Alexis Marouani¹,² * Oriane Siméoni¹ Hervé Jégou¹ Piotr Bojanowski¹ Huy V. Vo¹
¹ FAIR, Meta
² LIGM, Ecole des Ponts, IPParis, UGE, CNRS, 77455 Marne-la-Vallée, France
摘要
视觉Transformer(Vision Transformers)已成为强大、可扩展且多功能的表征学习器。为了同时捕获全局和局部特征,通常会在patch token序列前添加一个可学习的CLS类别token。尽管这两种token具有本质差异,但在模型中它们被完全相同地处理。在本工作中,我们通过分析类别token与patch token之间的交互,研究了不同预训练策略下全局与局部特征学习之间的摩擦。我们的分析揭示:标准归一化层在注意力机制之前已隐式地对这两种token类型进行了区分。基于这一发现,我们提出了专门的处理路径,选择性地解耦CLS token与patch token的计算流,特别是在归一化层和早期的查询-键-值(QKV)投影中。这种有针对性的专门化显著提升了密集预测任务中patch表征的质量。实验表明,我们的方法在标准基准测试上将分割性能提升了超过2个mIoU点,同时保持了强大的分类准确率。所提出的修改仅引入8%的参数增加,且不增加额外的计算开销。通过全面的消融实验,我们深入分析了哪些架构组件最受益于专门化设计,以及该方法如何在不同模型规模和学习框架下实现泛化。
1 引言
近年来,在开发能够生成丰富且高度泛化视觉表征的视觉基础模型方面取得了显著进展。特别是,使用视觉Transformer(ViT)模型(Dosovitskiy et al., 2021)在多种范式下训练的模型取得了最新的最先进结果,包括全监督(Touvron et al., 2022)、弱监督(Radford et al., 2021; Bolya et al., 2025)和自监督学习(Zhou et al., 2021; Oquab et al., 2023; Siméoni et al., 2025)。这些模型捕获了广泛的视觉语义,能够在多样化的下游任务和数据域上实现稳健性能。
ViT架构(Dosovitskiy et al., 2021)通过将图像划分为固定大小的patch来处理图像,然后将这些patch嵌入并输入到一系列Transformer块中。通常,一个可训练的CLS token会被添加到patch embedding序列之前,旨在聚合所有patch的信息。Patch和CLS token以不同的目标进行训练(如果有的话)。例如,大多数预训练方法仅对CLS token应用损失函数(Chen et al., 2020; Grill et al., 2020; Caron et al., 2021; Radford et al., 2021; Touvron et al., 2022);有些方法仅对patch token应用目标(He et al., 2022);而其他方法则对CLS和patch token使用独立的损失(Zhou et al., 2021; Oquab et al., 2023; Siméoni et al., 2025)。无论具体的训练范式如何,近期工作(Darcet et al., 2023; An et al., 2025; Siméoni et al., 2025)表明,CLS与patch token之间存在持续的不平衡。提出的解决方案包括在输入序列中引入额外的存储token(Darcet et al., 2023)、修改注意力机制(An et al., 2025),或引入额外的损失项以显式约束patch的局部性(Siméoni et al., 2025)。相比之下,我们假设这种不平衡源于模型通过相同的计算管道处理CLS和patch token,尽管它们具有根本不同的角色和性质,并提出解耦它们的处理方式以克服这种不平衡。
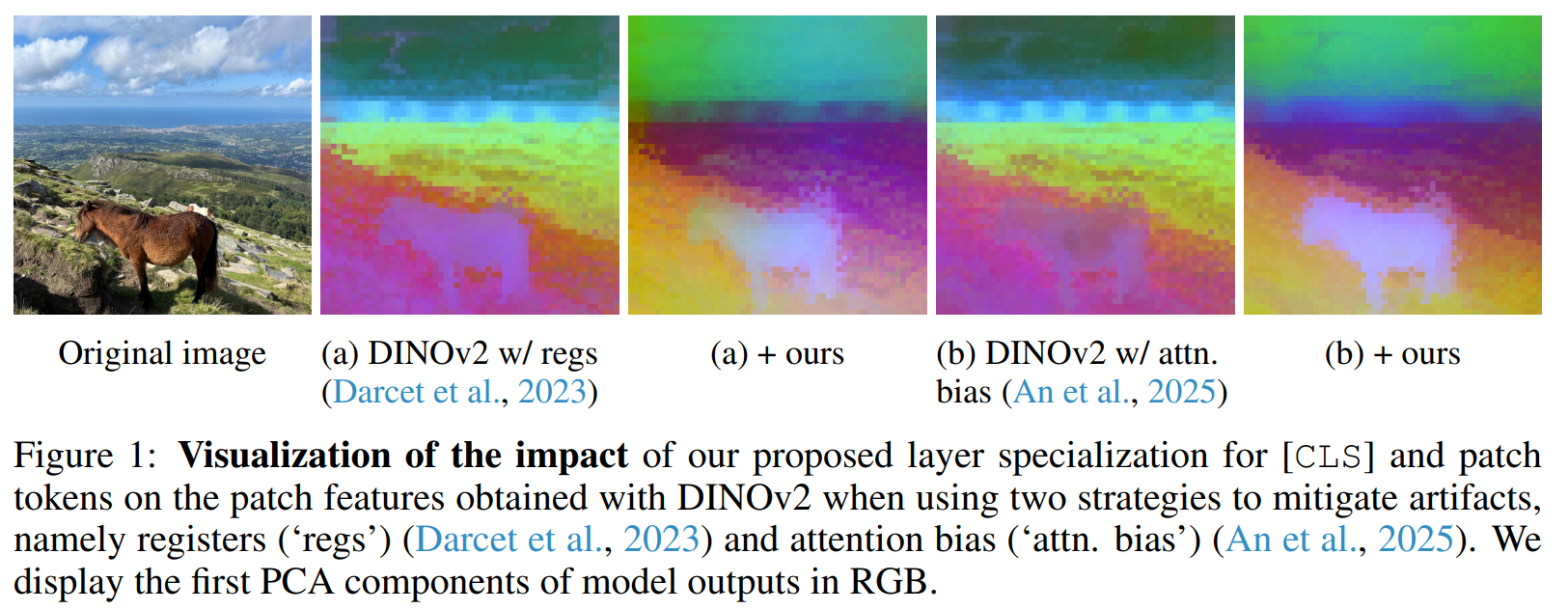
在本工作中,我们通过分析模型统计特性来更好地理解控制CLS与patch token交互的内部机制。我们的分析揭示了一个令人惊讶的发现:归一化层已经在注意力机制之前隐式地学习区分CLS与patch token。基于这一洞察,我们引入了一种简单而有效的架构修改,显式地分离CLS与patch token的处理(如图5所示)。仅通过最小集合的专门化层,我们的方法就产生了明显更丰富的密集特征(见图1),并在密集预测任务上带来了实质性提升。例如,我们在ViT-L模型上将分割基准测试的平均mIoU分数提升了高达2.2点。本工作揭示了Transformer模型内部的隐藏动态,同时也展示了有针对性的架构变更如何转化为显著的实际性能提升。我们的主要贡献如下:
