深度学习网络从入门到入土 使用块的网络VGG
个人导航
知乎:https://www.zhihu.com/people/byzh_rc
CSDN:https://blog.csdn.net/qq_54636039
注:本文仅对所述内容做了框架性引导,具体细节可查询其余相关资料or源码
参考文章:各方资料
文章目录
- [深度学习网络从入门到入土 使用块的网络VGG](#[深度学习网络从入门到入土] 使用块的网络VGG)
- 个人导航
- 参考资料
- 背景
- 架构(公式)
-
-
-
- [1. VGG Block 的形式](#1. VGG Block 的形式)
- [2. 为什么坚持用 3×3?](#2. 为什么坚持用 3×3?)
- [3. 典型的 VGG16 配置](#3. 典型的 VGG16 配置)
-
-
- 创新点
-
-
-
- [1. ==提出"块"作为结构单位==](#1. ==提出“块”作为结构单位==)
- [2. 小卷积核堆叠替代大卷积核](#2. 小卷积核堆叠替代大卷积核)
- [3. 强迁移能力(经典 backbone)](#3. 强迁移能力(经典 backbone))
-
-
- 代码实现
- 项目实例
参考资料
Very Deep Convolutional Networks for Large-Scale Image Recognition.
背景
AlexNet(2012)之后,大家发现 CNN "更深"通常更强,但当时"怎么加深"并不统一:
- AlexNet 用较大的卷积核(11×11、5×5)
- GoogLeNet 用 Inception(结构更复杂)
- 那时还没有 ResNet 的残差结构,深网络训练更难
VGG 提出的核心思想非常"工程化":用简单、统一、可重复堆叠的卷积块,把网络堆深
用大量 3×3 小卷积核 替代大卷积核,并用**Block(块)**的方式组织网络
-> 使结构更规整、易于扩展、易于迁移(也因此成为经典 backbone)
架构(公式)
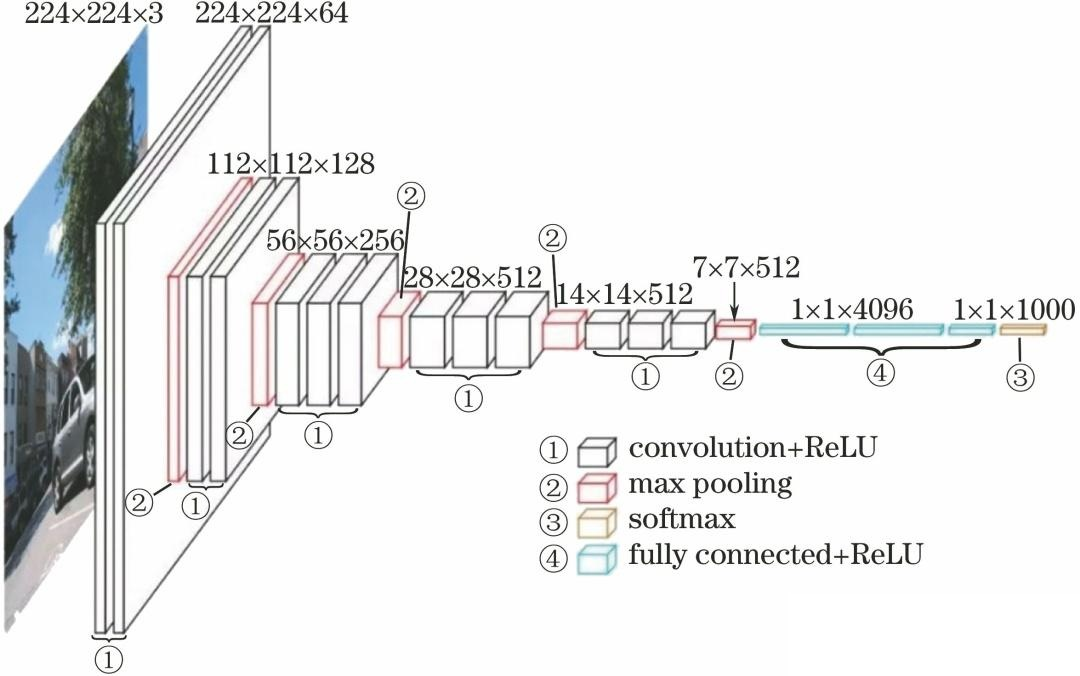
1. VGG Block 的形式
一个 VGG 块通常是:
( Conv 3 × 3 + ReLU ) × n ⏟ 同一尺度下堆叠 → MaxPool 2 × 2 , s = 2 \underbrace{(\text{Conv }3\times3 + \text{ReLU}) \times n}_{\text{同一尺度下堆叠}} \; \rightarrow \; \text{MaxPool }2\times2, s=2 同一尺度下堆叠 (Conv 3×3+ReLU)×n→MaxPool 2×2,s=2
也就是:同分辨率下做多次 3×3 卷积,然后池化缩小一半。
2. 为什么坚持用 3×3?
