Elasticsearch实战:JavaRestClient操作索引与文档及海量数据批处理指南(黑马商城)
前言
Elasticsearch 概念与基础实操的内容:Elasticsearch 概念与基础实操
在现代的后端开发中,随着业务数据量的不断攀升,传统的数据库(如MySQL)在面对复杂的全文检索或高并发查询时往往会遇到性能瓶颈。这个时候,引入Elasticsearch来进行架构优化就显得尤为重要。
而在Java生态,尤其是Spring Boot项目中,使用JavaRestClient(通常指RestHighLevelClient或新版的ElasticsearchClient)来与ES服务端进行交互是最主流的选择。本文将系统地梳理如何使用JavaRestClient进行索引库和文档的CRUD操作,并结合实际的企业级业务场景,深入剖析海量数据的批处理导入方案。
📚 目录(点击跳转对应章节)
[一、 核心操作抽象:统一的API调用范式](#一、 核心操作抽象:统一的API调用范式)
[二、 索引库与文档的基础操作指南](#二、 索引库与文档的基础操作指南)
[三、 核心进阶:Bulk批处理与海量数据导入实战](#三、 核心进阶:Bulk批处理与海量数据导入实战)
一、 核心操作抽象:统一的API调用范式
无论是操作索引库还是操作文档,观察JavaRestClient的API设计,我们可以总结出一个非常标准且统一的"四步走"范式。理解了这个范式,就能举一反三地掌握所有的CRUD操作,而不需要死记硬背每个方法的细节:
- 创建请求对象 (Request) :例如
CreateIndexRequest、DeleteIndexRequest、IndexRequest、GetRequest等。每一个动作对应一个特定的请求类。 - 准备请求参数:包括指定操作的索引名称、文档的ID、需要写入或更新的JSON数据(Source)等。
- 发送请求 (Client Execution) :通过
client对象对应的API发送请求,例如client.indices().create(...)或是client.index(...),通常需要传入请求对象和请求选项(如RequestOptions.DEFAULT)。 - 解析响应 (Response):获取服务端返回的响应对象,判断操作是否成功,或者提取查询到的数据。
二、 索引库与文档的基础操作指南
在理解Elasticsearch时,我们可以将其与关系型数据库进行类比:索引库(Index)相当于数据库中的"表",而文档(Document)则相当于表中的"行数据"。
1. 索引库操作
-
创建与删除 :在系统初始化时,我们通常会根据业务模型定义好Mapping,然后通过Java代码创建索引。删除操作则用于清理不再需要的整个数据集。
