目录
-
- 摘要
- [第一章 系统背景与技术选型](#第一章 系统背景与技术选型)
-
- [1.1 运维可观测性的挑战](#1.1 运维可观测性的挑战)
- [1.2 为什么选择 Rust](#1.2 为什么选择 Rust)
- [1.3 为什么选择 DeepSeek V3.2](#1.3 为什么选择 DeepSeek V3.2)
- [第二章 环境准备与基础设施搭建](#第二章 环境准备与基础设施搭建)
-
- [2.1 模型服务接入](#2.1 模型服务接入)
- [2.2 Rust 项目初始化](#2.2 Rust 项目初始化)
- [2.3 依赖管理与生态集成](#2.3 依赖管理与生态集成)
- [第三章 核心架构设计与模块实现](#第三章 核心架构设计与模块实现)
-
- [3.1 模块化设计理念](#3.1 模块化设计理念)
- [3.2 主程序控制流 (main.rs)](#3.2 主程序控制流 (main.rs))
- [3.3 异常检测引擎 (anomaly_detector.rs)](#3.3 异常检测引擎 (anomaly_detector.rs))
- [3.4 诊断引擎与报告生成 (diagnostic_engine.rs)](#3.4 诊断引擎与报告生成 (diagnostic_engine.rs))
- [3.5 LLM 客户端实现 (llm_client.rs)](#3.5 LLM 客户端实现 (llm_client.rs))
- [3.6 高性能日志解析 (log_parser.rs)](#3.6 高性能日志解析 (log_parser.rs))
- [第四章 编译、调试与问题修正](#第四章 编译、调试与问题修正)
-
- [4.1 编译过程](#4.1 编译过程)
- [4.2 遇到的问题与修正](#4.2 遇到的问题与修正)
- [第五章 案例分析与诊断验证](#第五章 案例分析与诊断验证)
-
- [5.1 构造故障场景](#5.1 构造故障场景)
- [5.2 执行诊断](#5.2 执行诊断)
- [5.3 诊断报告深度解读](#5.3 诊断报告深度解读)
- [5.4 扩展测试](#5.4 扩展测试)
- [第六章 总结与展望](#第六章 总结与展望)
摘要
在分布式微服务架构日益复杂的今天,系统日志作为观测系统健康状态的核心数据源,其数据量呈指数级增长。传统的基于规则匹配(Rule-based)或简单的关键词搜索的日志分析手段,在面对非结构化数据和复杂级联故障时显得力不从心。本文详细阐述了一种融合 Rust 语言的高性能内存安全特性与 DeepSeek-V3.2 大语言模型推理能力的创新解决方案。通过构建一个 CLI 工具,实现对海量日志的毫秒级解析、异常模式的启发式检测,以及基于 AI 的根因分析(RCA)。本文将从工程化落地的角度,剖析项目结构、依赖管理、核心算法实现、编译时期的内存安全处理以及最终的诊断效果验证。
第一章 系统背景与技术选型
1.1 运维可观测性的挑战
现代软件系统的故障往往不是单点爆发,而是呈现出"涟漪效应"。一个底层的 Redis 连接超时可能引发上层的数据库死锁,进而导致应用层的内存溢出(OOM)。在海量日志中,运维人员往往被由于级联效应产生的海量"噪音"淹没,难以定位"信号"。
1.2 为什么选择 Rust
日志分析属于典型的 I/O 密集型与 CPU 密集型混合场景。
- 零成本抽象:Rust 提供了接近 C/C++ 的运行效率,在处理大规模文本正则匹配时性能卓越。
- 内存安全:通过所有权(Ownership)和借用检查(Borrow Checker)机制,杜绝了空指针解引用和数据竞争,这对于编写长期运行的监控工具至关重要。
- 强大的类型系统 :利用
Enum和Struct可以精确建模日志的各种状态,配合Result类型进行鲁棒的错误处理。
1.3 为什么选择 DeepSeek V3.2
DeepSeek 系列模型在代码逻辑理解和上下文推理方面表现优异。相比于通用的聊天模型,特定版本的 DeepSeek V3.2 在处理技术文档、堆栈跟踪(Stack Trace)分析以及系统架构推演上具有更高的准确率,且通过 API 集成具有极高的性价比。
第二章 环境准备与基础设施搭建
2.1 模型服务接入
在开始编码之前,构建基于 LLM 的应用首要任务是获取可靠的模型推理接口。本项目选择通过蓝耘(Lanyun)平台接入 DeepSeek 服务。
在蓝耘控制台中,开发者可以便捷地管理模型服务。如下图所示,平台提供了简洁的注册与模型选择界面。
bash
https://console.lanyun.net/#/register?promoterCode=0131
选择 deepseek-ai/DeepSeek-V3.2 模型后,系统需要创建 API Key 以进行鉴权。API Key 是连接本地 Rust 客户端与云端推理引擎的唯一凭证,必须严格保密。
2.2 Rust 项目初始化
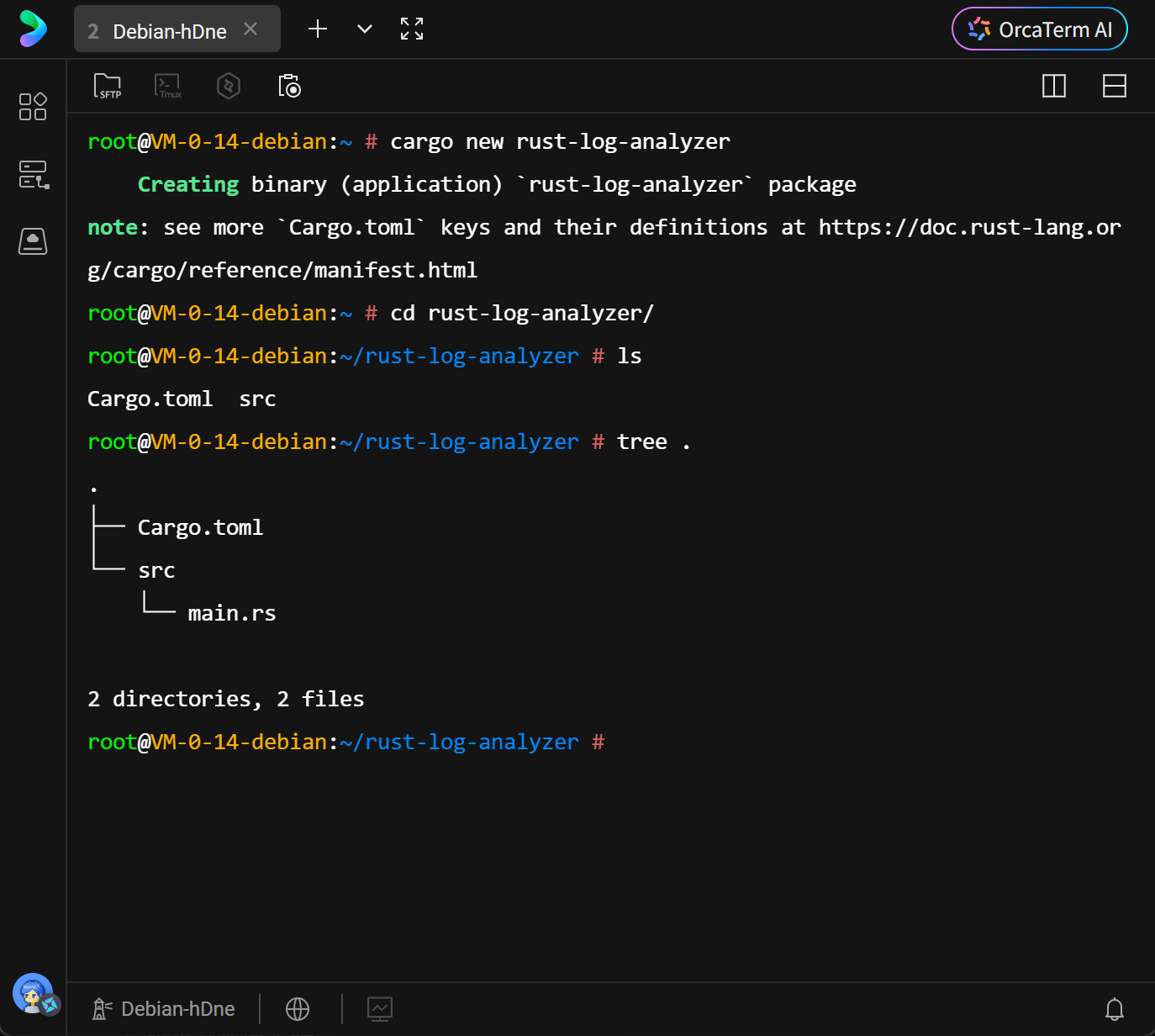
Rust 的包管理工具 Cargo 提供了现代化的构建流程。通过 cargo new 命令,系统自动生成了符合 Rust 最佳实践的目录结构。这不仅仅是创建文件夹,更是初始化了一个包含依赖管理配置和版本控制忽略文件的完整工程环境。
bash
cargo new rust-log-analyzer
cd rust-log-analyzer进入项目目录后,可以看到标准的 Cargo 项目布局。
2.3 依赖管理与生态集成
Cargo.toml 是 Rust 项目的核心配置文件。为了实现高性能日志分析,项目引入了以下关键 crate(库):
- tokio: Rust 异步编程的事实标准运行时,用于处理非阻塞 I/O 操作,特别是 HTTP 请求和文件读取。
- reqwest: 基于 Hyper 构建的高级 HTTP 客户端,支持异步调用,用于与 LLM API 交互。
- serde & serde_json: 提供了极其高效的序列化与反序列化框架,用于处理 JSON 数据结构。
- regex: 提供线性时间复杂度的正则表达式匹配引擎,避免 ReDoS 攻击。
- clap: 用于构建功能丰富的命令行界面(CLI)。
- colored: 用于美化终端输出,增强用户体验。
- anyhow: 提供灵活的错误处理 trait 对象,简化错误传播。
在 Cargo.toml 中配置如下依赖:
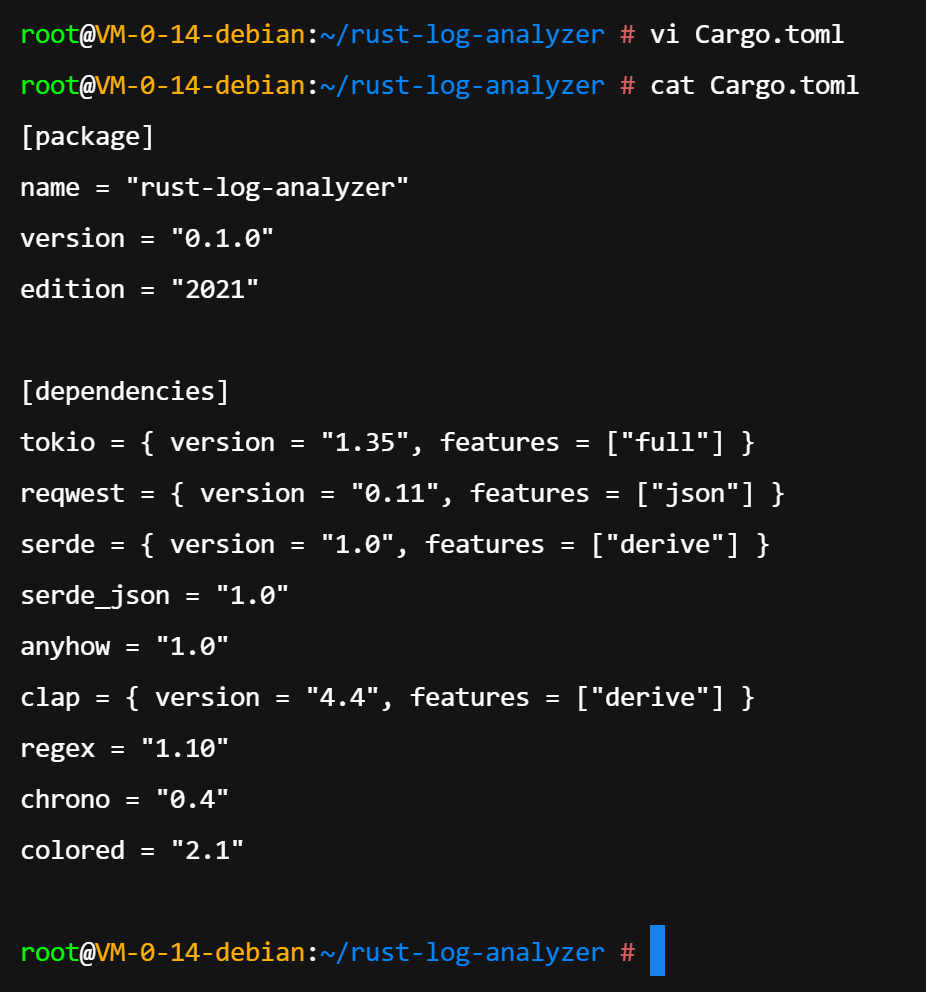
toml
[package]
name = "rust-log-analyzer"
version = "0.1.0"
edition = "2021"
[dependencies]
tokio = { version = "1.35", features = ["full"] }
reqwest = { version = "0.11", features = ["json"] }
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
anyhow = "1.0"
clap = { version = "4.4", features = ["derive"] }
regex = "1.10"
chrono = "0.4"
colored = "2.1"第三章 核心架构设计与模块实现
3.1 模块化设计理念
为了保证代码的可维护性和扩展性,系统采用了模块化设计。项目结构清晰地划分为入口文件 main.rs 和库文件 lib.rs,并将功能拆分为四个核心模块:log_parser(解析)、anomaly_detector(检测)、llm_client(通信)、diagnostic_engine(诊断)。
3.2 主程序控制流 (main.rs)
