在数学建模、学术研究、企业决策中,我们经常面临多准则抉择的难题:比如企业选择合作伙伴要权衡成本、服务、响应速度,产品选型要对比价格、性能、维护成本,项目评估要考量风险、收益、周期......这时,层次分析法(Analytic Hierarchy Process, AHP) 就是破解这类问题的"利器"------它能将模糊的定性判断转化为精准的定量计算,让决策更严谨、更有依据。
本文专为零基础读者打造,融合两篇文档的核心优势,以"企业选择合作伙伴"为实战案例,从原理拆解、Python实操、论文加分技巧到避坑指南,全程干货满满,帮你彻底掌握AHP并灵活运用到学习和工作中。
目录
[1. 核心定义](#1. 核心定义)
[2. 适用场景](#2. 适用场景)
[3. 核心优势](#3. 核心优势)
[Step 1:构建递阶层次结构(论文必画图表!)](#Step 1:构建递阶层次结构(论文必画图表!))
[Step 2:构造判断矩阵(两两比较定重要性)](#Step 2:构造判断矩阵(两两比较定重要性))
[Step 3:一致性检验(避免逻辑矛盾!)](#Step 3:一致性检验(避免逻辑矛盾!))
[Step 4:计算权重(核心输出!)](#Step 4:计算权重(核心输出!))
[Step 5:层次总排序(计算最终得分)](#Step 5:层次总排序(计算最终得分))
[1. 依赖库导入](#1. 依赖库导入)
[2. 核心函数实现](#2. 核心函数实现)
[3. 完整流程调用(基于合作伙伴选择场景)](#3. 完整流程调用(基于合作伙伴选择场景))
[4. 代码运行结果说明](#4. 代码运行结果说明)
[1. 评价体系构建:逻辑闭环](#1. 评价体系构建:逻辑闭环)
[2. 图表规范:专业直观](#2. 图表规范:专业直观)
[3. 数据支撑:避免主观臆断](#3. 数据支撑:避免主观臆断)
[4. 方法严谨:细节拉满](#4. 方法严谨:细节拉满)
[5. 结果分析:结合实际意义](#5. 结果分析:结合实际意义)
[6. 代码附录:体现实操能力](#6. 代码附录:体现实操能力)
一、什么是层次分析法(AHP)?
1. 核心定义
层次分析法是美国运筹学家萨蒂(T.L. Saaty)于20世纪70年代提出的多准则决策方法。核心思想是:将复杂问题拆解为"目标层→准则层→方案层"的递阶层次结构,通过"两两比较"确定各指标的重要性(权重),再通过定量计算得出最终决策结果。
2. 适用场景
-
评价类问题:合作伙伴评估、产品选型、供应商筛选、城市生态环境质量评价等;
-
决策类问题:项目方案优选、政策制定优先级排序、棚户区改造风险评估等;
-
无明确量化指标的问题:需结合专家意见、调研数据的定性+定量分析场景。
3. 核心优势
-
把模糊的"重要性"转化为可计算的权重,避免主观臆断;
-
层次清晰、逻辑严谨,零基础也能快速上手;
-
可操作性强,支持Python、Excel等工具实现,论文中易呈现。
二、AHP核心实操步骤(实战案例:企业选择合作伙伴)
决策目标:某企业选择最优合作伙伴(目标层)
评价准则(准则层):合作成本、服务质量、响应速度、企业口碑
备选方案(方案层):公司A、公司B、公司C
以下一步步拆解从定性判断到定量决策的完整流程。
Step 1:构建递阶层次结构(论文必画图表!)