- 我们分析了Vision Transformers中CLS与patch token之间的交互,并表明模型通过归一化层隐式尝试区分它们。
- 我们提出了一种架构修改,专门化它们的计算以减少它们之间的摩擦,同时保持操作数量不变。我们研究了Transformer块不同组件的专门化策略。
- 我们证明了该方法在不同模型规模和学习框架下的泛化能力,在不损害分类性能的前提下显著提升了密集预测任务的性能。
2 相关工作
视觉Transformer 受Vaswani et al. (2017)启发并由Dosovitskiy et al. (2021)首次引入,Vision Transformer已成为构建视觉模型的首选架构。典型的ViT模型由patch嵌入器和一系列Transformer块组成。给定一幅图像,patch嵌入器将其划分为等大小的方形patch,并将它们转换为表示图像中局部信息的patch token。可选地,一个可学习的CLS token会被添加到patch token集合中,以捕获全局信息。所有token随后通过Transformer块进行处理,这些块使用各种变换(尤其是多头自注意力操作符(Vaswani et al., 2017))对它们进行处理,该操作符允许token相互关注。在原始架构基础上,后续工作引入了额外组件以改进ViT的各个方面,如数据效率(Touvron et al., 2020; Yuan et al., 2021)、计算成本(Liu et al., 2021; Bolya et al., 2023)和归一化(Touvron et al., 2021)。ViT架构已在各种任务中实现了最先进性能(Carion et al., 2020; Strudel et al., 2021),简化了多模态学习(Radford et al., 2021; Fini et al., 2024),并为基础模型带来了优异的局部和全局表征(Oquab et al., 2014; Tschannen et al., 2025; Siméoni et al., 2025)。在大多数ViT中,CLS和patch token在Transformer块中功能上是可互换的------它们使用相同的操作符以完全相同的方式被处理------尽管它们具有不同的本质。我们的分析表明,对这些token的相同处理是次优的,解耦它们可以带来更好的局部特征用于密集任务。
改进密集特征学习 视觉表征学习方法主要集中在通过主要训练CLS token来优化全局表征,以在监督(Touvron et al., 2022)、弱监督(Radford et al., 2021; Tschannen et al., 2025)或自监督设置(Caron et al., 2021; Liu et al., 2021)下总结图像内容。作为副产品,它们也产生了在需要细粒度特征的任务(如目标检测、语义分割或深度估计)上表现良好的局部表征。最值得注意的是,自监督方法DINO(Caron et al., 2021)产生了优异的patch特征,极大地推动了无监督目标检测和分割的研究。iBoT(Zhou et al., 2021)通过掩码图像建模(He et al., 2022)增强了DINO,以同时优化全局和局部表征。DINOv2(Oquab et al., 2023)引入了Sinkhorn-Knopp中心化和解耦头等新技术组件,成功将DINO扩展到大型数据集和模型规模,在密集任务上取得了优异性能。使用Vision Transformers学习有意义的密集特征并非没有挑战。Darcet et al. (2023)讨论了在长时间训练期间大规模训练模型产生的噪声注意力图问题。这一问题导致patch token在被模型重新用于存储全局信息后失去其局部上下文,从而降低密集预测性能。他们提出了带寄存器(registers)的架构解决方案来缓解这些问题。其他成功增强局部特征质量的尝试包括训练后正则化邻近patch的相似性(Pariza et al., 2024)或通过Gram锚定机制恢复patch相似性(Siméoni et al., 2025)。与这些工作类似,我们在训练过程中通过专门化ViT中Transformer块内的CLS和patch token处理来改进密集特征质量,从而减少它们之间的摩擦。
3 CLS与Patch之间的摩擦
