
Kubernetes 核心技术-s ervice 详解
一、k8s 的Service介绍
kubernetes中,pod是应用程序的载体,我们知道虽然每个Pod都会分配一个单独的Pod IP,我们可以通过pod的ip来访问应用程序,但pod的ip不是固定的,是根据所在宿主机的docker0网卡生成的,每次重启,更新,调度等情况IP都会变,那pod与pod之间需要互相调用,肯定不能用ip的,因为地址不是固定的,另外Pod IP仅仅是集群内可见的虚拟IP,外部无法访问,为了解决这个问题,kubernetes提供了Service资源,Service会对提供同一个服务的多个pod进行聚合,并且提供一个统一的入口地址。通过访问Service的入口地址就能访问到后面的pod服务。
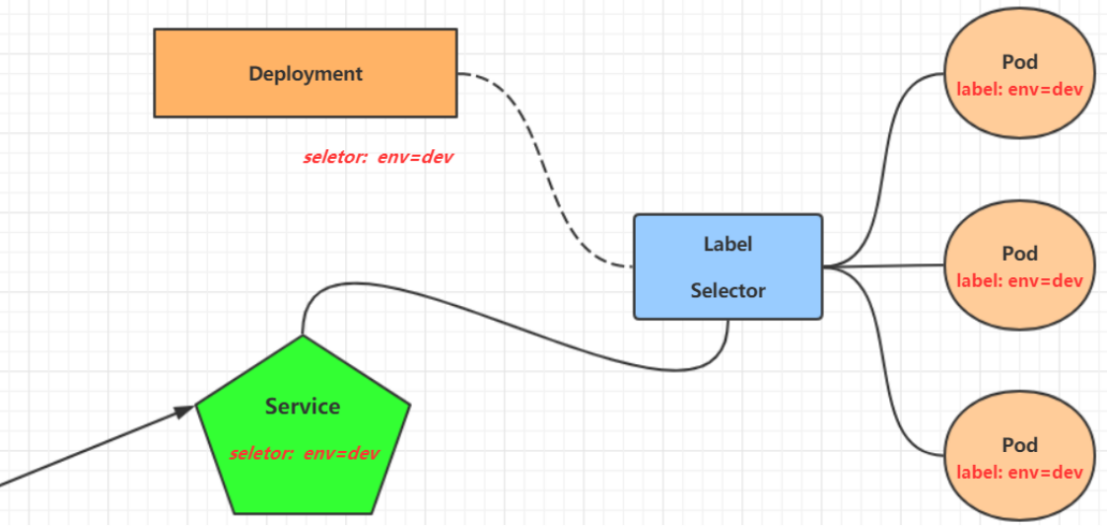
Kubernetes的Service是一种抽象,它定义了一组Pod的逻辑集合和一个用于访问它们的策略(Service代理Pod集合对外表现是为一个访问入口)。一个Service的目标Pod集合通常是由Label Selector 来决定的,通常使用RR轮询算法。
例如,假定有一组 Pod,它们对外暴露了 9376 端口,同时还被打上 app=MyApp 标签:
bash
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376上述配置创建一个名称为 "my-service" 的 Service 对象,它会将请求代理到使用 TCP 端口 9376,并且具有标签 "app=MyApp" 的 Pod 上。
Kubernetes 为为该service分配一个 IP 地址(有时称为 "集群IP"),该 IP 地址由kube-proxy使用。
注:service只有4层负载能力ip:port,无法提供7层负载(可以通过Ingress实现)
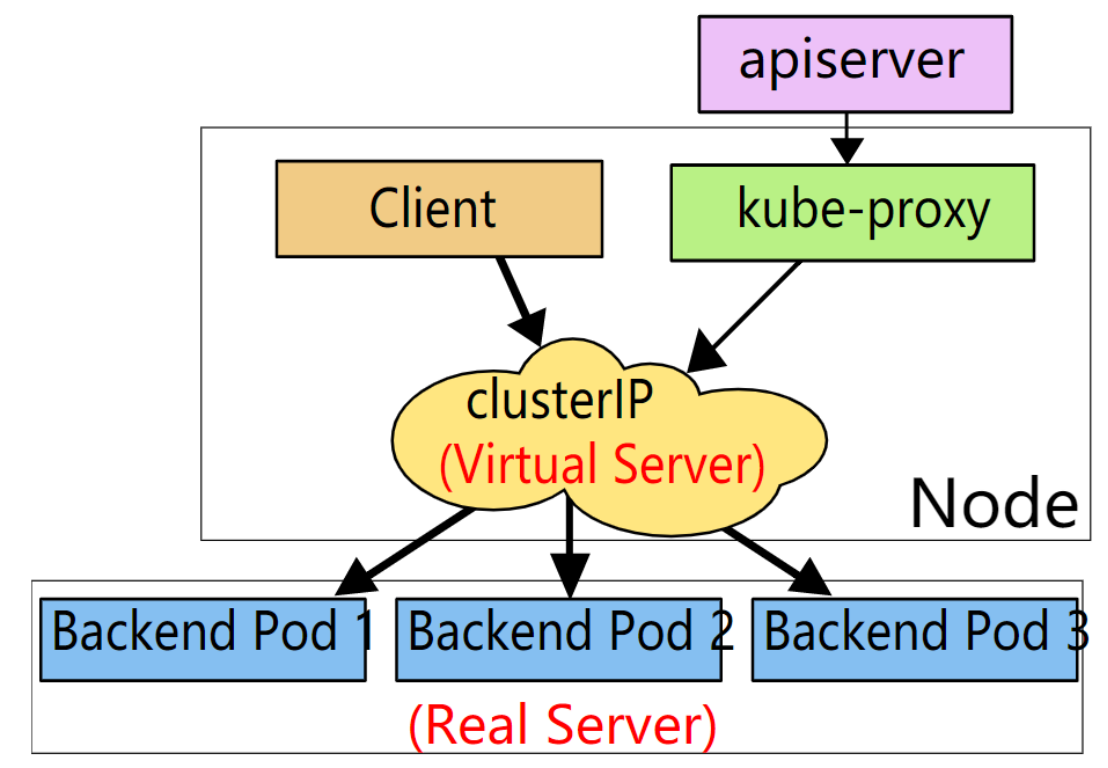
二、k8s的Service代理/工作模式
参考资料: https://kubernetes.io/zh/docs/concepts/services-networking/service/
Service能将pod的变化屏蔽在集群内部,同时提供负载均衡的能力,自动将请求流量分布到后端的pod,这一功能的实现真正起作用的其实是kube-proxy服务进程,每个Node节点上都运行着一个kube-proxy服务进程。当创建的时候会通过api-server向etcd写入创建的service的信息,而kube-proxy会基于监听的机制发现这种Service的变动,然后它会将最新的Service信息转换成对应的访问规则。
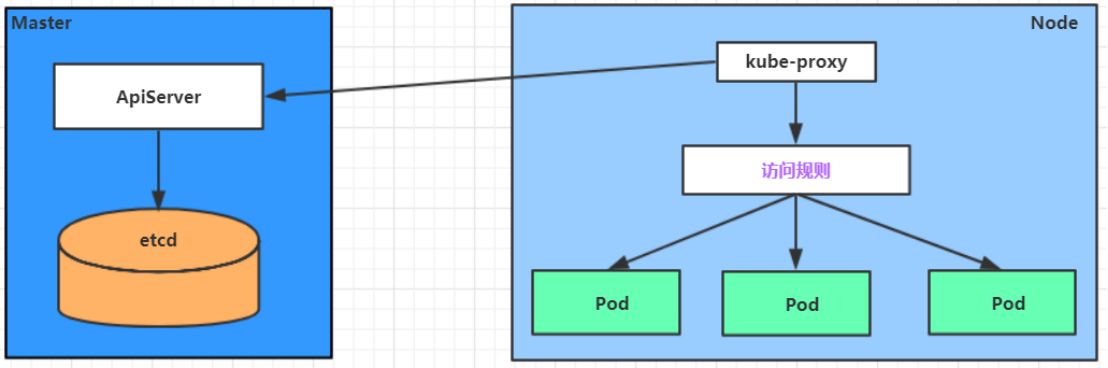
10.97.97.97:80 是service提供的访问入口
当访问这个入口的时候,可以发现后面有三个pod的服务在等待调用,
kube-proxy会基于rr(轮询)的策略,将请求分发到其中一个pod上去
这个规则会同时在集群内的所有节点上都生成,所以在任何一个节点上访问都可以。
bash
[root@node1 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.97.97.97:80 rr
-> 10.244.1.39:80 Masq 1 0 0
-> 10.244.1.40:80 Masq 1 0 0
-> 10.244.2.33:80 Masq 1 0 0kube-proxy目前支持三种工作模式
在 Kubernetes v1.0 版本,代理完全在 userspace。
在 Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。
从 Kubernetes v1.2 起,默认就是 iptables 代理。
在Kubernetes v1.8.0-beta.0 中,添加了 ipvs 代理,在 Kubernetes 1.14 版本开始默认使用 ipvs 代理
注: 在 Kubernetes v1.0 版本, Service 是"4层"(TCP/UDP over IP)概念。
在 Kubernetes v1.1 版本,新增了 Ingress API(beta 版),用来表示 "7层"(HTTP)服务
kube-proxy支持三种代理/工作模式: userspace(用户空间),iptables和IPVS;它们各自的操作略有不同。
1、u serspace 代理模式
userspace模式下,kube-proxy会监视Kubernetes控制节点对Service对象和Endpoints对象的添加和移除操作。kube-proxy会为每一个Service创建一个监听端口,发向Cluster IP的请求被Iptables规则重定向到kube-proxy监听的端口上,kube-proxy根据LB算法选择一个提供服务的Pod并和其建立链接,以将请求转发到Pod上。
该模式下,kube-proxy充当了一个四层负责均衡器的角色。由于kube-proxy运行在userspace中,在进行转发处理时会增加内核和用户空间之间的数据拷贝,虽然比较稳定,但是效率比较低。
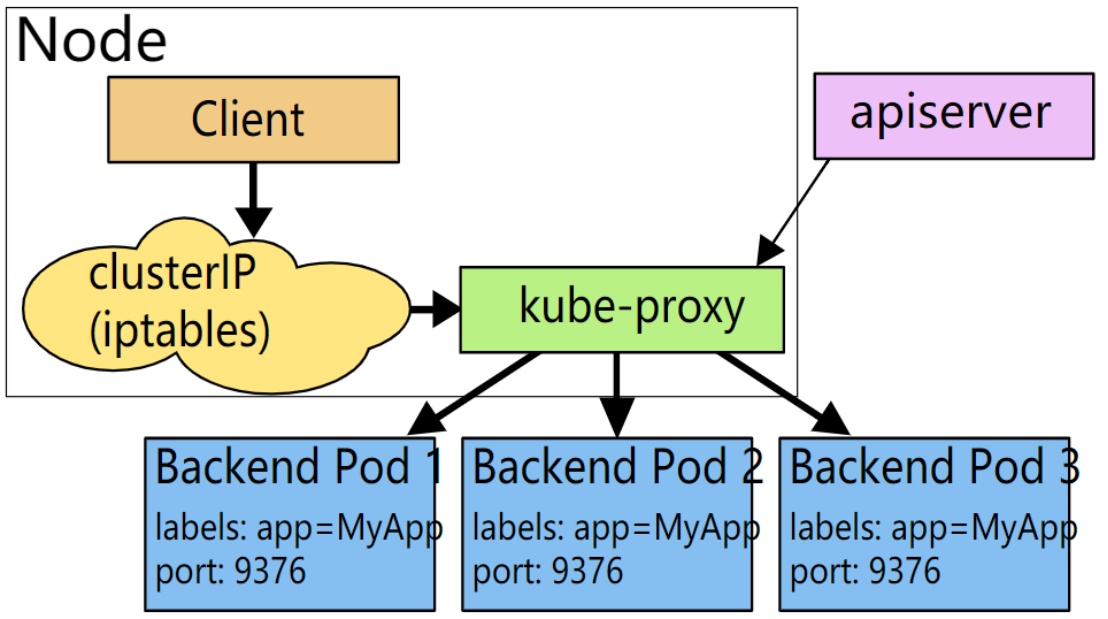
