论文题目 :4D-Animal: Freely Reconstructing Animatable 3D Animals from Videos
论文链接 :https://arxiv.org/pdf/2507.10437
论文代码:https://github.com/zhongshsh/4D-Animal
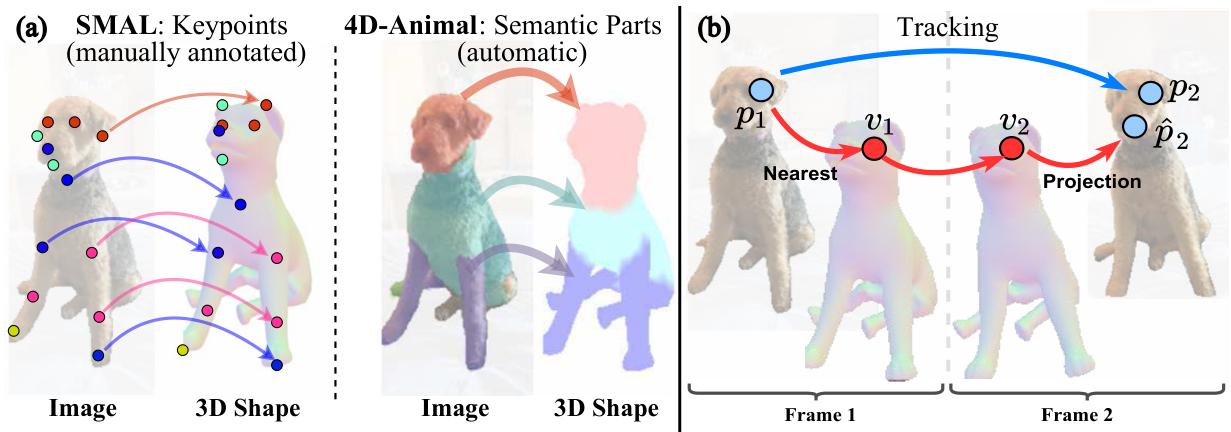
你随手拍一段狗在客厅里跑来跑去的视频:镜头晃、毛发纹理复杂、姿态夸张、还动不动被沙发遮住。你当然希望系统直接吐出一只"能动的 3D 狗"------能换视角、能贴纹理、能做动画。可现实往往是:先别急,请你在 200 帧里逐帧点关键点(左前爪、右后膝、尾巴尖......)。
4D-Animal 这篇论文要解决的就是这件事:能不能不依赖 sparse semantic keypoints(稀疏语义关键点),也能把 monocular video 变成时间连贯的 4D(3D + time)动物资产?它的答案很明确:可以,但要把"对齐的支点"从少量关键点,换成一套来自通用 2D 预训练模型的分层密集线索(hierarchical alignment cues)。代价也同样现实:标注负担下降,pipeline 依赖变重。
先看论文效果直观长什么样:

一、为什么动物 3D 重建不能直接照搬"人体那套"?
人体重建之所以能卷出 SMPL、GHUM 这类强参数模型,一个关键原因是:背后有大量 3D scans 和 motion capture 数据支撑强先验。四足动物看似只是"换个类别",但论文强调困难点在于:3D 动物数据更稀缺,而且解剖差异与姿态变化更难覆盖,导致许多依赖关键点的流程很难规模化。
在 model-based 的动物重建里,大家常用 SMAL(可理解为"四足版 SMPL")做模板:它能缓解遮挡、极端姿态、视角不足带来的歧义。但传统 SMAL fitting 往往默认你有每帧 2D keypoints:没有就人工标注;或者训练 keypoint detector 来替代人工。
问题是:动物 keypoint detector 并不稳。论文在 Introduction 做了一个很具体的核查:用 Animal3D 的人工标注,评估 BARC 的 keypoint detector,发现不同类别表现不一致,腿部等细长结构容易出现系统性偏差;并在可视化中对比了 PartGLEE 的 part segmentation,强调"通用 2D 模型的密集输出"可能更可靠。

于是论文把问题压缩成一句话:我们能否在没有人工稀疏关键点的前提下,从视频做 4D 重建?