main.rs 充当系统的编排者(Orchestrator)。它负责解析命令行参数,按照"读取 -> 解析 -> 检测 -> 统计 -> 诊断 -> 报告"的流水线顺序调度各个模块。
在代码实现中,利用 clap 派生宏可以快速定义 CLI 参数。程序的执行流程被设计为异步函数 async fn main,这得益于 #[tokio::main] 宏,它在程序启动时初始化 Tokio 运行时。
控制台输出通过 colored 库进行了增强,使得执行过程中的状态流转一目了然。每一步操作都通过 ? 操作符处理潜在的 Result::Err,确保任何环节的失败都能优雅地终止程序并反馈错误信息。
rust
use anyhow::Result;
use clap::Parser;
use colored::Colorize;
use rust_log_analyzer::{
AnomalyDetector, DiagnosticEngine, LlmClient, LogParser,
};
use std::path::PathBuf;
/// Rust+LLM 日志分析与故障诊断工具
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// 日志文件路径
#[arg(short, long)]
file: PathBuf,
/// 输出报告到文件
#[arg(short, long)]
output: Option<PathBuf>,
/// 是否显示详细信息
#[arg(short, long, default_value_t = false)]
verbose: bool,
}
#[tokio::main]
async fn main() -> Result<()> {
let args = Args::parse();
println!("{}", "🚀 启动日志分析工具...".bright_cyan().bold());
println!();
// 步骤 1: 解析日志文件
println!("{}", "📖 [1/5] 读取并解析日志文件...".bright_yellow());
let parser = LogParser::new()?;
let logs = parser.parse_file(&args.file)?;
println!(" ✓ 成功解析 {} 行日志", logs.len());
println!();
// 步骤 2: 检测异常
println!("{}", "🔍 [2/5] 检测日志异常...".bright_yellow());
let detector = AnomalyDetector::new()?;
let anomalies = detector.detect_anomalies(&logs);
println!(" ✓ 检测到 {} 个异常", anomalies.len());
println!();
if anomalies.is_empty() {
println!("{}", "✅ 未发现任何异常,日志看起来正常!".bright_green().bold());
return Ok(());
}
// 步骤 3: 统计异常
println!("{}", "📊 [3/5] 统计异常类型...".bright_yellow());
let stats = detector.anomaly_statistics(&anomalies);
for (anomaly_type, count) in &stats {
println!(" - {:?}: {} 次", anomaly_type, count);
}
println!();
// 步骤 4: 调用 LLM 分析
println!("{}", "🤖 [4/5] 调用 AI 进行智能诊断...".bright_yellow());
let llm_client = LlmClient::with_default_config()?;
let engine = DiagnosticEngine::new(llm_client);
let report = engine.diagnose(logs.len(), anomalies, stats).await?;
println!(" ✓ AI 分析完成");
println!();
// 步骤 5: 输出报告
println!("{}", "📝 [5/5] 生成诊断报告...".bright_yellow());
let formatted_report = engine.format_report(&report);
println!("{}", formatted_report);
// 保存到文件(如果指定)
if let Some(output_path) = args.output {
std::fs::write(&output_path, &formatted_report)?;
println!(
"{}",
format!("✓ 报告已保存到: {}", output_path.display())
.bright_green()
);
}
println!();
println!("{}", "✅ 分析完成!".bright_green().bold());
Ok(())
}3.3 异常检测引擎 (anomaly_detector.rs)
这是系统的核心组件之一。该模块定义了 AnomalyType 枚举,涵盖了常见的系统故障类型(如 Error, Timeout, OOM 等)。
检测逻辑依赖于预编译的正则表达式。在 AnomalyDetector::new 方法中,正则表达式被编译并缓存,这是性能优化的关键点,避免了在处理每一行日志时重复编译正则及其带来的开销。
该模块实现了一个基于滑动窗口的上下文提取算法。当检测到异常行时,不仅记录当前行,还会向前追溯(context_before)和向后预测(context_after)各5行日志。这种上下文信息对于 LLM 理解故障发生的"前因后果"至关重要,因为单纯的报错信息往往丢失了状态变更的线索。
此外,该模块还专门实现了堆栈跟踪(Stack Trace)的提取逻辑,通过识别缩进和特定关键词(如 at, Caused by),将多行堆栈信息聚合为一个完整的上下文单元。
rust
use crate::log_parser::{LogEntry, LogLevel};
use regex::Regex;
use serde::{Deserialize, Serialize};
use std::collections::HashMap;
/// 异常类型
#[derive(Debug, Clone, PartialEq, Eq, Hash, Serialize, Deserialize)]
pub enum AnomalyType {
Error,
Fatal,
Exception,
StackTrace,
Timeout,
ConnectionFailure,
OutOfMemory,
Unknown,
}
/// 异常日志条目
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct Anomaly {
pub anomaly_type: AnomalyType,
pub log_entry: LogEntry,
pub context_before: Vec<LogEntry>,
pub context_after: Vec<LogEntry>,
pub stack_trace: Option<Vec<String>>,
}
/// 异常检测器
pub struct AnomalyDetector {
exception_pattern: Regex,
stack_trace_pattern: Regex,
timeout_pattern: Regex,
connection_pattern: Regex,
