IO 多路转接与多路复用的内核全链路实现 ------ select/poll/epoll 源码级拆解
在前几篇里,我们分别拆开讲了 IO 等待模型的演进、epoll 的数据结构、回调路径与用户态编程范式。这一篇不再单点突破,而是做一次贯穿内核的总复盘:从系统调用入口出发,顺着 VFS(Virtual File System,虚拟文件系统)、file、socket、sock,一路走到 poll 回调、wait queue、eventpoll,再回到用户态事件循环。
你可以把这一篇当成整个系列的"结构体总图"。(本文内核源码截图使用2.6.26版本内核)
它不是讲一个机制,而是讲三个系统调用族是如何共享同一套内核对象,又在不同阶段分叉成不同模型的:
-
select ------ 典型的"多路转接"(一次性参数 + 线性扫描)
-
poll ------ 改良的"多路转接"(数组化 + 更通用事件掩码)
-
epoll ------ 真正的"多路复用"(监听关系持久化 + 事件驱动推送)
本篇的主线非常明确:
一个系统调用一个系统调用讲清楚,它到底调了谁,它依赖哪些结构体,它修改了哪些字段,这些字段如何共同完成语义。
我们会反复问三个问题:
-
这个 API 的"用户语义"是什么?
-
它在内核中映射成了哪些对象?
-
是哪些结构体的哪些字段共同实现了这个行为?
从 fd_set 的三个位图,到 struct pollfd 里的 events / revents,再到 struct epoll_event 的 events / data,这些看似相似的字段背后,其实是三种完全不同的内核组织方式。
!TIP
本篇可以单独阅读,但如果你已经看过前几篇,对 eventpoll、epitem、wait queue 的原理和实现有基本印象,会更容易建立整体图景。
Key Words:VFS、struct file、file_operations、socket、struct sock、poll_table、wait_queue(等待队列)、fd_set、pollfd、eventpoll、epitem、多路转接、多路复用
文章目录
-
- [IO 多路转接与多路复用的内核全链路实现 ------ select/poll/epoll 源码级拆解](#IO 多路转接与多路复用的内核全链路实现 —— select/poll/epoll 源码级拆解)
- 0.总结一条执行链路
- [1. 全局对象与调用链总览](#1. 全局对象与调用链总览)
-
- [1.1 "一切皆文件"落地到 socket 的历史原因](#1.1 “一切皆文件”落地到 socket 的历史原因)
- [1.2 内核对象地图](#1.2 内核对象地图)
- [1.3 核心论点一:三种机制共享同一个地基 ------ fd 只是索引,真正的等待绑定在 file/sock 背后的 wait queue](#1.3 核心论点一:三种机制共享同一个地基 —— fd 只是索引,真正的等待绑定在 file/sock 背后的 wait queue)
-
- [1.3.1 fd → file:fs/file.c](#1.3.1 fd → file:fs/file.c)
- [1.3.2 file 是 IO 等待的第一层载体](#1.3.2 file 是 IO 等待的第一层载体)
- [1.3.3 socket file 的特殊跳转:net/socket.c](#1.3.3 socket file 的特殊跳转:net/socket.c)
- [1.4 核心论点二:"就绪"由 file_operations->poll 定义,是一个"检查 + 注册回调"的二段式契约](#1.4 核心论点二:“就绪”由 file_operations->poll 定义,是一个“检查 + 注册回调”的二段式契约)
-
- [1.4.1 poll 语义的真正定义:fs/select.c](#1.4.1 poll 语义的真正定义:fs/select.c)
- [1.5 核心论点三:多路"转接" vs 多路"复用"的生命周期差异](#1.5 核心论点三:多路“转接” vs 多路“复用”的生命周期差异)
-
- [1.5.1 多路转接(select/poll)](#1.5.1 多路转接(select/poll))
- [1.5.2 多路复用(epoll)](#1.5.2 多路复用(epoll))
- 下一节预告
- [2. poll 语义的"二段式契约"(检查 + 注册等待)](#2. poll 语义的“二段式契约”(检查 + 注册等待))
-
- [2.1 为什么 poll 必须同时做"检查"和"注册等待"](#2.1 为什么 poll 必须同时做“检查”和“注册等待”)
- [2.2 核心论点一:`.poll` 是所有多路机制共享的真正接口](#2.2 核心论点一:
.poll是所有多路机制共享的真正接口) - [2.3 poll_table 的本质:一个"怎么挂队列"的函数指针](#2.3 poll_table 的本质:一个“怎么挂队列”的函数指针)
- [2.4 核心论点二:select/poll 与 epoll 的差异,全部体现在 _qproc 指向谁](#2.4 核心论点二:select/poll 与 epoll 的差异,全部体现在 _qproc 指向谁)
-
- [2.4.1 select / poll:把 current 挂进 wait queue](#2.4.1 select / poll:把 current 挂进 wait queue)
- [2.4.2 epoll:挂的不是进程,而是回调](#2.4.2 epoll:挂的不是进程,而是回调)
- [2.5 readiness mask:不是布尔值,而是一组"机会位"](#2.5 readiness mask:不是布尔值,而是一组“机会位”)
- [2.6 架构细节拆解(字段级)](#2.6 架构细节拆解(字段级))
-
- [2.6.1 file_operations::poll](#2.6.1 file_operations::poll)
- [2.6.2 struct sock::sk_sleep](#2.6.2 struct sock::sk_sleep)
- [2.6.3 poll_wait 的角色(fs/select.c)](#2.6.3 poll_wait 的角色(fs/select.c))
- [2.7 实战视角:用户态循环的真正含义](#2.7 实战视角:用户态循环的真正含义)
- 下一节预告
- [3. select / pselect6 的内核调用链](#3. select / pselect6 的内核调用链)
-
- [3.1 用户态输入:3 个 fd_set 位图](#3.1 用户态输入:3 个 fd_set 位图)
- [3.2 核心论点一:select 是典型"多路转接器"------临时路由表 + 全集线性扫描](#3.2 核心论点一:select 是典型“多路转接器”——临时路由表 + 全集线性扫描)
- [3.3 核心论点二:select 的核心成本不是等待,而是 copy + 扫描 + 回写](#3.3 核心论点二:select 的核心成本不是等待,而是 copy + 扫描 + 回写)
- [3.4 核心论点三:select 的等待挂载靠 __pollwait,但监听不持久导致唤醒后仍要重新扫描确认](#3.4 核心论点三:select 的等待挂载靠 __pollwait,但监听不持久导致唤醒后仍要重新扫描确认)
-
- [3.4.1 `sys_select / sys_pselect6`:系统调用入口做了什么(不重要)](#3.4.1
sys_select / sys_pselect6:系统调用入口做了什么(不重要)) - [3.4.2 `do_select`:主循环如何组织对象操作](#3.4.2
do_select:主循环如何组织对象操作) - [3.4.3 `__pollwait`:谁挂队列,挂到哪里](#3.4.3
__pollwait:谁挂队列,挂到哪里) - [3.5 fd_set 的逐位扫描:为什么它天生就是 O(n)](#3.5 fd_set 的逐位扫描:为什么它天生就是 O(n))
- [3.6 实战总结:select 什么时候还能用、坑在哪里](#3.6 实战总结:select 什么时候还能用、坑在哪里)
- [3.4.1 `sys_select / sys_pselect6`:系统调用入口做了什么(不重要)](#3.4.1
- 下一节预告
- [4. poll / ppoll 的内核调用链与 pollfd 语义](#4. poll / ppoll 的内核调用链与 pollfd 语义)
- [4.1 System V 风格接口的演进动机](#4.1 System V 风格接口的演进动机)
- [4.2 核心论点一:poll 解决了 FD_SETSIZE,但没解决 O(n)](#4.2 核心论点一:poll 解决了 FD_SETSIZE,但没解决 O(n))
- [4.3 核心论点二:events vs revents ------ 订阅语义与上报语义必须分清](#4.3 核心论点二:events vs revents —— 订阅语义与上报语义必须分清)
-
- [4.3.1 events:我关心什么](#4.3.1 events:我关心什么)
- [4.3.2 revents:内核告诉你发生了什么](#4.3.2 revents:内核告诉你发生了什么)
- [4.4 核心论点三:do_poll 的真实工作------拿 mask、做匹配、注册等待](#4.4 核心论点三:do_poll 的真实工作——拿 mask、做匹配、注册等待)
-
- [4.4.1 系统调用入口:sys_poll / sys_ppoll](#4.4.1 系统调用入口:sys_poll / sys_ppoll)
- [4.4.2 do_poll:主遍历循环(fs/select.c)](#4.4.2 do_poll:主遍历循环(fs/select.c))
-
- 第一步:初始化等待容器
- [第二步:遍历 pollfd 数组](#第二步:遍历 pollfd 数组)
- [第三步:mask → revents 的匹配与回填](#第三步:mask → revents 的匹配与回填)
- [4.4.3 poll_wait 与 __pollwait:谁被挂进 wait queue](#4.4.3 poll_wait 与 __pollwait:谁被挂进 wait queue)
- [4.5 pollfd 语义逐字段拆解](#4.5 pollfd 语义逐字段拆解)
- [4.6 实战总结:poll 的位置在哪里](#4.6 实战总结:poll 的位置在哪里)
- 下一节预告
- [5. epoll_create1 与 eventpoll 对象](#5. epoll_create1 与 eventpoll 对象)
- [5.1 核心论点一:epoll 的"复用"来自 eventpoll 这个持久内核对象](#5.1 核心论点一:epoll 的“复用”来自 eventpoll 这个持久内核对象)
- [5.2 核心论点二:epoll fd 不是被监听的 fd,而是"监听器对象"的句柄](#5.2 核心论点二:epoll fd 不是被监听的 fd,而是“监听器对象”的句柄)
- [5.3 核心论点三:eventpoll 把"管理结构"和"运行时结构"分离](#5.3 核心论点三:eventpoll 把“管理结构”和“运行时结构”分离)
- [5.4 架构细节:sys_epoll_create1 → do_epoll_create → file + eventpoll](#5.4 架构细节:sys_epoll_create1 → do_epoll_create → file + eventpoll)
-
