一、数据简介:本数据集系统整理了中国人力资源和社会保障部(原劳动和社会保障部)自2000年至2024年连续25年发布的年度《人力资源和社会保障事业发展统计公报》核心数据。作为中国政府在该领域的官方权威统计出版物,该数据集全面、连续地记录了中国在劳动就业、社会保障、收入分配等关键民生领域的发展历程与改革轨迹。
数据集采用"指标-年度"的二维结构,将分散于历年公报中的数百项关键统计指标进行提取、对齐与整合。主要涵盖劳动就业、社会保险、工资分配、劳动关系、劳动保障监察等。本数据集可用于经济学、社会学、公共管理等学科关于劳动力市场、社会保障、收入分配等领域的研究。
二、数据来源:内容提取自中华人民共和国人力资源和社会保障部(原劳动和社会保障部)于 2000 年至 2024 年逐年发布的《人力资源和社会保障事业发展统计公报》。
四、数据范围:2000-2024年
五、数据格式:excel
六、数据指标
|-----------|--------|
| 指标列 | 各年份数值列 |
| 遍历各年的指标名称 | 指标数值 |
七、数据展示
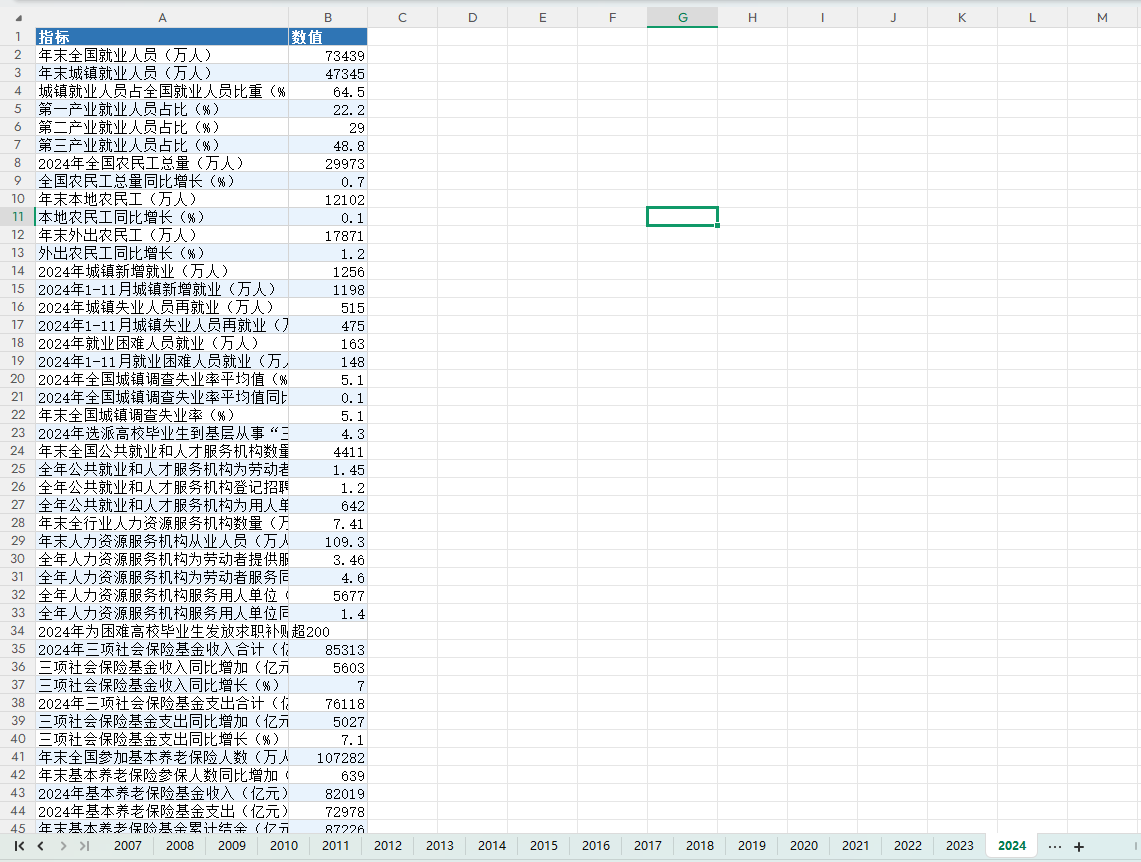
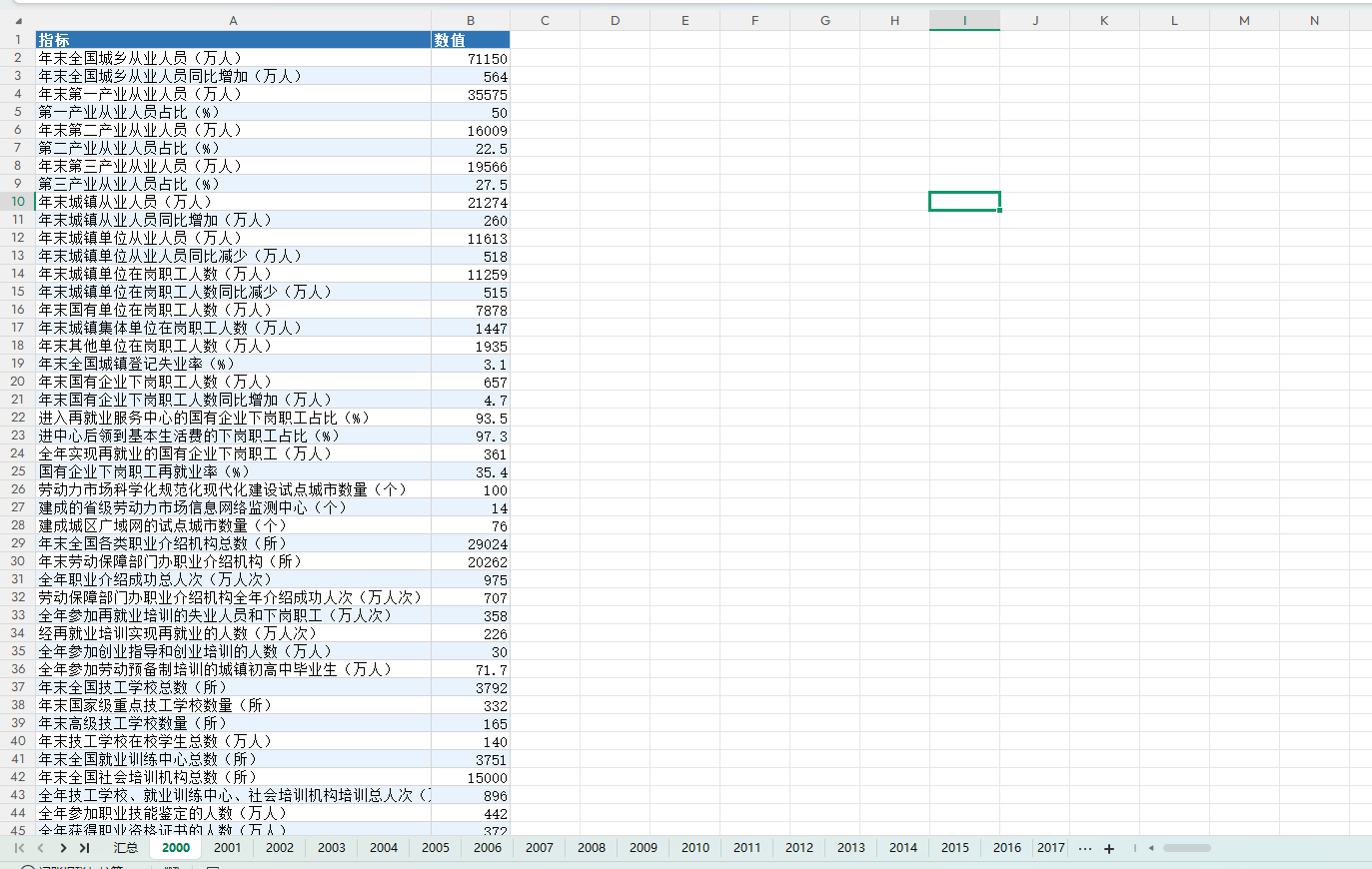
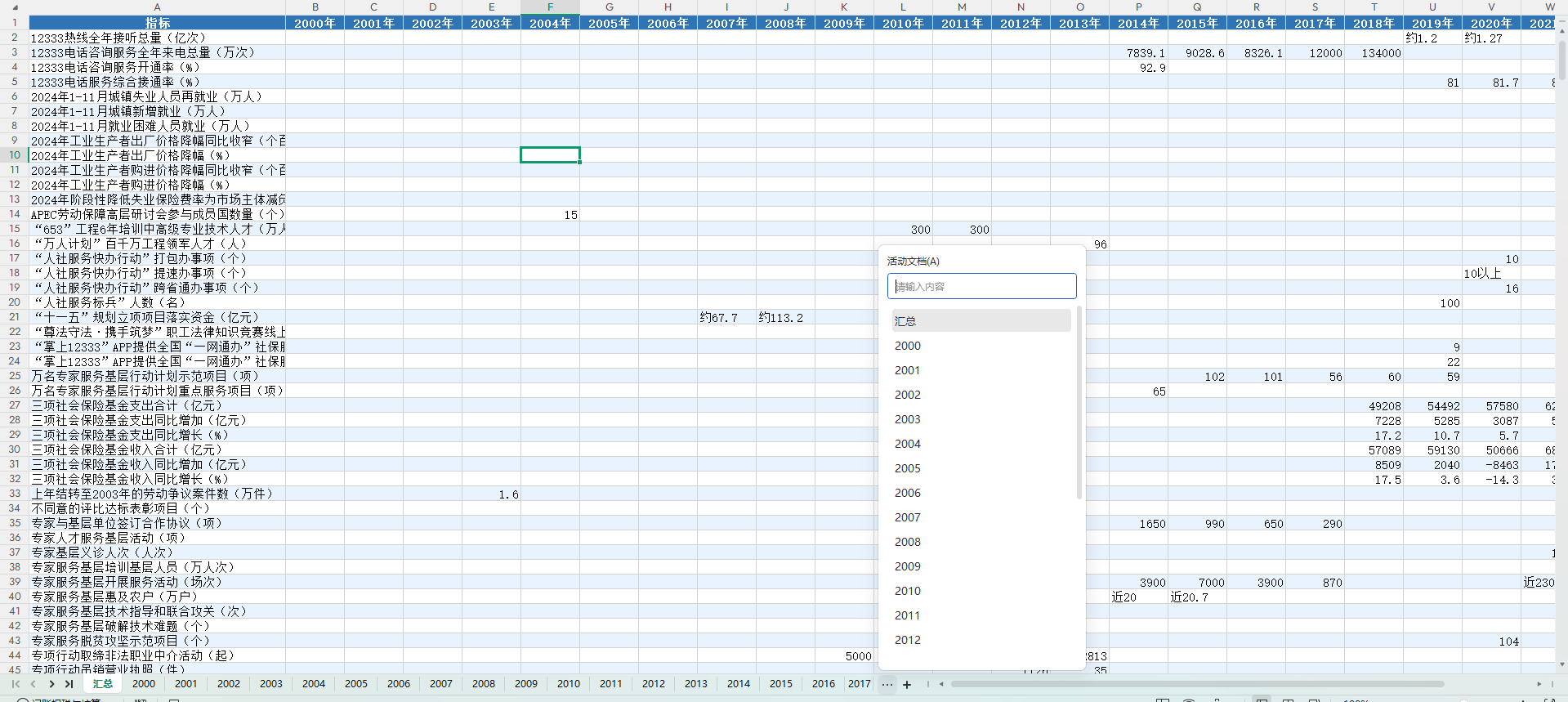
八、参考文献
1戚聿东,刘翠花,丁述磊.数字经济发展、就业结构优化与就业质量提升J.经济学动态,2020,(11):17-35.
九、下载链接 :https://download.csdn.net/download/li514006030/92660696