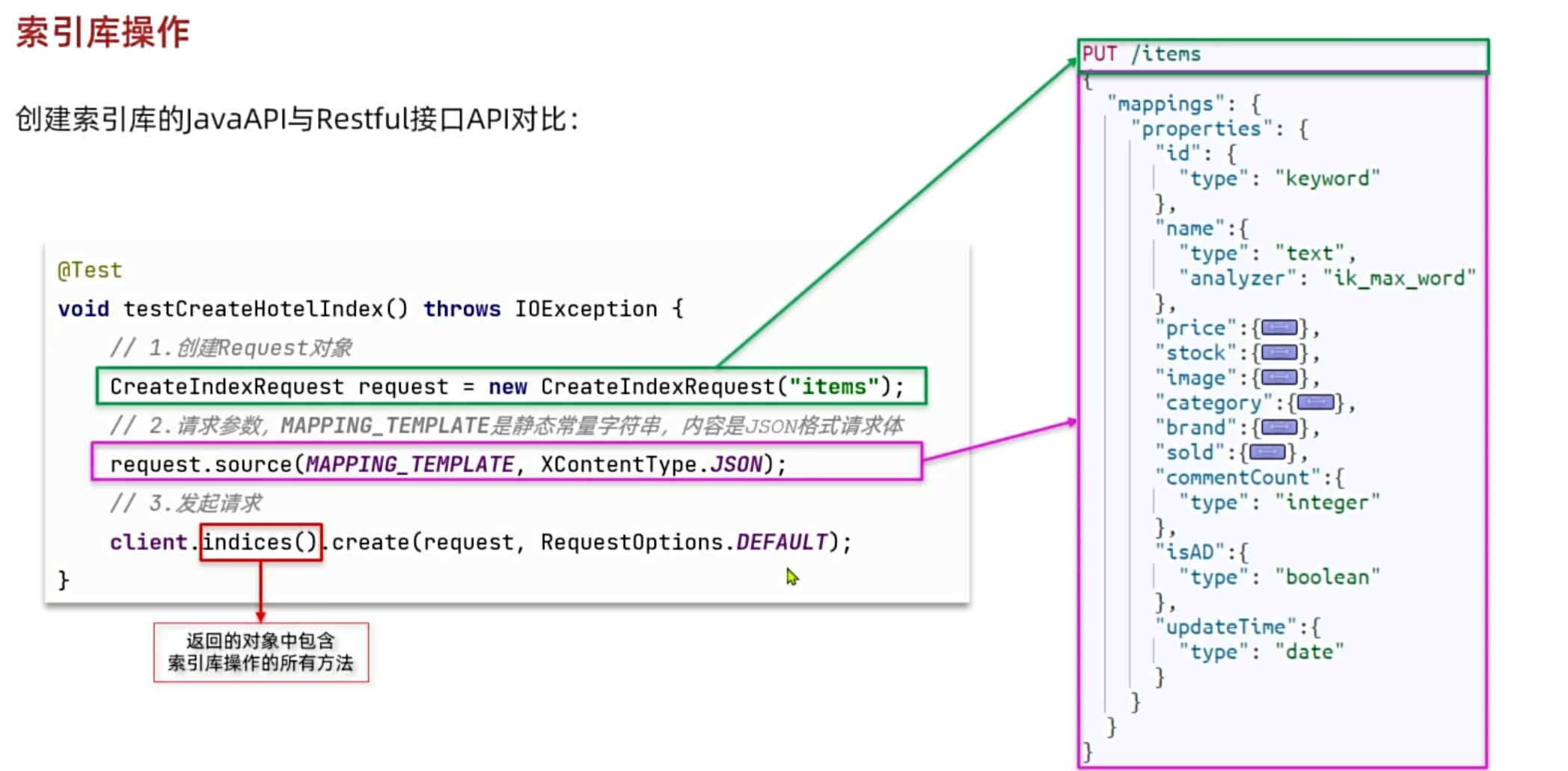

-
查询 :主要用于获取当前索引的结构信息(如别名、Mapping设置等),以验证索引是否按预期创建。

2. 文档的CRUD
- 新增与查询 :新增文档时,我们需要将Java实体类转换为JSON字符串(推荐使用工具库如Hutool的
JSONUtil或Fastjson/Jackson),然后作为请求的Source发送。查询文档则是根据ID精准定位数据。
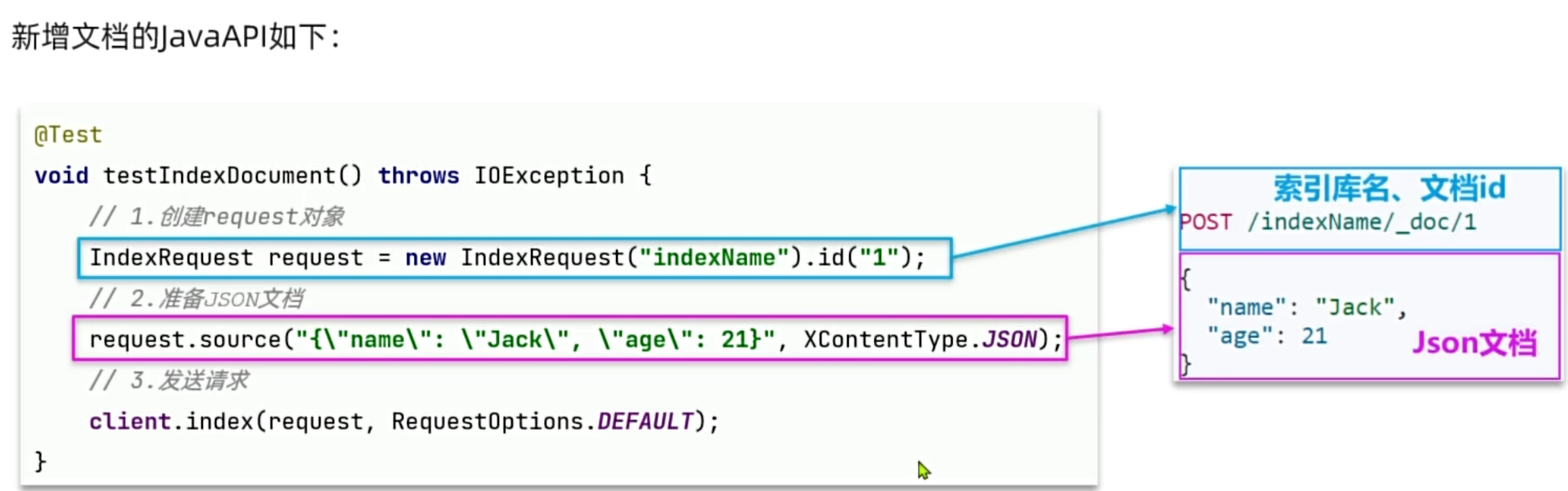
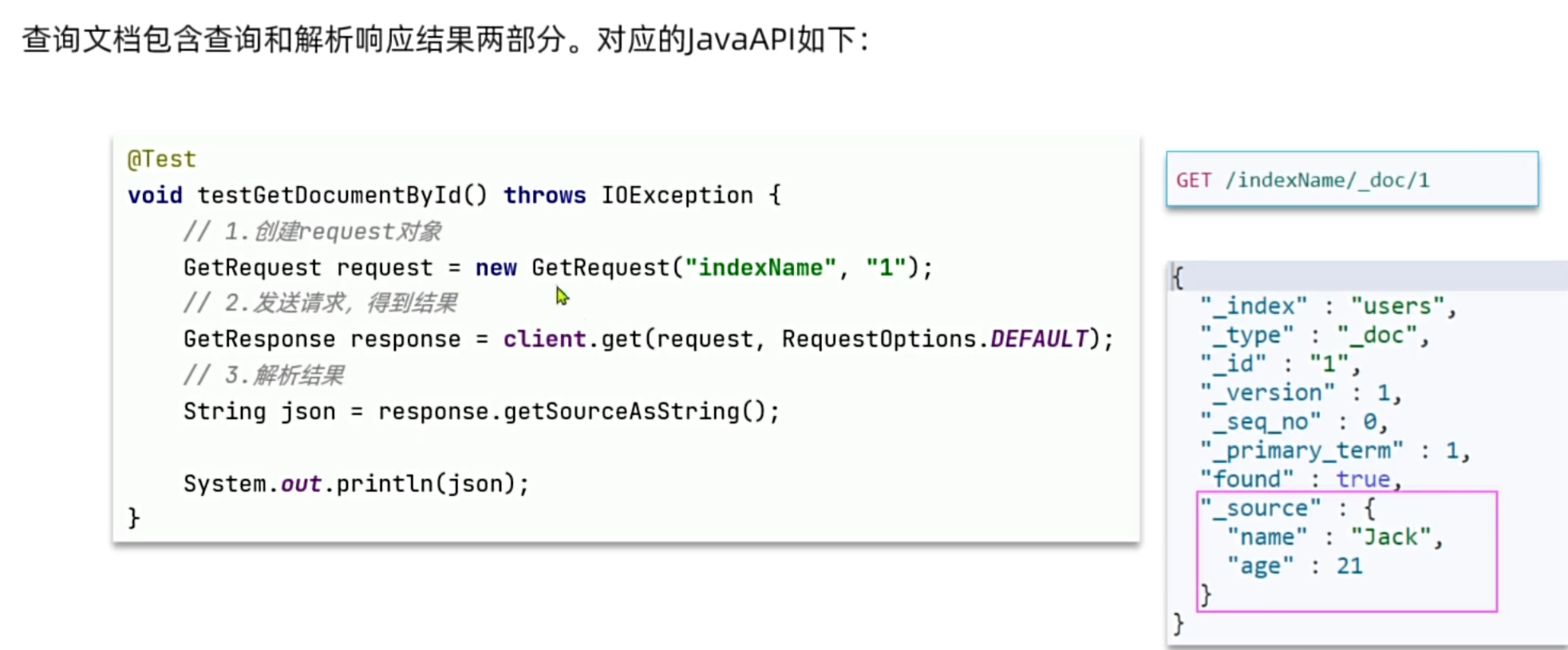
- 修改文档的两种姿势:
- 全量更新 :直接覆盖。本质上依然是发起一个Index请求,如果ID存在,ES会用新的JSON文档完全替换旧文档。
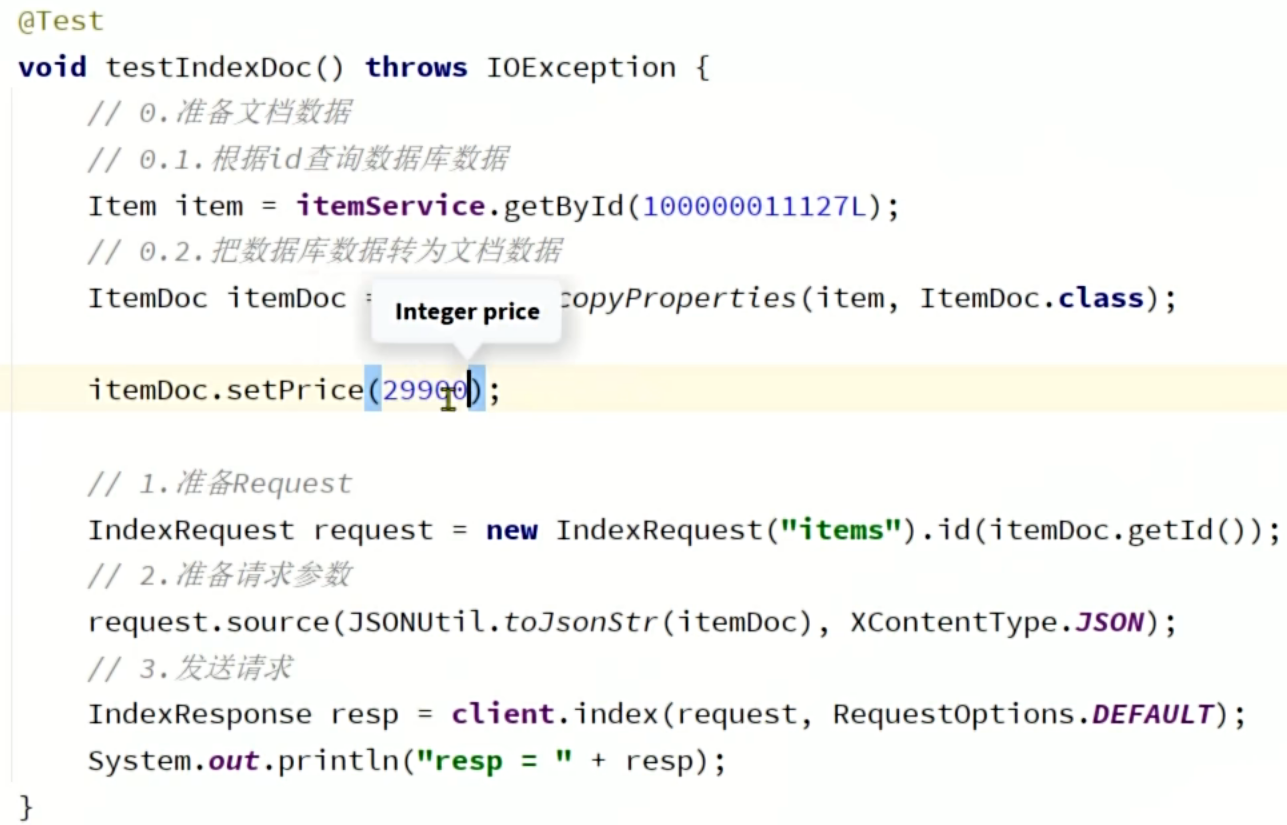
直接对要修改的内容进行set处理
-
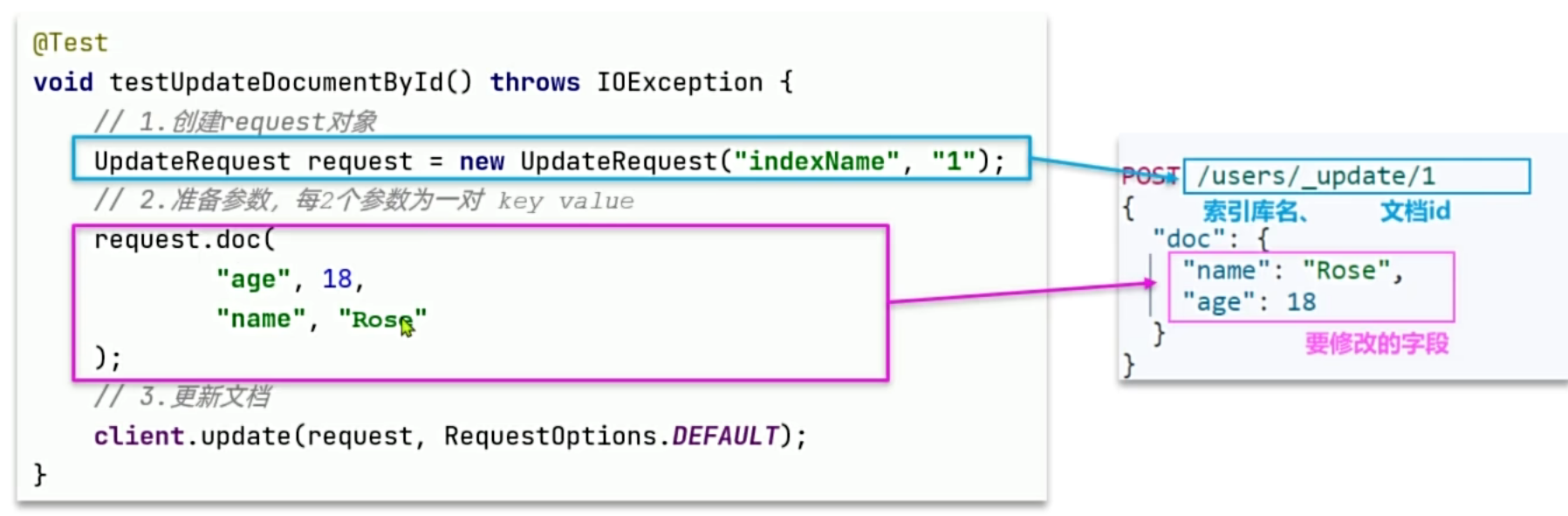
局部更新 :使用
UpdateRequest。这种方式只会修改我们显式指定的字段(set处理),未指定的字段保持原样。这在并发场景下或者只需要更新如"点赞数"、"状态"等单一字段时,能有效减少网络开销和覆盖冲突。
-
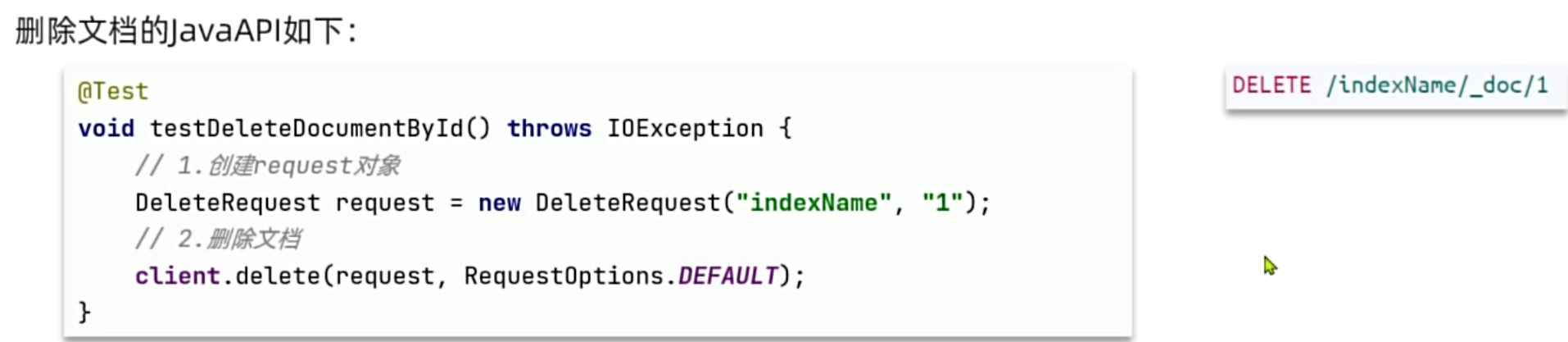