用多个 3×3 叠加可以替代大卷积核,并且非线性更多:
- 一个 5×5 卷积的感受野,可由两个 3×3 叠加得到 3 × 3 + 3 × 3 ⇒ 5 × 5 感受野 3\times3 \;+\; 3\times3 \Rightarrow 5\times5 \text{ 感受野} 3×3+3×3⇒5×5 感受野
- 一个 7×7 卷积的感受野,可由三个 3×3 叠加得到 3 × 3 + 3 × 3 + 3 × 3 ⇒ 7 × 7 3\times3 \;+\; 3\times3 \;+\; 3\times3 \Rightarrow 7\times7 3×3+3×3+3×3⇒7×7
好处:
- 参数更少
- 非线性层(ReLU)更多 → 表达能力更强
- 结构统一,方便堆深
3. 典型的 VGG16 配置
论文里用 "配置表" 表示(最常见是 VGG16 / VGG19):
- VGG16:
[2,2,3,3,3]个卷积层分布在 5 个块里 - 通道数:
64, 128, 256, 512, 512 - 每个块后面一个
2×2 maxpool
最后是分类头:FC 4096 -> FC 4096 -> FC num_classes
创新点
1. 提出"块"作为结构单位
VGG 的结构非常规整:每个 Block 做特征提取 + 下采样,重复堆叠即可
这让"深度"变成了一种可控超参数(11/13/16/19)
2. 小卷积核堆叠替代大卷积核
多个 3×3 代替 一个大核:
- 同等感受野下参数更少
- 非线性更多(表达力更强)
3. 强迁移能力(经典 backbone)
虽然 VGG 参数量大、计算慢,但其特征泛化强,早期大量检测/分割方法都用它做 backbone
代码实现
py
import torch
import torch.nn as nn
import torch.nn.functional as F
from byzh.ai.Butils import b_get_params
# -----------------------------
# VGG 各版本的"配置表"
# 用数字表示输出通道数,用 'M' 表示 MaxPool
# -----------------------------
cfgs = {
# VGG11: 8个conv + 3个linear(论文叫 11 层)
"VGG11": [
64, "M",
128, "M",
256, 256, "M",
512, 512, "M",
512, 512, "M"
],
# VGG13: 10个conv
"VGG13": [
64, 64, "M",
128, 128, "M",
256, 256, "M",
512, 512, "M",
512, 512, "M"
],
# VGG16: 13个conv(最常用)
"VGG16": [
64, 64, "M",
128, 128, "M",
256, 256, 256, "M",
512, 512, 512, "M",
512, 512, 512, "M"
],
# VGG19: 16个conv
"VGG19": [
64, 64, "M",
128, 128, "M",
256, 256, 256, 256, "M",
512, 512, 512, 512, "M",
512, 512, 512, 512, "M"
],
}
def make_vgg_features(cfg, use_bn=False):
"""
根据 cfg 列表构建 VGG 的卷积特征提取部分 features
- cfg: cfgs["VGG16"] 这种列表
- use_bn: 是否在每个卷积后加 BN(原论文中 无BN)
"""
layers = []
in_channels = 3 # 输入 RGB 三通道
for v in cfg:
if v == "M":
# 最大池化:把 H,W 各减半
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
else:
# 3×3 卷积(VGG 固定用 3×3,padding=1 -> 保持尺寸不变)
conv = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if use_bn:
layers.extend([conv, nn.BatchNorm2d(v), nn.ReLU()])
else:
layers.extend([conv, nn.ReLU()])
in_channels = v
return nn.Sequential(*layers)
class B_VGG11_Paper(nn.Module):
"""
VGG11:features + classifier
input shape: (N, 3, 224, 224)
"""
def __init__(self, num_classes=1000, use_bn=False):
super().__init__()
# 卷积特征提取部分
self.features = make_vgg_features(cfgs["VGG11"], use_bn=use_bn)
# 自适应池化到 7×7
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
# 分类头
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x) # N, 512, 7, 7(对 224 输入来说)
x = self.avgpool(x) # 强制变成 N, 512, 7, 7(更稳)
x = torch.flatten(x, 1) # N, 512*7*7
x = self.classifier(x) # N, num_classes
return x
class B_VGG13_Paper(nn.Module):
"""
VGG13:features + classifier
input shape: (N, 3, 224, 224)
"""
def __init__(self, num_classes=1000, use_bn=False):
super().__init__()
# 卷积特征提取部分
self.features = make_vgg_features(cfgs["VGG13"], use_bn=use_bn)
# 自适应池化到 7×7
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
# 分类头
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x) # N, 512, 7, 7(对 224 输入来说)
x = self.avgpool(x) # 强制变成 N, 512, 7, 7(更稳)
x = torch.flatten(x, 1) # N, 512*7*7
x = self.classifier(x) # N, num_classes
return x
class B_VGG16_Paper(nn.Module):
"""
VGG16:features + classifier
input shape: (N, 3, 224, 224)
"""
def __init__(self, num_classes=1000, use_bn=False):
super().__init__()
# 卷积特征提取部分
self.features = make_vgg_features(cfgs["VGG16"], use_bn=use_bn)
# 自适应池化到 7×7
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
# 分类头
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x) # N, 512, 7, 7(对 224 输入来说)
x = self.avgpool(x) # 强制变成 N, 512, 7, 7(更稳)
x = torch.flatten(x, 1) # N, 512*7*7
