【强化学习】第九章:基于Action-Critic框架的强化学习
如果说前面章节更偏重底层理论,那从本章开始就越接近前沿、越接近实践。基于AC框架的强化学习方法是当前强化学习中最流行、最普遍的方法。基于AC框架的算法也层出不穷,比如:A2C、PPO、TRPO等算法。
一、回顾策略梯度的计算过程,引出Action-Critic方法
1、什么是Action-Critic方法
本文承接 https://blog.csdn.net/friday1203/article/details/157839155?spm=1001.2014.3001.5501 ,把基于价值的方法,具体是value function approximation方法,引入到策略梯度方法中,就是Action-Critic方法。或者说,Action-Critic实际上就是把Policy gradient和value function approximation这两种方法结合起来的方法。所以从这个角度说,AC方法其实就是策略梯度方法的延申。下面我把完整的逻辑链条展示出来,看看是如何延申的: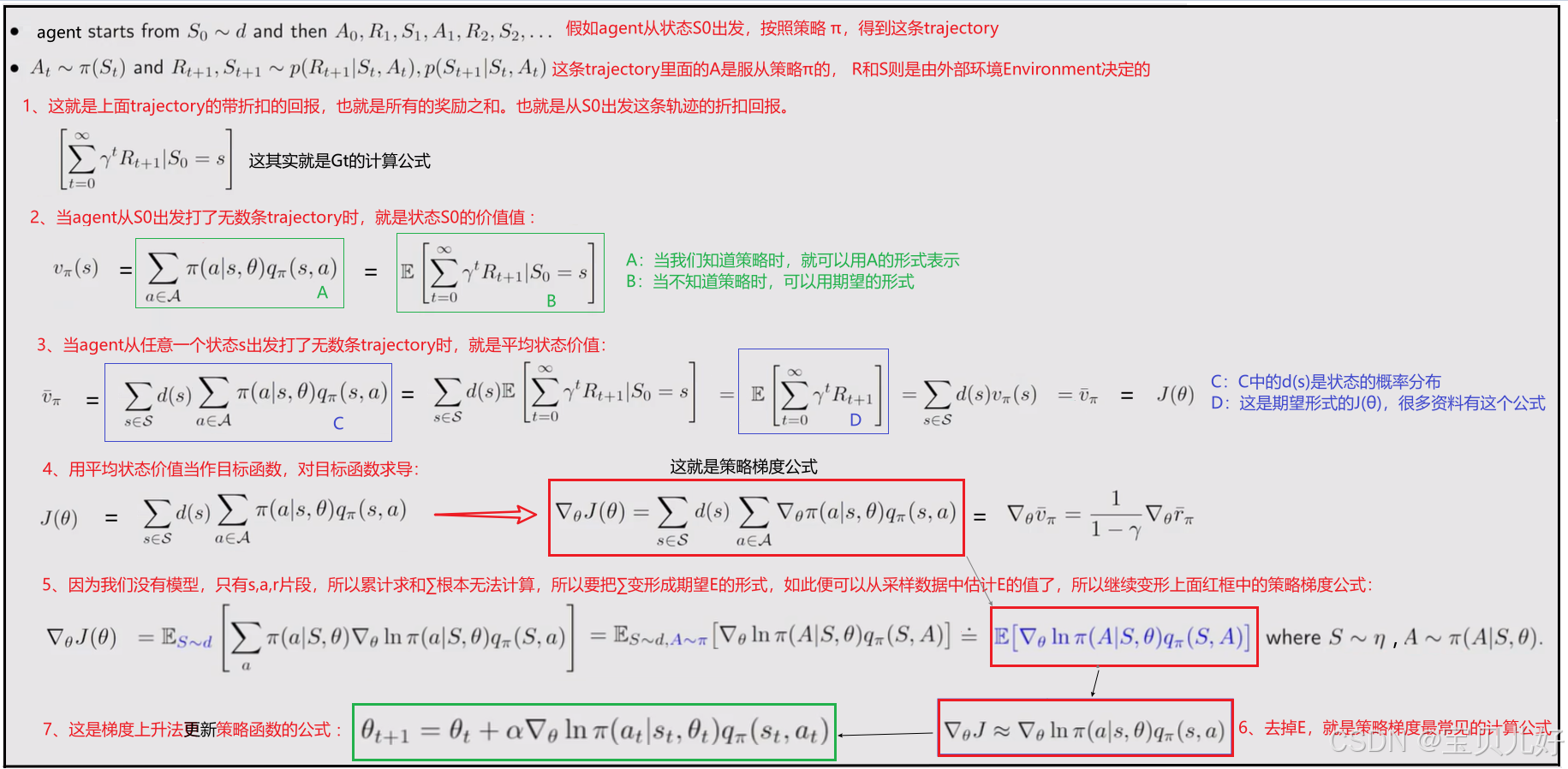

说明:上述方法得到的策略是最优的随机策略 。至于希望策略函数输出的是概率分布 ,然后按照概率采样动作,那就是确定性策略梯度方法(Deterministic Policy Gradient (DPG)) 了,我们下个篇章讲解。本篇章是随机策略梯度方法(SPG) 。
2、用一个例子,直观感受一下策略梯度的各个组 成部分 : 上图可以直观看到策略函数是如何进行迭代优化的。正是由于C的作用,使得好的行为更可能发生,坏的行为更不可能发生。
上图可以直观看到策略函数是如何进行迭代优化的。正是由于C的作用,使得好的行为更可能发生,坏的行为更不可能发生。
二、两个入门算法:QAC、A2C
1、最简单的AC算法:QAC 
这个算法是最简单的AC算法。QAC中的Q表示q_value的意思,所以叫QAC。这个算法虽然简单,但是从这个算法中我们可以比较清晰的看到AC方法的思想。这个算法的
Critic是SARSA + value function approximation 。
SARSA + value function approximation 用的是动作价值估计来更新价值函数的参数。详情见:https://blog.csdn.net/friday1203/article/details/157395866?spm=1001.2014.3001.5501
Actor是策略函数。上面大标题就有完整的推导过程。

就是用Critic对策略进行评估-->用Critic的评估的结果q,来更新Actor的策略-->用新策略生成经验数据-->用经验数据更新Critic-->用新的Critic评估策略-->用评估结果q更新Actor的策略-->用新新策略生成经验数据-->.....如此循环。
2、Advantage actor-critic(A2C)
引入一个偏置量来减小估计的方差(Baseline invariance)