SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS
自洽性提升语言模型中的思维链推理能力

摘要
思维链提示与预训练大语言模型结合,在复杂推理任务上取得了令人鼓舞的成果。本文提出一种新的解码策略------自洽性,以取代思维链提示中使用的朴素贪心解码。该方法首先生成多样化的推理路径集合,而非仅采用贪心路径,随后通过边缘化采样得到的推理路径来选取最一致的答案。自洽性基于这样的直观认识:复杂的推理问题通常允许多种不同的思考方式,并最终指向其唯一正确答案。我们广泛的实证评估表明,自洽性显著提升了思维链提示在一系列主流算术与常识推理基准测试上的性能,包括GSM8K(+17.9%)、SVAMP(+11.0%)、AQuA(+12.2%)、StrategyQA(+6.4%)和ARC-challenge(+3.9%)。
1.引言
尽管语言模型在一系列自然语言处理任务中展现出显著成就,但其推理能力常被视为一种局限,且仅通过扩大模型规模无法克服这一局限(Rae等人,2021;BIG-bench协作组,2021等)。为应对这一不足,Wei等人(2022)提出了思维链提示方法,该方法通过提示语言模型生成一系列简短句子,以模拟人类在解决问题时可能采用的推理过程。例如,针对问题"停车场原有3辆车,又来了2辆车,停车场现有几辆车?",语言模型不会直接回答"5",而是被引导输出完整的思维链:"停车场原本有3辆车。又来了2辆车。现在共有3 + 2 = 5辆车。答案是5。"研究观察到,思维链提示能显著提升模型在多种多步推理任务中的表现(Wei等人,2022)。
本文提出了一种名为"自洽性"的新型解码策略,以取代思维链提示(Wei等,2022)中使用的贪婪解码策略。该策略通过显著幅度进一步提升了语言模型的推理性能。自洽性基于这样的洞见:复杂推理任务通常存在多条能得出正确答案的推理路径(Stanovich & West, 2000)。一个问题所需的审慎思考与分析越多(Evans, 2010),能够推导出答案的推理路径多样性就越高。
图1通过示例阐释了自洽方法的具体流程。我们首先使用思维链提示引导语言模型,随后不采用贪婪解码获取最优推理路径,而是提出一种"采样-边缘化"解码流程:首先从语言模型的解码器中采样生成多样化的推理路径集合;每条推理路径可能导出不同的最终答案,因此我们通过对采样得到的推理路径进行边缘化处理,在最终答案集合中确定最具一致性的最优答案。这种方法类似于人类经验:当多种不同的思考方式指向同一答案时,人们对该答案的正确性会抱有更高置信度。相较于其他解码方法,自洽机制避免了贪婪解码中常见的重复性与局部最优问题,同时减轻了单次采样生成结果的随机性影响。
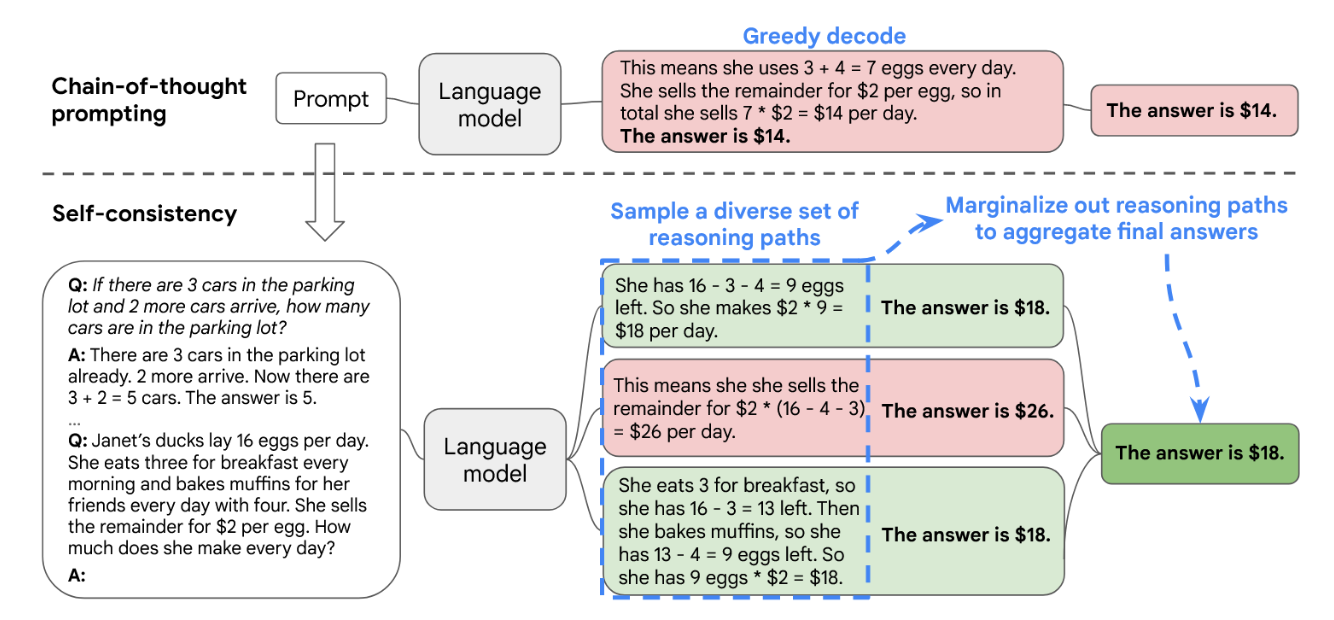
图1:自洽方法包含三个步骤:(1) 使用思维链提示法激发语言模型;(2) 通过从语言模型解码器中采样的方式替代思维链提示中的"贪婪解码",以生成多样化的推理路径集合;(3) 边缘化推理路径,并通过在最终答案集合中选择最一致的答案进行聚合。
自洽性相较于先前方法要简单得多------那些方法要么需要训练额外的验证器(Cobbe等人,2021年),要么需要基于额外人工标注来训练重排序器以提升生成质量(Thoppilan等人,2022年)。相反,自洽性是完全无监督的,可直接应用于预训练语言模型而无需额外人工标注,同时避免了任何额外的训练、辅助模型或微调。自洽性也不同于典型的集成方法(即训练多个模型并聚合各模型输出),它更像一种在单一语言模型基础上运作的"自集成"机制。
我们在四种不同规模的语言模型上评估了自洽性在广泛算术与常识推理任务中的表现:公开模型UL2-20B(Tay等人,2022)和GPT-3-175B(Brown等人,2020),以及两个密集激活的仅解码器语言模型LaMDA-137B(Thoppilan等人,2022)和PaLM-540B(Chowdhery等人,2022)。在所有四种语言模型上,自洽性方法均显著超越了思维链提示,在所有任务中取得明显提升。尤其是当与PaLM-540B或GPT-3结合使用时,自洽性在算术推理任务上达到了新的最先进性能水平,包括GSM8K(Cobbe等人,2021)(绝对准确率提升+17.9%)、SVAMP(Patel等人,2021)(+11.0%)、AQuA(Ling等人,2017)(+12.2%);在常识推理任务上,如StrategyQA(Geva等人,2021)(+6.4%)和ARC挑战集(Clark等人,2018)(+3.9%)也表现优异。在额外实验中,我们证明自洽性能够稳健提升那些因添加思维链反而可能损害性能(相比标准提示)的NLP任务表现(Ye & Durrett,2022)。我们还表明自洽性显著优于采样排序、束搜索、基于集成的方法,并且对采样策略和不完美的提示具有鲁棒性。
2.自我一致性于多元推理路径
人类的一个显著特点是思维方式各异。可以很自然地假设,在需要深思熟虑的任务中,很可能存在多种解决问题的路径。我们提出,这样的过程可以通过从语言模型的解码器中采样来模拟。例如,如图1所示,对于同一个数学问题,模型可以生成多条看似合理且最终都得到相同正确答案的推理过程(输出1和3)。由于语言模型并非完美的推理者,它也可能产生错误的推理路径或在某一步推理中出现失误(例如输出2),但此类解法最终得到相同答案的可能性较低。也就是说,我们假设正确的推理过程即使存在多样性,其最终答案的一致性也往往高于错误的推理过程。
我们基于这一直觉,提出了如下自洽性方法。首先,使用一组手动编写的思维链示例(Wei等人,2022)对语言模型进行提示。接着,我们从语言模型的解码器中采样一组候选输出,生成多样化的候选推理路径。自洽性与大多数现有采样算法兼容,包括温度采样(Ackley et al., 1985; Ficler & Goldberg, 2017)、top-k采样(Fan et al., 2018; Holtzman et al., 2018; Radford et al., 2019)以及核采样(Holtzman et al., 2020)。最后,我们通过对采样的推理路径进行边缘化处理,并选择生成答案中一致性最高的答案来进行答案聚合。
具体而言,假设生成的答案 a i a_i ai来自固定答案集合A,其中 i = 1 , ... , m i=1,...,m i=1,...,m表示从解码器中采样的m个候选输出的索引。给定提示和问题后,自洽性方法引入了一个额外的潜变量 r i r_i ri,它是代表第i个输出中推理路径的标记序列,并将 ( r i , a i ) (r_i, a_i) (ri,ai)的生成过程耦合起来,其中 r i → a i r_i → a_i ri→ai,即生成推理路径 r i r_i ri是可选的,仅用于得出最终答案 a i a_i ai。以图1中的输出3为例:前几句"她早餐吃了3个鸡蛋...因此她有9个鸡蛋 * 2美元 = 18美元"构成 r i r_i ri,而最后一句"答案是18美元"中解析出的数字18即为 a i a_i ai。在从模型解码器中采样得到多个 ( r i , a i ) (r_i, a_i) (ri,ai)后,自洽性方法通过对 r i r_i ri进行边缘化处理,对 a i a_i ai执行多数投票------即 a r g m a x a ∑ i m = 1 ( a i = a ) arg max_a \sum^m_i=1(a_i = a) argmaxa∑im=1(ai=a),或按我们的定义,从最终答案集合中选取"最一致"的答案。
