Flash Attention可以加速计算,节省显存。本文介绍了Flash Attention的原理,以及在GPU/NPU上的使用方式。
标准Attention
标准注意力计算公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
FlashAttention
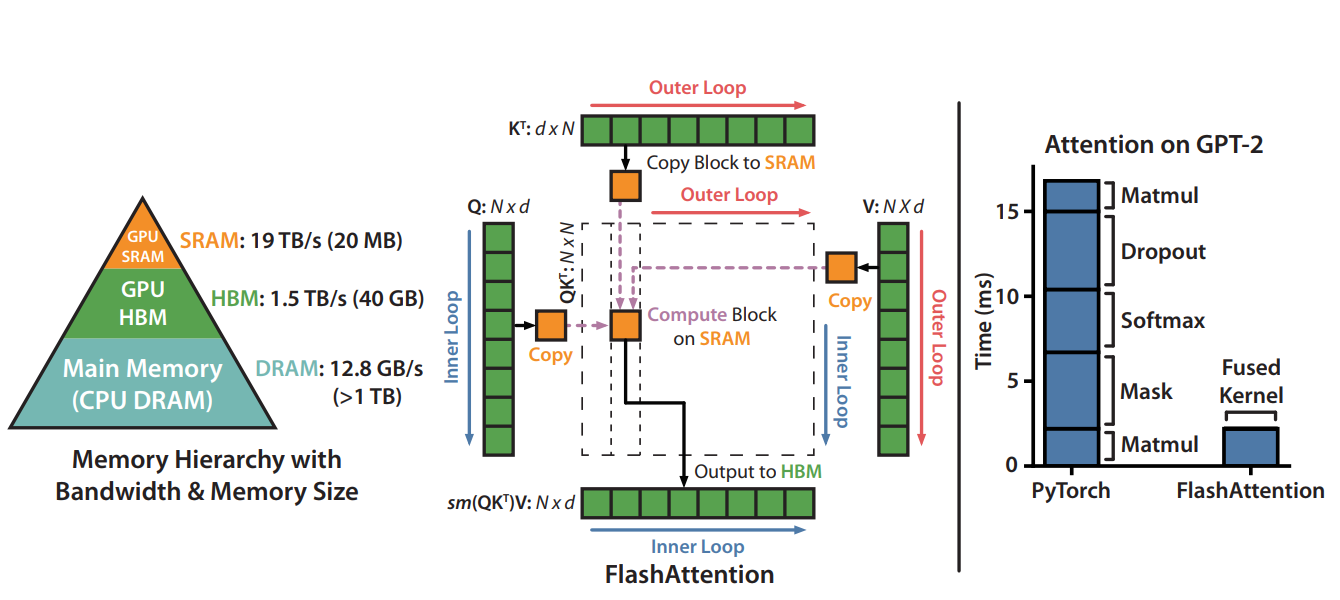
通过Tiling的方式减少SRAM和HBM之间的读写操作,从而提高Attention算子计算速度,并降低了中间激活值显存
- SRAM的带宽高,但内存有限;HBM的内存高,但带宽较低
- 以循环遍历的方式,每次从HBM中读取部分Q, K, V计算Attention,计算完成后,将O写入HBM
- 通过online-softmax的方式,对子序列softmax的值进行修正
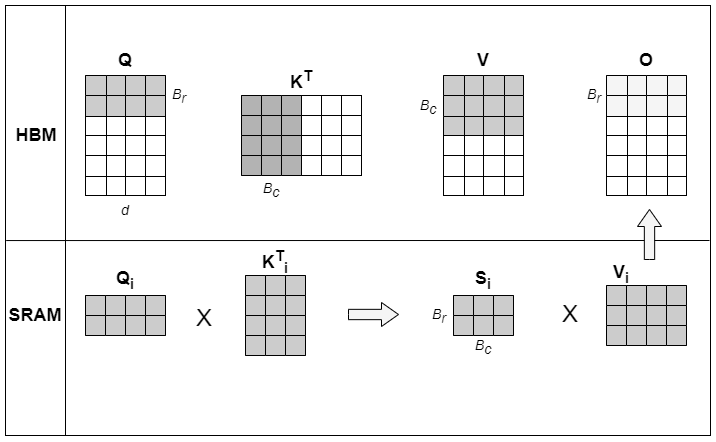
传统Attention的计算方式, Q , K , V ∈ ( N × d ) Q, K, V \in (N \times d) Q,K,V∈(N×d),总的IO访问量为 4 N ( N + d ) 4N(N+d) 4N(N+d)
- 从HBM中读取Q,K到SRAM,计算 S = Q K T S=QK^T S=QKT,然后写入HBM, i o = 2 N d + N 2 io=2Nd+N^2 io=2Nd+N2
- 从HBM中读取S到SRAM,计算 P = s o f t m a x ( S ) P=softmax(S) P=softmax(S),将P写入HBM, i o = 2 N 2 io=2N^2 io=2N2
- 从HBM中读取P和V到SRAM,计算 O = P V O=PV O=PV,将O写入HBM, i o = N 2 + N d + N d io=N^2+Nd+Nd io=N2+Nd+Nd
FlashAttention计算流程:
每次读取部分Q和部分K计算Attention,无需将 S = Q K T S=QK^T S=QKT的计算结果写入HBM

论文中A100实验数据(seq. length 1024, head dim. 64, 16 heads, batch size 64)
| Attention | Standard | FlashAttention |
|---|---|---|
| GFLOPs | 66.6 | 75.2 |
| HBM R/W (GB) | 40.3 | 4.4 |
| Runtime (ms) | 41.7 | 7.3 |
计算量略有增加,HBM读写大幅减少,性能明显提升。
GPU上用法
定长序列
同一批次中,每个序列的长度固定
Attention
小算子实现:softmax(Q @ K^T * softmax_scale) @ V
python
# B, N, S, D
attn = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(q.size(-1)))
if attn_mask is not None:
attn = attn + attn_mask
attn = attn.softmax(dim=-1)
out = attn @ vSDPA
torch原生实现:torch.nn.functional.scaled_dot_product_attention,与前面的小算子实现等价
python
def scaled_dot_product_attention(
query, # 输入的 query 张量,形状为 (batch, num_heads, q_len, head_dim)
