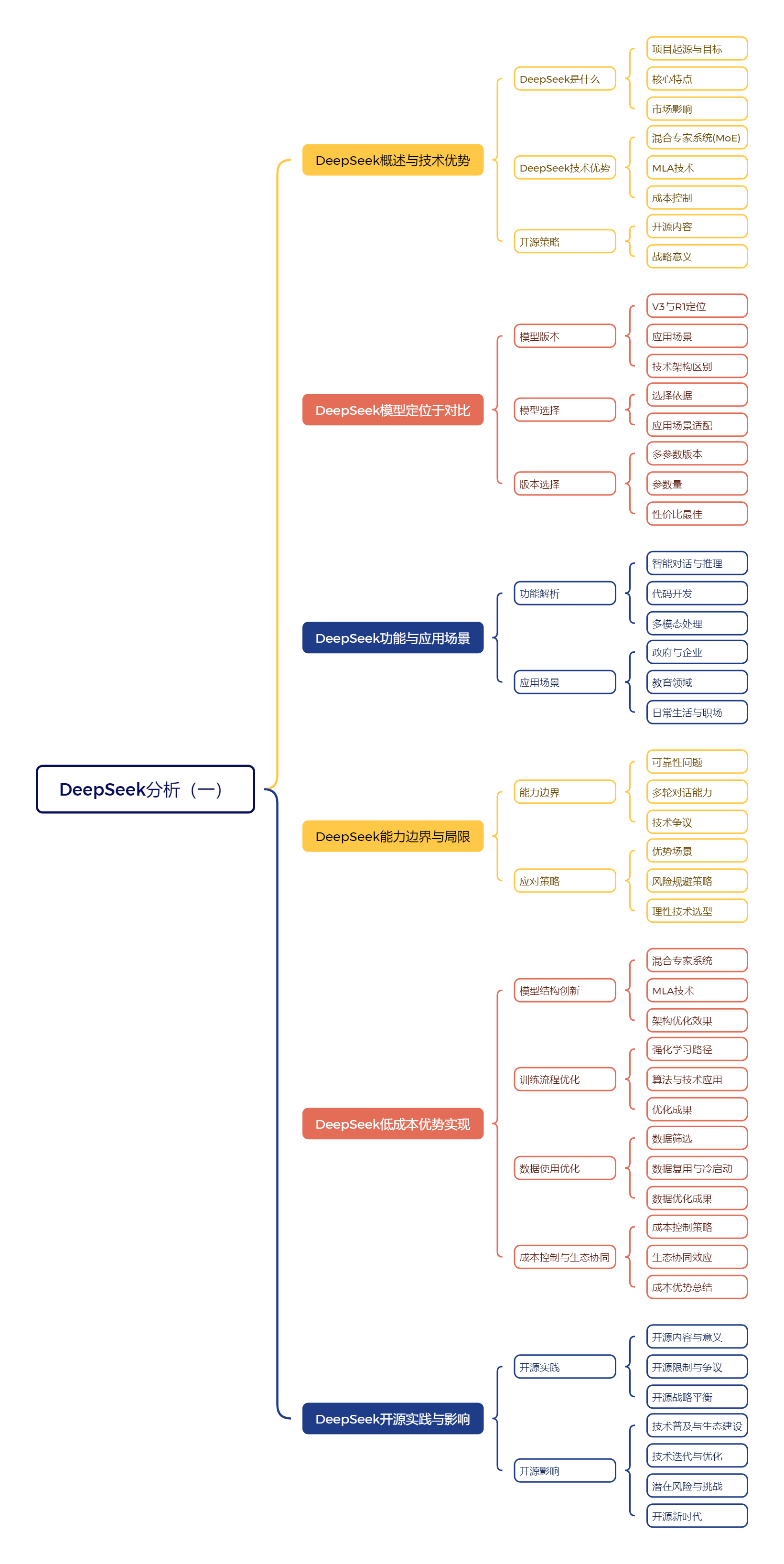
一、DeepSeek概述与技术优势
1、DeepSeek是什么
**【项目起源与目标】**DeepSeek是中国团队研发的大语言模型项目,旨在打造开源、强大且易用的AI工具,类以ChatGPT或Gemini,寓意通过深度学习探索智能边界。
**【核心特点】**开源开放,性能强大,多功能,中英文兼顾,高性价比。开源模型如DeepSeek-R1,定位推理模型,开源属性支持商业用途,降低企业应用AI门槛。
**【市场影响】**DeepSeek凭借开源、普惠、实用性理念,激发市场潜力,推动创新。其模型在Hugging Face平台覆盖多领域,被微软集成进Azure云平台,获云计算生态话语权。
2、DeepSeek技术优势
**【混合专家系统(MoE)】**MoE将大模型拆分为多个"专家"模块,各模块专注特定任务,推理时智能调配,不显著增加计算成本,大幅提升模型能力。
**【MLA技术】**MLA是DeepSeek自研的替代传统注意力机制的技术,推理速度和内存占用更具优势,提升训练和推理效率,降低资源消耗。
**【成本控制】**DeepSeek借助开源生态摊薄边际成本,提升GPU利用率,引入量化交易优化思维,打破"AI研发高投入"认知,实现高效能与低成本统一。
3、开源策略
**【开源内容】**DeepSeek开源模型权重、推理框架、部分训练代码和数据清洗工具,构建生态支持体系,降低AI技术使用门槛,推动技术普及。
**【战略意义】**开源吸引全球开发者参与,加速AI技术普及落地,为行业智能化转型注入动力。同时,技术方案接受全球检验优化,探索AI开源新路径。
二、DeepSeek模型定位于对比
1、模型版本
**【V3与R1定位】**V3是"端士军刀",功能全面,适用范围广,适合目常办公、教育辅导等;R1是"手术刀",专业精准,专注于复杂问题和高阶推理任务。
**【应用场景】**差异V3用于写邮件、报告、PPT等办公任务,简单代码生成;R1擅长战略规划、决策分析、复杂算法优化等,需较强逻辑推理和创造性思维。
**【技术架构区别】**V3强调"过程→结果",规范可控;R1注重"构建思维路径",多角度发散。V3适合低容错场景,R1适合前沿探索类任务。
2、模型选择
**【选择依据】**结构化、有标准答案任务选V3;不确定性强、需深度分析或创新思路问题选R1。也可结合使用,形成高效协作闭环。
**【应用场景适配】**不同参数规模模型适用于不同场景,如轻量级模型适合容错率高场景,中等规应用场景适配模模型适合企业级复杂任务,超大规模模型适合云端调用。
3、版本选择
**【多参数版本】**DeepSeek-R1系列有"满血版"和"蒸馏版",参数量从1.5B到671B,适配不同硬件条件。
**【参数量】**参数量是衡量模型复杂度的一个重要指标。通常来说,参数越多,模型对复杂关系的建模能力越强,但计算资源的需求也会指数级上升。
**【性价比最佳】**从技术经济学的角度来看,32B模型在大多数企业级应用中表现出了最佳性价比一一既能胜任跨模态数据处理、学术文献解析等复杂认知任务,又不需要超算级别的硬件投入。
- 1.5B~14B轻量级模型==》RTX3060==》处理藏头诗==》逻辑断裂==》贪吃蛇游戏代码==》静态画面=》适合容错率较高的场景