视觉Transformer通常使用一个可训练的CLS token进行训练,该token编码图像的全局信息,并被添加到patch token序列之前。尽管CLS和patch token具有不同的本质,当前模型却同等对待它们,对两者应用完全相同的操作。然而,Darcet et al. (2023)强调了这两种token类型之间潜在的通信问题,导致patch token的局部性严重丧失以及注意力图中出现不良异常值。虽然寄存器有助于缓解伪影的出现,但我们认为还可以做得更多。我们的观察表明,CLS与patch token之间仍存在一定程度的摩擦,如下所述。
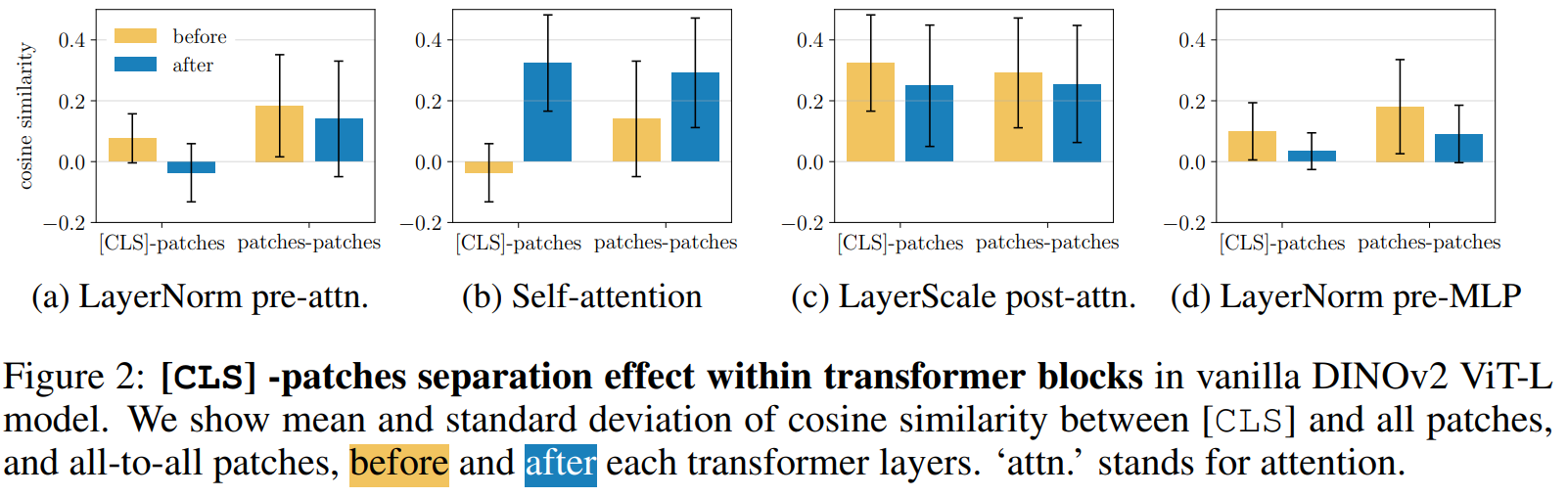
ViT通过注意力区分CLS和patch token 我们通过计算模型内不同位置(每个Transformer块中主要层之前和之后)的相似性来分析CLS与patch token之间的相互作用。在图2中,我们可视化了这些相似性的均值和标准差。我们的结果在1000幅图像的patch上以及所有模型块上取平均。此外,我们还展示了patch之间的相同统计量。虽然某些操作(如注意力后应用的LayerScale)对CLS与patch token之间的相似性影响很小,但自注意力层显著增加了它们的相似性。这种增加是预期的,因为自注意力重新对齐了不同类型的token。然而,我们的分析揭示了一个令人惊讶的现象:CLS与patch token的表征在计算管道的特定阶段(特别是在注意力操作之前)自然地产生分歧。实际上,注意力前应用的LayerNorm大幅降低了CLS与patch token之间的相似性,使其接近零。这种隐式区分表明,尽管共享参数化,模型在注意力机制之前尝试适应这些token类型的不同功能角色。我们在附录A.2中展示了更多层的统计量。
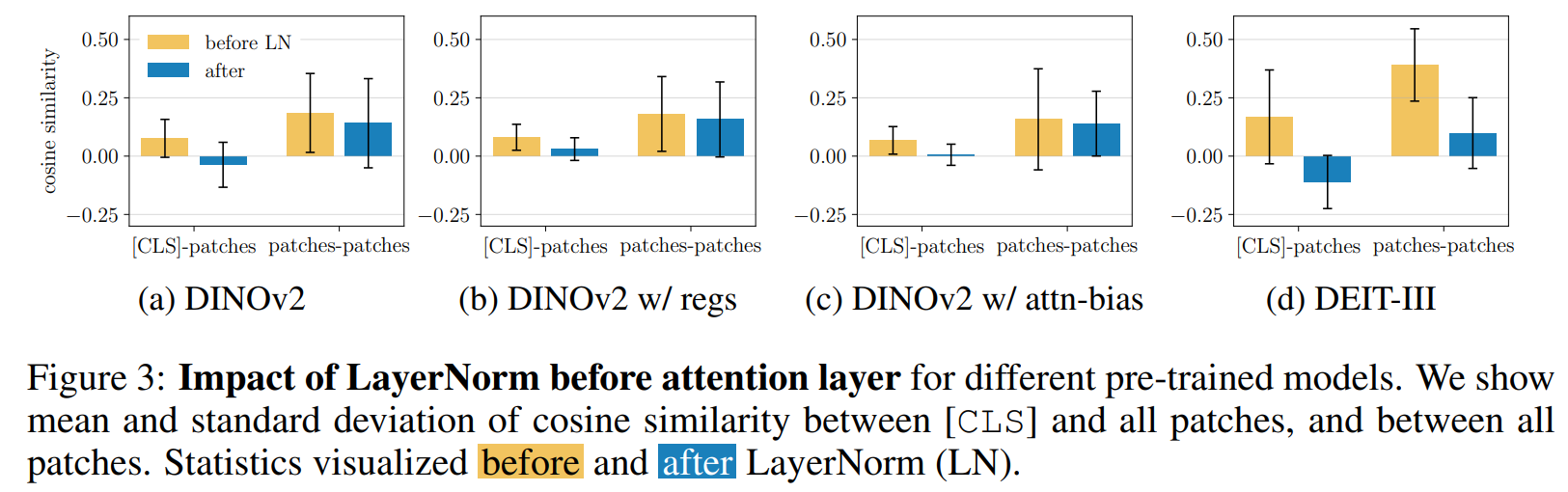
注意力前LayerNorm的作用 在图3中,我们聚焦于注意力前LayerNorm对不同预训练模型(包括DINOv2(Oquab et al., 2023)及其带寄存器(Darcet et al., 2023,记为'regs')和注意力偏置(An et al., 2025,记为'attn. bias')的变体,以及监督式DEIT-III(Touvron et al., 2022))中CLS与patch token相似性的影响。可以观察到,在所有情况下,在注意力机制之前,LayerNorm解耦了CLS与patch token,使它们能够在注意力过程中发挥不同功能。这种现象出现在所有预训练模型中,程度不同。例如,LayerNorm在DINOv2和DEIT-III中强烈强制CLS与patch之间产生负相关,而在DINOv2的变体中将相关性保持在接近零的水平。相比之下,patch token之间的相似性保持为正且 largely 稳定,仅观察到轻微下降------我们将其解释为正则化效应。这种效应可能防止秩崩溃并促进token在单位球面上更均匀的分布,与Wu et al. (2024)的观察一致。
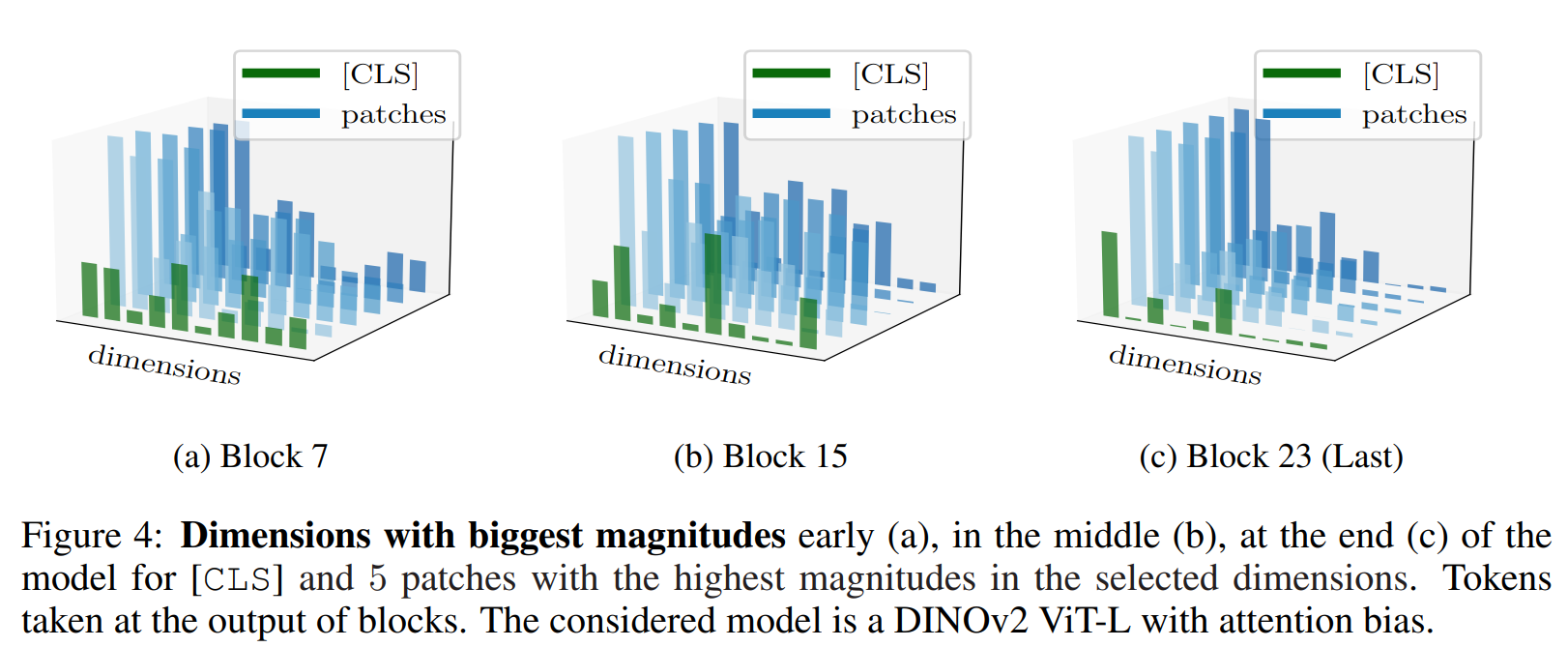
维度分离 为了理解分离效应如何在LayerNorm层中出现,必须回顾它执行逐点归一化和维度级仿射变换。因此,当输入在每个维度上具有非常不同的幅度时,就会出现分离效应。在图4中,我们绘制了在不同块输出处具有最大绝对幅度的维度(在patch和CLS上取平均)。我们观察到,某些特定维度仅被某种token类型利用。例如,在图4c中,第2维对patch呈现大幅度值,而对CLS几乎为零。此外,模型越深,共享维度的token类型越少。这使得归一化层能够执行区别性操作。它们不仅仅是正则化,还专门化并分离token。
上述所有观察表明,同等对待CLS和patch token迫使模型分配资源来隐式分离它们,而这些资源本可用于学习更有意义的特征。我们认为,解耦它们的处理将有助于模型学习更好的表征,如下一节所述。
4 CLS-Patch专门化:分析
在本节中,我们首先在4.1节定义提出的层专门化,在4.2节设置实验环境。在4.3节中,我们讨论为CLS和patch token拆分归一化的益处。我们还在4.4节中研究模型的哪部分需要专门化,更具体地在4.5节中研究哪些层需要专门化。
4.1 我们的提案:层专门化
基于前一节的观察,我们探索在ViT中解耦全局和局部表征的计算。受双流架构成功处理不同模态的启发(Esser et al., 2024),我们为CLS和patch token探索了类似方法。更具体地说,在经典Transformer块内部,CLS和patch token经过若干层:投影、一些归一化和MLP。我们提出通过为某些层使用不同权重来解耦CLS和patch token。实际上,我们不是使用单一层处理两种token类型,而是引入两个具有各自权重集的不同层------每个层专门用于CLS或patch token。这允许每层更好地捕获其相应token类型的独特特征。然而,token继续通过注意力机制正常交互,确保CLS与patch token之间的信息流得以保留。图5展示了这种专门化架构的示意图。虽然这种方法引入了一些额外的内存开销,但我们的实验表明,当选择性地应用层专门化以实现最佳性能时,模型大小的增加很小------约8%。更重要的是,层专门化不增加推理FLOPs,因为模型在推理期间继续执行相同的计算操作。这确保了即使我们通过有针对性的专门化增强模型的表征能力,模型的效率也得以保持。