key, # 输入的 key 张量,形状为 (batch, num_heads, k_len, head_dim)
value, # 输入的 value 张量,形状为 (batch, num_heads, v_len, head_dim)
attn_mask=None, # 注意力掩码
dropout_p=0.0, # Dropout 概率
is_causal=False, # 是否应用因果注意力掩码,用于自回归(auto-regressive)建模
scale=None # 缩放因子,默认为 1 / sqrt(head_dim)
)在NPU环境中,SDPA会自动替换为NPU上的FA(layout=BNSD)
flash_attn_func
flash-attention 官方实现:https://github.com/Dao-AILab/flash-attention
python
# B, S, N, D
def flash_attn_func(
q, k, v, # 输入的q,k,v张量,形状为(batch, seq_len, num_heads, head_dim)
dropout_p=0.0, softmax_scale=scale, causal=False)变长序列
将多个序列拼接为一个长序列,通过 cu_seqlens_q 和 cu_seqlens_k 参数接收长序列的累积长度;同一批次中,每个序列的长度有差异
函数定义:
python
# 定义
def flash_attn_varlen_func(
q, # 输入的 query 张量,形状为 (total_q, num_heads, head_dim),其中 total_q 是批量中所有查询token的总数
k, # 输入的 key 张量,形状为 (total_k, num_heads, head_dim)
v, # 输入的 value 张量,形状为 (total_v, num_heads, head_dim)
cu_seqlens_q, # 批量中每个查询序列的累积长度,形状为 (batch_size + 1,),数据类型为 torch.int32,用于从 q 中索引相应的位置
cu_seqlens_k, # 批量中每个 key 序列的累积长度,形状为 (batch_size + 1,),数据类型为 torch.int32,用于从 k 和 v 中索引相应的位置
max_seqlen_q, # 批量中最大query序列长度
max_seqlen_k, # 批量中最大 key 序列长度
dropout_p=0.0, # Dropout 概率
softmax_scale=None, # softmax 缩放因子,默认为 1 / sqrt(head_dim)
causal=False, # 是否应用因果注意力掩码,用于自回归(auto-regressive)建模
window_size=(-1, -1), # 用于实现滑动窗口局部注意力,(-1, -1) 表示无限制上下文窗口
alibi_slopes=None, # 用于添加注意力分数偏置,形状为 (nheads,) 或 (batch_size, num_heads),数据类型为 fp32
deterministic=False, # 是否使用确定性反向传播实现,比非确定性实现稍慢但使用更多内存,前向传播始终是确定性的
return_attn_probs=False, # 是否返回注意力概率,仅用于测试,返回的概率可能不具有正确缩放
block_table=None # 可选的块表,用于分块稀疏注意力
)测试样例:
python
from flash_attn import flash_attn_varlen_func
...
