备注:未经博主允许禁止转载,如有问题,欢迎指正。
个人笔记(整理不易,一起努力~)
笔记目录 :学习笔记目录_pytest和unittest、airtest_weixin_42717928的博客-CSDN博客
下载地址
安装提示,意思是这个用户版安装程序不适合以管理员身份运行,他是个人版的,如果需要为全部用户安装,去官网下载 System Installer(系统版安装程序)
这里我使用这个版本了
这里会有个问题,安装后发现登录和注册按钮点击无反应
这时候去打开这个浏览器,并且设置为默认浏览器,这时候按钮就能点击了
新界面
看不懂英文就Ctrl + Shift + X,安装个chinese插件
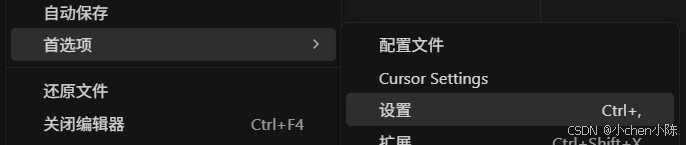
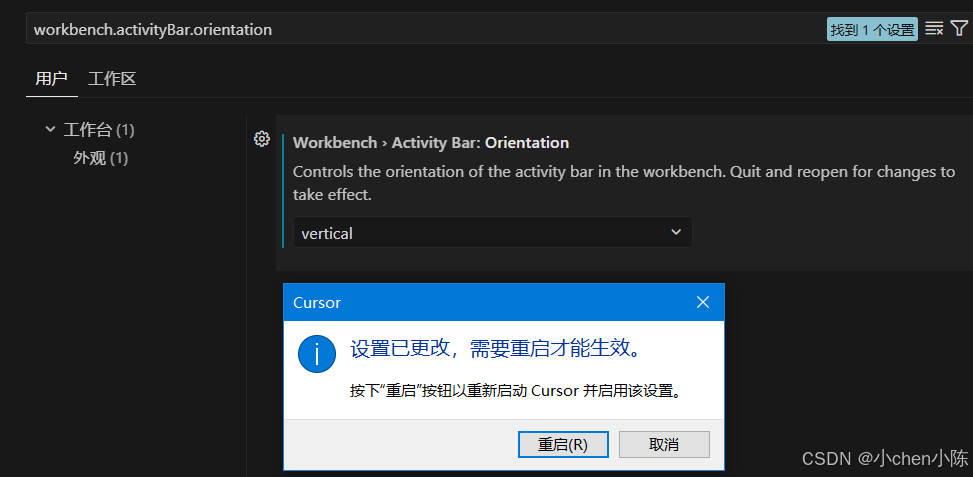
我习惯垂直显示,在设置-workbench.activityBar.orientation ,将其值改为 vertical,重启即可
可以看下内置的大模型
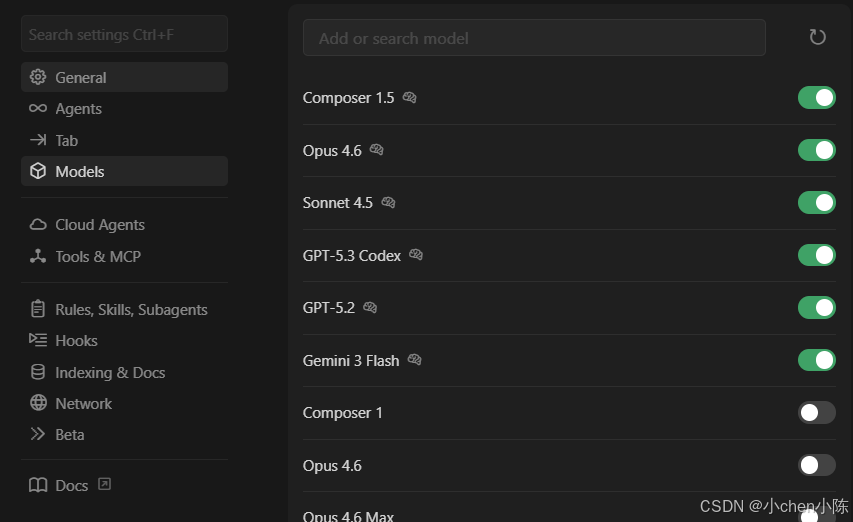
|----------------------------|-----------------|----------------------------------------------------------|
| 模型系列/名称 | 核心定位 | 关键原因 |
| Claude Opus 4.6 (Max) | 顶级全能代码模型 | SWE-Bench 通过率持续领先,系统级编程、复杂工程任务表现最强,上下文窗口最大,对长代码库理解深刻。 |
| GPT-5.3 Codex (Extra High) | OpenAI 最强编程代理 | 代码生成与调试能力顶尖,Terminal Bench 2.0 表现优异,主动协作和多步推理能力强,是工业界首选。 |
| Gemini 3 Pro | Google 多模态旗舰 | 原生多模态理解,复杂算法与数学推理能力突出,在 Codeforces 等平台表现超神,适合高难度算法题。 |
| GLM-5 | 国产开源旗舰 | 国内开源模型天花板,SWE-Bench 表现接近国际一线,在中文编程场景下有独特优势,可部署性强。 |
| DeepSeek-R1 | 国产代码模型新贵 | 专注代码领域,在代码生成、调试和重构上表现亮眼,SWE-Bench 通过率跻身第一梯队。 |
| Sonnet 4.5 | 高效全能模型 | 综合能力强,速度与质量平衡,适合中等复杂度任务,是 Opus 的高性价比替代。 |
| Nova 2.0 Pro | AWS 企业级代码模型 | 针对云原生和企业级应用优化,与 AWS 服务深度集成,稳定性和安全性高。 |
| GPT-5.2 Codex (Extra High) | 上一代旗舰编程模型 | 代码能力稳定可靠,广泛应用于生产环境,仍是很多团队的核心选择。 |
| Qwen3.5 | 阿里最新开源模型 | 代码生成精准度高,对中文注释和文档理解优秀,在轻量级部署上有优势。 |
| Composer 1.5 | Cursor 自研速度优先模型 | 针对代码库深度优化,多 Agent 工作流驱动,速度是同级别模型的4倍,适合快速迭代。 |
| GPT-5.2 (Extra High) | 通用旗舰模型 | 代码能力强,但非专门为编程优化,在纯代码任务上略逊于 Codex 系列。 |
| Claude 3.5 Sonnet | 前代高效全能模型 | 能力稳定,在新版本发布后仍属一线,但已被 Sonnet 4.5 超越。 |
| MiniMax M2.5 | 国产多模态模型 | 多模态理解能力强,代码能力处于中上水平,适合需要图文结合的开发场景。 |
| GPT-4o | OpenAI 前代多模态旗舰 | 多模态能力强,但代码能力已被 GPT-5.x 系列全面超越。 |
| Grok Code | X 社交向代码模型 | 适合快速脚本和原型开发,在特定场景有优势,但综合能力不及一线模型。 |
| Haiku 4.5 | 轻量高效模型 | 速度快,成本低,适合简单代码任务和实时补全,能力不及旗舰。 |
| Gemini 3 Flash | 极速轻量模型 | 响应极快,适合实时补全和简单任务,是速度优先场景的首选。 |
