作者:来自 Elasticsearch Lily Adler

一个开源 Elasticsearch 9.x 分析器插件,通过在分析链中对 token 进行词形还原,改善 Hebrew 搜索,以提高对 Hebrew 形态的召回率。
Elasticsearch 拥有丰富的新功能,帮助你为你的使用场景构建最佳搜索解决方案。在我们关于构建现代 Search AI 体验的实操 webinar 中,了解如何将这些功能付诸实践。你也可以现在开始免费 cloud 试用,或在本地机器上试用 Elastic。
Hebrew 在形态上非常丰富:前缀、词形变化和附着词使得精确 token 搜索脆弱。该项目提供了一个开源 Elasticsearch 9.x 的 Hebrew 分析器插件,在分析链中执行神经词形还原,使用嵌入的 DictaBERT 模型,并通过 ONNX Runtime 以 INT8 量化模型在进程中执行。
快速开始
下载相关版本或构建并安装(Linux 构建脚本会生成与 Elasticsearch 兼容的 zip):
./scripts/build_plugin_linux.sh在 Elasticsearch 中安装:
/path/to/elasticsearch/bin/elasticsearch-plugin install file:///path/to/heb-lemmas-embedded-plugin-<ES_VERSION>.zip测试:
curl -k -X POST "https://localhost:9200/_analyze" \
-H "Content-Type: application/json" \
-u "elastic:<password>" \
-d '{"tokenizer":"whitespace","filter":["heb_lemmas","heb_stopwords"],"text":"הילדים אוכלים את הבננות"}'为什么 Hebrew 搜索不同
Hebrew 在形态上非常丰富:前缀、后缀、词形变化和附着词都会合并为单一的表面形式。这使得简单的 tokenization 不足。没有真正的词形还原,搜索质量会下降;用户可能因为形式的简单变化而错过相关结果。该项目通过将 Hebrew 词形还原模型嵌入分析器本身解决了这个问题,使每个 token 在索引和查询前都通过神经模型处理。
示例
用户可能搜索词干 "בית"(house),但文档可能包含:
- בית(a house)
- בבית(in the house)
- לבית(to the house)
- בבתים(in houses)
- לבתים(to houses)
没有词形还原时,这些会成为不同的表面 token;词形还原会将它们规范化到相同的词干(בית),提高召回率:
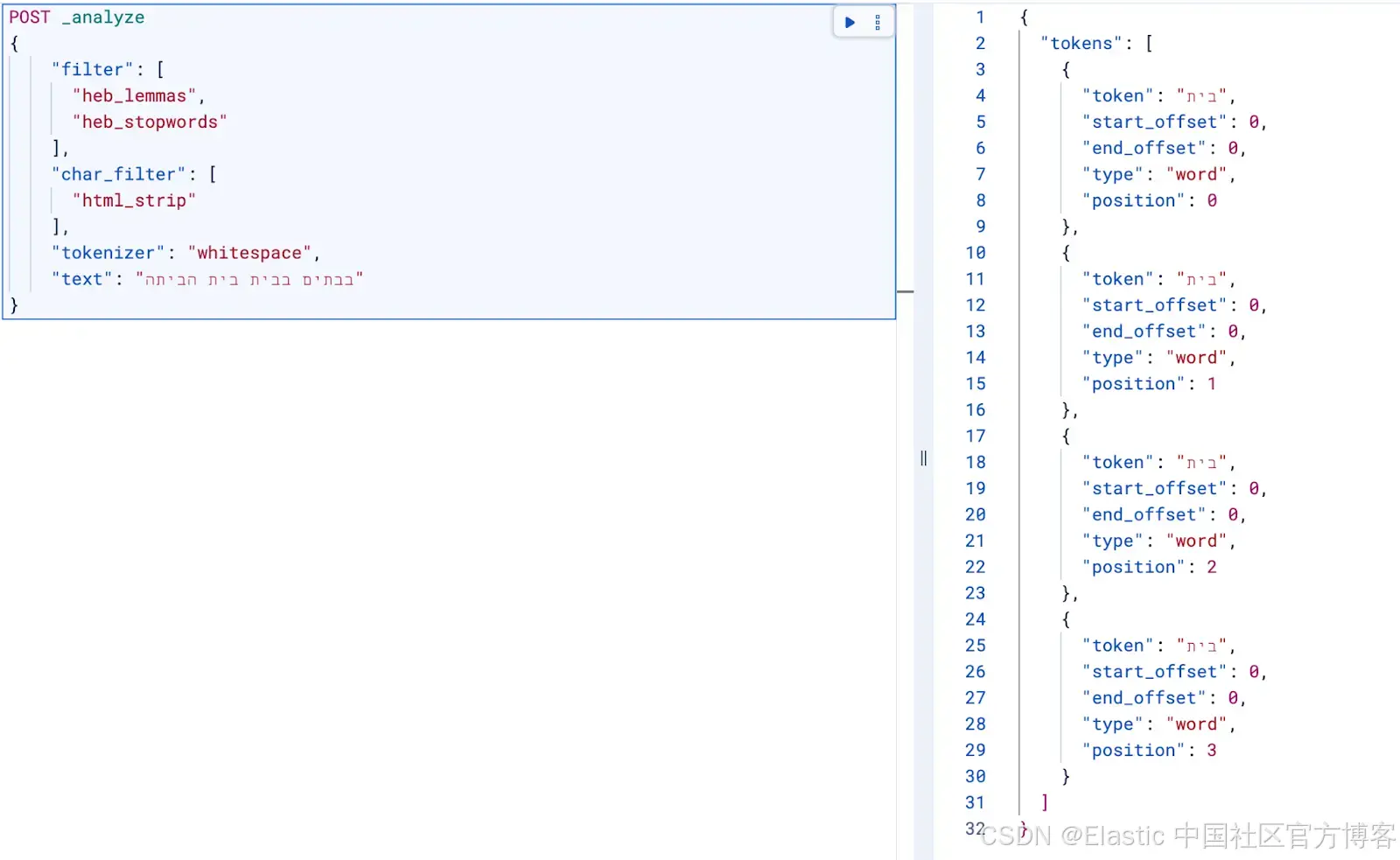
这个插件的功能
该分析器不是依赖规则的词干提取,而是在 Elasticsearch 分析链中运行 Hebrew 词形还原模型,为每个 token 输出一个规范化的词干。因为模型是神经网络,它可以在每个分析段中利用局部上下文,在模糊情况下选择合适的词干 ------ 同时仍生成适合索引和查询的稳定 token。该分析器:
- 在 Elasticsearch 内运行 Hebrew 词形还原模型。
- 为 Hebrew 文本生成更好的规范化 token。
- 支持停用词和标准分析器管道。
结果:快速、可靠的词形还原
该分析器针对实际吞吐量进行了优化:
- 使用 ONNX Runtime 进行进程内推理。
- INT8 量化模型以降低延迟和内存占用。
- 通过 Java Foreign Function Interface(FFI)实现高性能原生推理。
结果:快速、可靠的词形还原,操作行为可预测。
为了评估性能,我们在 Docker 容器(4 核,12 GB RAM)中对 100 万条大文档(5.7 GB 数据)进行基准测试,数据来源于 Hebrew Wikipedia 数据集。结果如下:
| Metric (search) | Task | Value | Unit |
|---|---|---|---|
| Min throughput | hebrew-query-search | 409.75 | ops/s |
| Mean throughput | hebrew-query-search | 490.65 | ops/s |
| Median throughput | hebrew-query-search | 491.85 | ops/s |
| Max throughput | hebrew-query-search | 496.13 | ops/s |
| 50th percentile latency | hebrew-query-search | 7.02242 | ms |