- [5.4.1 函数链与文件位置](#5.4.1 函数链与文件位置)
- [5.4.2 eventpoll 字段职责图](#5.4.2 eventpoll 字段职责图)
- [5.5 epoll file 的承载关系:private_data 的意义](#5.5 epoll file 的承载关系:private_data 的意义)
- [5.6 实战范式:epoll 实例为何总与 EventLoop 绑定](#5.6 实战范式:epoll 实例为何总与 EventLoop 绑定)
- 下一节预告
- [6. epoll_ctl(ADD / MOD / DEL)的内核实现](#6. epoll_ctl(ADD / MOD / DEL)的内核实现)
- [6.1 核心论点一:epoll_ctl 的本质,是把一次性监听请求固化为 epitem](#6.1 核心论点一:epoll_ctl 的本质,是把一次性监听请求固化为 epitem)
-
- [6.1.1 epitem 为什么必须存在](#6.1.1 epitem 为什么必须存在)
- [6.1.2 epitem 与 pollfd 的生命周期对比](#6.1.2 epitem 与 pollfd 的生命周期对比)
- [6.2 epoll_ctl 的整体调用框架](#6.2 epoll_ctl 的整体调用框架)
- [6.3 核心论点二:ADD ------ 创建 epitem,并把回调挂进目标 wait queue](#6.3 核心论点二:ADD —— 创建 epitem,并把回调挂进目标 wait queue)
-
- [6.3.1 EPOLL_CTL_ADD:ep_insert 的职责拆解](#6.3.1 EPOLL_CTL_ADD:ep_insert 的职责拆解)
- [6.3.2 epitem 的关键字段职责(逐字段)](#6.3.2 epitem 的关键字段职责(逐字段))
- [6.3.3 epoll 中的 poll_table 分歧点:不再是 __pollwait](#6.3.3 epoll 中的 poll_table 分歧点:不再是 __pollwait)
- [6.3.4 就绪时的推送链路(ADD 阶段已铺好路)](#6.3.4 就绪时的推送链路(ADD 阶段已铺好路))
- [6.4 核心论点三:事件驱动发生在回调,而不是 epoll_wait](#6.4 核心论点三:事件驱动发生在回调,而不是 epoll_wait)
-
- [6.4.1 回调函数:ep_poll_callback](#6.4.1 回调函数:ep_poll_callback)
- [6.4.2 epoll_wait:只消费 rdllist](#6.4.2 epoll_wait:只消费 rdllist)
- [6.5 MOD / DEL:对 epitem 的修改与销毁](#6.5 MOD / DEL:对 epitem 的修改与销毁)
-
- [6.5.1 EPOLL_CTL_MOD:ep_modify](#6.5.1 EPOLL_CTL_MOD:ep_modify)
- [6.5.2 EPOLL_CTL_DEL:ep_remove](#6.5.2 EPOLL_CTL_DEL:ep_remove)
- [6.6 核心论点四:epoll_ctl 管"关系",epoll_wait 管"交付"实现](#6.6 核心论点四:epoll_ctl 管“关系”,epoll_wait 管“交付”实现)
- [6.7 常见范式](#6.7 常见范式)
-
- [muduo(典型 Reactor)](#muduo(典型 Reactor))
- nginx(高吞吐)
- [6.8 结语:从"等"到"搬"](#6.8 结语:从“等”到“搬”)
- [THE END](#THE END)
接下来我会按板块展开:
-
多路转接(select / poll)------ 参数模型与线性扫描的完整调用链
-
多路复用(epoll)------ 监听关系持久化与回调驱动模型
-
三者统一视角 ------ poll 回调函数对象如何成为整个 IO 模型的枢纽
0.总结一条执行链路
这一章先跑一遍链路对整体流程有个宏观的认识。(以网络IO为例)
在 Linux 机器上使用网卡设备,网卡会给Linux注册一个驱动,在网络协议栈中 网卡是 MAC帧协议 一个网卡有一个MAC地址。网卡是底层PCIe设备,网卡可以通过DMA直接写内存,网卡接收到数据(MAC帧)会触发CPU上对应针脚产生硬件中断,网卡上层是网卡驱动,CPU收到硬件中断后就会调用对应驱动处理。在 Linux内核的内存 中有 struct socket 这是套接字文件对象,里面有用于输入输出的套接字缓冲区等等字段涉及tcp(inet_connection_sock,tcp_sock) udp(udp_sock) IP协议都需要在Linux网络模块中解决。由于本篇主要讲 IO模型 而非 Linux net 就不详细展开了设计是解耦的,所以不影响我们理解 IO。
你写的epoll程序
- epoll_create 本质是让内核创建一个
struct file *filp其 filp->private_data 设为一个 struct eventpoll 内核结构体,这个结构体内部有两个容器 rbr(红黑树根节点,键值为fd或者ffd),和rdllist(就绪链表),两者的节点数据结构都为struct epitem。两个容器初始化为空,rbr表示我检视哪些fd的哪些事件,rdllist表示当前的检视事件中哪些就绪了(哪些报错了)。 - 下一步进入 epoll_ctl 当传入宏 EPOLL_CTL_ADD 时,整个调用到ep_insert 内部执行包括但不限于:
- 红黑树系列helper函数内核会插入新 epitem(包含 哪个 fd 和哪些事件 event) 到 rbr (且红黑树自动去重)表示我关心这个 fd 的 event 事件。
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc)这个 inline 函数 只执行注册回调pt->qproc = ep_ptable_queue_proc;qproc关心的是我要怎么把自己挂到等待队列上以及被唤醒时使用什么函数将我唤醒,这个回调的作用很重要 select/poll 都有这个回调,但是设置的具体回调和epoll不一样。- 还在 ep_insert() 里,设置好ep_ptable_queue_proc后会调用关心的fd的file的f_op->poll函数,poll中会调 poll_wait。 poll_wait 是一个薄封装只要 pt->qproc not null就调刚刚设置的回调qproc。epoll 的 qproc 逻辑是在我们关注的 fd的等待队列里注册一个eppoll_entry 里面包含 wait_queue_t 和 void *base base 指向 epitem 而 wait_queue_t
*entry里的 func 指向ep_poll_callback。当我们关心的 fd 事件到来,会被 wake_up() :逻辑是遍历 entry 调用 entry->func也就是ep_poll_callback。这个ep_poll_callback做什么呢?1. 通过 entry 找到 epitem 2. 把 epitem 插到就绪链表 rdllist(刚刚也说了这个队列的节点类型就是 epitem)。就完成了,自动放入等待队列。 - 如果是调用 select()/poll() 的时候会进入 do_select/do_poll 内部都会设置poll_table 的 qproc 为 __pollwait(), 他就是设置一个 entry 里面字段 private 指向 current,func 指向 default_wake_function 这里就仅仅只是传入了调用select的current,还在 do_select/do_poll 里,设置好qproc后就会调用然后如果我们关心的 fd 有数据到了就会用 default_wake_function 来 wake_up 我们先前传过去的 current。被叫醒后我们还在 do_select 循环里(因为之前调用select会立即遍历一遍所有fd发现没有任何就绪,也不能忙等就调用schedule阻塞了所以回来的时候执行流还在do_select),此时被wake_up相当于告诉我当前可能你有机会碰到就绪的了,你就扫一遍吧。
- epoll_wait 就很简单了,安全地把 rdllist 就绪的事件返回。
1. 全局对象与调用链总览
这一章不谈 API,不谈参数,不谈 fd_set 或 epoll_event。
先把整条链路画清楚:一个 fd,从进程视角一路走进内核深处,到底落在什么对象上;IO 等待到底挂在哪里;谁负责唤醒谁。
1.1 "一切皆文件"落地到 socket 的历史原因
Unix 没有为"网络"单独发明一套对象体系,而是把 socket 强行塞进 VFS 体系。
这意味着:
-
进程看到的只是一个整数 fd
-
内核看到的是一个
struct file -
网络子系统看到的是一个
struct sock
socket 不是特殊存在,它只是 VFS 世界里的一种"特殊文件"。
这一决策,让 select/poll/epoll 可以统一在 file_operations 这一层之上实现,而不需要为每种 IO 类型重写等待逻辑。
1.2 内核对象地图
先给你一张"脑中必须常驻"的对象图:
c
// 进程级
task_struct
└── files_struct
└── fdtable
└── fd[fd] ---> struct file *
// VFS 层
struct file
├── f_op ---> struct file_operations
├── private_data ---> (socket 情况下指向 struct socket)
├── f_flags
└── f_inode
// socket 情况
struct socket
└── sk ---> struct sock
struct sock
└── sk_sleep ---> wait_queue_head_t再压一行你必须背熟的跳转链路:
c
fd
-> current->files->fdt->fd[fd]
-> struct file
-> file->f_op->poll(...)
-> (socket fd) file->private_data
-> struct socket
-> socket->sk
-> struct sock
-> sk->sk_sleep (wait queue 锚点)!TIP
如果你能闭眼默写这条链路,后面 select/poll/epoll 的所有实现都会变得自然。
1.3 核心论点一:三种机制共享同一个地基 ------ fd 只是索引,真正的等待绑定在 file/sock 背后的 wait queue
select、poll、epoll 的分歧,不在"怎么找 file",而在"怎么组织集合"。
但它们有一个完全共享的地基:
fd 只是索引;真正承载 IO 状态与等待语义的,是 file 背后的对象与它的 wait queue。
来看对象跳转链路。
1.3.1 fd → file:fs/file.c
系统调用拿到一个 fd 后,第一步一定是:
c
struct file *file = fget(fd);fget() 定义在 fs/file.c,它做的事极其简单却极其重要:
-
从
current->files拿到files_struct -
通过
files_struct->fdt->fd[fd]取出struct file* -
增加引用计数
关键字段:
c
struct files_struct {
struct fdtable __rcu *fdt;
...
