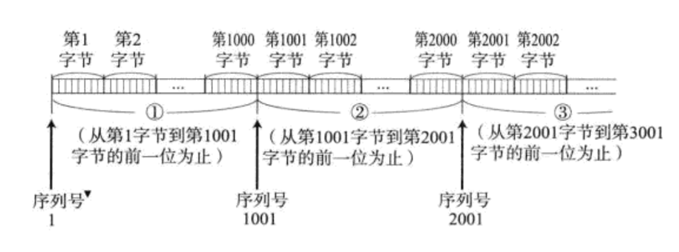
发送方的发送报头
TCP发送报头中:TCP序列号 就是 发送的报文 段的序列号------报文段中第一个字节的序列号
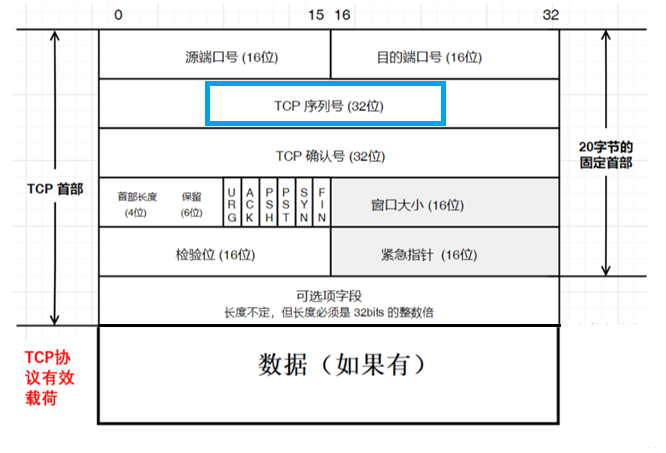
假设1000个字节长度为一个报文段:
- 第一个报文段:TCP序列号 = 1。这意味着它包含了从第1个字节开始的1000个字节(即字节1 到 1000)。
- 第二个报文段:TCP序列号 = 1001。这意味着它包含了从第1001个字节开始的1000个字节(即字节1001 到 2000)。
- 第三个报文段:TCP序列号 = 2001。这意味着它包含了从第2001个字节开始的1000个字节(即字节2001 到 3000)。
接收方的确认报头
接收方的确认同样是基于字节序列号的。
假设成功接收(1000个字节长度为一个报文段):
- 当接收方成功收到第一个报文段(字节1-1000)后,它会回复:ACK=1001。
- 这个 1001 的含义是:"截至到第1000号字节的所有数据我都已收到,我下一个期望收到的字节的序列号是1001"。
- 当发送方收到 ACK=1001 后,它就知道前1000个字节已经安全送达,可以继续发送从1001开始的数据。
假设发生丢包(1000个字节长度为一个报文段):
- 发送方同时发送第一个报文段:TCP序列号 = 1(即字节1 到 1000)、第二个报文段:TCP序列号 = 1001(即字节1001 到 2000)
- 成功接收第一个报文段,丢失第二个报文段
- 接收方回复两个相同的报文:ACK=1001
- 当发送方收到两个 ACK=1001 后,它就知道只有第一个报文段(前1000个字节)安全送达,需要重传第二个报文段
接受方回复报文的报头:标志位ACK为1,TCP确认号为1001( 简便写法:ACK=1001 )
标志位ACK为1 代表发送的报文具有应答性质,TCP确认号为1001 代表收到了1001序列号之前的所有数据,可以继续发送从1001开始的数据。
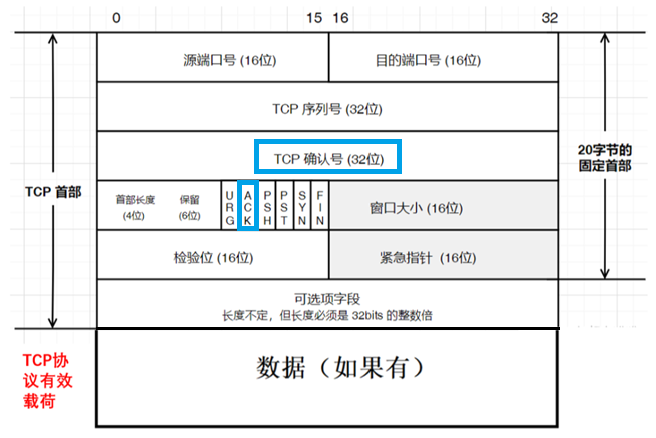
为什么需要两个序号(TCP序列号、TCP确认号)?
常见疑问:既然一方发送数据,一方接收数据,为什么不能只用一个序号作为发送方的序列号/接收方的确认号?
- 发送方需要TCP序列号来标识自己发出的数据。
- 接收方需要TCP确认号来告诉对方"我已经收到了哪些数据"
因为这里的发送方和接收方只是相对概念,通信的每一方都可以既是发送方又是接收方,同时为了提升效率,在发送数据段时,可能该数据段既有作为接收方的应答也有作为发送方的数据, 所以就同时需要TCP序列号和TCP确认号。
通信双方的TCP序列号和TCP确认号对应情况:
两组序号相互独立,互不干扰,体现了TCP的全双工通信模式
初始序列号是如何确定的?
在TCP建立连接(三次握手)时,通信双方会各自随机生成一个初始序列号。使用随机值是为了安全,防止被恶意预测和攻击。
- 客户端 在 SYN 报文中携带自己的初始序列号(例如 seq = x)。
- 服务端 在 SYN-ACK 报文中携带自己的初始序列号(例如 seq = y),并确认客户端的序列号(ACK = x+1)。
- 客户端 在最后的 ACK 报文中确认服务端的序列号(ACK = y+1)。
至此,连接建立,双方后续的数据传输都基于这个初始序列号递增。
2.超时重传机制
丢包的两种情况
丢包后就需要重传,而丢包分为两种情况:
**情况一:**主机A发送数据给B之后,可能因为网络拥堵等原因,数据无法到达主机B
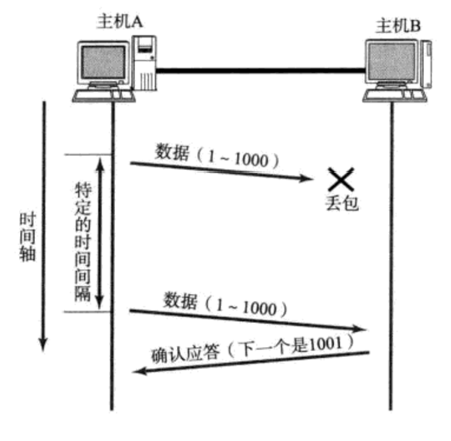
**情况二:**实际上数据并没有丢失,只是主机B发给A的ACK应答报文丢失了
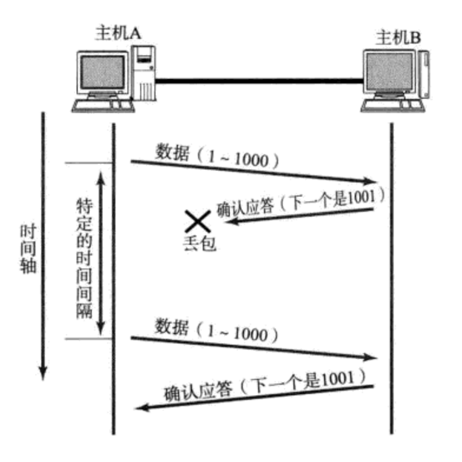
所以,发送方无法分辨是数据丢失还是应答丢失,只要特定的时间间隔没有收到应答ACK,都当作丢包处理。
TCP的重传机制
TCP协议通过一套统一的机制来避免丢包,保证可靠性:
- 发送方超时重传 :发送方无需关心具体是哪种丢包,只要特定的时间间隔没有收到应答ACK,就会触发重传
- 接收方丢弃重复数据:如果是应答ACK丢失,发送方的重传会导致接收方收到两份完全相同的数据。但TCP在报头中为每个数据字节设置了序列号,接收方可以利用序列号识别出重复的数据包并将其丢弃,确保向上层应用提交的数据是完整且不重复的
确定超时的时间
- 最理想的情况下,找到一个最小的时间,保证 "确认应答一定能在这个时间内返回"。
- 如果超时时间设的太长,会影响整体的重传效率
- 如果超时时间设的太短,有可能会频繁发送重复的包
- 但是这个时间的长短,随着网络环境的不同,是有差异的
TCP为了保证无论在任何环境下都能比较高性能的通信,因此会动态计算这个最大超时时间
- Linux中,超时以500ms为一个单位进行控制,每次判定超时重发的超时时间都是500ms的整数倍.