| GPT-5.1 Codex Max | 上一代专业编程模型 | 能力稳定,但已被 5.2/5.3 系列超越,主要用于兼容旧项目。 |
| Kimi K2 | 长上下文模型 | 长文本处理能力强,代码能力中等偏上,适合处理大型代码库文档。 |
| GPT-5.1 / 5.2 Mini | 轻量模型 | 成本极低,适合基础代码任务和教学场景。 |
| Composer 1 | 初代自研模型 | 已被 1.5 版本全面超越,仅作历史兼容。 |
| Gemini 2.5 Flash | 旧版轻量模型 | 能力不及 3 Flash,仅用于兼容旧环境。 |
也可以自定加入大模型
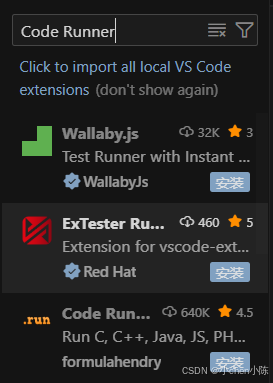
运行代码没运行按钮,就安装个插件
-
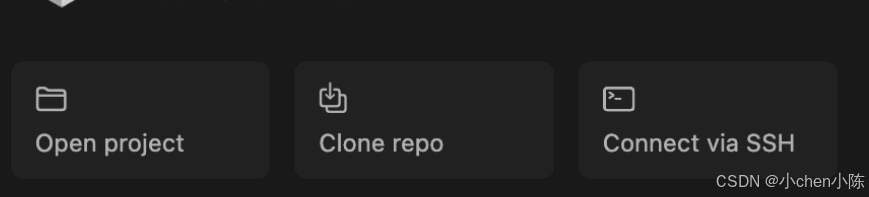
Open project: 打开本地已有的项目文件夹
-
**Clone repo:**直接从 Git 仓库克隆项目
-
**Connect via SSH:**通过 SSH 连接远程服务器上的项目,适合云服务器上的项目调试
-
**Recent projects:**列出最近打开的项目
也可以使用Ctrl + Shift + P,点击第一个安装

然后选择 在 PATH 中 安装 "cursor" 命令 - Shell Command: Install 'cursor' command in PATH 即可为系统 PATH 路径添加了 cursor 命令的引用
一些常用的命令行选项,可以通过 cursor --help 命令查看
控制台乱码:
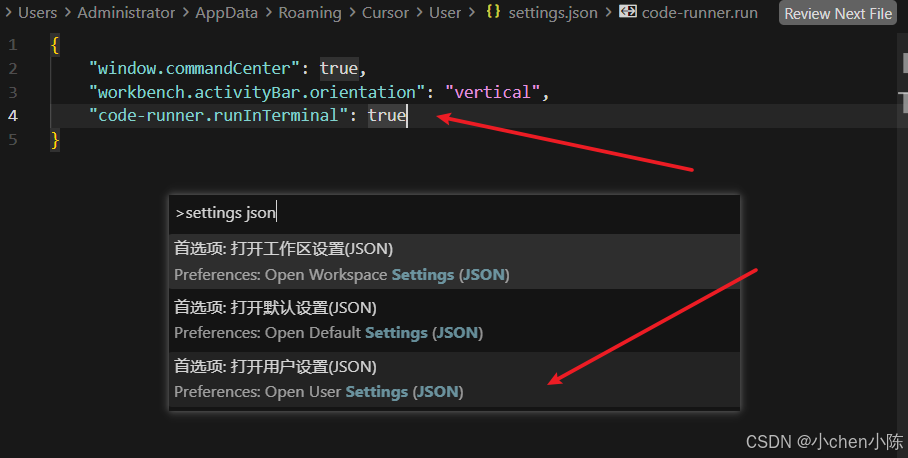
方案1:在settings.json加上"code-runner.runInTerminal": true,这样 Code Runner 会在终端里跑 python,终端对中文支持会好很多,一般就不乱了,在设置 UI 中也可以搜:Code Runner: Run In Terminal,勾上即可
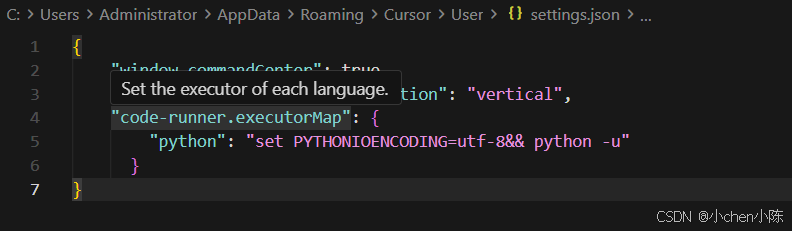
方案2:在settings加上
"code-runner.executorMap": {
"python": "set PYTHONIOENCODING=utf-8&& python -u"
}
含义:
- PYTHONIOENCODING=utf-8:强制 Python 用 UTF-8 编码标准输出/错误。
- Code Runner Output 面板按 UTF-8 解码 → 中文正常
接下来看看新旧版本的变化:
简单地说:
cursor从「AI 代码编辑器」彻底变成了「Agent 驱动的开发平台」
设计核心从「以文件为中心」变成「以 Agent 为中心」
| 旧版功能 | 新版对应模式 | 变化说明 |
|---|---|---|
| Chat 模式(只读问答,不改文件) | Ask 模式 | 完全继承旧版 Chat 的能力,纯解释、答疑、讲代码,不会修改你的任何文件,和你之前的用法完全一致 |
| Composer 模式(写代码、改文件) | Edit 模式 | 完全替代旧版 Composer,精准修改当前文件 / 选中的代码段,自动写入文件,支持逐行预览修改 |
| 旧版 Command 模式(终端命令执行) | 整合进 Agent 模式 | 彻底移除独立入口,现在 Agent 可以自动调用终端、执行命令、查看运行结果,不用单独开模式 |
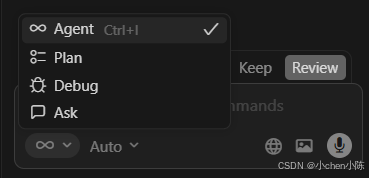
用Shift+Tab就能快速切换模式
1. 🔄 Agent(智能代理模式)
- 核心作用:这是新版最强大的模式,相当于旧版「Composer + Command + Chat」的超级整合体。它能自动理解复杂需求,跨文件修改代码、调用终端、运行命令、验证结果,全程闭环,不用你手动干预。
- 对应旧版:旧版里你需要手动切换 Composer 改代码、Command 跑命令、Chat 问问题,现在 Agent 模式一个顶仨,自动帮你搞定。
- 适用场景:全项目重构、多文件修改、自动修复终端报错、复杂工程化任务(比如 "给这个项目加登录接口")。