x = self.classifier(x) # N, num_classes
return x
class B_VGG19_Paper(nn.Module):
"""
VGG19:features + classifier
input shape: (N, 3, 224, 224)
"""
def __init__(self, num_classes=1000, use_bn=False):
super().__init__()
# 卷积特征提取部分
self.features = make_vgg_features(cfgs["VGG19"], use_bn=use_bn)
# 自适应池化到 7×7
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
# 分类头
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x) # N, 512, 7, 7(对 224 输入来说)
x = self.avgpool(x) # 强制变成 N, 512, 7, 7(更稳)
x = torch.flatten(x, 1) # N, 512*7*7
x = self.classifier(x) # N, num_classes
return x
if __name__ == "__main__":
# 测试 VGG11 输入输出
model = B_VGG11_Paper(num_classes=1000)
x = torch.randn(2, 3, 224, 224)
y = model(x)
print("VGG16 输出形状:", y.shape) # torch.Size([2, 1000])
print(f"参数量: {b_get_params(model)}") # 132_863_336
# 测试 VGG13 输入输出
model = B_VGG13_Paper(num_classes=1000)
x = torch.randn(2, 3, 224, 224)
y = model(x)
print("VGG16 输出形状:", y.shape) # torch.Size([2, 1000])
print(f"参数量: {b_get_params(model)}") # 133_047_848
# 测试 VGG16 输入输出
model = B_VGG16_Paper(num_classes=1000)
x = torch.randn(2, 3, 224, 224)
y = model(x)
print("VGG16 输出形状:", y.shape) # torch.Size([2, 1000])
print(f"参数量: {b_get_params(model)}") # 138_357_544
# 测试 VGG19 输入输出
model = B_VGG19_Paper(num_classes=1000)
x = torch.randn(2, 3, 224, 224)
y = model(x)
print("VGG16 输出形状:", y.shape) # torch.Size([2, 1000])
print(f"参数量: {b_get_params(model)}") # 143_667_240项目实例
库环境:
numpy==1.26.4
torch==2.2.2cu121
byzh-core==0.0.9.21
byzh-ai==0.0.9.53
byzh-extra==0.0.9.12
...VGG训练MNIST数据集:
py
# copy all the codes from here to run
import torch
import torch.nn.functional as F
from uploadToPypi_ai.byzh.ai.Bdata import b_stratified_indices
from byzh.ai.Btrainer import B_Classification_Trainer
from byzh.ai.Bdata import B_Download_MNIST, b_get_dataloader_from_tensor
# from uploadToPypi_ai.byzh.ai.Bmodel.study_cnn import B_VGG16_Paper
from byzh.ai.Bmodel.study_cnn import B_VGG16_Paper
from byzh.ai.Butils import b_get_device
##### hyper params #####
epochs = 10
lr = 1e-3
batch_size = 32
device = b_get_device(use_idle_gpu=True)
##### data #####
downloader = B_Download_MNIST(save_dir='D:/study_cnn/datasets/MNIST')
data_dict = downloader.get_data()
X_train = data_dict['X_train_standard']
y_train = data_dict['y_train']
X_test = data_dict['X_test_standard']
y_test = data_dict['y_test']
num_classes = data_dict['num_classes']
num_samples = data_dict['num_samples']
indices = b_stratified_indices(y_train, num_samples//10)
X_train = X_train[indices]
X_train = F.interpolate(X_train, size=(224, 224), mode='bilinear')
X_train = X_train.repeat(1, 3, 1, 1)
y_train = y_train[indices]
indices = b_stratified_indices(y_test, num_samples//10)
X_test = X_test[indices]
X_test = F.interpolate(X_test, size=(224, 224), mode='bilinear')
X_test = X_test.repeat(1, 3, 1, 1)
y_test = y_test[indices]
train_dataloader, val_dataloader = b_get_dataloader_from_tensor(
X_train, y_train, X_test, y_test,
batch_size=batch_size
)
##### model #####
model = B_VGG16_Paper(num_classes=num_classes)
##### else #####
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
##### trainer #####
trainer = B_Classification_Trainer(
model=model,
optimizer=optimizer,
criterion=criterion,
train_loader=train_dataloader,
val_loader=val_dataloader,
device=device
)
trainer.set_writer1('./runs/vgg16/log.txt')
##### run #####
trainer.train_eval_s(epochs=epochs)
##### calculate #####
trainer.draw_loss_acc('./runs/vgg16/loss_acc.png', y_lim=False)
trainer.save_best_checkpoint('./runs/vgg16/best_checkpoint.pth')
trainer.calculate_model()