- 如果重发一次之后,仍然得不到应答,等待 2*500ms 后再进行重传
- 如果仍然得不到应答,等待 4*500ms 进行重传,依次类推,以指数形式递增
- 累计到一定的重传次数,TCP认为网络或者对端主机出现异常,强制关闭连接
在Linux中,默认的最大重传次数由/proc/sys/net/ipv4/tcp_retries2决定,通常是15次。

3.连接管理机制
总述
在正常情况下,TCP要经过三次握手建立连接,四次挥手断开连接
在建立连接和断开连接时,客户端和服务端的状态会产生变化,这些状态的本质其实就是一个整数(宏)。
TCP通过三次握手,建立管理连接的数据结构。
作用:
- 便于操作系统管理服务器与多个客户端建立的连接
- 是TCP连接各种机制的基础(确认应答机制、超时重传机制......),保证了可靠性
具体内容:
cpp
struct tcp_sock {
struct inet_connection_sock inet_conn;
// TCP专用字段:序列号、窗口、拥塞控制等
};
struct inet_connection_sock {
/* inet_sock has to be the first member! */
struct inet_sock icsk_inet; // 基础的INET套接字信息
struct request_sock_queue icsk_accept_queue; // 用于管理建立连接前的请求队列(如TCP的SYN队列和accept队列)
unsigned long icsk_timeout; // 当前连接的超时时间
struct timer_list icsk_retransmit_timer; // 数据包重传定时器
struct timer_list icsk_delack_timer; // 延迟ACK定时器
__u32 icsk_rto; // 重传超时时间(根据RTT动态计算)
__u32 icsk_pmtu_cookie; // 记录路径MTU(Path MTU)发现的信息
const struct tcp_congestion_ops *icsk_ca_ops; // 指向拥塞控制算法的操作函数集
const struct inet_connection_sock_af_ops *icsk_af_ops; // 地址族相关的操作(IPv4/IPv6)
__u8 icsk_ca_state:6, // 拥塞控制状态机(如Open, Disorder, CWR, Recovery, Loss)
__u8 icsk_retransmits; // 记录超时重传的次数
__u8 icsk_pending; // 记录挂起的定时器事件(如ICSK_TIME_RETRANS)
__u8 icsk_backoff; // 重传退避指数,用于计算重传超时
__u8 icsk_syn_retries; // SYN重试次数
// ... 可能还有其他字段
};所以建立连接是需要成本的------时间和空间
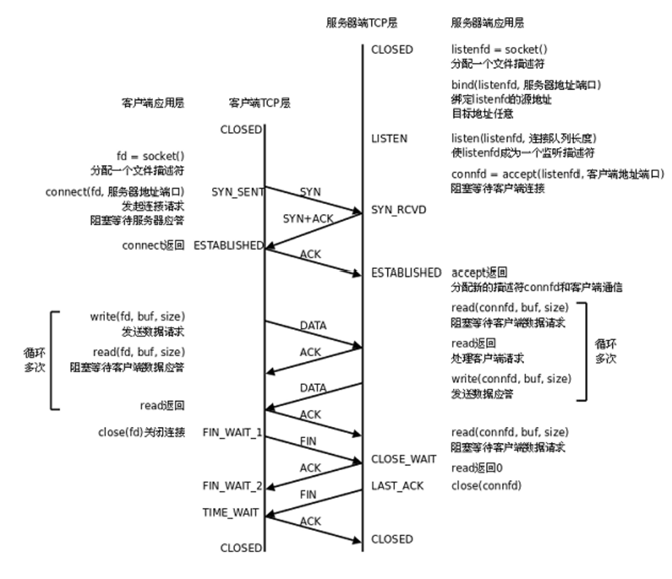
注:这里的SYN、ACK、FIN......其实是指传输的报头中对应标志位为1
服务端状态转化:
- CLOSED -\> LISTEN 服务器端调用listen后进入 LISTEN 状态,等待客户端连接
- LISTEN -\> SYN_RCVD 一旦监听到连接请求(同步报文段),就将该连接放入内核等待队列中,并向客户端发送SYN确认报文
- **SYN_RCVD -\> ESTABLISHED**服务端一旦收到客户端的确认报文,就进入 ESTABLISHED 状态,可以进行读写数据了
- **ESTABLISHED -\> CLOSE_WAIT**当客户端主动关闭连接(调用close),服务器会收到结束报文段,服务器返回确认报文段并进入 CLOSE_WAIT
- **CLOSE_WAIT -\> LAST_ACK**进入 CLOSE_WAIT 后说明服务器准备关闭连接(需要处理完之前的数据); 当服务器真正调用close关闭连接时,会向客户端发送FIN,此时服务器进入 LAST_ACK 状态,等待最后一个ACK到来(这个ACK是客户端确认收到了FIN)
- **LAST_ACK -\> CLOSED**服务器收到了对FIN的ACK,彻底关闭连接
客户端状态转化:
- **CLOSED -\> SYN_SENT**客户端调用connect,发送同步报文段;
- **SYN_SENT -\> ESTABLISHED**connect调用成功,则进入 ESTABLISHED 状态,开始读写数据;
- **ESTABLISHED -\> FIN_WAIT_1**客户端主动调用close时,向服务器发送结束报文段,同时进入 FIN_WAIT_1;
- **FIN_WAIT_1 -\> FIN_WAIT_2**客户端收到服务器对结束报文段的确认,则进入 FIN_WAIT_2,开始等待服务器的结束报文段;
- **FIN_WAIT_2 -\> TIME_WAIT**客户端收到服务器发来的结束报文段,进入 TIME_WAIT,并发出 LAST_ACK;
- **TIME_WAIT -\> CLOSED**客户端要等待一个2MSL(Max Segment Life,报文最大生存时间)的时间,才会进入 CLOSED 状态
三次握手
客户端connect主动发起连接进行三次握手,这个过程是由操作系统自动完成的
- 首先客户端和服务端都处于CLOSE状态。
- 服务端先进行LISTEN,监听某个窗口,客户端发送SYN请求建立连接,同时发送一个初始序号client_isn,客户端进入SYS_SENT状态。
- 服务端接收到请求后,发送SYN请求给客户端,并且确认接收到客户端请求,服务端初始化自己的序号server_isn,并且确认序号填上client_isn+1,随后服务端进入SYN_RCVD状态。
- 客户端接收到服务端连接信息后,回复服务端,并且确认序号填上server_isn+1,服务端进入ESTABLISHED状态,服务端接收到客户端确认后,进入ESTABLISHED状态。
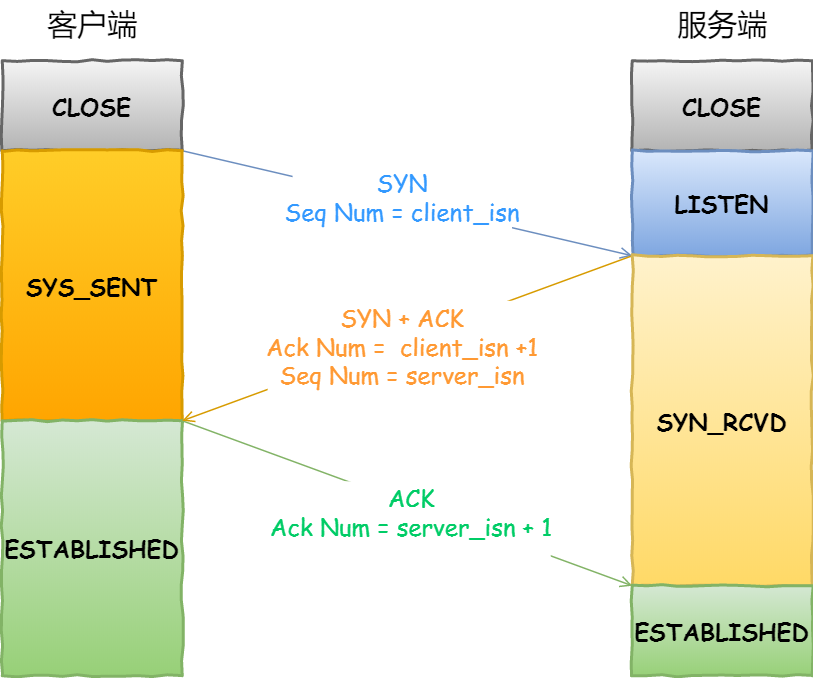
三次握手完成后,就可以进行相互发送数据了。
三次握手的作用
TCP通过三次握手,建立管理连接的数据结构------TCP连接各种机制的基础,保证了TCP连接的可靠性
如果服务端不调用accept,三次握手建立连接能够成功吗?
能够成功。
在TCP协议中,三次握手是由操作系统内核的TCP协议栈完成的,而不是由应用程序控制的。因此,当客户端发送SYN报文段到达服务器时,服务器内核会自动回复SYN-ACK,并在收到客户端的ACK后完成三次握手。此时,连接已经建立,并被放入服务器的监听套接字的连接队列(accept queue)中。
所以,即使服务端应用程序没有调用accept,三次握手仍然可以成功完成。但是,如果服务端一直不调用accept,那么已经建立的连接会一直停留在连接队列中。当连接队列满了之后,服务器内核可能会开始拒绝新的连接请求。
如果服务端并未收到第三次握手发送的 ACK 报文,会怎样处理?
三次握手不是一定成功的,也可能发生丢包。由于前两个报文有对应的应答,如果丢包会触发重传,所以我们重点讨论没有应答的第三个报文丢失:
- 超时重传 :而对于服务端来说,ACK报文是SYN+ACK报文的应答,如果没有收到,就会触发超时重传机制,等待 3 秒、6 秒、12 秒后重新发送 SYN+ACK 包,以便客户端重新发送 ACK 包
- 重置连接 :客户端在接收到 SYN+ACK 包后,就认为TCP连接已经建立,并且无法知道ACK包是否丢失,所以会正常发送数据。但是服务端收到客户端的数据后,会以 RST 包响应,用于重置TCP连接
一次握手为什么不行?