在表1中,我们展示了通过使用不同答案聚合策略在一系列推理任务上的测试准确率。除多数投票外,在聚合答案时也可对每个 ( r i , a i ) (r_i, a_i) (ri,ai)依据 P ( r i , a i ∣ 提示,问题) P(r_i, a_i| 提示,问题) P(ri,ai∣提示,问题)进行加权。需注意,计算 P ( ( r i , a i ∣ 提示,问题) P((r_i, a_i | 提示,问题) P((ri,ai∣提示,问题)时,我们既可取模型在给定(提示,问题)下生成 ( r i , a i ) (r_i, a_i) (ri,ai)的非归一化概率,也可通过输出长度对条件概率进行归一化(Brown et al., 2020)。
P ( r i , a i ∣ p r o m p t , q u e s t i o n ) = exp 1 K ∑ k = 1 K log P ( t k ∣ prompt,question , t 1 , . . . , t k − 1 ) , P(\mathbf{r}i,\mathbf{a}i\mid\mathrm{prompt},\mathrm{question})=\exp^{\frac{1}{K}\sum{k=1}^K\log P(t_k|\text{prompt,question},t_1,...,t{k-1})}, P(ri,ai∣prompt,question)=expK1∑k=1KlogP(tk∣prompt,question,t1,...,tk−1),
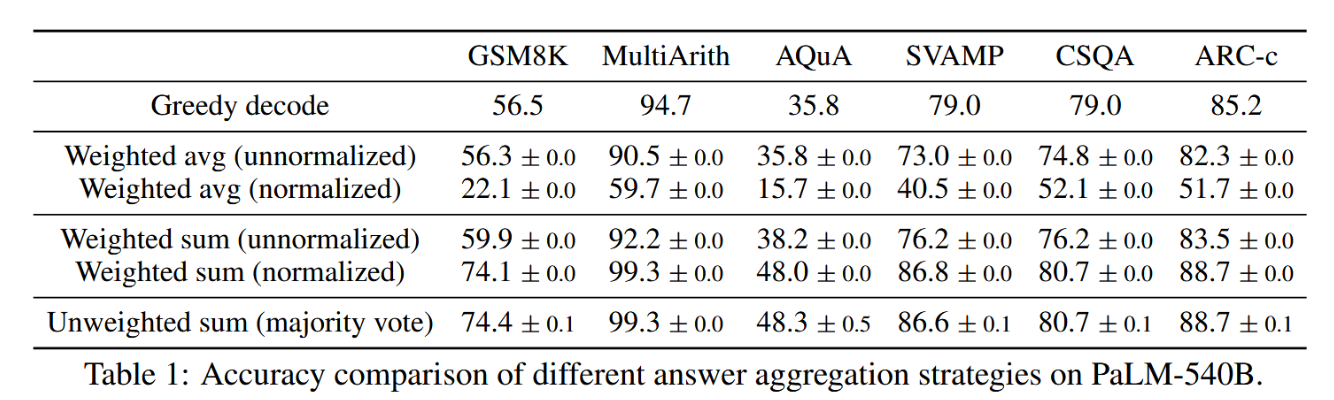
表1:不同答案聚合策略在PaLM-540B模型上的准确度对比
其中 l o g P ( t k ∣ p r o m p t , q u e s t i o n , t 1 , . . . , t k − 1 ) log P (t_k | prompt, question, t_1, . . . , t_{k−1}) logP(tk∣prompt,question,t1,...,tk−1) 表示在给定上文 token 条件下生成 ( r i , a i ) (r_i, a_i) (ri,ai)中第 k 个 token t k t_k tk 的对数概率,K 为 ( r i , a i ) (r_i, a_i) (ri,ai) 中的总 token 数。在表 1 中,我们发现采用"未加权求和"(即直接对 a i a_i ai 进行多数投票)与使用"归一化加权求和"聚合所得准确率非常接近。通过进一步检视模型输出的概率分布,发现这是因为对于每个 ( r i , a i ) (r_i, a_i) (ri,ai),其归一化条件概率 P ( r i , a i ∣ p r o m p t , q u e s t i o n ) P (r_i, a_i | prompt, question) P(ri,ai∣prompt,question) 彼此十分接近,即语言模型认为这些生成结果具有"相似的似然性"。此外,在答案聚合过程中,表 1 结果显示"归一化"加权求和(即公式 1)相比未归一化版本能获得显著更高的准确率。为保持完整性,表 1 同时报告了采用"加权平均"的结果(即每个 a 的得分为其加权总和除以 ∑ i = 1 m 1 ( a i = a ) \sum^m _{i=1} 1(a_i = a) ∑i=1m1(ai=a),该方法导致性能大幅下降。
自洽性探索了开放式文本生成与具有固定答案的最优文本生成之间一个有趣的空间。推理任务通常具有固定答案,这正是研究者们普遍考虑采用贪婪解码方法的原因(Radford等人,2019;Wei等人,2022;Chowdhery等人,2022)。然而我们发现,即使期望的答案是固定的,在推理过程中引入多样性也极具益处;因此我们利用了实验,如拉德福德等人(2019)、布朗等人(2020)及托皮兰等人(2022)所常用,该方法通常用于开放式文本生成以实现此目标。需注意的是,自洽性仅适用于答案来自固定集合的问题,但原则上,若能在多次生成间定义出良好的一致性度量标准(例如,判断两个答案是否一致或相互矛盾),该方法亦可扩展至开放式文本生成问题。
3.实验
我们通过一系列实验,在多项推理基准测试中将提出的自洽方法与现有方法进行比较。研究发现,对于所考察的各种规模的语言模型,自洽方法均能稳健地提升其推理准确性。
3.1 实验设置
任务与数据集。我们在以下推理基准上评估自洽性:
-
算术推理:在这些任务中,我们使用了数学应用题库(Koncel-Kedziorski等人,2016),包括AddSub(Hosseini等人,2014)、MultiArith(Roy & Roth,2015)和ASDiv(Miao等人,2020)。我们还纳入了AQUA-RAT(Ling等人,2017)、近期发布的小学数学问题基准GSM8K(Cobbe等人,2021),以及数学应用题挑战数据集SVAMP(Patel等人,2021)。
-
常识推理:在这些任务中,我们使用了CommonsenseQA(Talmor等人,2019)、StrategyQA(Geva等人,2021)以及AI2推理挑战数据集ARC(Clark等人,2018)。
-
符号推理:我们评估了两种符号推理任务:末字母拼接(例如,输入"Elon Musk"时输出应为"nk")以及来自Wei等人(2022)的硬币翻转任务(例如,一枚硬币初始正面朝上,经过多次翻转后是否仍为正面?)
语言模型与提示。我们在四种不同规模的基于Transformer的语言模型上评估自洽性:
• UL2(Tay等人,2022)是一个编码器-解码器模型,采用混合去噪器训练,拥有200亿参数。UL2完全开源,在零样本SuperGLUE任务中表现与GPT-3相当或更优,且仅需200亿参数,因而计算效率更高;
• GPT-3(Brown等人,2020)拥有1750亿参数。我们使用Codex系列中两个公开引擎code-davinci-001和code-davinci-002(Chen等人,2021)以提升可复现性;
• LaMDA-137B(Thoppilan等人,2022)是一个稠密的左到右、仅解码器语言模型,具有1370亿参数,基于网页文档、对话数据和维基百科的混合数据进行预训练;
• PaLM-540B(Chowdhery等人,2022)是一个稠密的左到右、仅解码器语言模型,具有5400亿参数,基于包含过滤网页、书籍、维基百科、新闻文章、源代码和社交媒体对话的高质量语料库(7800亿词元)进行预训练。
我们在小样本设定下进行所有实验,不对语言模型进行训练或微调。为确保公平比较,我们采用与Wei等人(2022)相同的提示方案:所有算术推理任务均使用相同的8个手动编写的示例;对于每个常识推理任务,则从训练集中随机选取4-7个样本,并配以人工编写的思维链提示。具体提示的完整细节详见附录A.3。
采样方案。为获取多样化的推理路径,我们遵循了Radford等人(2019)和Holtzman等人(2020)针对开放文本生成提出的类似设置。具体而言,对于UL2-20B和LaMDA-137B模型,我们采用了温度为T = 0.5的采样方法,并截取概率最高的前k个词元(k = 40);对于PaLM-540B模型,采用T = 0.7,k = 40的设定;而对于GPT-3模型,我们使用T = 0.7的温度采样且不进行top-k截断。我们在第3.5节提供了消融实验,以表明自洽性对于不同采样策略和参数普遍具有鲁棒性。