- 怎么用:直接在聊天框输入需求(比如 "运行 test1.py 并修复报错"),Agent 会自动判断需要做什么,自动调用终端、修改代码、验证结果,全程不用你管。
2. 📋 Plan(规划模式)
- 核心作用:让 AI 先 "想清楚" 再动手,先输出详细的执行步骤、修改计划,再按计划执行,避免盲目修改代码。
- 对应旧版:旧版没有独立的 Plan 模式,现在是新增的 "先规划后执行" 能力,让复杂任务更可控。
- 适用场景:超复杂任务(比如 "重构整个项目的架构"),你想先看 AI 的思路,确认没问题再让它动手,避免改乱代码。
- 怎么用:在聊天框输入需求后,切换到 Plan 模式,AI 会先输出一份详细的执行计划(比如 "步骤 1:修改配置文件;步骤 2:新增接口;步骤 3:编写测试"),你确认后,再让它按计划执行。
3. 🐞 Debug(调试模式)
- 核心作用:专门处理代码调试、报错修复,自动读取终端报错、定位问题根源、修改代码、重新运行验证,全程闭环,不用你手动复制报错。
- 对应旧版:旧版里你需要手动复制报错→切到 Chat→粘贴→问问题,现在 Debug 模式一键搞定。
- 适用场景:代码报错了,想让 AI 自动定位 bug、修复并验证;或者调试复杂逻辑(比如 "帮我调试这段算法的性能问题")。
- 怎么用:代码运行报错后,切换到 Debug 模式,输入需求(比如 "修复终端里的报错"),AI 会自动读取报错、定位问题、修改代码、重新运行验证,全程不用你碰终端。
4. ❓ Ask(问答模式)
- 核心作用 :纯问答、解释代码,完全不会修改你的任何文件,对应你熟悉的旧版「Chat 模式」,只读答疑,不改代码。
- 对应旧版:旧版的 Chat 模式,用法完全一致,只是换了个名字。
- 适用场景:问代码是什么意思、解释报错原因、查语法、讲概念(比如 "这段 Python 代码的逻辑是什么?""PEP8 规范是什么?")。
- 怎么用:切换到 Ask 模式,输入问题,AI 只会给你文字解释,不会修改任何文件,安全又省心。
| 模式 | 会不会改代码 | 核心能力 | 对应旧版 | 适用场景 |
|---|---|---|---|---|
| Agent | ✅ 会改(全项目) | 自动处理复杂任务,跨文件、调终端 | Composer+Command+Chat | 全项目重构、复杂任务 |
| Plan | ❌ 先规划,后执行 | 先出计划,再按计划改 | 新增功能 | 超复杂任务,先看思路 |
| Debug | ✅ 会改(精准修复) | 自动读报错、修 bug | 新增功能 | 代码报错、调试问题 |
| Ask | ❌ 完全不改 | 纯问答、解释代码 | Chat 模式 | 答疑、讲代码、查概念 |
Edit模式:和右侧的全局聊天面板,是两个完全独立、默认不互通的对话空间,对话是临时、用完即走的快捷对话,关闭文件 / 重启 Cursor 后就会消失,不会自动保存到右侧的主对话历史里,避免零碎的小修改污染你的主对话记录

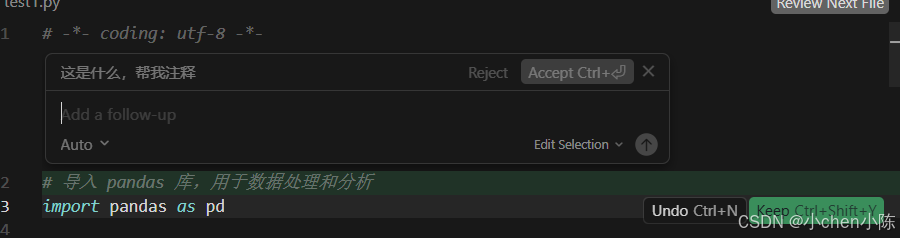
- 绿色高亮的行:就是 AI 给你新增的注释内容,标绿是告诉你「这是本次新增的修改」,和旧版 Composer 的差异高亮逻辑一模一样。
- 右下角的行级按钮(单条修改控制)
Keep Ctrl+Shift+Y:保留这一行的修改,确认要这行注释;Undo Ctrl+N:撤销这一行的修改,不要这行注释,恢复成原来的样子。
- 顶部的全局按钮(一键控制所有修改,最常用)
Accept Ctrl+回车:一键接受所有修改,把 AI 给你加的所有注释都保留下来,直接写入文件,和你旧版 Composer 的「确认修改」完全一致!Reject:一键拒绝所有修改,不要 AI 改的任何内容,恢复成你原来的代码,和旧版的「取消修改」一致。
- 底部的 Add a follow-up 输入框:如果你觉得改得不满意,想让 AI 调整(比如 "注释写得太简单了,再详细点"),就在这里输入需求,点右边的箭头发送,AI 会继续修改。
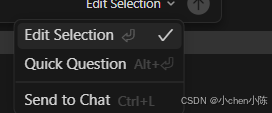
| 选项 | 对应旧版功能 | 核心用法 | 会不会改代码 |
|---|---|---|---|
