目录
[1. 🎯 开篇:为什么强化学习是AI皇冠上的明珠?](#1. 🎯 开篇:为什么强化学习是AI皇冠上的明珠?)
[2. 🧮 数学基础:马尔可夫决策过程(MDP)的精髓](#2. 🧮 数学基础:马尔可夫决策过程(MDP)的精髓)
[2.1 MDP:强化学习的通用语言](#2.1 MDP:强化学习的通用语言)
[2.2 值函数与策略:智能体的"世界观"和"方法论"](#2.2 值函数与策略:智能体的“世界观”和“方法论”)
[3. ⏳ 算法演进:从表格到神经网络的革命](#3. ⏳ 算法演进:从表格到神经网络的革命)
[3.1 Q-Learning:一切的原点](#3.1 Q-Learning:一切的原点)
[3.2 DQN:深度学习的第一次胜利](#3.2 DQN:深度学习的第一次胜利)
[3.3 Policy Gradient:直接学习策略](#3.3 Policy Gradient:直接学习策略)
[3.4 PPO:工业界的"瑞士军刀"](#3.4 PPO:工业界的“瑞士军刀”)
[4. ⚙️ PPO算法深度拆解](#4. ⚙️ PPO算法深度拆解)
[4.1 信任区域:PPO的哲学基础](#4.1 信任区域:PPO的哲学基础)
[4.2 优势估计:GAE的艺术](#4.2 优势估计:GAE的艺术)
[4.3 Actor-Critic架构:分工协作](#4.3 Actor-Critic架构:分工协作)
[5. 🛠️ 实战:OpenAI Gym + Stable-Baselines3](#5. 🛠️ 实战:OpenAI Gym + Stable-Baselines3)
[5.1 环境搭建:不要重复造轮子](#5.1 环境搭建:不要重复造轮子)
[5.2 第一个智能体:倒立摆控制](#5.2 第一个智能体:倒立摆控制)
[5.3 监控训练:TensorBoard可视化](#5.3 监控训练:TensorBoard可视化)
[6. 🎮 进阶实战:Atari游戏高手](#6. 🎮 进阶实战:Atari游戏高手)
[7. 🏢 企业级应用:从玩具到生产](#7. 🏢 企业级应用:从玩具到生产)
[7.1 案例1:智能库存管理](#7.1 案例1:智能库存管理)
[7.2 案例2:机器人控制](#7.2 案例2:机器人控制)
[8. ⚡ 性能优化技巧](#8. ⚡ 性能优化技巧)
[8.1 并行化:加速10倍的秘密](#8.1 并行化:加速10倍的秘密)
[8.2 超参数调优:不要盲目网格搜索](#8.2 超参数调优:不要盲目网格搜索)
[8.3 奖励工程:强化学习的灵魂](#8.3 奖励工程:强化学习的灵魂)
[9. 🔧 故障排查指南](#9. 🔧 故障排查指南)
[9.1 问题:奖励不上升](#9.1 问题:奖励不上升)
[9.2 问题:训练后期崩溃](#9.2 问题:训练后期崩溃)
[9.3 问题:过拟合](#9.3 问题:过拟合)
[10. 🔮 前沿与展望](#10. 🔮 前沿与展望)
[10.1 离线强化学习:从历史数据中学习](#10.1 离线强化学习:从历史数据中学习)
[10.2 多智能体强化学习:合作与竞争](#10.2 多智能体强化学习:合作与竞争)
[10.3 大语言模型+强化学习:AI智能体](#10.3 大语言模型+强化学习:AI智能体)
[11. 📊 性能对比与选型指南](#11. 📊 性能对比与选型指南)
[11.1 算法选择矩阵](#11.1 算法选择矩阵)
[11.2 硬件配置建议](#11.2 硬件配置建议)
[12. 📚 学习资源与进阶路径](#12. 📚 学习资源与进阶路径)
[12.1 官方文档(必读)](#12.1 官方文档(必读))
1. 🎯 开篇:为什么强化学习是AI皇冠上的明珠?