这是AHP的基础,需明确"三个层次",结构如下:
| 层级 | 含义 | 案例对应内容 |
|---|---|---|
| 目标层(最高层) | 决策的核心目标 | 选择最优合作伙伴 |
| 准则层(中间层) | 影响目标实现的关键指标 | 合作成本、服务质量、响应速度、企业口碑 |
| 方案层(最低层) | 待选择的具体选项 | 公司A、公司B、公司C |
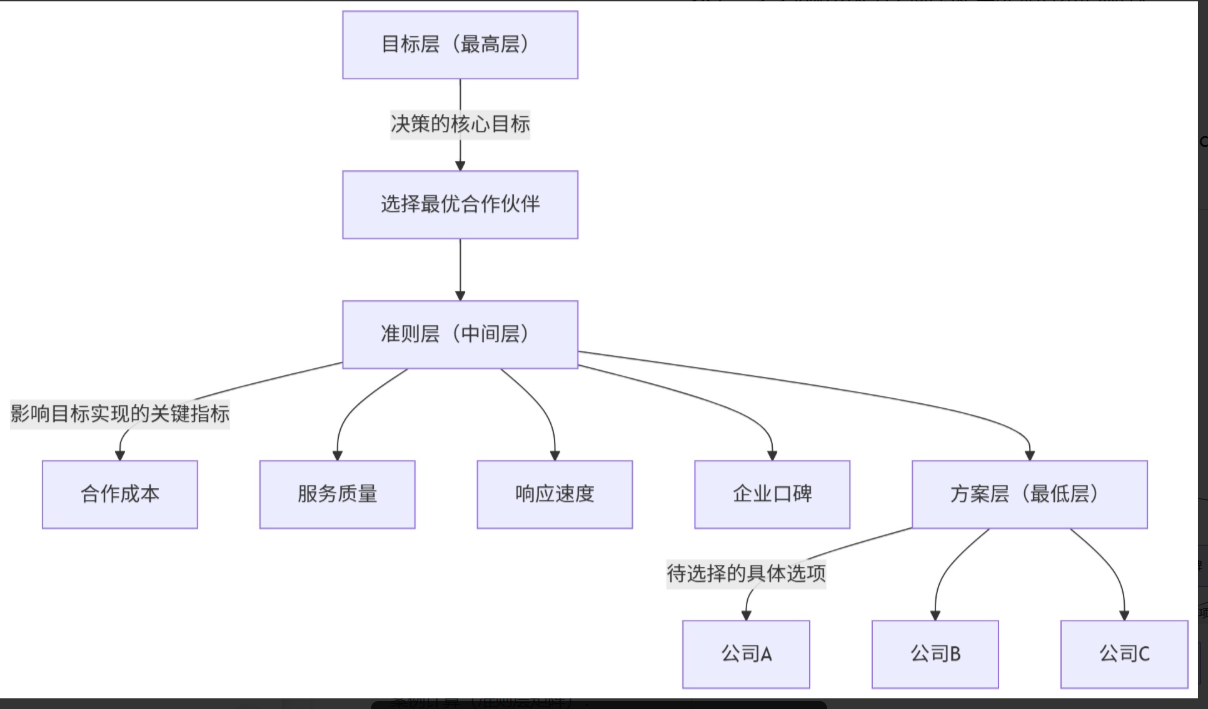
论文加分技巧1:
-
用专业工具绘制层级结构图(推荐ProcessOn、亿图),放在论文"评价体系构建"章节,直观清晰;
-
准则层的选取需有依据:可引用文献(如知网、Web of Science)、专家访谈结果、调查问卷数据,避免凭空捏造(例:参考行业内合作伙伴评价标准,结合企业实际需求,选取4项核心准则,覆盖成本、服务、效率、声誉四大维度)。
Step 2:构造判断矩阵(两两比较定重要性)
准则层各指标的重要性如何?方案层在每个准则下的表现如何?这一步通过"两两比较"解决,核心工具是1-9标度法。
(1)1-9标度法规则(必须熟记)
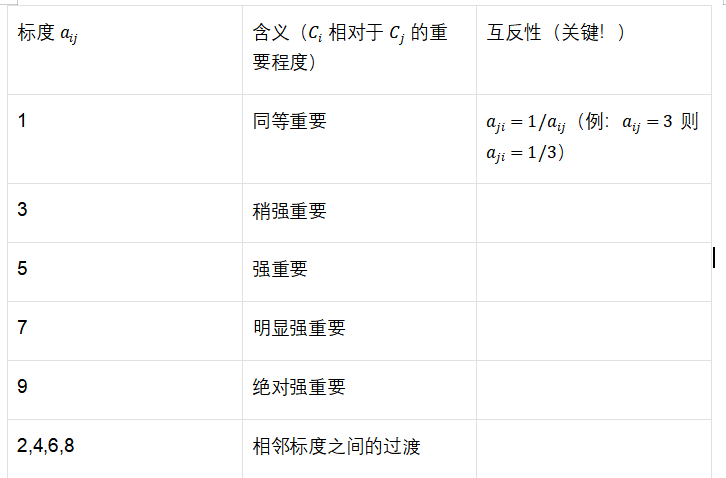
(2)构造两类判断矩阵
-
准则层判断矩阵:比较各准则对目标层的重要性(例:合作成本 vs 服务质量,响应速度 vs 企业口碑);
-
方案层判断矩阵:每个准则下,比较各方案的优劣(例:合作成本准则下,公司A vs 公司B)。
案例:准则层判断矩阵(4×4)
| 合作成本 | 服务质量 | 响应速度 | 企业口碑 | |
|---|---|---|---|---|
| 合作成本 | 1 | 3 | 2 | 4 |
| 服务质量 | 1/3 | 1 | 1/2 | 2 |
| 响应速度 | 1/2 | 2 | 1 | 3 |
| 企业口碑 | 1/4 | 1/2 | 1/3 | 1 |
案例:各准则下方案层判断矩阵(3×3)
- 合作成本准则(数值越小成本越低,重要性越高):