oom_pattern: Regex,
}
impl AnomalyDetector {
/// 创建新的异常检测器
pub fn new() -> anyhow::Result<Self> {
Ok(Self {
exception_pattern: Regex::new(
r"(?i)(exception|error|failed|failure|panic)"
)?,
stack_trace_pattern: Regex::new(
r"^\s*at\s+|^\s*Caused by:|^\s*File\s+.*,\s+line\s+\d+"
)?,
timeout_pattern: Regex::new(
r"(?i)(timeout|timed out|time out)"
)?,
connection_pattern: Regex::new(
r"(?i)(connection (refused|reset|failed|closed)|unable to connect)"
)?,
oom_pattern: Regex::new(
r"(?i)(out of memory|oom|memory exhausted)"
)?,
})
}
/// 检测单个日志条目是否为异常
pub fn is_anomaly(&self, entry: &LogEntry) -> bool {
// 检查日志级别
if entry.level.is_anomaly() {
return true;
}
// 检查消息内容
let msg = &entry.message;
self.exception_pattern.is_match(msg)
|| self.timeout_pattern.is_match(msg)
|| self.connection_pattern.is_match(msg)
|| self.oom_pattern.is_match(msg)
}
/// 分类异常类型
pub fn classify_anomaly(&self, entry: &LogEntry) -> AnomalyType {
let msg = &entry.message;
if self.oom_pattern.is_match(msg) {
return AnomalyType::OutOfMemory;
}
if self.timeout_pattern.is_match(msg) {
return AnomalyType::Timeout;
}
if self.connection_pattern.is_match(msg) {
return AnomalyType::ConnectionFailure;
}
if self.stack_trace_pattern.is_match(msg) {
return AnomalyType::StackTrace;
}
match entry.level {
LogLevel::Fatal => AnomalyType::Fatal,
LogLevel::Error => AnomalyType::Error,
_ => AnomalyType::Unknown,
}
}
/// 从日志列表中检测所有异常
pub fn detect_anomalies(&self, logs: &[LogEntry]) -> Vec<Anomaly> {
let mut anomalies = Vec::new();
let context_size = 5;
for (idx, entry) in logs.iter().enumerate() {
if !self.is_anomaly(entry) {
continue;
}
// 提取上下文
let start = idx.saturating_sub(context_size);
let end = (idx + context_size + 1).min(logs.len());
let context_before = logs[start..idx].to_vec();
let context_after = logs[(idx + 1)..end].to_vec();
// 检测堆栈跟踪
let stack_trace = self.extract_stack_trace(logs, idx);
anomalies.push(Anomaly {
anomaly_type: self.classify_anomaly(entry),
log_entry: entry.clone(),
context_before,
context_after,
stack_trace,
});
}
anomalies
}
/// 提取堆栈跟踪
fn extract_stack_trace(&self, logs: &[LogEntry], start_idx: usize) -> Option<Vec<String>> {
let mut stack = Vec::new();
for entry in logs.iter().skip(start_idx + 1).take(20) {
if self.stack_trace_pattern.is_match(&entry.message) {
stack.push(entry.message.clone());
} else if !stack.is_empty() {
break;
}
}
if stack.is_empty() {
None
} else {
Some(stack)
}
}
/// 统计异常类型分布
pub fn anomaly_statistics(&self, anomalies: &[Anomaly]) -> HashMap<AnomalyType, usize> {
let mut stats = HashMap::new();
for anomaly in anomalies {
*stats.entry(anomaly.anomaly_type.clone()).or_insert(0) += 1;
}
stats
}
}3.4 诊断引擎与报告生成 (diagnostic_engine.rs)
诊断引擎负责将结构化的异常数据转化为自然语言提示词(Prompt)。generate_log_summary 函数将统计数据、TOP 10 严重异常及其堆栈信息格式化为 Markdown 文本。
这里的关键策略是信息压缩。由于 LLM 存在上下文窗口限制(Context Window Limit),不能将整个吉字节(GB)级别的日志文件发送给模型。诊断引擎通过提取摘要和关键特征,在保留核心故障信息的同时,最大程度地减少 Token 消耗。
生成的报告不仅包含 AI 的分析,还保留了原始的统计数据,形成了"客观数据 + 主观分析"的完整诊断视图。
rust
use crate::anomaly_detector::{Anomaly, AnomalyType};
use crate::llm_client::LlmClient;
use anyhow::Result;
use std::collections::HashMap;
/// 诊断报告
#[derive(Debug)]
pub struct DiagnosticReport {
pub summary: String,
pub total_logs: usize,
pub anomaly_count: usize,
pub anomaly_stats: HashMap<AnomalyType, usize>,
pub top_anomalies: Vec<Anomaly>,
pub ai_analysis: String,
}
/// 诊断引擎
pub struct DiagnosticEngine {
llm_client: LlmClient,