当创建Service 时,Kubernetes master会给它指派一个虚拟IP地址,比如10. 97.97.97。假设 Service 的端口是 1234,该 Service 会被集群中所有的 kube-proxy 实例观察到。当代理看到一个新的Service,它会打开一个新的端口,建立一个从该 VIP 重定向到新端口的 iptables,并开始接收请求连接。
当一个客户端连接到一个 VIP,iptables 规则开始起作用,它会重定向该数据包到 Service代理的端口。Service代理选择一个backend pod,并将客户端的流量代理到 backend pod上。
这里为什么需要建iptables规则,因为kube-proxy 监听的端口在用户空间,所以需要一层 iptables 把访问服务的连接重定向给 kube-proxy 服务,这里就存在内核态到用户态的切换,代价很大,因此就有了iptables
2、Iptables代理模式
iptables模式下,kube-proxy会监视Kubernetes控制节点对 Service 对象和 Endpoints 对象的添加和移除。kube-proxy为service后端的每个Pod创建对应的iptables规则,直接将发向Cluster IP的请求重定向到一个Pod IP。
该模式下kube-proxy不承担四层负责均衡器的角色,只负责创建iptables规则。该模式的优点是较userspace模式效率更高,但不能提供灵活的LB策略,当后端Pod不可用时也无法进行重试。
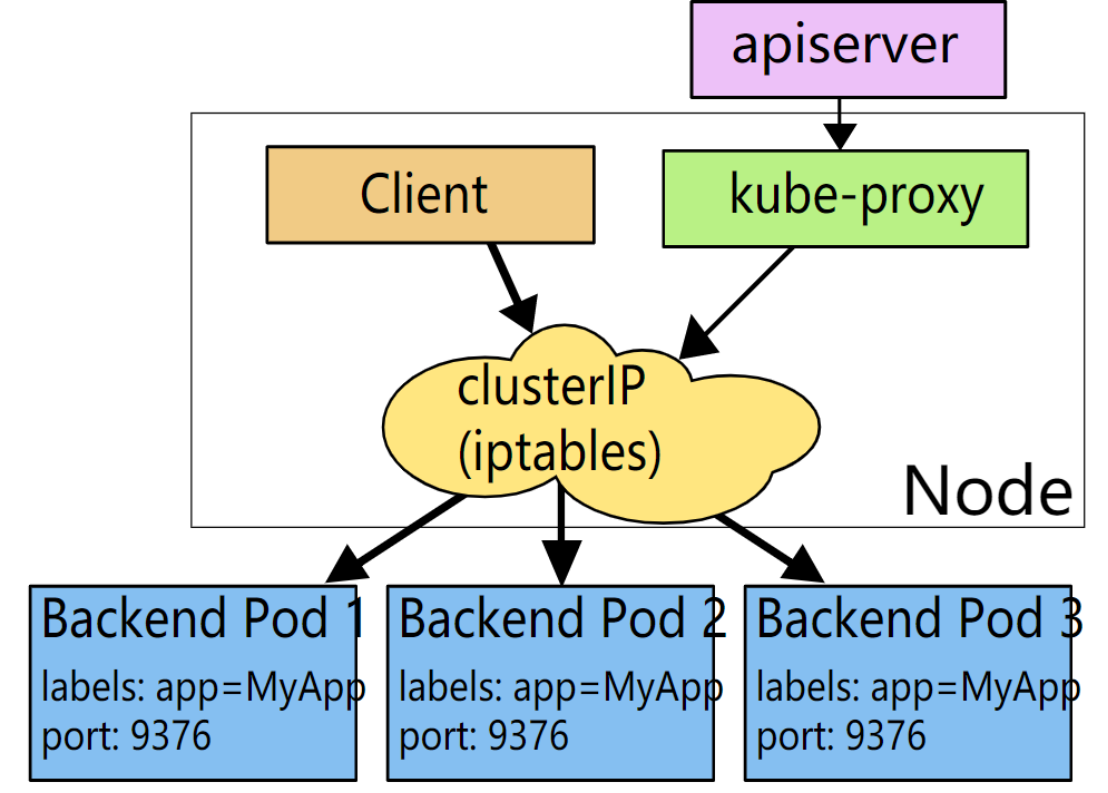
当创建 Service 时,Kubernetes 控制节点会给它指派一个虚拟 IP 地址,比如 10. 97.97.97。假设 Service 的端口是 1234,该 Service 会被集群中所有的 kube-proxy 实例观察到。当代理看到一个新的 Service, 它会配置一系列的 iptables 规则,从 VIP 重定向到 per-Service 规则。该 per-Service 规则连接到 per-Endpoint 规则,该 per-Endpoint 规则会重定向(目标 NAT)到 backend pod。
当一个客户端连接到一个 VIP,iptables 规则开始起作用。kube-proxy 在 iptables 模式下会选择(或者根据会话亲和性,或者随机)一个backend pod,数据包被重定向到这个 backend pod。
使用 iptables 处理流量具有较低的系统开销,因为流量由 Linux netfilter 处理, 而无需在用户空间和内核空间之间切换。 这种方法也可能更可靠。
如果 kube-proxy 在 iptables 模式下运行,并且所选的第一个 Pod 没有响应, 则连接失败。这与用户空间模式不同:在这种情况下,kube-proxy 将检测到与第一个 Pod 的连接已失败, 并会自动使用其他后端 Pod 重试。
你可以使用 Pod 就绪探测器验证后端 Pod 可以正常工作,以便 iptables 模式下的 kube-proxy 仅看到测试正常的后端。 这样做意味着你避免将流量通过 kube-proxy 发送到已知已失败的 Pod。
3、IPVS 代理模式
ipvs模式和iptables类似,kube-proxy监控Pod的变化并创建相应的ipvs规则。ipvs相对iptables转发效率更高。除此以外,ipvs支持更多的LB算法。
在大规模集群(例如10,000个服务)中,iptables 操作会显着降低速度。IPVS 专为负载平衡而设计,并基于内核内的哈希表。因此,你可以通过基于 IPVS 的 kube-proxy 在大量服务中实现性能一致性。同时,基于 IPVS 的 kube-proxy 具有更复杂的负载平衡算法(最少连接,轮询,加权等)。
在 ipvs 模式下,kube-proxy 监视 Kubernetes 服务和端点,调用 netlink 接口相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。访问服务时,IPVS 将流量定向到后端Pod之一。
IPVS 提供了更多选项来平衡后端 Pod 的流量。 这些是:
rr:轮询(Round-Robin)
lc:最少链接(Least Connection),即打开链接数量最少者优先
dh:目标地址哈希(Destination Hashing)
sh:源地址哈希(Source Hashing)
sed:最短预期延迟(Shortest Expected Delay)
注1:
ipvs (IP Virtual Server) 是基于 Netfilter 的,作为 linux 内核的一部分,实现了传输层负载均衡,ipvs 集成在LVS(Linux Virtual Server)中,它在主机中运行,并在真实服务器集群前充当负载均衡器, 可以将对 TCP/UDP 服务的请求转发给后端的真实服务器,因此 ipvs 天然支持 Kubernetes Service。ipvs 也包含了多种不同的负载均衡算法,例如轮询、最短期望延迟、最少连接以及各种哈希方法等,ipvs 的设计就是用来为大规模服务进行负载均衡的。
注2:
当 kube-proxy 以 IPVS 代理模式启动时,它将验证 IPVS 内核模块是否可用。 如果未检测到 IPVS 内核模块,则 kube-proxy 将退回到以 iptables 代理模式运行。
bash
# 此模式必须安装ipvs内核模块,否则会降级为iptables
# 开启ipvs
[root@master1 ~]# kubectl edit cm kube-proxy -n kube-system