| Edit Selection(你现在选的,带对勾) | 旧版「Composer 模式」 | 输入修改需求,AI 直接修改你选中的代码段,修改后会显示红 / 绿差异对比,你可以选择接受 / 拒绝 | ✅ 会改代码 |
| Quick Question | 旧版「Chat 模式(快速问答)」 | 输入问题,AI 只会给你解释、答疑这段代码,比如 "这段代码是什么意思""有没有 bug",纯问答 | ❌ 完全不改代码 |
| Send to Chat | 旧版「发送到聊天面板」 | 把你选中的代码,直接发送到右侧的大聊天窗口里,适合长需求、复杂对话,不用在小输入框里写 | ❌ 不改代码,仅发送上下文 |
| 对比维度 | 行内 Edit 模式(Edit Selection) | 右侧全局聊天面板(你截图里的这个) | 对应你熟悉的旧版功能 |
|---|---|---|---|
| 对话生命周期 | 临时对话,关闭文件就消失,不保存历史 | 持久对话,所有内容永久保存,随时能翻历史记录 | Edit 对应旧版 Composer 的临时修改弹窗;右侧面板对应旧版独立的 Chat 面板 |
| 作用范围 | 只能修改你选中的那一段代码,完全不碰其他内容,精准到行 | 可以跨文件、全项目操作,能改多个文件、调用终端、处理整个项目的复杂任务 | Edit 是单点精准修改;右侧面板是全项目复杂任务 |
| 内容互通 | 对话只存在于当前代码的弹窗里,不会同步到右侧面板 | 所有发送的内容、AI 回复都会永久保存在这个对话里 | 旧版 Composer 的对话不会自动进 Chat 面板,逻辑完全一致 |
| 适用场景 | 10 秒就能搞定的小需求:加注释、改变量名、修小段 bug、优化几行代码 | 长对话、复杂需求:全项目重构、多文件修改、架构设计、需要保留历史记录的需求 | |
| 可控性 | 极强,只会动你选中的代码,不会改乱其他内容 | 功能更全,可操作整个项目的任意文件 |
如果你想让 Edit 里的需求和对话,显示并保存在右侧的主聊天面板里,操作非常简单:
- 选中代码,唤起 Edit 输入框;
- 点击输入框里的「Edit Selection」下拉框;
- 选择 「Send to Chat」,就会把你选中的代码、输入的需求,一起发送到右侧的全局聊天面板里,对话就会永久保存在这里了。
给老用户的使用建议(对应你旧版的使用习惯)
- 快速改小段代码、加注释、修小 bug → 用行内 Edit Selection,快、无痕迹,不会污染你的主对话历史;
- 问长问题、复杂需求、需要保留对话历史、跨文件改东西 → 用右侧的全局聊天面板,对应你旧版的 Chat 模式;
- 全项目重构、多文件修改、自动跑终端命令 → 用右侧面板的 Agent 模式,这是旧版完全没有的新能力
旧版繁琐的「手动 @上下文」,现在被智能替代
旧版你必须手动@文件名、@代码块,AI 才能拿到上下文;
新版默认智能感知,Agent 模式下会自动理解你的需求,去代码库里找对应的文件、依赖、函数,不用再手动 @了(当然也保留了手动 @的能力,精准控制上下文)
旧版本的Command模式,独立的 Command 标签页,只在 2024 年 2 月 - 2024 年 8 月的 v0.20~v0.35 这几个中间小版本 里短暂上线过,只不过用的少,后面我那个版本就转到底部终端左下角 ,写着 Ctrl+K to generate a command,这个就是 Command 模式的核心功能
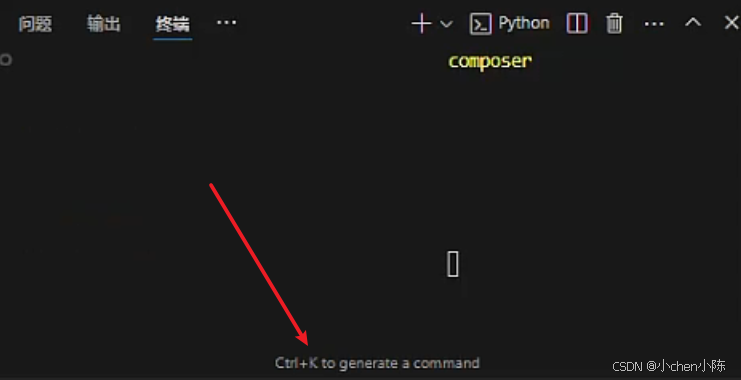
按 Ctrl+K,就会弹出输入框,用自然语言说需求(比如 "运行当前 Test.py 文件""安装 pandas 库"),AI 就会自动生成终端命令并执行,和独立的 Command 模式功能完全一致
现在的旧版 Command 模式 ,整合进新版 Agent 模式的自动终端调用
新版:直接在右侧聊天面板用 Agent 模式 ,AI 会自动判断什么时候需要用终端,不用你手动切换模式
- 比如你说 "运行 test1.py",Agent 会自动打开终端、执行命令、看运行结果
- 比如你说 "安装 openpyxl",Agent 会自动运行
