今天我们推出最新模型 MiniMax-M2.5。
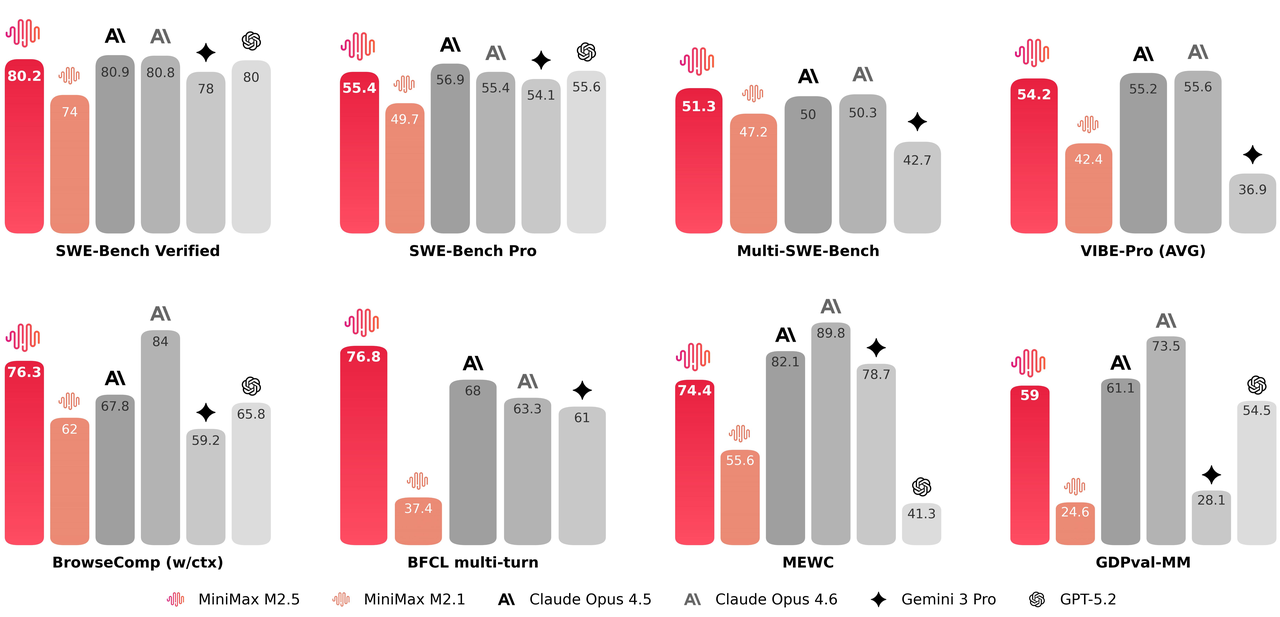
该模型在数十万复杂现实场景中通过强化学习进行广泛训练,在编程、智能体工具使用与搜索、办公及一系列高经济价值任务上达到业界顶尖水平,其**SWE-Bench Verified通过率80.2%、Multi-SWE-Bench 51.3%、BrowseComp(含上下文管理)76.3%**的表现尤为亮眼。
经过高效推理与任务分解优化训练,M2.5执行复杂智能体任务时展现惊人速度,完成SWE-Bench Verified评估比M2.1快37% ,与Claude Opus 4.6速度持平。
M2.5是首个让用户无需顾虑成本的尖端模型,真正实现"智能廉价如水电"的承诺。以每秒100 token的速度持续运行一小时仅需1美元。若降至每秒50 token,成本可低至0.3美元。我们希望M2.5的速度与成本优势能催生革命性智能体应用。
编程表现
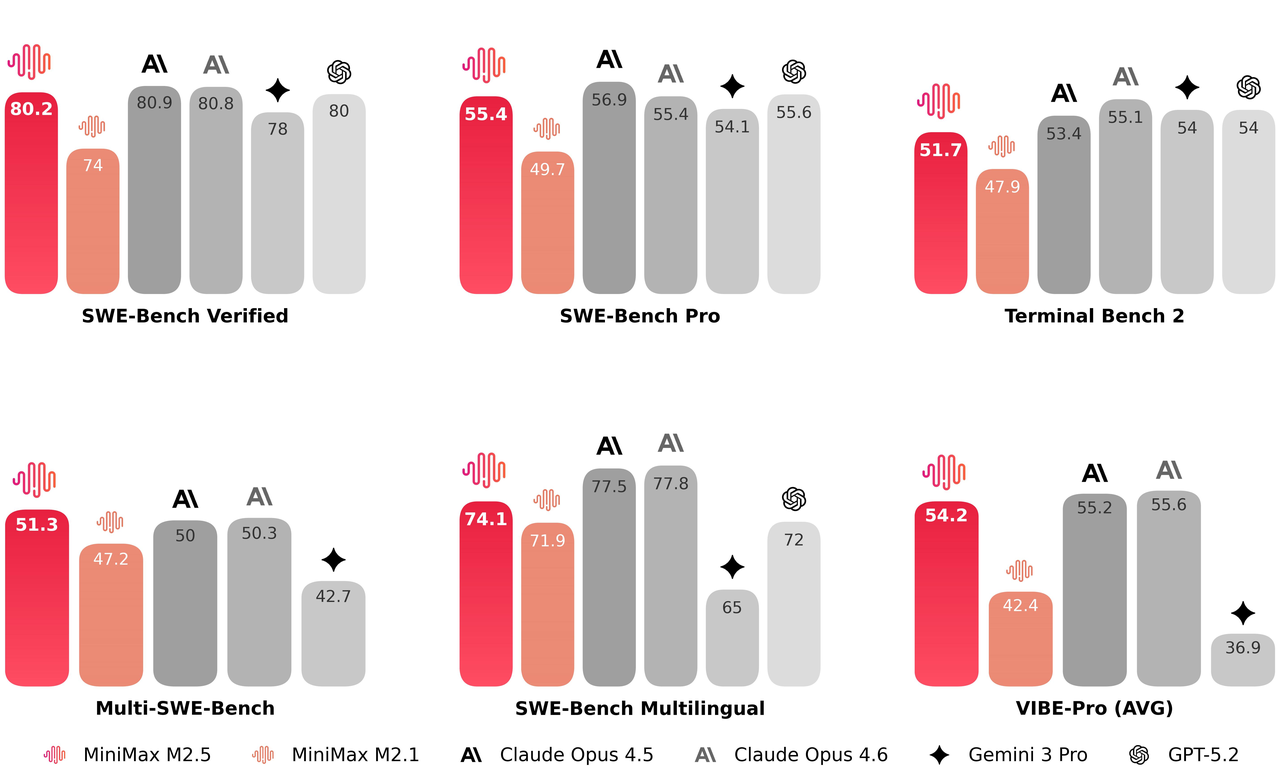
在编程评估中,MiniMax-M2.5相较前代取得显著进步,达到业界顶尖水准。其多语言任务表现尤为突出。
相较于前代模型的显著提升在于,M2.5具备了建筑师般的思维规划能力。该模型在训练过程中展现出编写技术方案(Spec)的倾向:在编写任何代码之前,M2.5会主动从资深软件架构师视角对项目的功能模块、结构设计和界面交互进行拆解规划。
M2.5基于20余万真实开发环境数据训练,支持包括Go/C/C++/TypeScript/Rust/Kotlin/Python/Java/JavaScript/PHP/Lua/Dart/Ruby等10余种编程语言。其能力远不止于修复BUG,而是在复杂系统开发全周期均展现出可靠表现:从0到1的系统设计与环境搭建,1到10的系统开发,10到90的功能迭代,直至90到100的完整代码审查与系统测试。涵盖Web/Android/iOS/Windows等多平台全栈项目,包含服务端API/业务逻辑/数据库等完整模块,而非仅前端网页demo。