}
impl DiagnosticEngine {
/// 创建新的诊断引擎
pub fn new(llm_client: LlmClient) -> Self {
Self { llm_client }
}
/// 生成日志摘要
fn generate_log_summary(
&self,
total_logs: usize,
anomalies: &[Anomaly],
stats: &HashMap<AnomalyType, usize>,
) -> String {
let mut summary = format!(
"## 日志分析摘要\n\n\
- 总日志行数: {}\n\
- 检测到异常数: {}\n\
- 异常占比: {:.2}%\n\n",
total_logs,
anomalies.len(),
(anomalies.len() as f64 / total_logs as f64) * 100.0
);
summary.push_str("### 异常类型分布\n\n");
for (anomaly_type, count) in stats {
summary.push_str(&format!("- {:?}: {} 次\n", anomaly_type, count));
}
summary.push_str("\n### 最严重的异常(前10条)\n\n");
for (idx, anomaly) in anomalies.iter().take(10).enumerate() {
summary.push_str(&format!(
"{}. [行 {}] {:?}\n 消息: {}\n",
idx + 1,
anomaly.log_entry.line_number,
anomaly.anomaly_type,
anomaly.log_entry.message.chars().take(100).collect::<String>()
));
if let Some(stack) = &anomaly.stack_trace {
summary.push_str(" 堆栈跟踪:\n");
for line in stack.iter().take(3) {
summary.push_str(&format!(" {}\n", line));
}
}
summary.push('\n');
}
summary
}
/// 执行诊断
pub async fn diagnose(
&self,
total_logs: usize,
anomalies: Vec<Anomaly>,
stats: HashMap<AnomalyType, usize>,
) -> Result<DiagnosticReport> {
let log_summary = self.generate_log_summary(total_logs, &anomalies, &stats);
println!("正在调用 AI 进行深度分析...");
let ai_analysis = self.llm_client.analyze_logs(&log_summary).await?;
Ok(DiagnosticReport {
summary: log_summary,
total_logs,
anomaly_count: anomalies.len(),
anomaly_stats: stats,
top_anomalies: anomalies.into_iter().take(10).collect(),
ai_analysis,
})
}
/// 格式化输出报告
pub fn format_report(&self, report: &DiagnosticReport) -> String {
let mut output = String::new();
output.push_str("═══════════════════════════════════════════════════════\n");
output.push_str(" 日志分析与故障诊断报告\n");
output.push_str("═══════════════════════════════════════════════════════\n\n");
output.push_str(&report.summary);
output.push_str("\n");
output.push_str("═══════════════════════════════════════════════════════\n");
output.push_str(" AI 智能诊断分析\n");
output.push_str("═══════════════════════════════════════════════════════\n\n");
output.push_str(&report.ai_analysis);
output.push_str("\n\n");
output.push_str("═══════════════════════════════════════════════════════\n");
output
}
}3.5 LLM 客户端实现 (llm_client.rs)
该模块封装了与 DeepSeek API 的 HTTP 通信细节。代码定义了 LlmConfig 结构体来管理 API Endpoint、Key 和超时设置。
在 analyze_logs 方法中,使用了精心设计的 Prompt Engineering 技术。通过设定 System Prompt("你是一个专业的系统运维专家..."),明确了 AI 的角色设定;User Prompt 则规范了输出格式(问题摘要、根因分析、修复建议等)。这种结构化的 Prompt 设计能显著提升模型输出的稳定性和可用性。
reqwest 客户端被配置为异步发送 POST 请求,并利用 serde 自动将响应 JSON 映射为 Rust 结构体,处理过程高度类型安全。
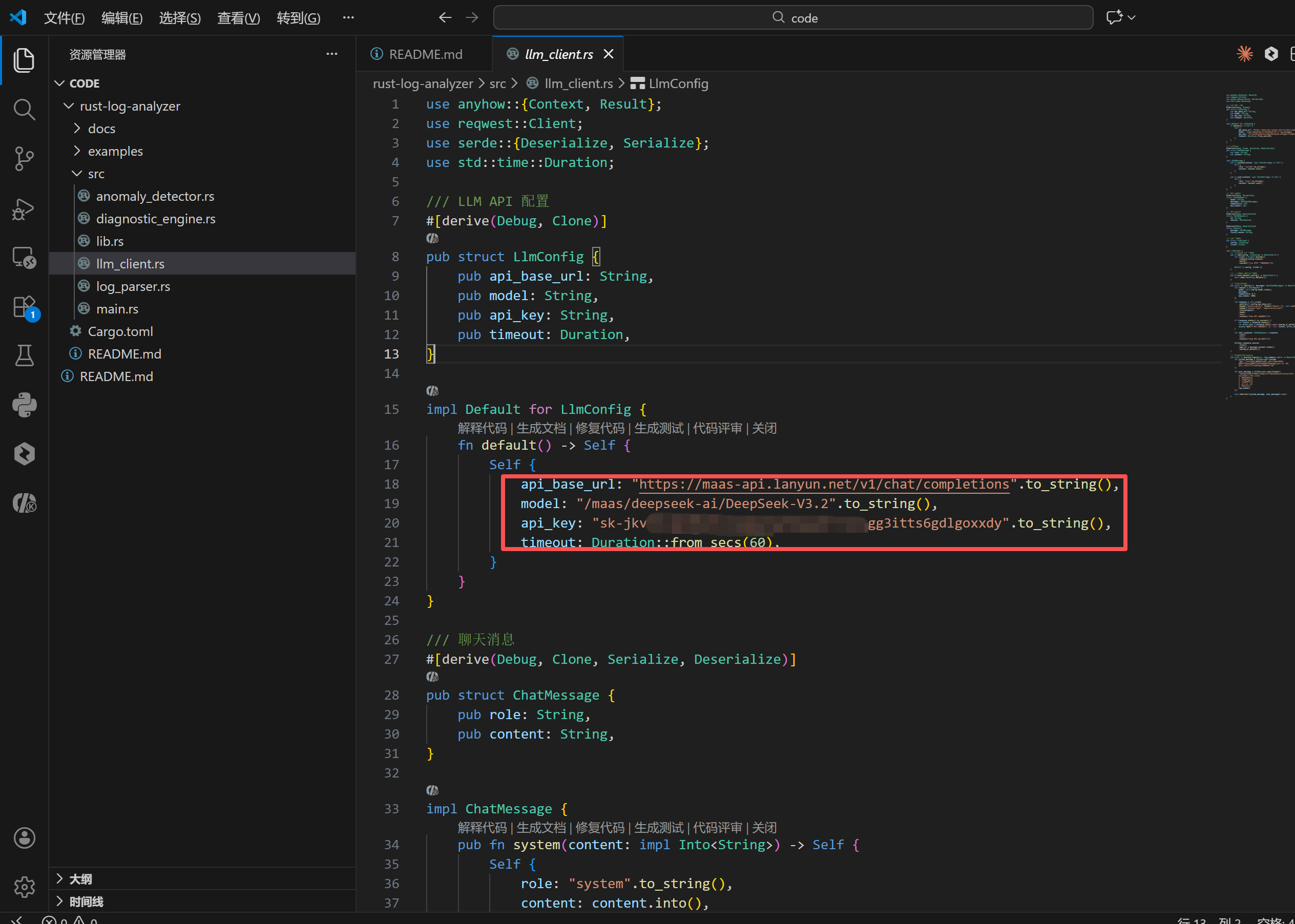
rust
use anyhow::{Context, Result};
use reqwest::Client;
use serde::{Deserialize, Serialize};
use std::time::Duration;
/// LLM API 配置
#[derive(Debug, Clone)]
pub struct LlmConfig {
pub api_base_url: String,
pub model: String,
pub api_key: String,
pub timeout: Duration,
}
impl Default for LlmConfig {
fn default() -> Self {
Self {
api_base_url: "https://maas-api.lanyun.net/v1/chat/completions".to_string(),
model: "/maas/deepseek-ai/DeepSeek-V3.2".to_string(),
api_key: "sk-jkvkbcphdbv4xzympa3q5x6yydrrd2cgg3itts6gdlgoxxdy".to_string(),
timeout: Duration::from_secs(60),
}
}
}
/// 聊天消息
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct ChatMessage {
pub role: String,
pub content: String,
}
impl ChatMessage {