| 公司A | 公司B | 公司C | |
|---|---|---|---|
| 公司A | 1 | 1/2 | 1/3 |
| 公司B | 2 | 1 | 1/2 |
| 公司C | 3 | 2 | 1 |
- 服务质量准则:
| 公司A | 公司B | 公司C | |
|---|---|---|---|
| 公司A | 1 | 3 | 2 |
| 公司B | 1/3 | 1 | 1/2 |
| 公司C | 1/2 | 2 | 1 |
- 响应速度准则:
| 公司A | 公司B | 公司C | |
|---|---|---|---|
| 公司A | 1 | 2 | 4 |
| 公司B | 1/2 | 1 | 3 |
| 公司C | 1/4 | 1/3 | 1 |
- 企业口碑准则:
| 公司A | 公司B | 公司C | |
|---|---|---|---|
| 公司A | 1 | 4 | 3 |
| 公司B | 1/4 | 1 | 1/2 |
| 公司C | 1/3 | 2 | 1 |
论文加分技巧2:
-
列出判断矩阵时,标注数据来源(例:基于15名行业专家、8名企业高管的两两比较打分,取平均值构建判断矩阵);
-
矩阵格式规范:用三线表呈现,标度含义可在表格下方注释,体现专业性。
Step 3:一致性检验(避免逻辑矛盾!)
构造判断矩阵时,可能出现"逻辑矛盾":比如"公司A服务质量比公司B好( a=3 ),公司B比公司C好( a=2 ),但公司A比公司C好( a=2 )"(理论上应为 3×2=6 ,与实际 a=2 矛盾)。此时需要通过一致性检验判断矩阵是否合理。
一致性检验三步法:
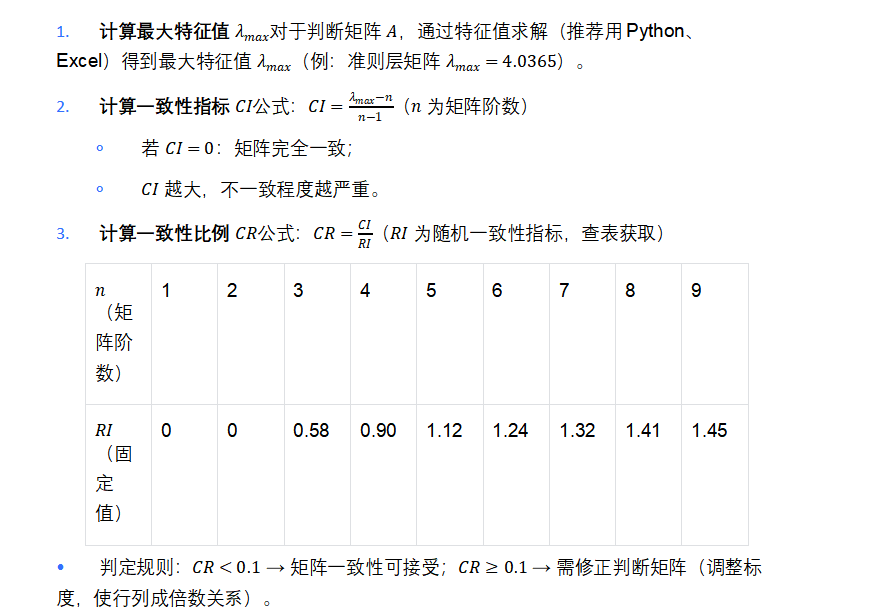

论文加分技巧3:
-
详细写出一致性检验过程(公式+计算步骤+结果),避免只给结论;
-
若矩阵未通过检验,需描述修正过程(例:初始矩阵 CR=0.12 ,通过调整"合作成本-响应速度"的标度从2改为3,修正后 CR=0.09 < 0.1),体现严谨性。
Step 4:计算权重(核心输出!)