为评估这些能力,我们还将VIBE基准测试升级为更具挑战性的Pro版本,大幅提升任务复杂度、领域覆盖度和评估精准度。总体而言,M2.5表现与Opus 4.5相当。
我们重点关注了模型在分布外测试框架上的泛化能力。通过不同编程代理框架在SWE-Bench Verified评估集上测试性能表现:
- Droid框架:79.7分(M2.5模型) > 78.9分(Opus 4.6模型)
- OpenCode框架:76.1分(M2.5模型) > 75.9分(Opus 4.6模型)
搜索和工具调用
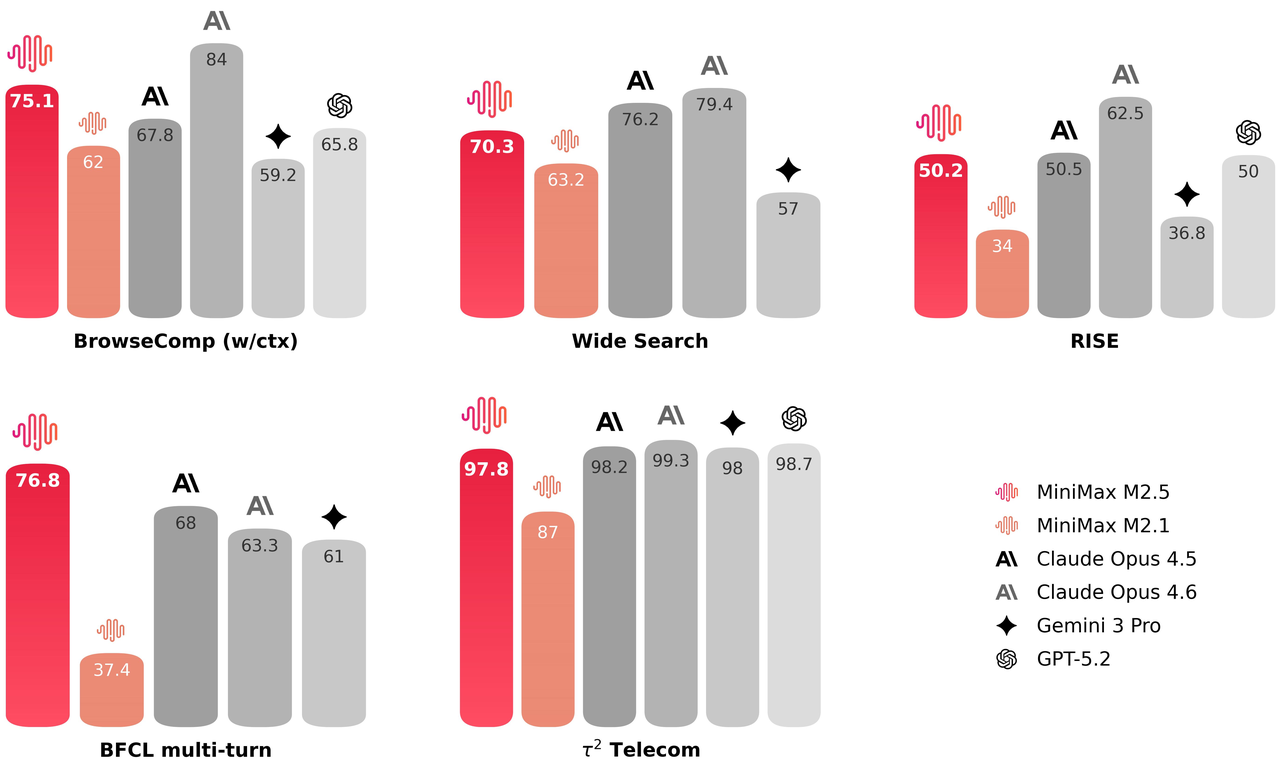
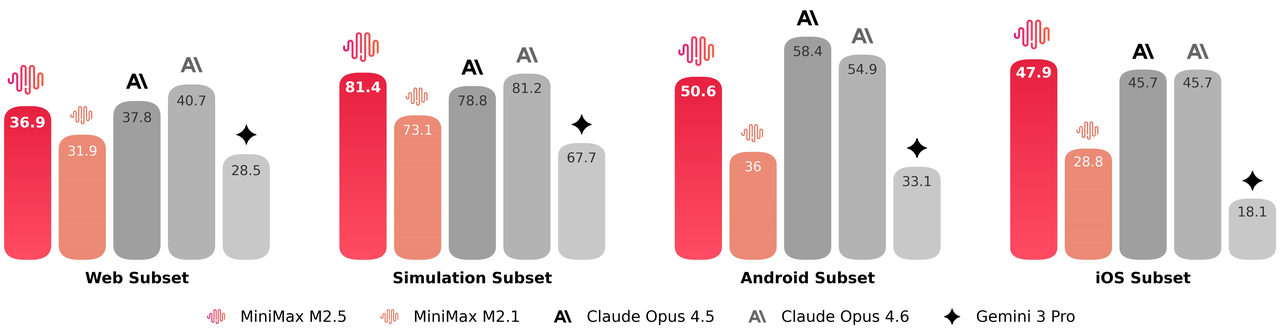
有效的工具调用和搜索是模型自主处理更复杂任务的前提。在BrowseComp、Wide Search等基准测试中,M2.5都实现了业界领先的性能表现。同时模型的泛化性也有所提升------M2.5在面对不熟悉的脚手架环境时展现出了更稳定的性能。
在专业人类专家执行的研究任务中,使用搜索引擎只是流程中的一小部分;大部分工作需要在信息密集的网页中进行深度探索。为此我们构建了RISE(Realistic Interactive Search Evaluation)来测量模型在真实专业任务中的搜索能力。结果显示M2.5在真实场景的专家级搜索任务中表现卓越。
相较于前代模型,M2.5在处理智能体任务时也展现出更优的决策能力:它学会了用更精准的搜索轮次和更好的token效率来解决问题。例如在BrowseComp、Wide Search和RISE等多个智能体任务中,M2.5都用更少的轮次取得了更好的结果,相比M2.1减少了约20%的轮次使用量。这说明模型已不仅是在把答案做对,更是在用更高效率的路径推理出结果。