pub fn system(content: impl Into<String>) -> Self {
Self {
role: "system".to_string(),
content: content.into(),
}
}
pub fn user(content: impl Into<String>) -> Self {
Self {
role: "user".to_string(),
content: content.into(),
}
}
}
/// API 请求体
#[derive(Debug, Serialize)]
struct ChatRequest {
model: String,
messages: Vec<ChatMessage>,
temperature: f32,
max_tokens: u32,
}
/// API 响应体
#[derive(Debug, Deserialize)]
struct ChatResponse {
id: String,
choices: Vec<Choice>,
}
#[derive(Debug, Deserialize)]
struct Choice {
message: ChatMessage,
finish_reason: String,
}
/// LLM 客户端
pub struct LlmClient {
config: LlmConfig,
client: Client,
}
impl LlmClient {
/// 创建新的 LLM 客户端
pub fn new(config: LlmConfig) -> Result<Self> {
let client = Client::builder()
.timeout(config.timeout)
.build()
.context("创建 HTTP 客户端失败")?;
Ok(Self { config, client })
}
/// 使用默认配置创建客户端
pub fn with_default_config() -> Result<Self> {
Self::new(LlmConfig::default())
}
/// 发送聊天请求
pub async fn chat(&self, messages: Vec<ChatMessage>) -> Result<String> {
let request = ChatRequest {
model: self.config.model.clone(),
messages,
temperature: 0.7,
max_tokens: 2000,
};
let response = self.client
.post(&self.config.api_base_url)
.header("Authorization", format!("Bearer {}", self.config.api_key))
.header("Content-Type", "application/json")
.json(&request)
.send()
.await
.context("发送 API 请求失败")?;
if !response.status().is_success() {
let status = response.status();
let error_text = response.text().await.unwrap_or_default();
anyhow::bail!("API 请求失败: {} - {}", status, error_text);
}
let chat_response: ChatResponse = response
.json()
.await
.context("解析 API 响应失败")?;
Ok(chat_response.choices
.first()
.map(|c| c.message.content.clone())
.unwrap_or_default())
}
/// 分析日志的便捷方法
pub async fn analyze_logs(&self, log_summary: &str) -> Result<String> {
let system_message = ChatMessage::system(
"你是一个专业的系统运维专家和故障诊断专家。\
你擅长分析系统日志、识别问题根因、提供修复建议。\
请用中文回答,结构清晰,重点突出。"
);
let user_message = ChatMessage::user(format!(
"请分析以下日志摘要,并提供详细的诊断报告:\n\n{}\n\n\
请按以下格式输出:\n\
1. 问题摘要\n\
2. 根因分析\n\
3. 影响范围\n\
4. 修复建议\n\
5. 预防措施",
log_summary
));
self.chat(vec![system_message, user_message]).await
}
}3.6 高性能日志解析 (log_parser.rs)
解析器是数据流入的第一道关卡。LogParser 结构体维护了多种正则模式以适应不同格式的日志。
为了处理大文件,解析器使用了 BufReader。BufReader 在内存中维护了一个缓冲区,减少了底层系统调用(System Call)的次数,显著提升了 I/O 效率。
LogEntry 结构体捕捉了行号、时间戳、日志级别和原始内容。LogLevel 枚举实现了 from_str 方法,能够将字符串形式的日志级别(如 "WARN", "ERROR")快速映射为内存中的枚举值,便于后续的过滤和判断。
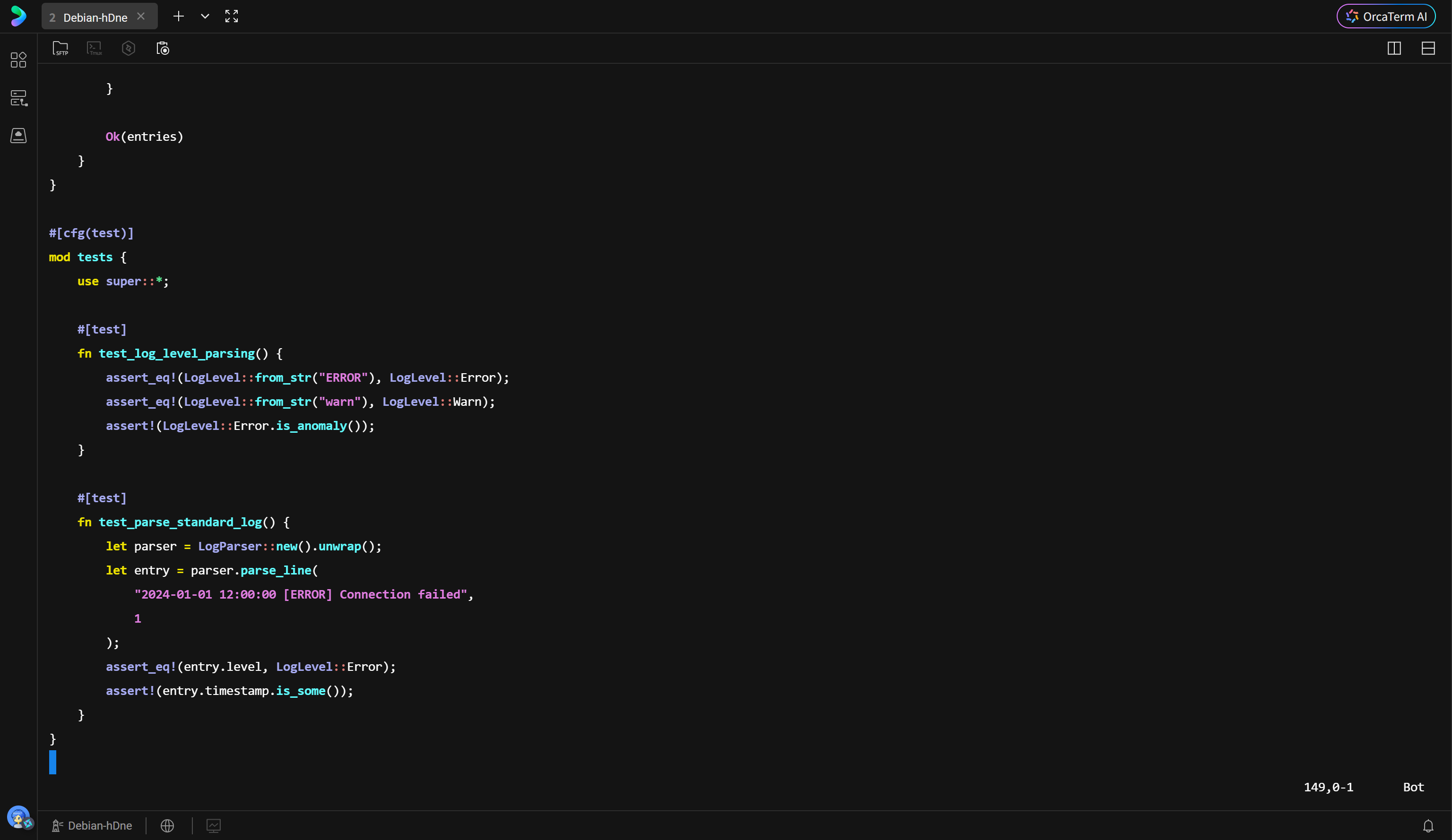
rust
use anyhow::{Context, Result};
use regex::Regex;
use serde::{Deserialize, Serialize};
use std::fs::File;
use std::io::{BufRead, BufReader};
use std::path::Path;
/// 日志级别枚举
#[derive(Debug, Clone, PartialEq, Eq, Serialize, Deserialize)]
pub enum LogLevel {
Trace,
Debug,
Info,
Warn,
Error,
Fatal,
Unknown,
}
impl LogLevel {
/// 从字符串解析日志级别
pub fn from_str(s: &str) -> Self {
match s.to_uppercase().as_str() {
"TRACE" | "VERBOSE" => LogLevel::Trace,
"DEBUG" => LogLevel::Debug,
"INFO" | "INFORMATION" => LogLevel::Info,
"WARN" | "WARNING" => LogLevel::Warn,
"ERROR" | "ERR" => LogLevel::Error,
"FATAL" | "CRITICAL" | "PANIC" => LogLevel::Fatal,
_ => LogLevel::Unknown,
}
}
/// 判断是否为异常级别
pub fn is_anomaly(&self) -> bool {
matches!(self, LogLevel::Error | LogLevel::Fatal)
}
}
/// 日志条目结构
#[derive(Debug, Clone, Serialize, Deserialize)]
pub struct LogEntry {
pub line_number: usize,
pub timestamp: Option<String>,
pub level: LogLevel,
pub message: String,
