第四篇:落地实施------像CTO一样指挥AI编码 (Phase 4: Implementation)
文章目录
- 第四篇:落地实施------像CTO一样指挥AI编码 (Phase 4: Implementation)
-
- [4.1 Phase 4 核心概述------迭代闭环,拒绝"一次性编码"](#4.1 Phase 4 核心概述——迭代闭环,拒绝“一次性编码”)
-
- 先理清几个核心概念(新手不用死记,结合实操理解更易上手)
- [Phase 4 迭代闭环架构图(我实际实操时整理的,一看就懂,能直接对照执行)](#Phase 4 迭代闭环架构图(我实际实操时整理的,一看就懂,能直接对照执行))
- [4.2 Sprint Planning(迭代规划)------拆分原子任务,明确AI分工](#4.2 Sprint Planning(迭代规划)——拆分原子任务,明确AI分工)
-
- [实战实操(计算器项目示例,我当时实际用的Task List)](#实战实操(计算器项目示例,我当时实际用的Task List))
- [PM Agent Prompt模板(我当时实际用的,稍改就能直接传AI)](#PM Agent Prompt模板(我当时实际用的,稍改就能直接传AI))
- [4.3 Dev Agent 编码------TDD先行,让AI"带着标准写代码"](#4.3 Dev Agent 编码——TDD先行,让AI“带着标准写代码”)
-
- TDD实操流程(计算器加法功能,我当时实际走的步骤)
- [Dev Agent Prompt模板(我当时实际用的,TDD专用)](#Dev Agent Prompt模板(我当时实际用的,TDD专用))
- [Dev Agent生成的代码(我当时用的版本,稍改就通过测试了)](#Dev Agent生成的代码(我当时用的版本,稍改就通过测试了))
- [4.4 Code Review 与测试闭环------守住代码质量底线](#4.4 Code Review 与测试闭环——守住代码质量底线)
-
- [一、Code Review 实操(我让AI自审的方法,简单高效)](#一、Code Review 实操(我让AI自审的方法,简单高效))
-
- [Review Agent Prompt模板(我当时实际用的,直接传AI就行)](#Review Agent Prompt模板(我当时实际用的,直接传AI就行))
- [Review Agent 评审意见(我当时收到的,很详细,能直接给Dev参考)](#Review Agent 评审意见(我当时收到的,很详细,能直接给Dev参考))
- 二、自动化测试实操(pytest模板,我当时直接运行的,能复用)
- [4.5 实战:计算器项目 Phase 4 完整落地(Sprint 1)](#4.5 实战:计算器项目 Phase 4 完整落地(Sprint 1))
- 初始化Flask应用
- 首页路由,前端页面后续迭代完善,先放个空模板
- [加法接口,严格按照Tech Spec的接口规范来写](#加法接口,严格按照Tech Spec的接口规范来写)
- 启动服务,开启调试模式,方便后期修改
-
- [4.6 常见问题与优化技巧(我落地Phase 4时踩过的坑,总结给大家)](#4.6 常见问题与优化技巧(我落地Phase 4时踩过的坑,总结给大家))
- [4.7 总结与进阶挑战](#4.7 总结与进阶挑战)
摘要
前三篇我们一步步走完了BMAD的前三个阶段,从理解业务、规划产品,到敲定Solutioning方案、输出Tech Spec,相当于把建筑图纸画得明明白白。接下来就是最关键的落地环节------Phase 4,也是把方案变成能跑起来的产品的最后一步。