办公场景
M2.5被训练为能在办公场景中产出真正可交付的成果。为此我们与金融、法律、社会科学等领域的资深专家展开了深度合作。他们设计需求、提供反馈、参与标准制定,并直接参与数据构建,将行业内的隐性知识带入了模型的训练流程。基于此,M2.5在Word、PPT、Excel财务建模等高价值工作场景中实现了显著的能力提升。在评估侧,我们构建了内部协作智能体评估框架(GDPval-MM),通过成对比较同时评估交付物的质量和智能体轨迹的专业性,同时监控全流程的token开销来估算模型在现实场景中的生产力收益。与其他主流模型的对比中取得了59.0%的平均胜率。
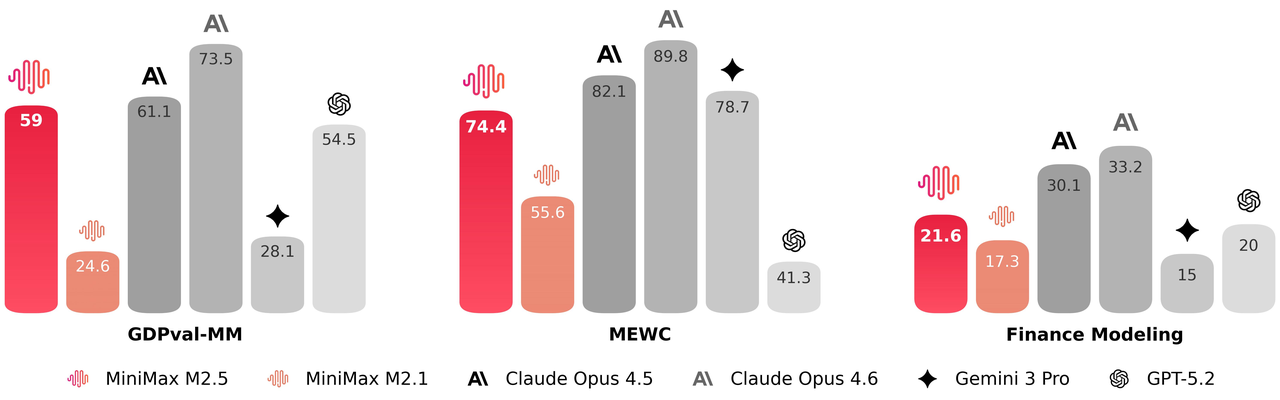
效率
现实世界充满截止日期与时间限制,任务完成速度是实际刚需。模型完成任务耗时取决于其任务分解效能、token利用效率和推理速度。M2.5原生服务速率达每秒100个token,是其他前沿模型的近两倍。此外,我们的强化学习机制激励模型进行高效推理与最优任务分解。基于这三大因素,M2.5在复杂任务中能实现显著的时间节省。
以SWE-Bench Verified测试为例,M2.5平均每个任务消耗352万token,而M2.1消耗372万token。得益于并行工具调用等能力提升,端到端运行时间从平均31.3分钟降至22.8分钟,提速37%。该运行时间与Claude Opus 4.6的22.9分钟持平,而单任务总成本仅为后者的10%。
成本
我们设计M2系列基座模型的目标是实现复杂智能体应用无需顾虑成本。M2.5已接近达成该目标。我们发布M2.5和M2.5-Lightning两个版本,能力相同但速度有别。M2.5-Lightning稳态吞吐达每秒100token,比其他前沿模型快两倍,输入token百万成本0.3美元,输出token百万成本2.4美元。吞吐50token/秒的M2.5成本减半。两版本均支持缓存,按输出价格计算,M2.5成本仅为Opus、Gemini 3 Pro和GPT-5的十分之一至二十分之一。