二、他们到底造了什么:4D-Animal = "特征到参数的加速器" + "从粗到细的四级对齐"
4D-Animal 的立场很清晰:它仍然是 optimization-based 的 SMAL fitting 路线(不是纯 feed-forward 一步出网格),但把"优化该听谁的"从 keypoints,换成四种密集对齐线索;并加入一个 dense feature network,让拟合更快更稳。
一个好记的类比:把每帧的 3D 拟合想成"把一件可变形的衣服(SMAL 模板)套到狗身上"。传统 keypoints 像是只给你几个衣扣位置;4D-Animal 则是给你从远到近的四种提示:先看轮廓、再看部件、再看像素级对应、最后用时间一致性把整段视频"缝起来"。
2.1 整体框架:先重建 mesh(形状/姿态),再重建 texture(外观)
论文把系统分为两阶段:
- Mesh reconstruction:回归并优化每帧 SMAL 参数;
- Texture reconstruction:在网格上重建纹理,让资产"能看"。
对应的总体结构与监督信号如下图:
2.2 Mesh:用 DINO-ViT 的图像特征,直接"翻译"成 SMAL 参数的初值/引导
对每一帧 (I_t),先用预训练的 DINO-ViT 提取特征 (z_t),再把 (z_t) 与帧索引 embedding (e_t) 拼接,送入一个浅层 MLP(论文称为 feature network),输出 SMAL 的形状参数 (\beta_t) 与姿态参数 (\theta_t)。论文在 SMAL 之外还使用了 limb length scaling、translation、vertex shifts(沿用 D-SMAL 的做法)来提升对真实犬体差异的适配。
这里"密集特征回归"的意义不是炫网络,而是工程上很直接:让优化从一开始就更接近合理解,减少在坏局部最优附近打转,从而提高稳定性并加速收敛(后面效率实验会看到"最高 3×"的速度提升结论)。
2.3 几何对齐:四级 hierarchical alignment,把"稀疏关键点"替换成"可互相兜底的密集信号"
论文的核心替换发生在 loss 上:不用 keypoints,而用四层对齐线索逐步收紧解空间(coarse-to-fine)。
- Object-level(轮廓级) :用 SAM 2 得到 instance mask,让渲染轮廓与 mask 通过 Chamfer distance 对齐,确保全局形状覆盖。
- Part-level(部件级) :用 PartGLEE 得到 head/body/feet/tail 的语义 part mask,在每个部件区域采样点并对齐到 SMAL 对应部件区域,提供"结构语义"。
- Pixel-level(像素级) :用 CSE 得到 dense pixel-to-vertex 对应;因为 CSE 与 SMAL 网格不同,论文用 Zoom-Out 做对齐,再用重投影误差约束细节(尤其四肢方向等)。
- Temporal-level(时间级) :用 BootsTAP 得到跨帧 point tracks,把同一 3D 顶点在相邻帧的投影对齐到轨迹上,强制 motion coherence,避免"每帧一只狗"的抖动。
论文特别强调一个"反直觉但关键"的工程事实:pixel-level 对应很强,但也很脏 ------噪声会把 silhouette 和 motion 带偏;因此必须用 object/part 先稳住大框架,再用 temporal 把整段视频锁成一致运动。
这四级线索在论文里也用示意图讲得很具体:
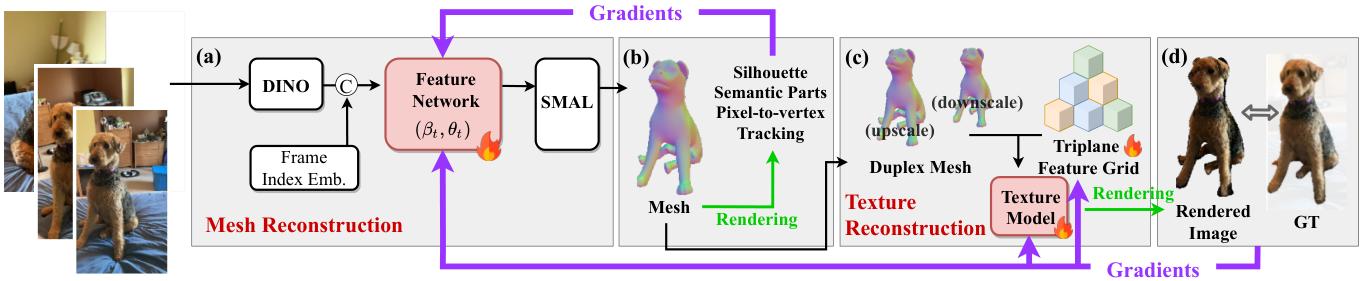
2.4 Texture:SMAL 网格太"粗",所以用 duplex mesh + triplane 提升外观表达力
论文指出:SMAL mesh 只有 3,889 vertices 和 7,774 faces,直接做 vertex color 表达力不足。于是用 SMAL mesh 当 scaffold 构建 duplex mesh ,并用一个可学习的 triplane feature grid + 浅层 MLP 解码颜色;纹理监督用 LPIPS(感知损失)在 mask 区域约束渲染外观贴近原图。
2.5 现实但致命的小环节:camera initialization 先把拟合"救活"
非刚体逐帧拟合里,camera 初始化差会直接崩盘。论文用 part-level 与 pixel-level 的 2D-3D 对应点,跑 EPnP-RANSAC 来初始化/修正相机,使后续优化更稳定;并指出 part(更可靠但粗)与 pixel(更细但易偏)互补。
三、实验设置:评测更像"工程验收",而不是只看一张渲染图
论文主要在 COP3D 上评测:50 段 dog fly-around 视频,每段 200 帧,按 15 帧 train block 与 5 帧 test block 交错划分;分辨率 256×256。指标覆盖几何与外观:IoU、IoUw5;PSNR、PSNRw5;LPIPS。并在 TracksTo4D 的 RGB-Depth 狗视频上,用 depth-based 指标 Abs Rel 与 (\delta) accuracy 验证结构正确性(通过每帧的尺度对齐确保公平比较)。
baseline 包括 model-based(Avatars、BARC、BITE)与 model-free(RAC)。其中 BARC/BITE 只估 pose,不做纹理,因此纹理指标主要对 Avatars 与 RAC 作对比。
四、结果:不靠 keypoints,指标反而更强;而且收敛更快
4.1 主结果(COP3D):4D-Animal 在多数指标上超过对手,包括"最差 5%"稳定性
在 COP3D 的 50 段序列上,论文 Table 1 报告:
- 4D-Animal(不使用 SK) :IoU 0.84 ,IoUw5 0.71 ,PSNR 21.28 ,PSNRw5 18.17 ,LPIPS 0.061。
- Avatars(使用 SK):IoU 0.81,IoUw5 0.66,PSNR 19.91,PSNRw5 17.25,LPIPS 0.073。
- RAC(model-free) :几何最差(论文用定量与定性对比强调 model-based 拟合的重要性)。
此外,论文指出 BARC、BITE 的 temporal consistency 不足会拉低 IoUw5。
把这些数字配上定性图,会更容易理解"差在哪里":

4.2 结构更对(TracksTo4D 深度评测):Abs Rel 明显下降,(\delta) 指标提升
论文 Table 2 报告:相对 Avatars,4D-Animal 的
- Abs Rel 从 0.427 降到 0.279;
- (\delta < 1.25) 从 0.651 提到 0.739((\delta < 1.25^2)、(\delta < 1.25^3) 也更高)。
这意味着它不是"贴图更像",而是 3D 结构也更接近真实深度。
4.3 训练效率:达到目标指标更快,IoU 速度最高可达 3×
论文在 RQ2 给出的结论是:用 COP3D 的 50 段视频对比训练过程,4D-Animal 达到目标指标更快,IoU speedup 最高可达 3×。这点很"新闻化",因为 optimization-based 方法过去常被诟病"慢、难迭代"。