q_seqlens = [24119, 13853, 68264, 2421, 6210] # query的序列长度列表
kv_seqlens = [24119, 13853, 68264, 2421, 6210] # key和value的序列长度列表
q_cu_seqlens = [24119, 37972, 106236, 110110, 112531, 118741] # 累积长度
kv_cu_seqlens = [24119, 37972, 106236, 110110, 112531, 118741]
max_seqlen_q = max(q_seqlens)
max_seqlen_k = max(kv_seqlens)
out = flash_attn_varlen_func(
q,
k,
v,
cu_seqlens_q,
cu_seqlens_k,
max_seqlen_q,
max_seqlen_k,
dropout_p=0.0,
softmax_scale=None,
causal=False
)NPU FA用法
- q, k, v 数据类型支持FLOAT16、BFLOAT16、FLOAT32
- 支持q和kv的head数量不相等(GQA),但要求 N q N_q Nq和 N k v N_{kv} Nkv成比例关系
- Attention mask与SDPA中的mask相反,取值为True或1代表该位不参与计算。mask格式受到layout, causal和sparse_mode的限制
- 不同的layout使用场景和性能有差异:定长序列用BNSD, BSND, SBH或BSH(其中BNSD性能最好),变长序列只能用TND
torch_npu.npu_fusion_attention-Ascend Extension for PyTorch6.0.0-昇腾社区