以每秒100输出token计算,M2.5连续运行一小时成本1美元;50TPS时价格降至0.3美元。换言之,1万美元可维持4个M2.5实例全年不间断运行。我们相信M2.5为经济系统中的智能体开发运营提供了近乎无限的可能性。对于M2系列,唯一剩下的问题是如何持续突破模型能力边界。
进化速率
从去年10月下旬至今的三个半月里,我们相继发布M2、M2.1和M2.5,模型进化速度超出最初预期。在备受推崇的SWE-Bench Verified基准测试中,M2系列的进步速度显著快于Claude、GPT和Gemini等同类模型家族。
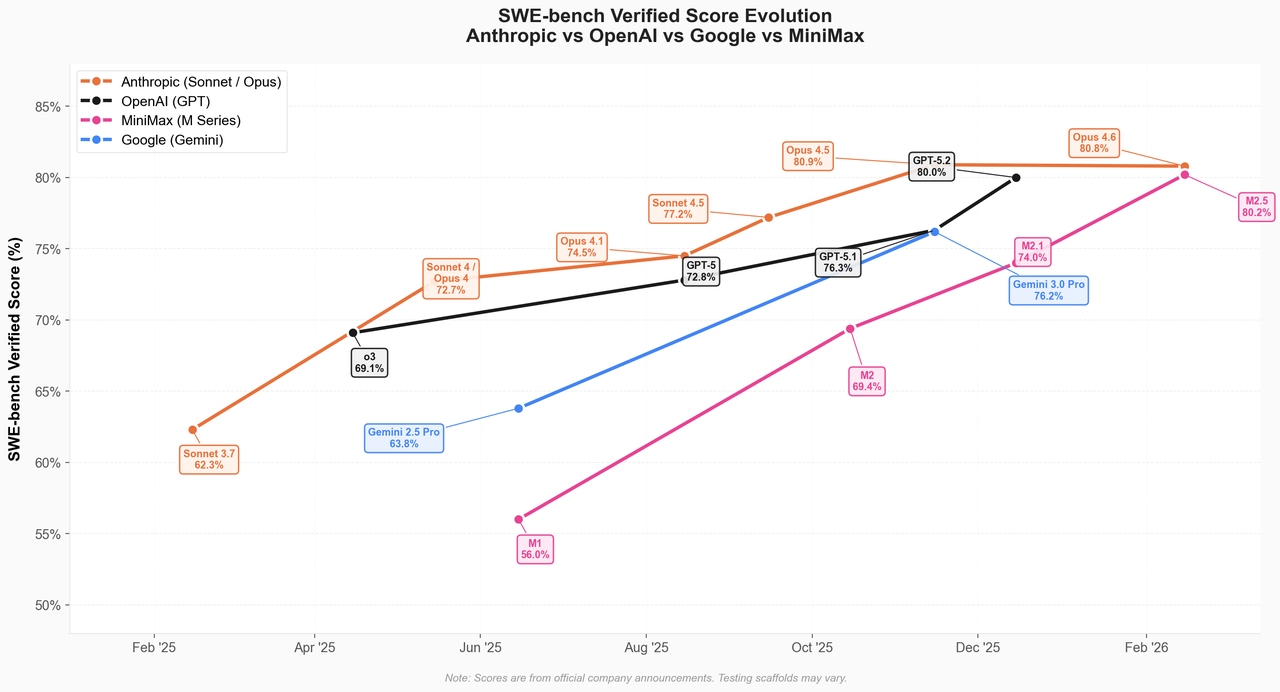
强化学习的规模化发展
上述进展的核心驱动力之一在于强化学习的规模化应用。随着模型训练过程的推进,我们也在持续收获其能力提升带来的效益。目前公司内部绝大多数任务与工作场景均已转化为强化学习的训练环境,此类环境数量迄今已达数十万量级。与此同时,我们在智能体强化学习框架、算法设计、奖励信号机制及基础设施工程等领域开展了系统性工作,以支撑强化学习训练的持续规模化扩展。
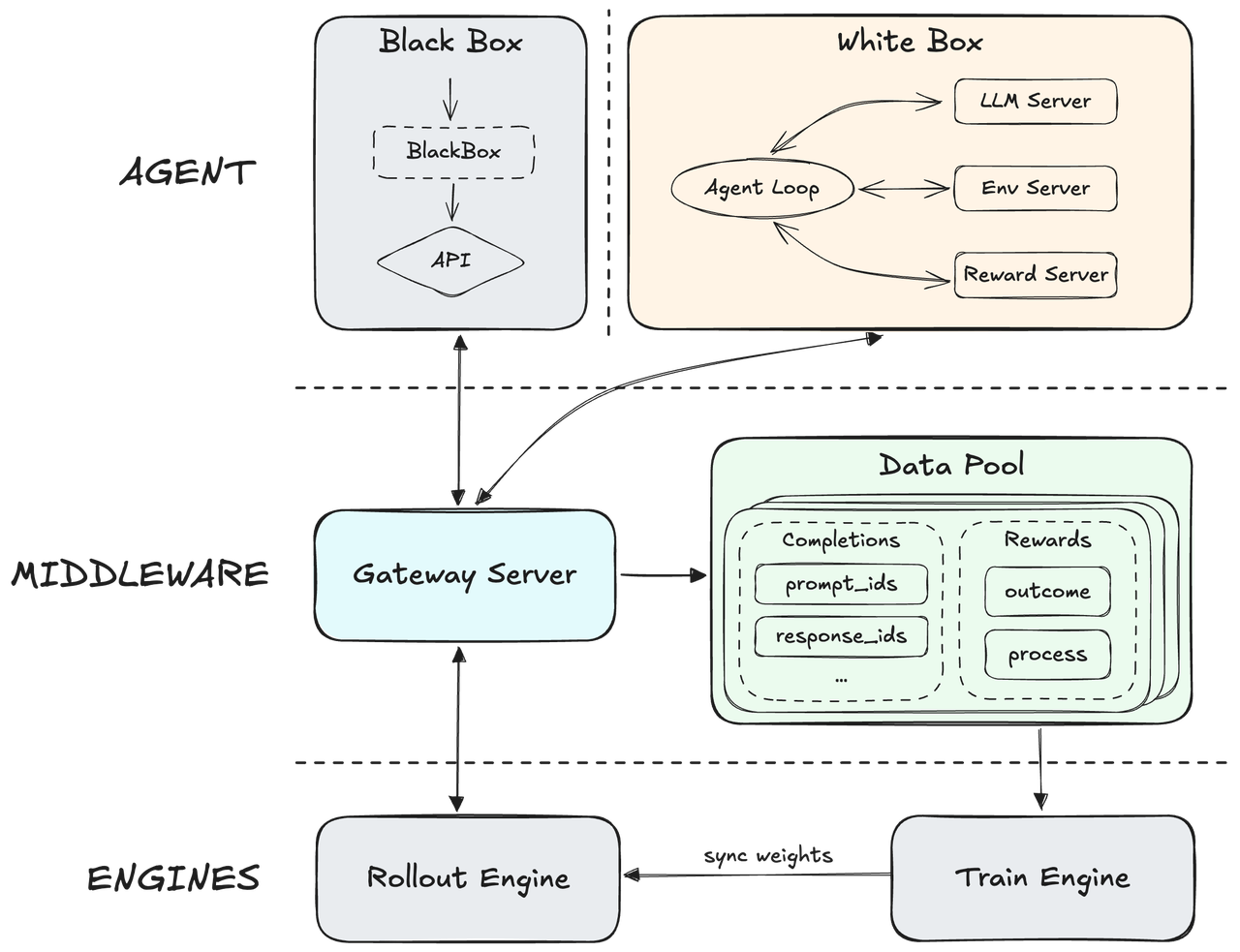
Forge------原生智能体强化学习框架
我们自主研发的原生智能体强化学习框架Forge,通过引入中间层实现了底层训练-推理引擎与智能体的完全解耦。该架构既能支持任意智能体的集成,又能优化模型在智能体框架与工具间的泛化能力。为提升系统吞吐量,我们优化了异步调度策略以平衡系统吞吐与样本非策略性,并创新设计了树状结构训练样本合并策略,最终实现约40倍的训练加速效果。