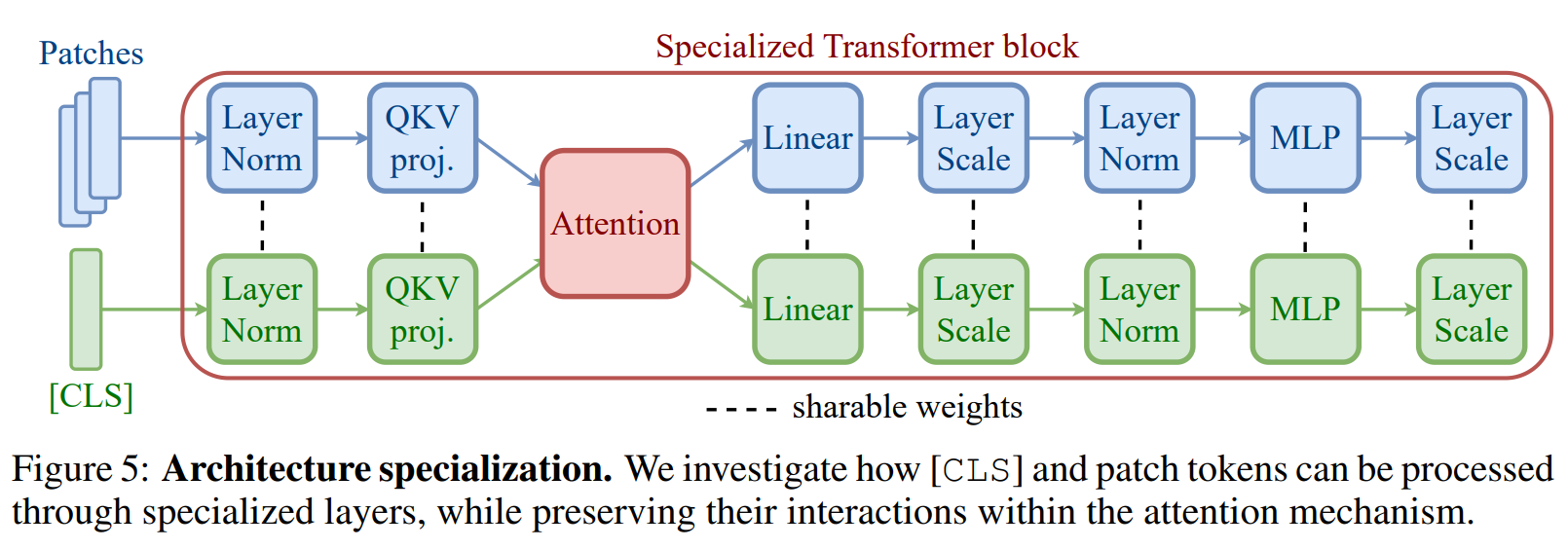
4.2 实验设置:训练与评估
训练 我们使用不同的预训练范式研究层专门化,包括流行的自监督策略DINOv2(Oquab et al., 2023)和全监督DeiT-III(Touvron et al., 2022)。我们还研究了不同模型规模(ViT-B, L, H)。除非另有说明,我们使用按照DINOv2方案训练的ViT-L模型生成结果。遵循An et al. (2025),我们在所有模型和注意力操作中集成了注意力偏置策略,该策略在不引入额外token的情况下缓解高范数异常(Darcet et al., 2023)。更多讨论见附录A.1。对于DINOv2,我们在ImageNet-22K(Ridnik et al., 2021)数据集上训练模型600k步。对于DeiT-III,我们在ImageNet-1K(Deng et al., 2009)上分别训练ViT-B 400个epoch和ViT-L 800个epoch。对于两种训练范式,我们都仅进行第一阶段预训练,省略高分辨率微调步骤。更多细节见附录A.3。
评估 遵循Oquab et al. (2014),我们通过在全局任务(ImageNet-1k(Deng et al., 2009))和密集预测任务上的线性探测来评估模型表征。对于语义分割,我们使用ADE20K(Zhou et al., 2017)、Cityscapes(Cordts et al., 2016)和PASCAL VOC(Everingham et al., 2010),报告mIoU。对于深度估计,我们使用KITTI(Geiger et al., 2013)、NYU Depth v2(Nathan Silberman & Fergus, 2012)和SUN RGB-D(Song et al., 2015),报告RMSE。对于检测,我们使用COCO(Lin et al., 2014),报告AP。某些表格显示了相应基准测试上分割和深度分数的平均值。更多细节见附录A.3。
4.3 专门化归一化层
如第3节所述,ViT尝试通过注意力操作前应用的LayerNorm分离CLS和patch token。基于这一观察,我们的初始实验专注于专门化模型中的归一化层(LayerNorms和Layer Scales),旨在进一步支持模型固有的分离这些特征类型的倾向。
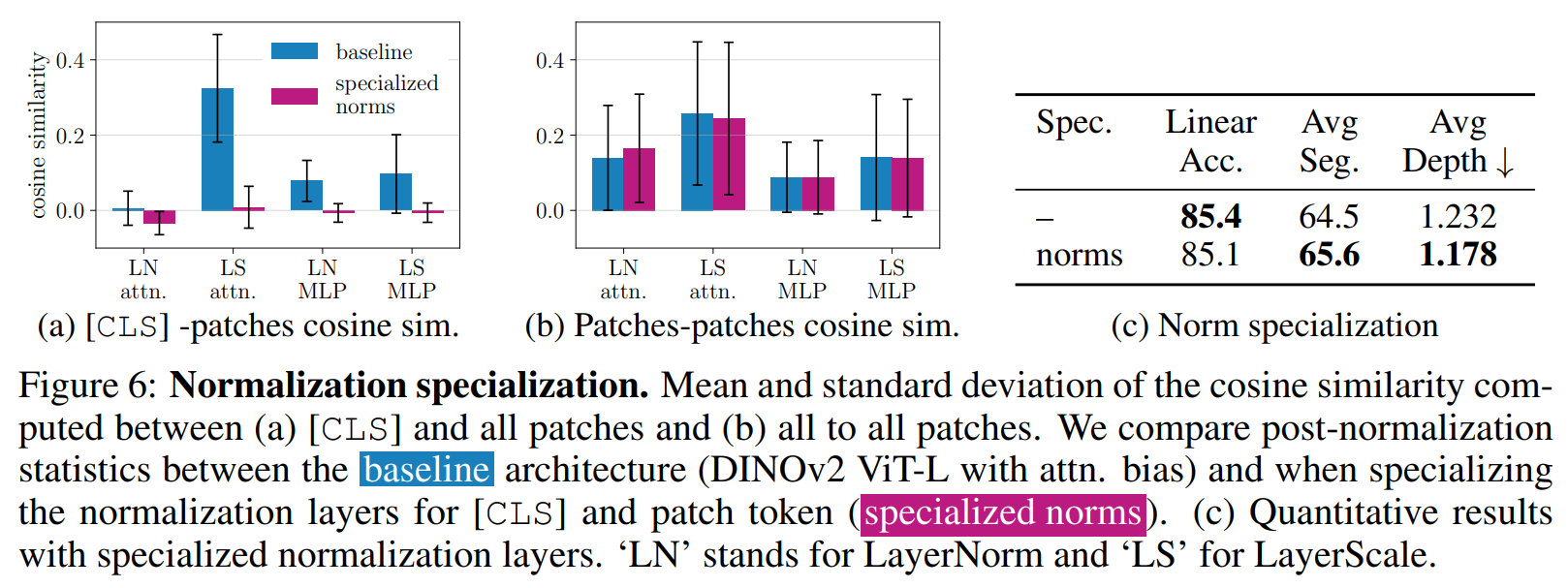
我们在模型的所有块中专门化归一化层。这种轻量级修改仅引入0.05%的额外参数,却显著改变了特征分布。在图6a中,我们报告了在每个归一化层后计算的CLS与所有patch之间余弦相似性的均值和标准差。我们将具有专门化归一化权重的变体与基线进行比较。相反,图6b展示了使用所有patch而非CLS时的相应统计量。我们观察到,专门化归一化层进一步放大了CLS与patch token的解耦,导致每次归一化步骤后它们的嵌入产生更明显的分离。
这些专门化归一化的影响在图6c中量化。专门化在密集预测任务上带来显著改进,在分割基准测试上平均增加+1.1个mIoU点,在深度估计上改进-0.054m。这些结果突显了token类型的更好专门化有利于patch表征。另一方面,全局结果略有下降。然而,我们在下一节中展示这种损失可以缓解。除非另有说明,在本文其余部分,我们在所有Transformer块中应用专门化的归一化层。
4.4 块级目标专门化
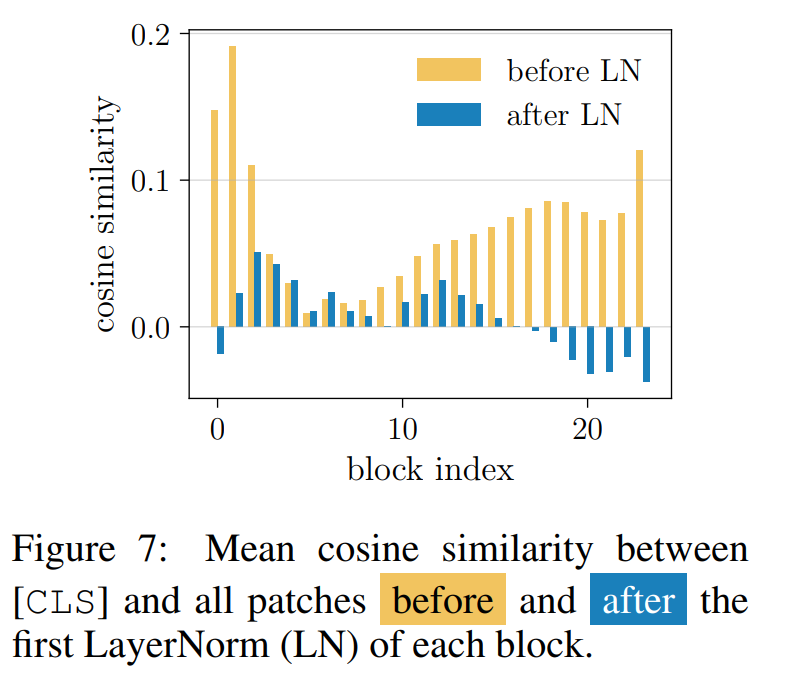
虽然ViT中的归一化层总体上显示出CLS-patch分离效应,但我们观察到其影响程度在所有块中并不均匀。从图7可以看出(该图描绘了每个块中第一个LayerNorm之前和之后的CLS-patch余弦相似性),归一化的分离效应取决于其在模型中的位置。实际上,模型开头和接近结尾的块受到的影响最大。我们认为早期块中分离的重要性源于它们靠近不同输入。尽管CLS token被训练为从patch中汇总信息,但它被初始化为学习参数,因此具有与patch token非常不同的输入分布。在模型后期,当token更接近最终表征和训练目标时,分离再次变得重要。上述观察表明,我们可以在模型内受益于更有针对性的专门化。接下来我们研究应专门化哪些块以优化模型性能。