3.2 主要结果
我们报告了10次运行的自洽性平均结果,每次运行中均从解码器独立采样40个输出。我们比较的基线是思维链提示配合贪心解码(Wei等人,2022),简称CoT提示法,该方法此前已用于大语言模型的解码过程(Chowdhery等人,2022)。
算术推理
结果如表2.7所示。自洽性方法相比思维链提示,在所有四种语言模型上均显著提升了算术推理性能。更令人惊讶的是,当语言模型规模增大时,性能提升更加显著:例如,UL2-20B模型上我们观察到绝对准确率提升+3%-6%,而在LaMDA137B和GPT-3模型上则达到+9%-23%。对于已在大多数任务中实现高准确率的大型模型(如GPT-3和PaLM-540B),自洽性仍能带来显著的额外增益:在AQuA和GSM8K任务上绝对准确率提升+12%-18%,在SVAMP和ASDiv任务上提升+7%-11%。通过自洽性方法,我们在几乎所有任务上都取得了新的最先进结果:尽管自洽性是无监督且与任务无关的,但这些结果优于需要任务特定训练或数千示例微调的现有方法(例如在GSM8K任务上)。
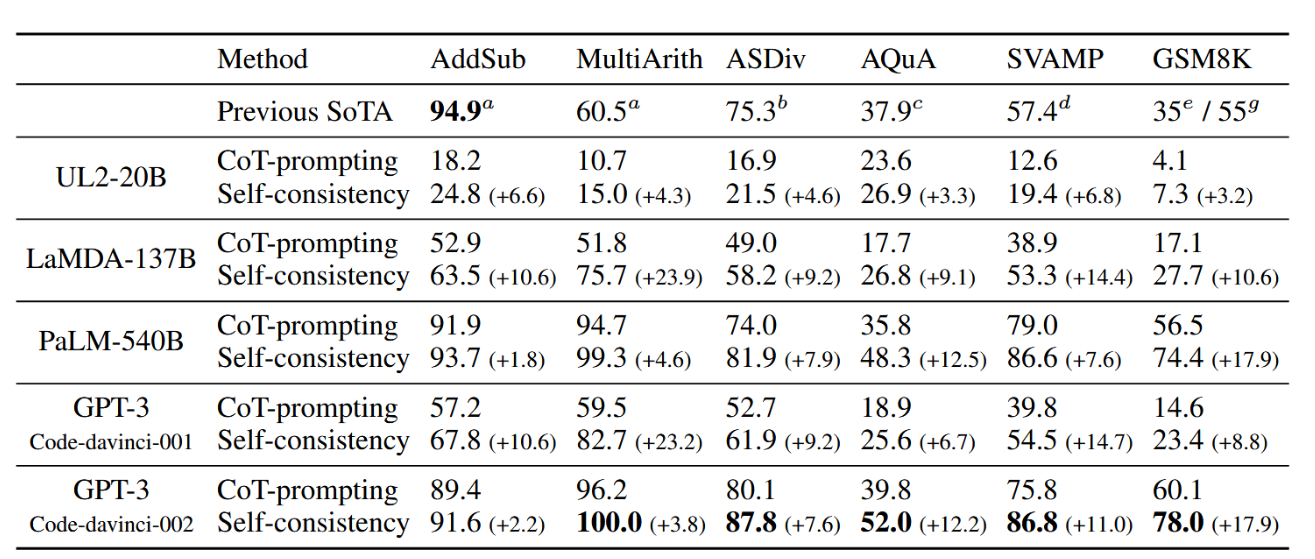
表2:自我一致性与思维链提示的算术推理准确率对比(Wei等人,2022)。先前的最先进基线结果来自:a: 相关性与LCA操作分类器(Roy & Roth, 2015),b: Lan等人(2021),c: Amini等人(2019),d: Pi等人(2022),e: 使用7.5k样本微调的GPT-3 175B(Cobbe等人,2021),g: 微调GPT-3 175B加额外175B验证器(Cobbe等人,2021)。各项任务的最佳性能以粗体显示。
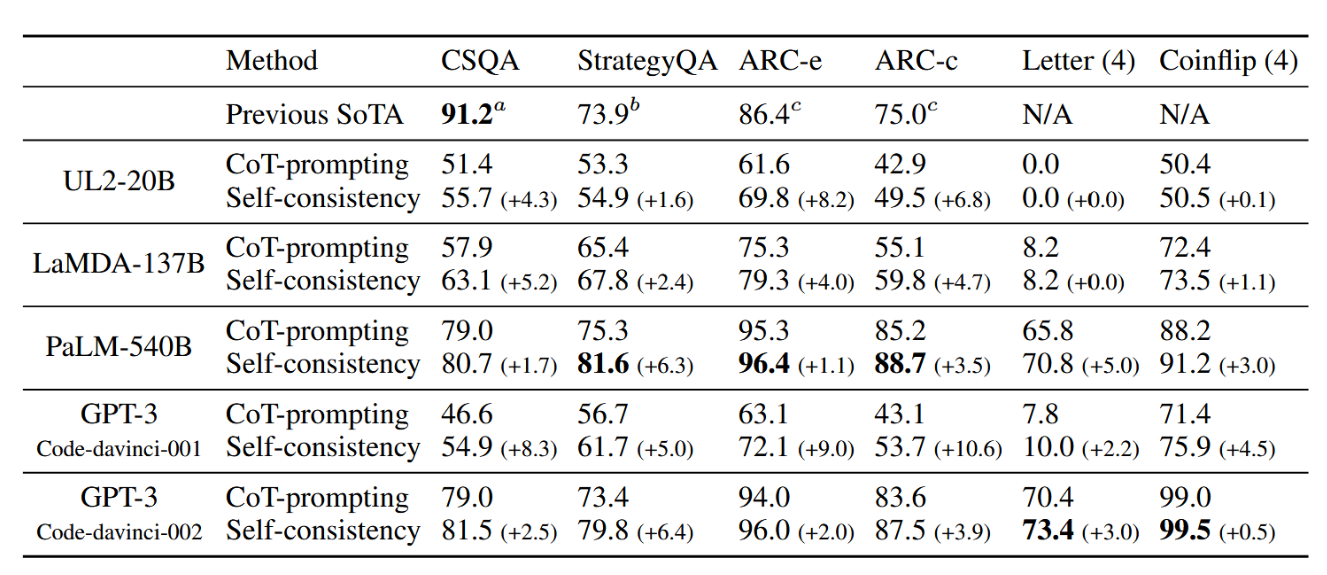
表3:基于自洽性的常识与符号推理准确率对比思维链提示方法(Wei等人,2022)。先前的最先进基线结果来源于:a: DeBERTaV3-large + KEAR(Xu等人,2021b),b: Chowdhery等人(2022),c: UnifiedQA-FT(Khashabi等人,2020)。各项任务的最佳性能以粗体标示。
常识与符号推理
表3展示了常识与符号推理任务的结果。与此前类似,自洽性方法在所有四种语言模型中均带来显著提升,并在六项任务中的五项上取得了最先进的结果。在符号推理任务中,我们测试了分布外(OOD)设定:输入提示中包含2个字母或2次翻转的示例,而我们测试的是4个字母和4次翻转的示例(该设定更具挑战性,因为PaLM-540B或GPT-3已在分布内设定下达到完美准确率)。在此具有挑战性的分布外设定中,当模型规模足够大时,自洽性相比思维链提示方法仍显示出相当显著的增益。
为展示采样推理路径数量的影响,我们在图2中绘制了准确率(10次运行的平均值和标准差)随采样路径数量(1、5、10、20、40)变化的关系。结果表明,采样更多数量(例如40条)的推理路径能够持续带来更好的性能,这进一步强调了在推理路径中引入多样性的重要性。在表4中,我们通过两个任务中的若干示例问题展示了与贪婪解码相比,自一致性方法能产生更丰富的推理路径集合。

图2:与LaMDA-137B模型上使用贪婪解码的思维链提示(橙色)相比,自洽性方法(蓝色)在算术和常识推理任务中的准确性均有显著提升。采样更多样化的推理路径能持续提高推理准确率。

表4:在PaLM-540B模型中,自洽性有助于修正贪婪解码错误的示例。此处展示了与真实答案一致的两条抽样推理路径。
3.3 当思维链损害性能时,自洽性提供助力
Ye 和 Durrett(2022)的研究表明,在少样本上下文学习中,与标准提示法相比,思维链提示法有时反而会损害模型表现。为此,我们开展了一项研究,利用自我一致性方法,考察其是否能在一系列常见自然语言处理任务中弥补这一不足。这些任务包括:(1)闭卷问答:BoolQ(Clark 等人,2019)、HotpotQA(Yang 等人,2018);(2)自然语言推理:e-SNLI(Camburu 等人,2018)、ANLI(Nie 等人,2020)以及 RTE(Dagan 等人,2005;Bar-Haim 等人,2006;Giampiccolo 等人,2007;Bentivogli 等人,2009)。
PaLM-540B 的结果展示在表5中。对于某些任务(例如 ANLI-R1, e-SNLI, RTE),与标准提示(Brown et al., 2020)相比,添加思维链确实会损害性能,但自我一致性能够稳健地提升性能并超越标准提示,这使其成为在常见 NLP 任务的少样本上下文学习中添加推理过程的可靠方法。

表5:标准/思维链提示与自洽方法在常见NLP任务上的对比。
3.4 与现有其他方法的比较
我们进行了一系列附加研究,结果表明自洽性方法显著优于包括采样排序、束搜索和基于集成方法在内的现有技术。
与采样排序法的比较
提升生成质量的常用方法之一是采样排序法,该方法从解码器中采样多个序列,随后根据各序列的对数概率进行排序(Adiwardana 等人,2020)。我们在 GPT-3 code-davinci-001 模型上将自洽性与采样排序法进行了对比,从解码器中采样与自洽性方法相同数量的序列,并选取排名最高序列的答案作为最终输出。结果如图 3 所示。尽管采样排序法通过额外采样和排序确实提高了准确率,但其增益远小于自洽性方法。
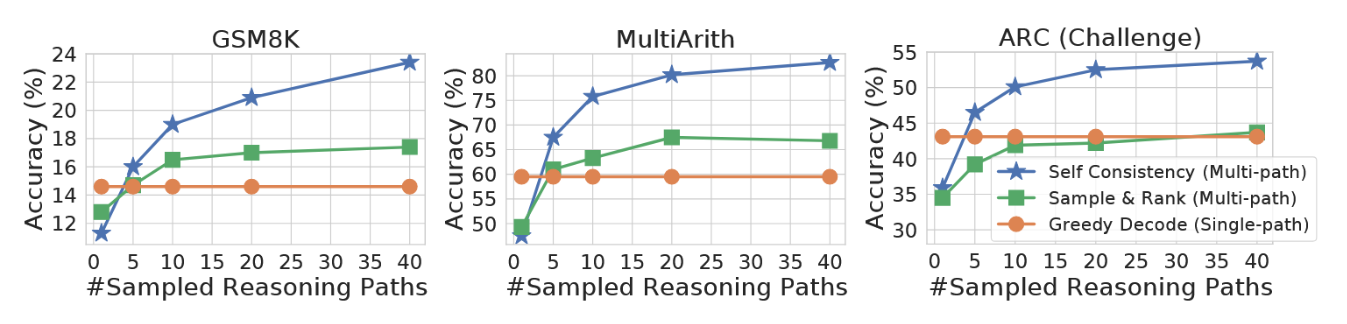
图3:在采样数量相同的情况下,自洽性方法显著优于采样排序方法。
与束搜索的对比
在表6中,我们比较了UL2-20B模型上自洽性与束搜索解码的性能。为确保公平比较,我们报告了相同束宽和推理路径数量下的准确率。在两项任务中,自洽性均显著优于束搜索。需注意,自洽性也可采用束搜索来解码每条推理路径(结果标注为"使用束搜索的自洽性"),但其表现弱于基于采样的自洽性。原因在于束搜索会降低输出的多样性(Li & Jurafsky, 2016),而在自洽性中,推理路径的多样性是实现更优性能的关键。
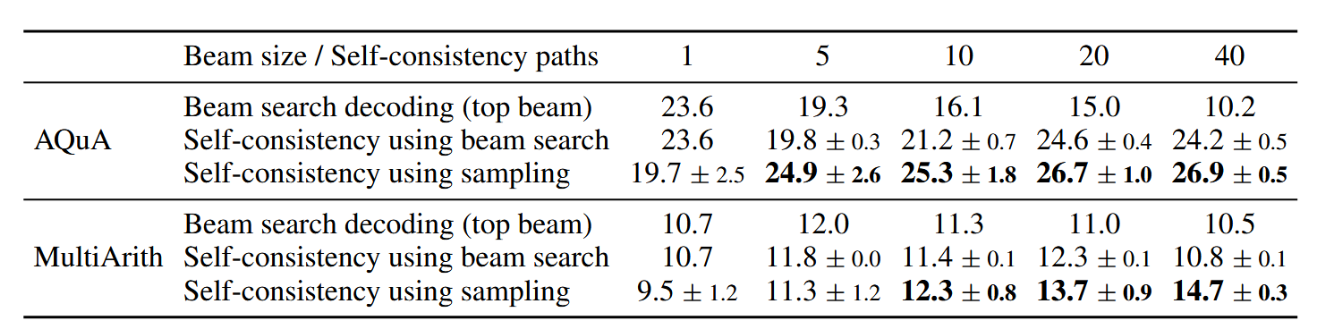
表6:在UL2-20B模型上对比自洽性与束搜索解码
与基于集成的学习方法比较
我们将自洽性与小样本学习中的集成方法进行了进一步比较。具体而言,我们通过以下两种方式进行集成:(1) 提示顺序排列:随机置换提示中的示例顺序40次,以缓解模型对提示顺序的敏感性(Zhao et al., 2021; Lu et al., 2021);(2) 多组提示(Gao et al., 2021):人工编写3组不同的提示。两种方法均采用贪心解码输出的答案进行多数投票作为集成结果。表7显示,与自洽性相比,现有基于集成的方法获得的性能提升明显更小。此外需注意,自洽性与典型的模型集成方法不同------后者需训练多个模型并聚合其输出,而自洽性更像在单一语言模型基础上实现的"自集成"。我们在附录A.1.3中额外展示了多模型集成的结果,其性能远低于自洽性方法。

表7:在LaMDA-137B模型中,自洽性优于提示顺序与多提示集成方法。