强化学习是机器学习领域最接近人类学习方式的范式。多年前我第一次接触Q-Learning时,完全没想到它能击败世界围棋冠军、控制工业机器人、甚至优化整个电网系统。
与监督学习需要大量标注数据不同,强化学习让智能体通过试错自主学习------就像婴儿学步,跌倒了再爬起来。这种"从交互中学习"的能力,让强化学习在游戏AI、机器人控制、金融交易、资源调度等领域大放异彩。
但现实很骨感:80%的强化学习项目死在原型阶段。原因很简单------训练不稳定、收敛难、调参玄学。今天,我就带你绕过这些坑,从理论到实战,掌握工业级强化学习的核心技巧。
2. 🧮 数学基础:马尔可夫决策过程(MDP)的精髓
2.1 MDP:强化学习的通用语言
马尔可夫决策过程是强化学习的数学框架,它定义了智能体与环境交互的基本规则。你可以把它想象成一个"决策流程图":在某个状态,你采取某个动作,环境给你一个奖励,并转移到下一个状态。

核心五元组 (S,A,P,R,γ)是必须刻在脑子里的:
-
状态空间 S:环境所有可能状态的集合。比如自动驾驶中,状态包括车辆位置、速度、周围障碍物等。
-
动作空间 A:智能体可以执行的所有动作。离散动作(如左转/右转)和连续动作(如方向盘角度)处理方式完全不同。
-
转移概率 P:环境动态性的数学描述。P(s′∣s,a)表示"在状态s执行动作a后,跳到状态s'的概率"。
-
奖励函数 R :环境的反馈信号。设计奖励函数是强化学习最艺术的部分------奖得不对,智能体就学歪。
-
折扣因子 γ:权衡眼前利益和长远收益。γ=0是"今朝有酒今朝醉",γ=0.99是"风物长宜放眼量"。
实战经验 :在工业场景中,状态设计往往比算法选择更重要。我曾经优化一个仓储机器人,最初用20维状态(包含各种传感器噪声),训练一个月没收敛。后来只用4维核心状态(位置、速度、目标距离、电量),一周就达到生产标准。
2.2 值函数与策略:智能体的"世界观"和"方法论"
值函数 V(s)是智能体的"世界观"------它认为状态s有多好。Q函数 Q(s,a)更细致,评估在状态s下采取动作a的价值。
策略 π(a∣s)是智能体的"方法论"------在状态s下应该采取什么动作。这里就分化出两大流派:
-
值迭代(Value-based):先学值函数,再推导策略。比如Q-Learning、DQN。
-
策略优化(Policy-based):直接学习策略函数。比如Policy Gradient、PPO。
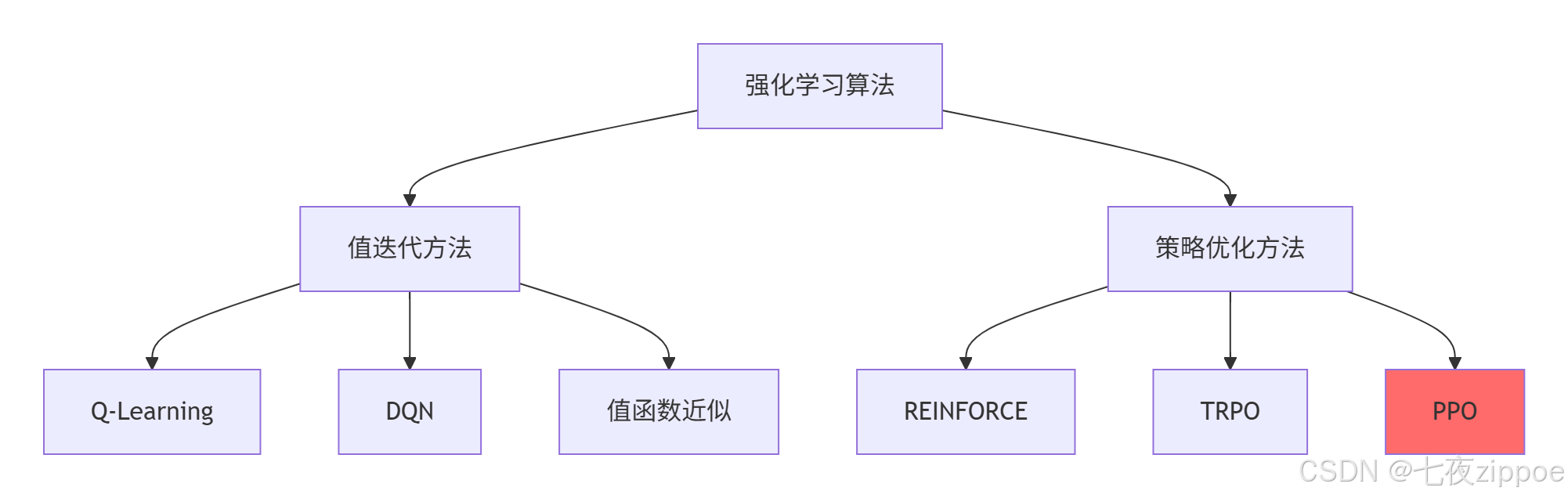
我的选择:对于离散动作、状态空间小的问题,用DQN;对于连续控制、复杂策略的问题,用PPO。这也是工业界的主流选择。
3. ⏳ 算法演进:从表格到神经网络的革命
3.1 Q-Learning:一切的原点
1992年,Chris Watkins提出Q-Learning时,神经网络还在低谷期。Q-Learning用一张Q表格存储每个状态-动作对的价值。
核心思想:用贝尔曼方程迭代更新Q值:
Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]优点:简单直观,收敛性有理论保证。
致命缺点:维度灾难。围棋有10170种状态,宇宙原子总数才1080,这表格存得下?
