作为一个用Stata做实证研究快4年的"老玩家",我敢说OLS回归是所有实证分析的"基本功"------它是理解更复杂模型的基础,也是论文里基准回归的标配。今天就结合我自己的实操经验,把OLS回归的完整流程、代码和避坑指南整理出来,新手也能直接上手。
一、先搞懂OLS回归的核心逻辑
OLS(普通最小二乘法)的核心思想其实很简单:通过最小化模型预测值和实际观测值之间的误差平方和,来估计自变量对因变量的影响。简单来说,就是找一条最贴合数据的直线。
不过要注意,OLS回归有几个关键假设,不满足的话结果可能会"失真":
- 线性关系:因变量和自变量之间得是线性关系
- 同方差:误差项的方差要恒定,不能忽大忽小
- 无自相关:误差项之间不能有关系
- 无多重共线性:自变量之间不能高度相关
二、Stata实操:从基础到进阶
1. 基础OLS回归命令
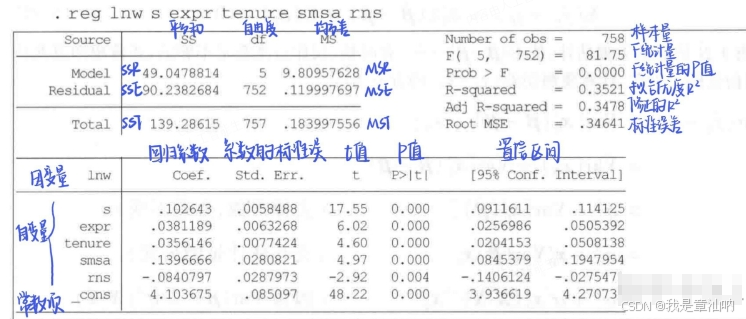
这是最常用的命令,直接输入就能跑回归,y是被解释变量,x、x1这些是解释变量。 Stata代码:
reg y x x1 x2 x3 // y为被解释变量,x、x1、x2、x3为解释变量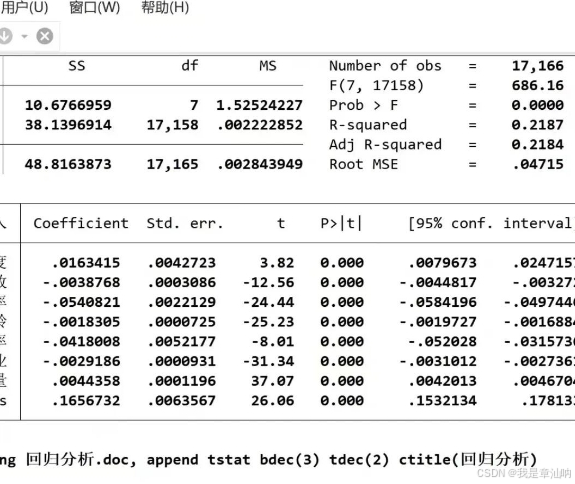
2. 控制固定效应
如果是面板数据,我习惯加入固定效应来控制不随时间或个体变化的因素,比如年份、行业。 Stata代码:
reg 被解释变量 解释变量 控制变量1 控制变量2 i.year i.industry // i.year控制年份固定效应,i.industry控制行业固定效应3. 处理异方差和自相关
如果模型存在异方差(误差项方差不恒定),我会用稳健标准误来修正,这样结果更可靠。 Stata代码:
reg y x x1 x2, robust // 稳健标准误
reg y x x1 x2, vce(cluster id) // 聚类稳健标准误,适合面板数据4. 导出回归结果到文件
论文里需要规范的回归表格,用这个命令可以直接导出到RTF文件,不用手动复制粘贴。 Stata代码:
est store reg1 // 存储回归结果
esttab reg1 using 主变量回归结果.rtf, replace nogap ar2 b(%6.4f) t(%6.4f) star(* 0.1 ** 0.05 *** 0.01)
// 导出结果到RTF文件,保留4位小数,显示t值和显著性星号三、回归结果怎么看?重点看这几个指标
每次跑出来回归结果,我都会先看这几个关键指标:
- 系数(Coefficient):自变量对因变量的边际影响,比如系数是0.5,就表示x增加1单位,y平均增加0.5单位
- p值(P>|t|):判断系数是否显著,一般p<0.05就说明显著
- R²(R-squared):模型的拟合优度,越接近1说明模型对数据的解释力越强
- 调整R²(Adj R-squared):修正后的R²,适合比较不同模型的拟合效果
四、实操避坑指南
-
变量选择要谨慎:核心解释变量要和研究问题直接相关,控制变量要选理论上会影响因变量的变量,别为了显著而乱加变量
-
多重共线性要注意:如果自变量之间高度相关(VIF>10),可以考虑删除一个变量或者合并变量
-
异常值处理 :跑回归前最好对连续变量进行缩尾处理,避免极端值影响结果 Stata代码:
winsor2 var1 var2 var3, cuts(1 99) replace // 对变量进行1%缩尾
-
稳健性检验不能少:换个模型、换个样本范围、换个变量衡量方式,看看结果是不是还显著,这是论文审稿人很看重的一点
五、进阶:面板数据的OLS回归
如果是面板数据(既有个体又有时间维度),除了基础OLS,还可以用固定效应和随机效应模型:
1. 固定效应模型
适合控制不随时间变化的个体异质性 Stata代码:
xtreg y x x1 x2, fe // 个体固定效应模型2. 随机效应模型
适合个体效应和自变量不相关的情况 Stata代码:
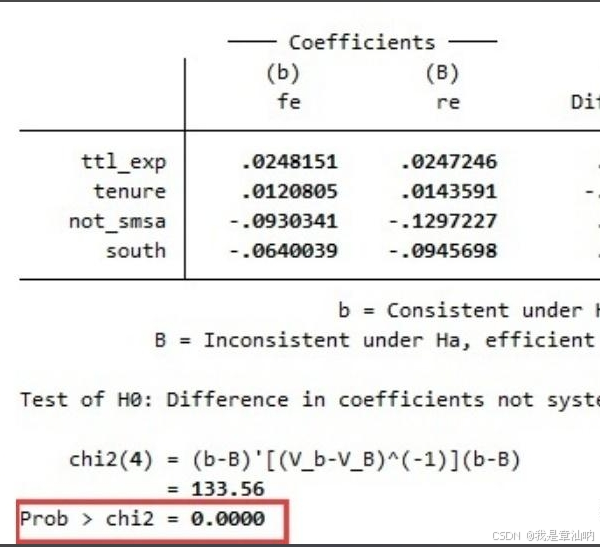
xtreg y x x1 x2, re // 随机效应模型3. 模型选择:豪斯曼检验
不知道选固定效应还是随机效应?跑个豪斯曼检验就行 Stata代码:
estimates store FE // 存储固定效应结果
estimates store RE // 存储随机效应结果
hausman FE RE // 豪斯曼检验如果p<0.05,就选固定效应模型;反之选随机效应模型