权重是各指标/方案的"重要程度占比",AHP中常用两种方法,论文中优先选特征值法(更严谨)。
方法1:算术平均法(简单易操作)
步骤:
-
对判断矩阵每一列归一化(列元素之和为1);
-
对归一化后的矩阵按行求和;
-
再归一化行和,得到权重。
方法2:特征值法(论文首选,Python实现)
步骤:
-
求解判断矩阵的最大特征值 对应的特征向量;
-
对特征向量归一化,得到权重。
两种方法对比(准则层权重结果)
| 准则 | 算术平均法权重 | 特征值法权重(论文推荐) |
|---|---|---|
| 合作成本 | 0.4154 | 0.4167 |
| 服务质量 | 0.1912 | 0.1905 |
| 响应速度 | 0.2654 | 0.2643 |
| 企业口碑 | 0.1280 | 0.1285 |
- 结论:一致性较好时,两种方法结果接近;论文中用特征值法(可标注:采用特征值法计算权重,该方法更适用于非一致性矩阵,符合实际决策场景)。
论文加分技巧4:
-
用Python代码实现权重计算,论文中可附上核心代码(注释清晰),或在附录中给出完整代码;
-
权重结果用表格呈现,标注计算方法(例:表X 各准则权重(特征值法))。
Step 5:层次总排序(计算最终得分)

案例总排序结果(论文核心表格)
| 准则 | 准则权重 | 公司A权重 | 公司B权重 | 公司C权重 |
|---|---|---|---|---|
| 合作成本 | 0.4167 | 0.1667 | 0.2857 | 0.5476 |
| 服务质量 | 0.1905 | 0.5455 | 0.1818 | 0.2727 |
| 响应速度 | 0.2643 | 0.6154 | 0.2564 | 0.1282 |
| 企业口碑 | 0.1285 | 0.6364 | 0.1364 | 0.2272 |
| 最终得分 | - | 0.5238 | 0.2945 | 0.1817 |
- 决策结论:公司A最终得分最高(0.5238),选为最优合作伙伴。
论文加分技巧5:
-
总排序后需做层次总排序一致性检验
-
结果分析需结合实际:例"合作成本是最重要的准则(权重0.4167),说明企业选择合作伙伴时优先控制成本;公司A虽在合作成本准则下权重较低(0.1667),但在服务质量(0.5455)、响应速度(0.6154)、企业口碑(0.6364)三项准则下表现突出,综合得分最高"。
三、Python完整实现代码(可直接运行)
1. 依赖库导入
python
import numpy as np
# 随机一致性指标RI表(n为矩阵阶数)
RI_TABLE = {1: 0.00, 2: 0.00, 3: 0.58, 4: 0.90, 5: 1.12,
6: 1.24, 7: 1.32, 8: 1.41, 9: 1.45, 10: 1.49}2. 核心函数实现
(1)一致性检验函数
python
def consistency_check(matrix):
"""
一致性检验:返回是否通过检验、CI、CR、最大特征值
matrix: 判断矩阵(numpy数组)
"""
n = matrix.shape[0]
# 计算最大特征值和特征向量(取实部避免虚数干扰)
eig_vals, eig_vecs = np.linalg.eig(matrix)
lambda_max = np.max(np.real(eig_vals)) # 最大实特征值
# 计算一致性指标CI
ci = (lambda_max - n) / (n - 1) if n > 1 else 0.00
# 计算一致性比例CR
ri = RI_TABLE.get(n, 1.49) # 超过10阶用1.49