理由一:不能防止单一客户端的SYN洪水攻击
假设一次握手就能建立连接,客户端发出SYN后,客户端建立连接,服务端收到数据直接建立连接。但是假如客户端发出SYN后,并没有在系统中建立相关的数据结构,也就没有建立连接;而服务端收到SYN后会直接建立连接,维护着一个套接字,占用系统资源。
如果客户端频繁向服务端发起连接申请请求,服务端会为其建立连接,但客户端自己不建立连接。此时服务端的系统资源很快就会被占用完,服务端也就崩溃了,这种现象被叫做SYN洪水。
所以,假设一次握手就能建立连接,服务器很容易被单一客户端的SYN洪水攻击,从而崩溃。
理由二:不能验证全双工通信能力
客户端发送SYN,服务器收到,服务器只能确认:客户端的发送能力是正常的。
两次握手为什么不行?
假设两次握手就能建立连接, 客户端向服务端发起建立连接的请求,服务端收到后直接建立连接,并给客户端发送了ACK应答+SYN连接请求,让客户端也建立连接。但如果客户端在 收到服务端的数据后选择不建立连接 或 直接丢弃数据 ,同样容易遭受单一客户端的SYN洪水攻击。
同时,两次握手也不能验证全双工通信能力。
为什么是三次握手?
理由一:以最小成本,确认双方通信意愿,防止单一客户端的SYN洪水攻击
- 客户端 → 服务器:SYN(请求建立连接)
- 服务器 → 客户端:SYN-ACK(确认客户端的请求SYN,并发送自己的请求SYN)
- 客户端 → 服务器:ACK(确认服务器的请求SYN)
这确认了双方通信意愿,确保了客户端先建立连接,服务器后建立连接,避免了服务器单方面建立连接的资源浪费。
三次握手可以有效防止单一客户端向服务端发起SYN洪水攻击:
通过三次握手进行SYN洪水攻击,需要客户端先建立连接。而常规服务器的配置往往比客户端高,可用的资源也更多,所以客户端往往耗不过服务端,自己先崩溃了。但是,不法分子可以制造木马,植入多个计算机(肉鸡),使同一时间多个客户端向服务端发起SYN洪水攻击,服务器也会崩溃。
所以说,三次握手只负责建立连接,不能保证连接的安全性。
理由二:以最短的方式,验证全双工通信能力
TCP是面向连接、全双工(Full-duplex)的协议,即双方可以同时发送和接收数据。
三次握手的本质是验证:"我们两个所处的网络是通畅的,能够支持全双工!"
- 第一次握手:客户端发送SYN,服务器收到。这样服务器就能确认:客户端的发送能力是正常的,验证了客户端→服务器路径通畅。
- 第二次握手:服务器发送SYN+ACK,客户端收到。这样客户端就能确认:服务器的接收和发送能力都是正常的,验证了服务器→客户端路径通畅(同时确认服务器愿连接)。
- 第三次握手:客户端发送ACK,服务器收到。这样服务器就能确认:客户端的接收能力是正常的,再次验证了客户端→服务器路径通畅(并确认客户端收到服务器响应)。
通过三次握手,双方都确认了彼此的发送和接收能力正常,从而确保了全双工通信。
三次握手本质上是四次握手
实际上,如果将三次握手拆分,那么就是:
- 客户端 -> 服务器:SYN
- 服务器 -> 客户端:ACK(对客户端SYN的确认)
- 服务器 -> 客户端:SYN(服务器自己的序列号)
- 客户端 -> 服务器:ACK(对服务器SYN的确认)
但是,中间两次(服务器对客户端SYN的确认ACK和服务器发送的请求SYN)可以合并为一次(可以理解为捎带应答),所以就成了三次。
所以三次握手本质上就是四次握手,不过第二次将中间两次合并为一次是以最小成本来验证全双工通信。
四次挥手
通信双方都调用close主动关闭连接进行四次挥手
这里以客户端先断开连接为例: (当一方发送FIN,表示它不再发送数据,但还能接收数据)
- 客户端发送关闭连接请求,将FIN置为1,客户端进入FIN_WAIT_1状态(客户端不再发送数据,可以接收数据)
- 服务端接收到报文向客户端发送ACK确认收到,服务端进入CLOSED_WAIT状态(服务端等待应用层处理,发送剩余数据或处理其他任务)
- 客户端收到ACK报文后进入FIN_WAIT_2状态(客户端接收剩余数据,等待服务端发送关闭)
- 服务端处理完数据后,向客户端发送FIN报文,服务端进入LAST_ACK状态(服务器不再发送数据,可以接收数据)
- 客户端接收到FIN报文后,向服务端发送确认ACK收到报文,并且进入TIME_WAIT状态(等待服务端确认收到ACK),在2MSL后完成关闭连接(客户端不再接收数据)
- 服务端接收到ACK报文后进入CLOSE状态完成关闭连接(服务端不再接收数据)
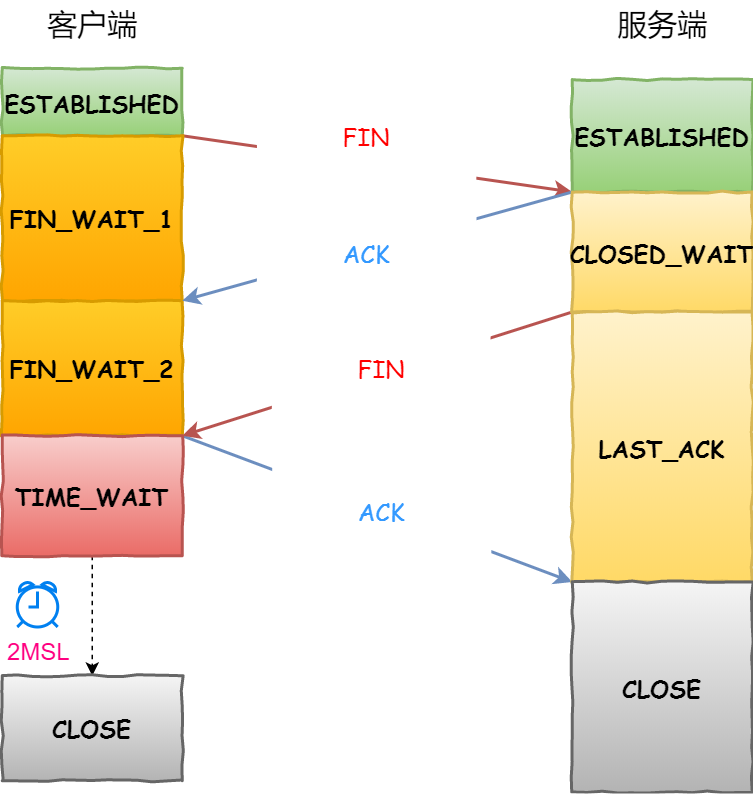
断开连接的一方发送FIN后,最后怎么还能发送ACK应答?
当一方发送FIN,表示它不再发送应用层的数据,而在底层双方可以有管理报文的交互。
CLOSE_WAIT 状态
被动断开连接的一方,接收对方的FIN发送ACK后(两次挥手完成),会进入CLOSE_WAIT状态。
被动关闭方已知对方不会再发送数据,但被动关闭方当前可能还有未发送的数据。所以,需要等待上层应用层进行close()调用,明确不会再传输数据到发送缓冲区后,才会发送FIN。若应用层长时间未调用close(),会导致CLOSE_WAIT状态的连接长期占用系统资源(如文件描述符、端口),最终可能引发 "too many open files" 等错误,导致新连接无法建立。
服务器出现大量CLOSE_WAIT状态的连接的可能原因:
- 服务器有bug,没有调用close
- 服务器繁忙,一直在推送消息给客户端,没来得及调用close
TIME_WAIT 状态
MSL是TCP报文段在网络中允许存在的最大时间,也可以理解为报文从发送方到接收方的最长时间。
主动断开连接的一方,接收对方的FIN发送ACK后(四次挥手完成),进入TIME_WAIT状态。
在确认断开连接后,为什么客户端还要等待2MSL的时间才进入CLOSE状态?(假设客户端主动断开连接)
理由一:尽可能保证最后一个ACK应答被服务端收到
如果第四次挥手的ACK应答报文丢失,未被服务器接收到,服务器就会重传FIN;收到重传的FIN后,客户端再补发ACK应答。而从客户端第一次发出ACK到再次收到服务端的FIN,刚好是两个MSL周期。
理由二:保证网络中的滞留报文消散
在断开连接时,可能因为网络原因,网络中还有服务端发送给客户端的报文未被接收。若客户端直接进入CLOSE状态,这些滞留的数据就无法被接收。
查看MSL的值:
bash
cat /proc/sys/net/ipv4/tcp_fin_timeout
为什么服务器关闭后,无法使用相同端口号立即重启?
