目录
一.什么是VAE?
1.名字的寓意
1. 为什么叫"变分"(Variational)
由来:源自数学中的"变分推断"(Variational Inference)方法
寓意:
在数学中,"变分"指的是通过优化一个函数(或泛函)来找到最优解
VAE使用变分推断来近似复杂的后验概率分布 P(z|x)
因为我们无法直接计算真实的后验分布,所以用一个简单的分布 Q(z|x) 去近似它
通俗理解:
就像用简单的圆形去近似一个复杂的不规则形状
虽然不完全准确,但足够好用
2. 为什么叫"自编码器"(Autoencoder)
由来:源自传统的自编码器结构
寓意:
自(Auto):自己给自己产生标签,不需要人工标注
编码器(Encoder):将输入压缩成低维表示
解码器(Decoder):将低维表示还原成原始输入
完整含义:一个通过变分推断方法训练的自编码器
2.VAE的核心思想
1. 基本架构
输入图片 x → 编码器 → 潜在分布 z → 采样 → 解码器 → 重建图片 x'
2. 三个关键创新
① 从"点"到"分布"的转变
传统自编码器:将输入编码成一个确定性的点
VAE:将输入编码成一个概率分布(均值和方差)
② 引入随机性
通过采样引入随机性,使模型具有生成能力
相邻的输入在潜在空间中也相邻(连续性)
③ 正则化约束
让潜在分布尽可能接近标准正态分布
保证潜在空间的结构化和完整性
3.VAE的数学本质
1. 生成模型视角
VAE试图学习数据的真实分布 P(x):
假设数据由某些隐变量 z 生成
学习从 z 到 x 的映射关系
2. 目标函数
损失函数 = 重建损失 + KL散度
text
Loss = ||x - x'||² + KLN(μ, σ²) \|\| N(0, 1)
重建损失:保证生成的图片像输入
KL散度:保证潜在空间有良好结构
4.为什么要发明VAE?
1. 解决传统自编码器的问题
传统自编码器:潜在空间不连续,空白区域无法生成有效图片
VAE:通过分布约束,使潜在空间连续、完整
2. 实现真正的生成能力
传统自编码器:只能重建,不能生成新样本
VAE:可以从潜在空间任意采样,生成全新样本
3. 为后续工作奠基
- 为后续的CVAE、VQ-VAE、Diffusion Models等奠定基础
5.直观类比
邮局寄信比喻
传统自编码器:把信复印一份(只能复制)
VAE:学会写信的风格,能写出相似但不同的新信(能创作)
画家学习比喻
输入:看名画(真实图片)
编码:理解画的风格特征(潜在空间)
生成:创作风格相似的新画(输出图片)
6.VAE的优缺点
优点
✅ 生成样本多样性好
✅ 潜在空间有良好结构
✅ 训练稳定,不易崩溃
✅ 可进行插值和属性编辑
缺点
❌ 生成图像偏模糊
❌ 边界不够清晰
❌ 对数似然估计不够精确
7.发展历程
2013年:Kingma等人提出原始VAE
2014年:CVAE(条件VAE)提出
2016年:β-VAE改进解耦表示
2017年:VQ-VAE引入离散潜在表示
至今:VAE思想被广泛应用于扩散模型等现代生成模型
总结
VAE的名字精准反映了其本质:
变分:使用变分推断近似复杂分布
自编码器:采用编码器-解码器结构
它不仅是生成模型,更是连接深度学习和概率图模型的桥梁,为后续生成模型的发展奠定了基础。
二.VAE图像生成的过程
1.具体步骤
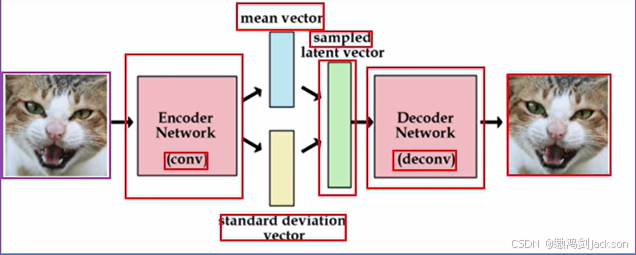
1. 输入图片(像素空间) → 一张真实图片输入VAE
2. 编码器处理 → 编码器不直接输出潜在向量,而是输出高斯分布的参数:
均值(μ):决定分布的中心位置
方差(σ²):决定分布的离散程度
3. 潜在空间采样 → 从高斯分布 N(μ, σ²) 中采样得到潜在向量 z
- 使用重参数化技巧:z = μ + σ * ε,其中 ε ~ N(0, 1)
4. 解码器重建 → 解码器将采样得到的z映射回像素空间
5. 输出图像(像素空间) → 输出重建后的新图片
完整链路:像素空间 → 编码 → 高斯分布参数(μ, σ²) → 采样 → 潜在向量z → 解码 → 像素空间
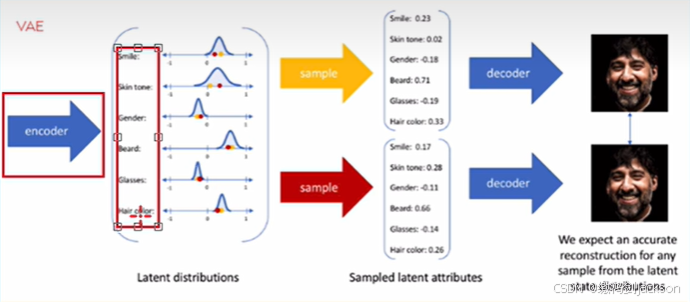
2.举例
三.什么是潜在空间?