};
struct fdtable {
struct file __rcu **fd;
...
};!NOTE
到这里为止,select/poll/epoll 完全一致。差异还没开始。
1.3.2 file 是 IO 等待的第一层载体
struct file 定义在 include/linux/fs.h:
c
struct file {
const struct file_operations *f_op;
void *private_data;
fmode_t f_mode;
unsigned int f_flags;
...
};其中:
-
f_op决定了"这个文件能做什么" -
.poll是 IO 等待的统一入口 -
private_data是具体子系统的桥梁(socket/pipe/tty)
关键点来了:
select/poll/epoll 并不直接操作 socket、pipe 或块设备,它们只调用 file->f_op->poll。
!TIP struct file_operations
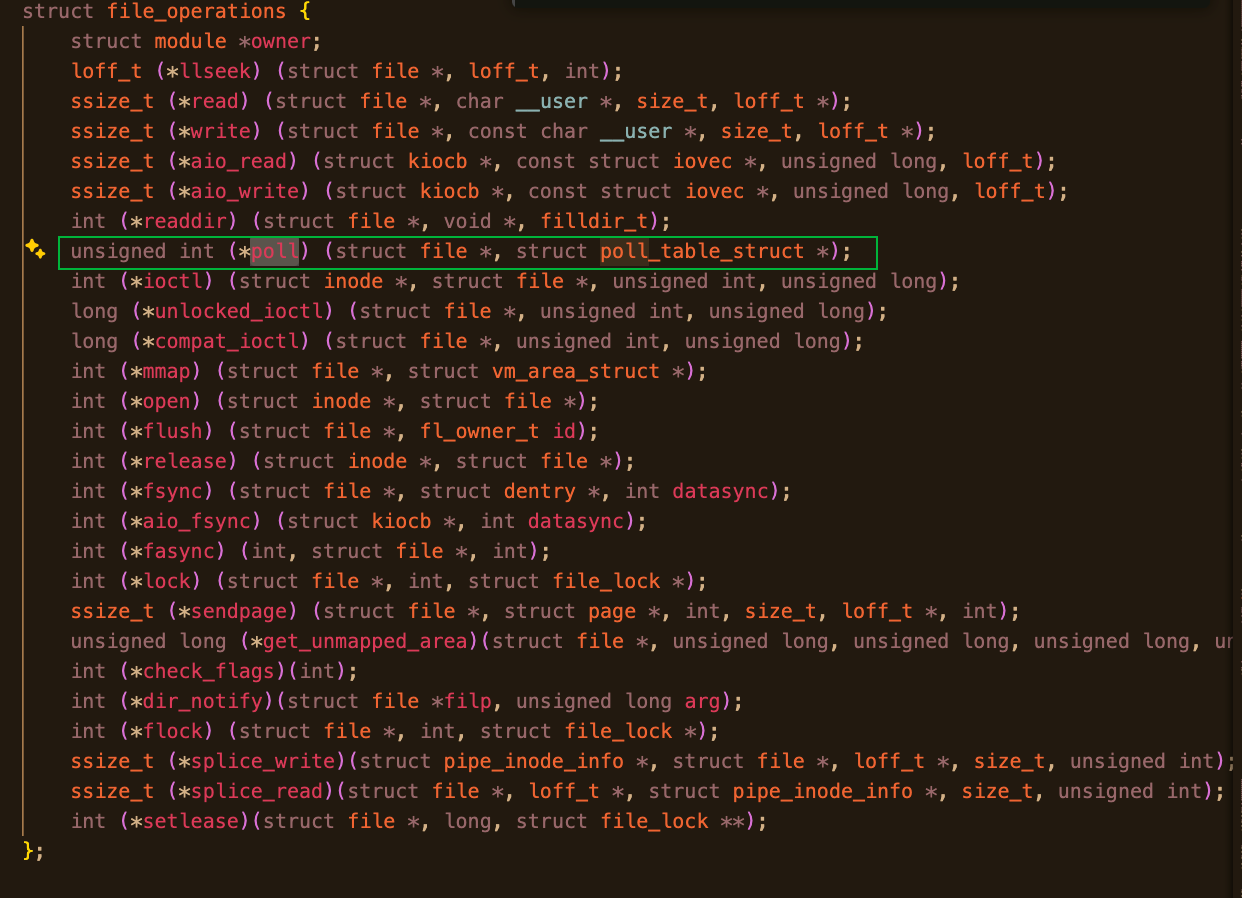
1.3.3 socket file 的特殊跳转:net/socket.c
socket fd 的 file->private_data 指向:
c
struct socket {
struct sock *sk;
...
};而真正的网络状态、接收队列、发送队列,都在:
c
struct sock {
wait_queue_head_t *sk_sleep;
...
};sk_sleep 是网络 IO 等待的锚点。
当 TCP 收到数据时,最终会:
c
wake_up_interruptible_poll(&sk->sk_sleep, EPOLLIN);!IMPORTANT
真正被唤醒的,不是"fd",不是"file",而是挂在
sk_sleep上的 wait queue entry。
到这里你应该能看到核心地基:
-
select/poll/epoll 都是"上层调度器"
-
真正的 IO 状态变化发生在 sock
-
真正的唤醒锚点是 wait_queue_head_t
1.4 核心论点二:"就绪"由 file_operations->poll 定义,是一个"检查 + 注册回调"的二段式契约
"readiness(就绪)"不是 epoll 发明的。
它由 file_operations->poll 定义。
1.4.1 poll 语义的真正定义:fs/select.c
在 fs/select.c 中,内核提供了 select/poll 的公共框架。
它会对每个 file 调用:
c
mask = file->f_op->poll(file, poll_table *);这个调用有两个目的:
-
立即检查当前是否就绪(返回 mask)
-
如果传入了 poll_table,则注册等待队列(通过 poll_wait)
这就是所谓的"二段式契约"。
第一段:状态检查
返回值是 EPOLLIN / EPOLLOUT / POLLERR 等掩码。
第二段:注册等待
如果当前不可用,就把调用者挂到 wait queue 上。
在 socket 的 poll 实现中,会看到:
c
poll_wait(file, &sk->sk_sleep, wait);poll_wait() 的核心动作:
-
调用
poll_table->qproc回调 -
由 qproc 决定"往 wait queue 上挂什么"
!TIP In poll.h
!NOTE
select/poll 用 qproc 把 current 进程挂进去
epoll 用 qproc 把 ep_poll_callback 挂进去
这就是后面分歧的根源

1.5 核心论点三:多路"转接" vs 多路"复用"的生命周期差异
现在开始真正的分歧。
1.5.1 多路转接(select/poll)
特点:
-
每次系统调用
-
临时构造集合(fd_set / pollfd)
-
线性扫描
-
poll_table 生命周期仅限本次调用
-
等待队列注册完,系统调用结束即丢弃
fd_set 是栈上位图;
struct pollfd 是用户态数组;
它们的生命周期极短。
内核不会保存"监听关系"。
1.5.2 多路复用(epoll)
特点:
-
epoll_create创建持久对象 -
epoll_ctl建立长期监听关系 -
epoll_wait只消费 ready list -
epitem 生命周期跨越多次系统调用
epitem 是真正的监听关系实体。
select/poll 的集合:
- 生命周期 = 一次系统调用
epoll 的集合:
- 生命周期 = epoll 实例的整个生命周期
这意味着:
-
select/poll 每次都重新组织集合并扫描
-
epoll 把扫描成本前移到"建立监听关系"阶段
-
运行时只处理"真正发生变化的 fd"
!IMPORTANT
转接 = 每次临时转发
复用 = 把关系固化,重复利用
!Supplement
词源考古
select:挑选
poll:轮询
epoll:event poll(事件轮询)
名字本身已经暗示:select/poll 是"我去问",epoll 是"事件驱动"。
下一节预告
下一节开始逐函数拆解,但必须先讲清最核心的"通用契约":
f_op->poll 与 poll_table 回调注册到底怎么工作。
如果这一层没打通,select/poll/epoll 后面的实现都会断链。
2. poll 语义的"二段式契约"(检查 + 注册等待)
VFS 层(struct file_operations->poll) × select/poll/epoll 公共框架
这一章是整个 IO 多路机制里最关键的一环 。
如果你没真正理解 .poll + poll_table 这一套契约,后面 select/poll/epoll 的所有差异,都会变成"背 API 细节"。
先给一句结论压轴,再慢慢拆:
select / poll / epoll 共享的真正接口不是系统调用,而是
file_operations->poll定义的一套"检查 + 注册等待"的二段式语义。
2.1 为什么 poll 必须同时做"检查"和"注册等待"
这不是设计洁癖,而是竞态条件逼出来的必然结果。
先假设一种"天真的设计":
-
内核先检查 fd 是否就绪
-
如果未就绪,就把当前任务挂到 wait queue
-
然后睡眠等待唤醒
听起来没毛病,但只要把时间线拉开,就会发现一个致命 race:
CPU 0: 检查 fd -> 发现当前不可读
CPU 1: 网络包到达 -> socket 变为可读 -> wake_up(sk_sleep)
CPU 0: 把当前任务挂进 wait queue -> 睡眠结果:事件已经发生,唤醒已经错过,进程却睡死了。
这个问题和条件变量里"必须 while 循环检查条件"的原因是同源的。
解决方法只有一个:检查状态 + 注册等待,必须在一个不可分割的语义块中完成。
这正是 .poll 回调的设计初衷。
2.2 核心论点一:.poll 是所有多路机制共享的真正接口
在内核中,不管你用的是:
-
select -
poll -
epoll
最终都会走到同一个地方:
c
file->f_op->poll(file, poll_table *);struct file_operations 里的 .poll,定义了**"这个 file 的就绪语义"**。
它不是"问一下状态",而是一个二段式契约:
-
立即检查当前状态,返回 readiness mask
-
如果状态未满足,通过 poll_table 把等待者挂进正确的 wait queue
换句话说:
.poll 的调用者,并不关心你怎么实现;
它只要求你要么告诉我现在就能干活,要么保证将来状态变化时我一定能被叫醒。
!IMPORTANT
readiness 从来不是 epoll 的专利,而是由
file_operations->poll定义的通用语义。
2.3 poll_table 的本质:一个"怎么挂队列"的函数指针
很多人第一次看 struct poll_table_struct,会被名字骗,以为它是个"表"。
实际上它的核心只有一个字段:
c
typedef struct poll_table_struct {
poll_queue_proc _qproc;
...