3.5 补充研究
我们进行了多项补充实验,以分析自洽方法的不同层面,包括其对抽样策略与参数的鲁棒性,以及该方法在提示不完善和非自然语言推理路径下的表现。
自洽性对采样策略与模型规模具有鲁棒性
我们通过改变温度采样中的T值(Ackley等人,1985;Ficler & Goldberg,2017)、Top-k采样中的k值(Fan等人,2018;Holtzman等人,2018;Radford等人,2019)以及核采样中的p值(Holtzman等人,2020),在PaLM-540B模型上进行了实验(图4左),证明了自洽性对不同采样策略及参数具有鲁棒性。图4(右)显示,在LaMDA-137B系列模型中,自洽性能够稳定提升所有规模模型的性能。对于较小规模模型,性能提升相对较低,这是因为某些能力(如算术运算)仅在模型达到足够规模时才会显现(Brown等人,2020)。
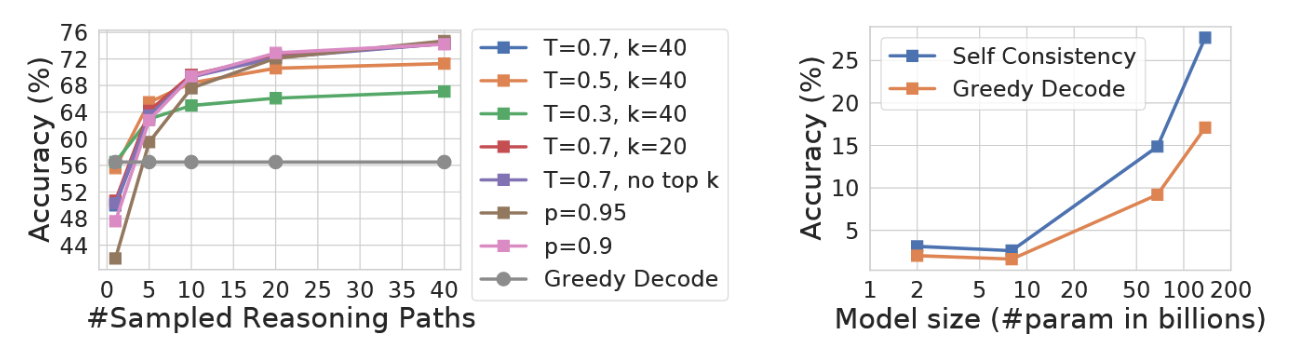
图4:GSM8K准确率。(左)自我一致性对不同采样策略和参数具有鲁棒性。(右)自我一致性提升了不同规模语言模型的性能。
在人工构建提示进行少样本学习时,标注者有时会在创建提示时出现细微错误。我们进一步研究了自洽性是否有助于提升语言模型对不完美提示的鲁棒性。表8展示了结果:虽然不完美的提示会降低贪婪解码的准确率(17.1 → 14.9),但自洽性能填补这一差距,稳健地提升最终结果。

表8:自洽性方法在GSM8K数据集上对于不完善提示、公式提示及零样本思维链的表现。
此外,我们发现一致性(以解码结果与最终聚合答案相符的百分比衡量)与准确性高度相关(如图5基于GSM8K数据集所示)。这表明可以利用自洽性来为模型生成的解决方案提供不确定性估计。换言之,可将较低的一致性视为模型置信度不足的指标;即自洽性使模型具备一定能力以"知晓其未知之处"。
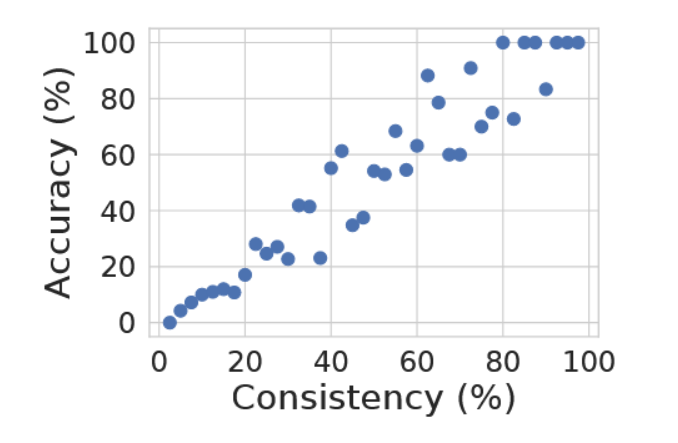
图5:一致性与模型准确率呈正相关。
自洽性在非自然语言推理路径与零样本思维链中的适用性
我们还检验了自洽性概念在替代性中间推理形式(如方程式)中的普适性(例如从"停车场已有3辆车,又来了2辆。现在共有3+2=5辆车"简化为"3+2=5")。结果展示于表8("带方程式的提示"):通过生成中间方程式,自洽性仍能提升准确性;但与生成自然语言推理路径相比,其增益较小,因为方程式长度较短,在解码过程中产生多样性的空间较小。此外,我们结合零样本思维链(Kojima等人,2022)测试了自洽性,结果表明自洽性在零样本思维链中同样有效,并在表8中显著提升了结果(+26.2%)。
我们使用与此前相同的提示语,但将推理路径中的所有数字替换为随机数字(最终答案除外),例如:从"停车场已有3辆车。又来了2辆。现在共有3 + 2 = 5辆车。"改为"停车场已有7辆车。又来了6辆。现在共有7 + 6 = 5辆车。"。
4.相关工作
语言模型中的推理。已知语言模型在算术、逻辑与常识推理等第二类任务中表现欠佳(Evans, 2010)。先前研究主要集中于通过专门化方法来提升推理能力(Andor等人,2019;Ran等人,2019;Geva等人,2020;Pie ̨kos等人,2021)。相较于已有研究,自洽性方法无需额外监督或微调即可广泛应用于多种推理任务,同时仍能显著提升Wei等人(2022)所提出的思维链提示方法的性能。
语言模型中的采样与重排序。文献中已提出多种语言模型解码策略,例如温度采样(Ackley等人,1985;Ficler与Goldberg,2017)、top-k采样(Fan等人,2018;Holtzman等人,2018;Radford等人,2019)、核心采样(Holtzman等人,2020)、最小贝叶斯风险解码(Eikema与Aziz,2020;Shi等人,2022)以及典型解码(Meister等人,2022)。另有一些研究致力于在解码过程中明确提升多样性(Batra等人,2012;Li等人,2016;Vijayakumar等人,2018)。
重排序是提升语言模型生成质量的另一种常见方法(Adiwardana等人,2020;Shen等人,2021)。Thoppilan等人(2022)通过收集额外的人工标注来训练用于响应过滤的重排序器。Cobbe等人(2021)训练了一个"验证器"来对生成的解决方案进行重排序,与仅对语言模型进行微调相比,这显著提高了数学任务的解决率。Elazar等人(2021)通过引入额外的一致性损失扩展预训练,从而提升了事实知识提取的一致性。所有这些方法都需要训练额外的重排序器或收集额外的人工标注,而自一致性方法则无需额外的训练、微调或数据收集。
提取推理路径。先前研究提出过多种任务专用方法,如构建语义图(Xu等人,2021a)、训练循环神经网络在维基百科图谱中检索推理路径(Asai等人,2020)、基于数学问题中人工标注的推理路径进行微调(Cobbe等人,2021),或使用启发式伪推理路径训练提取器(Chen等人,2019)。近期研究虽注意到推理过程多样性的重要性,但仅通过任务专用训练加以利用,例如在提取的推理路径上增加问答模型(Chen等人,2019),或在常识知识图谱中引入潜变量(Yu等人,2022)。相比这些方法,自洽性方法更为简洁且无需额外训练。我们提出的方法仅通过解码器采样耦合推理路径生成与最终答案,利用聚合机制获取最一致答案,无需引入额外模块。
语言模型的一致性问题。已有研究表明,语言模型在对话(Adiwardana等人,2020)、解释生成(Camburu等人,2020)和事实知识提取(Elazar等人,2021)中可能存在不一致性。Welleck等人(2020)将"一致性"定义为循环语言模型中生成无限长序列的特性。Nye等人(2021)通过添加受系统2启发的逻辑推理模块,提升了系统1模型生成样本的逻辑一致性。本文关注的"一致性"概念略有不同,即通过利用多样化推理路径间的答案一致性来提升准确性。
5.结论
我们引入了一种简单而有效的方法,称为"自洽性",并观察到该方法在四种不同规模的多种大型语言模型中,显著提升了算术和常识推理任务的一系列准确性。除了提升准确性外,自洽性在语言模型执行推理任务时也有助于收集推理依据,为模型输出提供不确定性估计,并改善其校准效果。
自洽性方法的一个局限在于其计算成本较高。实践中,使用者可以尝试少量推理路径(例如5或10条)作为起点,在不过多增加成本的情况下实现大部分性能提升------因为在多数情况下性能会快速达到饱和(图2)。作为未来工作的一部分,研究者可以利用自洽性生成更优质的监督数据对模型进行微调,使模型在微调后的单次推理中能给出更准确的预测。此外,我们观察到语言模型有时会产生错误或无意义的推理路径(例如表4中StrategyQA示例里两个人口数据并不完全准确),未来的研究需要进一步夯实模型生成推理依据的能力。
6.引用文献
- David H. Ackley, Geoffrey E. Hinton, and Terrence J. Sejnowski. A learning algorithm for boltzmann machines. Cognitive Science, 9(1):147--169, 1985. ISSN 0364-0213. URL https://www. sciencedirect.com/science/article/pii/S0364021385800124.