实战回忆:2013年,我用Q-Learning训练"井字棋"AI,效果很好。但当我试图用到"股票交易"时,状态空间瞬间爆炸------光股价离散化到100档,交易量100档,就有一万种状态。Q表格?不存在的。
3.2 DQN:深度学习的第一次胜利
2013年,DeepMind的DQN在Atari游戏上超越人类,开启了深度强化学习时代。DQN用神经网络代替Q表格,解决了维度灾难。
三大创新:
-
经验回放:打破数据相关性,让训练更稳定。
-
目标网络:固定目标值,缓解"追逐移动目标"问题。
-
端到端学习:直接从像素到动作,无需人工特征。
但问题还在 :DQN是"离散动作专属",对连续动作(如机器人控制)无能为力。而且Q-learning系列都有过估计毛病------总是乐观估计Q值,导致策略过于冒险。
3.3 Policy Gradient:直接学习策略
策略梯度方法不绕弯子,直接优化策略函数 πθ(a∣s)。通过策略梯度定理:
∇θJ(θ)=E[∇θlogπθ(a∣s)Q(s,a)]优点:
-
天然支持连续动作
-
探索性更好(可以学随机策略)
-
收敛性通常更好
缺点:
-
样本效率低(on-policy,用过的数据就扔)
-
训练不稳定(一步太大就崩盘)
3.4 PPO:工业界的"瑞士军刀"
2017年,OpenAI提出PPO,迅速成为工业界标准。PPO的核心思想是"小步快跑,别扯着蛋"。
PPO的两大绝技:
-
Clipped Surrogate Objective:用裁剪限制策略更新幅度
-
Generalized Advantage Estimation (GAE):平衡偏差和方差
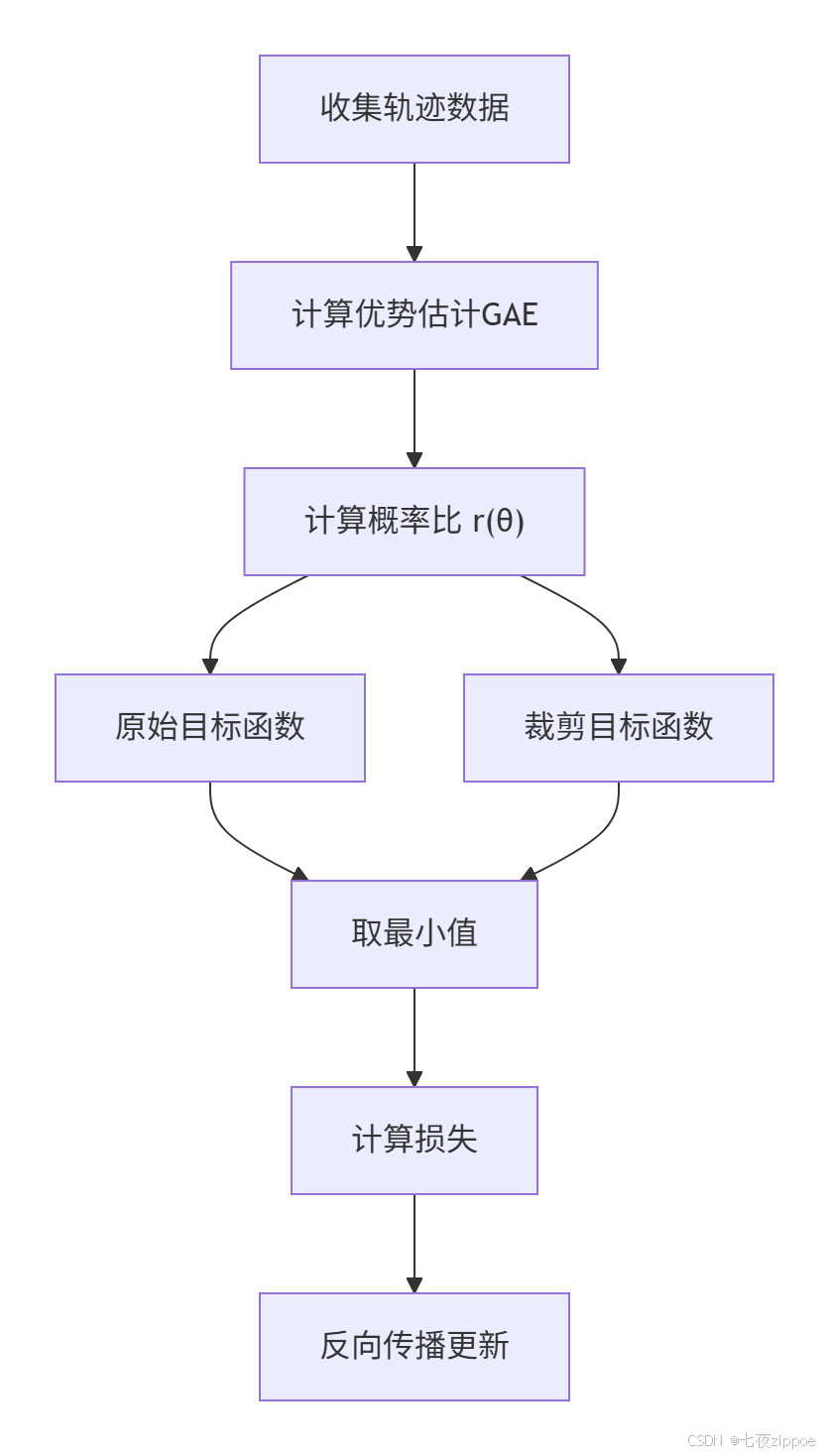
为什么PPO能统治工业界 ?不是因为它最强,而是因为它最稳。在真实场景中,稳定性比峰值性能重要100倍。你无法接受一个今天能赚100万、明天能亏200万的交易策略。
4. ⚙️ PPO算法深度拆解
4.1 信任区域:PPO的哲学基础
传统的策略梯度算法有个致命问题:步长太难调。步长大,容易"学崩";步长小,收敛慢得像蜗牛。
PPO的解决方案是信任区域优化:我只在旧策略附近的一小片"信任区域"内更新策略。数学上,通过限制新旧策略的KL散度来实现。
裁剪目标函数:
LCLIP(θ)=Et[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]这里:
-
rt(θ)=πθ(at∣st)/πθold(at∣st)是新旧策略概率比
-
At是优势函数
-
ϵ是裁剪参数(通常0.1-0.2)
白话解释:如果新策略比旧策略好很多(rt>> 1),我们就把它"按"在 1+ϵ;如果新策略变差了(rt<< 1),就把它"拉"到 1−ϵ。这样既鼓励改进,又防止突变。
4.2 优势估计:GAE的艺术
优势函数 At=Q(st,at)−V(st)衡量"这个动作比平均动作好多少"。
但At很难算准。蒙特卡洛方法(用整条轨迹的回报)无偏但高方差;时序差分(用一步估计)低方差但有偏。
GAE 是两者的折中:
AtGAE=l=0∑∞(γλ)lδt+l其中 δt=rt+γV(st+1)−V(st)
λ是调节参数:λ=0是纯TD(方差小),λ=1是纯MC(偏差小)。通常设 λ=0.95。
python
# GAE计算代码示例
def compute_gae(rewards, values, gamma=0.99, lam=0.95):
"""计算广义优势估计"""
advantages = []
gae = 0
next_value = 0
for t in reversed(range(len(rewards))):
delta = rewards[t] + gamma * next_value - values[t]
gae = delta + gamma * lam * gae
advantages.insert(0, gae)
next_value = values[t]
return advantages4.3 Actor-Critic架构:分工协作