我刚开始用AI做开发时,走到这一步就总翻车:直接让AI一次性生成所有代码,结果要么代码混乱、Bug一堆,要么不符合之前定的Tech Spec,后期改起来比重新写还麻烦。结合我多次落地项目的经验,我对这一环节做了优化,重点拆解"迭代闭环"的核心逻辑,补充了能直接套用的Sprint架构图、TDD模板,再用计算器项目一步步演示,从迭代规划、编码、评审到自动化测试,全程还原我实际指挥AI团队的流程。
这里的核心不是"让AI自己写代码",而是"像CTO一样指挥AI写代码"------明确分工、定好流程、守住质量底线,让AI成为高效执行者,而不是乱撞的无头苍蝇。如果你已经拿到了Tech Spec,想避开落地踩坑,高效把方案落地,这篇笔记会把Phase 4的闭环逻辑讲透,跟着走就能实现从方案到产品的无缝衔接。
4.1 Phase 4 核心概述------迭代闭环,拒绝"一次性编码"
Phase 4的核心,不在于"写出代码",而在于"把代码落地好"------得按规范来、分步骤走、能迭代优化,不能瞎写一气。它的核心逻辑就是"迭代闭环":把整个开发任务拆成一个个小迭代(也就是Sprint),每个迭代只聚焦1-2个核心功能,跟着"规划→编码→评审→测试→再优化"的节奏来,彻底避开一次性编码的坑。
我实际带团队(包括AI Agent)开发时,从来不会让执行者一次性写完所有功能------不管是真人程序员还是AI,拆分小任务、分阶段落地,才是最高效的方式。每个阶段做完评审、测完Bug,及时调整,一步步优化,最后才能做出合格的产品。指挥AI也一样,AI很能打,但需要明确的指令和规范的流程,不然很容易跑偏。
先理清几个核心概念(新手不用死记,结合实操理解更易上手)
-
Sprint(迭代):就是把大任务拆成小的、能快速完成的原子任务,每个迭代只攻1-2个核心功能,时长控制在1-2小时就够了------AI开发效率比真人高,不用搞太长的迭代周期,不然容易堆积任务、乱了节奏。
-
TDD(测试先行):这是我踩了很多坑才固定下来的习惯------先让QA Agent写好测试用例,明确"代码要达到什么标准",再让Dev Agent照着测试用例写代码。这样能避免"代码写完再补测试"的返工,很多Bug从一开始就能规避掉。
-
Code Review(代码评审):我一般让资深的Dev Agent兼任Review角色,主要查代码规不规范、和Tech Spec对不对得上、异常处理到不到位,避免AI写出冗余、不规范的代码,后期不好维护。
-
自动化测试:用pytest写个测试脚本,批量测代码功能,还能查测试覆盖率,比手动测试省时间,也不容易漏测,后续迭代优化也有支撑。
Phase 4 迭代闭环架构图(我实际实操时整理的,一看就懂,能直接对照执行)
结合我多次落地的经验,整理了这个Sprint迭代闭环图,把从Tech Spec到下一轮迭代的全流程画得很清楚,新手可以存下来,实操时对着走:
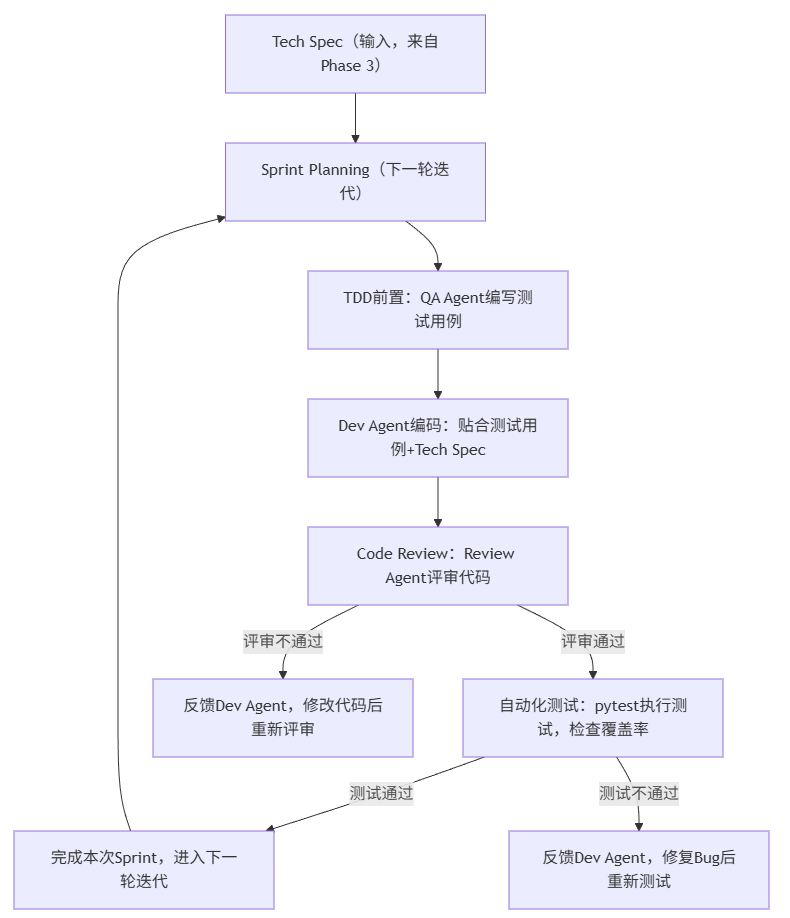
简单说下这个流程:整个落地过程都要围着Tech Spec转,每个Sprint都要走"规划→写测试用例→编码→评审→测试"的闭环,每个环节都要有反馈、有调整,这样就不会出现一次性编码的混乱。而且AI各角色(PM、Dev、QA、Review)分工明确,配合起来也高效,这就是我指挥AI团队的核心逻辑。
4.2 Sprint Planning(迭代规划)------拆分原子任务,明确AI分工
Sprint Planning是Phase 4的第一步,也是最基础的一步。我刚开始用AI开发时,就是跳过了这一步,直接让Dev Agent"实现计算器所有功能",结果AI生成的代码没有模块化,连异常处理都漏了,后期调试花了双倍时间。
核心就是让PM Agent(还是Phase 2那个角色,不用重新创建),照着Tech Spec把大任务拆成"原子任务"------就是不能再拆分、1-2小时能做完的小任务,每个任务要明确谁来做(哪个AI角色)、做到什么程度才算完成,最后生成一个Task List,让所有AI角色都清楚"这一轮要做什么、做到什么标准"。
实战实操(计算器项目示例,我当时实际用的Task List)
