一、前言
随着大模型技术从单一文本交互迈向多模态智能时代,视觉语言模型(VLM)已成为连接图像感知与语言理解的关键载体。传统大参数VLM凭借强大的综合能力,在图文问答、视觉推理等领域展现出惊人效果,但其对算力与存储的极高要求,也让多模态 AI 长期局限于云端服务与高端硬件环境,难以走向更广泛的落地场景。
超紧凑视觉语言模型的出现,正是大模型技术走向普惠化、轻量化与端侧化的重要突破。它以轻量化架构、精简参数和高效跨模态融合为核心,在保留大模型核心能力的同时,大幅降低部署门槛,让普通设备也能实现本地、实时、低延迟的图文交互。以Qwen2‑VL‑2B为代表的轻量级 VLM,依托大模型的预训练知识与对齐能力,将复杂的视觉理解与语言生成能力浓缩为可在个人电脑上运行的紧凑模型,为多模态AI打开了全新的应用空间。今天我们就由浅入深完整讲解超紧凑 VLM 的技术逻辑,并结合简单的示例,直观展示轻量化多模态大模型的工作方式,理解大模型如何从云端走向终端,为智能设备、离线应用、隐私计算与低成本 AI 部署提供可行的路径参考。

二、核心概念
首先要了解轻量级VLM的本质,我们可以把视觉语言模型(VLM)理解为能看懂图片的聊天机器人,它既具备视觉感知能力,能看懂图片内容,又具备自然语言理解与生成能力,能用文字回答关于图片的问题。
而超紧凑、轻量级 VLM(如 Qwen2-VL-2B) 则是这类模型的迷你版:
- 传统的大规模视觉语言模型(VLM)通常参数规模达数十亿甚至数百亿,依赖高性能计算集群才能运行,模型体积动辄数百GB,推理延迟在秒级,主要适用于对效果要求极致、资源充足的云端场景。
- 相比之下,轻量级 VLM(如 Qwen2-VL-2B)将参数规模压缩至仅20亿,不到前者的3%。它可在普通电脑的CPU或单张入门级GPU甚至边缘设备(如手机)上流畅运行,模型体积约 4GB,经量化后甚至可降至 1GB 以内,在损失少量精度的前提下,实现本地轻量化图文交互,推理速度提升至百毫秒级别,真正实现本地化、低延迟、低成本部署。
两者的根本差异在于定位:大模型追求性能上限,而轻量级VLM聚焦实用性、可及性与工程落地效率,让多模态能力可以走进终端设备,这才是超紧凑VLM的核心价值。
关键特征对比:
| 维度 | 传统大 VLM | 轻量级 VLM(Qwen2-VL-2B) |
|---|---|---|
| 参数规模 | 70B+ | 2B(仅为前者的 3%) |
| 硬件要求 | 8 卡 A100 GPU | 普通电脑 CPU / 单张入门 GPU |
| 模型体积 | 数百 GB | 约 4GB(量化后可压缩至 1GB) |
| 推理延迟 | 秒级 | 百毫秒级(本地) |
| 核心优势 | 效果极致 | 轻量化、低成本、易部署 |
三、基础知识
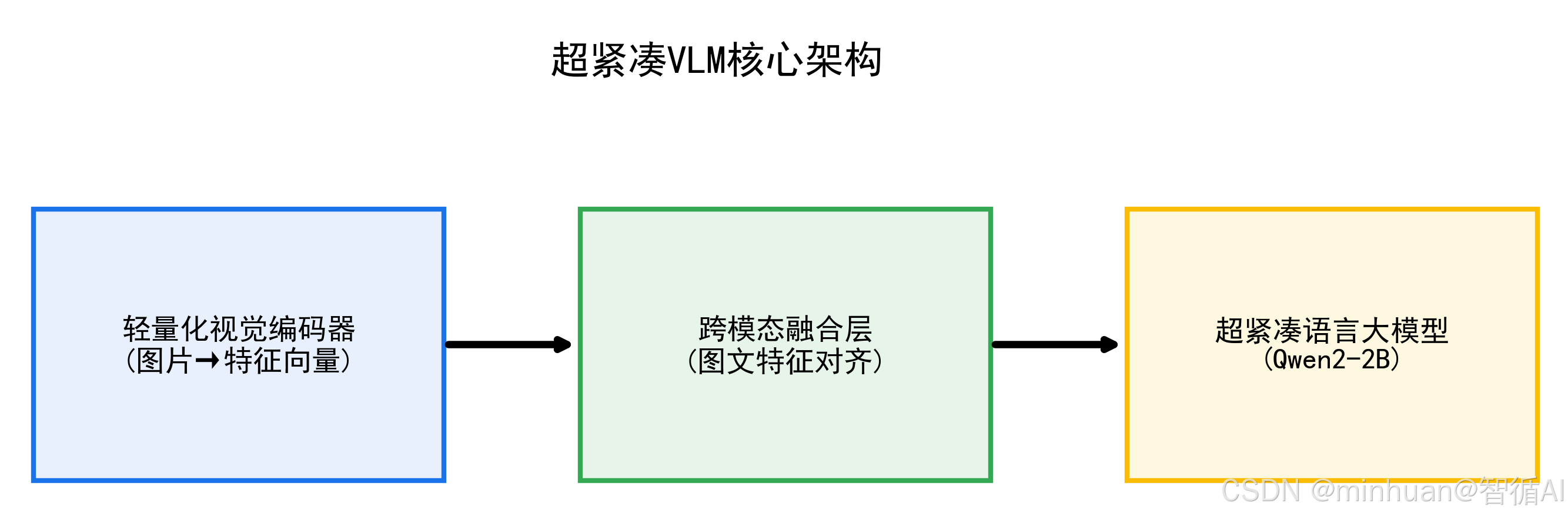
1. VLM 的三大核心组件
轻量级VLM本质是"轻量化视觉模块 + 轻量化语言模块 + 高效跨模态融合层"的组合体,每个组件都做了针对性的精简优化,以Qwen2-VL-2B为例:
- **视觉编码器:**Qwen2-VL-2B 采用精简版 ViT(视觉 Transformer),裁剪网络层数、压缩特征维度,仅保留核心的图像特征提取能力,避免冗余计算;
- **语言解码器:**基于 Qwen2-2B 轻量级大模型,减少Transformer层数(从 32 层精简至 16 层),优化注意力机制,保证语言理解、生成能力的同时降低计算量;
- **跨模态融合层:**放弃传统复杂的交叉注意力机制,改用"视觉特征投影 + 文本特征拼接"的轻量化方案,将图像特征映射到语言模型的语义空间,实现图文信息对齐。
2. 轻量级VLM的核心优化技术
轻量级 VLM 能做到"小而能用",核心依赖以下4类技术:
- **参数精简:**直接减少模型层数、隐藏层维度,比如将语言模型隐藏层从 4096 维压缩至 2048 维;
- **模型量化:**将模型参数从 32 位浮点数(FP32)转为 16 位(FP16)或 8 位(INT8),体积缩小 2-4 倍,推理速度提升 1-3 倍;
- **高效注意力:**用"滑动窗口注意力"、"分组注意力"替代全局注意力,减少计算复杂度;
- **知识蒸馏:**让小模型(Qwen2-VL-2B)学习大模型(Qwen2-VL-72B)的推理逻辑,在小参数规模下逼近大模型效果。
3. 轻量级VLM的核心原理
轻量级VLM的核心原理可以概括为用最小的代价实现图像与语言的有效对齐。其本质不是追求极致性能,而是在资源受限的设备上,让多模态能力真正可用、可部署。
具体来说,它通过以下三个关键环节实现这一目标:
3.1 高效视觉编码
- 使用参数量小、推理快的轻量级视觉主干网络,如MobileViT、EfficientNet 或Qwen-VL中的简化ViT,将输入图像压缩成一个低维但信息丰富的特征向量,例如从512维进一步压缩到128维。
- 这一步大幅降低计算开销,同时保留关键语义。
3.2 简洁的跨模态融合
- 避免复杂的多层交叉注意力机制,转而采用轻量融合策略,比如将视觉特征线性投影后拼接到文本 token 序列中,或通过少量可学习的"桥接 token"实现图文对齐。
- 这样既维持了基本的多模态理解能力,又显著减少模型复杂度。
3.3 小型化语言解码器
- 搭配超紧凑的语言模型,如TinyLlama、Phi-2 或 Qwen2-0.5B/1.5B系列,通常配合4-bit或8-bit量化技术,使整个系统能在普通CPU或低端GPU上实时运行。
- 虽然生成能力略逊于百亿级大模型,但在常见任务(如图像问答、内容描述、简单推理)上仍具备实用价值。
整体而言,轻量级VLM的设计哲学是:不做全能选手,而是做够用就好的端侧智能助手。它牺牲部分精度,换取极低的部署门槛和高响应速度,从而在手机、边缘设备、嵌入式系统等场景中释放多模态AI的真实价值。
4. 轻量级VLM对大模型生态的意义
轻量级 VLM(如 Qwen2-VL-2B)是大模型从云端专属越来越普及可用的核心桥梁,其价值体现在 5 个方面:
- **1. 降低使用门槛:**无需租赁昂贵的 GPU 服务器,普通开发者的个人电脑就能体验多模态 AI;