在平常测试时,如果直接关闭服务器(服务器主动关闭连接),那么服务器会维持TIME_WAIT状态一段时间, 原来的端口号仍然被占用,所以,短时间内服务器 绑定相同端口号 就会绑定失败。而如果是客户端主动关闭连接,服务器就可以短时间内使用相同端口号。
解决TIME_WAIT状态引起的bind失败的方法
在服务器的 TCP 连接没有完全断开之前不允许重新监听,某些情况下可能是不合理的
- 服务器需要处理非常大量的客户端的连接(每个连接的生存时间可能很短,但是每秒都有很大数量的客户端来请求)
- 这个时候如果由服务器端主动关闭连接(比如某些客户端不活跃,就需要被服务器端主动清理掉),就会产生大量 TIME_WAIT 连接
- 由于我们的请求量很大,就可能导致 TIME_WAIT 的连接数很多,每个连接都会占用一个通信五元组(源ip、源端口、目的ip、目的端口、协议)
- 如果新来的客户端连接的ip和端口号和 TIME_WAIT 占用的连接重复,就无法绑定,这是不合理的
使用 setsockopt ()设置 socket 描述符的选项 SO_REUSEADDR为1 ,表示允许创建端口号相同但IP地址不同的多个 socket 描述符
断开连接为什么要四次挥手?不能合并为三次挥手吗?

建立连接时,服务器在收到客户端的SYN后,可以将自己的SYN和ACK放在同一个报文中发送,因此可以三次握手。而断开连接时,TCP连接是全双工的,每个方向都必须单独关闭。当一方发送FIN,表示它不再发送数据,但还能接收数据。
四次挥手的过程(假设客户端先发起关闭):
- 客户端发送FIN,进入FIN_WAIT_1状态,表示客户端没有数据要发送了。
- 服务器收到FIN,发送ACK,进入CLOSE_WAIT状态。客户端收到ACK后进入FIN_WAIT_2状态。此时,客户端到服务器的连接关闭,但服务器到客户端的连接还可以传输数据。
- 服务器发送完剩余数据后,发送FIN,进入LAST_ACK状态。
- 客户端收到FIN,发送ACK,进入TIME_WAIT状态,服务器收到ACK后关闭连接。
为什么不能合并为三次?
因为服务器在收到客户端的FIN时,可能还有数据要发送,不能立即发送FIN。所以先发送ACK,等数据发送完毕后再发送FIN。因此,ACK和FIN不能像握手那样合并发送。
但是,如果服务器在收到FIN时,没有数据要发送,那么服务器是否可以将ACK和FIN合并呢?
理论上是可以的,但TCP协议设计时为了可靠,并没有这样做。因为TCP规范要求每个FIN必须单独确认,所以即使没有数据,也要分开两个步骤。
不过,在实际中,有时确实可以看到三次挥手,即服务器的ACK和FIN合并,但这不是标准行为,依赖于实现。
4.流量控制
接收端处理数据的速度是有限的,如果发送端发的太快,导致接收端的缓冲区被填满。这个时候,如果发送端继续发送,就会造成丢包,进而引起丢包重传等等一系列连锁反应。
所以,TCP需要根据接收端的处理能力,来决定发送端的发送速度, 这个机制就叫做流量控制(Flow Control):
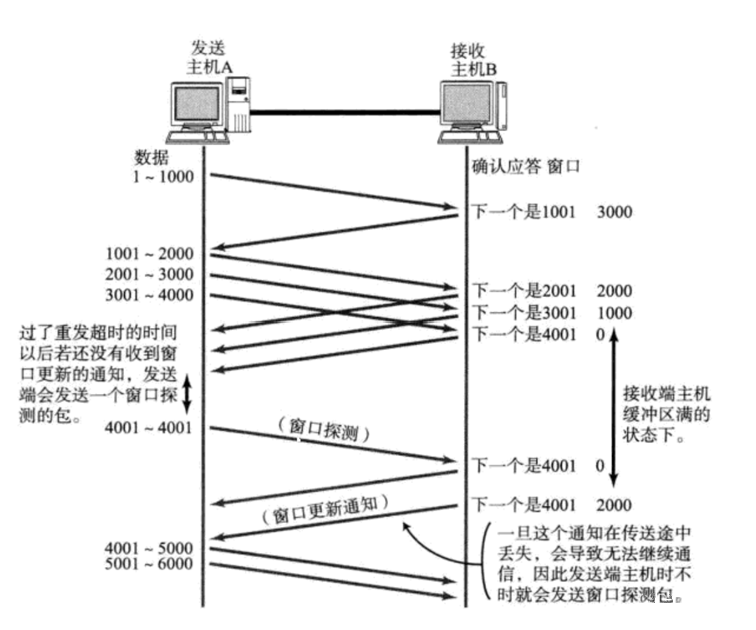
- 在接收端的应答报文中,报头中"窗口大小"字段会填入当前接收缓冲区的剩余空间大小
- 发送端接收报文后,会根据"窗口大小"调整发送速度
- 如果接收端缓冲区满了,就会将窗口大小置为0。这时发送方就不再发送数据,但会定期发送一个窗口探测 ,使接收端把窗口大小告诉发送端;同时,如果窗口大小更新,接收端也会主动发送窗口更新通知。
发送方如何在正式通信之前,得知接收缓冲区的大小?
在正式通信之前,通过三次握手,通信双方交换了窗口大小,使发送方第一个报文的大小合适
TCP首部中窗口大小字段只有16位,那么TCP窗口最大就是2^16-1字节吗?
实际上,TCP首部40字节选项中还包含了一个窗口扩大因子M,实际窗口大小是 窗口字段的值左移M位。
5.滑动窗口
滑动窗口的本质:流量控制的具体实现方案
滑动窗口的概念
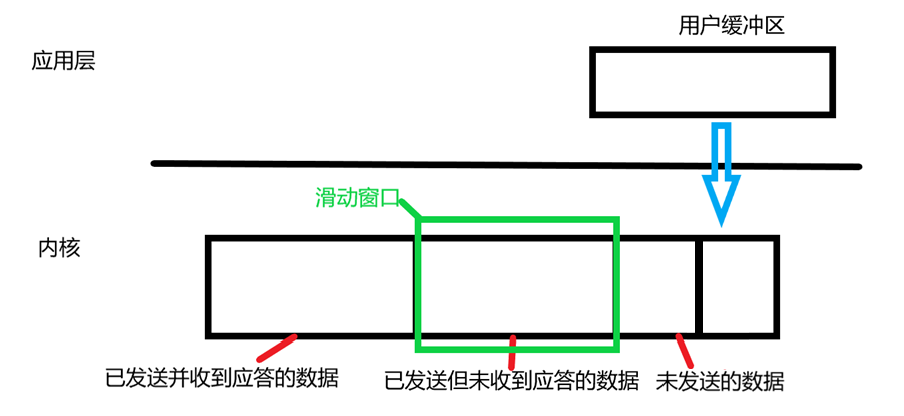
发送缓冲区中的数据可以分为:已发送并收到ACK应答的数据、已发送但未收到ACK应答的数据、还未发送的数据。
- 对于第一种而言,发送方已经能确定该报文被对方接收,所以这部分数据已经没有存在的必要了。当新数据被拷贝进缓冲区后,这部分数据会被新数据覆盖。
- 对于第二种而言,发送方虽然发送了数据,但是不知道该数据对方有没有接收到。所以这些数据还需要保留,以支持TCP进行超时重传。
- 对于第三种而言,数据还没发送,等待被处理。
**滑动窗口是发送缓冲区的一部分,其中都是已发送但未收到应答的数据。**通过不断发送数据,已发送并收到应答的数据增多,未发送的数据减少,窗口就会向右滑动,所以称为滑动窗口。
滑动窗口的大小就是发送方一次可以发送的最大数据量,与接收方的接收缓冲区的剩余大小有关,其通过报头中的窗口大小传递给发送方。
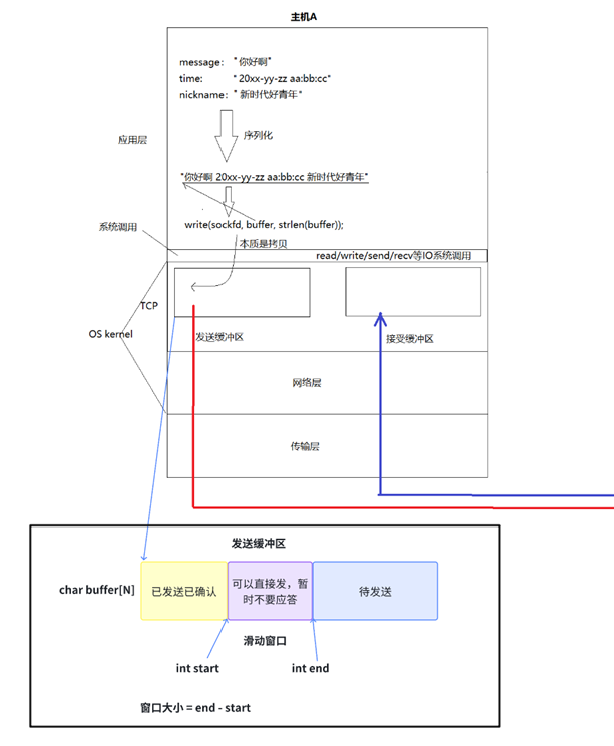
发送缓冲区的构造
发送缓冲区分为四部分,从左向右序列号依次增大:已发送并收到应答数据的空间、已发送但未收到应答数据的空间,未发送数据的空间,没有任何数据的空间
- 已发送已确认数据的空间,不需要刻意去清空,让新放入的数据覆盖即可
- 已发送但未收到应答数据的空间就是滑动窗口
- 未发送数据的空间后续会逐渐进入滑动窗口范围中
- 没有任何数据的空间用于接收用户缓冲区中的数据
滑动窗口的数据结构
先将"发送缓冲区"理解为一个char类型的数组(char bufferN),数组下标start和end明确"滑动窗口"范围,窗口滑动的滑动本质就是start和end下标增加
滑动窗口大小 = end - start,即窗口右边界减去左边界。
实际上,发送缓冲区是用数组构造的环形队列,空间可重复利用。
窗口移动机制
窗口移动本质上是下标start和end更新:
- 当接收方成功接收部分数据后,会发送应答ACK,报头中包含TCP确认号(期望接收的下一个序列号)和窗口大小
- start = 收到的TCP确认号,end = start + win(滑动窗口大小)
- start不变/增大------滑动窗口的左边界不变/向右移动,end不变/增大------滑动窗口的右边界不变/向右移动
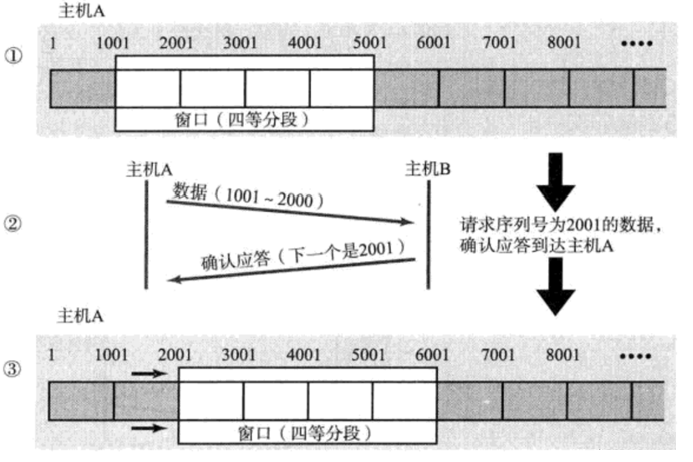
滑动窗口可以向左滑动吗?