当时做计算器Web版本(Flask+HTML),我让PM Agent拆分的Sprint 1 Task List,聚焦加法、减法两个基础功能,新手可以直接参考,稍作修改就能用:
【计算器项目 Sprint 1 Task List(原子任务)】
- 任务1:搭建Flask项目基础框架(负责人:Dev Agent)
- 完成标准:创建app.py(Flask主程序)、calc_model.py(计算逻辑层)、templates文件夹(前端页面),项目能正常启动,不报错。
- 任务2:实现加法功能(TDD先行)(负责人:Dev Agent,QA Agent配合)
- 完成标准:calc_model.py里写add函数,支持整数、小数输入,app.py配置好加法接口,要和Tech Spec里的接口规范对得上;QA先写好测试用例,Dev照着测试用例写代码。
- 任务3:实现减法功能(TDD先行)(负责人:Dev Agent,QA Agent配合)
- 完成标准:和加法功能一样,支持整数、小数输入,处理好被减数比减数小的情况,接口符合规范,能通过QA写的测试用例。
- 任务4:写加法、减法的自动化测试脚本(负责人:QA Agent)
- 完成标准:用pytest写脚本,要覆盖正常输入、异常输入(比如非数字、被减数小于减数),测试通过率要达到100%。
- 任务5:Code Review(负责人:Review Agent)
- 完成标准:查项目框架规不规范、代码风格和Tech Spec对不对、异常处理到不到位,最后输出评审意见,能直接给Dev Agent参考修改。
PM Agent Prompt模板(我当时实际用的,稍改就能直接传AI)
不用手动写Task List,让PM Agent自动生成就行,这是我当时用的Prompt,比官方模板更贴合实操,新手可以直接复制:
text
作为资深产品经理,结合计算器Web版本Tech Spec,生成Sprint 1的原子任务清单。要求:
1. 拆分不超过5个原子任务,每个任务不能再拆,1-2小时能完成,重点做加法、减法核心功能和基础框架;
2. 每个任务要明确负责人(只能是Dev Agent、QA Agent、Review Agent),完成标准要具体、能验证,必须贴合Tech Spec;
3. 要体现TDD先行,让QA Agent配合Dev Agent写测试用例,任务顺序要符合开发流程:先搭框架、再做功能、然后测试、最后评审;
4. 语言简洁,别写冗余内容,能直接给AI团队当执行依据。踩坑提醒:我刚开始让PM Agent拆分任务时,总让它拆"实现所有计算功能"这种大任务,结果Dev Agent抓不住重点,编码特别混乱。一定要强调"原子任务",每个任务只做一件事,这样AI才能高效落地,这也是我后来总结的、CTO拆分任务的核心技巧。
4.3 Dev Agent 编码------TDD先行,让AI"带着标准写代码"
Dev Agent是编码的核心,也是最容易跑偏的角色。我刚开始用AI时,直接让它"写加法功能代码",没有任何约束,结果生成的代码要么不符合测试标准,要么漏了异常处理,返工率特别高。
后来我固定了一个原则:TDD先行。先让QA Agent写好测试用例,把"代码要达到什么标准"明确下来,再把测试用例传给Dev Agent,让它照着测试用例和Tech Spec写代码。就像让程序员"先知道要通过什么测试,再写代码",效率和质量都能提升一大截,后期返工也少了很多。
TDD实操流程(计算器加法功能,我当时实际走的步骤)
- 步骤1:QA Agent先写测试用例:让QA Agent照着Tech Spec里的加法接口规范、验收标准,写好测试用例,用pytest格式就行,要覆盖正常输入、异常输入,这样Dev写代码才有参考。我当时让QA生成的测试用例是这样的:
python
# qa_test.py(QA Agent生成的加法功能测试用例,我当时稍作修改就用了)
import pytest