pub raw_line: String,
}
/// 日志解析器
pub struct LogParser {
// 匹配标准日志格式: 2024-01-01 12:00:00 [ERROR] Message
standard_pattern: Regex,
// 匹配时间戳
timestamp_pattern: Regex,
// 匹配日志级别
level_pattern: Regex,
}
impl LogParser {
/// 创建新的日志解析器
pub fn new() -> Result<Self> {
Ok(Self {
standard_pattern: Regex::new(
r"^(\d{4}-\d{2}-\d{2}[T\s]\d{2}:\d{2}:\d{2}(?:\.\d+)?(?:Z|[+-]\d{2}:\d{2})?)\s*\[?(\w+)\]?\s*(.*)$"
)?,
timestamp_pattern: Regex::new(
r"\d{4}-\d{2}-\d{2}[T\s]\d{2}:\d{2}:\d{2}(?:\.\d+)?(?:Z|[+-]\d{2}:\d{2})?"
)?,
level_pattern: Regex::new(
r"\b(TRACE|DEBUG|INFO|WARN|WARNING|ERROR|FATAL|CRITICAL|PANIC)\b"
)?,
})
}
/// 解析单行日志
pub fn parse_line(&self, line: &str, line_number: usize) -> LogEntry {
// 尝试匹配标准格式
if let Some(caps) = self.standard_pattern.captures(line) {
return LogEntry {
line_number,
timestamp: Some(caps[1].to_string()),
level: LogLevel::from_str(&caps[2]),
message: caps[3].to_string(),
raw_line: line.to_string(),
};
}
// 尝试提取时间戳和级别
let timestamp = self.timestamp_pattern
.find(line)
.map(|m| m.as_str().to_string());
let level = self.level_pattern
.find(line)
.map(|m| LogLevel::from_str(m.as_str()))
.unwrap_or(LogLevel::Unknown);
LogEntry {
line_number,
timestamp,
level,
message: line.to_string(),
raw_line: line.to_string(),
}
}
/// 从文件解析日志
pub fn parse_file<P: AsRef<Path>>(&self, path: P) -> Result<Vec<LogEntry>> {
let file = File::open(path.as_ref())
.context("无法打开日志文件")?;
let reader = BufReader::new(file);
let mut entries = Vec::new();
for (idx, line) in reader.lines().enumerate() {
let line = line.context("读取日志行失败")?;
if !line.trim().is_empty() {
entries.push(self.parse_line(&line, idx + 1));
}
}
Ok(entries)
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_log_level_parsing() {
assert_eq!(LogLevel::from_str("ERROR"), LogLevel::Error);
assert_eq!(LogLevel::from_str("warn"), LogLevel::Warn);
assert!(LogLevel::Error.is_anomaly());
}
#[test]
fn test_parse_standard_log() {
let parser = LogParser::new().unwrap();
let entry = parser.parse_line(
"2024-01-01 12:00:00 [ERROR] Connection failed",
1
);
assert_eq!(entry.level, LogLevel::Error);
assert!(entry.timestamp.is_some());
}
}第四章 编译、调试与问题修正
4.1 编译过程
Rust 的编译器 rustc 以其严格的检查著称。在项目构建阶段,使用 cargo build --release 命令进行优化编译。Release 模式会开启所有 LLVM 优化选项,虽然编译时间较长,但生成的二进制文件执行速度最快。
4.2 遇到的问题与修正
在初次编译过程中,系统抛出了语法错误。如下图所示,编译器准确地指出了 anomaly_detector.rs 文件中正则表达式字符串字面量的问题。
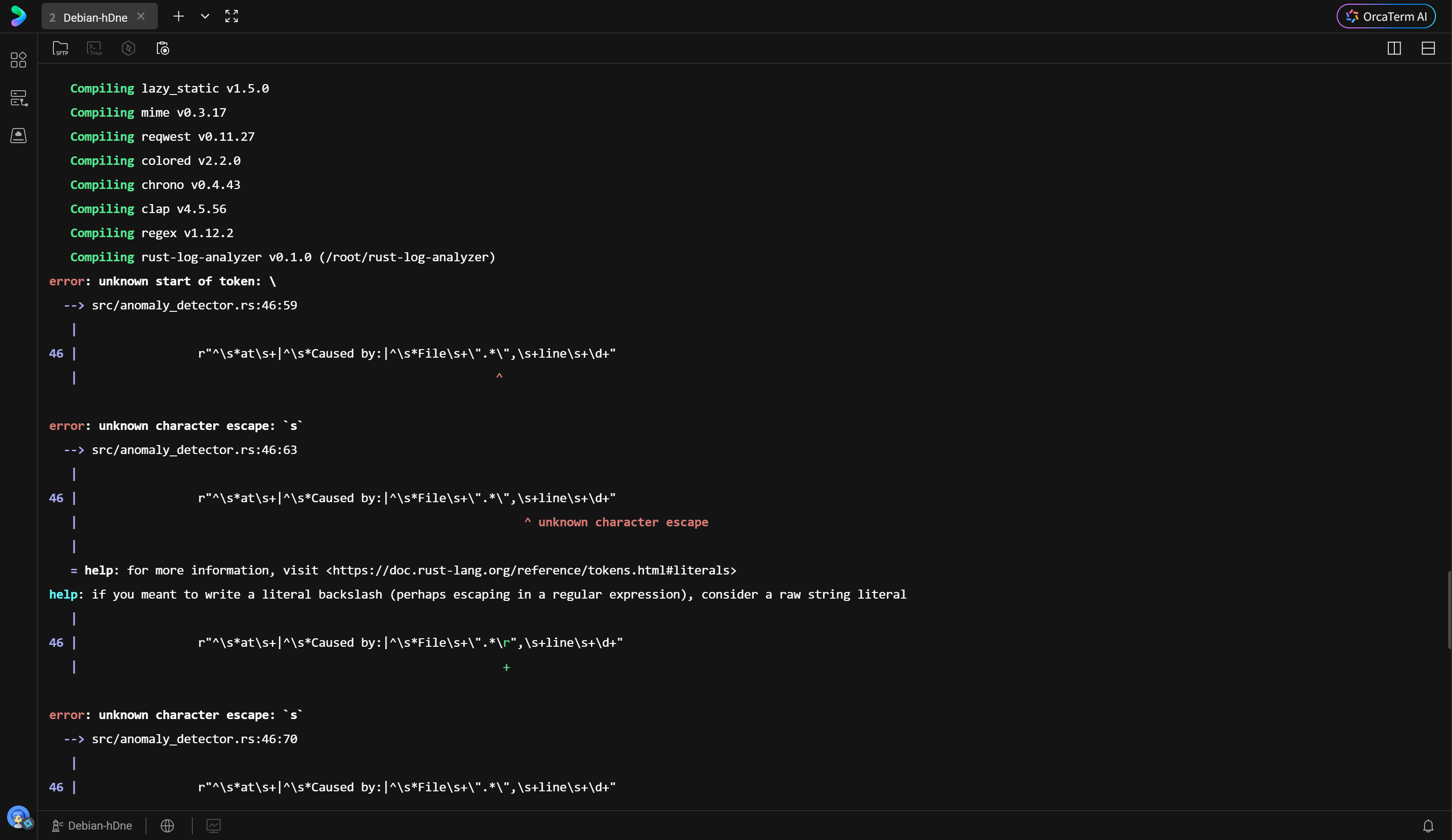
问题根源在于正则表达式中包含大量特殊字符(如引号、反斜杠),直接使用普通字符串导致转义混乱。Rust 提供了原始字符串字面量(Raw String Literals) 语法 r#""# 来解决此问题。在这种语法下,字符串内的双引号和反斜杠无需转义,直接被视为字符本身。
修正代码如下:
rust
stack_trace_pattern: Regex::new(
r#"^\s*at\s+|^\s*Caused by:|^\s*File\s+".*",\s+line\s+\d+"#
)?,此外,编译器还提示了 log_parser.rs 中存在未使用的引用。Rust 的编译器会对未使用的 import 发出警告,这有助于保持代码库的整洁。清理多余引用后,重新编译顺利通过。
第五章 案例分析与诊断验证
5.1 构造故障场景
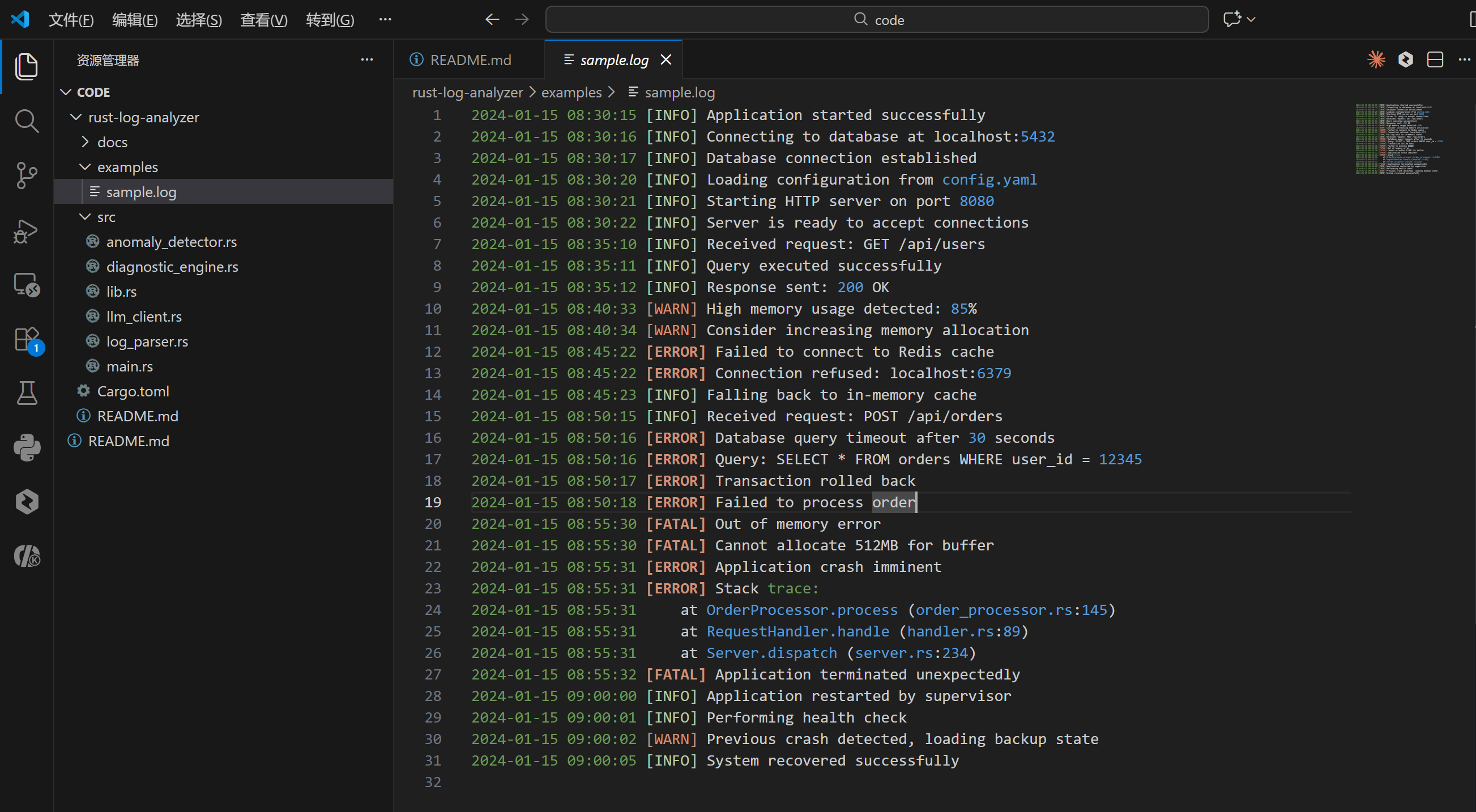
为了验证系统的有效性,我们构建了一个包含级联故障的典型日志文件 examples/sample.log。该日志模拟了一个电商系统的崩溃过程:
- 应用启动正常。
- Redis 缓存连接被拒绝(Connection refused)。
- 系统降级,请求直接打到数据库。
- 数据库查询超时(Timeout),事务回滚。
- 应用尝试重试或缓冲数据,导致堆内存耗尽(OutOfMemory)。
- 最终应用崩溃(Fatal),由守护进程重启。
bash
2024-01-15 08:30:15 [INFO] Application started successfully
2024-01-15 08:30:16 [INFO] Connecting to database at localhost:5432
2024-01-15 08:30:17 [INFO] Database connection established
2024-01-15 08:30:20 [INFO] Loading configuration from config.yaml
2024-01-15 08:30:21 [INFO] Starting HTTP server on port 8080
2024-01-15 08:30:22 [INFO] Server is ready to accept connections