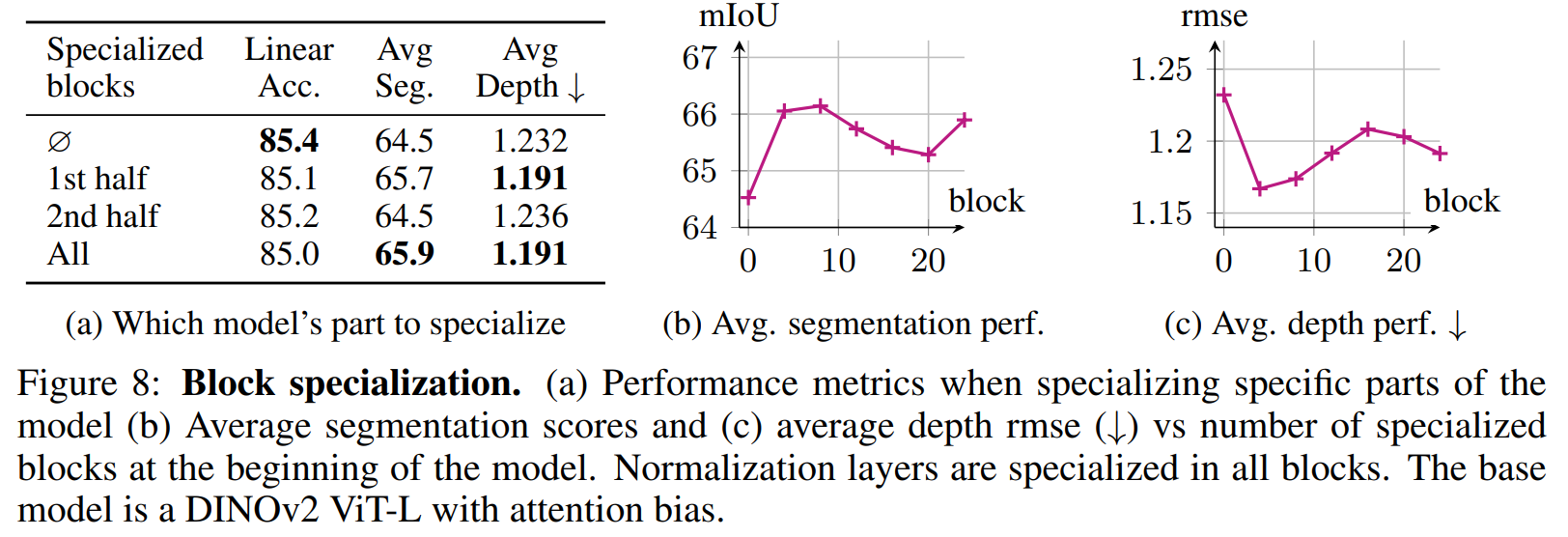
我们首先定量比较专门化模型不同部分的影响,如图8a所示。为此,我们在DINOv2训练期间专门化前半部分、后半部分或所有Transformer块(在专门化所有归一化层的基础上)。在一个块内,所有层都被专门化。我们的发现表明,专门化靠近输入的早期层可获得最佳性能。具体而言,专门化前半部分层将分割结果平均提高1.2个mIoU点,而线性准确率仅略有下降。相比之下,专门化后期层与基线相比没有改进。我们将此归因于CLS和patch token在前半部分共享表征空间的事实;一旦这种交互建立,进一步专门化效果有限。最后,虽然专门化所有层产生最高的分割性能,但它带来更高的内存成本和更大的线性准确率下降。
我们进一步分析从开头开始专门化的块数量如何影响性能(图8b和8c)。我们将专门化块的数量从0变化到24(ViT-L中的总块数),步长为4,观察到专门化模型前三分之一可获得最佳结果,而专门化后期层会降低性能。值得注意的是,模型深度三分之一处的最佳点与图7中相似性分数统计量的显著转变相吻合,这可能解释了专门化早期层的有效性。
4.5 Transformer块内的目标专门化
前一节表明,仔细选择要专门化的Transformer块对于优化性能很重要。我们现在探索是否可以通过在Transformer块内有针对性地选择要专门化的特定层来实现进一步改进。在以下实验中,我们在模型前三分之一的块中专门化不同层,同时在所有块中应用归一化层的专门化。
表1显示了在不同层专门化策略下模型在全局和密集预测任务上的性能(QKV投影、Linear和MLP,见图5)。我们观察到,全局任务的性能在很大程度上独立于所选层而保持稳定。相比之下,密集分割任务的结果在仅归一化专门化的基础上获得了进一步改进。有趣的是,收益并不随专门化层数量或额外参数的增加而单调增加,这与典型的缩放定律(Touvron et al., 2021)预期不同。专门化QKV和/或注意力后投影 consistently 带来改进。特别是,专门化QKV投影带来的收益最大,它仅引入8%的额外参数,同时在归一化基础上平均增加+1个mIoU点。相比之下,专门化注意力后投影没有带来额外收益,而MLP层的专门化要么无效要么对性能产生负面影响。注意,我们可以通过在专门化QKV投影时使用低秩适应(Low Rank Adaptation)来缓解这8%的内存成本开销。我们在附录A.5中用不同秩生成了鼓舞人心的初步结果,并将深入研究留作未来工作。
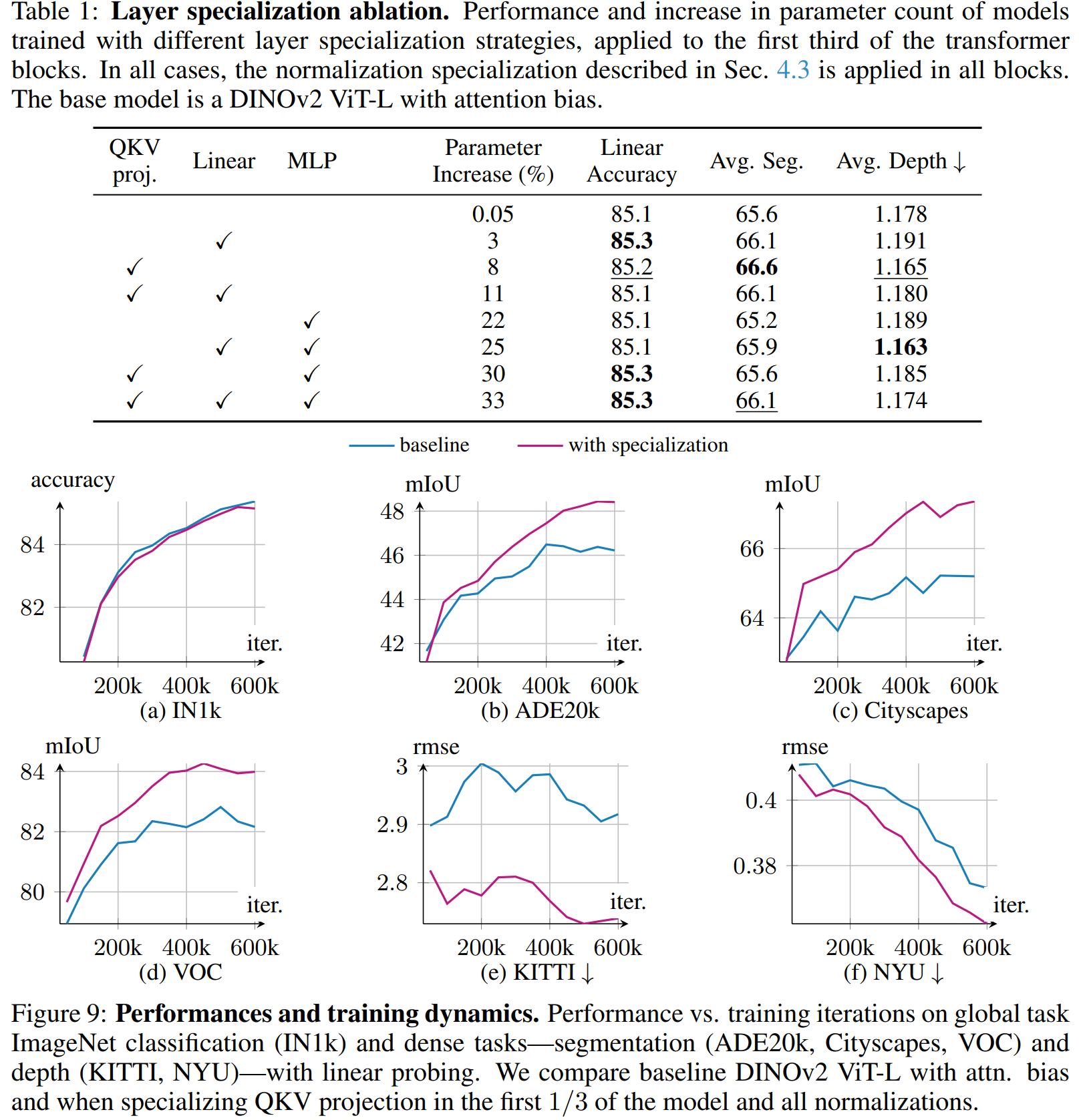
我们的整体结果表明,在注意力机制之前增加CLS与patch token之间的解耦(通过分离的归一化和投影)有助于改进密集预测性能。我们假设,鼓励CLS和patch token在注意力机制中承担更不同的角色可以增强它们的交互,最终提高整体模型有效性。我们还在附录A.6中报告了仅专门化QKV投影而归一化层保持共享的设置结果。在此配置中,性能与基线相当,表明归一化层的专门化对于实现改进至关重要,如4.3节所示。
在图9中,我们将归一化和QKV投影专门化的性能动态与基线DINOv2(带注意力偏置)进行比较。在所有密集基准测试上------包括分割和深度估计------专门化 consistently 增强了结果。这些改进在训练早期阶段就很明显,并随时间持续增加。这一趋势表明,采用专门化不仅提升了性能,还有助于更稳定的训练动态。
4.6 泛化结果
我们研究了专门化方法在DINOv2不同变体上的泛化能力,结果呈现在表2上部。具体而言,我们使用DINOv2方案训练模型,采用两种高范数处理策略------寄存器(Darcet et al., 2023)("4 registers")和注意力偏置(An et al., 2025)("attn. bias")------以及无任何处理策略。在所有情况下,我们观察到专门化 consistently 提升密集预测结果,在ADE20k上最高提升4.8%,而对分类性能影响可忽略(下降不超过0.2%)。这表明更好地分离CLS和patch token的处理与两种高范数处理策略互补,以改进密集特征。我们还在表2中部研究了DINOv2 ViT-B和ViT-H模型上的专门化。可以看出,我们提出的专门化在大多数基准测试上带来改进,证实了其在不同ViT模型规模上的泛化能力。
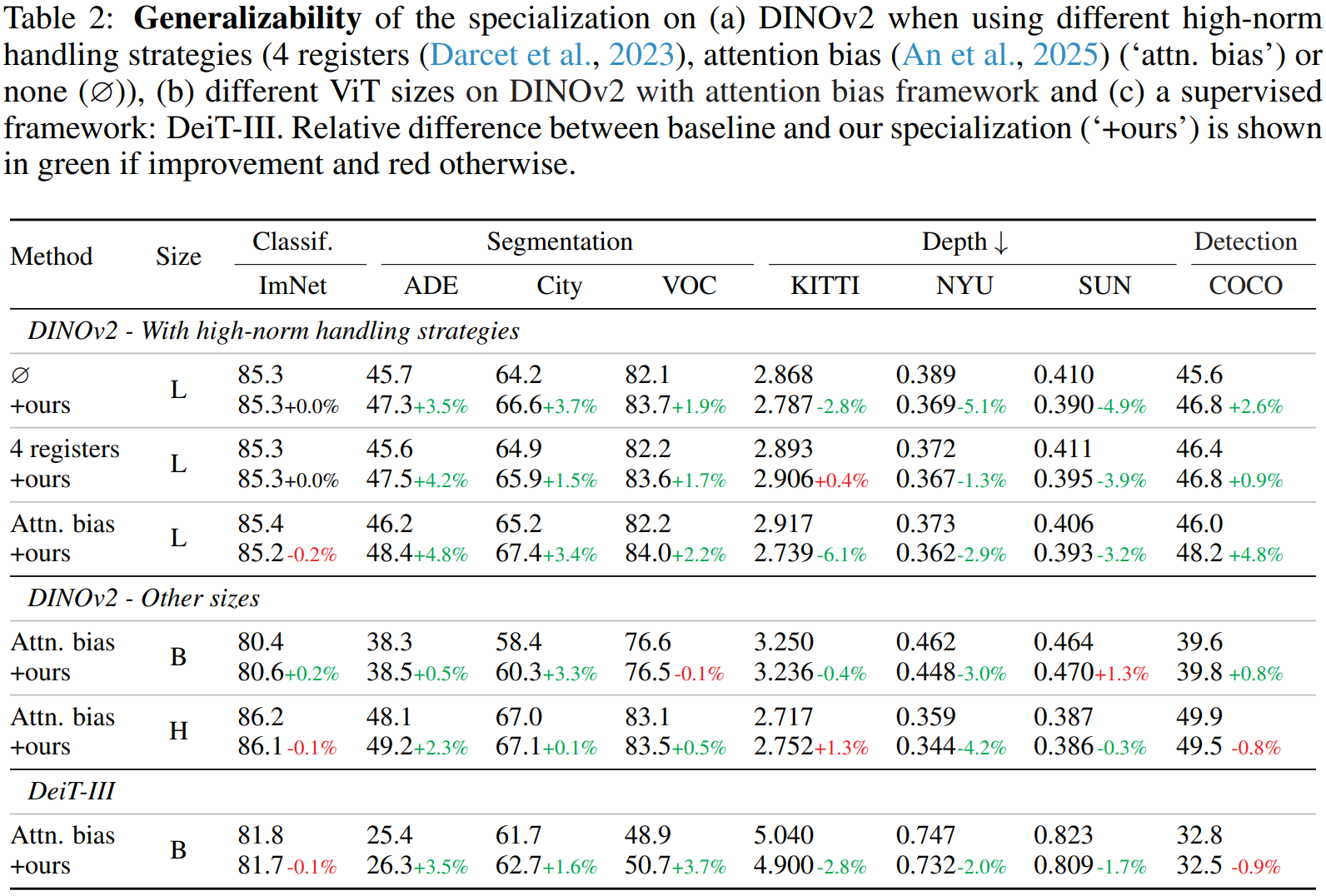