} poll_table;poll_queue_proc 的原型在 include/linux/poll.h:
c
typedef void (*poll_queue_proc)(struct file *file,
wait_queue_head_t *wq,
struct poll_table_struct *pt);实际2.6.26源码长这样:
!TIP poll_table_struct 和 回调函数类型 源码
它只回答一个问题:
当某个 file 的 poll 实现调用 poll_wait(file, &wq, pt) 时,我到底该怎么把"等待者"挂到这个 wait_queue 上?
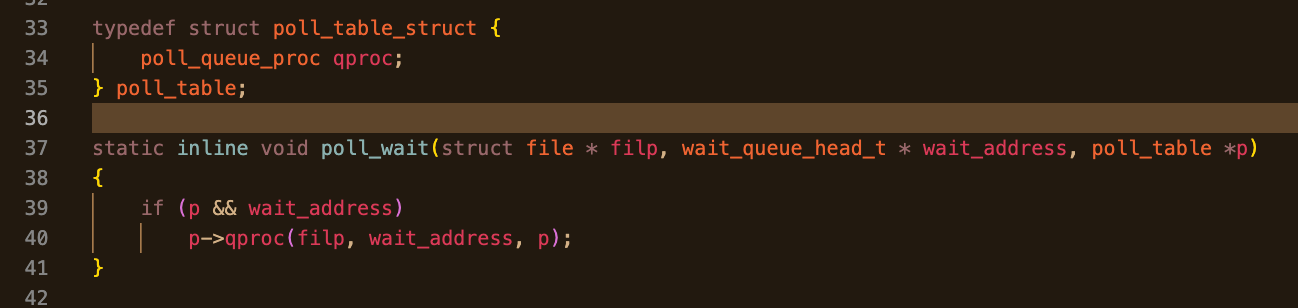

这就是 select/poll 和 epoll 的分歧点。
2.4 核心论点二:select/poll 与 epoll 的差异,全部体现在 _qproc 指向谁
2.4.1 select / poll:把 current 挂进 wait queue
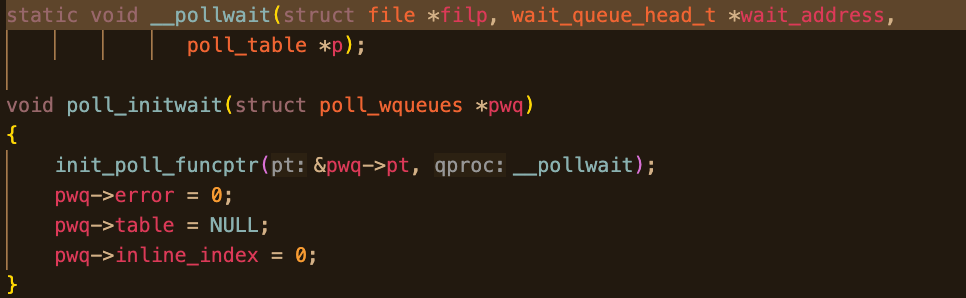
在 fs/select.c 中,select/poll 使用的 _qproc 是 __pollwait。而epoll的回调则是自己定义的一个函数。
简化后select\poll的回调的逻辑可以理解为:
c
static void __pollwait(struct file *file,
wait_queue_head_t *wq,
poll_table *pt)
{
add_wait_queue(wq, ¤t->poll_wait);
}!TIP
fs/select.c
linux/poll.h
__pollwait的定义 (fs/select.c)

也就是说:
-
谁在调用 select/poll?
-
就把 当前进程 挂进 file 对应的 wait queue
-
等待 wake_up 发生,再回来继续扫描
这是典型的"多路转接"模型:
睡的是进程,醒来之后再自己去判断谁就绪了。
2.4.2 epoll:挂的不是进程,而是回调
epoll 完全不一样。
在 fs/eventpoll.c 中,epoll 会构造一个专用的 poll_table,其 _qproc 指向:
c
ep_ptable_queue_proc这个函数不会把 current 挂进去,而是:
-
分配一个
struct eppoll_entry -
设置
wait_queue_entry.func = ep_poll_callback -
把这个 entry 挂进目标 file 的 wait queue
结果是:
-
epoll 把"当事件发生时该干什么"提前注册好了
-
wake_up 发生时,直接调用回调
-
回调负责把 epitem 推入 ready list
!NOTE
select/poll:wait queue 里挂的是 task
epoll:wait queue 里挂的是 callback
而这一切的分歧,只来自于 poll_table->_qproc 指向了不同的实现。
2.5 readiness mask:不是布尔值,而是一组"机会位"
.poll 的返回值类型是 __poll_t,本质是一个 bitmask:
c
POLLIN // 可读
POLLOUT // 可写
POLLERR // 错误
POLLHUP // 挂断
...这组位的语义非常重要,它们表达的不是"完成",而是:
"现在推进 IO 状态是有意义的"
以 socket 为例:
-
POLLIN:接收队列非空(read 不会阻塞) -
POLLOUT:发送缓冲未满(write 可能推进) -
POLLERR:错误状态已出现 -
POLLHUP:对端关闭
注意这里的关键词:可能。
即使 POLLIN 置位,你也可能只读到一部分数据;
即使 POLLOUT 置位,你也可能只写入一部分字节。
这就是为什么用户态必须遵循"机会通知"范式:
-
收到事件 ≠ IO 完成
-
必须循环 read / write
-
直到返回
-EAGAIN
这为后文的 ET/LT、drain IO、为什么不 drain 会丢事件,全部埋下了伏笔。
!IMPORTANT
readiness 是"条件成立的机会",不是"承诺"。
2.6 架构细节拆解(字段级)
2.6.1 file_operations::poll
c
struct file_operations {
__poll_t (*poll)(struct file *, struct poll_table_struct *);
...
};-
定义 IO 就绪语义
-
统一入口
-
被 select/poll/epoll 共享调用
2.6.2 struct sock::sk_sleep
c
struct sock {
wait_queue_head_t sk_sleep;
...
};-
网络 IO 的等待锚点
-
poll_wait 会把 entry 挂到这里
-
wake_up 从这里触发
2.6.3 poll_wait 的角色(fs/select.c)
c
static inline void poll_wait(struct file *file,
wait_queue_head_t *wq,
poll_table *pt)
{
if (pt && pt->_qproc)
pt->_qproc(file, wq, pt);
}poll_wait 本身不关心你是谁,它只转发给 _qproc。
!TIP
极简 poll 钩子伪实现
c__poll_t my_poll(struct file *file, poll_table *pt) { poll_wait(file, &my_wq, pt); // 注册等待(可能什么都不做) return condition ? POLLIN : 0; // 返回就绪 mask }这就是"检查 + 注册"的最小模型。
!Supplement
POLLIN / POLLOUT 在 socket 上的典型映射
POLLIN:接收队列非空
POLLOUT:发送缓冲未满
POLLHUP:FIN 已到达
POLLERR:错误状态已置位
2.7 实战视角:用户态循环的真正含义
从内核视角看,你在用户态写的:
c
while (read(fd, buf, ...) > 0) {}本质是在:
-
消耗 readiness 提供的"机会"
-
把 socket 状态从"可读"推进回"不可读"
-
重新制造下一次"边沿/水平"变化
如果你不这么做:
-
LT 会不断提醒你(内核兜底)
-
ET 会直接"沉默"(协议违约)
下一节预告
下一节正式开始拆 select / pselect6(多路转接):
-
用户态 3 个
fd_set如何 copy 进内核 -
do_select()如何线性扫描 -
__pollwait如何把 current 挂队列 -
为什么每次返回前都要重置
fd_set
到那时,你会清楚地看到:
多路转接的成本,究竟花在了哪里。
3. select / pselect6 的内核调用链
syscall 层(sys_select/sys_pselect6)→ fs/select.c(do_select)→ 遍历 fd_set → 调用 f_op->poll
select 是"多路转接器",不是"多路复用器"。它没有任何持久监听关系,只有一次性的"临时路由表"。
3.1 用户态输入:3 个 fd_set 位图
函数: select(nfds, &readfds, &writefds, &exceptfds, &tv)
结构体: fd_set(位图)
字段/宏: FD_SET/FD_CLR/FD_ISSET/FD_ZERO,硬上限 FD_SETSIZE
fd_set 的本质是位图:第 i 位表示 fd=i 是否被关注。这个接口来自早期 Unix/BSD 时代的工程折中:那时 fd 数量小,位图操作快且简单,CPU cache 也远没今天这么敏感。
FD_SETSIZE 的硬限制,来自位图大小的静态约束。它不是"内核能力限制",而是 API 形态决定的:你用固定大小位图表达集合,必然有最大容量。
!NOTE
select 的"老",不在功能,而在表达方式:位图 + 固定上限,让它注定不适合大量 fd。
3.2 核心论点一:select 是典型"多路转接器"------临时路由表 + 全集线性扫描
函数: sys_select / sys_pselect6 → do_select
结构体: fd_set(输入集合也是输出集合)
字段/语义: 监听关系不持久,每次调用重新组织并扫描
为什么叫"转接"?