# 修改mode: "ipvs"
[root@master1 ~]# kubectl delete pod -l k8s-app=kube-proxy -n kube-system
[root@node1 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.97.97.97:80 rr
-> 10.244.1.39:80 Masq 1 0 0
-> 10.244.1.40:80 Masq 1 0 0
-> 10.244.2.33:80 Masq 1 0 0三、K8s service的类型
Kubernetes ServiceTypes允许指定你所需要的Service类型,默认是ClusterIP。
Type 的取值以及行为如下:
ClusterIP: 它是Kubernetes系统自动分配的虚拟IP,通过集群的内部 IP 暴露服务,选择该值时服务只能够在集群内部访问。 这也是默认的 ServiceType
**NodePort:**将Service通过指定的Node上的端口暴露给外部,通过此方法,就可以在集群外部访问服务,NodePort 服务会路由到自动创建的ClusterIP 服务。通过请求<节点IP>:<节点端口>,你可以从集群的外部访问一个 NodePort service。
**LoadBalancer:**使用外接负载均衡器完成到服务的负载分发,注意此模式需要外部云环境支持。外部负载均衡器可以将流量路由到自动创建的NodePort 服务和ClusterIP服务上。
**ExternalName:**把集群外部的服务引入集群内部,直接使用。通过返回 CNAME 和对应值,可以将服务映射到externalName字段的内容(例如,foo.bar.example.com)。无需创建任何类型代理。
四、K8s service使用
1、实验环境准备
在使用service之前,首先利用Deployment创建出3个pod,注意要为pod设置app=nginx-pod的标签
创建deployment.yaml,内容如下:
root@master1 \~# cat deployment.yaml
bash
apiVersion: apps/v1
kind: Deployment
metadata:
name: pc-deployment
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80root@master1 \~# kubectl create -f deployment.yaml
bash
deployment.apps/pc-deployment created查看deploy,pod信息
root@master1 \~# kubectl get deploy,pod -n dev -o wide --show-labels
bash
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR LABELS
deployment.apps/pc-deployment 3/3 3 3 3m25s nginx nginx:1.17.1 app=nginx-pod <none>
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
pod/pc-deployment-5ffc5bf56c-25d6g 1/1 Running 0 3m25s 10.244.2.151 node2 <none> <none> app=nginx-pod,pod-template-hash=5ffc5bf56c
pod/pc-deployment-5ffc5bf56c-cp4rt 1/1 Running 0 3m25s 10.244.2.152 node2 <none> <none> app=nginx-pod,pod-template-hash=5ffc5bf56c
pod/pc-deployment-5ffc5bf56c-rg65b 1/1 Running 0 3m25s 10.244.1.126 node1 <none> <none> app=nginx-pod,pod-template-hash=5ffc5bf56c为了方便后面的测试,修改下三台nginx的index.html页面(三台修改的IP地址不一致)
root@master1 \~# kubectl exec -it pc-deployment-5ffc5bf56c-25d6g -n dev /bin/sh
bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
# echo "10.244.2.151" > /usr/share/nginx/html/index.html修改完毕之后,访问测试
bash
[root@master1 ~]# curl 10.244.2.151
10.244.2.151
[root@master1 ~]# curl 10.244.2.152
10.244.2.152
[root@master1 ~]# curl 10.244.1.126
10.244.1.1262、ClusterIP类型的service
**ClusterIP Service是 Kubernetes 的默认服务类型。**自动分配一个仅cluster内部可以访问的虚拟ip,集群内的其它应用都可以访问该服务。集群外部无法访问它
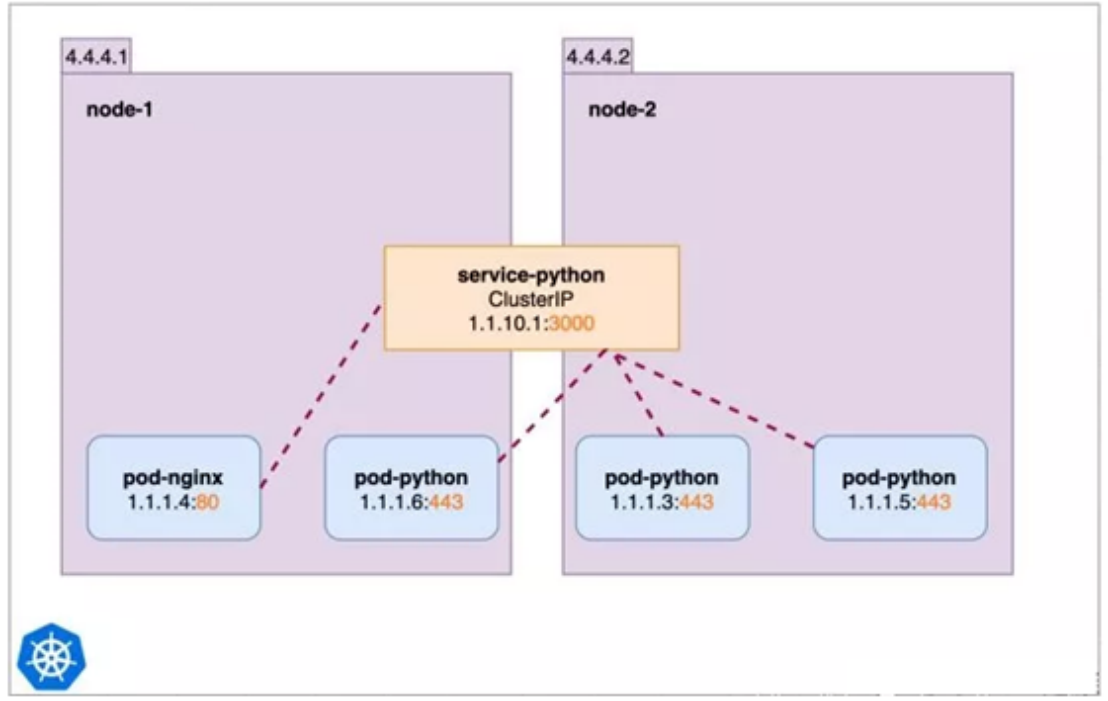
