在导入数据表之前,需要先根据数据表结构创建对应的es索引。
环境说明:
因工作环境的原因,本文基于以下环境完成:
(1)Linux系统:openEuler、Ubuntu
(2)Elasticsearch集群:8.14.0,安装与配置过程详见https://blog.csdn.net/u013007181/article/details/158008344
(3)kibana:8.14.0,安装与配置过程详见上述链接
(4)MariaDB:5.5.5-10.4.22
(5)JDK:openjdk 17.0.18
一、安装logstash
以logstash-9.3.0,并安装到/usr/local/logstash/logstash-9.3.0目录中为例
以root身份创建logstash用户组和用户账号,并创建安装目录/usr/local/logstash。
bash
# 创建logstash普通用户账号
groupadd logstash && mkdir /home/logstash && useradd -m -g logstash -d /home/logstash -s /bin/bash logstash
# 创建安装目录并授权
mkdir /usr/local/logstash && cd /usr/local/logstash && chown -R logstash:logstash /usr/local/logstash
# 为logstash设置登录密码
passwd logstash以logstash账号登录系统,并以logstash账号身份完成以下操作。
bash
# 下载安装包
wget https://artifacts.elastic.co/downloads/logstash/logstash-9.3.0-linux-x86_64.tar.gz
# 解压安装包
tar -xzf logstash-9.3.0-linux-x86_64.tar.gz解压后,logstash就安装完成了。
二、下载JDBC connector
需要下载相应的 JDBC connector。针对我的情况,我在地址MySQL :: Download Connector 下载合适的 Connector,MariaDB 5.5或MySQL 5.7建议下载mysql-connector-java-5.1.49.tar.gz。如下图所示。
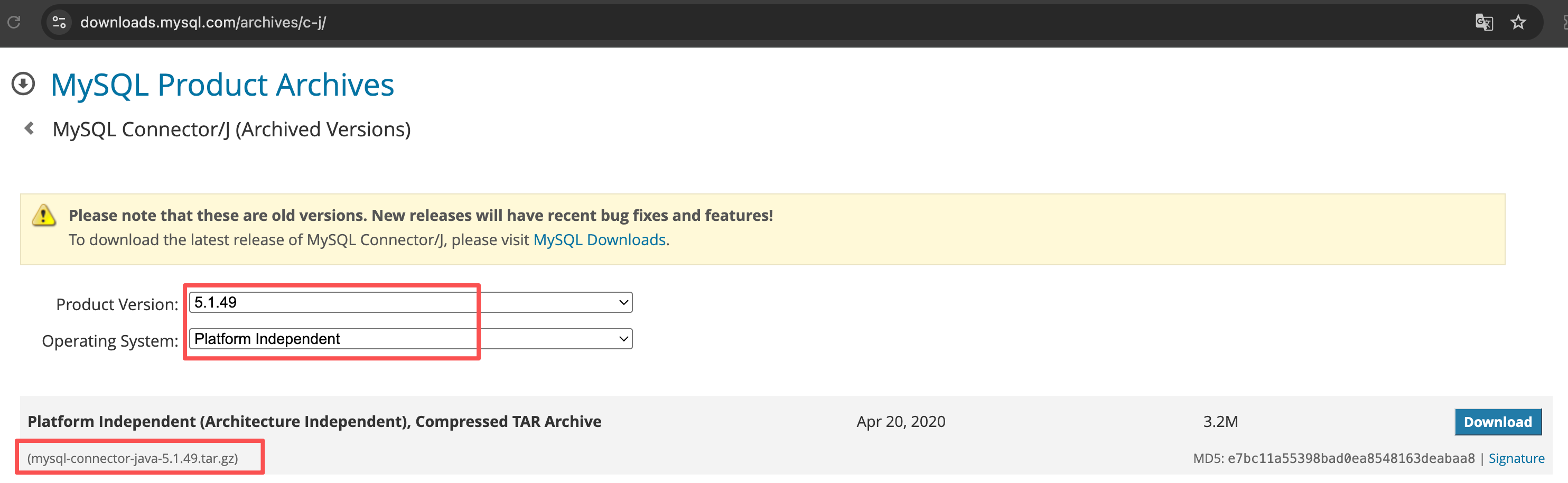
下载完这个 Connector后,解压并复制文件mysql-connector-java-5.1.49.jar到 /usr/local/logstash/logstash-9.3.0/logstash-core/lib/jars目录下。
bash
# 解压
tar -xzf logstash-9.3.0-linux-x86_64.tar.gz
# 复制文件
cp mysql-connector-java-5.1.49/mysql-connector-java-5.1.49.jar /usr/local/logstash/logstash-9.3.0/logstash-core/lib/jars三、配置Logstash
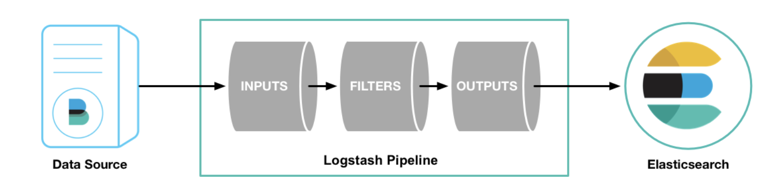
Logstash 管道有input和output两个必须元素,以及一个可选的filter元素。input使用来自源的数据,filter在你指定时修改数据,output将数据写入目标(比如es)。工作示意图如下:
以下以导入db_goods表为例,es中与该表对应的索引为es_db_goods_id经,在/usr/local/logstash/logstash-9.3.0/config目录下,创建导入数据库表的配置文件(如import_db_goods_to_es.conf),文件内容示例如下,具体的账号、主机、表和索引名称请修改为自己的内容:
bash
input {
jdbc {
# MySQL JDBC 驱动路径
jdbc_driver_library => "/usr/local/logstash/logstash-9.3.0/logstash-core/lib/jars/mysql-connector-java-5.1.49.jar"
# JDBC 驱动类名,如果是MySQL 8,则应为com.mysql.cj.jdbc.Driver
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库连接字符串
jdbc_connection_string => "jdbc:mysql://<你数据库服务器IP地址>:3306/<你的数据库名称>?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8"
# 数据库用户名,如root
jdbc_user => "连接数据库的账户名"
# 数据库密码
jdbc_password => "连接数据库的账户密码"