| 90th percentile latency | hebrew-query-search | 10.7338 | ms |
| 99th percentile latency | hebrew-query-search | 19.0406 | ms |
| 99.9th percentile latency | hebrew-query-search | 27.165 | ms |
| 50th percentile service time | hebrew-query-search | 7.02242 | ms |
| 90th percentile service time | hebrew-query-search | 10.7338 | ms |
| 99th percentile service time | hebrew-query-search | 19.0406 | ms |
| 99.9th percentile service time | hebrew-query-search | 27.165 | ms |
| Error rate | hebrew-query-search | 0 | % |
开源且兼容 Elastic
该插件完全开源,可在以下环境中使用:
- Elastic 开源发行版
- Elastic Cloud
你可以自行构建,也可以下载预构建版本并像安装其他插件一样安装。
要将分析器插件上传到 Elastic Cloud,请在 Elastic Cloud 控制台中导航到 Extensions 部分,然后进行上传。
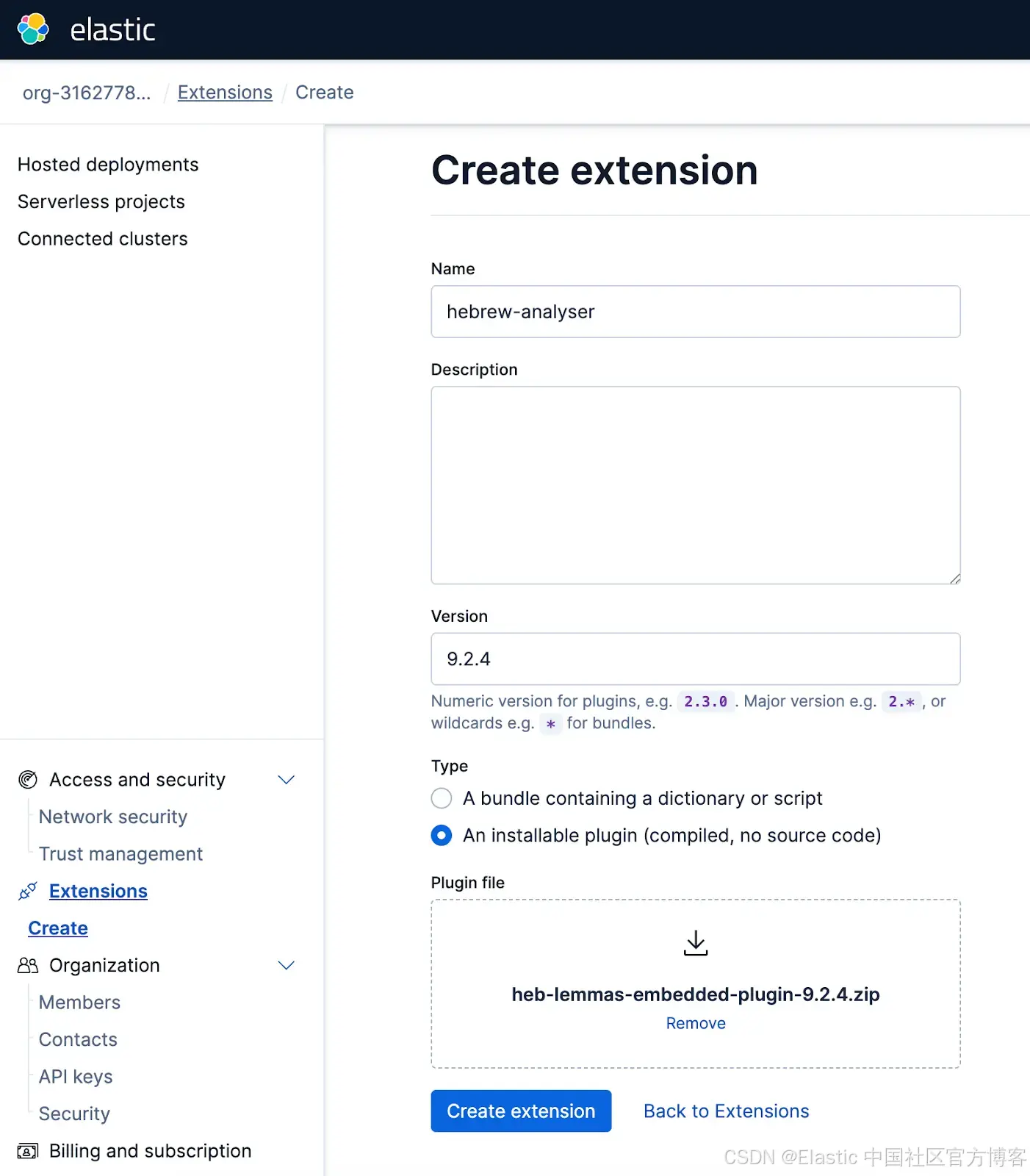
鸣谢
该项目是 Korra ai Hebrew 分析插件(MIT)的一个 fork,由 Korra.ai 实现,并在 MAFAT 和以色列创新局领导的国家 NLP 项目资助和指导下完成。
此 fork 关注 Elasticsearch 9.x 兼容性,并通过 ONNX Runtime 完全在进程内运行词形还原,使用 INT8 量化模型和捆绑的 Hebrew 停用词。词形还原由 DictaBERT dicta-il/dictabert-lex(CC‑BY‑4.0)提供支持。
特别感谢 Dicta 团队为社区提供高质量的 Hebrew 自然语言处理(NLP)模型。
链接
原文:https://www.elastic.co/search-labs/blog/elasticsearch-lemmatization-hebrew-analyzer