因为 select 的工作方式像一个一次性路由器:
用户态把三张路由表(read/write/except 三个位图)塞进内核;
内核照着这张表,把"就绪结果"重新写回同一张表;
系统调用返回,路由表随即作废------内核不保存任何监听关系。
这种设计天然导致 O(n) 扫描。原因不是实现不够聪明,而是模型强制你扫描:
-
位图表达的是"集合",而不是"对象链表"。内核拿到的只是一个 bitset。
-
"就绪"并不是内核统一字段能直接读出的标志位,它要调用
file->f_op->poll去问不同类型的 file。 -
既然你没给内核一个"仅包含已注册监听对象的容器",内核就只能从 0 扫到
nfds-1,遇到置位的 fd 再进一步取 file、调用 poll。
这就解释了两个现象:
-
为什么 select 的性能与"监听总数 nfds"相关,而不是与"实际就绪数"相关
-
为什么你每次循环都得重置 fd_set:因为返回时 fd_set 已经被内核改写成"就绪子集",原始监听集合已经丢了
!IMPORTANT
select 的 API 就决定了它只能"临时组织集合 → 全集扫描 → 覆写输出",没有任何可能演化成持久监听模型。
3.3 核心论点二:select 的核心成本不是等待,而是 copy + 扫描 + 回写
这一段要把"为什么 fd_set 必须重置"的根因讲透。
函数: sys_select / do_select
结构体: 用户态 fd_set ↔ 内核位图缓冲
字段/语义: 输入集合与输出集合复用同一块内存语义导致的 API 限制
select 的语义非常"古典":
你把 readfds 传进去,它既是"我关心的集合",也是"返回时的就绪集合"。同一块内存承担两种角色,这会逼出三段不可避免的成本:
-
copy_from_user(fd_set)
内核必须先把三个位图拷进内核缓冲,否则无法安全访问用户内存。
-
线性扫描
内核从 0...nfds-1 扫每一位,检查是否置位;置位则
fget(fd)找到struct file*,调用.poll获取 mask。 -
回写结果(fd_set 被内核改写)
内核把"就绪位"写回位图,再 copy_to_user 回用户态。
这一步的副作用是:原始监听集合被覆盖掉,下一轮必须重置。
这里 API 的限制非常硬:
你想避免重置 fd_set,就必须有"输入集合"和"输出集合"分离的接口;
但 select 从设计开始就把它们绑定在同一块内存上,导致用户态只能每轮 rebuild。
这也是为什么 select 在高并发长连接场景会出现一种典型浪费:
大量 fd 长期监听但多数时间不活跃,你却每轮都要构造位图、copy、扫描、回写。
!NOTE
这不是"实现可以优化"的问题,而是"API 把输入与输出绑死"的语义后果。
3.4 核心论点三:select 的等待挂载靠 __pollwait,但监听不持久导致唤醒后仍要重新扫描确认
这一段必须把"wakeup 后仍要扫"的硬伤讲清楚。
3.4.1 sys_select / sys_pselect6:系统调用入口做了什么(不重要)
函数: sys_select / sys_pselect6
结构体: 超时对象、信号掩码、poll_wqueues
语义: pselect6 多了"临时信号掩码"这个原子窗口
pselect6 的存在,本质是修补一个经典竞态:
"我准备睡了,但信号在我睡前来了又丢了"。
它通过在进入等待前设置一个临时 signal mask,把"设置掩码"和"睡眠等待"合并成不可分割窗口。
这一层属于 syscall 框架,和多路机制的本质无关,点到为止。
3.4.2 do_select:主循环如何组织对象操作
函数: do_select()(fs/select.c)
结构体: 内核位图、poll_wqueues(等待容器)
字段: poll_table->_qproc = __pollwait
do_select 的核心节奏就是:
-
为本次调用初始化等待容器
poll_wqueues很多地方的变量名就叫pwq -
把
poll_table->_qproc指向__pollwait这是 poll 和 select 通用的回调,实现位于 fs/select.c 上面刚刚也讲了有 -
扫描每个可能 fd 位
-
对置位 fd:
fget(fd)取 file,调用file->f_op->poll(file, pt)获取 mask,并在 poll 内部通过poll_wait注册等待 -
若有就绪则收集结果并返回;若无则睡眠等待唤醒;醒来后回到第 3 步继续扫描确认
关键对象落点在这里:poll_wqueues。
select/poll 在内核里会维护一个"本次调用挂了哪些 wait queue"的容器,用于退出时清理。它不是 epoll 那种持久结构,而是一次性临时账本。
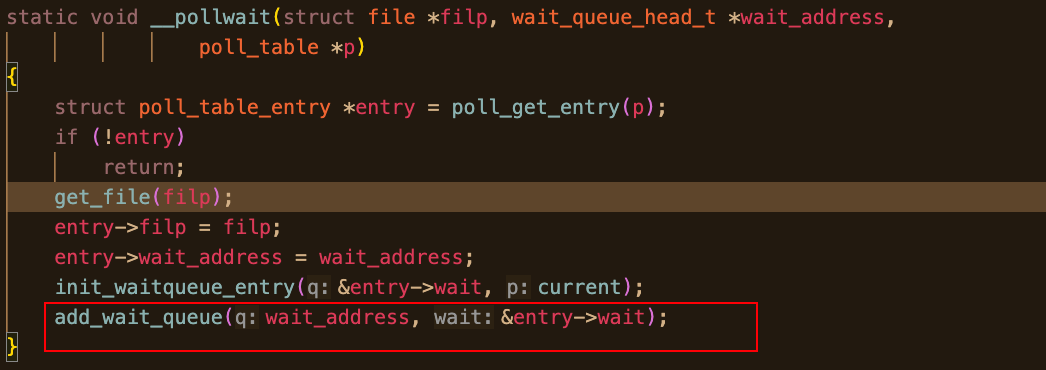
3.4.3 __pollwait:谁挂队列,挂到哪里
函数: __pollwait()(fs/select.c)
结构体: poll_table(包含一个回调 qproc 字段) / poll_wqueues / wait_queue_head_t
字段/语义: 把 current 任务挂到目标对象的 wait queue
上一章已经抓住了核心:poll_wait(file, &wq, pt) 只会调用 pt->_qproc。
select 把 _qproc 设为 __pollwait,含义就是:
-
fd->file->f_op->poll内部调用poll_wait时 -
最终把 当前任务 挂到对应对象的 wait queue 上(socket 就是
sk->sk_sleep)
于是"等待"这件事成立了:事件发生时 wake_up 会把 current 叫醒。
问题来了:为什么醒来后还要重新扫描?
因为 wake_up 的语义只是"你关心的某个条件可能成立了",但它不会告诉你"哪个 fd 就绪了"。
wait queue 是以"等待者列表"为核心的机制,不是"事件列表"。select 并没有持久监听对象,也没有 ready list,因此它在被唤醒后唯一能做的事就是------回到 do_select 再扫一遍全部集合,重新调用 .poll 确认状态。
这就是模型硬伤:
你可以把睡眠交给 wait queue,但你无法把"就绪归属"交给 wait queue,因为你没有关系对象来承载它。
!IMPORTANT
select 的 wakeup 只能把你叫醒,却不能把"就绪 fd 列表"交付给你;因此醒来后必须重新扫描确认,这是转接模型的结构性缺陷。
3.5 fd_set 的逐位扫描:为什么它天生就是 O(n)
函数: do_select()
结构体: 内核位图
语义: 逐位扫描 + 条件调用 .poll
内核会对位图做逐位测试:哪一位为 1,就去拿对应 fd 的 struct file* 并调用 .poll。无论你用什么位操作 helper,本质都绕不开"在 nfds 范围内检查每一位"的工作量。
这也是为什么在高 fd 数下,select 会表现出一种很典型的"CPU 空转":
绝大多数 fd 没有事件,但你仍然必须检查它们在位图中的位置,才能知道它们"没事件"。
!TIP
select 的最小正确范式:每轮重置 fd_set
cFD_ZERO(&rfds); FD_SET(listenfd, &rfds); for (fd : conns) FD_SET(fd, &rfds); n = select(maxfd+1, &rfds, NULL, NULL, &tv); // 返回后:rfds 只保留就绪位忘记重置,等价于把"上轮就绪位"当成"本轮监听位",很容易直接漏事件或死循环。问题的本质就是设计的时候没有将等待队列(关心的fd)和就绪队列解耦。让 fd_set 承担了两种语义,导致模型扩展性差
!Supplement
exceptfds 常被误用
它不是"异常事件大全"。在 socket 上,exceptfds 往往与 OOB(Out-Of-Band,带外数据)或特定错误语义有关,工程上通常宁可用 POLLERR/POLLHUP 这类语义更明确的位来处理错误与关闭。
3.6 实战总结:select 什么时候还能用、坑在哪里
select 还能用的场景非常明确:fd 很少、工具型程序、兼容性优先(很多古老系统接口支持最好)。
典型踩坑也几乎都是 API 形态造成的:
-
忘记每轮重置 fd_set(最常见)
-
maxfd 计算错(nfds 传小直接漏事件,传大浪费扫描)
-
超过 FD_SETSIZE(要么编译期限制,要么运行期行为混乱)
下一节预告
下一节讲 poll / ppoll(仍属多路转接):
-
pollfd的events/revents如何替代 3 个 fd_set -
为什么 API 更现代,但内核本质仍然线性扫描
-
把
struct pollfd的语义讲透,为后面 epoll 的"监听关系持久化"做对照
4. poll / ppoll 的内核调用链与 pollfd 语义
sys_poll / sys_ppoll → fs/select.c(do_poll)→ 遍历 pollfd → f_op->poll → 回填 revents
这一章的定位非常清晰:poll 是 select 的"现代化接口版本",但不是模型升级。
如果说 select 是"位图时代的多路转接器",那 poll 只是把"路由表"从位图换成了结构体数组,内核里的那套工作方式,一行都没变。
4.1 System V 风格接口的演进动机
poll 的出现,并不是为了性能,而是为了解决 select 在接口层面的三大痛点:
-
FD_SETSIZE的硬上限 -
三个 fd_set 可读性差、表达能力弱
-
位图 API 不利于扩展新的事件语义
System V 体系下,poll 用一个显式结构体 struct pollfd 取代了三个位图,让"我关心什么"和"发生了什么"在接口层面被拆开表达。
但注意:这是"表达能力的进步",不是"内核模型的进步"。
4.2 核心论点一:poll 解决了 FD_SETSIZE,但没解决 O(n)
函数: sys_poll / sys_ppoll
结构体: 用户态 struct pollfd[]
语义: 每次系统调用,临时传入监听集合,内核线性扫描
poll 的 API 看起来"现代"很多:
c
struct pollfd {
int fd;
short events; // 我关心什么
short revents; // 实际发生了什么
};你可以监听任意数量的 fd,只要你能在用户态分配数组,这确实比 select 的位图舒服得多。
但从内核视角看,poll 和 select 的模型完全一致:
-
用户态 每次调用 都传入一份"监听集合"
-
内核 不会保存任何监听关系
-
内核 必须遍历整个数组
-
就绪结果 回填到同一份数组
do_poll() 的核心节奏,和 do_select() 没有本质区别:
"扫一遍 → 问一遍 → 收集一遍"。
因此,poll 的时间复杂度仍然是 O(nfds)。
nfds 越大、活跃 fd 越少,浪费越明显。
!IMPORTANT
poll 只是把"位图扫描"换成了"数组扫描",扫描这件事本身从未消失。
4.3 核心论点二:events vs revents ------ 订阅语义与上报语义必须分清
这是 poll 相比 select 最容易写错、但也最重要的地方。
4.3.1 events:我关心什么
events 是用户态的输入字段,表达的是"我希望内核在什么条件下通知我"。
典型组合包括:
-
POLLIN:可读 -
POLLOUT:可写 -
POLLPRI:高优先级数据(如 OOB)
4.3.2 revents:内核告诉你发生了什么
revents 是内核回填字段,表达的是"实际发生的状态变化"。
关键点在于:
revents 不是 events 的子集。
以下事件 无视订阅,必须上报:
-
POLLERR:错误 -
POLLHUP:挂断 -
POLLNVAL:fd 非法
原因非常现实:
错误和挂断不是"机会通知",而是状态终结信息 。