这里说的BNSD性能最好并不是绝对的,还要结合Attention前后的操作综合考虑,比如在序列长度较短的情况下,输入shape是BSND的,如果对q,k,v做transpose操作得到BNSD的shape,再调用FA算子,那么可能Transpose的开销就大于了BNSD的收益了,所以需要综合考虑。
定长序列
SDPA在npu上会自动转换为BNSD的FA
不使能causal时
python
if atten_mask.dtype == torch.bool:
atten_mask_npu = torch.logical_not(attention_mask.bool()).to(device) // atten_mask需要取反
else:
atten_mask_npu = attention_mask.bool().to(device)
head_num = query.shape[1]
res = torch_npu.npu_fusion_attention(
query, key, value, head_num, input_layout="BNSD",
pse=None,
atten_mask=atten_mask_npu,
scale=1.0 / math.sqrt(query.shape[-1]),
pre_tockens=2147483647,
next_tockens=2147483647,
keep_prob=1
)[0]使能causal时
python
atten_mask_npu = torch.triu(torch.ones([2048, 2048], dtype=torch.bool, device=q.device), diagonal=1)
head_num = query.shape[1]
res = torch_npu.npu_fusion_attention(
query, key, value, head_num, input_layout="BNSD",
pse=None,
atten_mask=atten_mask_npu,
scale=1.0 / math.sqrt(query.shape[-1]),
keep_prob=1,
sparse_mode=2)[0]sparse_mode为2时,代表leftUpCausal模式的mask,对应以左上顶点划分的下三角场景(参数起点为左上角)
flash_attn_func对应BSND格式,如果要使用BNSD,需要综合考虑transpose的开销。sparse_mode=0场景下mask限制较多如果想支持自定义格式的mask,需要将sparse_mode=1
FA:
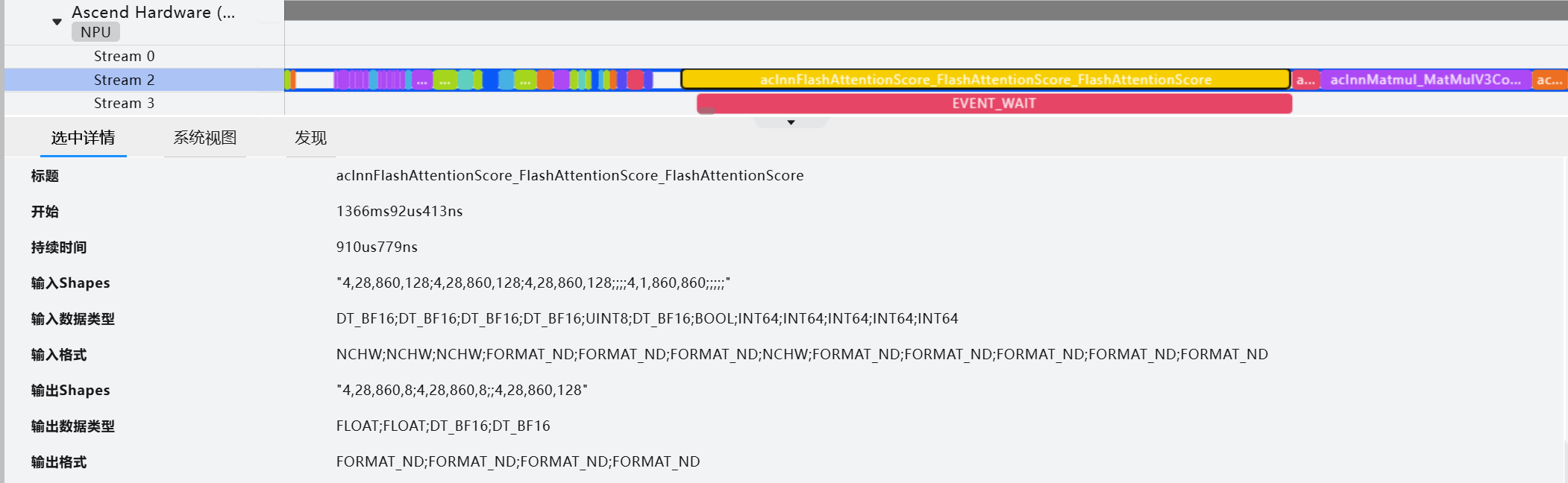
FAG:
NPU同样支持BSND,可以直接替换flash_attn_func
不使能causal时
python
head_num = q.shape[2]
out = torch_npu.npu_fusion_attention(q, k, v, head_num, "BSND", keep_prob=1.0, scale=scale)[0]使能causal时
python
atten_mask_npu = torch.triu(torch.ones([2048, 2048], dtype=torch.bool, device=q.device), diagonal=1)
head_num = q.shape[2]
out = torch_npu.npu_fusion_attention(q, k, v, head_num, "BSND", keep_prob=1.0,
scale=scale, atten_mask=atten_mask_npu, sparse_mode=3)[0]sparse_mode为3时,代表rightDownCausal模式的mask,对应以右下顶点划分的下三角场景(参数起点为右下角)。该场景下忽略pre_tockens、next_tockens取值。atten_mask为优化后的压缩下三角矩阵(2048*2048)