pip install openpyxl - 比如代码报错了,Agent 会自动读取终端报错、定位问题、修改代码、重新运行验证
新版 Cursor 的 AI 在读取终端时,默认有一套「优先看最新内容」的逻辑
它的读取规则是:
- 优先看「最后一次运行」的输出 :它会自动识别终端里的命令提示符(比如
PS F:\...>或C:\...>),只读取最后一个命令之后的所有内容; - 自动跳过旧的、已结束的命令:上面旧的报错,因为是在之前的命令里输出的,AI 会自动忽略;
- 重点关注红色报错:它会优先识别终端里标红的错误信息,自动过滤掉普通的白色 / 灰色输出
3 种让它 100% 只看最新报错的方法(实操)
如果你想完全保险,避免它偶尔看错,可以用下面这 3 种方法,按推荐程度排序:
方法 1:运行代码前,先清空终端
这是最彻底的方法,清空后终端里只有最新的输出,AI 绝对不会看错:
- 清空终端旧信息
- 运行代码获得最新的运行结果 / 报错
- 直接在 Agent 模式说:"看终端报错并修复",AI 只会读取这唯一的最新内容。
方法 2:在需求里加「关键词」,明确引导它
如果你不想清空终端,就在你的 prompt 里加几个词,明确告诉它只看最新的:
- ❌ 普通说法:"看终端报错"
- ✅ 精准说法(直接复制):
- "看终端最后一次运行的报错,帮我修复"
- "忽略上面旧的,只看最新的这一次报错"
- "看终端最下面的红色报错,定位 bug"
加了这些关键词后,AI 会自动跳过上面的旧记录,只读取终端末尾的最新内容。
方法 3:手动选中最新报错(最笨但最精准)
如果你还是不放心,就用最直接的方法:只选中最新的那几行报错,发给 AI:
- 在终端里,用鼠标只选中你刚运行出来的那几行红色报错(不要选上面旧的);
- 按快捷键
Ctrl + L(或者右键选中的内容 → 点击「Send to Chat」); - 选中的报错会自动发送到右侧聊天面板;
- 直接输入:"帮我修复这个报错",AI 只会基于你选中的这一段内容回答,100% 不会混淆。
prompt/prɑːmpt/本质就是「你写给 AI 的指令 / 问题 / 需求」
| 类型 | 是什么 | 举例 | 你之前用过的场景 |
|---|---|---|---|
| 临时 prompt(日常用) | 你在聊天框 / Edit 模式里临时输入的需求,用完就存在对话里 | "给这段代码加注释""修复终端报错" | Edit 模式输入框、右侧 Agent/Ask 聊天框里的内容 |
| 系统 prompt(全局设置) | 藏在 Cursor 设置里的「全局指令」,会给 AI 定 "规矩",所有对话都生效 | "始终用中文写注释""遵循 Python PEP8 规范""回答要简洁" | 无需手动输,AI 会默认遵守的底层规则 |
临时 prompt
- Edit 模式(改代码) :选中代码 → 按
Ctrl+I→ 输入框里写需求(比如 "给这段代码加详细中文注释")→ 发送,这个需求就是 prompt; - Agent/Ask 模式(问答 / 全项目操作):右侧聊天框里输入 "看终端最新报错并修复"→ 发送,这句话就是 prompt;
系统 prompt(全局设置,定制 AI 的 "行为准则")
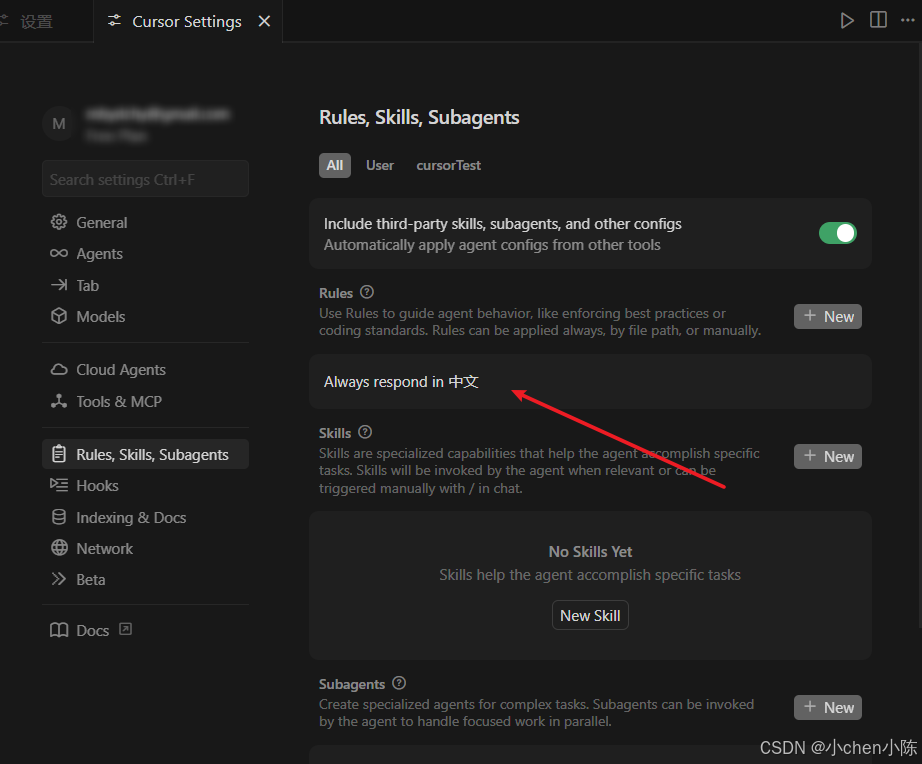
截图里已经有一条规则:Always respond in 中文,这就是一条全局规则,意思是让 AI 在所有对话中都用中文回应
顶部的「All」「User」「cursorTest」标签,可以切换规则的作用范围:
User:全局规则,对所有项目生效。cursorTest:项目级规则,只对当前项目生效(优先级更高)
旧版的「system prompt」已经升级为这里的 Rules,功能更强大,还可以配合 Skills(技能)、Subagents(子代理)一起使用
Skills 技能系统
你可以通过SKILL.md文件,定义自己的专属工作流、代码规范、常用命令,Agent 会自动识别并加载使用。比如把公司的代码规范写成 Skill,AI 写代码会自动遵守,不用每次都在 prompt 里重复说明
Subagents 子代理(2026 年 1 月最新更新)
针对超复杂任务,主 Agent 会自动把任务拆分成独立子任务,分给专属子代理并行处理,比如你要做一个完整的前后端项目,它会自动拆分前端、后端、数据库、测试等子任务,同步推进,不用你一步步引导