智能体强化学习算法与奖励设计
在算法层面,我们延续使用了去年初提出的CISPO算法,以确保混合专家模型在大规模训练中的稳定性。针对智能体推演中长上下文带来的信用分配难题,我们引入了过程奖励机制,实现对生成质量的端到端监控。此外,为深度契合用户体验,我们通过智能体轨迹评估任务完成时长,实现了模型智能度与响应速度的最优平衡。
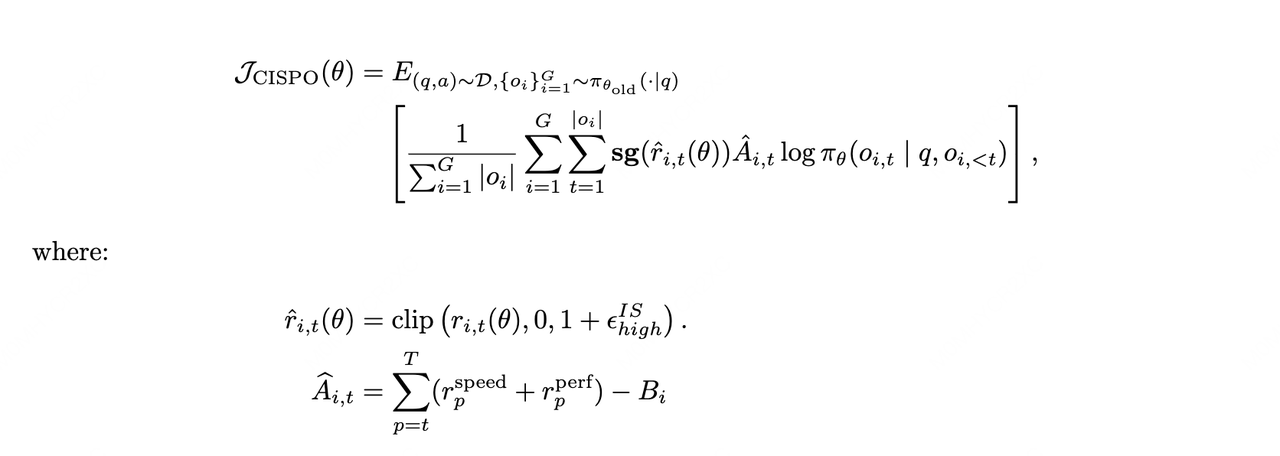
我们将在另一篇技术博客文章中发布关于强化学习规模化的更全面介绍。
MiniMax智能体:M2.5作为专业员工
M2.5已全面部署于MiniMax智能体,提供最佳智能体体验。
我们已将核心信息处理能力提炼为标准化的办公技能,深度集成于MiniMax智能体中。在MAX模式下,当处理Word排版、PPT编辑、Excel计算等任务时,MiniMax智能体会根据文件类型自动加载相应办公技能,提升任务输出质量。
此外,用户可将办公技能与特定行业专业知识相结合,创建可复用的专家模块以适应具体任务场景。
以行业研究为例:通过将成熟的研究框架SOP(标准操作流程)与Word技能相结合,智能体可严格遵循既定框架自动获取数据、整理分析逻辑并输出格式规范的研究报告------而非仅生成原始文本段落。在金融建模场景中,通过将机构专有的建模标准与Excel技能结合,智能体可按照特定风控逻辑和计算标准自动生成并验证复杂金融模型,而非简单输出基础表格。
截至目前,用户已在MiniMax智能体上构建了超过10,000个专家模块,且数量仍在快速增长。MiniMax也针对办公、金融、编程等高频场景,在智能体平台上构建了多套深度优化、开箱即用的专家套件。
MiniMax自身已成为首批受益于M2.5能力的企业。在公司日常运营中,30%的整体任务由M2.5自主完成,覆盖研发、产品、销售、人力资源及财务等部门------渗透率持续攀升。在编程场景表现尤为突出,M2.5生成的代码占新提交代码量的80%。