cr = ci / ri if ri != 0 else 0.00
# 判断是否通过(CR<0.1)
is_pass = cr < 0.1
return is_pass, ci, cr, lambda_max(2)权重计算函数(算术平均法+特征值法)
python
def calculate_weight(matrix, method='eigenvalue'):
"""
计算权重向量
matrix: 判断矩阵(numpy数组)
method: 计算方法('arithmetic'为算术平均法,'eigenvalue'为特征值法)
"""
n = matrix.shape[0]
if method == 'arithmetic':
# 算术平均法:列归一化→行求和→归一化
col_normalized = matrix / matrix.sum(axis=0, keepdims=True)
row_sum = col_normalized.sum(axis=1)
weight = row_sum / row_sum.sum()
return weight
elif method == 'eigenvalue':
# 特征值法:最大特征值对应特征向量→归一化
eig_vals, eig_vecs = np.linalg.eig(matrix)
lambda_max = np.max(np.real(eig_vals))
max_eig_vec = np.real(eig_vecs[:, np.argmax(np.real(eig_vals))])
weight = max_eig_vec / max_eig_vec.sum()
return weight
else:
raise ValueError("method仅支持'arithmetic'或'eigenvalue'")(3)层次总排序函数
python
def total_ranking(criterion_weights, scheme_matrices):
"""
层次总排序:计算各方案最终得分
criterion_weights: 准则层权重向量(numpy数组)
scheme_matrices: 各准则下方案层判断矩阵列表(每个元素为numpy数组)
"""
n_schemes = scheme_matrices[0].shape[0]
scheme_weights = []
ci_list = [] # 记录各准则下矩阵的CI,用于总排序一致性检验
# 计算每个准则下方案的权重及CI
for mat in scheme_matrices:
# 一致性检验
is_pass, ci, cr, _ = consistency_check(mat)
ci_list.append(ci)
if not is_pass:
print(f"警告:某准则下方案判断矩阵一致性检验未通过(CR={cr:.4f}),建议调整矩阵")
# 用特征值法计算该准则下方案权重(论文推荐)
w = calculate_weight(mat, method='eigenvalue')
scheme_weights.append(w)
# 层次总排序:准则权重×对应方案权重,求和
scheme_weights = np.array(scheme_weights).T # 转置为(方案数×准则数)
total_scores = np.dot(scheme_weights, criterion_weights)
# 层次总排序一致性检验
ri_list = [RI_TABLE[mat.shape[0]] for mat in scheme_matrices]