但要把张力讲完整:论文在 Limitations 也明确承认,4D-Animal 集成多个预训练 2D 模型(如 SAM 2、PartGLEE、CSE、BootsTAP、DINO-ViT),训练时会带来额外计算开销与工程复杂度。它把成本从"人工标注"转移到了"工具链依赖与计算"。
五、为什么它能稳:不是某个 loss 神奇,而是"分层互补"让噪声也能被驯服
论文的消融(Table 3)把依赖关系讲得很直白:
- 去掉 object-level 轮廓对齐 (L_{obj}) ,IoU 会掉到 0.51(从"像不像一只狗"的底座直接塌掉)。
- 去掉 纹理损失 (L_{tex}) ,PSNR 会掉到 12.94 ,LPIPS 变差到 0.147(说明"好看"不是顺带来的)。
- 去掉 part/pixel/time 中任意一个,整体都会下降(幅度相对小,但体现每层都在补不同的短板)。
这就是 4D-Animal 的方法论:承认单一密集线索会噪声大、不完美,于是用多层线索互相兜底。你可以把它想成:
- silhouette 负责"别跑出大轮廓";
- parts 负责"别把头尾、四肢语义搞乱";
- pixels 负责"把细节收紧";
- time 负责"别让每帧各画各的"。
在相机初始化上,论文 Table 4 同样体现"互补"------EPnP-RANSAC 更稳,而 part+pixel 的组合最好;单用 pixel 可能因为偏置反而拖累。
六、它的外溢价值:4D-Animal 可能在"补真实 3D 数据缺口"
论文在 RQ4 讨论一个很现实的下游:image-to-3D generation。它观察到许多 3D 生成模型在 Objaverse 等 synthetic 数据上训练后,面对真实动物图像会出现明显 domain gap(例如 LGM 在单视图输入下可能退化为"扁平结构",多视图扩增也难保持一致性);而用 4D-Animal 重建出的 3D 资产去 fine-tune,有机会缩小 sim-to-real gap,让未见过的单张动物图也生成更合理的 3D。
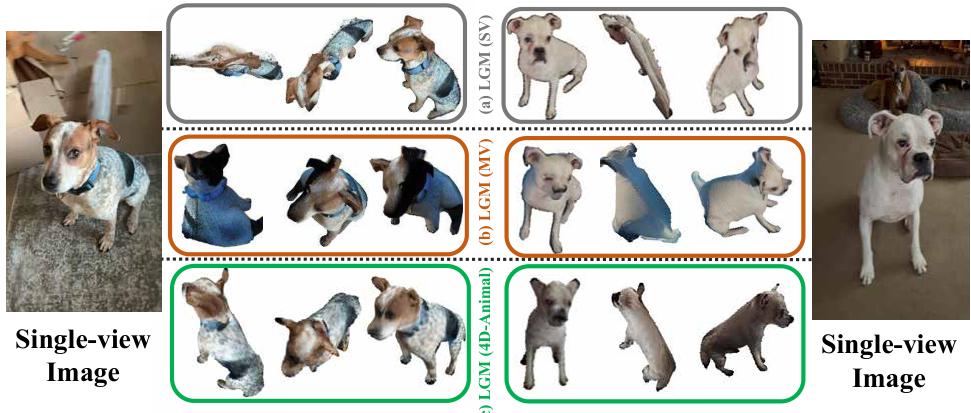
这件事的意义在于:动物领域的硬天花板往往不是"模型不够复杂",而是真实、可用、可规模化的 3D 数据太少。如果"从随手视频提取可动画资产"变得更可行,那么它不仅是一个重建方法,也可能成为真实世界 3D 数据的生产工具。
小结:当我们不再标关键点,下一道瓶颈会在哪里?
4D-Animal 做了一次很清晰的"范式搬迁":为了拟合 SMAL,我们不必把希望押在稀疏 keypoints 上;可以改用 foundation models 提供的密集线索,用分层对齐把噪声压住,并在 COP3D 与 TracksTo4D 上拿到更好的 IoU/IoUw5、纹理指标与深度结构指标,同时把训练迭代提速到最高 3×。
但它也把新的问题摆上台面:当重建系统越来越依赖一串预训练 2D 模型时,我们是在摆脱人工,还是把不确定性外包给更复杂的工具链?论文已经指出 motion blur、遮挡不全、罕见形态(如耳朵形状)会让这些 2D cues 失灵------这意味着下一代方法可能要回答更尖锐的问题:
未来的"稳健性"到底来自更强的 2D cues、端到端的联合优化,还是更强的 3D/时序先验来补足信息缺失?
当你真的想把"家里那段随手拍狗视频"变成可复用、可交易的 3D asset 时,最脆弱的环节会是数据、模型,还是我们对失败场景的容忍边界?