- **2. 降低落地成本:**企业无需为 VLM 部署投入百万级硬件成本,轻量级模型可直接集成到 APP、小程序中;
- **3. 提升隐私性:**用户的图片、问题无需上传云端,本地推理避免数据泄露风险;
- **4. 拓展应用场景:**可部署在智能摄像头、手机、智能家居等端侧设备,实现离线识图问答、本地相册AI分析、车载视觉交互等场景;
- **5. 技术普惠:**让中小团队、个人开发者能参与多模态AI的研发与创新,推动生态多元化。
四、执行流程
用户输入的图片和文字经过编码、跨模态融合后,由轻量级解码器快速生成自然语言答案。

流程说明:
- **1. 输入:图片+文字问题:**用户上传一张图片(如产品图、场景照片、医学影像)并提出与之相关的自然语言问题,系统接收多模态输入。
- **2. 消息格式构造:**将图片数据和文本问题封装为标准化的数据结构,标识不同模态类型,为模型处理做好准备。
- **3. 应用聊天模板:**按照多模态模型的指令格式要求,将输入拼接为预设的对话模板,如"图片:图像;问题:文本;请回答:",确保输入结构符合模型训练规范。
- **4. 视觉编码器:**采用轻量化视觉模型(如MobileNet、TinyViT)将原始像素压缩为固定维度的视觉特征向量,保留关键语义信息,同时控制计算开销。
- **5. 文本编码器:**使用轻量级文本编码器(如DistilBERT、AlBERT)将用户问题转化为语义特征向量,捕捉问题意图和关键实体。
- **6. 跨模态融合层:**通过协同注意力机制或特征拼接方式,将视觉特征与文本特征映射到同一语义空间,完成图文信息的对齐与交互融合。
- **7. 轻量级语言解码器:**基于融合后的多模态特征,使用参数精简的生成模型(如TinyLlama)逐词自回归解码,生成流畅、相关的回答内容。
- **8. 解码输出:**将模型生成的Token序列通过分词器解码为人类可读的自然语言文本,返回给用户作为最终答案。
五、应用实践
1. 简单直接的识别输出
python
from PIL import Image
from transformers import Qwen2VLProcessor, Qwen2VLForConditionalGeneration
from modelscope import snapshot_download
# 模型缓存目录
cache_dir = "D:\\modelscope\\hub"
# -------------- 1. 从 ModelScope 加载【Qwen2-VL-2B 轻量VLM】--------------
model_name = "Qwen/Qwen2-VL-2B-Instruct"
print(f"正在从 ModelScope 下载模型: {model_name}")
model_dir = snapshot_download(model_name, cache_dir=cache_dir)
print("加载模型...")