如果用户态不关心它们,连接会直接泄漏或假死。
这也是为什么一个正确的 poll 循环,必须优先处理 POLLERR | POLLHUP,而不是只看 POLLIN。
!NOTE
如果你用 poll 却只判断
(revents & events),那你几乎一定会写出 bug。
4.4 核心论点三:do_poll 的真实工作------拿 mask、做匹配、注册等待
这一段把 函数 → 结构体 → 字段 → 语义 串起来。
4.4.1 系统调用入口:sys_poll / sys_ppoll
函数: sys_poll / sys_ppoll
差异点:
-
ppoll支持纳秒级超时 -
ppoll支持临时 signal mask(和 pselect6 一样,解决竞态)
这些差异属于 syscall 封装层,不影响 poll 的核心模型。
最终都会进入:
c
do_poll(pfds, nfds, timeout)4.4.2 do_poll:主遍历循环(fs/select.c)
函数: do_poll()
结构体: struct pollfd[]、struct poll_wqueues
字段: poll_table->_qproc = __pollwait
do_poll 的核心逻辑可以拆成三步:
第一步:初始化等待容器
c
poll_initwait(&pwq);poll_wqueues 用来记录"本次 poll 调用,往哪些 wait queue 上挂过东西",以便退出时统一清理。
第二步:遍历 pollfd 数组
对每一个 pollfd:
-
如果
fd < 0,直接跳过(这是 poll 支持"空槽"的一个小特性) -
fget(fd)→ 拿到struct file* -
调用:
c
mask = file->f_op->poll(file, &pwq.pt);这里发生了两件事:
-
.poll返回 readiness mask -
如果 mask 不满足,
.poll内部通过poll_wait()注册等待(走_qproc = __pollwait)
第三步:mask → revents 的匹配与回填
内核不会把 mask 原样塞进 revents,而是做一次语义匹配:
-
(mask & events)→ 用户关心的就绪事件 -
mask & (POLLERR | POLLHUP | POLLNVAL)→ 无条件加入 revents
匹配完成后,内核把结果写回:
c
pfds[i].revents = matched_mask;!IMPORTANT
注册等待 必须发生在检查之后但仍在同一轮调用中,这是"检查 + 注册"二段式契约的落地。
4.4.3 poll_wait 与 __pollwait:谁被挂进 wait queue
这一点和 select 完全一致。
关键字段:
c
poll_table->_qproc = __pollwait;意味着:
-
.poll内部调用poll_wait(file, &wq, pt) -
最终执行
__pollwait -
把 current 进程 挂进目标对象的 wait queue(socket 就是
sk->sk_sleep)
事件发生时,wake_up 会把进程叫醒;
但 不会告诉你哪个 fd 就绪了。
所以醒来后,do_poll 必须 重新遍历整个 pollfd 数组 ,再次调用 .poll 确认状态。
这一步,正是 poll 无法避免 O(n) 的根本原因。
4.5 pollfd 语义逐字段拆解
c
struct pollfd {
int fd; // 被监听的对象索引
short events; // 输入:我关心什么
short revents; // 输出:发生了什么
};-
fd:只是索引,不承载任何状态 -
events:订阅语义,决定"哪些 mask 会被关心" -
revents:上报语义,可能包含未订阅位
poll 把"输入集合"和"输出集合"拆成了两个字段,但仍然放在同一个结构体数组中。这比 select 清晰,但仍然是一次性结构。
!TIP
最小正确 poll 范式
cint n = poll(pfds, nfds, timeout); for (i = 0; i < nfds; i++) { if (pfds[i].revents & (POLLERR | POLLHUP)) { // 必须优先处理 } if (pfds[i].revents & POLLIN) { // read until EAGAIN } if (pfds[i].revents & POLLOUT) { // write until EAGAIN } }忽略错误位,几乎等价于资源泄漏。
!Supplement
为什么 revents 可以包含你没订阅的位
因为错误和挂断不是"机会",而是"状态事实"。
内核不能尊重你的订阅而隐瞒它们,否则用户态将永远无法得知连接已死。
4.6 实战总结:poll 的位置在哪里
在现代工程中,poll 的定位非常明确:
-
小规模 fd
-
控制面 / 管理线程
-
兼容性要求高的场景
一旦进入高并发长连接领域,poll 的 O(n) 扫描会迅速成为瓶颈。
这不是 API 用得好不好,而是模型注定的。
下一节预告
下一节正式进入 epoll(多路复用):
-
epoll_create1创建的struct eventpoll是什么对象 -
它的生命周期如何跨越系统调用
-
哪些关键字段支撑了"监听关系持久化"
从这一节开始,多路机制才真正发生质变。
5. epoll_create1 与 eventpoll 对象
sys_epoll_create1 → fs/eventpoll.c(创建 eventpoll)→ 返回 epoll fd
这一节把 epoll 的"复用"落地到一个很具体的东西上:一个长期存在的内核对象 。
select/poll 的集合是参数,epoll 的集合是状态;这不是比喻,是对象生命周期的硬差异。
5.1 核心论点一:epoll 的"复用"来自 eventpoll 这个持久内核对象
先把"复用"这个词讲得更硬一点:
所谓复用,不是"一个接口更快",而是 监听集合不再随系统调用消失。
select/poll 的监听集合是什么?
-
select:三个
fd_set位图,用户态构造,copy 进内核,内核扫描,回写后就作废 -
poll:一个
pollfd[]数组,用户态构造,copy 进内核,内核扫描,回写 revents 后就作废
它们共同的特点是:
集合存在于系统调用参数里,生命周期 = 一次系统调用。
于是成本也是一次性但反复发生的:
-
反复构造集合(用户态 O(n))
-
反复 copy_from_user(数据搬运)
-
反复线性扫描(内核 O(n))
-
反复回写结果(copy_to_user)
epoll 的根本变化,是把"集合"从参数提升为内核状态。
这件事靠的不是红黑树,而是一个对象:struct eventpoll。
当 epoll_create1 创建出这个对象后:
-
监听集合由内核持久维护
-
epoll_ctl只做增删改(低频) -
epoll_wait只消费就绪队列(高频但只与就绪数相关)
于是"扫描成本"被前移并摊销到监听关系建立阶段;"copy 成本"也从"每轮整集合 copy"变成"只在 epoll_wait 返回时 copy 就绪事件数组"。
!IMPORTANT
select/poll 每轮都要把"整张路由表"搬进搬出;epoll 只把"发生的事件"搬出去。
这就是 epoll 的复用含义:
复用的不是函数调用,而是内核里那份长期存在的监听关系状态。
5.2 核心论点二:epoll fd 不是被监听的 fd,而是"监听器对象"的句柄
很多人第一次看 epoll,会下意识把 epfd 当成"某种特殊 fd 集合"。这会让你后面理解 epoll_ctl / epoll_wait 时不断混乱。
epoll fd 的地位很明确:
它本身就是一个 fd,和 socket fd 一样走同一条路径:
c
epfd -> current->files->fdt->fd[epfd] -> struct file区别在于:这个 struct file 不是"网络连接",而是一个"监听器对象"的文件承载体。它的 private_data 指向真正的 epoll 实例对象:
c
file->private_data == struct eventpoll *也就是说:
-
你对 epfd 做
close(epfd),关掉的是整个 epoll 实例 -
你把 epfd 传进
epoll_ctl,是在修改这个实例的监听集合 -
你把 epfd 传进
epoll_wait,是在这个实例上等待就绪事件
这就解释了一个常见的工程事实:
epoll 实例通常与 EventLoop 同生共死。muduo 的 EventLoop、nginx 的 worker event loop,本质上都是"持有一个 epfd 并围绕它消费事件"。
!NOTE
epfd 不是数据源,它是"事件调度器"的句柄。
5.3 核心论点三:eventpoll 把"管理结构"和"运行时结构"分离
epoll 为什么需要一个独立对象?因为它要同时解决两类完全不同的问题:
-
管理问题:我要维护监听集合,支持 ADD/MOD/DEL,能按 fd 快速查找对应监听项
-
运行时问题:我要在事件发生时快速投递,并让 epoll_wait 以低开销交付就绪事件
这两类问题的访问模式完全不同:
-
管理是低频、强一致性、需要查找定位
-
运行时是高频、追求低延迟、最好 O(1) 入队出队
因此 eventpoll 的字段设计天然分区:管理区、就绪区、等待区。
5.4 架构细节:sys_epoll_create1 → do_epoll_create → file + eventpoll
5.4.1 函数链与文件位置
函数链:
-
sys_epoll_create1(flags) -
do_epoll_create(flags)(命名可能随版本略有差异,但在fs/eventpoll.c) -
创建一个匿名 file,并绑定
struct eventpoll -
安装到 fdtable,返回 epfd
源码路径:
-
fs/eventpoll.c -
结构体定义通常也在该文件中(部分版本会有
include/linux/eventpoll.h)
5.4.2 eventpoll 字段职责图
下面用"职责划分"的方式拆字段,避免你陷入字段堆里出不来。字段名在不同小版本可能有微调,但角色不变。
c
/* fs/eventpoll.c(骨架化,强调职责) */
struct eventpoll {
/* 1) 管理区:监听集合(用于 epoll_ctl) 是一颗 rbTree 红黑树 */
struct rb_root_cached rbr; // 监听关系索引:fd -> epitem
/* 2) 运行时区:就绪队列(用于 epoll_wait 交付) */
struct list_head rdllist; // ready list:已就绪的 epitem 链表
/* 3) 等待区:让 epoll_wait 睡眠/唤醒 */
wait_queue_head_t wq; // epoll_wait 睡在这里,回调 push 时 wake_up
/* 4) 并发控制:管理路径 vs 运行时路径锁 */
struct mutex mtx; // 保护 epoll_ctl 的增删改(集合结构一致性)
spinlock_t lock; // 保护 rdllist 等快路径(低延迟)
};这张图对应三种调用的职责分工:
-
epoll_ctl:主要碰 管理区(rb-tree)+ 少量关联状态 -
回调推送(后面讲
ep_poll_callback):主要碰 运行时区 (rdllist)+wake_up(wq) -
epoll_wait:主要睡/醒在 等待区 ,醒后消费 运行时区
!IMPORTANT
epoll 的关键不是"有红黑树",而是"管理结构与运行时结构分离",否则你会在高频事件路径上被查找与锁拖死。
5.5 epoll file 的承载关系:private_data 的意义
为什么必须用 struct file 承载 eventpoll?