❌ 不可以向左滑动!
滑动窗口只能向右滑动,不能向左滑动。
原因:
- 在发送缓冲区中,从左到右序列号是严格递增的
- 当滑动窗口中的数据被确认,这部分数据就不再需要重传,左边界(start)会根据应答报头中的TCP确认号("已发送且已确认"的数据的下一个序列号)向右滑动,释放缓冲区空间。
滑动窗口的工作示例
假设发送方需要发送300字节的数据,并且每个数据包大小为100字节:
- 发送方首先发送三个100字节的数据包(序号1-100、101-200、201-300)。
- 接收方收到第一个数据包(序号1-100),并返回ACK(ack=101),表示它准备接收序号101的下一个字节。
- 发送方收到ACK后,滑动窗口会向前滑动,继续发送剩余数据包。
滑动窗口的大小
窗口大小是浮动的,与接收方缓冲区的空闲空间的大小有关。
在通信双方三次握手 建立连接的过程中,接收方会携带一个window size(窗口大小)字段,告知发送方自己的接收能力,从而让发送方设置初始滑动窗口的大小
正式通信时 ,接收方的ACK确认报文都会携带一个window size(窗口大小)字段,告知发送方自己当前还能接收多少数据,发送方根据这个值动态调整滑动窗口大小。
滑动窗口可以变大吗?可以变小吗?可以不变吗?可以为0吗?
注:win值为TCP报头中的窗口大小值
✅ 可以变大!
条件:
- 接收方缓冲区的空闲空间变大 → 通过ACK报文通告一个更大的win值。
- 发送方收到该ACK后,增大窗口大小(end-start增大)。
示例:
- 初始窗口大小 = 1000
- 接收方处理完部分数据,空闲空间增加 → 通告 win=2000
- 发送方更新窗口 → 新窗口大小 = 2000
✅ 可以变小!条件:
- 接收方缓冲区快满了 → 通过ACK报文通告更小的win值。
- 发送方收到后,减小窗口大小(end-start减小)。
示例:
- 当前窗口大小 = 1000
- 接收方通告 win=500
- 发送方调整窗口 → 新窗口大小 = 500
⚠️ 这种行为称为"窗口缩放",用于防止接收方溢出。
✅ 可以不变!当接收方通告的窗口大小没有变化时,滑动窗口大小保持不变。
场景:
- 接收方处理速度稳定,缓冲区占用率稳定。
- 发送方持续发送数据,但每次收到的ACK中win值相同。
- 窗口只是"滑动",但大小不变。
✅ 可以为0!意义:
- 当接收方缓冲区完全满时,会通告 win=0。
行为:
- 发送方停止发送数据,进入"零窗口等待状态",但会定期发送窗口探测报文(Window Probe)以询问接收方窗口是否打开
- 接收方缓冲区出现剩余空间,接收端也会主动发送窗口更新通知报文。
处理丢包问题
如果某个数据包丢失,接收方不会确认丢失的数据包,而是继续确认已收到的数据。发送方会根据丢失数据包的ACK缺失情况触发超时重传机制,重新发送丢失的数据包。
1. 正常情况下滑动窗口的工作
应答ACK报头中,如果确认号为X+1,表示X+1之前的所有数据全都收到了,下一个期望字节的确认号为X+1。
假设发送方发送了多个数据包,每个数据包的序列号分别为1-100,101-200,201-300。接收方收到1-100、101-200、201-300的数据段后,会分别确认接收到的数据,返回ACK=101、ACK=201、ACK=301。
在这个过程中滑动窗口的变化:
- 发送方发出数据后未收到应答前,滑动窗口不发生变化
- 收到ACK=101后,滑动窗口的左边界start由1变为101
- 收到ACK=201后,滑动窗口的左边界start由101变为201
- 收到ACK=301后,滑动窗口的左边界start由201变为301
- 滑动窗口的大小始终与最新的应答报头中的窗口大小相关
2. 丢包的情况
假设发送方发送了多个数据包,如下所示:
- 第一个数据包:1到100
- 第二个数据包:101到200
- 第三个数据包:201到300
假设第二个数据包(序号101到200)丢失了,其他数据包正常接收。
3. 接收方的行为
接收方不会丢弃已经收到的数据,而是会将它们存储在接收缓冲区中,等待丢失的数据包的到来。
接收方在确认数据时会发送一个重复的ACK,指示它仍然在等待丢失的数据包。
此时,接收方已成功接收了序号为1到100和201到300的数据,但不会对序号为201到300的数据段发送确认,返回两次重复的ACK=101。
4. 发送方的行为
发送方的行为流程:
- 发送方已经发送了序号1到300的三个数据包,但它只收到了两个ACK=101 ,继续等待应到的报文ACK=201,不会立即重传。
- 等待ACK=201的时长超出特定时长,触发超时重传机制,并重新发送101到200的丢失数据包。
- 一旦发送方重新发送了丢失的数据包(序号101到200),接收方就会再次确认并返回ACK=301,表示它已经成功接收到序号为1到300的数据。
在这个过程中滑动窗口的变化:
- 发送方发出数据后未收到应答前,滑动窗口不发生变化
- 收到第一个ACK=101后,滑动窗口的左边界start由1变为101
- 收到第二个ACK=101后,滑动窗口的左边界不发生变化
- 触发超时重传机制,发送方重传101到200的数据包,滑动窗口不发生变化
- 收到ACK=301后,滑动窗口的左边界start由101变为301
- 滑动窗口的大小始终与最新的应答报头中的窗口大小相关
5. TCP的快速重传(Fast Retransmit)
如果发送方连续收到3个重复的ACK (即重复ACK的次数大于等于3次),它会立即触发快速重传(Fast Retransmit),而不等待超时。