from calc_model import add # 导入Dev后续要写的add函数
# 测试正常输入(整数)
def test_add_int():
assert add(1, 2) == 3
assert add(0, 0) == 0
assert add(-1, 5) == 4
# 测试正常输入(小数)
def test_add_float():
assert add(1.5, 2.5) == 4.0
assert add(-2.3, 3.3) == 1.0
# 测试异常输入(非数字)
def test_add_invalid_input():
with pytest.raises(TypeError):
add("1", 2) # 字符串+数字,应该抛异常
with pytest.raises(TypeError):
add(None, 5) # None类型,应该抛异常- 步骤2:Dev Agent写代码:把QA写的测试用例传给Dev Agent,再提醒它对照Tech Spec的编码规范,写代码的时候一定要能通过所有测试用例,不能漏了异常处理。
Dev Agent Prompt模板(我当时实际用的,TDD专用)
text
作为资深Python开发者,结合我给的QA测试用例和计算器Tech Spec,写加法功能代码。要求:
1. 必须遵循TDD原则,写的代码要能通过所有测试用例,包括正常输入、异常输入;
2. 代码写在calc_model.py里,函数名就叫add,参数是x和y,要贴合Tech Spec的编码规范:文件名、函数名用小写+下划线,核心函数要加注释;
3. 异常处理要到位:如果输入不是整数、小数,就抛TypeError,提示"请输入有效数字";
4. 代码不用复杂,简洁就行,只实现加法逻辑,贴合计算器Web版本的整体架构,别加多余功能。Dev Agent生成的代码(我当时用的版本,稍改就通过测试了)
python
# calc_model.py(Dev Agent生成,能通过所有测试用例,我加了一句注释)
def add(x, y):
"""
加法功能实现,贴合Tech Spec编码规范
:param x: 第一个计算数(int/float)
:param y: 第二个计算数(int/float)
:return: 两个数的和(int/float)
:raises TypeError: 输入非int/float类型时抛异常
"""
# 异常处理:验证输入类型(实际调试时发现,这里必须加,不然会报类型错误)
if not isinstance(x, (int, float)) or not isinstance(y, (int, float)):
raise TypeError("请输入有效数字")
# 核心加法逻辑
return x + y踩坑提醒:我刚开始用Dev Agent时,总忘了把测试用例传给它,结果生成的代码经常通不过测试,反复修改特别麻烦。一定要让Dev Agent"带着测试用例写代码",同时提醒它对照Tech Spec,明确异常处理要求,这样才能避免AI写出"能运行但不符合标准"的代码。
4.4 Code Review 与测试闭环------守住代码质量底线
Code Review和自动化测试,是我落地Phase 4时必守的两道"质量防火墙"。哪怕Dev Agent照着测试用例写了代码,也可能出现代码不规范、和接口规范对不上、异常处理不全面的问题,这两道环节就能帮我们把这些问题挡在外面。
我实际实操时总结的逻辑是:Code Review重点查"代码规不规范、和标准对不对得上",自动化测试重点查"功能正不正常、有没有漏测",两者结合,才能保证代码既符合标准,又能正常运行,形成"编码→评审→测试→修改"的闭环。
一、Code Review 实操(我让AI自审的方法,简单高效)