processor = Qwen2VLProcessor.from_pretrained(model_dir, trust_remote_code=True)
model = Qwen2VLForConditionalGeneration.from_pretrained(model_dir, trust_remote_code=True, device_map="auto").eval()
print("模型加载完成!\n")
# -------------- 2. 输入:图片 + 问题 --------------
# 替换成你本地的图片(猫/狗/杯子都行)
image = Image.open("test2.png").convert("RGB")
question = """请详细描述这张图片中的内容,包括:
1. 场景环境描述(位置、背景、光线等)
2. 主体动物的详细特征(外观、姿态、表情、颜色等)
3. 动物之间的互动关系
4. 任何有趣的细节或观察点
5. 整体氛围感受
请尽可能丰富地展开描述,提供生动的细节。"""
# -------------- 3. VLM 推理 --------------
# Qwen2-VL 使用消息格式
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": question}
]
}
]
# 处理输入:先应用模板,再转换为 tensor
text = processor.apply_chat_template(messages, tokenize=False)
inputs = processor(text=text, images=image, return_tensors="pt").to(model.device)
output = model.generate(**inputs, max_new_tokens=512, do_sample=False)
answer = processor.decode(output[0], skip_special_tokens=True)
# -------------- 4. 输出结果 --------------
print("问题:", question)
print("VLM回答:", answer)示例参考图片:test2.png

输出结果:
问题: 请详细描述这张图片中的内容,包括:
场景环境描述(位置、背景、光线等)
主体动物的详细特征(外观、姿态、表情、颜色等)
动物之间的互动关系
任何有趣的细节或观察点
整体氛围感受
请尽可能丰富地展开描述,提供生动的细节。
VLM回答:
这张图片展示了一只猫和一只狗,它们坐在窗台上。猫坐在窗台上,而狗则躺在窗台上。猫的毛色是橙色的,有黑色的条纹,它的眼睛是绿色的。狗的毛色是 金色的,它的眼睛是黑色的。猫和狗都背向窗户,窗台上有一个白色的碗,里面装着食物。窗台是木制的,窗户是木制的,背景是蓝 色的天空。
2. 参数优化处理输出
- 增加了对模型加载数据类型的指定:指定了torch_dtype=torch.float16。这意味着模型将使用半精度浮点数来减少内存占用。
- 改进了推理过程中的生成参数控制:在调用model.generate()方法时,不仅设置了max_new_tokens和do_sample,还增加了temperature和top_p参数来进一步控制生成文本的随机性和质量。
- 增加了对推理过程的详细分步注释:在执行VLM推理步骤时提供了更为详细的注释,帮助理解每个步骤的目的和作用。
python
from PIL import Image
import torch
from transformers import Qwen2VLProcessor, Qwen2VLForConditionalGeneration
from modelscope import snapshot_download
import warnings
warnings.filterwarnings("ignore") # 屏蔽无关警告,提升体验
# ====================== 1. 配置与模型加载 ======================
# 模型缓存目录(避免重复下载,建议设置固定路径)
cache_dir = "D:\\modelscope\\hub"
# 轻量级VLM模型名称(Qwen2-VL-2B-Instruct)
model_name = "Qwen/Qwen2-VL-2B-Instruct"
print(f"【第一步】从ModelScope下载轻量级VLM模型: {model_name}")
# 下载模型到本地缓存(首次运行需下载,约4GB,后续直接加载)
model_dir = snapshot_download(model_name, cache_dir=cache_dir)
print("【第二步】初始化处理器与模型")
# 处理器:负责图片/文本的预处理(缩放、编码、格式转换)
processor = Qwen2VLProcessor.from_pretrained(model_dir, trust_remote_code=True)
# 加载模型:device_map="auto"自动分配到CPU/GPU,eval()进入推理模式
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_dir,
trust_remote_code=True,
device_map="auto", # 自动选择设备(有GPU用GPU,无则用CPU)
torch_dtype=torch.float16, # 半精度加载,减少内存占用
).eval() # 推理模式,禁用训练相关的梯度计算
