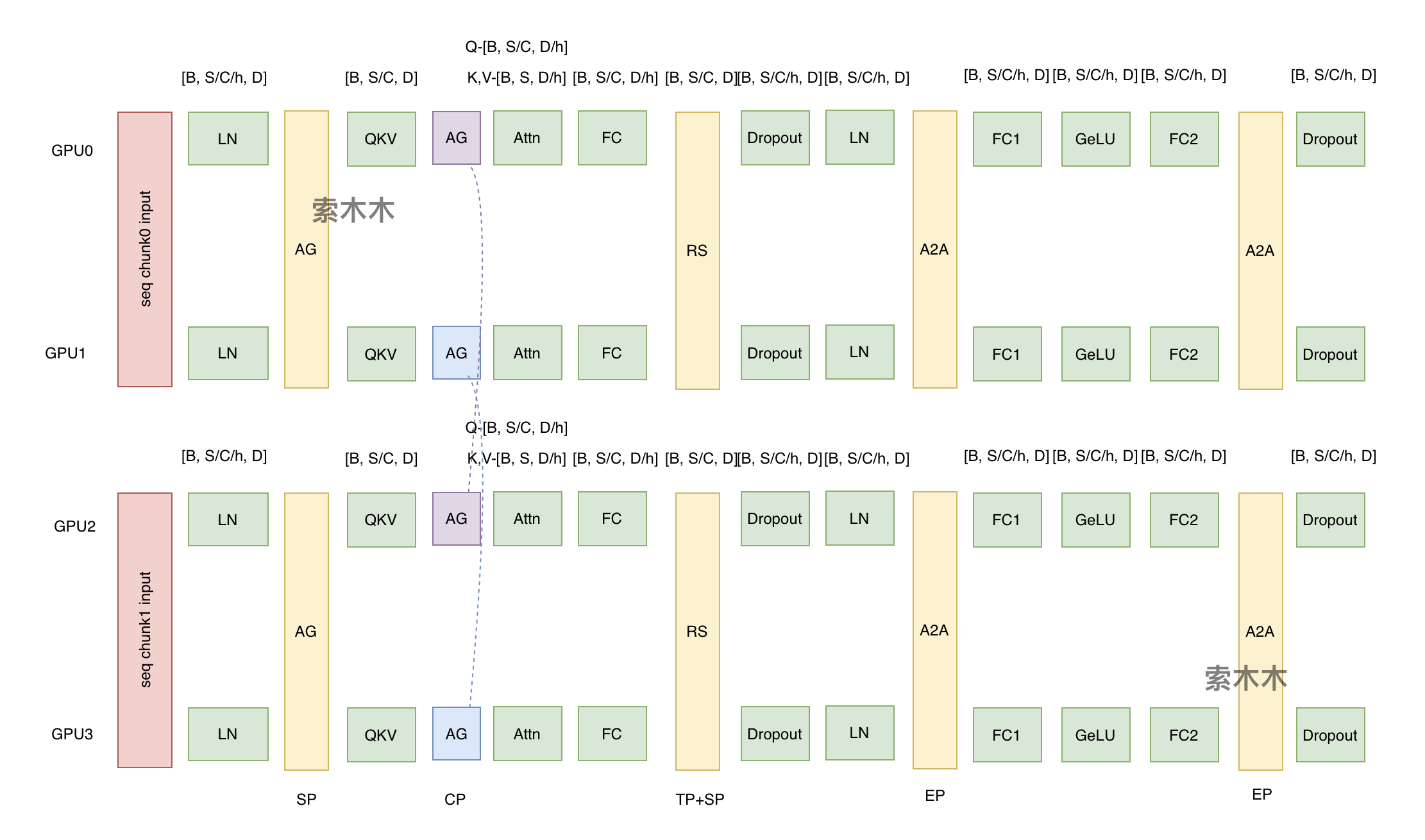
一. CP并行原理
megatron中的context并行(简称CP)与sequence并行(简称SP)不同点在于,SP只针对Layernorm和Dropout输出的activation在sequence维度上进行切分,CP则是对所有的input输入和所有的输出activation在sequence维度上进行切分,可以看成是增强版的SP。之前我有篇文章重点讲了TP、SP、EP技术。本文我讲下长文本的CP技术,以及怎么和TP和SP结合的。
-
如果是为了常规显存优化 (Megatron 路径),设置
sequence_parallel=True,此时它依附于 TP 。此时未配置CP, SP=TP 。总卡数 -
如果是为了训练长文本 (1M 上下文这种),参数通常是
context_parallel_size,此时它与 TP 是乘法关系, CP与TP正交,SP=TP 。总卡数。
二. CP+TP并行场景分析
下文我们重点分析训练长文本的场景,即CP>1。CP=1的常规场景前文有分析。
- TP=1 情况
(1)本地K,V计算:CP是按输入token维度切分好,设c=CP, 维度B, S/c, D作为输入进行Q、K、V计算,通过乘以矩阵。各卡得到的K, V, Q, 都是本地的部分结果。
(2)全局K, V计算:需要再通过一次all-gather得到全局K、V, 注意Q不是全局,是分卡存储。
(3)计算attention: 。输出维度和Q不变,还是B,S/c, D 。
(4)后续再经过linear, Dropout等,维度都不变。
- TP>1 情况, 此时CP与TP正交。
(1)本地K, V计算:维度B, S/c, D作为输入进行Q、K、V计算,通过乘以矩阵, 此时因为TP>1,
矩阵都会按列切分到TP下的各GPU上. 设h=TP(head数),
,
。 Q, K, V运算的结果Q, K, V矩阵维度是B, S/c, D/h。
(2)全局K, V计算:K, V通过一次all-gather聚合,维度是B, S, D/h。
(3)计算attention, 。输出维度和Q不变,还是B,S/c, D/h 。
(4) 然后计算linear, 此时矩阵通过按行切分,到各GPU的
, 输出维度是B, S/c, D, 但此时各GPU在D维度的数据后续需要做一次reduce聚合。
(5)进入dropout,layernorm前,再进行reduce-scatter操作, 相当于在D维度上做了一次reduce聚合. Scatter相当于在SP维度再进行一次切分,Megtron默认SP=TP。输出维度是B, S/c/h, D.
三. CP+TP+SP+EP全场景分析
举例CP=2, TP=2, SP=2,EP=2,CP与TP正交