删除文档 :构建
DeleteRequest并传入对应的文档ID即可完成物理删除。
三、 核心进阶:Bulk批处理与海量数据导入实战
在真实的业务场景中(例如将电商系统中的商品数据同步到ES构建搜索引擎),我们面临的数据量往往是数十万甚至百万级别的。如果采用单条数据循环插入的方式,网络I/O的开销将极其巨大,耗时无法忍受。
这时候就需要使用 BulkRequest。BulkRequest 本质上是一个请求的容器,它允许我们将多个独立的 IndexRequest、UpdateRequest 或 DeleteRequest 组装在一起,然后通过一次网络请求发送给ES服务端批量执行。
业务实战:商品数据的平滑导入
批处理基础:
BulkRequest中提供了add方法,用以添加其它CRUD的请求:
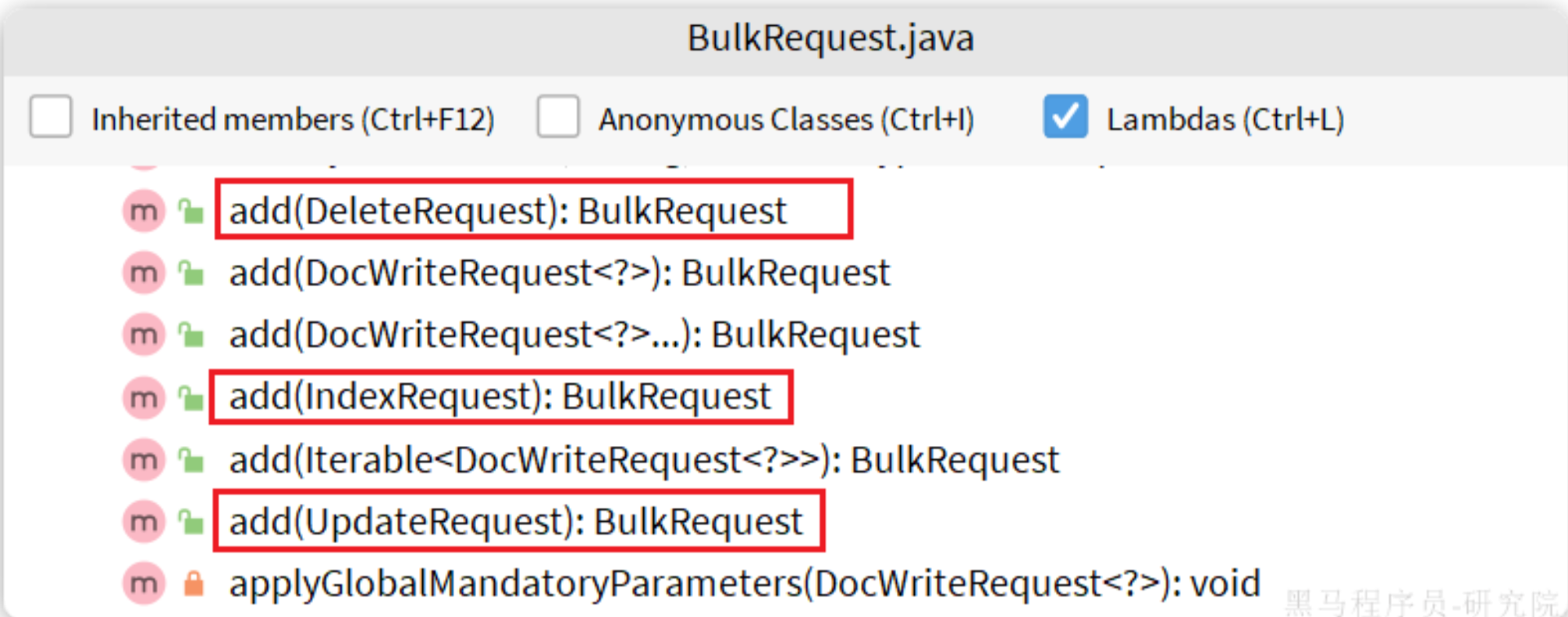
可以看到,能添加的请求有:
IndexRequest,也就是新增UpdateRequest,也就是修改DeleteRequest,也就是删除
示例:
java
@Test
void testBulk() throws IOException {
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备请求参数