total_ci = np.dot(criterion_weights, ci_list)
total_ri = np.dot(criterion_weights, ri_list)
total_cr = total_ci / total_ri if total_ri != 0 else 0.00
print(f"\n层次总排序一致性检验:CR={total_cr:.4f},{'通过' if total_cr < 0.1 else '未通过'}")
return total_scores, scheme_weights, total_cr3. 完整流程调用(基于合作伙伴选择场景)
python
if __name__ == "__main__":
# ---------------------- Step1:构造判断矩阵 ----------------------
# 1. 准则层判断矩阵(合作成本C1、服务质量C2、响应速度C3、企业口碑C4)
criterion_matrix = np.array([
[1, 3, 2, 4], # C1与其他准则的比较
[1/3, 1, 1/2, 2],# C2与其他准则的比较
[1/2, 2, 1, 3], # C3与其他准则的比较
[1/4, 1/2, 1/3, 1]# C4与其他准则的比较
])
# 2. 各准则下方案层判断矩阵(公司A、B、C)
cost_matrix = np.array([[1, 1/2, 1/3], [2, 1, 1/2], [3, 2, 1]]) # 合作成本
service_matrix = np.array([[1, 3, 2], [1/3, 1, 1/2], [1/2, 2, 1]]) # 服务质量
speed_matrix = np.array([[1, 2, 4], [1/2, 1, 3], [1/4, 1/3, 1]]) # 响应速度
reputation_matrix = np.array([[1, 4, 3], [1/4, 1, 1/2], [1/3, 2, 1]]) # 企业口碑
scheme_matrices = [cost_matrix, service_matrix, speed_matrix, reputation_matrix]
criterion_names = ["合作成本", "服务质量", "响应速度", "企业口碑"]
scheme_names = ["公司A", "公司B", "公司C"]
# ---------------------- Step2:准则层权重计算与一致性检验 ----------------------
print("="*60)
print("准则层分析结果(目标:选择最优合作伙伴)")
print("="*60)
is_pass_crit, ci_crit, cr_crit, lambda_max_crit = consistency_check(criterion_matrix)
print(f"准则层判断矩阵最大特征值:{lambda_max_crit:.4f}")
print(f"一致性指标CI:{ci_crit:.4f}")
print(f"一致性比例CR:{cr_crit:.4f}")
print(f"准则层一致性检验{'通过' if is_pass_crit else '未通过'}")
# 计算准则权重(两种方法对比)
weight_arithmetic = calculate_weight(criterion_matrix, method='arithmetic')
weight_eigenvalue = calculate_weight(criterion_matrix, method='eigenvalue')