因为 Linux 想要的不是"一个孤立对象",而是:
-
有引用计数与生命周期管理
-
能被 fdtable 索引
-
能参与
close()的资源回收语义 -
能配合
CLOEXEC等通用 fd 行为
这就是 epoll_create1 的"工程化落点":
它创建的不只是 struct eventpoll,还创建一个 file,把它挂到 fdtable 上,使它成为一个标准 fd。
!TIP
epoll fd 的对象关系伪代码
cepfd -> file (epoll file) -> file->private_data == struct eventpoll*你后面理解 epoll_ctl/epoll_wait 时,每次迷糊就把这句默念一遍。
!Supplement
epoll_create vs epoll_create1 的演进差异
epoll_create1(flags)允许直接指定EPOLL_CLOEXEC,避免 "create 后再 fcntl 设置" 的竞态窗口。这和
open/openat、pipe2的演进逻辑一致:把常用的 fd 语义在创建阶段一次性原子化。
5.6 实战范式:epoll 实例为何总与 EventLoop 绑定
因为 epoll 的价值不是"能等",而是"能复用监听关系"。
一旦你频繁创建/销毁 epoll 实例,相当于把摊销成本又拉回到"每轮重建",直接自废武功。
muduo 的做法是:一个 EventLoop 一个 epfd,长期持有;
nginx 的做法是:worker 进程内维护事件模块与 epoll 实例,长期运行。
这个模型背后对应的是:eventpoll 作为持久内核对象,本来就应该是"进程级资源",而不是"临时调用产物"。
下一节预告
下一节讲 epoll_ctl :逐条拆 ADD / MOD / DEL 的内核路径。重点会落在:
-
epitem如何记录一个被监听 fd 的全部信息 -
poll_table回调在 epoll 里如何被"改造成 push ready list"机制 -
为什么 epoll 需要把监听关系固化成 epitem,而不是复用 pollfd
6. epoll_ctl(ADD / MOD / DEL)的内核实现
sys_epoll_ctl → fs/eventpoll.c(ep_insert / ep_modify / ep_remove)→ 建立 epitem 与回调 → 等待 / 就绪联动
这一章把 epoll 的最后一块拼图补齐。
如果前面你已经理解了 eventpoll 是持久对象 、poll 回调是通用契约,那么这一章要做的事情只有一件:
把"监听关系"这个抽象,落到 epitem 这个具体对象上,并顺着源码把它的生命周期完整走一遍。
6.1 核心论点一:epoll_ctl 的本质,是把一次性监听请求固化为 epitem
先给结论,再展开:
epoll_ctl 做的不是"配置参数",而是"创建 / 修改 / 删除内核中的关系对象"。这个对象叫 epitem。
6.1.1 epitem 为什么必须存在
对比一下三种模型的"监听关系"载体:
-
select:
监听关系 = fd_set 位图
生命周期 = 一次系统调用
内核里没有任何实体表示"我在监听谁"
-
poll:
监听关系 = pollfd 数组项
生命周期 = 一次系统调用
内核里同样没有实体
-
epoll:
监听关系 = epitem
生命周期 = epoll_ctl(ADD) 到 epoll_ctl(DEL) / close(epfd)
只要监听关系需要 跨系统调用存在 ,你就必须有一个内核对象来承载它。
否则,内核在"事件发生的那一刻",根本不知道该把事件交给谁。
这就是 epitem 存在的根本原因:
它把"被监听 fd + 关注事件 + 回调挂载信息 + 就绪状态"绑定成一个不可分割的单元。
6.1.2 epitem 与 pollfd 的生命周期对比
这是很多人一直模糊的地方:
-
pollfd 是用户态结构体,内核只在调用期间"借用"
-
epitem 是内核对象,内核长期持有
因此:
-
pollfd 的 events/revents 每次都要 copy
-
epitem 的 event mask 常驻内核,只在 MOD 时更新
-
pollfd 不可能被"回调"
-
epitem 必须能被回调并自带上下文
!IMPORTANT
epoll_ctl 的"ADD",语义上等价于:
"把这条监听关系注册进内核事件系统里,并让我以后不再扫表。"
6.2 epoll_ctl 的整体调用框架
函数入口:
c
sys_epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)这一步做的事情和前面章节已经熟悉了:
-
fget(epfd)→ 拿到 epoll file -
file->private_data→ 拿到struct eventpoll *ep -
根据
op分发到不同路径
c
switch (op) {
case EPOLL_CTL_ADD:
ep_insert(ep, file, fd, event);
break;
case EPOLL_CTL_MOD:
ep_modify(ep, fd, event);
break;
case EPOLL_CTL_DEL:
ep_remove(ep, fd);
break;
}从这一刻开始,epoll_ctl 完全只操作 eventpoll 与 epitem,不再关心用户态。
6.3 核心论点二:ADD ------ 创建 epitem,并把回调挂进目标 wait queue
6.3.1 EPOLL_CTL_ADD:ep_insert 的职责拆解
函数: ep_insert()
文件: fs/eventpoll.c
ep_insert 的职责非常集中,可以拆成四步:
-
为被监听 fd 创建一个 epitem
-
把 epitem 插入 eventpoll 的"管理结构"(rbr)
-
通过 poll 语义,把 epitem 的回调挂进目标对象的 wait queue
-
如果 fd 在 ADD 时已经就绪,把 epitem 放进 rdllist
6.3.2 epitem 的关键字段职责(逐字段)
下面这段结构体你现在必须能"按职责背下来":
c
struct epitem {
/* 管理结构节点 */
struct rb_node rbn; // 插入 eventpoll->rbr,用于查找/去重
/* 运行时就绪链表节点 */
struct list_head rdllink; // 挂入 eventpoll->rdllist
/* 监听关系上下文 */
struct eventpoll *ep; // 属于哪个 epoll 实例
struct file *ffd; // 被监听的 file*
int fd; // 被监听的 fd 值(索引)
/* 用户关注的事件 */
struct epoll_event event; // events + data(用户态透传)
/* 等待队列挂载信息 */
struct list_head pwqlist; // 所有挂入目标 wait queue 的 entry
};每一个字段大致用途:
-
rbn:没有它,你无法快速判断"这个 fd 是否已经被监听" -
rdllink:没有它,你就没法 O(1) 把就绪事件交给 epoll_wait -
ffd / fd:回调发生时,必须知道这是哪个 fd -
event:回调发生时,必须知道用户订阅了什么 -
pwqlist:DEL 时,必须把之前注册进 wait queue 的回调全部拆干净
!NOTE
epitem 是"监听关系的最小完备单元",删掉任何一块,epoll 都会退化。
!TIP 2.6.26 epitem 源码注释