使用指南
MiniMax智能体平台: https://agent.minimax.io/
MiniMax API开放平台: https://platform.minimax.io/
MiniMax编程方案订阅: https://platform.minimax.io/subscribe/coding-plan
本地化部署指南
从HuggingFace仓库下载模型: https://huggingface.co/MiniMaxAI/MiniMax-M2.5
推荐使用以下推理框架(按字母顺序排列)部署模型:
SGLang框架
建议使用SGLang框架部署MiniMax-M2.5模型。具体操作请参考我们的SGLang中文部署指南。
vLLM
我们推荐使用vLLM来部署MiniMax-M2.5。请参阅我们的vLLM部署指南。
Transformers
我们推荐使用 Transformers 来部署 MiniMax-M2.5。请参考我们的 Transformers 部署指南。
KTransformers
我们推荐使用KTransformers来部署MiniMax-M2.5。具体操作请参考KTransformers部署指南
ModelScope
你也可以从 modelscope 获取模型权重。
推理参数
我们推荐使用以下参数以获得最佳性能:temperature=1.0,top_p = 0.95,top_k = 40。默认系统提示:
You are a helpful assistant. Your name is MiniMax-M2.5 and is built by MiniMax.工具调用指南
请参阅我们的工具调用指南。
联系我们
通过model@minimax.io联系我们。
附录
M2.5的更多基准测试结果:
| Benchmark | MiniMax-M2.5 | MiniMax-M2.1 | Claude Sonnet 4.5 | Claude Opus 4.5 | Claude Opus 4.6 | Gemini 3 Pro | GPT-5.2 (thinking) |
|---|---|---|---|---|---|---|---|
| AIME25 | 86.3 | 83.0 | 88.0 | 91.0 | 95.6 | 96.0 | 98.0 |
| GPQA-D | 85.2 | 83.0 | 83.0 | 87.0 | 90.0 | 91.0 | 90.0 |
| HLE w/o tools | 19.4 | 22.2 | 17.3 | 28.4 | 30.7 | 37.2 | 31.4 |
| SciCode | 44.4 | 41.0 | 45.0 | 50.0 | 52.0 | 56.0 | 52.0 |
| IFBench | 70.0 | 70.0 | 57.0 | 58.0 | 53.0 | 70.0 | 75.0 |
| AA-LCR | 69.5 | 62.0 | 66.0 | 74.0 | 71.0 | 71.0 | 73.0 |
评估方法:
- SWE基准测试:SWE-bench Verified、SWE-bench Multilingual、SWE-bench-pro和Multi-SWE-bench在内部基础设施上使用Claude Code作为脚手架进行测试,覆盖默认系统提示词,结果取4次运行平均值。此外,SWE-bench Verified还在Droid和Opencode脚手架上使用默认提示词进行了评估。
- Terminal Bench 2:使用Claude Code 2.0.64作为评估脚手架进行测试。修改了部分问题的Dockerfiles以确保问题本身的正确性,统一将沙箱规格扩展至8核CPU和16GB内存,超时时间统一设置为7,200秒,并为每个问题配备基础工具集(ps、curl、git等)。虽未对超时进行重试,但增加了对脚手架空响应的检测机制,对最终响应为空的任务进行重试以处理各种异常中断情况。最终结果取4次运行平均值。