我们进一步探索全监督训练设置,将专门化应用于使用DEIT-III(Touvron et al., 2022)策略训练的ViT-B。我们观察到密集预测任务的一致改进,在VOC上收益高达3.7%。对于ViT-L,专门化未带来收益,可能由于训练动态与缺乏引导密集特征学习的局部损失有关,导致密集性能随时间下降(更多细节见附录A.7)。这些结果表明,专门化的有效性可能取决于训练目标,为未来研究指明了有前景的方向。
最后,我们在图1中使用PCA可视化学习到的patch表征,针对使用寄存器或注意力偏置训练的DINOv2模型。在两种设置下,结合我们的专门化策略都产生了更清晰、语义更有意义的patch表征。具体而言,该方法减少了纹理和均匀区域中的伪影,从而实现更准确的目标分割。更多可视化见附录A.8。
4.7 更多比较
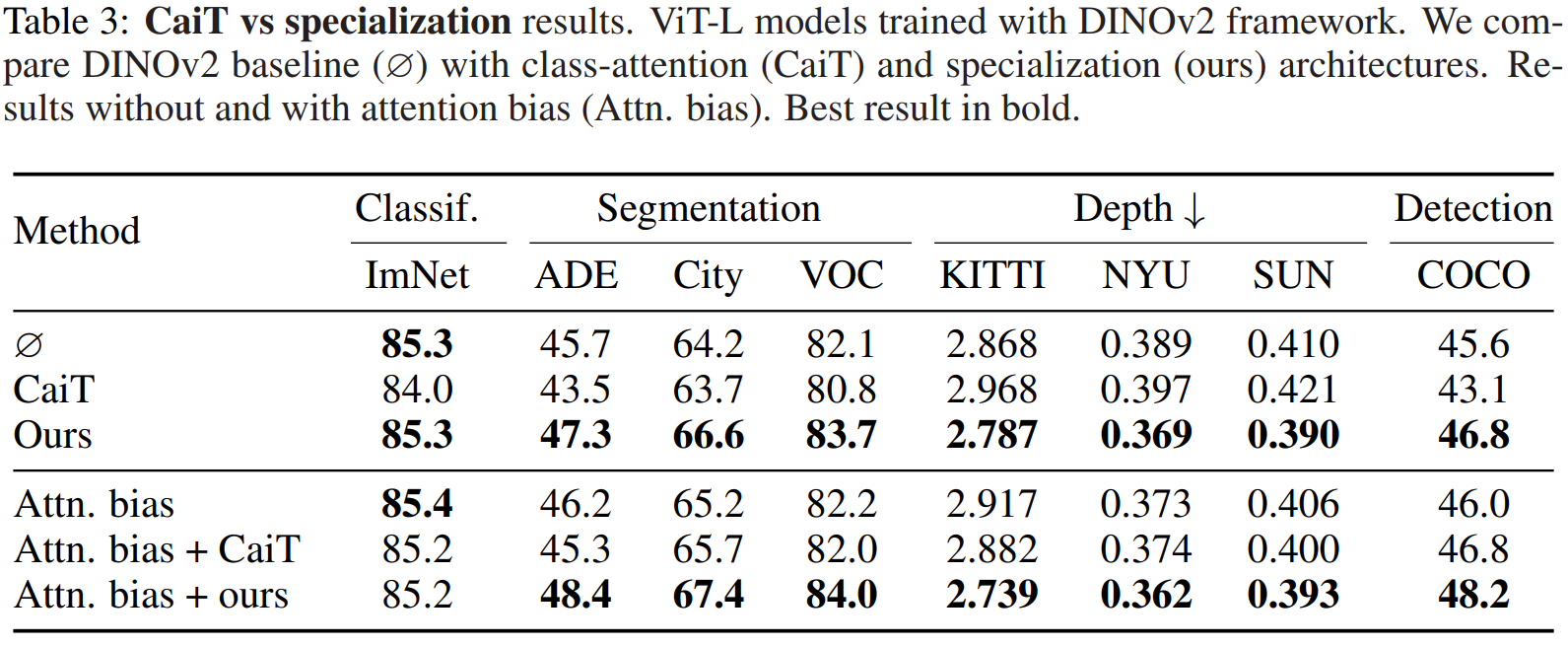
我们将专门化方法与CaiT(Touvron et al., 2021)中的类别注意力机制进行比较,结果见表3。我们按照DINOv2框架训练两种模型,有无注意力偏置。在CaiT架构中,patch token通过Transformer块处理,然后附加CLS并通过2个类别注意力层更新,以聚合最后一个块的patch token信息。我们在表3中报告结果,观察到我们的专门化在所有下游任务上 consistently 优于类别注意力机制。
5 结论
在本工作中,我们研究了Vision Transformers中CLS与patch计算的解耦,重点关注它们的不同角色和交互。通过全面分析,我们证明了解耦它们的处理路径并选择性地专门化架构层可在密集预测任务(包括分割和深度估计)上带来显著改进,同时保持强大的全局性能。我们的方法在不增加计算开销的情况下实现这些收益,仅需最小的额外参数成本,并在多种ViT架构和框架上实现泛化。这些发现突显了定制化架构设计的重要性,并为未来研究指明了有前景的方向,包括进一步探索高效专门化策略以及在更广泛模态和任务上的应用。
附录
A 附录
A.1 处理Token交互异常
在本工作中,我们研究了CLS token与patch token的不同角色如何影响它们在模型内部的交互。先前工作(Darcet et al., 2023; Sun et al., 2024)表明,尽管共享计算路径,这些不同类型的token会发展出相互依赖关系,可能导致token异常,表现为patch特征空间中的高范数异常值(high-norm outliers)。这些异常表明全局表征与局部表征之间信息流动存在潜在张力。
寄存器(Registers) 为缓解在不同预训练策略下观察到的此类伪影(Oquab et al., 2023; Touvron et al., 2022; Radford et al., 2021),Darcet et al. (2023)提出在输入序列中添加可学习的寄存器token,其作用是在patch与CLS token的内部通信中替代高范数patch。这样做可缓解此类伪影的出现并提升整体结果。
注意力偏置(Attention bias) An et al. (2025)近期关于大语言模型中伪影的研究调查了系统性出现的异常值,他们将其与注意力机制联系起来。他们提出的解决方案是在每个注意力头的键(keys)和值(values)中添加可学习偏置。他们分析了该方案与寄存器方案的等价性。
表4:范数处理策略对DINOv2结果的影响
| 范数处理方法 | IN | ADE | City. | NYU↓ |
|---|---|---|---|---|
| 无 | 85.3 | 45.7 | 64.2 | 0.389 |
| 4个寄存器 | 85.3 | 45.6 | 64.9 | 0.372 |
| 注意力偏置 | 85.4 | 46.2 | 65.2 | 0.373 |
在我们的实验中,我们观察到两种策略对高范数伪影具有相似影响。如表4所示,使用注意力偏置('attn. bias')策略可获得最佳整体性能,在分割基准测试上(如ADE20k和Cityscapes)有显著提升。为最小化可能影响CLS与patch token交互的混杂因素,我们采用注意力偏置策略,该策略可在不引入额外token的情况下缓解高范数异常。
A.2 其他层对CLS-Patch相似性的影响
我们在图10中报告了Transformer块内MLP层和MLP后LayerScale层对CLS-patch相似性的影响。与自注意力层类似,MLP层增加了CLS与patch之间的相似性,因为它对齐了特征。MLP后的LayerScale层与其它归一化层类似,显示出更强的解耦效应。
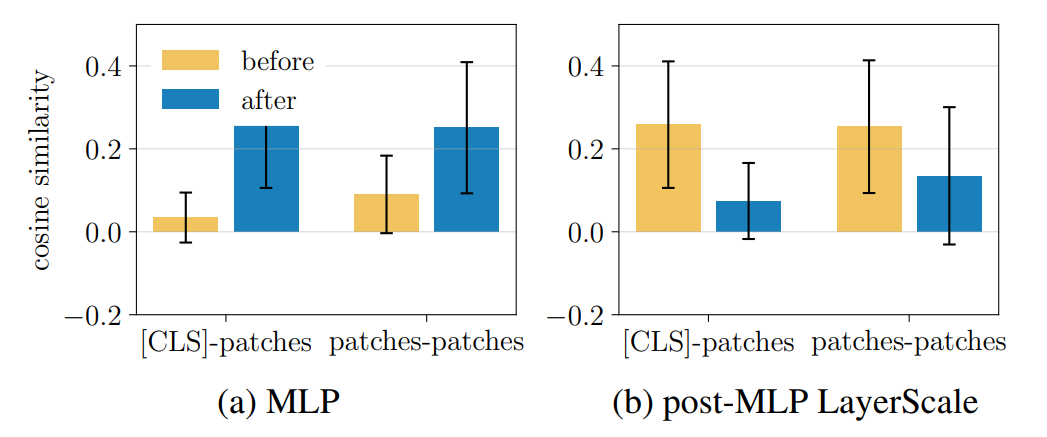