快速重传的目的是尽早发现丢包并尽快恢复数据的传输。
快速重传的过程:
在我们的例子中,如果发送方连续收到3个ACK=101的报文(即接收方重复确认它已经接收到的部分数据),发送方就会立即重传丢失的序号101到200的数据段,而不需要等待超时。
通过快速重传,发送方可以减少丢包造成的延迟,提高数据传输的效率。
6. 滑动窗口中的丢包与流量控制的关系
**丢包不仅影响数据的传输速度,还与TCP的流量控制机制密切相关。**发送方根据滑动窗口大小来决定是否可以继续发送数据。如果接收方的缓冲区已经满了,它会通过返回一个窗口大小为0的ACK报文,发送方的滑动窗口大小变为0,暂停发送数据。直到接收方有足够的空间继续接收数据,发送方的滑动窗口重新变大,开始发送数据。
如果发生丢包,发送方没有收到对应的应答,滑动窗口会保持不变,直到丢失的数据包被重新发送并成功确认。
7.总结
滑动窗口中的丢包处理是TCP协议确保可靠传输的重要机制之一。通过接收方发送重复ACK和发送方进行超时重传或快速重传,TCP能够有效地恢复丢失的数据,并确保数据按顺序正确到达接收方。
在滑动窗口协议中,丢包的发生并不会导致整个连接的中断,而是通过这种可靠的重传机制和滑动窗口的控制,保证数据最终能够完整并有序地传输。
序列号的作用总结
- 标识数据顺序: 接收方可以根据序列号将乱序到达的数据包重新排序,组装成正确的数据流
- 消除重复数据: 如果接收到相同序列号的数据,接收方可以识别并丢弃重复的数据包
- 作为确认的依据: 确认应答ACK正是基于序列号来告知发送方"我已经收到哪个数据了"
- 支持滑动窗口:滑动窗口正是基于序列号来制定滑动规则
6.拥塞控制
由于网络中同时会有大量主机发送消息,网络也可能发生拥堵,导致了丢包问题。
拥塞控制的概念
网络拥堵的情况下,在刚开始阶段就贸然发送大量的数据是雪上加霜的。为了根据实际的网络情况动态的控制发送数据量大小,于是就引入了拥塞机制。
为了在发送方调节发送的数据量,引入了拥塞窗口 cwnd,会根据网络状况动态的变化:
- 当网络拥塞时该值变小
- 当网络畅通时该值变大
**发送窗口swnd = min(拥塞窗口cwnd,接收窗口rwnd),**也就是两者取最小值
- swnd(发送方):发送方缓冲区中滑动窗口的大小,发送方一次性发送数据量的大小
- cwnd(网络):拥塞窗口
- rwnd(接收方):接收方缓冲区中剩余空间大小,接收方给发送方的应答报头中窗口大小的值
拥塞控制是TCP尽可能快地将数据传输给对方,又要避免给网络造成太大压力的折中方案。
拥塞控制的算法
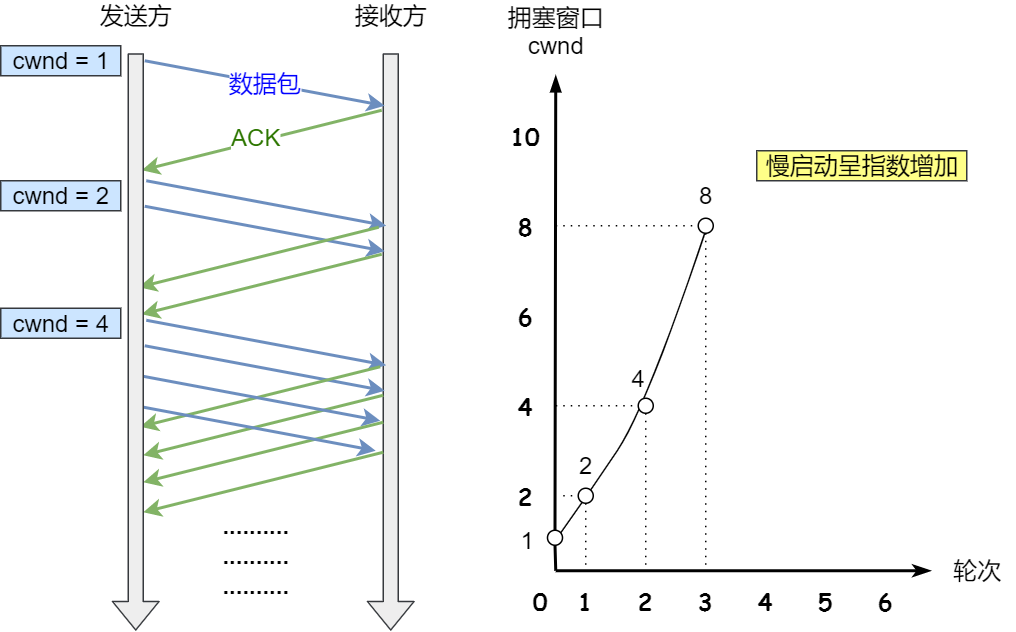
1.慢启动
在刚开始时,由于不清楚网络情况,需要一点一点的发送数据进行测试(探路过程) ,然后拥塞窗口大小再以指数倍进行增长。慢启动只是意味着最初发送的数据较少,但提高发送数据量的速度很快。
- 初始时 拥塞窗口cwnd = 1
- 在收到第一个ACK应答后,cwnd增加1
- 在收到第二个ACK应答后,cwnd增加到4
- 以此类推,指数倍进行增长......
2. 拥塞避免算法
但是拥塞窗口大小一直指数增长并不合理,所以我们要及时调整。
引入慢启动门限ssthresh ,当拥塞窗口大于这个值时就线性增长,减缓速度;小于这个值时继续以指数增长:
- 当cwnd<=ssthresh时,启用慢启动算法
- 当cwnd>ssthresh时,启用拥塞避免算法
当进入拥塞避免算法后,每收到一个ACK,cwnd就增加1,慢慢地进行线性增长。
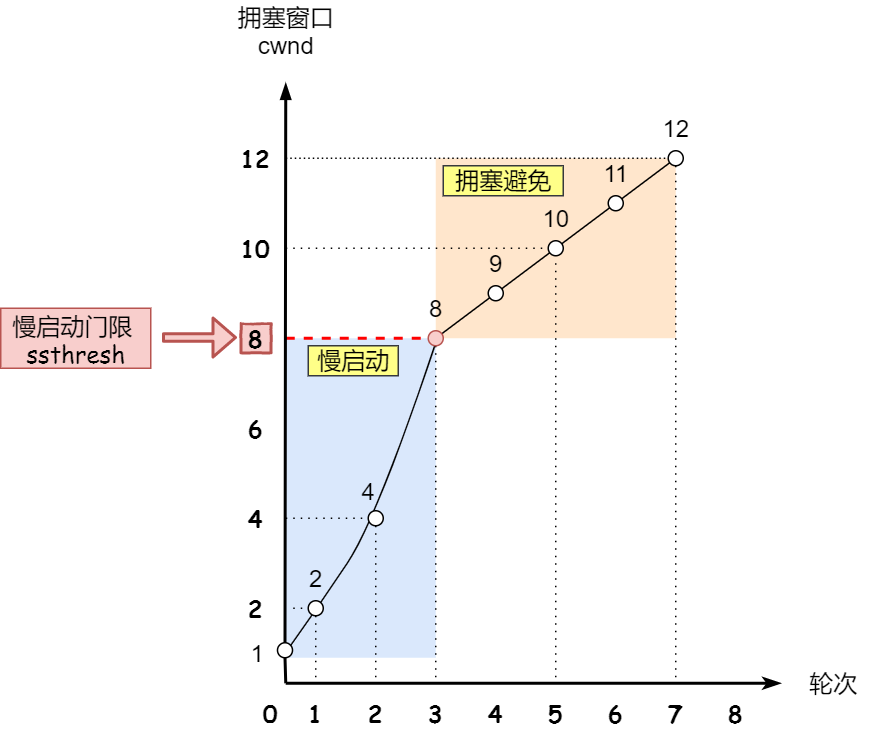
3. 拥塞发生算法
- 少量丢包时,仅仅触发超时重传
- 大量丢包时,就认为网络拥塞,会触发重传并进入拥塞发生算法
重传有两种机制:超时重传和快速重传。当网络拥塞发生,触发超时重传时,拥塞控制算法会将 ssthresh 设为 cwnd/2(不小于2) ,然后将 cwnd 设置为1,重新进行慢启动。
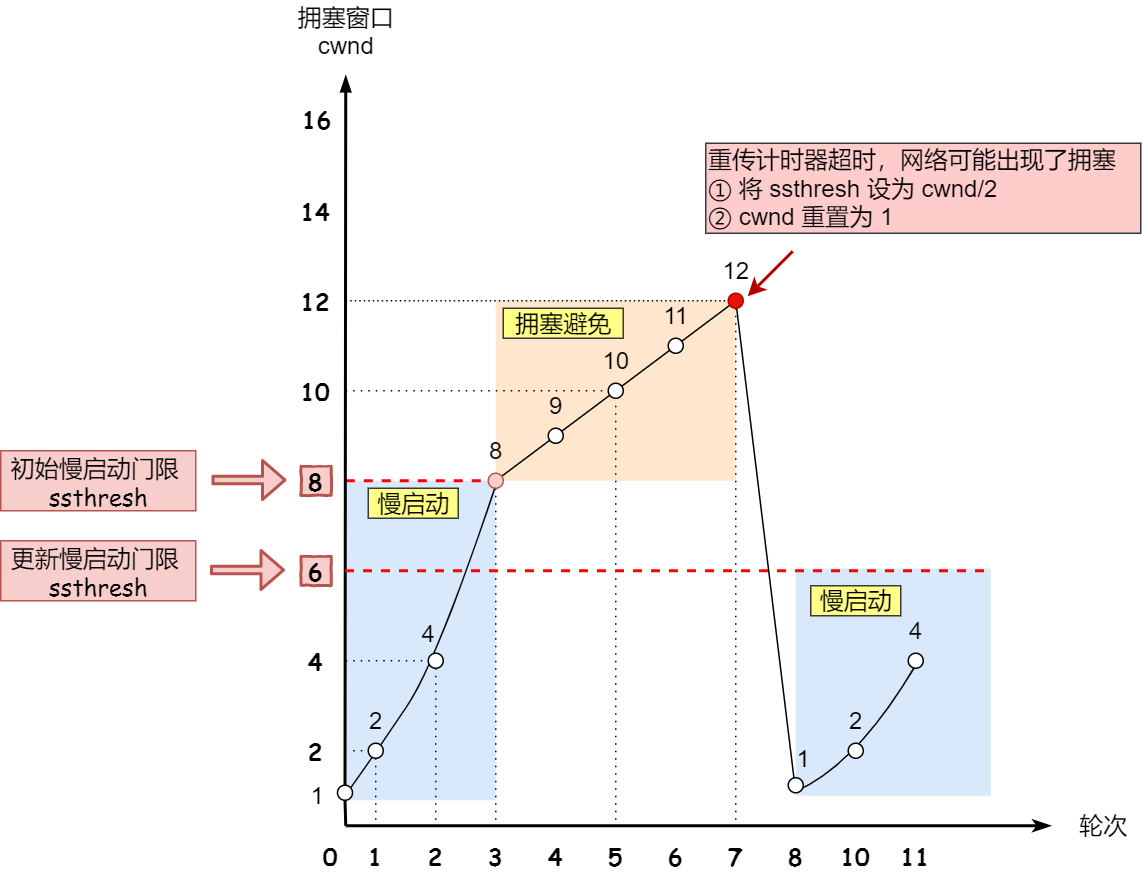
4. 快速恢复
拥塞发生算法会导致数据传输的波动较大,容易造成网络卡顿,于是有了快速恢复算法
触发快速重传时,通常使用快速恢复算法,发送方能接收到三份同样的ACK报文,说明当前网络状态是不错的。
算法流程如下:
- 收到第3个重复的ACK时,将ssthresh设置为当前cwnd的一半。
- 设置cwnd=ssthresh+3
- 重传丢失的报文段
- 每收到一个重复的ACK,cwnd+1
- 确认新数据的ACK到达时,设置cwnd=ssthresh。
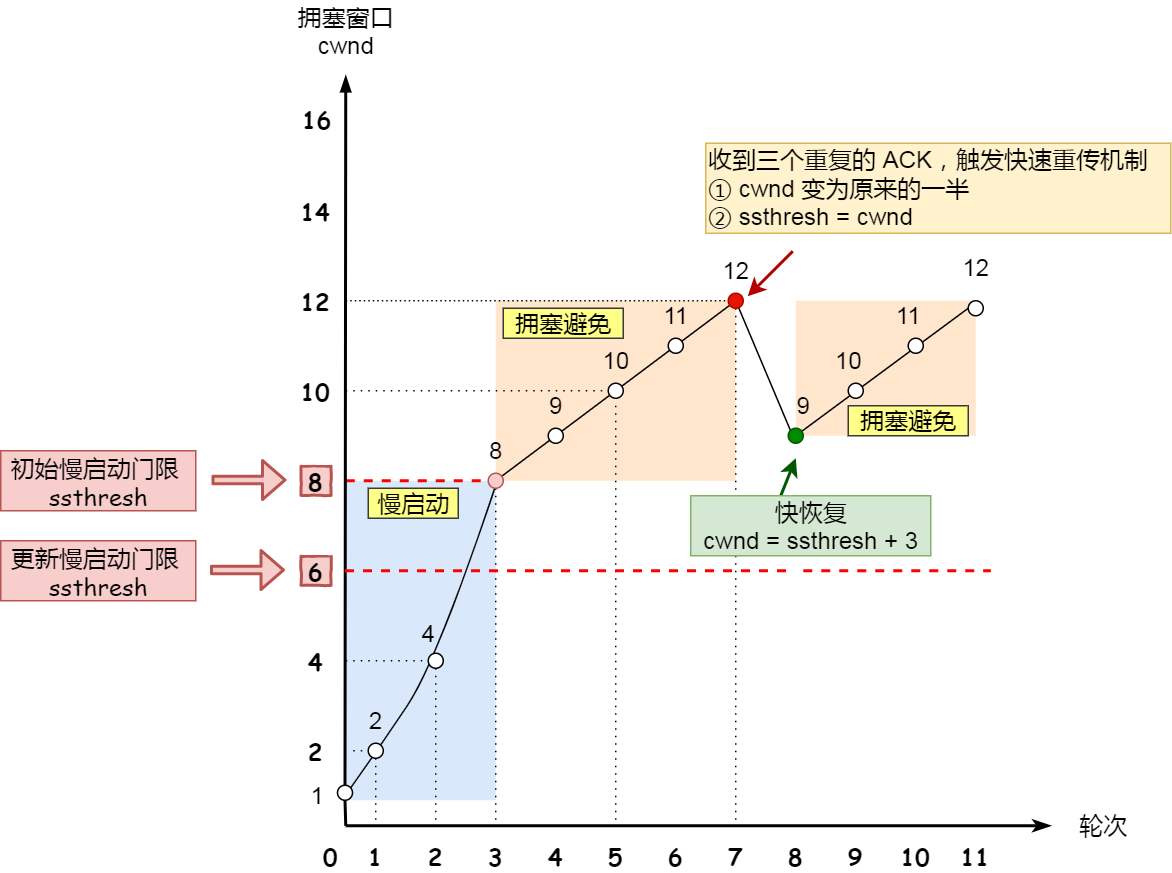
7. 延迟应答和捎带应答
延迟应答
延迟应答 是一种提高传输效率的机制。接收方在接受到数据后不会立即回应发送方,而是等待一段时间再回复,增加接收方缓冲区的剩余空间,从而能够返回一个更大的窗口值。 同时,隔几个包才进行应答,也可以减少应答数据包的数量。
举例说明:
- 假设接收端缓冲区为1M,一次收到了500K的数据;如果立刻应答,返回的窗口就是500K
- 但实际上可能处理端处理的速度很快,10ms之内就把500K数据从缓冲区消费掉了
- 在这种情况下,接收端处理还远没有达到自己的极限,即使窗口再放大一些,也能处理过来
- 如果接收端稍微等一会再应答,比如等待200ms再应答,那么这个时候返回的窗口大小就是1M
窗口越大,网络吞吐量就越大,传输效率就越高,我们的目标是在保证网络不拥塞的情况下尽量提高传输效率。
不是所有的包都可以延迟应答的:
- 数量限制:每隔N个包就必须应答一次