- 32B~70B中等级别模型==》A100显卡==》贪吃蛇游戏代码==》可交互
- 671B超大规模=》云端API
三、DeepSeek功能与应用场景
1、功能解析
**【智能对话与推理】**DeepSeek具备强大的智能对话与推理能力,能解答高难度数学题、参与多轮深入对话,展现接近人类的思考能力,进行复杂逻辑推理。
**【代码开发】**对程序员而言,DeepSeek是得力助手,能生成多种编程语言代码,自动检测修复错误,优化代码,显著降低开发成本,提升编程效率。
**【多模态处理】**DeepSeek可同时处理图像、文本等多形式信息,进行综合分析,在阅读图文报告时能提供更准确深入的分析结果,拓展应用边界。
2、应用场景
**【政府与企业】**在政务领域,DeepSeek推动政务流程自动化,助力数据开放共享;在通信行业,实现视频会议纪要自动生成、代码优化、云平台运维成本降低。
**【教育领域】**对教师,DeepSeek辅助备课、参与双师课堂"、生成练习题、自动批改作业;对学生,提供趣味文章、作文批改建议、知识点总结、解题思路。
**【日常生活与职场】**DeepSeek可定制旅行攻略、解读体检报告、提供健康建议、协助决策;在职场,生成会议纪要、处理文档、辅助代码开发,提升工作效率。
四、DeepSeek能力边界与局限
1、能力边界
**【可靠性问题】**DeepSeek-R1"幻觉率"高于GPT-4,医疗诊断误诊率高于Claude-3.5,可靠性待提升,需谨慎用于对准确性要求极高的领域。
**【多轮对话能力】**DeepSeek多轮对话存在"记忆衰退"问题,超过一定轮数后遗忘上下文信息,影响连贯性,需优化以提升用户体验。
**【技术争议】**成本神话:训练成本低受质疑,实际H100芯片使用量可能高于公开数据;国产突破:核心框架基于开源系统,非完全自主可控;行业应用效果:部分案例数据夸大;开源诚意:关键参数和训练数据闭源。
2、应对策略
**【优势场景】**部署在复杂逻辑推理、中文自然语言处理、成本敏感任务等优势场景大胆应用,发挥DeepSeek潜力。
**【风险规避策略】**关键决策场景启用"三重验证"机制,人工审核、多模型对比、检查数据出处,降低AI"幻觉"风险;敏感数据应用考虑本地化部署,保障数据安全。
**【理性技术选型】**根据任务需求对比选择工具,如代码开发选DeepSeekCoder,创意写作选Claude,多模态任务选GPT-4V,发挥各工具优势。
五、DeepSeek低成本优势实现
1、模型结构创新
**【混合专家系统】**MoE改变传统模型"全员在线"方式,稀疏激活机制降低计算量和显存占用,减少对GPU依赖,提升资源利用率。
**【MLA技术】**MLA提升模型处理信息效率,减少冗余计算,进一步压缩成本,为模型装上更敏锐"眼晴",抓佳关键信息。
**【架构优化效果】**这些创新使DeepSeeki在保持高性能的同时,显著降低硬件资源需求,为实现低成本奠定基础,推动A技术普及。
2、训练流程优化