- VIBE-Pro:内部基准。使用Claude Code作为脚手架自动验证程序的交互逻辑和视觉效果。所有分数均通过统一流程计算,包含需求集、容器化部署和动态交互环境。最终结果取3次运行平均值。
- BrowseComp:采用与WebExplorer(Liu等人,2025年)相同的智能体框架。当令牌使用量超过最大上下文的30%时,丢弃全部历史记录。
- Wide Search:采用与WebExplorer(Liu等人,2025年)相同的智能体框架。
- RISE:内部基准。包含人类专家的真实问题,评估模型在复杂网络交互场景下的多步信息检索与推理能力。在WebExplorer(Liu等人,2025年)智能体框架基础上增加了基于Playwright的浏览器工具套件。
- GDPval-MM:内部基准。基于开源GDPval测试集,使用定制化智能体评估框架,由LLM-as-a-judge对完整轨迹进行成对胜/平/负判断。单任务平均令牌成本根据各厂商官方API定价(无缓存)计算。
- MEWC:内部基准。基于MEWC(微软Excel世界锦标赛)构建,包含2021-2026年Excel电竞比赛主赛区及其他赛区的179道赛题,评估模型理解竞赛Excel表格并使用Excel工具解题的能力。通过逐个比对输出单元格与答案单元格的值计算得分。
- 金融建模:内部基准。主要包含行业专家构建的金融建模问题,涉及通过Excel工具执行的端到端研究分析任务。每个问题均采用专家设计的评分标准进行打分。最终结果取3次运行平均值。
- AIME25 ~ AA-LCR:基于Artificial Analysis智能指数排行榜涵盖的公开评测集及评测方法,通过内部测试获得。