Redis 数据结构和内部编码
type 命令实际返回的就是当前键的数据结构类型,它们分别是:string(字符串)、list(列表)、hash(哈希)、set(集合)、zset(有序集合),但这些只是 Redis 对外的数据结构。
实际上 Redis 针对每种数据结构都有自己的底层内部编码实现,而且是多种实现,这样 Redis 会
在合适的场景选择合适的内部编码
|--------|--------------------|
| 数据结构 | 内部编码 |
| string | raw int embstr |
| hash | hashtable ziplist |
| list | linkedlist ziplist |
| set | hashtable intset |
| zset | skiplist ziplist |
可以看到每种数据结构都有⾄少两种以上的内部编码实现,例如 list 数据结构包含了 linkedlist 和ziplist 两种内部编码。同时有些内部编码,例如 ziplist,可以作为多种数据结构的内部实现,可以通过 object encoding 命令查询内部编码:
bash
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> lpush mylist a b c
(integer) 3
127.0.0.1:6379> object encoding hello
"embstr"
127.0.0.1:6379> object encoding mylist
"quicklist"Redis 这样设计有两个好处:
1)可以改进内部编码,而对外的数据结构和命令没有任何影响,这样⼀旦开发出更优秀的内部编码, 无需改动外部数据结构和命令,例如 Redis 3.2 提供了 quicklist,结合了 ziplist 和 linkedlist 两者的优势,为列表类型提供了⼀种更为优秀的内部编码实现,而对用户来说基本⽆感知。
2)多种内部编码实现可以在不同场景下发挥各⾃的优势,例如 ziplist 比较节省内存,但是在列表元素比较多的情况下,性能会下降,这时候 Redis 会根据配置选项将列表类型的内部实现转换为
linkedlist,整个过程用户同样无感知。
单线程架构
现在开启了三个 redis-cli 客户端同时执行命令。
bash
客户端 1 设置⼀个字符串键值对:
127.0.0.1:6379> set hello world
客户端 2 对 counter 做⾃增操作:
127.0.0.1:6379> incr counter
客户端 3 对 counter 做⾃增操作:
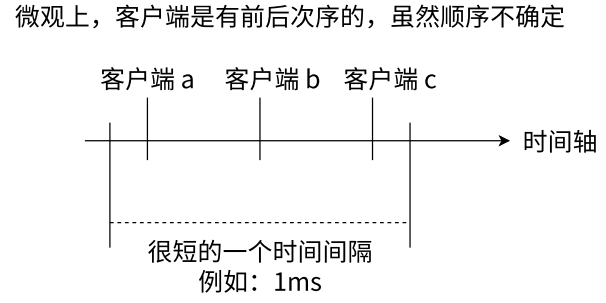
127.0.0.1:6379> incr counterRedis 是采用单线程模型执行命令的是指:虽然三个客户端看起来是同时要求 Redis 去执行命令的,但微观角度,这些命令还是采用线性方式去执行的,只是原则上命令的执行顺序是不确定的,但一定不会有两条命令被同步执行。
可以想象 Redis 内部只有一个服务窗口,多个客户端按照它们达到的先后顺序被排队在窗口前,依次接受 Redis 的服务,所以两条 incr 命令无论执行顺序,结果一定是 2,不会发生并发问题,这个就是 Redis 的单线程执行模型。
为什么单线程还能这么快
a. 纯内存访问。Redis 将所有数据存放在内存中,内存的响应时长大约为 100 纳秒,这是 Redis 能够实现高性能访问的重要基础。
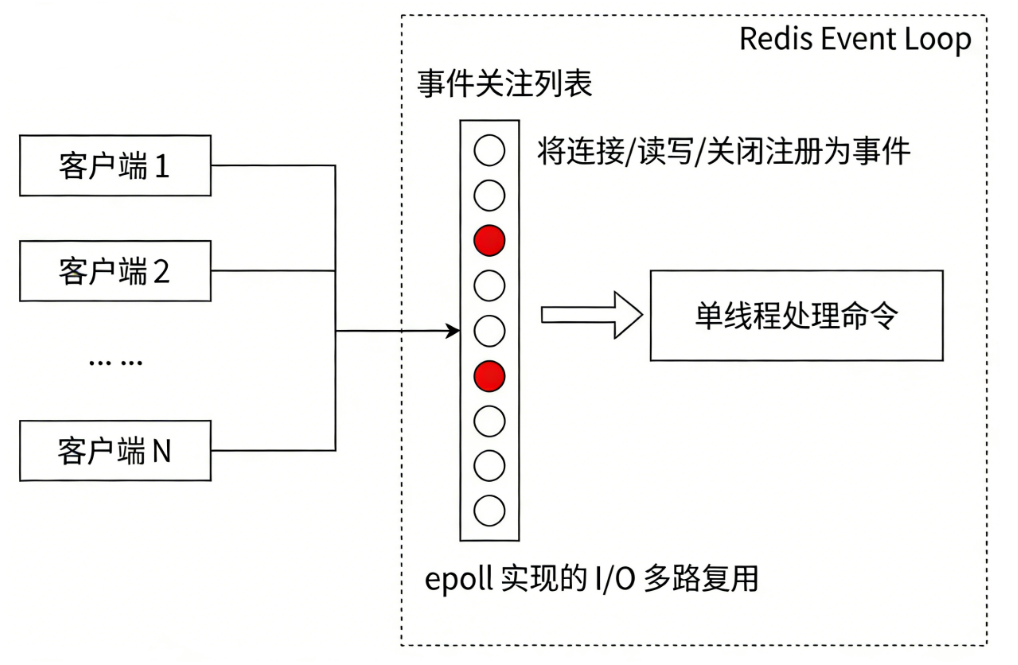
b. 非阻塞 IO。Redis 使用 epoll 作为 I/O 多路复用技术的实现,再结合自身的事件处理模型,将 epoll 中的连接、读写、关闭等操作转换为事件,不在网络 I/O 上浪费过多时间,如图所示。
c. 单线程避免了线程切换和竞态产生的消耗。单线程可以简化数据结构和算法的实现,让程序模型更简单;同时避免了多线程环境下,因竞争共享数据而产生的线程切换与等待开销。
虽然单线程给 Redis 带来很多好处,但还是有一个致命的问题:对于单个命令的执行时间都是有要求的。如果某个命令执行过长,会导致其他命令全部处于等待队列中,迟迟等不到响应,造成客户端的阻塞,对于 Redis 这种高性能的服务来说是非常严重的,所以 Redis 是面向快速执行场景的数据库。