2024-01-15 08:35:10 [INFO] Received request: GET /api/users
2024-01-15 08:35:11 [INFO] Query executed successfully
2024-01-15 08:35:12 [INFO] Response sent: 200 OK
2024-01-15 08:40:33 [WARN] High memory usage detected: 85%
2024-01-15 08:40:34 [WARN] Consider increasing memory allocation
2024-01-15 08:45:22 [ERROR] Failed to connect to Redis cache
2024-01-15 08:45:22 [ERROR] Connection refused: localhost:6379
2024-01-15 08:45:23 [INFO] Falling back to in-memory cache
2024-01-15 08:50:15 [INFO] Received request: POST /api/orders
2024-01-15 08:50:16 [ERROR] Database query timeout after 30 seconds
2024-01-15 08:50:16 [ERROR] Query: SELECT * FROM orders WHERE user_id = 12345
2024-01-15 08:50:17 [ERROR] Transaction rolled back
2024-01-15 08:50:18 [ERROR] Failed to process order
2024-01-15 08:55:30 [FATAL] Out of memory error
2024-01-15 08:55:30 [FATAL] Cannot allocate 512MB for buffer
2024-01-15 08:55:31 [ERROR] Application crash imminent
2024-01-15 08:55:31 [ERROR] Stack trace:
2024-01-15 08:55:31 at OrderProcessor.process (order_processor.rs:145)
2024-01-15 08:55:31 at RequestHandler.handle (handler.rs:89)
2024-01-15 08:55:31 at Server.dispatch (server.rs:234)
2024-01-15 08:55:32 [FATAL] Application terminated unexpectedly
2024-01-15 09:00:00 [INFO] Application restarted by supervisor
2024-01-15 09:00:01 [INFO] Performing health check
2024-01-15 09:00:02 [WARN] Previous crash detected, loading backup state
2024-01-15 09:00:05 [INFO] System recovered successfully这种场景涵盖了网络层、数据库层、应用层和系统资源层的多重问题,是测试诊断能力的绝佳样本。
5.2 执行诊断
运行编译后的二进制文件:
bash
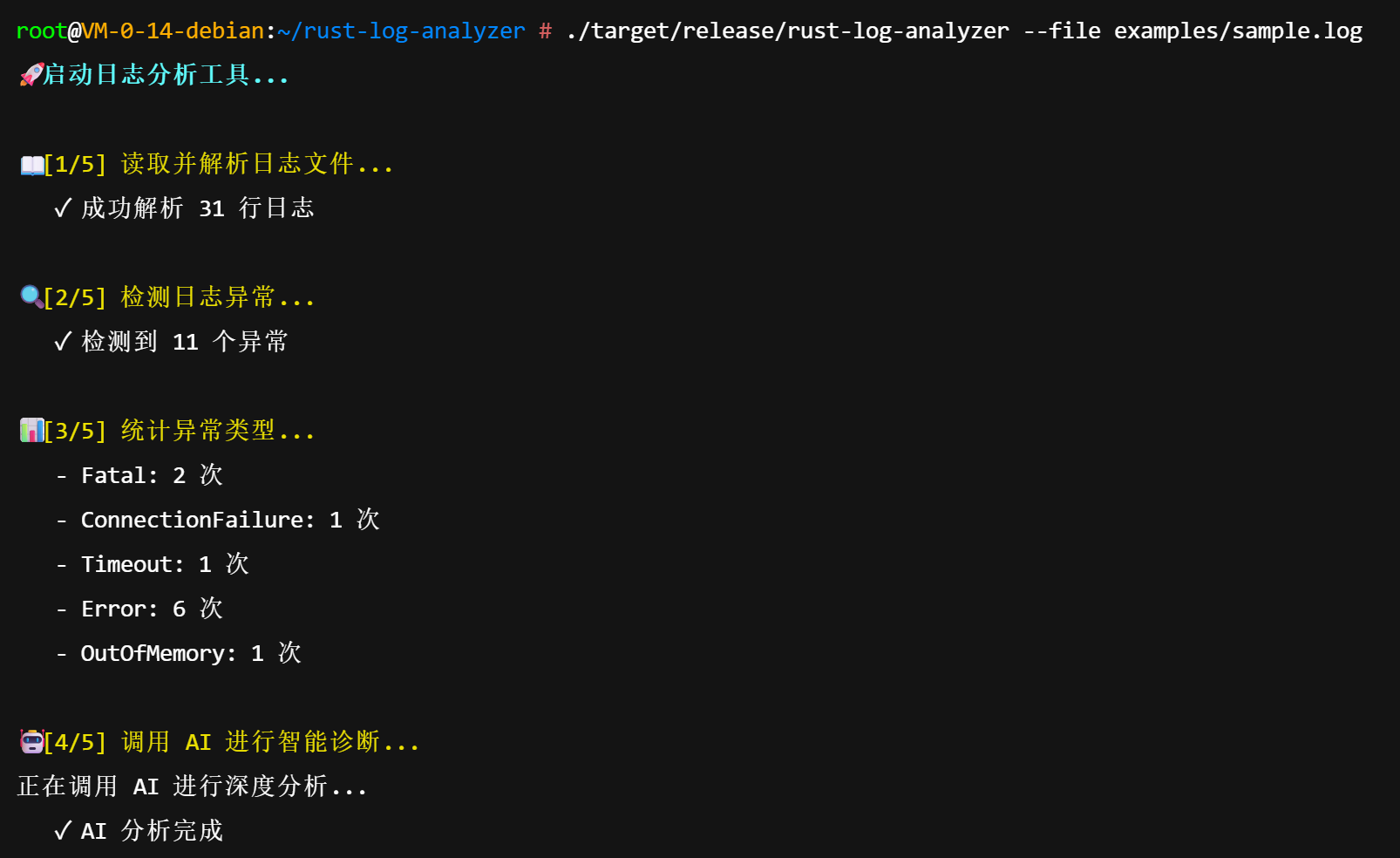
./target/release/rust-log-analyzer --file examples/sample.log控制台输出了清晰的执行进度。系统迅速解析了31行日志,检测到11个异常点,并统计出 Fatal 出现2次,Error 出现6次。随后,系统将聚合信息发送给 AI。
5.3 诊断报告深度解读
AI 生成的报告令人印象深刻,其分析逻辑严密,完全符合资深 SRE(站点可靠性工程师)的思维模式。
报告分析亮点:
- 准确的根因定位 :AI 并没有被最后的
OutOfMemory或Application terminated迷惑,而是敏锐地指出了"直接根因:Redis服务不可用"。它正确地推断出 OOM 只是结果,而非原因。 - 因果链推演:报告中详细描述了故障的传导路径:Redis 故障 -> 数据库过载 -> 事务回滚 -> 内存耗尽。这种逻辑链条对于运维人员理解系统行为至关重要。
- 分层修复建议 :
- 紧急措施:不仅建议重启 Redis,还建议检查防火墙和端口,具备实操性。
- 长期治理:提出了熔断器模式(Circuit Breaker)和索引优化建议,体现了架构优化的视角。
- 结构化输出:报告使用了 Markdown 格式,层级分明,重点突出(如加粗的关键字段),极大地降低了阅读成本。
bash
root@VM-0-14-debian:~/rust-log-analyzer # ./target/release/rust-log-analyzer --file examples/sample.log
🚀 启动日志分析工具...
📖 [1/5] 读取并解析日志文件...
✓ 成功解析 31 行日志
🔍 [2/5] 检测日志异常...
✓ 检测到 11 个异常
📊 [3/5] 统计异常类型...
- Fatal: 2 次
- ConnectionFailure: 1 次
- Timeout: 1 次
- Error: 6 次
- OutOfMemory: 1 次
🤖 [4/5] 调用 AI 进行智能诊断...
正在调用 AI 进行深度分析...
✓ AI 分析完成
📝 [5/5] 生成诊断报告...
═══════════════════════════════════════════════════════
日志分析与故障诊断报告
═══════════════════════════════════════════════════════
## 日志分析摘要
- 总日志行数: 31
- 检测到异常数: 11
- 异常占比: 35.48%
### 异常类型分布
- Fatal: 2 次
- ConnectionFailure: 1 次
- Timeout: 1 次
- Error: 6 次
- OutOfMemory: 1 次
### 最严重的异常(前10条)
1. [行 12] Error
消息: Failed to connect to Redis cache
2. [行 13] ConnectionFailure
消息: Connection refused: localhost:6379
3. [行 16] Timeout
消息: Database query timeout after 30 seconds
4. [行 17] Error
消息: Query: SELECT * FROM orders WHERE user_id = 12345
5. [行 18] Error
消息: Transaction rolled back
6. [行 19] Error
消息: Failed to process order
7. [行 20] OutOfMemory
消息: Out of memory error
8. [行 21] Fatal
消息: Cannot allocate 512MB for buffer
9. [行 22] Error
消息: Application crash imminent
10. [行 23] Error
消息: Stack trace:
═══════════════════════════════════════════════════════