# SQL 查询语句
statement => "SELECT * FROM db_goods"
# 是否分页查询(适用于大数据量)
jdbc_paging_enabled => true
# 每页大小
jdbc_page_size => 1000
}
}
output {
elasticsearch {
# Elasticsearch 地址
hosts => ["http://<你的es服务器IP地址>:9200"]
# 目标索引名称
index => "es_db_goods_idx"
# 文档 ID(可选,避免重复插入)
document_id => "%{id}"
# 如果es需要认证信息,则请提供(如以下的账号信息)
user => "<连接es的账号名>"
password => "<连接es的账号密码>"
}
}如果还有其它数据表要导入,可参照上述配置文件内容,为每个数据表创建一个对应的导入配置文件。
四、导入数据
配置完成后,在/usr/local/logstash/logstash-9.3.0目录下,运行以下命令即可导入数据库表数据到es。
bash
bin/logstash -f config/import_db_goods_to_es.conf五、同步数据库数据
完成导入数据库数据后,还可以使用logstash实现让es自动同步数据库的数据。在/usr/local/logstash/logstash-9.3.0/config目录下,创建一个同步数据库的配置文件sync_db_goods_to_es.conf,示例内容如下:
bash
input {
jdbc {
# MySQL JDBC 驱动路径
jdbc_driver_library => "/usr/local/logstash/logstash-9.3.0/logstash-core/lib/jars/mysql-connector-java-5.1.49.jar"
# JDBC 驱动类名,如果是MySQL 8,则应为com.mysql.cj.jdbc.Driver
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库连接字符串
jdbc_connection_string => "jdbc:mysql://<你数据库服务器IP地址>:3306/<你的数据库名称>?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8"
# 数据库用户名,如root
jdbc_user => "连接数据库的账户名"
# 数据库密码
jdbc_password => "连接数据库的账户密码"
# 是否分页查询(适用于大数据量)
jdbc_paging_enabled => true
# 每页大小
jdbc_page_size => 1000
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
# SQL 查询语句
statement => "SELECT *, UNIX_TIMESTAMP(update_time) AS unix_ts_in_secs FROM db_goods WHERE (UNIX_TIMESTAMP(update_time) > :sql_last_value AND update_time < NOW()) ORDER BY update_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
elasticsearch {
# Elasticsearch 地址
hosts => ["http://<你的es服务器IP地址>:9200"]
# 目标索引名称
index => "es_db_goods_idx"
# 文档 ID(可选,避免重复插入)
document_id => "%{[@metadata][_id]}"
# 如果es需要认证信息,则请提供(如以下的账号信息)
user => "<连接es的账号名>"
password => "<连接es的账号密码>"
}
}以上配置文件可实现每5秒自动同步数据库的db_goods表数据,其中db_goods表中的id字段是主键,为避免重复,通常也用作es文档id,db_goods表中每插入或更新一条记录,该记录的update_time字段也随之更新,logstash将利用该字段实现对数据库的轮询和更新。
完成配置后,在/usr/local/logstash/logstash-9.3.0目录下,执行以下命令即可实现自动同步数据库数据。
bash
bin/logstash -f config/sync_db_goods_to_es.conf同样的,如果需要同步其它表,可参照上述配置,为每个表创建同步配置文件,只需修改表名和索引名。
因为同一台主机上,logstash进程只允许存在一个,如果需要同时同步多个数据表,可采用配置config/pipelines.yml 文件定义多管道。编辑该文件,将每个表对应的同步配置文件作为一个管道加入。