- Daniel Adiwardana, Minh-Thang Luong, David R. So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu, and Quoc V. Le. Towards a human-like open-domain chatbot, 2020.
- Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. MathQA: Towards interpretable math word problem solving with operation-based formalisms. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2357--2367. Association for Computational Linguistics, June 2019. URL https://aclanthology.org/N19-1245.
- Daniel Andor, Luheng He, Kenton Lee, and Emily Pitler. Giving BERT a calculator: Finding operations and arguments with reading comprehension. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019. URL https://aclanthology. org/D19-1609.
- Akari Asai, Kazuma Hashimoto, Hannaneh Hajishirzi, Richard Socher, and Caiming Xiong. Learning to retrieve reasoning paths over wikipedia graph for question answering. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum? id=SJgVHkrYDH.
- Roy Bar-Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. The second pascal recognising textual entailment challenge. In Proceedings of the second PASCAL challenges workshop on recognising textual entailment, 2006.
- Dhruv Batra, Payman Yadollahpour, Abner Guzman-Rivera, and Gregory Shakhnarovich. Diverse m-best solutions in markov random fields. In Proceedings of the 12th European Conference on Computer Vision - Volume Part V, ECCV'12, pp. 1--16, Berlin, Heidelberg, 2012. Springer-Verlag. ISBN 9783642337147. URL https://doi.org/10.1007/978-3-642-33715-4_1.
- Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. The fifth pascal recognizing textual entailment challenge. In TAC, 2009. BIG-bench collaboration. Beyond the imitation game: Measuring and extrapolating the capabilities of language models. In preparation, 2021. URL https://github.com/google/ BIG-bench/.
- Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In Advances in Neural Information Processing Systems, 2020. URL https://proceedings.neurips.cc/paper/2020/ file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
- Oana-Maria Camburu, Tim Rocktäschel, Thomas Lukasiewicz, and Phil Blunsom. esnli: Natural language inference with natural language explanations. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (eds.), Advances in Neural Information Processing Systems 31, pp. 9539--9549. Curran Associates, Inc., 2018. URL http://papers.nips.cc/paper/ 8163-e-snli-natural-language-inference-with-natural-language-explanations. pdf.
- Oana-Maria Camburu, Brendan Shillingford, Pasquale Minervini, Thomas Lukasiewicz, and Phil Blunsom. Make up your mind! adversarial generation of inconsistent natural language explanations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 4157--4165, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020. acl-main.382. URL https://aclanthology.org/2020.acl-main.382.
- Jifan Chen, Shih-Ting Lin, and Greg Durrett. Multi-hop question answering via reasoning chains. CoRR, abs/1910.02610, 2019. URL http://arxiv.org/abs/1910.02610.
- Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. Palm: Scaling language modeling with pathways, 2022. URL https://arxiv.org/abs/2204.02311.
- Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. In NAACL, 2019.
- Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv, abs/1803.05457, 2018.
- Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021.
- Ido Dagan, Oren Glickman, and Bernardo Magnini. The pascal recognising textual entailment challenge. In Machine Learning Challenges Workshop, pp. 177--190. Springer, 2005.
- Bryan Eikema and Wilker Aziz. Is MAP decoding all you need? the inadequacy of the mode in neural machine translation. In Proceedings of the 28th International Conference on Computational Linguistics, pp. 4506--4520, Barcelona, Spain (Online), December 2020. International Committee on Computational Linguistics. URL https://aclanthology.org/2020.coling-main. 398.
- Yanai Elazar, Nora Kassner, Shauli Ravfogel, Abhilasha Ravichander, Eduard Hovy, Hinrich Schütze, and Yoav Goldberg. Measuring and improving consistency in pretrained language models. Transactions of the Association for Computational Linguistics, 9:1012--1031, 2021. doi: 10.1162/tacl_a_00410. URL https://aclanthology.org/2021.tacl-1.60.
- Jonathan St BT Evans. Intuition and reasoning: A dual-process perspective. Psychological Inquiry, 21(4):313--326, 2010.
- Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 889--898, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-1082. URL https://aclanthology.org/P18-1082.
- Jessica Ficler and Yoav Goldberg. Controlling linguistic style aspects in neural language generation. In Proceedings of the Workshop on Stylistic Variation, pp. 94--104, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. doi: 10.18653/v1/W17-4912. URL https: //aclanthology.org/W17-4912.
- Tianyu Gao, Adam Fisch, and Danqi Chen. Making pre-trained language models better few-shot learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 3816--3830, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.295. URL https://aclanthology.org/2021.acl-long. 295.
- Mor Geva, Ankit Gupta, and Jonathan Berant. Injecting numerical reasoning skills into language models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020. doi: 10.18653/v1/2020.acl-main.89. URL https://aclanthology.org/2020. acl-main.89.
- Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? A question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 2021. URL https://aclanthology.org/ 2021.tacl-1.21.
- Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. The third pascal recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing, pp. 1--9. Association for Computational Linguistics, 2007.
- Ari Holtzman, Jan Buys, Maxwell Forbes, Antoine Bosselut, David Golub, and Yejin Choi. Learning to write with cooperative discriminators. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1638--1649, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-1152. URL https://aclanthology.org/P18-1152.
- Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. In International Conference on Learning Representations, 2020. URL https: //openreview.net/forum?id=rygGQyrFvH.
- Mohammad Javad Hosseini, Hannaneh Hajishirzi, Oren Etzioni, and Nate Kushman. Learning to solve arithmetic word problems with verb categorization. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014. doi: 10.3115/v1/D14-1058. URL https://aclanthology.org/D14-1058.
- Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. UNIFIEDQA: Crossing format boundaries with a single QA system. In Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 1896--1907, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.findings-emnlp.171. URL https://aclanthology.org/2020.findings-emnlp.171.
- Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (eds.), Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=e2TBb5y0yFf.
- Rik Koncel-Kedziorski, Subhro Roy, Aida Amini, Nate Kushman, and Hannaneh Hajishirzi. MAWPS: A math word problem repository. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2016. doi: 10.18653/v1/N16-1136. URL https://aclanthology.org/N16-1136.
- Yihuai Lan, Lei Wang, Qiyuan Zhang, Yunshi Lan, Bing Tian Dai, Yan Wang, Dongxiang Zhang, and Ee-Peng Lim. MWPToolkit: An open-source framework for deep learning-based math word problem solvers. arXiv preprint arXiv:2109.00799, 2021. URL https://arxiv.org/abs/ 2109.00799.
- Jiwei Li and Dan Jurafsky. Mutual information and diverse decoding improve neural machine translation, 2016. URL https://arxiv.org/abs/1601.00372.
- Jiwei Li, Will Monroe, and Dan Jurafsky. A simple, fast diverse decoding algorithm for neural generation. CoRR, abs/1611.08562, 2016. URL http://arxiv.org/abs/1611.08562.
- Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2017. doi: 10.18653/v1/P17-1015. URL https://aclanthology.org/P17-1015.
- Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. ArXiv, abs/2104.08786, 2021.
- Clara Meister, Tiago Pimentel, Gian Wiher, and Ryan Cotterell. Typical decoding for natural language generation. arXiv preprint arXiv:2202.00666, 2022.
- Shen Yun Miao, Chao Chun Liang, and Keh Yih Su. A diverse corpus for evaluating and developing English math word problem solvers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020. URL https://aclanthology.org/2020. acl-main.92.
- Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. Adversarial NLI: A new benchmark for natural language understanding. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2020.
- Maxwell Nye, Michael Henry Tessler, Joshua B. Tenenbaum, and Brenden M. Lake. Improving coherence and consistency in neural sequence models with dual-system, neuro-symbolic reasoning. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan (eds.), Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id= uyKk_avJ-p4.
- Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2080--2094, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main. 168. URL https://aclanthology.org/2021.naacl-main.168.
- Xinyu Pi, Qian Liu, Bei Chen, Morteza Ziyadi, Zeqi Lin, Yan Gao, Qiang Fu, Jian-Guang Lou, and Weizhu Chen. Reasoning like program executors, 2022.
- Piotr Pi ̨ekos, Mateusz Malinowski, and Henryk Michalewski. Measuring and improving BERT's mathematical abilities by predicting the order of reasoning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), 2021. doi: 10.18653/v1/2021.acl-short.49. URL https://aclanthology.org/2021.acl-short.49.
- Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
- Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446, 2021.
- Qiu Ran, Yankai Lin, Peng Li, Jie Zhou, and Zhiyuan Liu. NumNet: Machine reading comprehension with numerical reasoning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019. doi: 10.18653/v1/D19-1251. URL https://aclanthology. org/D19-1251.
- Subhro Roy and Dan Roth. Solving general arithmetic word problems. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 2015. doi: 10.18653/v1/ D15-1202. URL https://aclanthology.org/D15-1202.