PPO采用Actor-Critic架构,这是深度强化学习的"黄金搭档":
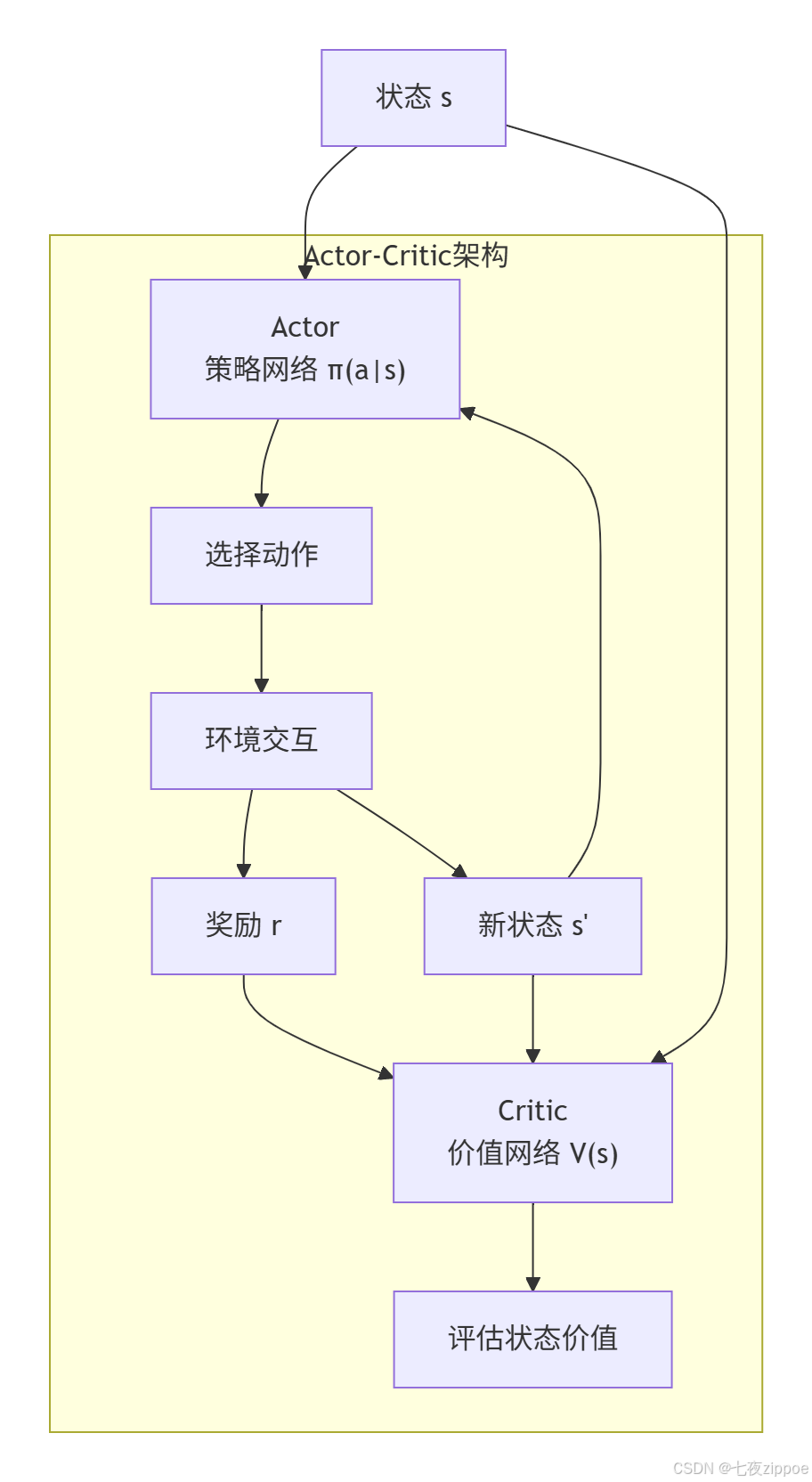
Actor(演员):策略网络,负责"做什么"。输入状态,输出动作分布。
Critic(评论家):价值网络,负责"好不好"。输入状态,输出状态价值。
两者的关系:Critic告诉Actor"你这个动作在当前位置能得多少分",Actor根据这个反馈调整自己的表演策略。有点像导演(Critic)指导演员(Actor)。
5. 🛠️ 实战:OpenAI Gym + Stable-Baselines3
5.1 环境搭建:不要重复造轮子
强化学习最烦的就是写环境。好在有OpenAI Gym,提供了从经典控制到Atari游戏的100+个环境。
bash
# 基础安装
pip install gymnasium
pip install stable-baselines3[extra]
# 额外环境(按需)
pip install box2d-py # 连续控制环境
pip install atari-py # Atari游戏
pip install mujoco # 机器人仿真(需要许可证)为什么用Gymnasium而不是Gym?Gymnasium是Gym的维护分支,API更干净,bug更少。OpenAI官方也推荐用Gymnasium。
5.2 第一个智能体:倒立摆控制
倒立摆(CartPole)是强化学习的"Hello World"。任务很简单:控制小车左右移动,不让杆子倒下。
python
# 完整训练代码
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.evaluation import evaluate_policy
# 1. 创建环境
env = gym.make("CartPole-v1")
# 2. 创建PPO模型
model = PPO(
"MlpPolicy", # 策略网络:多层感知机
env,
learning_rate=3e-4, # 学习率,PPO对这个不敏感
n_steps=2048, # 每次收集多少步数据
batch_size=64, # 批大小
n_epochs=10, # 每次数据用几轮
gamma=0.99, # 折扣因子
gae_lambda=0.95, # GAE参数
clip_range=0.2, # 裁剪范围,PPO核心参数!
verbose=1 # 显示训练日志
)
# 3. 训练
model.learn(total_timesteps=100000)
# 4. 评估
mean_reward, std_reward = evaluate_policy(model, env, n_eval_episodes=10)
print(f"平均奖励: {mean_reward:.2f} +/- {std_reward:.2f}")
# 5. 保存模型
model.save("ppo_cartpole")
# 6. 加载并测试
del model
model = PPO.load("ppo_cartpole")
obs, _ = env.reset()
for _ in range(1000):
action, _ = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, _ = env.step(action)
env.render() # 显示画面
if terminated or truncated:
obs, _ = env.reset()
env.close()参数调优经验:
-
n_steps:每次收集的数据量。太小则方差大,太大则更新慢。2048是经验值。 -
clip_range:裁剪范围。环境简单用0.2,环境复杂用0.1。 -
gae_lambda:GAE参数。0.95是通用设置,如果训练不稳定可降到0.9。
5.3 监控训练:TensorBoard可视化
训练强化学习模型最怕的就是"黑盒"。你不知道它学得怎么样,什么时候崩。