类型为ClusterIP的service,这个service有一个ClusterIP,其实就一个VIP。具体实现原理依靠kube proxy组件,通过iptables或是ipvs实现。
这种类型的service 只能在集群内访问
创建service-clusterip.yaml文件
bash
[root@master1 ~]# cat service-clusterip.yaml
apiVersion: v1
kind: Service
metadata:
name: service-clusterip
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: 10.97.97.97 # service的ip地址,如果不写,默认会生成一个
type: ClusterIP
ports:
- port: 80 # Service端口
targetPort: 80 # pod端口
创建service
[root@master1 ~]# kubectl create -f service-clusterip.yaml
service/service-clusterip created
使用 kuebctl get svc查看service :
[root@master1 ~]# kubectl get svc -n dev -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service-clusterip ClusterIP 10.97.97.97 <none> 80/TCP 93s app=nginx-pod
查看service的详细信息
在这里有一个Endpoints列表,里面就是当前service可以负载到的服务入口
[root@master1 ~]# kubectl describe -n dev svc service-clusterip
Name: service-clusterip
Namespace: dev
Labels: <none>
Annotations: <none>
Selector: app=nginx-pod
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.97.97.97
IPs: 10.97.97.97
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.1.126:80,10.244.2.151:80,10.244.2.152:80
Session Affinity: None
Events: <none>
查看ipvs的映射规则
[root@master1 ~]# ipvsadm -Ln
TCP 10.97.97.97:80 rr
-> 10.244.1.126:80 Masq 1 0 0
-> 10.244.2.151:80 Masq 1 0 0
-> 10.244.2.152:80 Masq 1 0 0
访问10.97.97.97:80观察效果
[root@master1 ~]# for i in $(seq 1 10) ; do curl 10.97.97.97:80 ; done
10.244.2.152
10.244.2.151
10.244.1.126
10.244.2.152
10.244.2.151
10.244.1.126
10.244.2.152
10.244.2.151
10.244.1.126
10.244.2.152Endpoint
Endpoint是kubernetes中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址,它是根据service配置文件中selector描述产生的
一个Service由一组Pod组成,这些Pod通过Endpoints暴露出来,Endpoints是实现实际服务的端点集合。换句话说,service和pod之间的联系是通过endpoints实现的
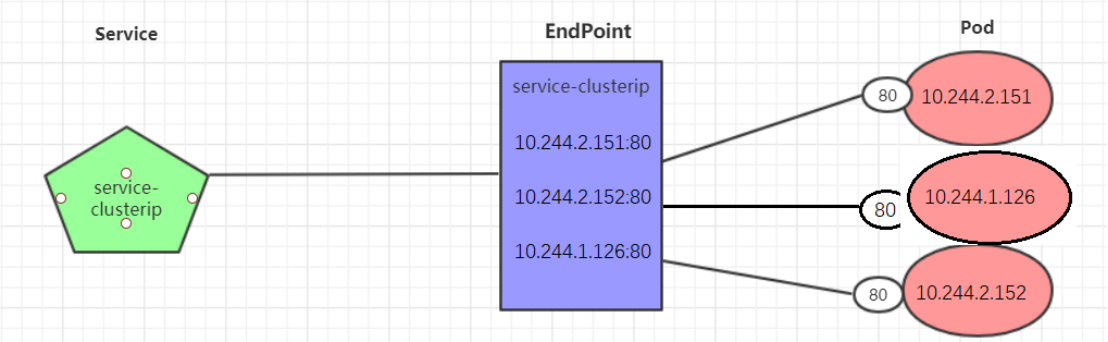
bash
[root@master1 ~]# kubectl get endpoints -n dev -o wide
NAME ENDPOINTS AGE
service-clusterip 10.244.1.126:80,10.244.2.151:80,10.244.2.152:80 32m负载分发策略
对Service的访问被分发到了后端的Pod上去,目前kubernetes提供了两种负载分发策略:
如果不定义,默认使用kube-proxy的策略,比如随机、轮询
基于客户端地址的会话保持模式,即来自同一个客户端发起的所有请求都会转发到固定的一个Pod上,此模式可以使在spec中添加sessionAffinity:ClientIP选项
bash
[root@master1 ~]# ipvsadm -Ln
TCP 10.97.97.97:80 rr
-> 10.244.1.126:80 Masq 1 0 0
-> 10.244.2.151:80 Masq 1 0 0
-> 10.244.2.152:80 Masq 1 0 0
循环访问测试
[root@master1 ~]# for i in $(seq 1 10) ; do curl 10.97.97.97:80 ; done
10.244.2.152
10.244.2.151
10.244.1.126
10.244.2.152
10.244.2.151