- 时间限制:超过最大延迟时间就必须应答一次
具体的数量和超时时间,依操作系统不同也有差异,一般N取2,超时时间取200ms。
不一定每个报文都有应答,确认序号提供了支持:
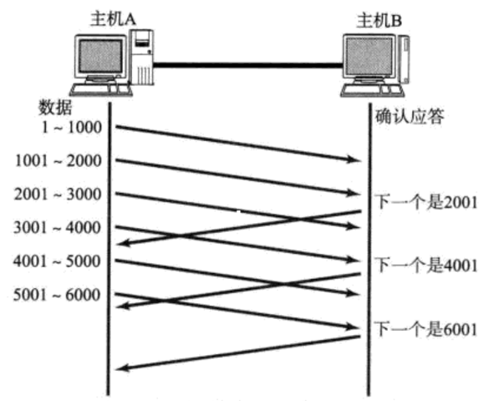
捎带应答
通信时一般不会单独发送ACK确认报文。而是在接收方给发送方回复消息时,消息本身作为有效载荷,标志位ACK置为1并填入确认序号,将ACK确认报文捎带传回。
例如:客户端给服务器说了 "How are you",服务器也会给客户端回一个 "Fine, thank you"。那么这个时候ACK就可以搭顺风车,和服务器回应的 "Fine, thank you" 一起回给客户端
三、补充知识
1.面向字节流和粘包问题
面向字节流
在TCP中,数据是以字节流的形式进行传输的,TCP不关心字节流的内容,它只会按顺序将这些字节流从发送方传输到接收方。具体来说:
- **发送缓冲区:**当你调用write()函数写数据时,数据会进入TCP的发送缓冲区。如果缓冲区已满,write()会阻塞,直到缓冲区有足够空间。
- **接收缓冲区:**接收到的数据存放在接收缓冲区,调用read()时会读取这些数据。如果接收缓冲区为空,read()会阻塞,直到数据到达。
TCP会根据窗口大小 、拥塞控制 和流量控制 等因素来动态调整数据的发送量,数据可能会被拆分成多个包发送,也可能会被合并在一起。
面向字节流的关键点:
- TCP看不出数据的边界,只会按顺序传递字节流。
- 你写100个字节的数据,可以通过1次write或者100次write来完成;同样的,读取100个字节的数据也可以通过1次read或者多次read来完成。
粘包问题
粘包问题发生在应用层,它通常是因为TCP作为面向字节流的协议,并不知道应用层的数据包的边界。结果,发送的多个数据包可能会被接收方合并成一个数据包,或者一个数据包被拆成多个部分。
**原因:**TCP在传输时只是简单地发送字节流,没有像UDP那样有"报文长度"的字段,因此接收方无法准确区分数据包的边界。
解决办法:明确两个包之间的边界
- **定长包:**可以使用固定长度的包,每次都按固定大小读取
- **变长包:**在包头约定包的总长度,接收方通过读取包头的长度信息,来确定包的边界。比如,HTTP协议中的Content-Length字段
- **分隔符:**为每个包定义一个明确的分隔符,接收方根据分隔符来解析数据包
**UDP没有粘包问题:**因为UDP是面向报文的协议,每个数据包是独立的,UDP不会拆分或合并数据包。它只是简单地将数据包从源端传输到目的端。
- 在UDP报头中有16位UDP长度,由于报头是定长的,能够算出有效载荷的长度,将数据包一个一个地传输给应用层
- 在TCP报头中有4位首部长度,只能够算出报头的长度,不能算出有效载荷的长度,只能直接将数据包交给应用层,由应用层分离
2.TCP连接异常问题
TCP连接过程中可能会出现各种异常,以下是常见的几种情况:
连接建立异常:
- 客户端发送SYN包后没有收到服务端的SYN+ACK,可能是网络不通或服务端未监听该端口。
- 服务端拒绝连接,可能是服务端未启动或端口已关闭。
连接断开异常:
- 客户端或服务端发送FIN包后未收到对方的ACK包,可能是网络不稳定或对方宕机。
- 如果连接已断开,服务端或客户端重新启动后可能会遇到连接建立失败的问题。
传输数据异常:
- 数据丢失、乱序、重复、校验和错误等都可能导致数据传输异常,通常通过超时重传、滑动窗口等机制进行修复。
客户端掉线:
- 当客户端掉线时,服务器端可能在短时间内不会知道客户端已掉线,连接会一直保持。TCP会使用心跳机制(基于保活定时器)来检查客户端是否还在线,如果多次未收到ACK,服务器会关闭连接。
3.listen函数的第二个参数
listen系统调用原型
cpp#include<sys/socket.h> int listen(int sockfd, int backlog);**功能:**设置该文件描述符为监听状态
参数:
- int sockfd表示之前使用socket()返回的文件描述符sockfd
- int backlog表示全连接队列的长度
**返回值:**成功返回一个用于通信的文件描述符,失败返回-1并设置错误码errno
全链接队列
TCP维护了一个全连接队列,存储状态为 ESTABLISHED 的 TCP 连接,这些连接已通过三次握手,但未由服务器应用层处理(即未调用 accept())。
作用:
当服务器应用层繁忙无法及时处理连接时,全连接队列临时存储这些连接。当资源空闲时,这些连接能被立刻使用。
- 由于系统资源是有限的,系统最多只能维护一定数量的通信套接字。
- 而通信套接字使用完毕后,对应的系统资源就会被释放,处于空闲状态。
- 此时,应用层调用accept(),队列中的连接不需要再进行三次握手,会被立即分配通信套接字,开始传输数据
- 这样系统资源就不会再出现空闲状态,提高资源利用率
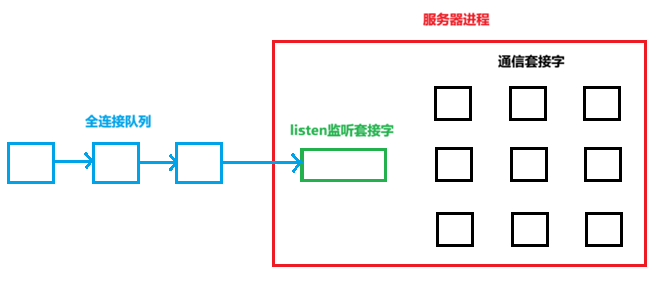
listen的第二个参数backlog就能指定全连接队列的长度,具体长度等于backlog+1。
全连接队列的长度不能太长,因为队列太长时,维护队列会消耗系统资源。
实验证明
- 用于测试的服务器不调用accpet(),新的客户端请求会被直接放入全连接队列中
- listen的第二个参数backlog为1,全连接队列的长度为2
HttpServer.hpp
cpp
#pragma once
#include <iostream>