Stable-Baselines3内置TensorBoard支持:
python
# 训练时记录日志
model = PPO(
"MlpPolicy",
env,
tensorboard_log="./ppo_cartpole_tensorboard/", # 日志目录
verbose=0
)
model.learn(total_timesteps=100000, tb_log_name="first_run")然后启动TensorBoard:
tensorboard --logdir ./ppo_cartpole_tensorboard/打开浏览器看 http://localhost:6006,关键指标:
-
charts/episodic_return:每回合总奖励,应该稳步上升
-
losses/value_loss:价值网络损失,应该下降
-
losses/policy_loss:策略网络损失,应该下降
-
charts/entropy:策略熵,衡量探索程度。开始时高,逐渐下降

6. 🎮 进阶实战:Atari游戏高手
倒立摆太简单?来试试Atari游戏。这里以Pong(乒乓球)为例:
python
# Atari Pong训练
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.atari_wrappers import AtariWrapper
from stable_baselines3.common.vec_env import DummyVecEnv, VecFrameStack
# 创建Atari环境
def make_env():
env = gym.make("PongNoFrameskip-v4")
env = AtariWrapper(env) # Atari专用包装
return env
# 向量化环境 + 帧堆叠
env = DummyVecEnv([make_env])
env = VecFrameStack(env, n_stack=4) # 堆叠4帧以感知运动
# 使用CNN策略
model = PPO(
"CnnPolicy", # 卷积神经网络,处理图像
env,
learning_rate=2.5e-4,
n_steps=128,
batch_size=256,
n_epochs=4,
gamma=0.99,
gae_lambda=0.95,
clip_range=0.1, # Atari游戏需要更小的裁剪
verbose=1,
tensorboard_log="./ppo_pong_tensorboard/"
)
# 长时间训练
model.learn(total_timesteps=10_000_000) # 1000万步,需要几小时关键技术点:
-
帧堆叠:单帧图片是静态的,堆叠4帧才能看到球的运动
-
CNN策略:卷积神经网络自动提取图像特征
-
长时间训练:Atari游戏需要百万步级别的训练
硬件要求:训练Atari级别的模型,最好有GPU。CPU训练可能需要几天。
7. 🏢 企业级应用:从玩具到生产
7.1 案例1:智能库存管理
背景:电商公司需要优化库存,平衡缺货损失和仓储成本。
MDP建模:
-
状态:库存水平、未来7天预测销量、在途货物、季节性因子
-
动作:订购数量(0-1000)
-
奖励:销售额 - 仓储成本 - 缺货惩罚
-
折扣:γ=0.95(看重近期效益)
实现要点:
python
class InventoryEnv(gym.Env):
def __init__(self):
self.observation_space = gym.spaces.Box(
low=0, high=1000, shape=(10,), dtype=np.float32
)
self.action_space = gym.spaces.Discrete(101) # 0-100
def step(self, action):
# 模拟一天销售
demand = self._generate_demand()