10.244.1.126
10.244.2.152
10.244.2.151
10.244.1.126
10.244.2.152
修改分发策略----spec. sessionAffinity: ClientIP
查看ipvs规则【persistent 代表持久】
[root@master1 ~]# ipvsadm -Ln
TCP 10.97.97.97:80 rr persistent 10800
-> 10.244.1.126:80 Masq 1 0 0
-> 10.244.2.151:80 Masq 1 0 10
-> 10.244.2.152:80 Masq 1 0 0
循环访问测试
[root@master1 ~]# for i in $(seq 1 5) ; do curl 10.97.97.97:80 ; done
10.244.2.151
10.244.2.151
10.244.2.151
10.244.2.151
10.244.2.151
删除service
[root@master1 ~]# kubectl delete -f service-clusterip.yaml
service "service-clusterip" deleted3、NodePort类型的service
我们的场景不全是集群内访问,也需要集群外业务访问。NodePort当然是其中的一种实现方案
在之前的案例中,创建的Service的ip地址只有集群内部才可以访问,如果希望将Service暴露给集群外部使用,那么就要使用到另外一种类型的Service,称为NodePort类型。NodePort的工作原理其实就是将service的端口映射到Node的一个端口上,然后就可以通过NodeIp:NodePort来访问service了
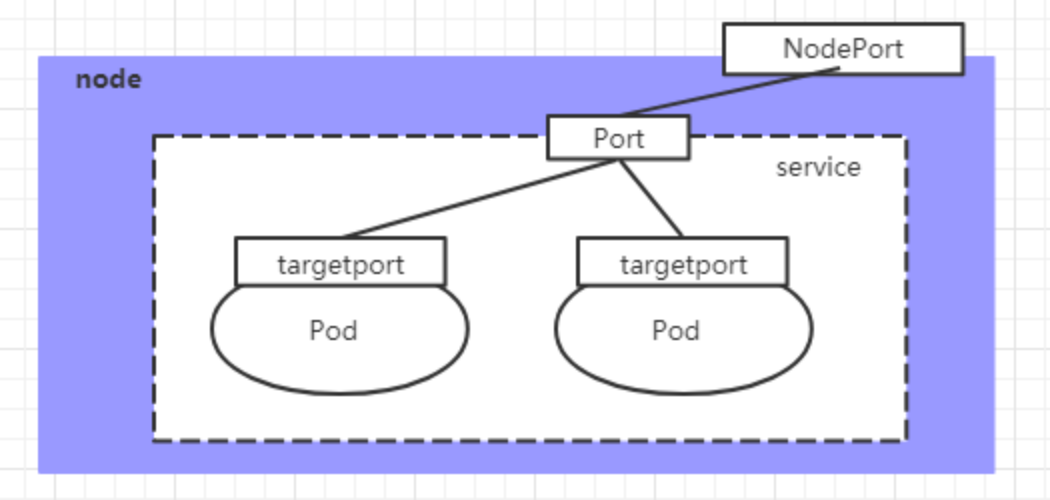
bash
创建service-nodeport.yaml
[root@master1 ~]# cat service-nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: service-nodeport
namespace: dev
spec:
selector:
app: nginx-pod
type: NodePort # service类型
ports:
- port: 80
nodePort: 30002 # 指定绑定的node的端口(默认的取值范围是:30000-32767), 如果不指定,会默认分配
targetPort: 80
创建service
[root@master1 ~]# kubectl create -f service-nodeport.yaml
service/service-nodeport created
查看service
[root@master1 ~]# kubectl get svc -n dev -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service-nodeport NodePort 10.100.133.32 <none> 80:30002/TCP 3m24s app=nginx-pod接下来可以通过浏览器去访问集群中任意一个nodeip的30002端口,即可访问到pod提供的应用了。该端口有一定的范围,比如默认Kubernetes将在--service-node-port-range标志指定的范围内分配端口(默认值:30000-32767)

4、LoadBalancer类型的service
LoadBalancer和NodePort很相似,目的都是向外部暴露一个端口,区别在于LoadBalancer会在集群的外部再来做一个负载均衡设备,而这个设备需要外部环境支持的,外部服务发送到这个设备上的请求,会被设备负载之后转发到集群中
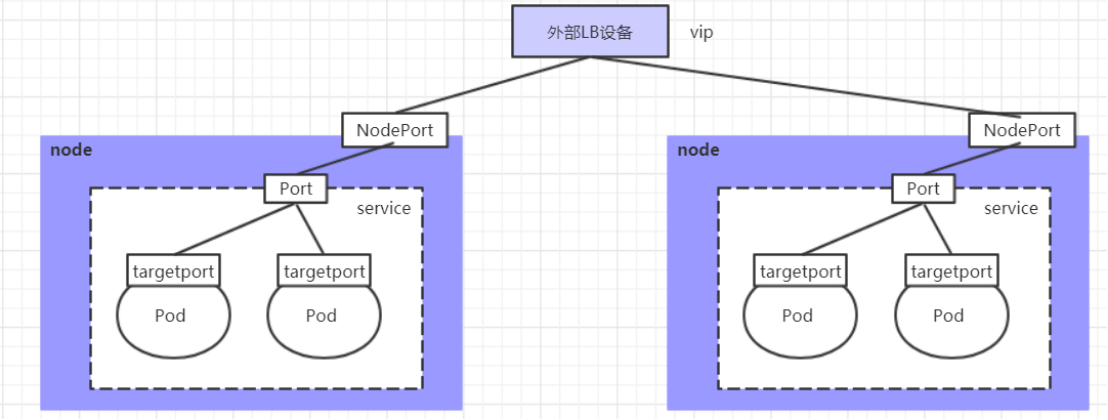
参考资料:
++++https://kubernetes.io/zh/docs/tasks/access-application-cluster/create-external-load-balancer/++++
++++https://kubernetes.io/zh/docs/concepts/services-networking/service/++++
LoadBalancer类型service 如下:
bash
apiVersion: v1
kind: Service
metadata:
name: example-service
spec:
selector:
app: example
ports:
- port: 8765
targetPort: 9376
nodePort: 30003
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 192.0.2.1275、ExternalName类型的service
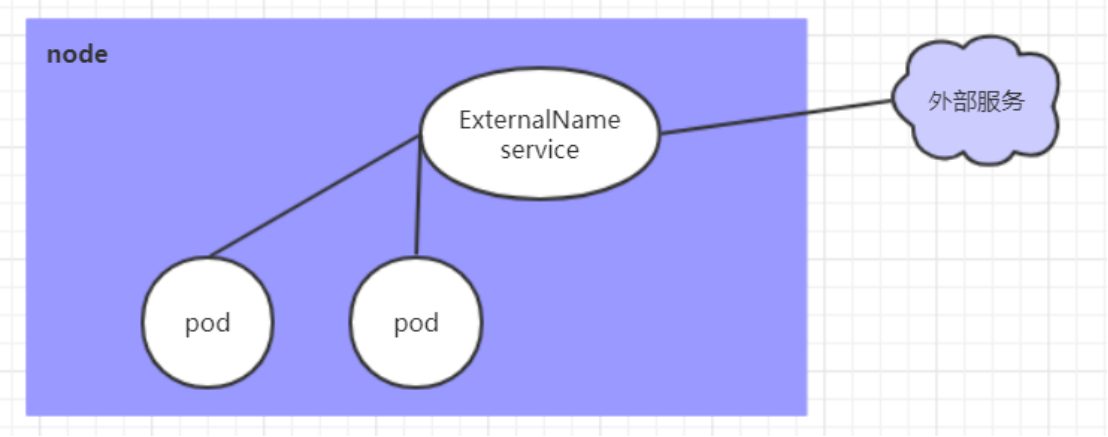
ExternalName类型的Service用于引入集群外部的服务,它通过externalName属性指定外部一个服务的地址,然后在集群内部访问此service就可以访问到外部的服务了
bash
[root@master1 ~]# cat service-externalname.yaml
apiVersion: v1
kind: Service
metadata:
name: service-externalname
namespace: dev
spec:
type: ExternalName # service类型
externalName: www.baidu.com #改成ip地址也可以
创建service
[root@master1 ~]# kubectl create -f service-externalname.yaml
service/service-externalname created
查看service
[root@master1 ~]# kubectl get -n dev svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service-externalname ExternalName <none> www.baidu.com <none> 14s <none>
域名解析
CoreDNS_IP的查看方式:
[root@master1 ~]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 27d
查看CoreDNS pod
[root@master1 ~]# kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-78fcd69978-fv2f5 1/1 Running 17 (42h ago) 27d 10.244.0.37 master1 <none> <none>
coredns-78fcd69978-tn5vz 1/1 Running 17 (42h ago) 27d 10.244.0.36 master1 <none> <none>
..................................
[root@master1 ~]# dig @10.96.0.10 service-externalname.dev.svc.cluster.local
service-externalname.dev.svc.cluster.local. 30 IN CNAME www.baidu.com.
www.baidu.com. 30 IN CNAME www.a.shifen.com.
www.a.shifen.com. 30 IN A 110.242.68.3
www.a.shifen.com. 30 IN A 110.242.68.4
注:解析域名格式:
dig @CoreDNS_IP SVC_NAME.NAMESPACE.svc.cluster.local
或
nslookup SVC_NAME.NAMESPACE.svc.cluster.local CoreDNS_IP
类型为 ExternalName 的service将服务映射到 DNS 名称,而不是典型的选择器。这种类型的Service通过返回CNAME和它的值,可以将服务映射到 externalName 字段的内容( 例如:www.baidu.com )。ExternalName Service是Service 的特例,它没有selector,也没有定义任何的端口和Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务
例如,以下Service定义将prod名称空间中的my-service服务映射到 my.database.example.com:
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
当查询主机my-service.prod.svc.cluster.local 时(解析域名格式:SVC_NAME.NAMESPACE.svc.cluster.local,默认就是svc.cluster.local),集群DNS服务返回CNAME记录,其值为 my.database.example.com。访问my-service的方式与其他服务的方式相同,但主要区别在于重定向发生在 DNS 级别,而不是通过代理或转发。
注:你需要 CoreDNS 1.7 或更高版本才能使用ExternalName类型。
[root@master1 ~]# kubectl describe -n dev service service-externalname
Name: service-externalname
Namespace: dev
Labels: <none>
Annotations: <none>
Selector: <none> #可以看到没有选择器
Type: ExternalName
IP Families: <none>
IP:
IPs: <none>
External Name: www.baidu.com
Session Affinity: None
Events: <none>6、HeadLess类型的Service
在某些场景中,开发人员可能不想使用Service提供的负载均衡功能,而希望自己来控制负载均衡策略,针对这种情况,kubernetes提供了HeadLess Service,这类Service不会分配Cluster IP,如果想要访问service,只能通过service的域名进行查询
所谓headless service指:没有ClusterIP的service,它仅有一个service name。这个服务名解析得到的不是service的集群IP,而是Pod的IP,当其它人访问该service时,将直接获得Pod的IP,进行直接访问