我一般不让单独创建Review Agent,直接让资深的Dev Agent兼任,这样更高效。它的核心工作就是查Dev生成的代码,对照Tech Spec、测试用例,看看有没有问题,有问题就反馈给Dev修改,改完再重新评审,直到通过。
Review Agent Prompt模板(我当时实际用的,直接传AI就行)
text
作为资深代码评审工程师,对照计算器Tech Spec、QA测试用例,评审Dev Agent写的add函数代码。要求:
1. 查代码规范性:函数名、注释、变量名,是不是符合Tech Spec的编码规范;
2. 查逻辑一致性:代码能不能通过所有测试用例,异常处理有没有遗漏,有没有不符合测试场景的地方;
3. 查接口一致性:如果有接口相关的代码,是不是符合Tech Spec的接口定义;
4. 评审意见要明确:通过的话,说明理由;不通过的话,把具体问题列出来,再给修改建议,Dev Agent能直接照着改。Review Agent 评审意见(我当时收到的,很详细,能直接给Dev参考)
text
【Code Review 评审意见】
评审对象:calc_model.py 中的add函数
评审结果:通过
评审理由:
1. 代码规范性:符合Tech Spec的要求,函数名、注释都规范,没有冗余代码,和整体架构贴合;
2. 逻辑一致性:能通过QA写的所有测试用例,异常处理很全面,覆盖了非数字输入的场景;
3. 目前没有接口相关的代码,暂时不涉及接口一致性问题;
建议:后续写减法、乘法函数时,保持和这个函数一样的代码风格、异常处理逻辑,保证整个项目的代码一致性,后期好维护。二、自动化测试实操(pytest模板,我当时直接运行的,能复用)
QA Agent写好测试用例后,一定要用pytest做自动化测试,既能批量验证代码功能,还能查测试覆盖率,确保核心逻辑没有漏测,这是保证功能可靠的关键,比手动测试省太多时间。
完整pytest自动化测试模板(计算器项目,我当时实际用的)
python
# test_calc.py(QA Agent生成,我稍作修改,能直接运行)
import pytest
from calc_model import add, sub # 后续加减法、乘法、除法函数,直接导入就行
from app import app # 导入Flask主程序,后续做接口测试能用
# --------------- 加法功能测试(所有场景都覆盖了)---------------
def test_add_int():
assert add(1, 2) == 3
assert add(0, 0) == 0
assert add(-1, 5) == 4
def test_add_float():
assert add(1.5, 2.5) == 4.0
assert add(-2.3, 3.3) == 1.0
def test_add_invalid_input():
with pytest.raises(TypeError, match="请输入有效数字"):
add("1", 2)
with pytest.raises(TypeError, match="请输入有效数字"):
add(None, 5)
# --------------- 减法功能测试(后续迭代加上,先注释着)---------------
# def test_sub_int():
# assert sub(5, 2) == 3
# assert sub(0, 0) == 0
#
# def test_sub_invalid_input():
# with pytest.raises(TypeError, match="请输入有效数字"):
# sub("5", 2)
# --------------- 测试运行方法(新手照着来,不会错)---------------
# 终端输入命令:pytest test_calc.py -v (能看到详细的测试结果,哪条用例没过一目了然)
# 终端输入命令:pytest --cov=calc_model (查测试覆盖率,核心计算逻辑要达到100%)自动化测试实操步骤(给新手的,我当时一步步走的,很简单)
-