sales = min(self.inventory, demand)
# 计算奖励
revenue = sales * self.price
holding_cost = self.inventory * 0.1
lost_sales = max(0, demand - sales) * self.penalty
reward = revenue - holding_cost - lost_sales
# 更新库存
self.inventory = max(0, self.inventory - sales) + action
return self._get_state(), reward, False, {}训练技巧:
-
使用课程学习:从简单需求分布开始,逐步复杂化
-
添加历史特征:包括过去7天的销售数据
-
使用集成模型:训练多个智能体投票决策
7.2 案例2:机器人控制
背景:工业机械臂需要学习抓取不同形状的物体。
挑战:
-
状态空间高维(关节角度、速度、摄像头图像)
-
动作空间连续(每个关节的扭矩)
-
奖励稀疏(只有抓住/没抓住)
解决方案:
python
# 使用SAC(更适合连续控制)
from stable_baselines3 import SAC
model = SAC(
"MlpPolicy",
env,
learning_rate=3e-4,
buffer_size=1_000_000, # 经验回放池要大
learning_starts=10000, # 先收集一些数据再学
batch_size=256,
tau=0.005, # 目标网络软更新参数
gamma=0.99,
verbose=1
)关键技术:
-
分层强化学习:高层决策抓取位置,底层控制关节
-
演示学习:先用人工演示预训练
-
域随机化:随机化物体颜色、光照、摩擦力,提高泛化性
8. ⚡ 性能优化技巧
8.1 并行化:加速10倍的秘密
强化学习最大的瓶颈是数据收集。一个智能体跟环境交互,大部分时间在等。
解决方案:并行收集。
python
from stable_baselines3.common.vec_env import SubprocVecEnv
import multiprocessing
def make_env(env_id, rank):
def _init():
env = gym.make(env_id)
env.reset(seed=rank) # 不同种子增加多样性
return env
return _init
num_cpu = multiprocessing.cpu_count()
env = SubprocVecEnv([make_env("CartPole-v1", i) for i in range(num_cpu)])
model = PPO("MlpPolicy", env, verbose=1)
# 现在数据收集速度提高num_cpu倍!注意:不是所有环境都支持并行。有些环境有全局状态(比如物理引擎),并行会出错。
8.2 超参数调优:不要盲目网格搜索
强化学习的超参数调优是个玄学。我的经验:
-
先调学习率:PPO对学习率不敏感,3e-4是安全选择
-
再调裁剪范围:简单任务0.2,复杂任务0.1
-
最后调GAE:如果训练不稳定,降低gae_lambda
自动调参工具:
-
Optuna:最流行的调参框架
-
Ray Tune:分布式调参,适合大规模
python
import optuna
from stable_baselines3 import PPO
def optimize_ppo(trial):
"""Optuna优化PPO超参数"""
return {
'learning_rate': trial.suggest_float('lr', 1e-5, 1e-3, log=True),
'n_steps': trial.suggest_categorical('n_steps', [256, 512, 1024, 2048]),