- Jianhao Shen, Yichun Yin, Lin Li, Lifeng Shang, Xin Jiang, Ming Zhang, and Qun Liu. Generate & rank: A multi-task framework for math word problems. In Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 2269--2279, Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. URL https://aclanthology. org/2021.findings-emnlp.195.
- Freda Shi, Daniel Fried, Marjan Ghazvininejad, Luke Zettlemoyer, and Sida I. Wang. Natural language to code translation with execution. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 3533--3546, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology. org/2022.emnlp-main.231.
- Keith E Stanovich and Richard F West. Individual differences in reasoning: Implications for the rationality debate? Behavioral and brain sciences, 23(5):645--665, 2000. URL https: //pubmed.ncbi.nlm.nih.gov/11301544/.
- Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019. URL https://aclanthology. org/N19-1421.
- Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Dara Bahri, Tal Schuster, Steven Zheng, Denny Zhou, Neil Houlsby, and Donald Metzler. Unifying language learning paradigms, 2022. URL https://arxiv.org/abs/2205.05131.
- Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022. URL https://arxiv.org/abs/ 2201.08239.
- Ashwin Vijayakumar, Michael Cogswell, Ramprasaath Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. Diverse beam search for improved description of complex scenes. Proceedings of the AAAI Conference on Artificial Intelligence, 32, Apr. 2018. URL https: //ojs.aaai.org/index.php/AAAI/article/view/12340.
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. Conference on Neural Information Processing Systems (NeurIPS), 2022. URL https://arxiv. org/pdf/2201.11903.
- Sean Welleck, Ilia Kulikov, Jaedeok Kim, Richard Yuanzhe Pang, and Kyunghyun Cho. Consistency of a recurrent language model with respect to incomplete decoding. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 5553--5568, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020. emnlp-main.448. URL https://aclanthology.org/2020.emnlp-main.448.
- Weiwen Xu, Yang Deng, Huihui Zhang, Deng Cai, and Wai Lam. Exploiting reasoning chains for multi-hop science question answering. In Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 1143--1156, Punta Cana, Dominican Republic, November 2021a. Association for Computational Linguistics. URL https://aclanthology.org/2021. findings-emnlp.99.
- Yichong Xu, Chenguang Zhu, Shuohang Wang, Siqi Sun, Hao Cheng, Xiaodong Liu, Jianfeng Gao, Pengcheng He, Michael Zeng, and Xuedong Huang. Human parity on commonsenseqa: Augmenting self-attention with external attention, 2021b. URL https://arxiv.org/abs/ 2112.03254.
- Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2369--2380, Brussels, Belgium, October-November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-1259. URL https://aclanthology.org/D18-1259.
- Xi Ye and Greg Durrett. The unreliability of explanations in few-shot prompting for textual reasoning. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (eds.), Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum? id=Bct2f8fRd8S.
- Wenhao Yu, Chenguang Zhu, Lianhui Qin, Zhihan Zhang, Tong Zhao, and Meng Jiang. Diversifying content generation for commonsense reasoning with mixture of knowledge graph experts. In Findings of Annual Meeting of the Association for Computational Linguistics (ACL), 2022.
- Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate before use: Improving few-shot performance of language models. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research. PMLR, 2021. URL https://proceedings.mlr.press/ v139/zhao21c.html.
A 附录
A.1 补充实验数据
A.1.1 采样策略与参数的鲁棒性
我们在图6中通过对LaMDA-137B模型改变温度采样中的T值和Top-k采样中的k值,对不同采样策略和参数的结果进行了消融实验。结果表明,自洽性对于各种采样策略和参数均具有鲁棒性。
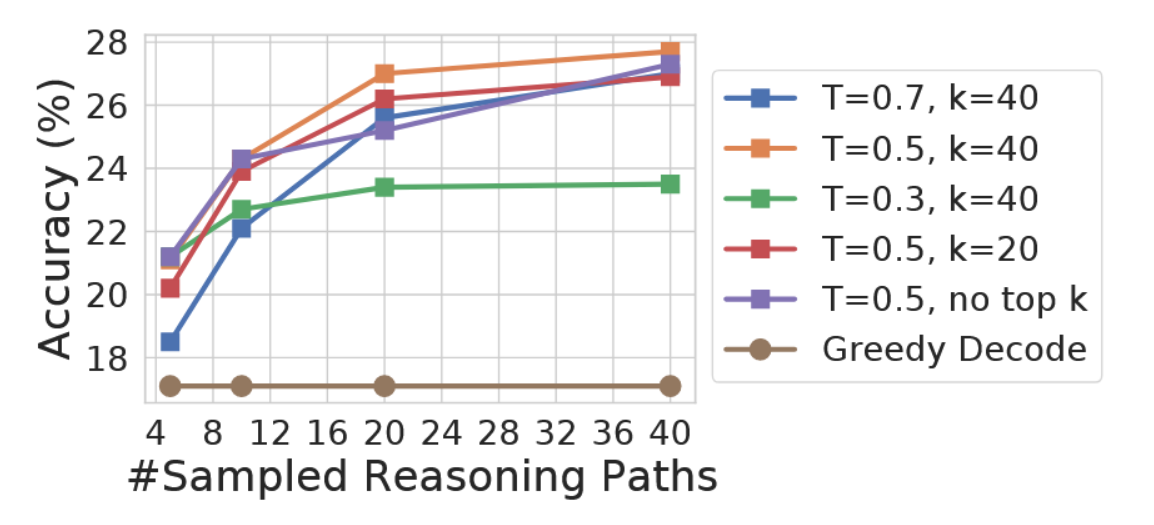
图6:LaMDA-137B模型在GSM8K数据集上的准确率。在不同采样策略与采样参数下,自我一致性方法均有效。
在图7和图8中,我们分别展示了LaMDA-137B和PaLM-540B模型上自洽性与单路径贪婪解码的对比结果。在模型规模扩大已实现高精度的基础上,自洽性方法相较贪婪解码在两种模型上均取得了极为显著的提升。
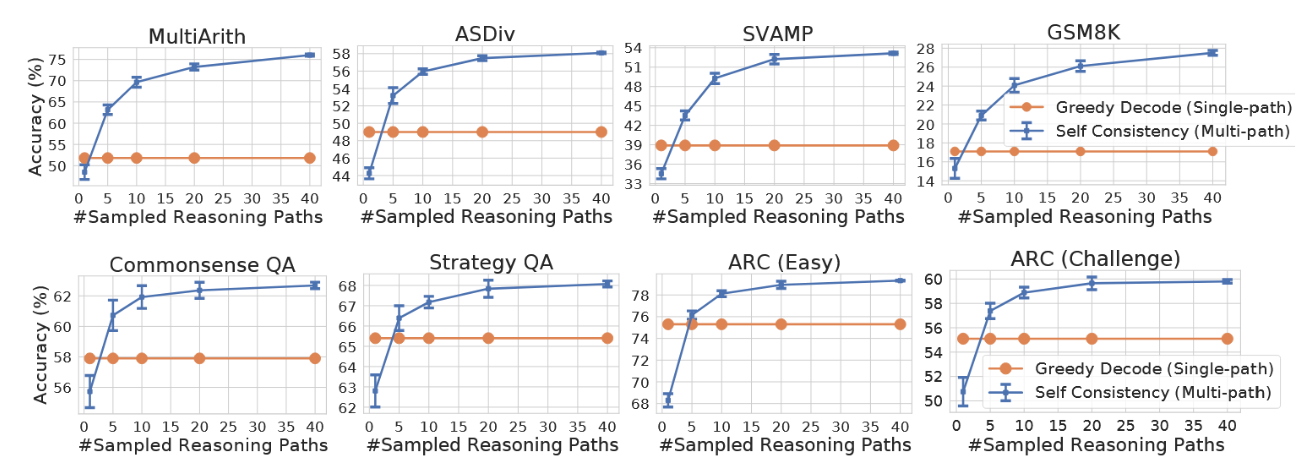
图7:自洽性(蓝色)在各类算术与常识推理任务中均显著提升了准确性,优于LaMDA-137B。采样更多样化的推理路径能持续提高推理准确率。
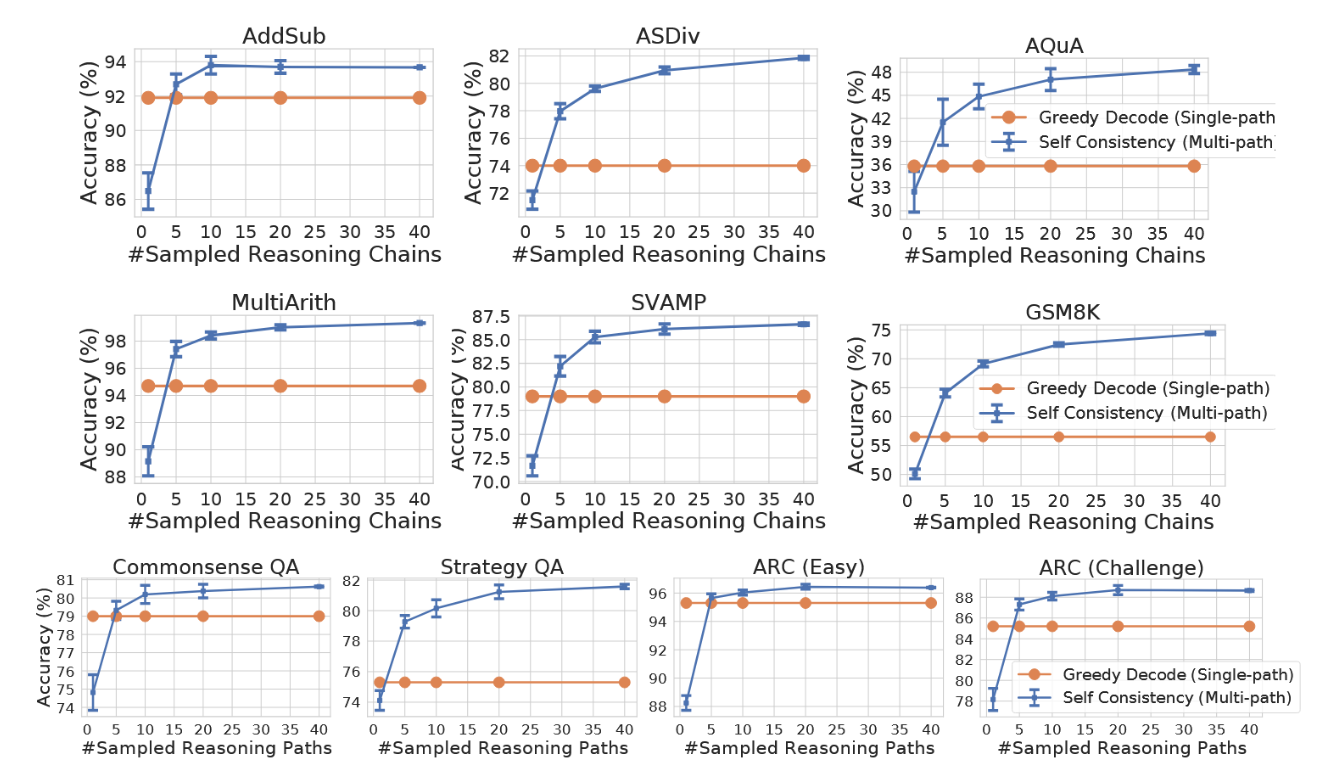
图8:自洽(蓝色)方法在各类算术及常识推理任务中显著提升了PaLM-540B的准确性。采样更多样化的推理路径持续有助于提高推理准确率。
我们在表12中进一步展示了LaMDA-137B模型的额外采样推理路径,在表13中展示了PaLM-540B模型的采样推理路径。我们发现,额外采样的推理路径中的多样性确实有助于模型在聚合后得出更准确的最终答案。
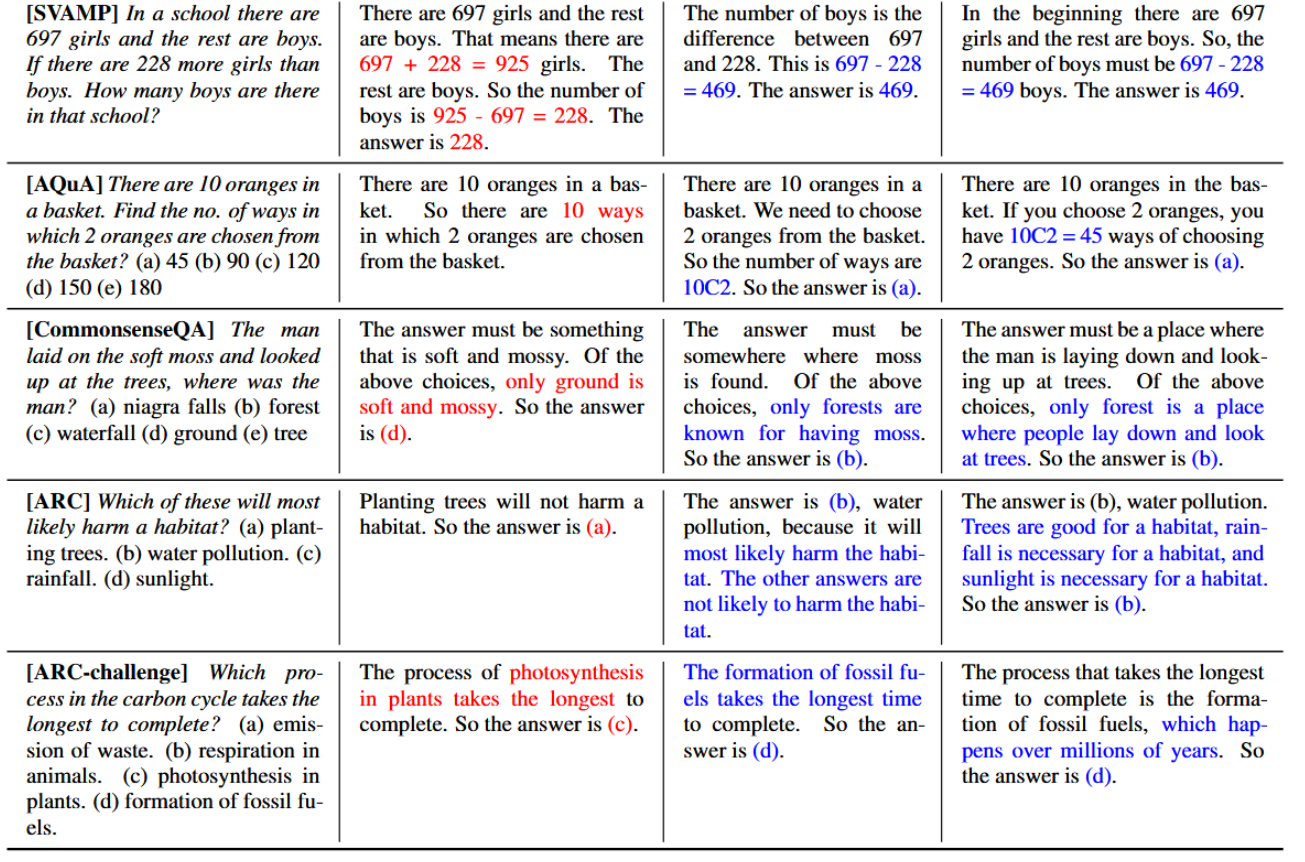
表12:在LaMDA-137B模型上,自洽性有助于修复贪婪解码错误的更多示例。其中展示了两条与事实一致且经采样的推理路径。
A.1.2 对不同提示词集的鲁棒性
在表9中,我们进一步证明自洽性对不同输入提示集具有较强鲁棒性。我们为模型手动编写了三组不同的思维链提示。在所有提示集中,自洽性相较原始思维链方法均能带来稳定提升。

表9:PaLM-540B模型在GSM8K数据集上的准确率。结果表明,自洽方法对于输入中的不同提示具有鲁棒性。
A.1.3 与模型集成方法的比较
此外,我们提供了对多个语言模型输出进行直接集成(ensemble)的结果。如表10所示,通过对3个语言模型的序列进行贪婪解码(greedy decoding),采用多数投票法(10次运行取平均)。请注意,这是一种典型的集成方法(对多个模型的预测结果进行平均),其性能显著低于自洽方法(PaLM-540B的自洽准确率达到74.4%),因为较低能力的模型会拉高能力模型的整体表现。此外,该方法存在两点局限:1)集成需要多个模型,而这并非总能满足,而自洽方法仅需单一模型即可实现"自我集成";2)若其中一个模型明显较弱,反而可能损害最终性能。

表10:多模型集成在GSM8K数据集上的准确率对比。
A.1.4 将自洽性与其他集成策略相结合
自洽性与其他集成策略完全兼容,尽管自洽性所实现的性能增益显著高于其他集成策略(且能够"覆盖"其他集成策略所带来的性能提升)。我们进一步开展了实验,并将结果呈现在表11中(为公平比较,我们使用40组提示或40种提示排列与采用40条路径的自洽性进行对比,所有实验均基于PaLM540B模型)。

表11:自洽性与其他集成策略的结合。
A.2 资源与推理详细说明
对于所有四个语言模型,我们仅执行基于提示的推理。对于UL2模型,我们使用TPU v3(2x2配置,4芯片,8核心)。对于GPT-3模型,实验通过公共API完成。对于LaMDA-137B模型,我们使用TPU v3(8x8配置,64芯片,128核心)。对于PaLM-540B模型,我们使用TPU v4(4x4x12配置,192芯片,384核心)。在UL2和LaMDA-137B上,大多数推理任务(约1,000个示例)耗时1至4小时;在PaLM-540B上则需约2至12小时。部分任务(如常识推理)耗时较长,但每个任务不超过2天。
A.3 完整提示词集
我们在表14和表15中分别列出了用于两个新引入数据集------AQUA-RAT(Ling等人,2017)和AI2推理挑战赛(ARC)(Clark等人,2018)------所使用的全部提示细节,其中本文中的示例思维链由我们手动编写。
表14:AQUA-RAT任务的少样本示例。
Q: 约翰发现15个数的平均值为40。如果每个数增加10,那么这些数的平均值是多少?
答案选项:(a) 50 (b) 45 (c) 65 (d) 78 (e) 64
A: 如果每个数增加10,那么这些数的平均值也增加10。所以新的平均值是50。答案是(a)。
Q: 如果 a / b = 3/4 且 8a + 5b = 22,求a的值。
答案选项:(a) 1/2 (b) 3/2 (c) 5/2 (d) 4/2 (e) 7/2
A: 如果 a / b = 3/4,那么 b = 4a / 3。所以 8a + 5(4a / 3) = 22。这可以简化为 8a + 20a / 3 = 22,即 44a / 3 = 22。所以 a 等于 3/2。答案是(b)。
Q: 一个人以20公里/小时的速度行驶,并在2.5小时后到达目的地,求距离是多少?
答案选项:(a) 53公里 (b) 55公里 (c) 52公里 (d) 60公里 (e) 50公里
A: 这个人行驶的距离应为 20公里/小时 * 2.5小时 = 50公里。答案是(e)。
Q: 输入从1到500的数字需要多少次击键?
答案选项:(a) 1156 (b) 1392 (c) 1480 (d) 1562 (e) 1788
A: 从1到9有9个一位数。从10到99有90个两位数。从100到500有401个三位数。9 + 90(2) + 401(3) = 1392。答案是(b)。表15:ARC简单版/挑战版的小样本示例。
问:乔治想通过快速搓手来暖手。哪种手掌皮肤表面会产生最多的热量?(a)干燥的手掌。(b)湿润的手掌。(c)涂有油的手掌。(d)涂有润肤露的手掌。
答:干燥表面比其他光滑表面在摩擦时更可能产生更大摩擦力,因此干燥的手掌会产生最多的热量。答案是(a)。
问:哪种因素最可能导致人发烧?(a)运动后腿部肌肉放松。(b)血液中的细菌群落。(c)皮肤上的少量病毒颗粒。(d)胃中正在消化的碳水化合物。
答:选项(b),细菌群落最可能导致人发烧。答案是(b)。
问:水分子状态的哪种变化会导致分子排列成固定位置?(a)沸腾。(b)熔化。(c)凝固。(d)蒸发。
答:当水凝固时,分子会排列在固定位置;其他选项中分子仍在运动。答案是(c)。
问:在电路中使用开关时,开关可以(a)导致电荷积聚。(b)增加和降低电压。(c)使电流改变方向。(d)停止和启动电流流动。
答:开关的功能是启动和停止电流的流动。答案是(d)。表16:HotpotQA(闭卷设置)的少样本示例。
问:哪本杂志创刊更早,《亚瑟杂志》还是《女性之先》?