request.add(new IndexRequest("items").id("1").source("json doc1", XContentType.JSON));
request.add(new IndexRequest("items").id("2").source("json doc2", XContentType.JSON));
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
}实际场景的业务开发
当我们要导入商品数据时,由于商品数量达到数十万,因此不可能一次性全部导入。建议采用循环遍历方式,每次导入1000条左右的数据。
下面这段代码展示了一个非常经典且健壮的后端批处理同步逻辑:
java
@Test
void testLoadItemDocs() throws IOException {
// 分页查询商品数据
int pageNo = 1;
int size = 1000;
while (true) {
Page<Item> page = itemService.lambdaQuery().eq(Item::getStatus, 1).page(new Page<Item>(pageNo, size));
// 非空校验
List<Item> items = page.getRecords();
if (CollUtils.isEmpty(items)) {
return; // 数据加载完毕,退出循环
}
log.info("加载第{}页数据,共{}条", pageNo, items.size());
// 1.创建Request
BulkRequest request = new BulkRequest("items");
// 2.准备参数,添加多个新增的Request
for (Item item : items) {
// 2.1.转换为文档类型ItemDTO
ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);
// 2.2.创建新增文档的Request对象
request.add(new IndexRequest()
.id(itemDoc.getId())
.source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON));
}
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
// 翻页
pageNo++;
}
}代码深度解析与技术思考
这段实战代码中包含了几个非常关键的工程化思考,值得深入体会:
- 为什么必须分页查询?避免OOM (Out Of Memory)