'gae_lambda': trial.suggest_float('gae', 0.8, 0.99),
'clip_range': trial.suggest_float('clip', 0.1, 0.3),
}
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100) # 100次试验8.3 奖励工程:强化学习的灵魂
坏奖励导致坏行为,这是强化学习第一定律。
常见坑:
-
奖励稀疏 :只有最终结果有奖励。解决方案:奖励塑形
-
奖励欺骗 :智能体找到系统漏洞刷分。解决方案:奖励验证
-
奖励冲突 :多个目标相互矛盾。解决方案:多目标优化
奖励塑形示例:
python
# 倒立摆的原始奖励:每步+1,倒了结束
# 奖励塑形:增加角度惩罚
def shaped_reward(state, action, next_state):
x, x_dot, theta, theta_dot = state
original_reward = 1.0
# 角度惩罚:杆子越垂直奖励越高
angle_penalty = -abs(theta) * 0.1
# 位置惩罚:小车越靠中奖励越高
position_penalty = -abs(x) * 0.01
return original_reward + angle_penalty + position_penalty9. 🔧 故障排查指南
9.1 问题:奖励不上升
可能原因:
-
学习率太高/太低
-
探索不够
-
奖励设计有问题
排查步骤:
python
# 1. 检查探索熵
print(f"策略熵: {model.log_entropy}") # 应该从高逐渐降低
# 2. 检查梯度
for name, param in model.policy.named_parameters():
if param.grad is not None:
print(f"{name}: grad norm = {param.grad.norm().item():.4f}")
# 3. 可视化轨迹
episode_rewards = []
obs, _ = env.reset()
for _ in range(1000):
action, _ = model.predict(obs, deterministic=False)
obs, reward, terminated, truncated, _ = env.step(action)
episode_rewards.append(reward)
plt.plot(episode_rewards)
plt.title("单轨迹奖励")
plt.show()9.2 问题:训练后期崩溃
现象:奖励先上升后突然暴跌。
原因:策略更新太大,跳出信任区域。
解决方案:
-
减小
clip_range -
增加
n_epochs(每批数据多训几次) -
使用策略熵约束:防止策略过早确定
python
model = PPO(
"MlpPolicy",
env,
ent_coef=0.01, # 熵系数,鼓励探索
clip_range=0.1, # 更小的裁剪
n_epochs=20, # 更多训练轮次
target_kl=0.01, # KL散度约束
)9.3 问题:过拟合
现象:训练环境表现好,测试环境差。
原因:记住了特定环境,没学到通用策略。
解决方案:
-
域随机化:随机化环境参数
-
正则化:添加L2正则
-
集成学习:训练多个策略投票
python
# 域随机化示例
class RandomizeEnv(gym.Wrapper):
def __init__(self, env):
super().__init__(env)
def reset(self, **kwargs):
# 每次重置随机化参数
self.env.mass = np.random.uniform(0.5, 1.5) # 随机质量
self.env.length = np.random.uniform(0.8, 1.2) # 随机长度
return self.env.reset(**kwargs)10. 🔮 前沿与展望