print("\n准则权重(算术平均法):")
for name, w in zip(criterion_names, weight_arithmetic):
print(f"{name}:{w:.4f}")
print("\n准则权重(特征值法,论文推荐):")
for name, w in zip(criterion_names, weight_eigenvalue):
print(f"{name}:{w:.4f}")
# ---------------------- Step3:层次总排序与结果输出 ----------------------
print("\n" + "="*60)
print("层次总排序结果(各合作伙伴最终得分)")
print("="*60)
total_scores, scheme_weights, total_cr = total_ranking(weight_eigenvalue, scheme_matrices)
# 输出详细结果
print("\n各方案在各准则下的权重(特征值法):")
weight_table = np.hstack([scheme_weights, total_scores.reshape(-1, 1)])
headers = criterion_names + ["最终得分"]
print("-" * 60)
print(f"{'方案':<8}" + "".join([f"{h:<12}" for h in headers]))
print("-" * 60)
for i, name in enumerate(scheme_names):
row_data = [f"{weight_table[i, j]:.4f}" for j in range(weight_table.shape[1])]
print(f"{name:<8}" + "".join([f"{d:<12}" for d in row_data]))
print("-" * 60)
# 排名及最优方案
sorted_scores = sorted(dict(zip(scheme_names, total_scores)).items(), key=lambda x: x[1], reverse=True)
print("\n合作伙伴排名:")
for i, (name, score) in enumerate(sorted_scores, 1):
print(f"第{i}名:{name},最终得分:{score:.4f}")
print(f"\n推荐最优合作伙伴:{sorted_scores[0][0]}")4. 代码运行结果说明
四、AHP在论文中的加分写法(核心干货)
1. 评价体系构建:逻辑闭环
-
开篇说明AHP的适用性:例"本研究需综合考虑成本、服务、效率、声誉4类指标,属于多准则决策问题,层次分析法(AHP)能有效将定性判断转化为定量计算,故采用该方法构建评价体系";
-
准则层选取需参考文献:例"参考XX学者提出的合作伙伴评价指标体系,结合企业实际运营需求,剔除'合作年限'等非核心指标,最终确定4个一级准则"。
2. 图表规范:专业直观
-
层级结构图:用标准化符号(矩形框表示层级,箭头表示隶属关系),标注清晰;
-
判断矩阵、权重表、总排序表:用三线表(Word中"表格样式-三线表"),表头包含"指标/方案""权重""计算方法"等要素;
-
结果可视化:用柱状图展示各方案最终得分,用饼图展示准则层权重分布(推荐Excel、Matplotlib绘制)。
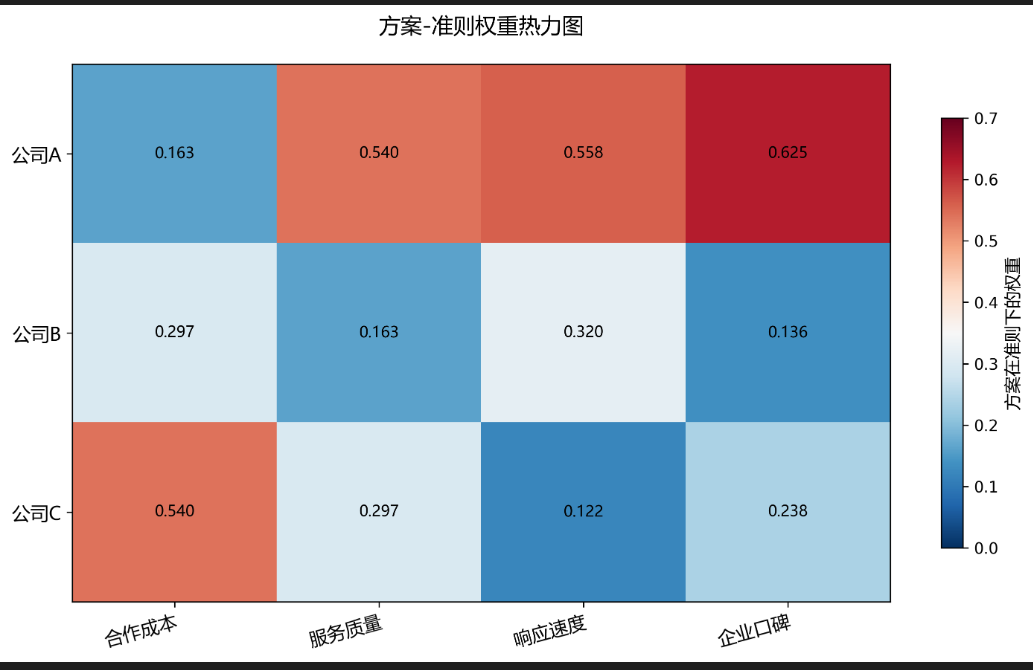