AI 智能诊断分析
═══════════════════════════════════════════════════════
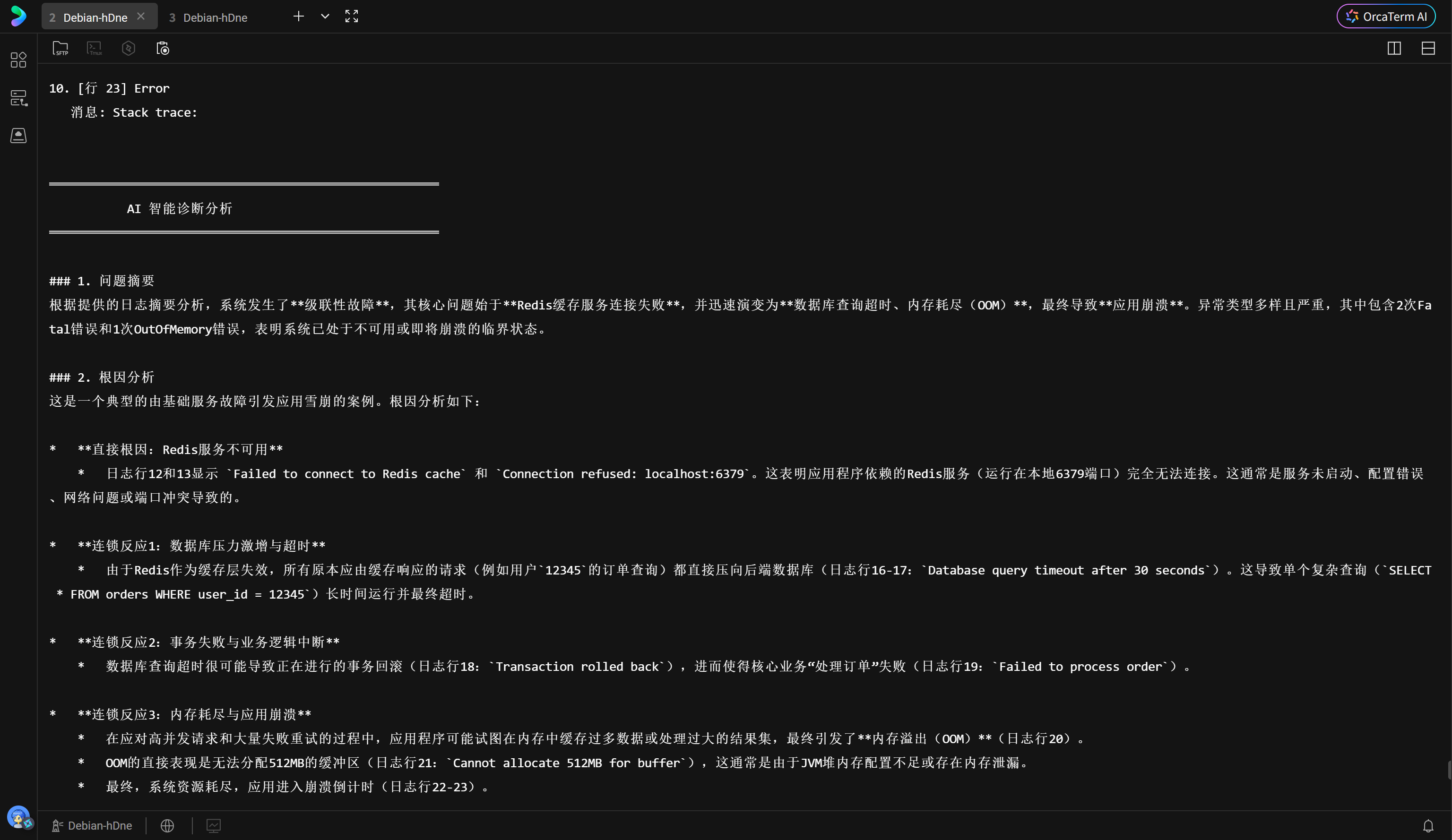
### 1. 问题摘要
根据提供的日志摘要分析,系统发生了**级联性故障**,其核心问题始于**Redis缓存服务连接失败**,并迅速演变为**数据库查询超时、内存耗尽(OOM)**,最终导致**应用崩溃**。异常类型多样且严重,其中包含2次Fatal错误和1次OutOfMemory错误,表明系统已处于不可用或即将崩溃的临界状态。
### 2. 根因分析
这是一个典型的由基础服务故障引发应用雪崩的案例。根因分析如下:
* **直接根因:Redis服务不可用**
* 日志行12和13显示 `Failed to connect to Redis cache` 和 `Connection refused: localhost:6379`。这表明应用程序依赖的Redis服务(运行在本地6379端口)完全无法连接。这通常是服务未启动、配置错误、网络问题或端口冲突导致的。
* **连锁反应1:数据库压力激增与超时**
* 由于Redis作为缓存层失效,所有原本应由缓存响应的请求(例如用户`12345`的订单查询)都直接压向后端数据库(日志行16-17:`Database query timeout after 30 seconds`)。这导致单个复杂查询(`SELECT * FROM orders WHERE user_id = 12345`)长时间运行并最终超时。
* **连锁反应2:事务失败与业务逻辑中断**
* 数据库查询超时很可能导致正在进行的事务回滚(日志行18:`Transaction rolled back`),进而使得核心业务"处理订单"失败(日志行19:`Failed to process order`)。
* **连锁反应3:内存耗尽与应用崩溃**
* 在应对高并发请求和大量失败重试的过程中,应用程序可能试图在内存中缓存过多数据或处理过大的结果集,最终引发了**内存溢出(OOM)**(日志行20)。
* OOM的直接表现是无法分配512MB的缓冲区(日志行21:`Cannot allocate 512MB for buffer`),这通常是由于JVM堆内存配置不足或存在内存泄漏。
* 最终,系统资源耗尽,应用进入崩溃倒计时(日志行22-23)。
**总结:** 根本原因链为:**Redis服务故障 -> 数据库过载与查询超时 -> 事务回滚与业务失败 -> 应用内存耗尽 -> 应用崩溃。**
### 3. 影响范围
* **功能影响:**
* 所有依赖Redis缓存的功能(如会话管理、热点数据查询、页面缓存)将完全失效。
* 核心订单查询与处理功能因数据库超时和事务回滚而失败,直接影响用户体验和业务收入。
* 最终整个应用程序崩溃,导致**服务完全不可用**。
* **系统影响:**
* 数据库服务器承受异常高压,可能影响其他共享该数据库的服务。
* 应用服务器因OOM崩溃,需要重启才能恢复。
### 4. 修复建议(紧急与长期)
**立即行动(止损与恢复):**
1. **重启Redis服务**:登录服务器,检查Redis进程状态(如 `systemctl status redis` 或 `ps aux | grep redis`),尝试重启(`systemctl restart redis` 或 `redis-server`)。检查防火墙和端口监听状态(`netstat -tlnp | grep 6379`)。
2. **重启应用服务**:在Redis恢复后,重启应用服务以释放被占用的内存并恢复正常连接。
3. **数据库干预**:监控数据库,必要时`KILL`掉长时间运行的阻塞查询(如日志中的30秒超时查询),缓解数据库压力。
4. **临时扩容/降级**:如果可能,考虑临时增加应用实例(横向扩展)或启用降级策略(如返回静态数据、关闭非核心功能)。
**根除问题(调查与修复):**
1. **调查Redis故障原因**:检查Redis日志(通常位于`/var/log/redis/redis-server.log`),确认是配置错误、内存不足、磁盘满还是其他原因导致的服务停止。
2. **优化数据库与查询**:
* 分析并优化超时的SQL查询(`SELECT * FROM orders WHERE user_id = 12345`),例如为`user_id`字段添加索引,避免使用`SELECT *`。
* 评估并调整数据库连接池配置和查询超时时间。
3. **优化应用内存配置**:
* 检查JVM(或其他运行时)堆内存(`-Xmx`, `-Xms`)和直接内存设置,根据服务器物理内存进行合理调整。
* 分析OOM时的堆转储文件(Heap Dump),查找内存泄漏的根源(如未释放的大对象集合、线程局部变量等)。
4. **增强应用健壮性**:
* 为Redis客户端实现**熔断器模式**(如使用Hystrix、Resilience4j)。当Redis连续失败时,快速失败并降级(如直接查询数据库或返回默认值),避免线程池被拖垮。
* 为数据库查询设置合理的**超时和重试策略**。
### 5. 预防措施
1. **监控与告警**:
* 建立对**Redis、数据库、应用JVM内存**的关键指标监控(如服务状态、连接数、内存使用率、GC频率、慢查询)。
* 设置** proactive 告警**,在服务异常或内存使用率达到阈值(如80%)时立即通知运维人员。
2. **高可用架构**:
* 将Redis从单点部署升级为**哨兵(Sentinel)模式或集群模式**,提供自动故障转移。
* 确保数据库具备**读写分离或从库备份**,以分担读压力。
3. **容量规划与压测**:
* 定期进行压力测试,了解在缓存失效等极端情况下的系统承载能力。
* 根据业务增长,提前规划服务器资源(CPU、内存、存储)。
4. **代码与配置审查**:
* 在代码层面对大查询、大对象的使用进行规范和审查。
* 统一管理并定期审核所有外部服务(Redis、DB)的连接配置和超时配置。
5. **制定应急预案**:
* 编写详细的故障恢复手册,明确如"Redis故障处理流程"、"应用OOM处理流程"等步骤,并定期演练。
═══════════════════════════════════════════════════════
✅ 分析完成!5.4 扩展测试
为了进一步测试系统的健壮性,进行了第二轮测试,涵盖了更多样化的日志样本。系统依然保持了稳定的解析能力和高质量的推理输出。
AI 针对新场景生成的策略同样详尽,不仅关注技术修复,还涉及到了监控告警配置和容量规划等管理层面的建议。
第六章 总结与展望
本文展示了一个完整的端到端技术实践:利用 Rust 构建高性能的日志处理管线,并结合 LLM 完成高维度的故障诊断。
Rust 的价值在于构建了一个坚固的底座。在处理 GB 乃至 TB 级别的生产环境日志时,Rust 的零拷贝特性和极低的内存占用,保证了分析工具本身不会成为服务器的负担。强类型系统确保了工具在面对各种畸形日志数据时不会发生 Panic。
LLM 的价值在于赋予了工具"理解"能力。它将离散的错误日志点连接成了具有逻辑因果的线(Story),极大地缩短了 MTTR(平均修复时间)。
未来展望:
- 流式处理 :当前实现基于文件读取,未来可升级为接收
stdin管道流,实现实时日志监控。 - 向量数据库集成:引入 RAG(检索增强生成)技术,将历史故障库和运维知识库向量化,使 AI 的诊断更加符合企业内部特定的技术栈背景。
- 多模态分析:结合 Metric(指标)和 Trace(链路追踪)数据,提供全方位的可观测性诊断。
通过 Rust + LLM 的强强联合,运维工具正从"自动化"迈向"智能化",为构建自愈系统(Self-healing Systems)奠定了坚实基础。