这个是 Cursor 里的 AI 模型自动选择模式,意思是:
- Auto(自动模式):当这个开关打开时,Cursor 会根据你当前任务的复杂度,自动选择最合适的 AI 模型(比如简单的代码补全用快模型,复杂的多文件修改用强模型),不用你手动切换。
- Balanced quality and speed, recommended for most tasks:这是对 Auto 模式的说明,意思是它会在「生成质量」和「响应速度」之间做平衡,适合绝大多数日常开发任务,既不会太慢,也能保证不错的效果。
大概了解了新版本的cursor后,接下来思考如何使用?
1:先规划后执行
先把东西想清楚,规划如何做
| 专业名词 | 通俗解释 | 作用 / 类比 |
|---|---|---|
| Spec(全称 Specification) | 就是「详细的做事说明书 / 规格书」,比 Plan Mode 的 "计划" 更正式、更规范 | 装修的 "施工图纸 + 材料清单 + 工期表",写得越细,结果越准 |
| OpenSpec/SpecKit | 专门用来生成 "正式 Spec" 的外部工具 / 框架(相当于装修的 "设计模板") | 不用自己瞎写清单,用现成的模板生成规范的 "做事说明书" |
就跟OpenSpec/SpecKit生成Spec一样,cursor也可以使用plan去生成规划,
然后交给Agent执行
2:上下文与规则配置
使用上下文感知的项目规则:新版本已经支持Skills
ps:.mdc 是 Cursor 早期版本 推出的「增强型 Markdown 文件」(可以理解为 "带元数据的 Markdown"),是专门用来定义「项目级细粒度规则」的专属格式 ------ 本质就是比普通 .md 文件多了几行 Cursor 能识别的 "元数据"(比如 globs、description),用来实现 "精准的上下文感知"。普通的全局规则(Rules)是 "一刀切" 的(对所有文件生效),而 .mdc 文件能实现「编辑特定文件时,才加载对应规则」,避免规则泛滥导致 AI 响应混乱
globs:文件匹配规则(和编程里的文件通配符一样),告诉 Cursor "哪些文件要加载这个规则";
| 符号 | 含义 | 例子 | 匹配效果 |
|---|---|---|---|
* |
匹配「任意文件名」(不跨目录) | *.py |
匹配所有 .py 文件(比如 test.py、main.py) |
** |
匹配「任意目录」(跨目录 / 递归) | **/src/*.py |
匹配所有目录下 src 文件夹里的 .py 文件(比如 a/src/test.py、b/c/src/main.py) |
? |
匹配「单个字符」(用得少) | test?.py |
匹配 test1.py、test2.py,不匹配 test10.py |
description:规则的简短描述,Agent 能看懂,当它需要用到规则时会智能拉取(比如你让 AI 改 Python 代码,它会先看这个 description,再加载完整规则)
新版本(2026.1.26 及以后)优先推荐用 Skills,而非 .mdc 文件
简单说:.mdc 只能 "被动加载规则",而 Skills 能 "主动调用技能"
| 对比维度 | .mdc 文件 | Skills |
|---|---|---|
| 功能范围 | 仅能定义 "规则" | 不仅能定义规则,还能绑定自定义命令、子代理(如 Bash subagent)、触发条件、甚至调用外部工具 |
| 触发逻辑 | 仅靠 globs 匹配文件 |
支持文件匹配、关键词触发、手动调用等多种方式,更灵活 |
| 联动性 | 仅和 AI 规则联动 | 和 Agent/Plan/Debug 模式深度联动,能作为 "技能包" 被 AI 主动调用 |
拆分大文件:重构大文件;以此为目标进行模块化
ps:大文件会产生巨大的上下文开销。AI 必须读取整个文件才能理解一个小小的更改,所以文件过大需要要求AI帮助重构并将其拆分为单一职责的模块(但是随着LSP的发展,后续可能不需要了)