1.解释
这是一个非常核心的问题。要理解"潜在空间",我们首先要理解**VAE(变分自编码器)**试图解决什么问题。
简单来说,"潜在空间"就是一个"压缩了的、有组织的、抽象的特征世界"。
为了让你更直观地理解,我们可以用一个**"公司员工信息"**的类比来说明。
- 从"像素世界"到"特征世界"
你看到的图像(原始数据):这就像一张详细的员工登记表,上面有姓名、年龄、照片、籍贯、电话号码、几十页的个人履历等等。信息量非常大,很具体,但也很冗余。在计算机眼里,一张图像就是数百万个像素点的颜色数值(RGB值)。这就是"像素世界"。
VAE的编码器 :它就像一个**"信息压缩专员"**。它的工作不是简单的裁剪图片,而是分析这张图,"看"出其中的关键要素。
比如,看到一张人脸,它会提取:"这是个圆脸、有双眼皮、鼻子挺高、面带微笑、肤色偏白......"
它把这些最关键的特征从像素里抽离出来,丢掉那些不重要的细节(比如背景的一小块阴影、衣服上的一个小褶皱)。
- 什么是"潜在空间"?
这个"信息压缩专员"把提取出的关键特征(比如脸型、眼睛大小、表情、肤色)整理成一个简洁的清单 ,这个清单所在的"世界",就是潜在空间。
在潜在空间里,一张图不再是一个个像素,而是一个**"坐标点"**。
潜在空间是一个多维空间:每个特征(脸型、表情等)都是一个"维度"。比如:
第一个维度是"脸型"(从圆脸到方脸)
第二个维度是"表情"(从悲伤到开心)
第三个维度是"肤色"(从白到黑)
第四个维度是"是否有胡子"
等等......
每张图片都对应一个点 :那么,我给你的那张人脸照片,经过编码器压缩后,就变成了这个多维空间里的一个点。这个点的坐标是:
(脸型:0.8, 表情:0.9, 肤色:0.2, 胡子:0.0, ...)这个坐标的集合,就叫"潜在向量"或"隐变量"。
所以,潜在空间就像一个所有可能图像的"特征索引卡"仓库。每个索引卡(潜在向量)都对应着一张具体的图像。
- VAE让这个空间变得"有规律"
普通的自编码器(AE)也会生成一个潜在空间,但它可能很乱。VAE最厉害的地方在于,它通过特殊的训练方法,强制这个潜在空间变得连续、规则且有意义。
连续性:在潜在空间里,如果两个点离得很近,它们代表的图像就应该看起来很相似。比如,一个点代表"微笑的猫",它旁边的点可能就是"微笑的狗"或者"大笑的猫",而不是突然变成一个"汽车"。
有意义的维度:你可以在潜在空间里"漫步"。
如果你沿着"表情"这个维度往前走,解码器生成的人脸就会从悲伤慢慢变成微笑。
如果你沿着"肤色"维度移动,生成的人脸就会从白变黑。
- 解码器的作用
现在,解码器 就像一个**"画像师"**。它拿到你给的"特征清单"(潜在空间里的一个点),然后根据这个清单,重新画出一张完整的图像。这个过程就叫"解码"或"生成"。
总结一下:
潜在空间不是一张图片 ,它是一个抽象的、数学上的多维空间 。它存储的是图像的**"本质特征"**(隐变量),而不是像素本身。
编码器 的作用:把你看到的图像(像素世界)"映射" 到这个抽象的特征空间(潜在空间)里的一个点上。
这个空间是"有组织"的:相似的图像在这个空间里是相邻的点,并且特征的改变是平滑连续的。这就让我们可以通过在这个空间里移动,来生成新的、从未见过的图像。
一句话总结:
潜在空间就是VAE在学习过程中,为所有图像总结出的一个**"压缩的、有组织的特征字典"**,空间里的每一个坐标点,都对应了一种独特的图像特征组合。
2.总结
简单来说:
像素空间 是你**"看到"** 的世界(具体的),而潜在空间 是模型**"理解"**的世界(抽象的)。
| 特征维度 | 像素空间 | 潜在空间 |
|---|---|---|
| 本质 | 原始数据的物理表达 | 抽象数据的压缩表达 |
| 构成 | 由具体的像素点(RGB值)构成 | 由抽象的特征(隐变量/坐标)构成 |
| 特点 | 冗余、高维、不规整 。 包含大量背景噪声和细节,信息量大但效率低。 | 紧凑、低维、有结构 。 只保留核心特征,信息密度高,维度远低于像素空间。 |
| 关系 | 图像的具体"肉身" | 图像的抽象"灵魂"或"DNA" |
以上就是本篇文章的全部内容,喜欢的话可以留个免费的关注呦~~~