面对数十万的数据,如果一条SQL直接selectAll将所有数据加载到JVM内存中,极大概率会导致内存溢出导致服务崩溃。采用while(true)配合 MyBatis-Plus 的分页查询(每次限制1000条),能够以时间换空间,保证内存的平稳运行。size = 1000是一个经验值,既保证了每次Bulk请求的负载不会过大,又兼顾了网络传输的效率。 - 数据模型的解耦:PO与Doc的转换
代码中特意使用了BeanUtil.copyProperties(item, ItemDoc.class)。在规范的架构设计中,数据库实体类(PO/Item)和Elasticsearch的文档对象模型(Doc/ItemDoc)往往是不同的。数据库可能包含很多不需要被检索的冗余字段,转换为专门的ItemDoc可以剔除无效数据,减小ES存储压力,同时实现持久层与检索层的数据模型解耦。 - 优雅的循环终止条件
利用CollUtils.isEmpty(items)作为跳出循环的条件非常巧妙。当某一页查询不到任何记录时,说明数据库中的存量数据已经全部遍历且同步完毕,此时安全退出即可。
总结
掌握JavaRestClient不仅是熟练调用几个API那么简单,更重要的是理解其背后统一的设计理念。同时,在面对实际的高并发或海量数据场景时,要学会结合分页查询、数据模型转换以及Bulk批处理技术,编写出具备高可用性和高健壮性的企业级代码。这对于构建复杂的微服务系统以及提升后端系统的整体架构能力,都是非常宝贵的经验。