10.1 离线强化学习:从历史数据中学习
传统RL需要在线交互,成本高、危险。离线RL直接从历史数据学习,适合金融、医疗等场景。
挑战:分布偏移------历史数据中没有的状态-动作对,智能体不会处理。
解决方案:
-
CQL:保守Q学习,防止对未见数据过估计
-
IQL:隐式Q学习,更稳定的离线算法
python
from stable_baselines3 import CQL
# 离线RL示例
model = CQL(
"MlpPolicy",
env,
buffer_size=1_000_000,
learning_starts=10000,
verbose=1
)
# 从数据集学习
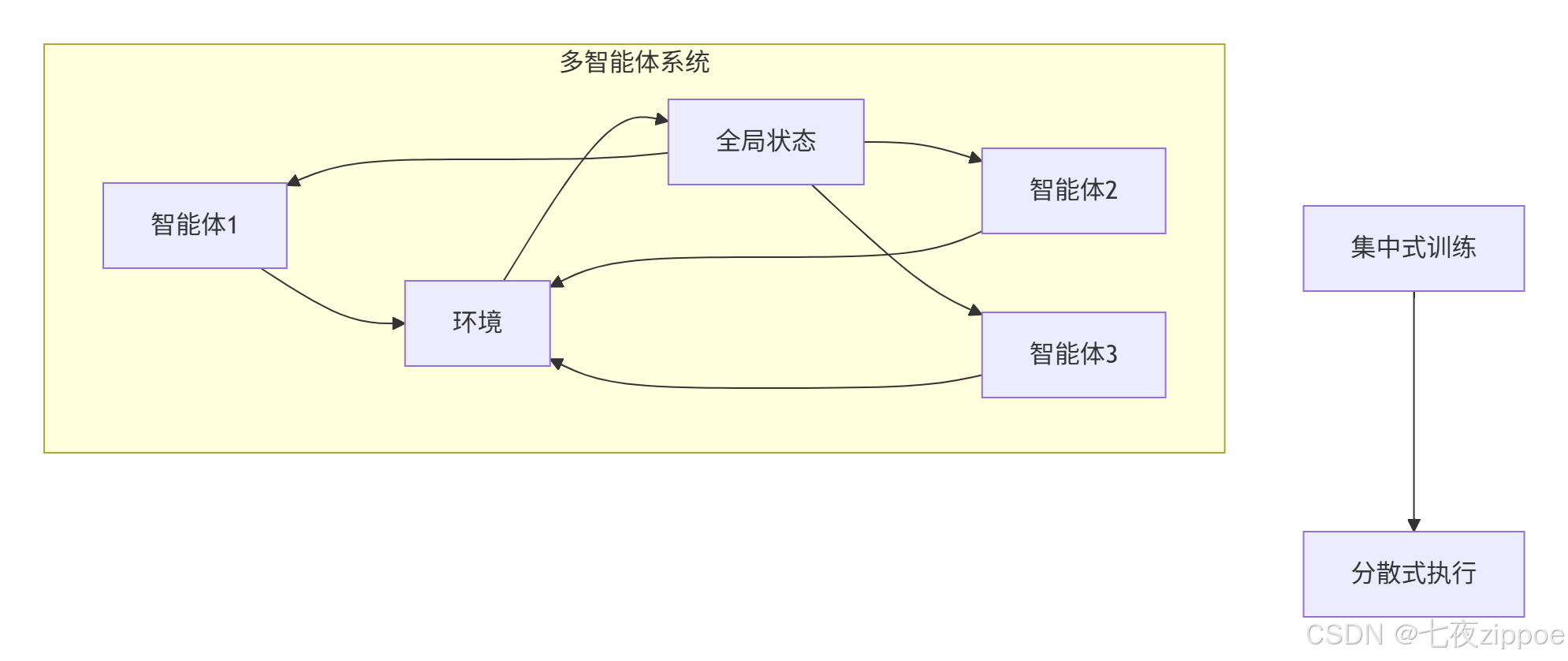
model.learn(total_timesteps=100000, offline=True)10.2 多智能体强化学习:合作与竞争
应用场景:多机器人协作、自动驾驶车队、多玩家游戏。
挑战:环境非平稳------其他智能体也在学习。
算法:
-
MAPPO:多智能体PPO
-
QMIX:值分解,适合合作任务
-
MADDPG:多智能体DDPG
10.3 大语言模型+强化学习:AI智能体
最新趋势:用LLM作为策略网络,处理自然语言指令。
应用:
-
Voyager:Minecraft自动探索
-
SayCan:机器人执行自然语言指令
-
WebGPT:用RL微调GPT进行网页导航
python
# 伪代码:LLM+RL
class LLMAgent:
def __init__(self, llm_model):
self.llm = llm_model
self.memory = [] # 经验记忆
def act(self, state, instruction):
# 用LLM生成动作
prompt = f"状态: {state}\n指令: {instruction}\n动作:"
action = self.llm.generate(prompt)
return action
def learn(self, reward):
# 用RL微调LLM
loss = self.rl_loss(reward)
loss.backward()11. 📊 性能对比与选型指南
11.1 算法选择矩阵
| 场景特征 | 推荐算法 | 理由 | 训练时间 | 样本效率 |
|---|---|---|---|---|
| 离散动作,状态空间小 | DQN | 简单稳定 | 快 | 高 |
| 连续动作,中等复杂度 | PPO | 工业标准 | 中 | 中 |
| 连续动作,高难度 | SAC | 探索能力强 | 慢 | 低 |
| 有历史数据 | CQL | 离线学习 | 快 | 高 |
| 多智能体合作 | MAPPO | 中央训练 | 慢 | 中 |
| 稀疏奖励 | HER | 目标重标记 | 中 | 中 |
11.2 硬件配置建议
| 预算 | CPU | GPU | 内存 | 适合场景 |
|---|---|---|---|---|
| 低(<5k) | 8核 | 无 | 16GB | 经典控制、简单游戏 |
| 中(5k-20k) | 16核 | RTX 4070 | 32GB | Atari游戏、机器人仿真 |
| 高(>20k) | 32核+ | RTX 4090 * 2 | 64GB+ | 大规模多智能体、3D环境 |
经验之谈:对于大多数工业应用,中等配置足够。RL的瓶颈更多是算法和调参,不是算力。
12. 📚 学习资源与进阶路径
12.1 官方文档(必读)
-
**Stable-Baselines3文档** - 最全的示例和API文档
-
**Gymnasium文档** - 环境库,比OpenAI Gym维护更好
-
**Ray RLlib** - 分布式RL框架,适合大规模
-
**OpenAI Spinning Up** - 最好的RL理论教程
-
**Hugging Face RL教程** - 交互式学习网站