其实一般headless services一般结合StatefulSet来部署有状态的应用
bash
创建service-headliness.yaml
[root@master1 ~]# cat service-headless.yaml
apiVersion: v1
kind: Service
metadata:
name: service-headliness
namespace: dev
spec:
selector:
app: nginx-pod
clusterIP: None # 将clusterIP设置为None,即可创建headliness Service
type: ClusterIP
ports:
- port: 80
targetPort: 80
创建service
[root@master1 ~]# kubectl create -f service-headless.yaml
service/service-headliness created
获取service,发现CLUSTER-IP未分配
[root@master1 ~]# kubectl get -n dev svc service-headliness -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service-headliness ClusterIP None <none> 80/TCP 23s app=nginx-pod
查看service详情
[root@master1 ~]# kubectl describe -n dev svc service-headliness
Name: service-headliness
Namespace: dev
Labels: <none>
Annotations: <none>
Selector: app=nginx-pod
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: None
IPs: None
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.1.126:80,10.244.2.151:80,10.244.2.152:80
Session Affinity: None
Events: <none>
查看域名的解析情况
root@master1 ~]# kubectl exec -it pc-deployment-5ffc5bf56c-25d6g -n dev /bin/sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
# cat /etc/resolv.conf
nameserver 10.96.0.10
search dev.svc.cluster.local svc.cluster.local cluster.local
[root@master1 ~]# dig @10.96.0.10 service-headliness.dev.svc.cluster.local
service-headliness.dev.svc.cluster.local. 30 IN A 10.244.2.152
service-headliness.dev.svc.cluster.local. 30 IN A 10.244.2.151
service-headliness.dev.svc.cluster.local. 30 IN A 10.244.1.126五、k8s service定义
bash
Service yaml的资源清单文件:
kind: Service # 资源类型
apiVersion: v1 # 资源版本
metadata: # 元数据
name: service # 资源名称
namespace: dev # 命名空间
spec: # 描述
selector: # 标签选择器,用于确定当前service代理哪些pod
app: nginx
type: # Service类型,指定service的访问方式
clusterIP: # 虚拟服务的ip地址
sessionAffinity: # session亲和性,支持ClientIP、None两个选项
ports: # 端口信息
- protocol: TCP
port: 3017 # service端口
targetPort: 5003 # pod端口
nodePort: 31122 # 主机端口|--------------------------------------|----------|----------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 属性名称 | 取值类型 | 是否必选 | 取值说明 |
| apiVersion | string | required | v1 |
| kind | string | required | Service |
| metadata | object | required | 元数据 |
| metadata.name | string | required | service名称 |
| metadata.namespace | string | required | 命名空间,默认为default |
| metadata.labels\[\] | list | | 自定义标签属性列表 |
| metadata.annotation\[\] | list | | 自定义注解属性列表 |
