note
- ROLL团队分享的在终端环境中训练Agentic RL(具身强化学习)的实践经验 ,核心观点是:Agentic RL不仅仅是算法问题,更是环境、基础设施和算法的协同设计。
- mask & filter 策略:当前对训练有害或无法提供有效学习信号的样本都可以采用mask或是filter
- Crash 是常态,关键是如何Resume。Agentic RL本身就是细节很多,这本质上也是一套高度耦合的系统:数据、环境、奖励、调度、优化......任何一个小环节出问题,都可能在几十个 step 之后放大成一次 crash。
- 训练出现不稳定时,两条经验性原则:
- 优先针对极端轨迹进行定向处理(如果极端轨迹能被某些特征定位到,例如 mask 掉超长负样本),如果仍然不稳定,再采用全局重加权。
- RL 梯度通常比监督学习噪声更大,因此更小的学习率,配合更强的约束、退火或自适应机制,往往更稳定。细粒度行为监控与惩罚
文章目录
- note
-
-
- [1. 为什么Agentic RL比传统RLVR更难?](#1. 为什么Agentic RL比传统RLVR更难?)
- [2. 核心工程挑战与解决方案](#2. 核心工程挑战与解决方案)
-
- [A. 环境管理的"双模驱动"](#A. 环境管理的“双模驱动”)
- [B. 数据质量是生命线](#B. 数据质量是生命线)
- [C. 训练稳定性技巧](#C. 训练稳定性技巧)
- [3. 监控与避坑](#3. 监控与避坑)
- [4. 经验和总结](#4. 经验和总结)
-
- Reference
1. 为什么Agentic RL比传统RLVR更难?
- 传统RLVR(如解数学题):是"单步赌博机"问题。模型给出答案,获得奖励,干净简单。
- Agentic RL(如网页导航、工具调用):是"多步交互式决策"问题。模型需要在稀疏、延迟的奖励信号下,在动态环境中持续行动,并承担长程信用分配的责任。
- 本质区别 :从"会回答 "的模型,升级为"会行动"的模型。
2. 核心工程挑战与解决方案
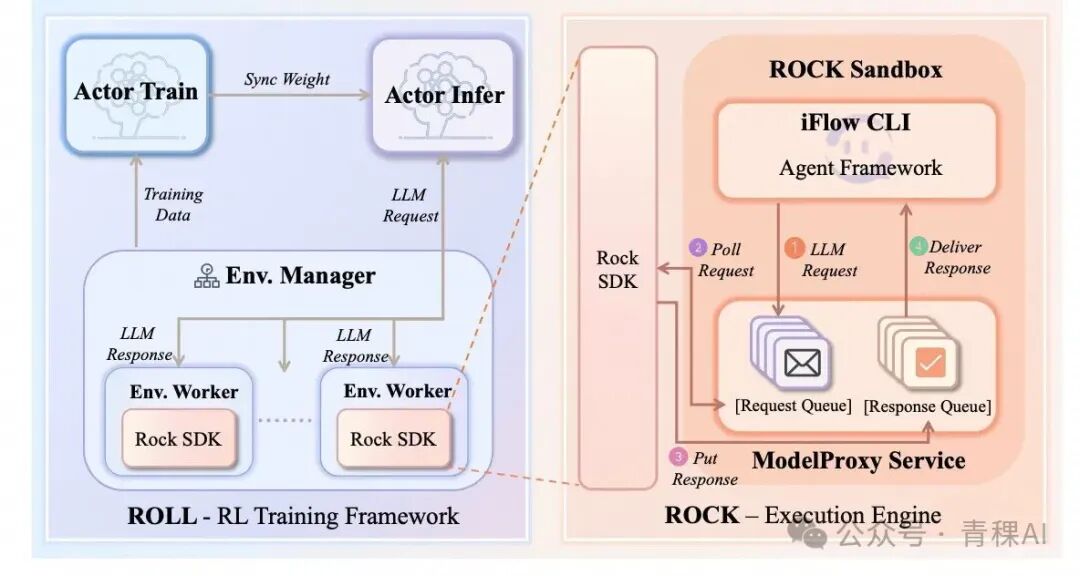
首先在 ROLL 中构建了一套环境管理器,并清晰地划分了三个核心组件之间的交互边界:ROLL(训练框架)、iFlow CLI(Agent 框架) 和 ROCK(沙箱管理器)。
A. 环境管理的"双模驱动"
为了在训练和部署时保持一致,团队设计了两种模式:
- Roll-Managed Mode :由训练框架(ROLL)主导上下文和轨迹管理,灵活性高,适合引入丰富的Prompt模板。
- CLI-Native Mode :直接调用Agent框架(iFlow CLI)的API,一致性高,确保训练输入与真实使用场景完全一致。
B. 数据质量是生命线
RL 实例主要来自两个来源:
1、大规模合成的实例:按照难度与标签采样,并由多个外部供应方进一步标注与筛选。
2、专家编写的实例:通常难度更高、构造更精细。
- 伪阳性(False Positive) :高达40%的合成数据存在漏洞,导致模型"作弊"(如不构建流水线,直接写文件通过测试)。解决方案是引入LLM-as-judge验证模块严格审查。
- 环境净化:严格隔离测试文件,防止模型读取测试脚本"走捷径"。
C. 训练稳定性技巧
- Mask and Filter策略 :
- 对不可恢复错误(如环境崩了):直接Mask掉样本,不产生梯度。
- 对偶发错误(如网络抖动):按比例过滤,避免过度重试。
python
class GroupFilterTB:
def __init__(self, config: AgenticConfig, env_manager_config: EnvManagerConfig, mode: str):
self.config = config
self.env_manager_config = env_manager_config
self.mode = mode
self.global_filter_stats = {"total": 0, "filtered": 0}
def filter(self, group_id: int, episode_id: int, group: list[DataProto]):
"""
Decide whether to filter out an entire group of rollouts.