图10:MLP层和MLP后LayerScale层对标准DINOv2预训练模型中CLS-patch相似性的影响。我们展示了CLS与所有patch之间('CLS-patches')以及patch之间('patches-patches')余弦相似性的均值和标准差,分别在所考虑层之前和之后计算。
A.3 训练与评估细节
在本工作中,我们遵循Oquab et al. (2023)的实验协议,在一组全局任务和密集预测任务基准测试上评估训练模型的性能。
分类任务 对于全局任务,我们在ImageNet分类(Deng et al., 2009)上执行线性探测。我们使用SGD优化器训练线性层12500次迭代,采用随机调整大小裁剪(random-resized-crop)数据增强,并以CLS token作为线性层的输入。我们还对学习率进行以下网格搜索:{1.0e−5,2.0e−5,5.0e−5,0.0001,0.0002,0.0005,0.001,0.002,0.005,0.01,0.02,0.05,0.1}\{1.0e^{-5}, 2.0e^{-5}, 5.0e^{-5}, 0.0001, 0.0002, 0.0005, 0.001, 0.002, 0.005, 0.01, 0.02, 0.05, 0.1\}{1.0e−5,2.0e−5,5.0e−5,0.0001,0.0002,0.0005,0.001,0.002,0.005,0.01,0.02,0.05,0.1}。然后我们报告在验证集上获得的最高准确率值,这是常见做法。
分割任务 对于语义分割,我们使用ADE20K(Zhou et al., 2017)、Cityscapes(Cordts et al., 2016)和VOC(Everingham et al., 2010),并报告每个数据集的平均交并比(mIoU)分数。当我们报告分割任务的平均性能时,我们在上述3个数据集上取分数平均值。我们在每个基准测试的训练集上以1e−31e^{-3}1e−3的学习率训练线性分类器40000次迭代。该线性层应用于冻结主干网络的patch输出特征(最后一层归一化之后)之上,特征进一步通过训练的批归一化(batch normalization)层进行归一化。
深度估计 对于深度估计,我们在KITTI(Geiger et al., 2013)、NYU Depth v2(Nathan Silberman & Fergus, 2012)和SUN RGB-D(Song et al., 2015)上进行评估,报告平均均方根误差(RMSE)分数。当我们报告密集任务的平均性能时,我们在上述3个数据集上取分数平均值。我们在每个基准测试的训练集上以1e−31e^{-3}1e−3的学习率训练线性分类器38400次迭代。对于该线性层的输入,我们取主干网络中四个均匀间隔层的patch和CLS输出特征,不应用最后一层归一化。
检测任务 对于检测任务,我们在COCO(Lin et al., 2014)上进行评估,报告平均精度(AP)分数。我们在Plain-DETR实现(Lin et al., 2023)基础上进行训练,使用官方仓库提供的配置。更具体地说,我们使用RPE DETR模型训练12个epoch,线性学习率为0.0002,预热步数为1000步。与默认配置相比,并遵循Simeoni et al. (2025)的评估框架,我们保持ViT编码器冻结。
使用DINOv2和DeiT-III模型训练时,我们遵循官方仓库提供的默认配置,并进行修改以在注意力中添加偏置并专门化层或块。
使用CaiT训练时,我们遵循Touvron et al. (2021)提供的默认架构,并使用DINOv2的自监督框架训练模型。我们使用与DINOv2实验相同的超参数。
A.4 DeiT-III中归一化层的专门化
我们在图11中报告了使用DeiT-III预训练策略时归一化层专门化的影响。与DINOv2情况类似,采用专门化归一化后,CLS-patch平均余弦相似性显著降低,显示出解耦效应。
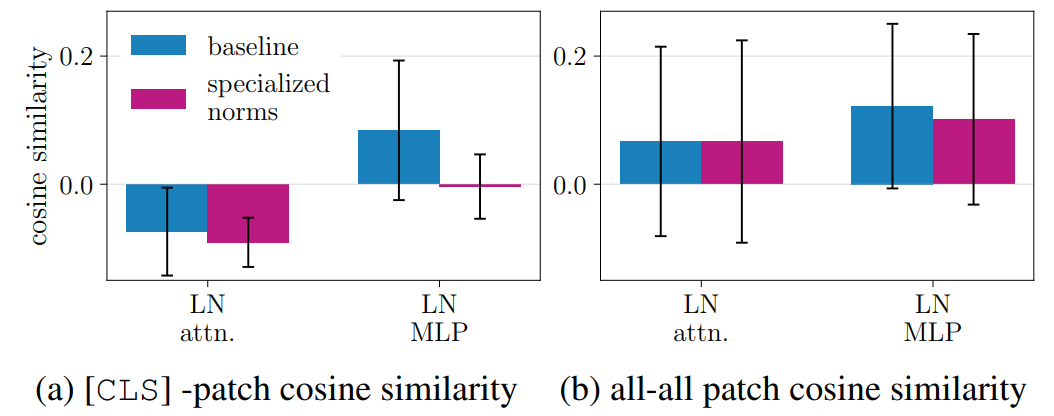
图11:归一化层的专门化。计算CLS与所有patch之间(a)以及所有patch之间(b)的余弦相似性均值和标准差。平均值在1000幅图像和所有模型块上计算。我们将标准架构('Baseline')与归一化专门化后模型('Specialized norms')的归一化后统计量进行比较。'LN'代表LayerNorm,'LS'代表LayerScale。
A.5 LoRA近似