**【强化学习路径】**摒弃监督微调,采用纯强化学习,让模型自主学习,减少对昂贵标注数据依赖,降低训练成本。
**【算法与技术应用】**自研GRPO算法提升训练速度;FP8混合精度训练降低内存消耗;MTP技术加快推理速度,实现训练效率提升与成本降低。
**【优化成果】**通过这些优化,DeepSeek在训练过程中更高效利用资源,减少人力物力投入,提升模型性能与成本效益。
3、数据使用优化
**【数据筛选】**机制建立高效数据筛选机制,精准提取有价值信息,提升数据利用率,改变"数据越多越好"传统认知。
**【数据复用与冷启动】**强化学习中实现数据复用,发挥有限数据更大价值;具备冷启动能力,少量种子数据即可快速启动训练,达到较高性能。
**【数据优化成果】**通过优化数据使用,DeepSeek减少数据采集与处理成本,提升训练效率与模型性能,实现数据资源高效利用。
4、成本控制与生态协同
**【成本控制策略】**采用国产硬件提升芯片替代率;动态GPU租赁策略降低采购租赁成本;数据中心使用绿色电力与液冷技术降低能耗开支;分摊前期研发投入至多个衍生模型,降低边际训练成本。
**【生态协同效应】**开源策略吸引开发者参与优化改进,节省研发成本,加速技术迭代;联合云计算平台和办公软件厂商,打造完整AI生态体系,降低部署与资源获取成本;以竞争力API定价吸引用户,分摊固定成本,实现"以量取胜"
**【成本优势总结】**DeepSeeki通过技术创新与精细化管理,在降低成本道路上取得显著成果,为A大模型发展提供新思路,推动技术普及与行业发展,让更多人享受AI技术红利。
六、DeepSeek开源实践与影响
1、开源实践
**【开源内容与意义】**DeepSeek开源模型权重、推理框架、部分训练代码和数据清洗工具,构建生态支持体系,降低AI技术使用门槛,推动技术普及与落地。
**【开源限制与争议】**未开源完整训练代码、训练数据、MoE路由参数等,保留核心技术,维持商业优势。这种"有限开源"引发"真假开源"争议,但推动生态建设与技术迭代。
**【开源战略平衡】**DeepSeek的开源是"战略性开源",在"开放"与"保护核心技术"间找到平衡,吸引开发者参与,推动生态建设,同时维持商业竞争力。
2、开源影响
**【技术普及与生态建设】**开源降低AI技术使用门槛,让更多人接触前沿模型,加速AI技术普及和落地,为行业智能化转型注入动力,推动生态建设。
**【技术迭代与优化】**技术方案接受全球开发者检验和优化,有助于技术持续迭代和完善,提升模型性能与质量,推动AI技术发展。
**【潜在风险与挑战】**开源可能导致模型被滥用,甚至用于非法目的;"非完全开源"模式可能阻碍真正意义上的技术共享,引发争议与讨论。
**【开源新时代】**DeepSeek的开源实践为Al领域探索出新路径,释放A!走向开放、协作和普惠新时代的信号,推动AI技术发展与应用。