ps:LSP(语言服务器协议):编辑器和 "代码理解专家" 之间的沟通规则,核心是**精准提取代码上下文,**有 LSP:AI 只读相关代码片段 → 开销骤降 → 不用拆分大文件,Cursor 已经部分实现了 LSP 相关能力,只是还没完全覆盖 "大文件精准切片"
-
比如你在 Cursor 里按住 Ctrl 点击函数名,能跳转到定义处 → 这就是 LSP 让语言服务器找到的;
-
比如你编辑 Python 文件时,Cursor 能自动提示函数参数 → 也是 LSP 的功劳;
-
等 Cursor 完全实现 LSP 对大文件的 "精准上下文提取" 后,就不用再手动拆分大文件了
忽略无关文件:使用 .cursorignore (优先级比skills高)排除那些 git 没有忽略但在 AI 上下文中不需要的文件,以防止 Token 浪费
禁用闲置的并且不支持延迟加载的 MCP:在不主动使用时关闭不支持延迟加载的 MCP,不支持延迟加载的闲置MCP 配置会消耗 Token 并分散模型的注意力;仅在专门与外部工具交互时(例如 JIRA MCP)启用 MCP 工具。对于支持延迟加载MCP可以保留,只在命中meta信息时加载必要上下文
ps:MCP 是 Model Context Protocol 「模型上下文协议」:Cursor 里的 AI 模型(LLM)和外部工具 / 服务(比如 JIRA、数据库、API)之间的 "沟通桥梁"
每个 MCP 旁边都会有一个开关(Toggle),用来启用 / 禁用它(我这里还没add MCP)
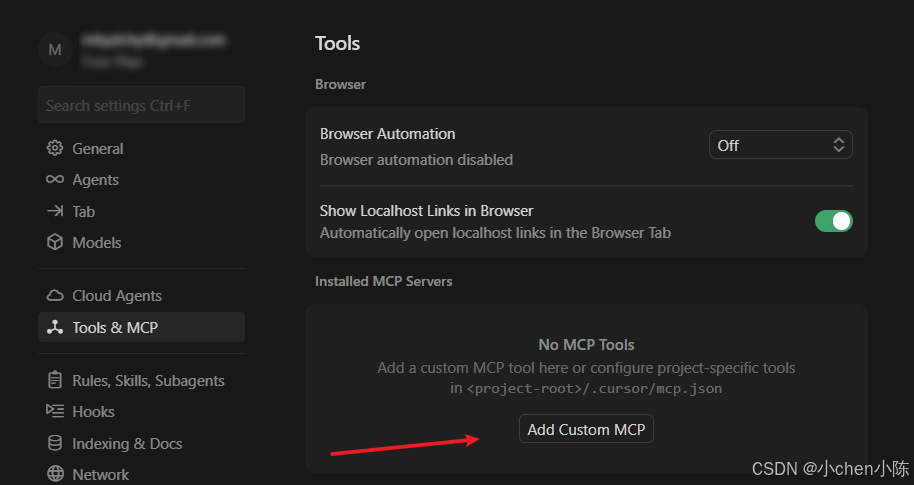
不支持延迟加载的 MCP 有个 "坑":
- 只要你开启它,哪怕半天不用(闲置),它也会一直把自己的配置、连接信息、甚至工具数据塞进 AI 的上下文里;
- 后果 1:消耗 Tokens(AI 处理上下文的 "容量"),导致大文件 / 复杂需求时容易超出上下文限制;
- 后果 2:分散 AI 注意力(比如你让 AI 改 Python 代码,JIRA MCP 的无关信息会让 AI 分心,甚至出现幻觉)。
| MCP 类型 | 特点 | 例子 |
|---|---|---|
| 不支持延迟加载 | 一旦开启,就全程占用 AI 上下文(不管用不用),消耗 Tokens、分散注意力 | 早期的 JIRA MCP、部分数据库 MCP |
| 支持延迟加载 | 开启后不占上下文,只有用到时(命中 meta 信息)才加载,用完就释放 | 新版的 Git MCP、File MCP |
「meta 信息」(元信息)就是描述 "信息的信息" :它不直接是代码、文本这类核心内容,而是用来标注 "这个内容是什么、该怎么用、和谁关联" 的辅助信息
比如:Git MCP 的 meta 信息
Git MCP 的 meta 信息就是和 Git 相关的关键词 / 指令:
- 比如你在 Cursor 聊天框输入:"帮我写一个 git commit 信息""解决 git merge 冲突""查看 git log";
- 这些关键词(git commit/merge/log)就是 Git MCP 的 meta 信息;
- 只有输入这些词时,Git MCP 才会加载;你只写 "改一下 Python 函数",它就不加载
易混点:meta 信息 ≠ 核心内容
| 类型 | 例子(Git MCP 场景) | 作用 |
|---|---|---|
| meta 信息 | git commit、JIRA-123 | 触发 MCP 加载的 "开关" |
| 核心内容 | 具体的 commit 信息文本 | MCP 加载后获取的实际数据 |
控制输出冗余:明确限制 AI 生成不必要的总结、解释或文档,除非你主动要求
LMM废话说,由于输出 Token 通常比输入 Token 更贵且更慢,冗长的回复会浪费资源并弄乱聊天记录,可以加规则优化,如:"仅在明确要求时才创建新文档。"
3:工作流与交互
拆分任务与管理会话:将复杂功能分解为原子子任务,并频繁开启新对话(New Chat),随着聊天记录的增长,LLM(大模型) 的表现会下降。一个新的对话意味着清除了噪点
ps:不要在一个长对话中完成整个功能,而是为"API 实现"、"前端逻辑"和"UI 样式"创建单独的对话
使用 @:使用 @ 符号手动缩小上下文范围,防止 AI 猜测(并产生幻觉)它需要读取哪些文件
ps:什么是ai幻觉?