| spec | object | required | 详细描述 |
| spec.selector\[\] | list | required | label selector配置,将选择具有指定label标签的pod作为管理范围 |
| spec.type | string | required | service的类型,指定service的访问方式,默认值为ClusterIP **取值范围如下:**ClusterIP:虚拟服务的ip,用于k8s集群内部的pod访问;NodePort:使用宿主机的端口,使能够访问各node的外部客户端通过node的ip地址和端口就能访问服务;LoadBalancer:使用外接负载均衡器完成到服务的负载分发,需要在spec.status.loadBalancer字段指定外部负载均衡器的ip地址,并同时定义nodePort和clusterIP,用于公有云环境 |
| spec.clusterIP | string | | 虚拟服务的ip地址,当type=clusterIP时,如果不指定,则系统进行自动分配。也可以手工指定。当type=LoadBalancer时,则需要指定 |
| spec.sessionAffinity | string | | 是否支持session,可选值为ClientIP,表示将同一个源ip地址的客户端访问请求都转发到同一个后端pod,默认值为none |
| spec.ports\[\] | list | | Service需要暴露的端口列表 |
| spec.ports\[\].name | string | | 端口名称 |
| spec.ports\[\].protocol | string | | 端口协议,支持tcp和udp,默认值为 tcp |
| spec.ports\[\].port | int | | 服务监听的端口号 |
| spec.ports\[\].targetPort | int | | 需要转发到后端pod的端口 |
| spec.ports\[\].nodePort | int | | 当spec.type=NodePort时,指定映射到物理机的端口号 |
| status | object | | 当spec.type=LoadBalance时,设置外部负载均衡器的地址,用于公有云环境 |
| status.loadBalancer | object | | 外部负载均衡器 |
| status.loadBalancer.ingress | object | | 外部负载均衡器 |
| status.loadBalancer.ingress.ip | string | | 外部负载均衡器的ip地址 |
| status.loadBalancer.ingress.hostname | string | | 外部负载均衡器的主机名 |
六、K8s Service的三种端口
在实际生产环境中,一般有两种访问:对集群内部的访问,集群外部的访问
我们先理解Service Port的几种类型
Service yaml配置文件如下:
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort #新增,修改配置使用NodePort方式映射端口
ports:
- port: 443
targetPort: 8443
nodePort: 30008
selector:
k8s-app: kubernetes-dashboard
**port :**service 暴露在 cluster ip (service的ip)上的端口,port 是提供给集群内部服务之间访问 service 的入口**nodePort :**是 k8s 提供给集群外部客户访问 service 入口的一种方式。会在宿主机上映射一个端口,供外部应用访问模式。不指定的话会随机分配个,分配的端口在apiserver的配置文件中指定了--service-node-port-range=30000-50000,表示只允许分配30000-50000之间的端口
比如一个nginx应用需要能被外部访问,就需要配置类型为type: NodePort,并且需要配置下nodePort: 30002(指定固定端口),这样的话外部使用http://ip:30002就可以访问这个应用了
**targetPort :**是 pod 中容器实例上的端口,即容器本身暴露的端口,和dockerfile中的expose意思一样
**port、nodePort 总结:**port 和 nodePort 都是 service 的端口,前者暴露给集群内客户访问服务,后者暴露给集群外客户访问服务
转发逻辑是:<NodeIP>:<nodeport> => <ServiceVIP>:<port>=> <PodIP>:<targetport>
七、多端口service
对于某些服务,你需要公开多个端口。Kubernetes允许你在Service对象上配置多个端口定义。为服务使用多个端口时,必须提供所有端口名称,以使它们无歧义
例如:在下面的例子中,Service设置了两个端口号,并且为每个端口号都进行了命名:
bash
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377注:
与一般的Kubernetes名称一样,端口名称只能包含小写字母、数字字符和"-""。 端口名称还必须以字母、数字字符开头和结尾
例如,名称 123-abc 和 web 有效,但是 123_abc 和 -web 无效