#include <string>
#include <cerrno>
#include <cstring>
#include <cstdlib>
#include <sys/types.h>
#include <sys/socket.h>
#include <functional>
#include <strings.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <sys/wait.h>
#include <thread>
using namespace std;
enum
{
USAGE_ERROR = 1,
SOCKET_ERROR = 2,
BIND_ERROR = 3,
LISTEN_ERROR = 4,
ACCEPT_ERROR = 5,
READ_ERROR = 6,
WRITE_ERROR = 7
};
class HttpServer
{
private:
uint16_t _port; // 端口号
int _listen_sockfd; // socket描述符(文件描述符)
public:
HttpServer( const uint16_t &port)
: _port(port),
_listen_sockfd(-1)
{
}
// 初始化服务器
void InitServer()
{
// 1. 创建socket
_listen_sockfd = socket(AF_INET, SOCK_STREAM, 0); // IPv4协议 TCP模式 默认值
if (_listen_sockfd == -1)
{
exit(SOCKET_ERROR);
}
// 2. 绑定bind
struct sockaddr_in local; // IPv4 网络地址结构体
bzero(&local, sizeof(local)); // 清空结构体
local.sin_family = AF_INET; // 表示使用 IPv4 协议
local.sin_port = htons(_port); // 端口号 htons 主机字节序转网络字节序
local.sin_addr.s_addr = INADDR_ANY; // 系统定义的宏(值为 0x00000000,对应 IPv4 地址 0.0.0.0)
int n = bind(_listen_sockfd, (struct sockaddr *)&local, sizeof(local)); // 绑定socket与地址
if (n < 0)
{
exit(BIND_ERROR);
}
// 3. 监听listen
n = listen(_listen_sockfd, 1); // 最大连接数2
if (n < 0)
{
exit(LISTEN_ERROR);
}
}
// 启动服务器
void Start()
{
while (true)
{
sleep(1);
}
}
~HttpServer()
{
}
};HttpServer.cpp
cpp
#include <iostream>
#include <memory>
#include <string>
#include <fstream>
#include "HttpServer.hpp"
using namespace std;
// 输入 ./tcpServer port
int main(int argc, char *argv[])
{
if (argc != 2)
{
cerr << "Usages:" << argv[0] << " port" << endl;
exit(USAGE_ERROR);
}
uint16_t _port = atoi(argv[1]);
unique_ptr<HttpServer> httpserver(new HttpServer( _port));
httpserver->InitServer();
httpserver->Start();
return 0;
}**运行结果:**全连接队列未满时,客户端发起新的请求,进行三次握手,放入队列,客户端和服务器状态为ESTABLISHED
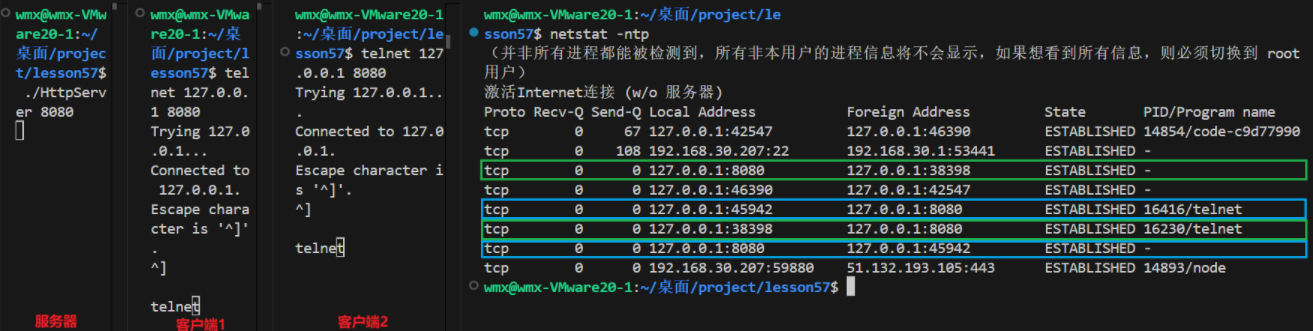
**运行结果:**全连接队列已满后,客户端发起新的请求时,客户端状态为SYN_SENT(半连接)

一段时间后,如果新的请求还没有完成三次握手,连接就会超时,客户端自动退出

但是如果应用层调用accept()取走了全连接队列中的连接,半连接就会完成三次握手,放入队列中
操作系统维护了两个队列:
- 半链接队列,保存处于SYN_SENT和SYN_RECV状态的请求
- 全连接队列,保存处于ESTABLISHED状态的连接,等待应用层调用accept获取
四、TCP小结
1.TCP的机制
可靠性:
校验和,序列号,确认应答,超时重发,连接管理,流量控制,拥塞控制
提高性能:
滑动窗口,捎带应答,延迟应答,快速重传
2.TCP/UDP对比
- TCP用于可靠传输的情况,应用于文件传输,重要状态更新等场景
- UDP用于对高速传输和实时性要求较高的通信领域,例如,早期的QQ、视频传输等,另外UDP可以用于广播
归根结底,TCP和UDP都是程序员的工具,什么时机用,具体怎么用,还是要根据具体的需求场景去判定.
3.用UDP实现可靠传输(经典面试题)
参考TCP的可靠性机制,在应用层实现类似的逻辑;
例如:
- 引入序列号,保证数据顺序;
- 引入确认应答,确保对端收到了数据;
- 引入超时重传,如果隔一段时间没有应答, 就重发数据;
- ...