变长序列
TND:T指total_seq,N指num_heads,D指head_dim
varlen场景只支持SS格式,SS分别是maxSq和maxSkv
python
q_seqlens = [24119, 13853, 68264, 2421, 6210] # query的序列长度列表
kv_seqlens = [24119, 13853, 68264, 2421, 6210] # key和value的序列长度列表
q_cu_seqlens = [24119, 37972, 106236, 110110, 112531, 118741] # 累积长度
kv_cu_seqlens = [24119, 37972, 106236, 110110, 112531, 118741]
max_seqlen_q = max(q_seqlens)
max_seqlen_k = max(kv_seqlens)
# 不使能causal时,无需传入mask
output = torch_npu.npu_fusion_attention(
q, k, v, head_num,
pse=None,
atten_mask=None,
scale=1.0 / math.sqrt(q.shape[-1]),
keep_prob=1,
input_layout="TND",
actual_seq_qlen=tuple(cu_seqlens_q[1:].cpu().numpy().tolist()),
actual_seq_kvlen=tuple(cu_seqlens_k[1:].cpu().numpy().tolist()))[0]
# 使能causal时,需要传入mask
attn_mask = torch.triu(torch.ones([2048, 2048], dtype=torch.bool, device=q.device), diagonal=1)
output = torch_npu.npu_fusion_attention(
q, k, v, head_num,
pse=None,
padding_mask=None,
atten_mask=attn_mask_npu,
scale=1.0 / math.sqrt(q.shape[-1]),
keep_prob=1,
input_layout="TND",
actual_seq_qlen=tuple(cu_seqlens_q[1:].cpu().numpy().tolist()),
actual_seq_kvlen=tuple(cu_seqlens_k[1:].cpu().numpy().tolist()),
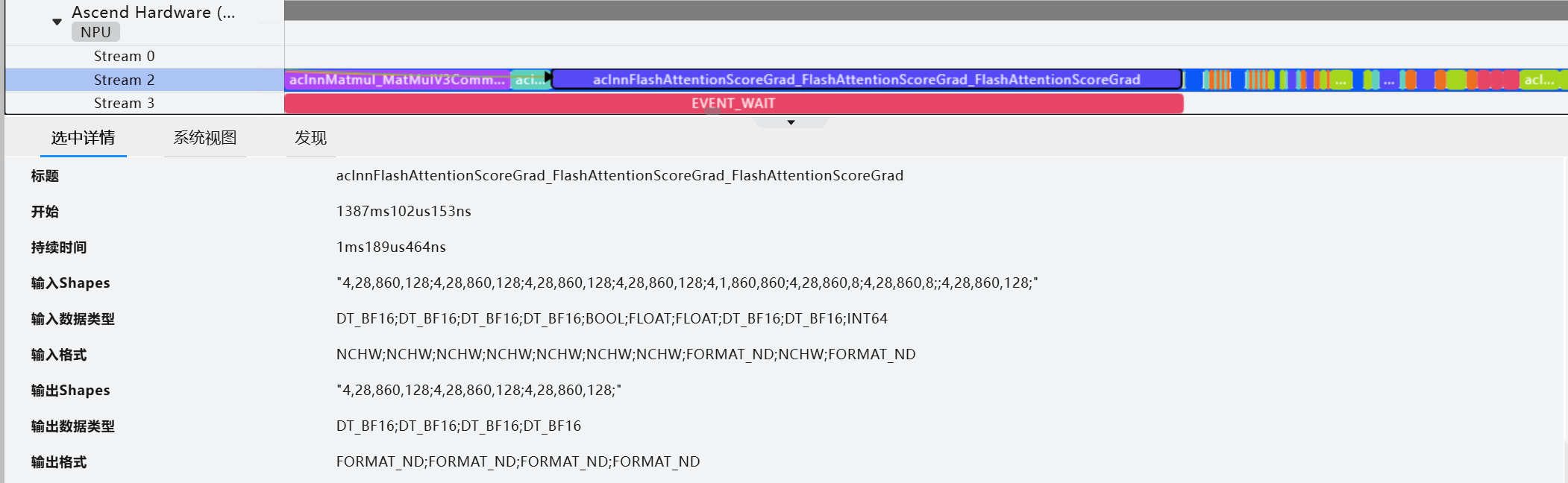
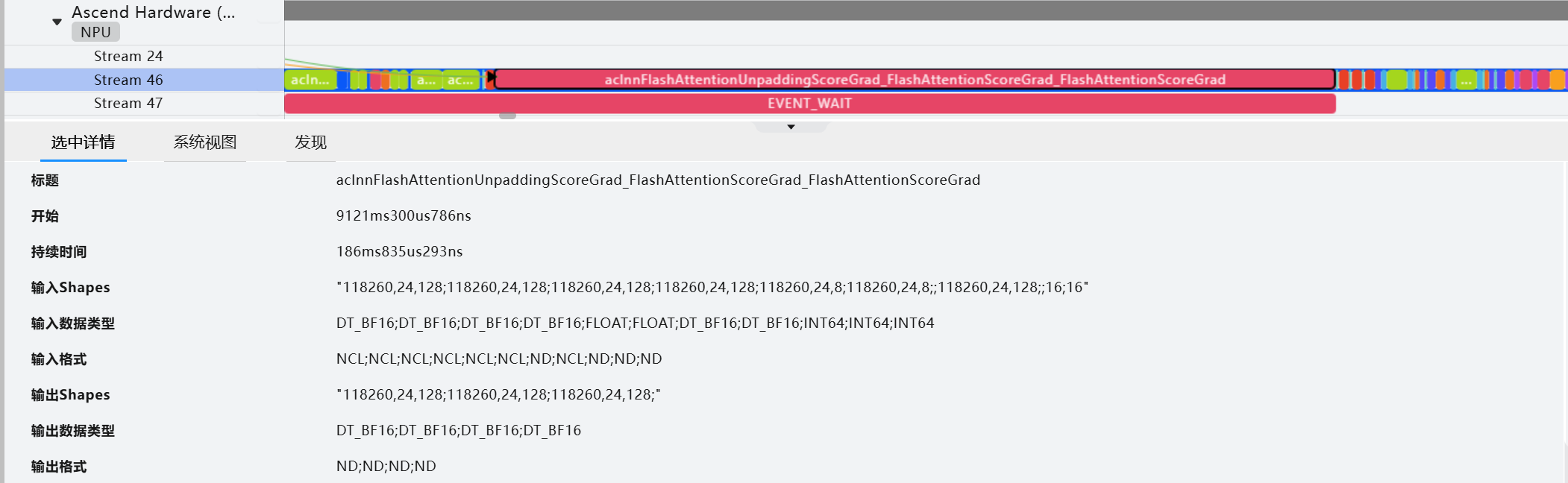
sparse_mode=3)[0]FA:
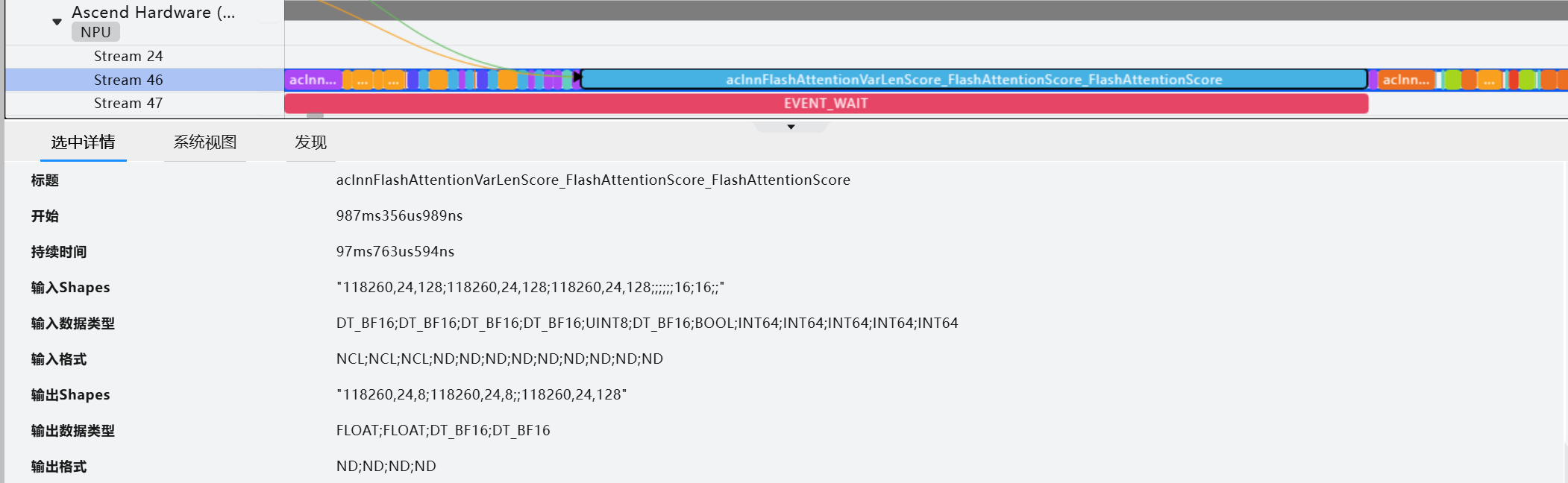
FAG:
Tips
- mask用torch在npu上生成,不要使用numpy然后转为Tensor
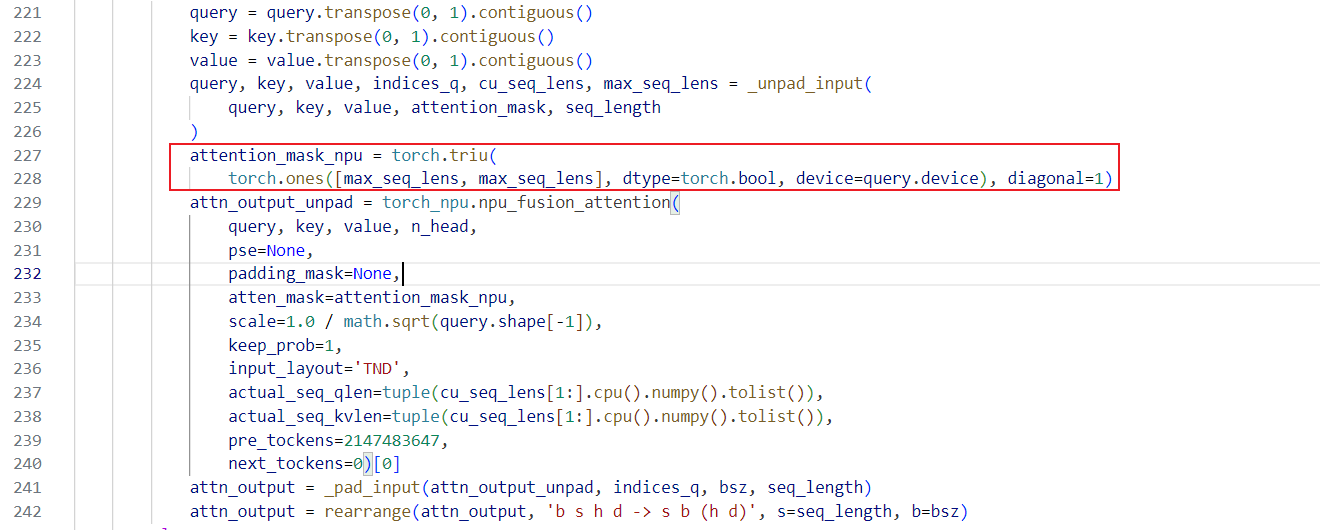
- TND中的
tuple(cu_seqlens_q[1:].cpu().numpy().tolist())可以提前缓存到cpu上。GPU上flash_attn_varlen_func支持torch.tensor,而NPU只支持list,多了d2h的操作,未来应该会优化一下
参考资料
- FlashAttention论文:https://arxiv.org/abs/2205.14135
- B站视频:Flash Attention 为什么那么快?原理讲解