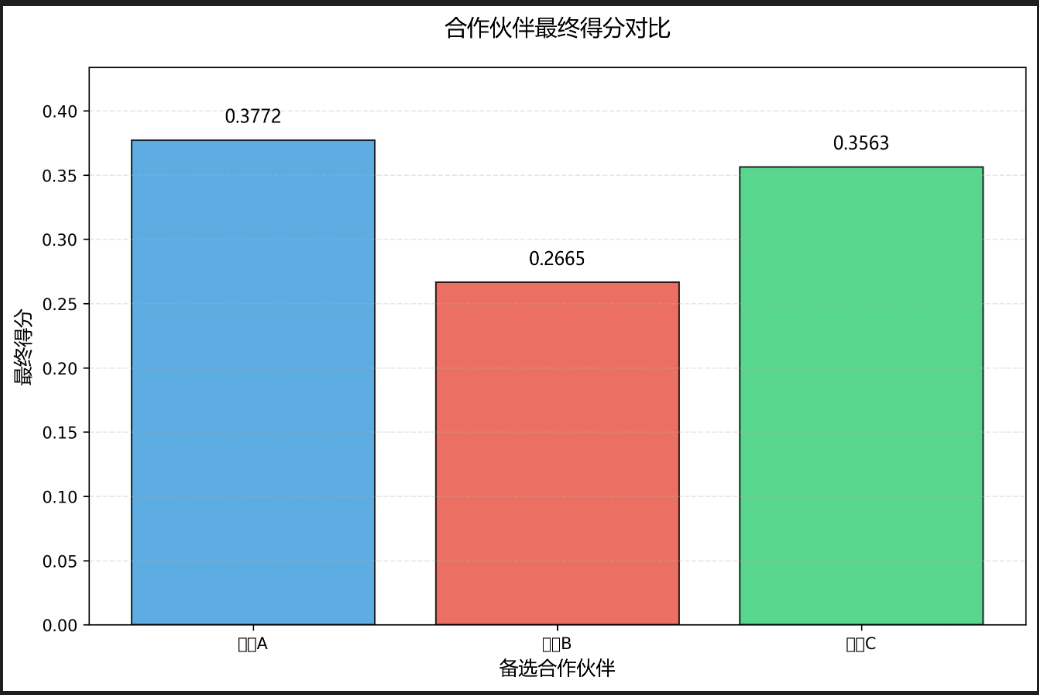
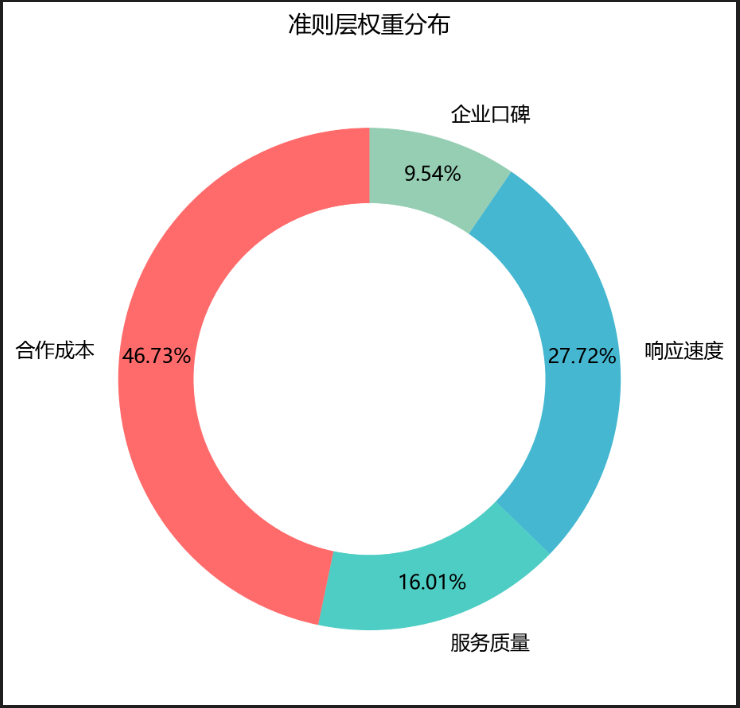
3. 数据支撑:避免主观臆断
-
专家打分:说明专家背景(例:邀请10名从事供应链管理的副教授及以上专家、5名企业采购高管参与两两比较打分);
-
调研数据:若准则层来自问卷,需说明样本量(例:发放调查问卷300份,回收有效问卷278份,有效回收率92.7%);
-
文献引用:标注标度法、权重计算方法的理论依据(例:采用萨蒂(1980)提出的1-9标度法构建判断矩阵,该标度法已被广泛应用于多准则决策领域)。
4. 方法严谨:细节拉满
-
一致性检验:不仅做准则层检验,还需做层次总排序检验,写出完整计算过程;
-
权重计算:对比两种方法(算术平均法+特征值法),说明选择依据;
-
灵敏度分析(进阶加分项):分析准则权重变化对最终结果的影响(例:若合作成本权重增加10%,公司A得分变为0.501,仍为最优方案,说明决策结果稳健)。
5. 结果分析:结合实际意义
-
不要只罗列得分,要解释"为什么":例"合作成本准则权重最高(0.4167),说明企业选择合作伙伴时成本控制是核心诉求;公司C在合作成本准则下表现最优(0.5476),但因服务质量和响应速度不足,综合得分最低";
-
对比其他方法:若条件允许,可与熵权法、TOPSIS法结合(例:采用AHP-熵权法组合赋权,既考虑专家主观判断,又融入数据客观信息,结果更全面)。
6. 代码附录:体现实操能力
-
附录添加Python代码:标注关键函数功能(如"一致性检验函数""层次总排序函数"),体现编程能力;
-
补充可视化代码:用Matplotlib绘制得分对比图,示例:
pythonimport matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] # 支持中文 plt.figure(figsize=(10, 6)) plt.bar(scheme_names, total_scores, color=['#1f77b4', '#ff7f0e', '#2ca02c'], width=0.6) plt.xlabel('备选合作伙伴', fontsize=12) plt.ylabel('最终得分', fontsize=12) plt.title('合作伙伴选择方案得分对比', fontsize=14, fontweight='bold') for i, score in enumerate(total_scores): plt.text(i, score+0.01, f'{score:.4f}', ha='center', fontsize=11) plt.tight_layout() plt.savefig('合作伙伴得分对比图.png', dpi=300, bbox_inches='tight')
五、常见误区与避坑指南
-
准则层指标过多:AHP适用于指标数≤9的场景,过多会导致两两比较逻辑混乱,建议控制在3-7个;
-
忽略一致性检验:直接用未检验的矩阵计算权重,论文易被质疑严谨性;
-
判断矩阵凭空捏造:无专家/调研数据支撑,标度赋值随意,缺乏说服力;
-
只给结果不分析:仅列出得分排名,不解释结果的实际意义,论文深度不足;
-
代码运行报错:确保判断矩阵为正互反矩阵( a*{ij}=1/a*{ji} ,对角线元素为1),且为方阵。
六、总结
层次分析法的核心价值在于"将模糊判断量化",通过本文的合作伙伴选择案例,能清晰看到从准则权重确定到方案得分计算的完整逻辑。掌握Python实现方法和论文呈现技巧,不仅能解决数学建模、企业决策中的实际问题,还能让学术写作更具严谨性和说服力。