答:《亚瑟杂志》创刊于1844年。《女性之先》创刊于1989年。因此《亚瑟杂志》创刊更早。答案是《亚瑟杂志》。
问:奥拜瑞家族所属的酒店集团总部位于哪座城市?
答:奥拜瑞家族所属的酒店集团名为奥拜瑞集团。奥拜瑞集团的总部位于德里。答案是德里。
问:詹姆斯·亨利·米勒的妻子是哪国人?
答:詹姆斯·亨利·米勒的妻子是琼·米勒。琼·米勒是美国人。答案是美国人。
问:《安布之家》所改编的荷兰-比利时电视剧首播于哪一年?
答:《安布之家》改编自荷兰-比利时电视剧《安布之家》。该剧首播于2006年9月。答案是2006年。此外,我们在表17中列出了所有算术推理任务所使用的精确提示语集合,因为Wei等人(2022)的研究中引入了多组提示语。其中,CommonsenseQA和StrategyQA任务所使用的提示语与Wei等人(2022)原文保持一致。
我们在以下表格中同样提供了常见自然语言处理任务(包括自然语言推理(表18、表19、表20)和闭卷问答任务(表16、表21))所使用的精确提示词。
表17:所有算术推理任务的小样本示例,引自Wei等人(2022)的研究。
问:林地里原本有15棵树。今天林地工人将在林地里植树。结束后,林地里会有21棵树。请问林地工人今天种植了多少棵树?
答:起初有15棵树,之后有21棵树。两者的差值就是他们种植的树的数量。因此,他们一定种植了21 - 15 = 6棵树。答案是6。
问:如果停车场里有3辆车,又来了2辆车,那么停车场里现在有多少辆车?
答:停车场原本有3辆车。又来了2辆。现在一共有3 + 2 = 5辆车。答案是5。
问:莉娅有32块巧克力,她妹妹有42块。如果她们吃掉了35块,那么她们总共还剩多少块巧克力?
答:莉娅有32块巧克力,她妹妹有42块。这意味着原本总共有32 + 42 = 74块巧克力。吃掉了35块。因此她们总共还剩74 - 35 = 39块巧克力。答案是39。
问:贾森有20根棒棒糖。他给了丹尼一些棒棒糖。现在贾森有12根棒棒糖。请问贾森给了丹尼多少根棒棒糖?
答:贾森原本有20根棒棒糖。既然现在他只有12根,那么他一定把剩下的给了丹尼。他给丹尼的棒棒糖数量一定是20 - 12 = 8根。答案是8。
问:肖恩有5个玩具。圣诞节时,他从妈妈和爸爸那里各得到了2个玩具。请问他现在有多少个玩具?
答:他有5个玩具。从妈妈那里得到2个后,他有了5 + 2 = 7个玩具。然后从爸爸那里又得到2个,所以他总共有7 + 2 = 9个玩具。答案是9。
问:服务器机房原本有9台电脑。从周一到周四,每天安装5台电脑。请问现在服务器机房有多少台电脑?
答:从周一到周四共有4天。每天增加5台电脑。这意味着总共增加了4 * 5 = 20台电脑。最初有9台电脑,所以现在有9 + 20 = 29台电脑。答案是29。
问:迈克尔有58个高尔夫球。星期二他丢失了23个高尔夫球。星期三他又丢失了2个。请问星期三结束时他还剩多少个高尔夫球?
答:迈克尔最初有58个球。星期二丢失23个后,他还剩58 - 23 = 35个球。星期三他又丢失了2个,所以现在他有35 - 2 = 33个球。答案是33。
问:奥利维亚有23美元。她买了五个百吉饼,每个3美元。请问她还剩多少钱?
答:她买了5个百吉饼,每个3美元。这意味着她买百吉饼花了5 * 3 = 15美元。她最初有23美元,所以现在还剩下23 - 15 = 8美元。答案是8。表18:ANLI任务的小样本示例。
前提:"从概念上讲,撇脂策略有两个基本维度------产品和地理。"基于此前提,我们能否得出"产品和地理是撇脂策略得以运作的原因"这一假设为真?选项:- 是 - 否 - 无法判断
答:仅基于"撇脂策略有两个基本维度"无法推断出这两个维度是其运作的原因。答案是无法判断。
前提:"我们的其中一名成员将细致地执行您的指示。"基于此前提,我们能否得出"我团队的一名成员将以极高的精度执行您的命令"这一假设为真?选项:- 是 - 否 - 无法判断
答:"one of"等同于"一名成员","carry out"等同于"执行",且"minutely"等同于"极高的精度"。答案是是。
前提:"成人与儿童皆宜的乐趣。"基于此前提,我们能否得出"仅适合儿童的乐趣"这一假设为真?选项:- 是 - 否 - 无法判断
答:"成人与儿童"与"仅儿童"相矛盾。答案是否。
前提:"他转身向弗雷娜微笑。"基于此前提,我们能否得出"他向跟在她母亲身后慢慢行走的弗雷娜微笑"这一假设为真?选项:- 是 - 否 - 无法判断
答:前提并未提及"弗雷娜在行走"。答案是无法判断。
前提:"嗯,你在电视上也看到那个了"基于此前提,我们能否得出"你也能在电视上看到那个"这一假设为真?选项:- 是 - 否 - 无法判断
答:"also"与"as well"含义相同。答案是是。
前提:"我和弗雷娜都与他战斗过,他差点打败了我们。"基于此前提,我们能否得出"弗雷娜和我都从未与他战斗过"这一假设为真?选项:- 是 - 否 - 无法判断
答:"我和弗雷娜都"与"弗雷娜和我都从未"相矛盾。答案是否。表19:e-SNLI的少样本示例(解释部分来源于原始数据集中众包的标注)。
前提:"一个人骑着马跳过一架损坏的飞机。"基于这一前提,我们能否得出假设"一个人正在训练他的马参加比赛"为真?选项:- 是 - 否 - 无法判断 A:这个人不一定在训练他的马。答案是无法判断。
前提:"一个人骑着马跳过一架损坏的飞机。"基于这一前提,我们能否得出假设"一个人在餐厅点煎蛋卷"为真?选项:- 是 - 否 - 无法判断 A:一匹正在跳跃的马不可能在餐厅点餐。答案是否。
前提:"一个人骑着马跳过一架损坏的飞机。"基于这一前提,我们能否得出假设"一个人在户外,骑在马上"为真?选项:- 是 - 否 - 无法判断 A:损坏的飞机在户外。答案是是。
前提:"孩子们对着镜头微笑挥手。"基于这一前提,我们能否得出假设"他们在对父母微笑"为真?选项:- 是 - 否 - 无法判断 A:他们对着镜头微笑挥手并不意味着父母或任何人在镜头后面。答案是无法判断。
前提:"孩子们对着镜头微笑挥手。"基于这一前提,我们能否得出假设"孩子们在皱眉"为真?选项:- 是 - 否 - 无法判断 A:一个人不可能同时微笑和皱眉。答案是否。
前提:"孩子们对着镜头微笑挥手。"基于这一前提,我们能否得出假设"有孩子在场"为真?选项:- 是 - 否 - 无法判断 A:必须有孩子在场才能看到他们微笑挥手。答案是是。表20:RTE任务的小样本示例。
前提:"尚未在伊拉克发现大规模杀伤性武器。"基于此前提,我们能否断定假设"在伊拉克发现了大规模杀伤性武器。"为真?
答:"未发现大规模杀伤性武器"与"发现了大规模杀伤性武器"相矛盾。答案为否。
前提:"教皇约翰·保罗二世去世后,一个原本充满悲伤的场所变成了庆祝之地,罗马天主教信徒聚集在芝加哥市中心,庆贺新教皇本笃十六世的就任。"基于此前提,我们能否断定假设"本笃十六世是罗马天主教的新任领袖。"为真?
答:"新教皇本笃十六世的就任"意味着"本笃十六世是新任领袖"。答案为是。
前提:"一名男子被指控于26年前谋杀一名青少年,随后将出庭受审,该案件是BBC One《罪案观察》节目首次报道的案件。1983年10月30日,16岁的科莱特·阿拉姆在前往诺丁汉郡凯沃斯男友家的途中失踪。其后她的尸体在离家不远的田野中被发现。现年50岁的保罗·斯图尔特·哈钦森被控谋杀,将于稍后在诺丁汉治安法庭出庭。"基于此前提,我们能否断定假设"保罗·斯图尔特·哈钦森被指控用刀刺死一名女孩。"为真?
答:前提并未说明保罗·斯图尔特·哈钦森"用刀刺死"该女孩。答案为否。
前提:"赫赛汀此前已获准用于治疗病情最严重的乳腺癌患者,该公司于周一表示,将与联邦监管机构讨论将该药物处方扩大至更多乳腺癌患者的可能性。"基于此前提,我们能否断定假设"赫赛汀可用于治疗乳腺癌。"为真?
答:"赫赛汀获准用于治疗乳腺癌"意味着"赫赛汀可用于治疗乳腺癌"。答案为是。表21:BoolQ(闭卷设置)的少样本示例。
问:System of a Down乐队有两位主唱吗?
答:System of a Down乐队目前的成员包括Serj Tankian、Daron Malakian、Shavo Odadjian和John Dolmayan。Serj和Daron负责演唱,因此该乐队确实有两位主唱。答案是肯定的。
问:伊朗和阿富汗说同一种语言吗?
答:伊朗和阿富汗都使用印欧语系的波斯语。答案是肯定的。
问:大提琴和低音提琴是同一种乐器吗?
答:大提琴演奏时需坐下,将乐器置于双膝之间,而低音提琴演奏时可站立或坐在高脚凳上。答案是否定的。
问:在埃普瑟姆车站可以使用牡蛎卡吗?
答:埃普瑟姆火车站服务于萨里郡的埃普瑟姆镇,不在伦敦牡蛎卡的使用区域内。答案是否定的。