AI 明明不知道、没查到、没把握,却一本正经地 「瞎编、胡说、造不存在的东西」,而且说得特别像真的,这就叫 AI 幻觉。
这是大模型(LLM)本身的问题,AI 不是靠 "记忆事实",而是靠预测下一个词最可能是什么 来生成内容。一旦它不确定,就会编得很合理 ,但内容是假的
控制终端噪音:保持日志清洁,并使用高性价比的模型来处理执行任务,2026.1.26更新 下载最新版本Cursor,其已经内置Bash subagent(Agent 模式里输入需求后,只要涉及终端操作,都是 Bash subagent 在干活),可以很好的解决这个问题
ps:Bash subagent 解决问题的核心逻辑
- 第一步:过滤终端输出,只提取 "高价值信息"(解决日志冗余)
Bash subagent 会先对终端输出做 "降噪处理":
- 自动识别并丢弃无关内容:比如环境加载日志、非关键警告、重复的调试信息;
- 精准抓取核心信息:只保留编译错误、运行时报错、命令执行结果等关键内容;
- 第二步:匹配 "性价比模型" 处理终端任务(解决模型浪费)
Bash subagent 会根据任务复杂度自动选模型:
- 简单任务(比如提取报错、执行基础命令):用轻量 / 低价模型(比如 Flash、Grok),速度快、Token 成本低;
- 复杂任务(比如根据报错改代码):再把关键信息传给高端模型,让高端模型只做 "改代码" 这个核心活;→ 避免用高端模型做 "找报错" 这种低价值工作,实现 "高性价比"。
- 第三步:闭环处理,减少无效交互(进一步降低噪音)
Bash subagent 能直接替主 Agent 完成终端相关的闭环操作:
- 比如你说 "运行 test.py 并修复报错":
- Bash subagent 用轻量模型执行
python test.py; - 过滤出关键报错;
- 只把报错传给主 Agent(高端模型)改代码;
- 改完后,Bash subagent 再用轻量模型重新运行验证;→ 全程只有关键信息在模型间传递,没有冗余日志的来回传输,彻底控制 "终端噪音"。
- Bash subagent 用轻量模型执行
4:故障排除与优化
陷入僵局时的使用重置策略:如果一个 Bug 在多次尝试后仍未修复,**停止并重置;**上下文窗口已经被失败的尝试污染了。继续下去只会导致死循环和糟糕的代码;删除最近的消息或开始一个新的对话。使用更具体的约束条件编辑你的 Prompt。选择 Continue 前先 revert 代码
拒绝并让AI自己改正:使用"Reject(拒绝)"按钮或明确说不正确;你自己默默修复 AI 的糟糕代码并不能教会模型任何东西;如果输出是错误的,拒绝更改并解释原因,强制其自我修正。这同样适用于你想修改现有代码时
5: 处理大型遗留项目
通过日志增强理解:利用 AI 在遗留代码中植入日志以追踪执行流
ps:遗留系统通常包含"僵尸逻辑"(已废弃/死亡但仍存在的代码)和误导性的描述或者注释。日志提供了实际运行情况的"真实数据(Ground Truth)",而不是凭空猜测
如:
- 指示 AI 增强核心逻辑的日志记录。
- 运行应用程序并分析日志,验证哪些代码块实际上被命中了。
- 要求 AI 根据这些发现生成报告
6:模型选择策略
根据任务难度匹配模型,以优化成本和速度
复杂逻辑 / 规划 / 深度调试
- 推荐模型 :Claude 4.5 Sonnet, GPT-5.2,
Gemini 3 Pro - 使用场景:制定计划、重构、架构决策。
简单编辑 / 样板代码 / 测试执行
- 推荐模型 :
grok-code,Gemini 3 Flash - 使用场景:快速修复、编写简单的单元测试、解释终端错误。
如果你不确定复杂度
- 使用 Auto 模式
其他新功能:
1:Cursor 2.4内置 AI 图像生成器,基于 Google Nano Banana Pro模型,直接在编辑器里生成图片
并自动保存到项目根目录的assets/文件夹
2:cursor blame,责任归属