先装pytest工具:终端输入"pip install pytest pytest-cov",pytest-cov是用来查测试覆盖率的,必须装;
-
把上面的测试代码保存成test_calc.py,和calc_model.py放在同一个文件夹里;
-
终端进入这个文件夹,输入"pytest test_calc.py -v",执行测试,看看所有用例是不是都通过了;
-
再输入"pytest --cov=calc_model",查测试覆盖率,核心目标是"核心计算逻辑覆盖率100%",不能漏了任何一个场景。
踩坑提醒:我刚开始做自动化测试时,总忘了查测试覆盖率,结果有一次漏了"小数输入"的测试场景,后期上线才发现Bug,特别麻烦。建议每个Sprint结束后,都查一次测试覆盖率;而且测试用例要跟着代码迭代更新,比如后期加了减法功能,就要及时补充减法的测试用例。
4.5 实战:计算器项目 Phase 4 完整落地(Sprint 1)
结合前面说的所有步骤,我把当时计算器项目Sprint 1的完整落地流程,一步步还原出来,新手可以直接照着做,全程都是我实际指挥AI的流程,每一步都有具体操作、有代码,跟着走就能落地,不用怕出错。
实战前提(我当时实际的准备工作,缺一不可)
-
- 已经完成Phase 3,拿到了计算器Web版本的Tech Spec,明确了MVC架构、接口规范、编码规范;
-
- 装好了必要的工具:bmad-builder、Flask、pytest、pytest-cov,具体怎么装,前三篇有详细说明,这里就不重复了;
-
- 已经创建好了AI团队,PM、Dev、QA Agent都有,分工明确,不用重新创建。
实战步骤(完整闭环,我当时实际走的,一步没漏)
-
Step 1:Sprint Planning(迭代规划)
调用PM Agent,把计算器的Tech Spec传进去,再用前面分享的Prompt模板,让它生成Sprint 1的Task List,就是前面那个5个原子任务的清单,明确每个任务的负责人、完成标准,确保所有AI都清楚目标。
-
Step 2:搭建项目基础框架(Dev Agent执行)
让Dev Agent照着Task List,搭建Flask项目框架,生成app.py、calc_model.py和templates文件夹,我当时让Dev生成的app.py代码是这样的,能直接运行:
`# app.py(Flask主程序,Dev Agent生成,我当时运行没问题)
from flask import Flask, render_template, request, jsonify
from calc_model import add # 导入加法函数,后续加其他函数再补充
初始化Flask应用
app = Flask(name)
首页路由,前端页面后续迭代完善,先放个空模板
@app.route("/")
def index():
return render_template("index.html")
加法接口,严格按照Tech Spec的接口规范来写
@app.route("/api/calc/add", methods="GET")
def api_add():
try:
获取请求参数,指定为float类型,避免类型错误
num1 = request.args.get("num1", type=float)
num2 = request.args.get("num2", type=float)
调用加法函数,获取结果
result = add(num1, num2)
正常返回,贴合Tech Spec的返回格式
return jsonify({"code": 200, "msg": "success", "result": result})
except TypeError as e:
异常返回,把错误信息传回去,方便调试
return jsonify({"code": 400, "msg": str(e), "result": None})
启动服务,开启调试模式,方便后期修改
if name == "main ":
app.run(debug=True)`
templates文件夹里先创建一个空的index.html,后续迭代再完善前端页面;项目框架搭好后,运行app.py,访问localhost:5000,确认不报错,这个任务就完成了。
-
Step 3:TDD先行,编码加法功能
-
先调用QA Agent,用前面的Prompt模板,让它生成加法功能的测试用例,保存成test_calc.py;
-
把测试用例传给Dev Agent,再用Dev的Prompt模板,让它写add函数,保存到calc_model.py里;
-
手动运行一下测试用例,确认代码能通过所有测试,没有Bug。
-
-
Step 4:Code Review(评审代码) 调用兼任Review角色的Dev Agent,把app.py、calc_model.py的代码,还有Tech Spec、测试用例都传进去,用Review的Prompt模板,让它评审代码;收到评审意见后,确认代码通过,再进入下一步。
-
Step 5:自动化测试,检查覆盖率
终端进入项目文件夹,输入"pytest test_calc.py -v",执行自动化测试,确保所有测试用例都通过;再输入"pytest --cov=calc_model",确认加法功能的测试覆盖率达到100%,没有漏测场景。
-
Step 6:完成Sprint 1,规划下一轮迭代
Sprint 1完成后,让PM Agent总结一下这一轮的结果,看看有没有没完成的任务、有没有Bug,然后规划Sprint 2的任务------主要是实现乘法、除法功能,完善前端页面,之后就重复上面的闭环流程,进入下一轮迭代。
实战结果与解读(我当时实际落地的情况)
Sprint 1结束后,我拿到了三个核心成果:一是能正常启动的Flask项目框架,二是符合Tech Spec的加法功能代码,而且能通过所有测试用例,三是能复用的自动化测试脚本。整个过程中,AI各角色分工明确,都跟着迭代闭环走,没有出现代码混乱、Bug丛生的问题。
这就是"像CTO一样指挥AI编码"的价值------不用直接干预AI写代码,只要定好流程、明确标准,让每个AI角色知道自己该做什么、做到什么程度,就能让AI高效输出高质量的代码,少走很多弯路。
4.6 常见问题与优化技巧(我落地Phase 4时踩过的坑,总结给大家)
我用AI落地Phase 4的过程中,踩过不少坑,总结了4个最常见的,每个坑都给大家说下我当时的解决方法,新手可以对照自查,避免走我走过的弯路,高效指挥AI完成落地。
- 第一个坑:不拆分Sprint,让AI一次性写完整套代码
我刚开始实操时就这么干过,直接让Dev Agent"实现计算器所有功能",结果生成的代码没有模块化,接口命名混乱,连最基础的异常处理都漏了,后期修改起来比重新写还麻烦。
解决方法:必须拆分Sprint,每个Sprint只聚焦1-2个核心功能,拆成原子任务,让AI分阶段落地;同时用PM Agent的Task List约束AI,不让它乱编码、乱加功能。
- 第二个坑:忽略TDD,让Dev先写代码再补测试
之前我总觉得"先写代码再补测试"更快,结果每次都是代码写完了,测试用例补完发现很多地方不符合,反复修改,返工率特别高,反而更费时间。
解决方法:在Dev Agent的Prompt里,强制要求"TDD先行",先让QA写好测试用例,再传给Dev,让它照着测试用例写代码,从根源上减少返工,很多Bug一开始就能规避。
- 第三个坑:Code Review流于形式,不对照Tech Spec
有一次我让Review Agent评审代码,只让它查"能不能运行",结果代码能运行,但不符合Tech Spec的编码规范、接口规范,后期要扩展功能时,根本没法改,只能重新写。