print("模型加载完成!\n")
# ====================== 2. 输入准备:图片 + 问题 ======================
print("【第三步】加载图片与构造问题")
# 替换为你的本地图片路径(支持jpg/png等格式)
image_path = "87.cat.png"
try:
# 加载并转换为RGB格式(统一图片通道,避免格式错误)
image = Image.open(image_path).convert("RGB")
except Exception as e:
print(f"图片加载失败:{e}")
exit(1)
# 自定义问题(可替换为任意关于图片的问题)
question = "这张图片里有什么?请详细描述一下。"
# ====================== 3. 轻量级VLM核心推理流程 ======================
print("【第四步】执行VLM推理")
# Step 1:构造Qwen2-VL要求的消息格式(多模态输入标准格式)
messages = [
{
"role": "user", # 角色:用户
"content": [
{"type": "image", "image": image}, # 图片内容
{"type": "text", "text": question} # 文字问题
]
}
]
# Step 2:应用聊天模板(标准化输入,让模型理解对话逻辑)
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# Step 3:处理输入,转换为模型可识别的张量(tensor)
inputs = processor(
text=text,
images=image,
return_tensors="pt" # 返回PyTorch张量
).to(model.device) # 转移到模型所在设备(CPU/GPU)
# Step 4:生成回答(轻量化生成策略,控制算力消耗)
with torch.no_grad(): # 禁用梯度计算,提升速度、减少内存占用
output = model.generate(
**inputs,
max_new_tokens=200, # 限制最大生成长度,避免算力浪费
do_sample=False, # 确定性生成,结果更稳定
temperature=0.0, # 温度设为0,无随机生成
top_p=1.0 # 核采样,仅用最高概率的token
)
# Step 5:解码输出,得到自然语言回答
answer = processor.decode(output[0], skip_special_tokens=True)
# ====================== 4. 结果输出 ======================
print("\n【最终结果】")
print(f"问题:{question}")
print(f"轻量级VLM回答:\n{answer}")关键技术细节:
- 视觉特征处理:Qwen2-VL-2B 将输入图片缩放至 448×448(而非大模型的 768×768),减少像素级计算;提取的视觉特征维度从 1024 压缩至 512,降低后续融合计算量;
- 聊天模板标准化:Qwen2-VL 要求输入遵循固定的对话模板(如{"role":"user","content":\[{"type":"image"},{"type":"text"}}]),目的是让模型统一理解输入格式,减少冗余的格式解析计算;
- 生成策略优化:轻量级 VLM 通常使用do_sample=False(确定性生成)、max_new_tokens限制生成长度,避免过度消耗算力。
示例参考图片:cat.png

输出结果:
【第一步】从ModelScope下载轻量级VLM模型: Qwen/Qwen2-VL-2B-Instruct
Downloading Model from modelscope to directory: D:\modelscope\hub\Qwen\Qwen2-VL-2B-Instruct
【第二步】初始化处理器与模型
Loading weights: 100%|█| 729/729 [00:04<00:00, 171.08it/s, Materializing param=model.visual.patch_embed.proj.
Some parameters are on the meta device because they were offloaded to the disk and cpu.
模型加载完成!
【第三步】加载图片与构造问题
【第四步】执行VLM推理
【最终结果】
问题:这张图片里有什么?请详细描述一下。
轻量级VLM回答:
system
You are a helpful assistant.
user
这张图片里有什么?请详细描述一下。
assistant
这张图片里有一只猫。猫的毛色是橙色和棕色相间的条纹,眼睛是黄色的,耳朵竖立着。它正坐在一个白色的窗台上,背景是白色的墙壁和窗户。猫的表情看起来很平静,似乎在观察周围的环境。
六、总结
VLM使我们进一步的理解大模型从来不是越大越好,能落地、能用得起才是真价值。之前总觉得多模态AI都是云端大模型的专属,必须靠高端GPU才能跑,慢慢的发现,以Qwen2-VL-2B为代表的轻量级VLM,直接把多模态能力拉到了普通电脑就能运行的级别,让大模型从遥不可及变成了随手可用。
VLM的核心逻辑:把图片转成特征、和文字特征对齐,再用轻量化大模型生成回答,看似简单的流程,藏着参数精简、模型量化、知识蒸馏这些关键技术。所以严格来说小模型不是缩水,而是用更高效的结构,保留大模型最核心的能力。