"""
self.global_filter_stats["total"] += 1
# Step 1: Check whether this group contains any rollout
# that explicitly requests to be dropped
# (e.g., due to tool timeout, transient execution error)
should_drop = False
for data in group:
if data.meta_info.get("drop_flag", False):
should_drop = True
break
# If no rollout indicates a drop condition, keep the group
if not should_drop:
return False
# Step 2: Compute the current global filter ratio
# This guards against pathological cases where
# too many groups are dropped and training stalls
current_global_filter_ratio = (
self.global_filter_stats["filtered"] / self.global_filter_stats["total"]
if self.global_filter_stats["total"] > 0 else 0.0
)
# If we already filtered too much globally, stop filtering
if current_global_filter_ratio >= 0.5:
return False
# Also prevent the *next* filter from exceeding the limit
if (self.global_filter_stats["filtered"] + 1) / self.global_filter_stats["total"] > 0.5:
return False
# Step 3: Drop this group and update global stats
self.global_filter_stats["filtered"] += 1
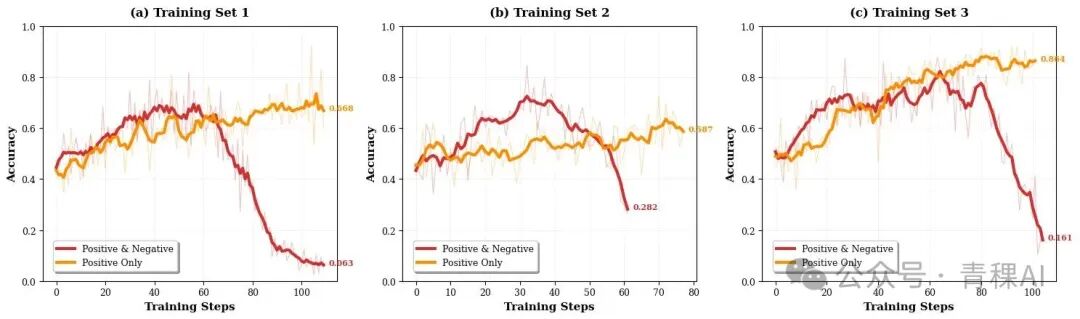
return True- 保守起步 :早期仅使用正样本轨迹训练,构建稳定策略流形;后期再引入负样本提升泛化能力。
- Chunked MDP(交互片段优化) :不按单个Token优化,而是按完整的"工具调用动作单元"优化,解决长程信用分配难题。
3. 监控与避坑
- Reward Hacking(奖励黑客) :模型会学会"坏习惯",如反复重试、修改环境配置。需要细粒度监控工具使用频率和命令模式。
- 崩溃是常态 :训练中崩溃是常态,关键是要有可视化监控体系,快速定位是极端负样本主导还是数据分布问题,并进行回滚或重加权。
4. 经验和总结
训练出现不稳定时,我们通常优先检查以下几个信号:
- 是否有少量极端轨迹正在主导更新?(典型特征:异常长的失败轨迹,伴随重尾分布的负回报)→ 采用masking,降低这些轨迹的权重,并收紧 clipping。
- 负样本是否在整体上占据主导?→ 降低负样本权重,过滤低置信度失败样本,或采用课程式训练策略。
- 模型是否在学习"坏模式"?→ 引入行为惩罚、更多维的奖励设计等。
两条经验性原则:
- 优先针对极端轨迹进行定向处理(如果极端轨迹能被某些特征定位到,例如 mask 掉超长负样本),如果仍然不稳定,再采用全局重加权。
- RL 梯度通常比监督学习噪声更大,因此更小的学习率,配合更强的约束、退火或自适应机制,往往更稳定。细粒度行为监控与惩罚
Agentic RL是一套高度耦合的系统,任何小环节(数据、环境、奖励)出问题都会被放大。前期需要大量繁琐的工程排查,但一旦基建(如异步训练管线、沙箱管理)搭好,后续训练会变得非常稳定。
未来方向包括:挖掘更真实的Human-in-the-loop闭环 、构建更开放的环境 、以及设计更细粒度的奖励模型。
Reference
English Version:https://www.notion.so/The-Bitter-Lesson-Behind-Building-Agentic-RL-in-Terminal-Environments-2eaddd45837f80c9ad2ed6a15ef3c1a1?pvs=21
🚀ROLL TEAM:https://wwxfromtju.github.io/roll_team.html
📄 技术报告:https://arxiv.org/pdf/2512.24873
🧠 模型:https://huggingface.co/FutureLivingLab/iFlow-ROME
🧩 框架:
RL训练框架: https://github.com/alibaba/ROLL
沙盒环境管理: https://github.com/alibaba/ROCK
Agent框架:https://github.com/iflow-ai/iflow-cli
📊 Benchmarks: https://github.com/alibaba/terminal-bench-pro
苦涩的教训!ROLL团队分享:Agentic RL 训练中的实践经验