由于参数增加可能成为训练效率的瓶颈,我们探索使用低秩自适应(Low-Rank Adaptation, LoRA)(Hu et al., 2022)技术来减少可训练参数数量,同时保持性能。此外,我们假设CLS与patch表征共享共同特征。因此,我们将CLS流视为patch流的专门化,而非完全不同的流。然后,对于选择专门化的层fff,我们将类别token xclsx_{cls}xcls上的操作计算为patch层 fpatchf_{patch}fpatch 与秩为 rrr 的低秩自适应(LoRA)分解 fcls(r)f^{(r)}_{cls}fcls(r) 之和。
图12:LoRA影响。(a)LoRA设计可视化:CLS作为patch的近似。(b)不同LoRA配置(秩16和128)在模型前三分之一处的性能指标和参数增加。在所有情况下,均应用第4.3节描述的归一化专门化,对应'norms'行。
| 专门化策略 | 参数增加(%) | 线性准确率 | 平均分割 | 平均深度↓ |
|---|---|---|---|---|
| 无 | − | 85.4 | 64.5 | 1.232 |
| norms | 0.05 | 85.1 | 65.6 | 1.178 |
| +QKV | 8.3 | 85.2 | 66.6 | 1.165 |
| +LoRA QKV r=16 | 0.2 | 85.3 | 65.8 | 1.188 |
| +LoRA QKV r=128 | 1.4 | 85.2 | 65.9 | 1.193 |
我们在实验中专门化归一化层和QKV投影,并使用秩为16和128(嵌入维度为1024)的LoRA近似。图12b中呈现的结果显示,在仅专门化归一化层的基础上,分割任务获得改进(分别提升+0.2+0.2+0.2和+0.3+0.3+0.3个mIoU点),同时仅增加有限数量的参数(分别增加+0.15%+0.15\%+0.15%和+1.35%+1.35\%+1.35%)。我们将进一步研究留作未来工作。
A.6 归一化专门化的必要性
除第4.5节中的专门化实验外,我们还进行了仅在模型前三分之一处专门化QKV投影但不专门化归一化层的实验。我们在表5中绘制了该实验结果,并与基线及我们最佳模型(在模型前三分之一处专门化归一化层和QKV投影)进行比较。我们观察到,仅专门化QKV投影相比基线带来的改进很小,例如在分割任务平均mIoU上仅提升+0.2+0.2+0.2点。这表明专门化归一化层对获得最佳性能至关重要。
表5:专门化归一化的重要性。在Transformer块前三分之一处应用不同层专门化(Spec.)策略的性能。所有块中的归一化层均被专门化。基线为带注意力偏置的ViT-L DINOv2。
| 模型 | 线性准确率 | 平均分割 | 平均深度↓ |
|---|---|---|---|
| 基线 | 85.4 | 64.5 | 1.232 |
| 专门化归一化 | 85.1 | 65.6 | 1.178 |
| 专门化归一化 & QKV投影 | 85.2 | 66.6 | 1.165 |
| 专门化QKV投影 | 85.4 | 64.7 | 1.211 |
A.7 DeiT-III的额外结果
我们在图13中报告了遵循DeiT-III训练ViT-B和ViT-L模型时VOC分割任务的性能曲线。我们观察到性能在预训练中期达到峰值,然后在末期显著下降。我们将此行为归因于缺乏驱动密集性能的局部损失。我们观察到在训练前半段我们的专门化带来显著增益,但这些增益随后在性能下降中被稀释,特别是在ViT-L情况下。
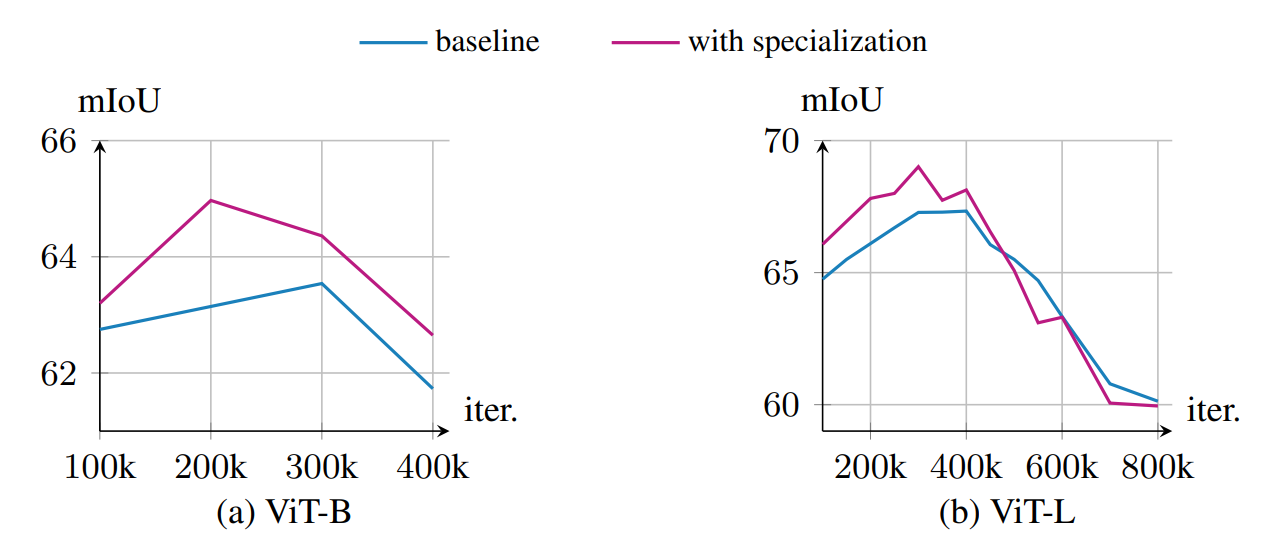
图13:DeiT-III训练演化。我们可视化(a)ViT-B和(b)ViT-L在DeiT-III预训练('baseline')及添加我们的层专门化时整个训练过程中的VOC分割性能(mIoU)。
A.8 其他定性结果
我们在图14、15和16中展示了更多定性结果,这些结果来自使用标准架构、4个寄存器或注意力偏置按照DINOv2预训练的模型,以及集成我们专门化策略的模型。每幅图显示使用patch特征计算的前三个主成分(PCA),并映射到RGB颜色空间。在所有情况下,我们都观察到专门化有助于生成更精确的patch特征且伪影更少。例如,我们邀请读者关注狗的背部(第一行),在原始预训练中可见的伪影在我们的专门化下显著减少。

图14:模型输出的前三个PCA主成分(RGB映射)。在模型前1/31/31/3处专门化归一化层和QKV投影。ViT-L使用标准DINOv2。

图15:模型输出的前三个PCA主成分(RGB映射)。在模型前1/31/31/3处专门化归一化层和QKV投影。ViT-L DINOv2带4个寄存器。
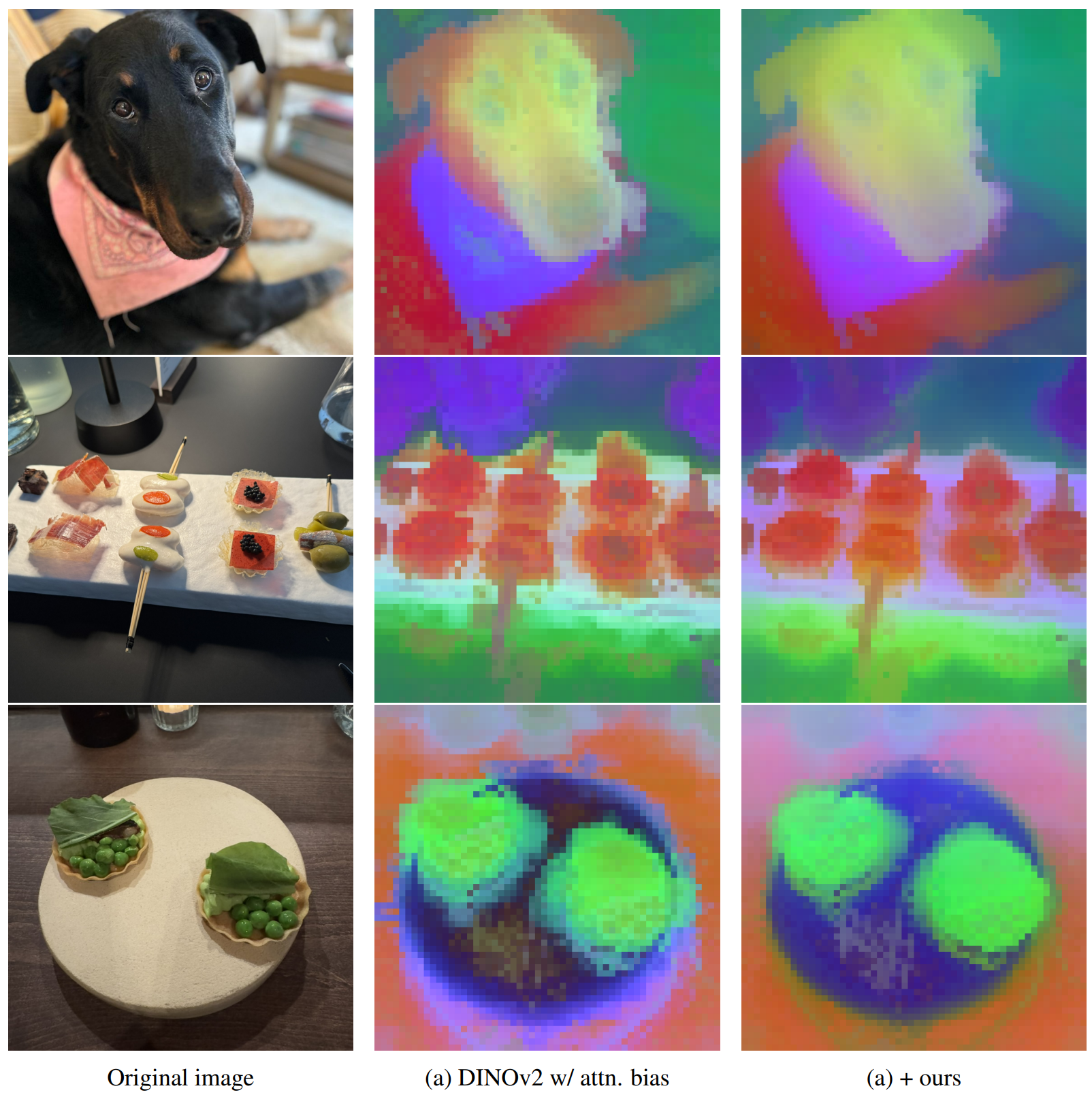
图16:模型输出的前三个PCA主成分(RGB映射)。在模型前1/31/31/3处专门化归一化层和QKV投影。ViT-L DINOv2带注意力偏置。