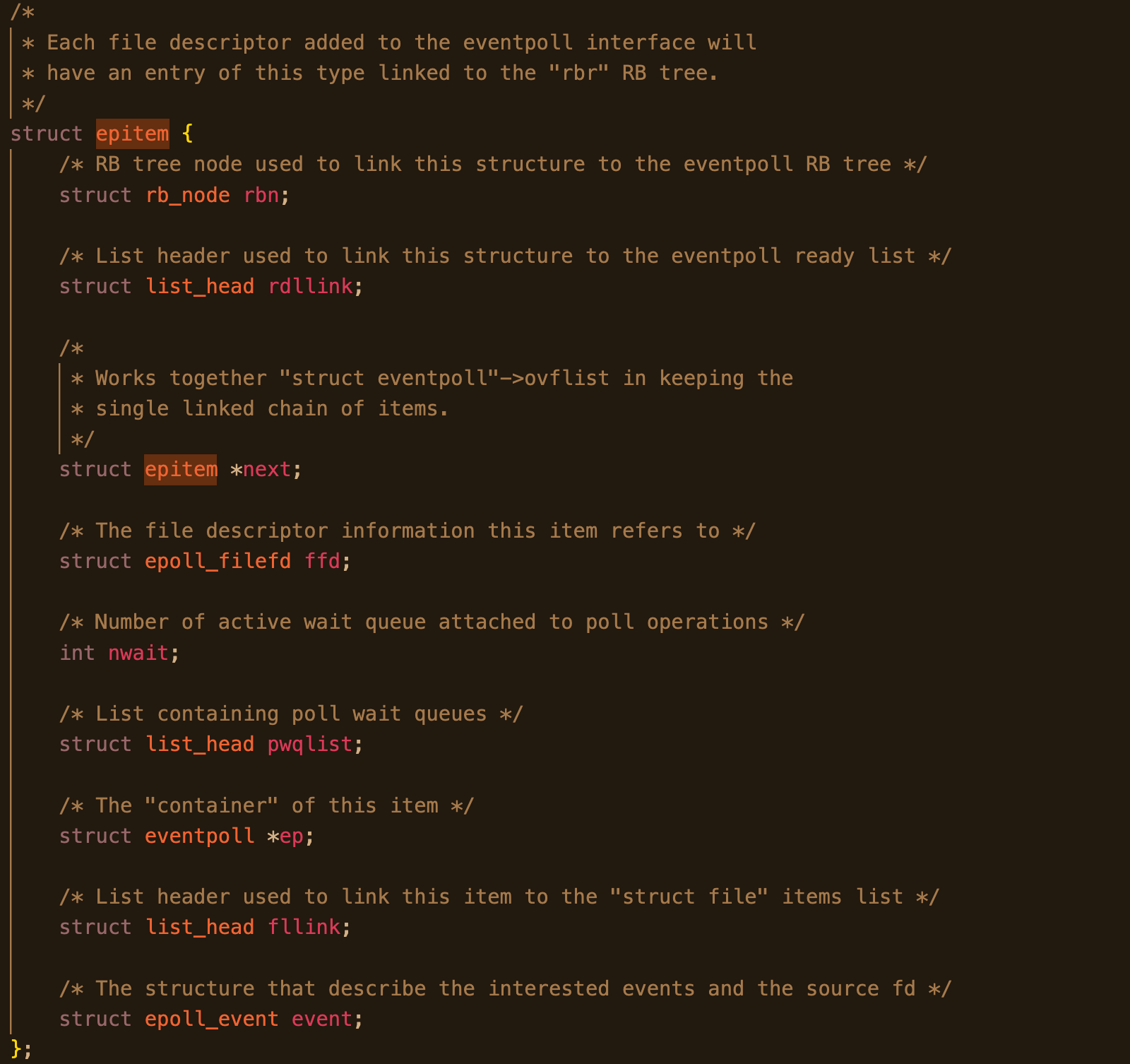
6.3.3 epoll 中的 poll_table 分歧点:不再是 __pollwait
在 ep_insert 中,epoll 会构造一个专用的 poll_table (上文有讲,内部其实就是一个回调函数字段),其 _qproc 指向的不是 __pollwait,而是 epoll 自己的队列处理函数 ep_ptable_queue_proc 。
逻辑含义非常明确:
-
select/poll:
_qproc = __pollwait→ 把 current task 挂进 wait queue -
epoll:
_qproc = ep_ptable_queue_proc→ 把 epitem 的回调 entry 挂进 wait queue
也就是说,在 ADD 阶段:
c
file->f_op->poll(file, &epoll_poll_table);并不是为了"等",而是为了:
把"当这个对象就绪时该执行的回调"注册进内核的等待链路里。
这一步完成之后,epoll 就不需要再"问"这个 fd 了。
!Supplement ep_pqueue 和 poll_table
其实刚刚说说的 ep_insert 的逻辑没问题,但是在我查阅的Linux版本中回调是
6.3.4 就绪时的推送链路(ADD 阶段已铺好路)
如果 fd 在 ADD 时就已经满足就绪条件:
-
.poll会返回 mask -
epoll 会立即把 epitem 放入 rdllist
-
epoll_wait 下一次调用将立刻返回
这保证了:epoll 不会漏掉 ADD 之前已经发生的事件。
6.4 核心论点三:事件驱动发生在回调,而不是 epoll_wait
这一段是 epoll 能"无扫描"的关键。
6.4.1 回调函数:ep_poll_callback
当 socket 收到数据、pipe 可写、设备就绪时:
-
底层子系统调用
wake_up_* -
wait queue 被遍历
-
对应的 wait_queue_entry->func 被调用
-
对 epoll 来说,这个 func 就是
ep_poll_callback
ep_poll_callback 做三件事:
-
从 wait_queue_entry 找到 epitem
-
把 epitem 放进 eventpoll->rdllist(如果还不在)
-
wake_up(eventpoll->wq),唤醒 epoll_wait
这一刻非常重要:
事件在"发生时"就被路由到了正确的 epoll 实例。
epoll_wait 醒来之后,不做检查、不做扫描,只做"交付"。
6.4.2 epoll_wait:只消费 rdllist
epoll_wait 的逻辑可以高度概括为:
-
如果 rdllist 为空,睡在
eventpoll->wq -
醒来后,把 rdllist 中的 epitem 逐个取出
-
拷贝
epitem->event到用户态数组 -
根据 LT/ET/ONESHOT 决定是否保留 / 清除就绪状态
这一步完全不关心 fd 总数,只关心"当前发生了多少事件"。
!IMPORTANT
epoll 的性能优势来自 callback → rdllist → 交付 这条路径,而不是来自"更聪明的扫描"。
6.5 MOD / DEL:对 epitem 的修改与销毁
6.5.1 EPOLL_CTL_MOD:ep_modify
MOD 的语义非常单纯:
-
找到对应 fd 的 epitem(通过 rbr)
-
更新 epitem->event.events
-
根据新事件掩码调整行为(ET/LT/ONESHOT)
MOD 不会重新建立监听关系,只修改已有关系的属性。
这也是为什么:
-
ONESHOT 必须通过 MOD 重新 arm
-
修改事件关注集合是 O(1) 的管理操作
6.5.2 EPOLL_CTL_DEL:ep_remove
DEL 的复杂度反而比 ADD / MOD 更高,因为它必须 完全拆除 epitem 的副作用:
-
从 eventpoll->rbr 中删除 epitem
-
如果在 rdllist 中,把它摘掉
-
遍历 epitem->pwqlist,把所有 wait queue entry 从目标对象的 wait queue 中移除
-
释放 epitem
这一套流程,保证了:
-
epoll 不会在 future wakeup 中再收到这个 fd 的事件
-
不会出现 use-after-free
-
不会留下"幽灵回调"
!NOTE
epitem 的 pwqlist 是 DEL 能正确工作的关键,没有它就无法安全解绑。
6.6 核心论点四:epoll_ctl 管"关系",epoll_wait 管"交付"实现
把整个模型压成一句可复述的话:
epoll_ctl 是管理路径:创建 / 修改 / 删除监听关系(epitem)。
epoll_wait 是运行路径:消费已经发生的事件(rdllist)。
一旦你在脑中混淆这两条路径,下面这些问题一定会出现:
-
ET 模式下不 drain → 事件不再触发
-
ONESHOT 忘记 rearm → fd 永久沉默
-
LT 模式反复触发 → 忘记消费就绪状态
这不是 epoll 的问题,而是"职责边界理解错误"。
6.7 常见范式
muduo(典型 Reactor)
-
epoll + nonblocking
-
LT 模式
-
事件回调只做"搬运与分发"
-
真正读写在 Channel 层循环 drain 到 EAGAIN
nginx(高吞吐)
-
epoll + nonblocking
-
常用 ET
-
严格 drain
-
状态机复杂,但 wakeup 次数极少
这两种风格差异,本质来自 如何消费 epitem 对应的 readiness。
!TIP
用户态 epoll 最小正确范式
c// 1) socket 设 O_NONBLOCK // 2) epoll_ctl(ADD) // 3) epoll_wait 返回后: while ((n = read(fd, buf, ...)) > 0) { ... } if (n == -1 && errno != EAGAIN) { error; }不 drain,本质就是违背 poll 语义。
!Supplement
面试题回答骨架
1) 为什么 epoll 比 poll 快?
poll:每次调用线性扫描所有 fd
epoll:监听关系持久化为 epitem
事件发生时通过回调直接推入 rdllist
epoll_wait 只消费就绪事件,无扫描
2) ET 为什么容易丢事件?
ET 只在状态变化时通知一次
用户态必须 drain 到 EAGAIN
未完全消费就绪状态,不会再次触发回调
!Supplement
词源考古
item:内核中常指"关系 / 实体节点"(如 list item、rb item)
epoll 在设计的时候有两个容器在 struct epollevent 里,一个是红黑树一个是双向链表,他们的节点本质都是 epitem 而且两个容器共用 epitem 这样减少了拷贝而且修改 epitem 不会导致数据在两个容器之间不一致的问题减少了这部分维护的开销。
poll callback:表示"被 poll 框架回调的处理函数",epoll 正是利用了这一钩子
6.8 结语:从"等"到"搬"
到这里,这一篇、乃至整个《Linux IO 模型纵深解析》的 "等的机制" 已经彻底打通:
-
select/poll:多路转接,参数即集合,线性扫描
-
epoll:多路复用,关系即对象,事件驱动
本系列 1~6 篇在这里也算是把 select/poll 和 epoll 模型的前世今生讲通了。第一次写这样的文章集,有不好的地方请大家多多包涵,可以私信讨论,随时欢迎。谢谢大家。