bash
# /usr/local/logstash/logstash-9.3.0/config/pipelines.yml
- pipeline.id: goods-sync
path.config: "/usr/local/logstash/logstash-9.3.0/config/sync_db_goods.conf"
pipeline.workers: 1
pipeline.batch.size: 125
- pipeline.id: orders-sync
path.config: "/usr/local/logstash/logstash-9.3.0/config/sync_db_orders.conf"
pipeline.workers: 1
pipeline.batch.size: 125
- pipeline.id: users-sync
path.config: "/usr/local/logstash/logstash-9.3.0/config/sync_db_users.conf"
pipeline.workers: 1
pipeline.batch.size: 125完成多管道配置后,执行以下命令启动 Logstash,它将自动加载 pipelines.yml 中定义的所有管道。
bash
/usr/local/logstash/logstash-9.3.0/bin/logstash六、将 Logstash 配置为 systemd 服务
6.1 创建logstash.service文件
创建 /etc/systemd/system/logstash.service,内容如下:
bash
[Unit]
Description=Logstash
Documentation=https://www.elastic.co/guide/en/logstash/current/index.html
After=network-online.target
Wants=network-online.target
[Service]
Type=simple
User=logstash
Group=logstash
WorkingDirectory=/usr/local/logstash/logstash-9.3.0
# 环境变量(可根据需要调整堆内存等)
Environment=LS_HEAP_SIZE=1g
Environment=LS_JAVA_OPTS="-Djava.io.tmpdir=/usr/local/logstash/logstash-9.3.0/tmp"
# 启动命令(使用 --path.settings 指定配置目录)
ExecStart=/usr/local/logstash/logstash-9.3.0/bin/logstash "--path.settings" "/usr/local/logstash/logstash-9.3.0/config"
# 标准输出和错误输出到 journal
StandardOutput=journal
StandardError=journal
# 重启策略
Restart=always
RestartSec=10
# 文件描述符限制
LimitNOFILE=65536
# 内存锁定(如果配置文件中有 bootstrap.memory_lock 则可能需要)
# LimitMEMLOCK=infinity
[Install]
WantedBy=multi-user.target6.2 新加载 systemd 并启动服务
bash
# 重新加载配置
sudo systemctl daemon-reload
# 设置开机自启
sudo systemctl enable logstash
# 启动服务
sudo systemctl start logstash
# 查看状态
sudo systemctl status logstash
# 查看实时日志
sudo journalctl -u logstash -f6.3 验证多管道运行
bash
# 查看 Logstash 日志,确认所有管道已启动
sudo journalctl -u logstash | grep "Pipeline started"
# 或者通过 ES 查看索引数据是否同步
curl -u es用户名:es用户密码 "http://<es节点IP地址>:9200/_cat/indices?v"执行以下命令可监控管道状态。
bash
curl -u es用户名:es用户密码 "http://localhost:9600/_node/pipelines?pretty"七、参考文献
1 https://blog.csdn.net/UbuntuTouch/article/details/101691238
2 https://blog.csdn.net/UbuntuTouch/article/details/103874185