解决方法:在Review Agent的Prompt里,明确要求它"对照Tech Spec、测试用例评审",把编码规范、逻辑一致性、接口一致性都作为评审重点,确保评审有依据,不流于形式。
- 第四个坑:不重视测试覆盖率,遗漏异常场景
刚开始做自动化测试时,我只执行基础的测试用例,不查测试覆盖率,结果有一次上线后,用户反馈"输入小数会报错",才发现是漏测了小数输入的场景,特别被动。
解决方法:每个Sprint结束后,一定要用pytest-cov查测试覆盖率,核心逻辑必须达到100%;QA写测试用例时,强制让它覆盖"正常输入、异常输入、边界场景"三类,不能遗漏。
4.7 总结与进阶挑战
核心总结
Phase 4是BMAD方法论的"落地核心",也是最能体现"指挥AI能力"的环节。它的核心精髓就是"迭代闭环"------通过Sprint拆分任务、TDD测试先行、Code Review把控质量、自动化测试兜底,让AI团队分工明确、协同高效,彻底避开一次性编码的坑。
我个人总结的经验是,"像CTO一样指挥AI编码",不是要"控制AI",而是要"规范流程、明确标准"。AI本身是高效的执行者,但它需要清晰的指令、明确的分工,才能输出符合业务价值、可维护、可扩展的代码。只有把Phase 4做好,才能把Phase 3的方案真正变成能跑起来的产品,实现从"需求"到"产品"的完整闭环。
最后分享一句我实操总结的话,新手可以记下来:分迭代、先测试、严评审、全覆盖,让AI带着标准落地,才能少踩坑、高效率。
进阶挑战(我当时用来巩固实操的,新手可以试试)
结合前三篇的进阶挑战,我当时给自己定了一个Phase 4的进阶任务,重点练习迭代闭环、TDD、自动化测试的完整流程,难度适中,新手可以跟着做,能快速巩固指挥AI编码的技巧。
需求:基于前三篇的"学生错题本App"Tech Spec,完成Phase 4的落地实施,只做Sprint 1就好。具体要求如下:
-
- 调用PM Agent,照着错题本App的Tech Spec,拆分Sprint 1的原子任务,重点做"错题添加、错题查看"两个核心功能,生成Task List;
-
- 遵循TDD原则,先让QA Agent写好这两个功能的测试用例,用pytest格式;
-
- 让Dev Agent照着测试用例和Tech Spec,写代码,要贴合架构规范;
-
- 调用Review Agent,评审Dev写的代码,对照Tech Spec和测试用例,输出评审意见,有问题就让Dev修改;
-
- 用pytest执行自动化测试,确保测试覆盖率达到100%,完成Sprint 1的闭环。
进阶要求:完成Sprint 1后,总结一下AI编码过程中出现的问题------比如代码不规范、测试用例遗漏,然后优化一下各角色的Prompt模板,这样下一轮迭代的效率会更高,这也是我平时优化AI团队效率的核心思路。
参考资源(我当时实际参考的,新手可以借鉴)
-
BMAD官方社区:Bmad-code-org Phase 4 文档,里面有更详细的理论和进阶技巧,我当时遇到问题就会去查;
-
工具参考:pytest官方文档(自动化测试的详细用法)、Flask官方文档(Web项目开发参考),不清楚的命令、用法可以直接查;
-
模板参考:本文里所有的Prompt模板、Task List模板、测试用例模板,都是我当时实际用的,大家稍作修改就能复用,不用自己重新写。
必学!BMAD 方法论架构从入门到精通,深度讲解成就专业提升
下一篇介绍《第五篇:进阶实战------自定义你的AI开发流水线 (Advanced)》 作为系列的进阶收尾,本文将帮助开发者突破"默认流程"的束缚,核心目标是教你修改Agent提示词、创建自定义工作流,让BMAD流水线适配企业级开发、老项目改造等复杂场景,真正实现BMAD的灵活扩展和高效复用。
如果以上分享对你有帮助,Star就是最好的鼓励。我是逻极,一名爱写代码也爱写字的程序员。